
Abstract
Abstract
1. Introduction
Mathematically speaking, we want to find a subset S out of a set of random variables
Exploring the conditioned associations can uncover hidden mechanisms or processes that operate only when the condition exists. For example, such mechanisms can be quantitative and qualitative modifications of elements of the immune system in response to pathogens, emergency services recruitment upon a catastrophic event, or DNA mutations in an infecting virus arising under the selection pressure of a novel treatment.
Pearl (2009) specifies the benefits of using a graph representation of joint probability mapping—specifically clarity, convenience, and economical representation. Graphical notation and terminology will be used in this article.
Problem example
Assume there are three random binary variables (car rental shortage [
Exploring the correlations between
Graphical representation of the dependencies between three random variables.
Using Bayesian networks to infer about conditioned patterns
Bayesian networks (BNT) represent the conditional dependencies between random variables, using a Directed A-cyclic Graph (DAG) (Cooper and Herskovits, 1992). BNT are commonly used in problems similar to ours, such as mapping the associations between genes (Friedman et al., 2000) and the associations between HIV DNA mutations (Deforche et al., 2006).
The condition variable is usually referred to as a variable with a predefined value. Predefining the value of a variable is commonly termed “intervention” or “perturbation” of the observed data.
Pearl (2009) uses the term “Atomic Intervention” to describe an external manipulation of a network variable value. He suggests adding to the condition variable a parent variable that activates the induced state (Pearl, 1993).
Pe'er et al. (2001) explored the causal relationships between genes' expression level. In their article, they note that external perturbations such as medical treatment, which have no direct influence over other variables (in this case gene expression level) but indirectly affect the values of many other variables, should be regarded as “indicator variables,” and added to the BNT with the constraint that they cannot have other variables as network parents.
Note that the above examples require manipulating or placing constraints over the discovered network structure.
The result of inducing the condition variable to our data will be a joint probability map, containing a node representing the condition. In order to deduce the conditioned associations, one can traverse through the nodes connected to the condition node, or review the whole connected component containing the condition node.
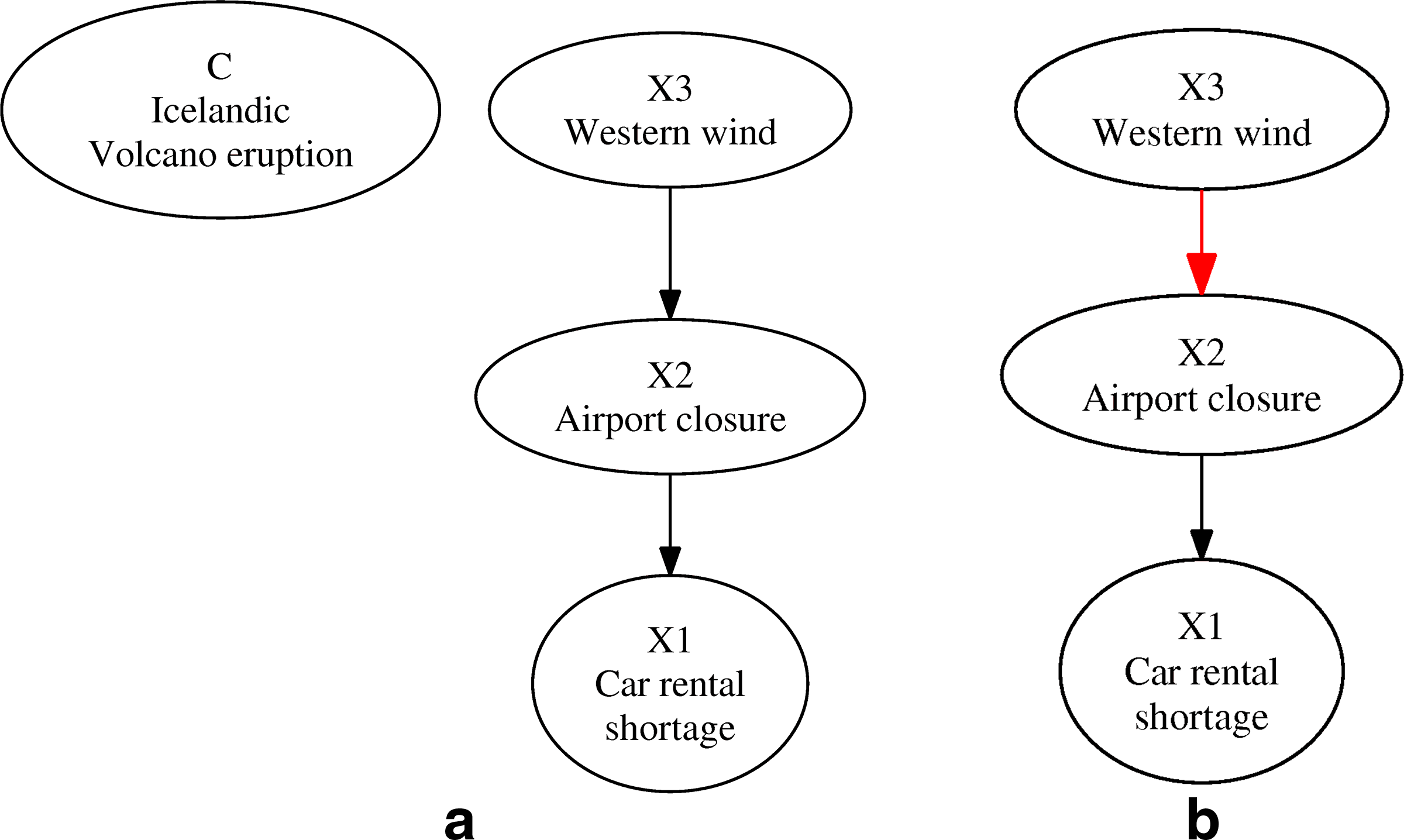
Figure 2 displays the joint probability mapping of our example, represented by a BNT. It is clear that the new edge,

Bayesian Network representing the joint distribution mapping of X1, X2, X3, and the condition C. The edge x3 → x2 was retrieved using the BNT.
However, this case demonstrates the ambiguity encountered when trying to discover conditioned associations using BNT. The
