An approximate nested tandem repeat (NTR) in a string T is a complex repetitive structure consisting of many approximate copies of two substrings x and X (“motifs”) interspersed with one another. NTRs fall into a class of repetitive structures broadly known as subrepeats. NTRs have been found in real DNA sequences and are expected to be important in evolutionary biology, both in understanding evolution of the ribosomal DNA (where NTRs can occur), and as a potential marker in population genetic and phylogenetic studies. This article describes an alignment algorithm for the verification phase of the software tool NTRFinder developed for database searches for NTRs. When the search algorithm has located a subsequence containing a possible NTR, with motifs X and x, a verification step aligns this subsequence against an exact NTR built from the templates X and x, to determine whether the subsequence contains an approximate NTR and its extent. This article describes an algorithm to solve this alignment problem in O(|T|(|X| + |x|)) space and time. The algorithm is based on Fischetti et al.'s wrap-around dynamic programming.
1. Introduction
An approximate nested tandem repeat (NTR) in a string T is a complex repetitive structure consisting of many approximate copies of two substrings x and X (“motifs”) interspersed with one another. The name derives from the fact that an NTR may be thought of as two tandem repeats nested within one another.
Approximate nested tandem repeats have been found in real DNA sequences, such as that of Colocasia esculenta, the ancient staple food crop taro (Matroud et al., 2011). The intergenic spacer (IGS) region in the taro ribosomal DNA contains an NTR consisting of eleven approximate copies of a 48-bp motif, interspersed within a tandem repeat consisting of 96 approximate copies of an 11-bp motif. The NTR found in taro, used as a genetic marker, offers the potential to elucidate the prehistory of the early agriculture of this ancient food crop, as mutation events appear to be accumulating on a thousand-year time scale. NTRs in general also offer an opportunity to investigate concerted evolution whereby mutations are propagated throughout the many hundreds of copies of the IGS region in the taro genome.
To develop a fuller understanding of the nature of the NTR, we have developed software to find them (Matroud et al., 2011). This comprises two phases. The first phase is the detection phase, where the sequence is scanned to locate candidate NTRs and construct their consensus motifs X and x. The second phase is the verification phase, where a subsequence containing a possible NTR, with motifs X and x, is aligned against all patterns of the form
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland,xspace}\usepackage{amsmath,amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}
{ \bf x}^{s_0}{ \bf X}^{t_0} { \bf x}^{s_1} { \bf X}^{t_1} \cdots
{ \bf x}^{s_k} { \bf X}^{t_k}.
\end{align*}\end{document}
Such an alignment is needed to find the extent and structure of the NTR (i.e., to find the exponents si, ti occurring above) and may also be used to evaluate the fit of the template motifs x and X. We call this problem the motif alignment problem for NTRs, to distinguish it from the mapping problem (variants alignment problem) that arises at later stages of the analysis.
The purpose of this article is to present an algorithm to solve the motif alignment problem for approximate NTRs, given a sequence T, and the motifs x and X identified by our NTR search algorithm NTRFinder (Matroud et al., 2011). Our alignment algorithm runs in O(|T|(|x| + |X|)) space and time, and plays a key rule in the verification phase of NTRFinder. It is based on the wrap-around dynamic programming technique introduced by Fischetti et al. (1993) to solve the corresponding problem for (ordinary) tandem repeats. We show it can be readily adapted for use with more complex repetitive structures built from three or more motifs.
1.1. Related work
String similarity problems arise in many contexts, and as a result, many algorithms exist to address them. Finding the exact similarity between two strings is a fundamental computer science problem, and a number of good solutions have been introduced by several authors (Gusfield, 1997). However, such exact matching algorithms generally are not useful when applied to molecular data, which tend to contain approximate rather than exact matches due to the mutations that have occurred over time.
Many string similarity problems of biological interest can be phrased as alignment problems (for a precise definition of alignment, see Section 2.4). These include the problem of aligning two entire strings A and B (global alignment [Needleman and Wunsch, 1970]); the problem of aligning substrings of the string A against substrings of B (local alignment [Smith and Waterman, 1981]); and the problem of finding all occurrences of string B within string A (Navarro, 1999). Such alignment problems are commonly solved using the technique of dynamic programming.
Of greatest interest to us is the problem of finding the substring of T that best matches a substring of xs for some s > 1 (tandem repeat alignment). To solve this problem efficiently, Fischetti et al. (1993) introduced wrap-around dynamic programming which has O(|T||x|) space and time complexity. This article solves the motif alignment problem by extending Fischetti et al.'s algorithm to handle more than one repeated motif.
2. Definitions
2.1. Alphabets and strings
An alphabet is a nonempty set Σ of symbols or characters, and a string over Σ is a finite sequence of elements of Σ. We write Σ* for the set of all strings over the alphabet Σ, and |S| for the length of the string S.
Given a string S and integers i, j such that 0 < i ≤ j ≤ |S|, we will write S[i] for the ith character of S, and S[i, j] for the substring consisting of the ith to jth characters of S. Given a second string T, the concatenation of S and T is the string ST, where
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland,xspace}\usepackage{amsmath,amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}
( { \bf ST} ) [ i ] = \begin{cases}{ \bf S} [ i ] \qquad \qquad {
\rm if} \ i \leq \mid { \bf S} \mid , \\ { \bf T} [i - \mid { \bf
S} \mid] \ \quad \ { \rm if} \ i > \mid { \bf S} \mid .\end{cases}
\end{align*}\end{document}
In applications to DNA sequences, Σ is typically the set {A, G, C, T}, and we will use this alphabet in examples. However, our algorithm is not restricted to this case.
2.2. The edit distance
In order to compare two strings X and Y, it is useful to have some measure of the extent to which