This matter could be resolved by exploring the differences between the BNT without the condition variable and the BNT containing the condition variable. Yet in many cases, the proportion of the samples with a positive value of the condition variable may be large enough for the conditioned associations to appear in the BNT without the condition variable. In other cases, when the proportion of the samples with a positive condition value is small enough, the conditioned associations will not be discovered in the BNT with the condition variable. In fact, the former ambiguity was clearly visible in a simulation described later in this article.
Deforche et al. (2006) overcomes this issue by preexamining the candidate variables for the BNT and selecting variables that show significant correlation with the condition. This way the chance that background associations will arise is lowered; conversely, conditioned associations with variables that are not significantly correlated with the condition may be lost. In the above example, since Western wind (
Another drawback might be caused by the stochastic nature of searching the BNT model and its DAG structure. Reconstructing the BNT structure from given observational data requires searching through all possible models and looking for the model that maximizes the log-likelihood of the data. Since this problem is NP-Hard (Chickering et al., 2004), cases with more than a few variables require heuristic search methods (Friedman et al., 2000). Since prior causal knowledge is missing in many cases, our model search can result in structures that satisfy the observed statistical dependencies, but cannot accurately recover the underlying “real” structure or suggest an equivalent model that may hide the conditioned associations.
Consider the case displayed in Figure 3a, where an additional variable is added to our network: ash cloud (

Alternate Bayesian Network representation of our data. These networks maintain the d-separation criteria between the variables, though now the novel conditioned association (x3 → x2) should be searched within the whole connected component containing C.
This example shows the ambiguity faced when trying to draw conclusions concerning the conditioned association while exploring the graph structure of the BNT. In cases where the network structure is unknown, a single criterion cannot be applied in order to locate the conditioned associations, since we can alternate between two different graph structures that represent a single conditioned association.
This ambiguity affects the search procedure applied in order to locate the novel conditioned associations. To ensure that the conditioned association edges are covered by our search space, the edge directions should be ignored and the edges of the connected component containing the condition should be added to our search space. However, our search space will be greatly obscured by background association added to our result. Applying the methods described above, such as adding an activating variable (Pearl, 1993) to the condition variables, or removing the edges from the parents of the condition variable, while increasing the inference capabilities of the network, still does not eliminate the ambiguity regarding other variables.
Dependency networks
Heckerman et al. (2000) suggest a method that deals with some of the problems that arise, when interpreting a resultant BNT, especially the tight topology constraints, such as DAG, and the dependencies implied from the d-separation criteria.
This method iteratively regresses, using probabilistic decision trees. Each variable uses the rest of the model variables, and uses the prediction capabilities of the regressor variables as criteria for adding an edge between the regressor variables and the predicted variable. This method retains the “Markov Blanket” property of the BNT—given the parents' values for a network variable; it renders this variable independent of all other variables.
Dependency networks provide another advantage over other modeling methods: since the computation is done locally over the variable's immediate neighborhood, the computational effort is polynomial over the number of variables and, as such, more efficient.
Meinshausen et al. (2006) suggest a method for reconstructing the variables' graphical neighborhood using an estimation of Tibshirani's (1996) lasso method, applying penalty over the regression coefficients norm, and applying a zero value to coefficients with negligible prediction values. While regressing a variable using all the other variables as predictors. Non-zero coefficients will add an edge between the predictor and the predicted variables, that is, enabling a robust and computational efficient method for reconstructing a dependency network, especially in high dimensional cases.
Friedman et al. (2008) later enhance this model, suggesting an efficient exact solution to the lasso peer regression problem, using the Banerjee et al. (2008) blockwise coordinate descent approach. This method, herein graphical lasso, is demonstrated on cell signaling data from 11 different proteins.
Dependency networks efficiently solve the above problems, providing a straightforward interpretation and usage of a robust numerical mechanism. Yet the ambiguity between the background and conditioned associations still needs to be solved, since the condition variable is still part of the resulting network.
Current state of the art and the proposed method
The above sections display the inherent limitations of locating conditioned associations using BNT modeling, mainly the DAG structure that constrains the network structure and observational equivalency that may produce different graphical models for similar variable dependencies. Both limitations can cause the conditioned associations to appear far, or not on the path of the condition variable in the result graph, and so, largely increase the number of associations that need to be tested as candidates for conditioned associations.
Dependency networks and their recent adaptations solve this problem by addressing the local dependency neighborhood of the variable. Therefore, at least one of the conditioned association vertices should be a neighbor of the condition variable.
Yet, both Bayesian and dependency networks may identify associations that are independent of the condition (background associations). Since the background associations have the same topological features as conditioned associations, it is hard to discriminate between conditioned and non-conditioned associations, which results in a major increase in the search space.
We introduce a modification of the dependency network method, which obtains a graph containing only conditioned related associations.
We suggest a tool, based on an efficient and numerically robust implementation of ridge regression, which maps the associations of variables under the condition. These properties render it invariant to the proportion of the conditioned samples in the population. The resulting graph identifies the associations between variables that are correlated specifically under the condition variables, and so solving the ambiguity between associations in the general population (background associations) and conditioned associations.
2. IRR Method
We suggest a method that graphically maps conditioned associations between variables. Each association can be illustrated as a directed edge between the variables. The edges can be weighted according to the assumed prediction strength between the variables under the condition. The result will be a network structure (built as a directed graph) that will map the variable associations under the condition.
Exploring the network structure is done by regressing the condition variable using the remaining variables, observing the weight change of the regressor variables when omitting one, and then again regressing the condition variable by the remaining variables.
We will show that the weight change in the remaining variables is relative to their predictive value over the omitted variable under the condition.
Prediction capabilities of one variable by another, under the condition, can be used as a cue for conditioned association, which can later be tested separately by a simple hypothesis testing tool.
Defining the problem
Let
Selection or regularized regression method
In a classic regression problem, we want to find a weight set W that satisfies the equation:
In order to handle the problem of regressing variables with high covariance (typical of the problems explored by the Iterative Ridge Regression [IRR]), which cause instability when inverting the sample matrix, a statistical method called ridge regression, or Tikhonov regularization (Tychonoff and Arsenin, 1977) is utilized. This method adds a penalty over the weight vector norm.
where the λ parameter stands for the ridge parameter.
Another method, called the lasso regularization, suggested by Tibshirani (1996), replaces the ridge regression's L2 norm penalty of the weight vector, with L1 norm penalty:
While it also has an efficient solution of the weight vector, it also tends toward a zero value for negligible coefficients when using a large enough λ value.
As was recently suggested, the elastic nets (Zou and Hastie, 2005) use a mix of L2 and L1 regularization over the weight norm:
where the α parameter value determines whether the penalty leans toward L2 (which displays the ridge regression behavior) or L1 (lasso).
In their most recent article, Friedman et al. (2010) display a distinction between the above three regularization methods—ridge regression, lasso, and elastic nets—in regards to the effect of the weight change of regressor variables after omitting one of them.
Since the L2 norm penalty amplifies an uneven weight distribution, ridge regression tends to split the coefficient weight of the omitted variable between the highly correlated variables. Lasso, on the other hand, tends to pick one correlated variable to receive the weight of the omitted variable. Elastic-nets behavior depends on the value of the α parameter.
In our case, the inter-relations between the variables are more relevant than the precision of the model's prediction. Therefore, the ridge regression will be more suitable for our needs, while there is a need for a threshold value to filter the negligible interaction,
Iterative interaction discovery
Once the regularization method is chosen, the conditioned interactions are discovered while iterating over the model variables.
At the first stage, the regression of the condition variable will be done, using the variables in S:
Later, in each iteration j, the values of variable
This results in a new set of weights for the remaining features, Wj, which will be compared with the original set of weights. The weight difference of each feature can be computed: ΔWj = WB − Wj
As proved in Appendix 7c, ΔWj is the coefficients vector that gives the best regularized estimation of
At this point, the benefits of ridge regression come in hand. The best estimation of
For instance, if
In this case, one can expect all of the variables that highly correlate with
Therefore, each element
If [ΔWj]i passes a known threshold t, the association
Passing both criteria, an edge xj → xk will be added to our graph G.
See Appendix (sections 7a and 7b) for pseudo code and demonstration of the method.
Complexity of the IRR algorithm
Since the IRR algorithm uses both ridge regression and χ2 test, both have many robust and efficient implementations, its calculation time is a linear function over the sample size.
Overall, using an N size variable set and an M size sample set, the IRR regresses the sample set N times, then tests again within the set all of the N variables for significant associations.
In this case, the IRR's asymptotic complexity is O(N2M).
3. Comparing the IRR Algorithm with BNT
Herein is a performance comparison of the IRR algorithm with the state-of-the art BNT algorithm. Both algorithms try to locate a priori induced associations between variables that correlate under a condition.
Data set construction
The sample set contains 1000 samples with 20 variables. Each variable can hold a binary value of − 1 or 1.
Each sample is assigned with a binary condition value; the total size of the condition vector is 1000 samples. All sample values were initialized to −1, afterwards 0.2 of the samples had their values inversed to simulate background noise.
Out of the 20 variables, four variables were randomly selected to hold the conditioned pattern – their values will be correlated under the condition and random otherwise.
Out of the condition vector, a predefined ratio (0.8) of the samples was set as a condition, and their values were set to 1. Out of the conditioned samples, a predefined ratio (0.2) was randomly selected to hold the pattern. These samples will have a positive (1) value in the conditioned pattern variables.
After the construction of the sample set, sampling noise was induced by inversing the values of a predefined ratio (noise level) of the sample set.
Simulation overview
Both the IRR and the BNT algorithms were used to extract the conditioned pattern variables. We used the BNT Matlab package of Murphy (2001) for BNT construction. The BNT was constructed using the K2 algorithm (Cheng et al., 1997) that outperformed other network construction algorithms (Leray and Francois, 2004).
As described above, the BNT result DAG was searched for the connected component containing the condition variable. All the variables in this connected component (ignoring edge directions) were tested as the result pattern.
The BNT and the IRR result patterns were tested against the induced pattern and scored using the Jaccard Index. For each noise level, 100 independent simulation executions were performed, and the mean and standard deviation of the Jaccard score were used as a basis for performance comparison between the IRR and the BNT (see exact simulation details in Appendix 7d).
Results
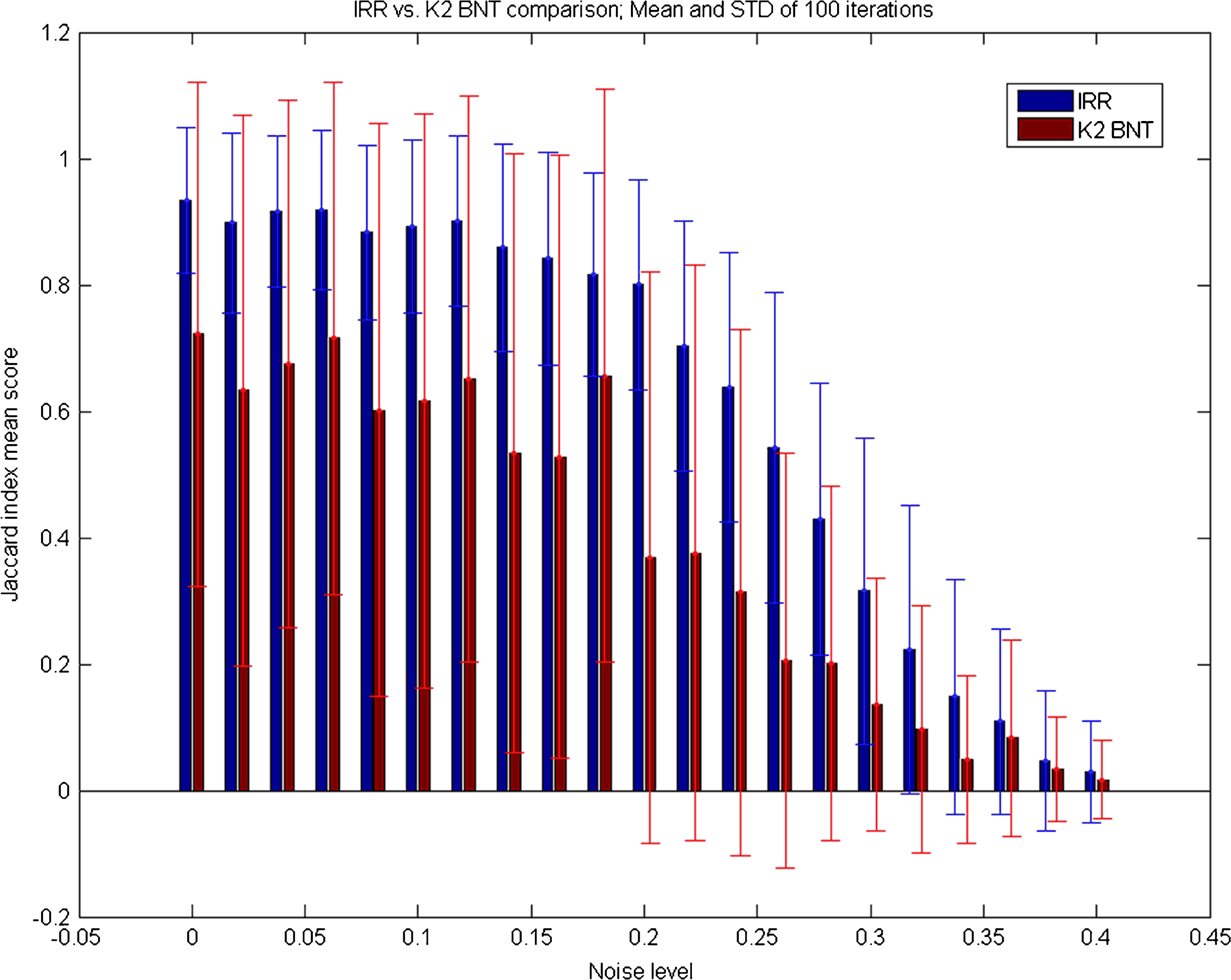
Graphic representation of the Jaccard index scoring mean and STD of the IRR and Bayesian Network K2 algorithms, over 100 iterations. The IRR algorithm significantly outperforms the Bayesian Network K2 algorithm (p < 0.01). The STD values show more stable performance by the IRR as compared with the K2 algorithm.
The comparison results
The simulation results show that the IRR performs well when trying to locate conditioned patterns in data that have up to 25% noisy (i.e., reversed) values. At these noise levels, the IRR significantly (p < 0.01) outperforms known state-of-the-art algorithms such as the K2 BNT algorithm.
These results emphasize the effect of association ambiguity of the BNT, as shown in the following simulation case:
In this case, a 4 sized pattern that includes variable numbers 1, 16, 17, and 20 was induced to a 20 random variables data set. These variables associate only under the condition; otherwise, they are randomly correlated.
Figure 5 shows that the IRR result is a fully connected graph, which includes the pattern variables. The BNT graph, which by nature is a DAG, contains the pattern variables but also two other variables (var12 and var15) that were randomly associated with the pattern variables, regardless of the condition.
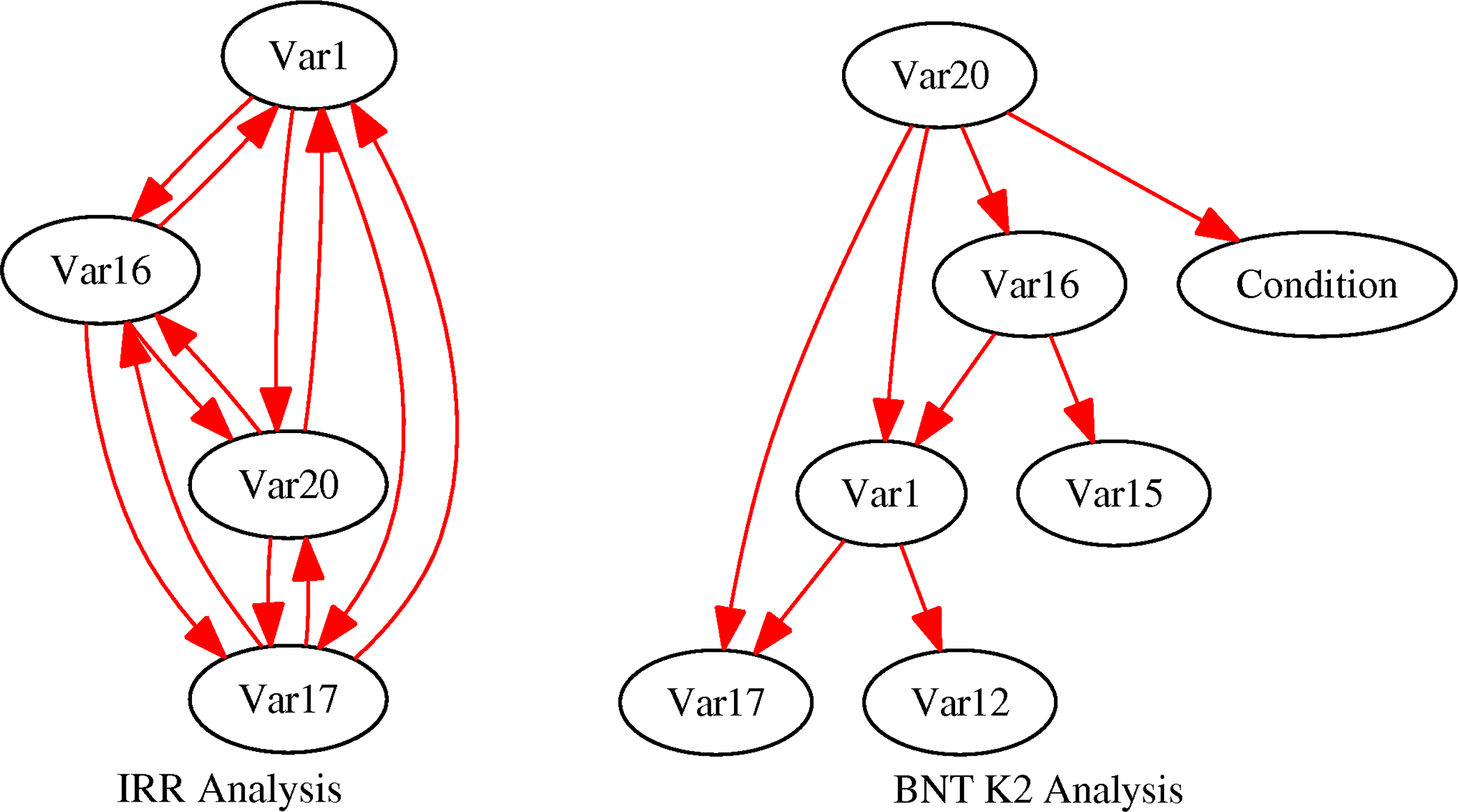
Graphical result of pattern locating. The pattern contains four variables (Var1, Var16, Var17, and Var20) in a 20 random variables data set. The IRR has fully located the induced pattern, while the BNT has also located two randomly correlated variables (Var12 and Var15), not associated in the pattern under the condition.
As described before, we can only assume about the conditional nature of the BNT result by exploring the connected component of the graph containing the condition, and ignoring the direction of the edges, thus including variables 12 and 15 in the suggested pattern result.
In this case, the Jaccard index score of the IRR graph will be 1 (fully compatible with the pattern), while the BNT result will be 0.67.
4. Application of the IRR for Prediction of Human Immunodeficiency Virus (HIV) Resistance Mutation Patterns
We used IRR to explore patterns of HIV RNA mutations that emerge in HIV-infected people after the initiation of antiretroviral drug treatment. These mutations, termed drug-resistant mutations, are preferentially selected because they render the virus resistant to the drugs admitted. In fact, this was the trigger for the development of IRR in the first place.
In most cases, the treatment is targeted to interfere with the activity of specific HIV proteins, such as viral protease, reverse-transcriptase and integrase. The mutations occur in parts of the viral RNA sequences that map into the protein active sites upon translation. These are the sites that are affected by the HIV treatment. Characterization of the associations between resistance mutations and treatment regimens can be beneficial in the selection and optimization of treatment. It can be used to predict the appearance of resistance mutations or to assess the functional behavior of the mutant protein and reveal interactions among the drugs and among different coexisting mutations.
Deforche et al. (2006) have explored the interactions between resistance mutations using BNT modeling. Their data set contained amino acid samples of the protease site from HIV patients and their treatment history (focusing specifically on the protease inhibitor [PI] Nelfinavir [NFV]). First, χ2 test was applied to identify mutations that significantly correlated with the treatment. A new data set was then created, where the presence/absence of a given mutation in each sample was represented by the Boolean value of a variable assigned to this mutation. An additional variable was assigned to the NFV treatment status of this sample.
BNT modeling was used to explore associations between the variables described above. The resultant network recovered some of the known interactions between the NFV-induced mutations. It also pointed to new associations that were later found to be biologically meaningful.
We will briefly describe the application of IRR to the same biological process using our own data.
Data and method
A total of 1745 sample protease sequences were obtained from the depository of the National HIV Reference Laboratory (NHRL): 1261 samples were of individuals infected with subtype-C HIV, of which 170 were treated with NFV, and 454 samples were of subtype-B, of which 29 patients were treated with NFV.
Using IRR, we separately analyzed each subtype's samples, since C and B subtypes display different resistance mutation patterns (Grossman et al., 2004; Kantor et al., 2005; Rhee et al., 2006).
For each of the two subtypes, the amino acid sequences were compared to the subtype consensus sequence (that is, the sequence that is the best representative of the wild-type virus). The subtype consensus sequences were equal in samples from drug-naive HIV carriers and in the general sample population, reflecting the fact that variants constitute a small minority in the sequence population. After the consensus comparison, a mutations variable set was established by including every diversion from consensus that occurred at least twice
For each mutation, a binary variable was created, indicating for each sample whether the mutation appeared in that sample (positive value, set to + 1) or not (−1). Similarly, the condition variable binary value indicates the NFV treatment status for each sample.
A binary frequency matrix of the mutation variables and the condition variable over the sample population was used as input for the IRR algorithm.
The IRR algorithm used a value of 50 as the ridge parameter and p < 0.05 as the χ2 test significance range.
Results
Graphical representations of the HIV mutation data constructed via IRR are displayed in Figure 6a (subtype B analysis) and 6b (subtype C analysis). Associations that showed exceptionally significant χ2 scoring (p < 0.00000) and IRR scoring of >0.01 are marked by red edges.

IRR graphical result of amino acid mutations associations found in subtype B
A detailed comparison with previously established results and a discussion of the potential significance of new, previously unknown associations is in preparation and will be published (Bar-Yaakov et al., 2011). Briefly, out of the 31 mutations in the IRR-generated networks, 13 have been previously identified as resistance mutations. The IRR network contains several directed paths that match known resistance mutation pathways. In addition, the IRR network shared 24 mutations and a number of pathways with the BNT generated through the analysis of Deforche et al. (2006). Importantly, the IRR method revealed novel associations, such as V15I-D30N, that are biologically plausible and that provide new insights into the mechanisms of drug-resistance development.
Our results display some inconsistencies with previous publications. These and implications regarding limitations of the method and possible remedies are discussed in more detail in elsewhere (Bar-Yaakov et al., 2011).
5. Conclusion
This article introduced IRR, a modification of the dependency network method, which produces a directed graph containing only condition-related associations. We have described a robust and computationally efficient estimator algorithm used to uncover such a network.
We showed that the IRR algorithm performs better than the current state-of-the-art BNT when the purpose is to identify conditioned associations.
We also briefly describe, here and in a forthcoming publication, a real-life application of the IRR method to the analysis of HIV mutation patterns that emerge in HIV-infected patients treated with a particular antiretroviral drug. We have demonstrated that our method can recover, from a pool of viral sequences, known associations of such treatment with selected resistance mutations as well as documented associations between different mutations. Moreover, the IRR method revealed novel associations that are statistically significant and biologically plausible.
6. Appendix
For IRR pseudo code and detailed demonstration of the IRR algorithm, please refer to www.cs.tau.il/∼nin.
Analytical proof of the IRR method
Given a random variable set
Let Wj be the resulting weight vector, after the ridge regression of c using S excluding xj:
In the case where
Denote
Hence:
Since:
After decomposing:
Since we have a better regularized estimation for
Therefore, it can use
And this contradicts with the argmin property of Wj. ▪
In the above procedure, we have proved that by simple reduction of Wj from WB we receive the best regularized estimation of the omitted variable by its co-variables.
Exact details of the IRR—BNT simulation
(1) Parameters
(a) Number of features—N
(b) Number of samples—M
(c) Condition ratio out of samples—ratio of samples that are conditioned.
(d) Pattern description
(i) Pattern size—number of features in the pattern.
(ii) Pattern-condition ratio—the ratio of the conditioned samples which contains the pattern.
(e) Background noise level—ratio of random data members which have positive value (before pattern induction).
(f) Sampling noise level—ratio of random data members, which will have their value inverted.
(2) Data creation
(a) Allocate an N by M data matrix (samples).
(b) Allocate an M size vector (condition vector).
(c) Reset the sample matrix and the condition vector values to − 1.
(d) Randomly select cells out of the sample's matrix, until selecting total cells ratio of background noise level. Inverse their value to 1.
(e) Randomly select cells out of the condition vector, until selecting an amount of cells corresponding to the condition ratio multiplied by the samples set size. These are the condition indices, Inverse their value to 1.
(f) Pattern induction
(i) Randomly select total of pattern size indices out of the features indices. These are the pattern indices.
(ii) Randomly select samples, until reaching total of (pattern-condition ratio * size of condition indices), which their corresponding indices in the condition vector are positive. These are the conditioned samples associated with the condition vector.
(iii) Change the values of the conditioned samples in the pattern indices to 1.
(g) Sampling noise induction
(i) Randomly select values until reaching a ratio of sampling noise level out of the samples values, and inverse their values.
(1) IRR execution and scoring
(a) Use the sample matrix and the condition vector as an input to the IRR algorithm.
(b) IRR result is the estimated conditioned pattern; use Jaccard Index to evaluate the similarity between the original induced pattern and the estimated IRR result pattern.
(2) BNT execution and scoring
(a) We used the BNT package (Murphy, 2001) for executing a Bayesian network analysis over the simulated data.
(b) We compared the IRR with the K2 Bayesian network algorithms (Cheng et al., 1997), showed to outperform or match other BNET algorithms (Leray and Francois, 2004)
(c) Input for the BN was created by concatenating the sample matrix and the condition vector—the condition vector becomes another feature in the sample features.
(d) We used the DAG result of the Bayesian Network Power Constructor (BNPC) algorithm (Cooper and Herskovits, 1992), for topological sorting used to deduct the variable order, needed as an input for the K2 algorithm.
(e) The scoring was done by searching the connected component of the DAG result that contains the condition feature.
(f) We assemble a variable set containing the variables in the connected component.
(g) The set is regarded as the result estimated pattern of the algorithm.
(h) We use Jaccard Index to evaluate the similarity between the original induced pattern and the estimated BNT result pattern.
(1) In each comparison iteration, we simulated an input data matrix with parameters values as follows
(a) Number of features—N = 20
(b) Number of samples—M = 1000
(c) Condition ratio out of samples = 0.8
(d) Single pattern induced
(i) Pattern size = 4
(ii) Pattern-condition ratio = 0.2.
(e) Background noise level = 0.2
(f) Sampling noise level = variable across the simulation
(2) We used the simulated data as an input to the IRR, BNPC, and K2 algorithms.
(3) For each set of parameters, we used 100 executions to get an average score on each sampling noise level.
Footnotes
Disclosure Statement
No competing financial interests exist.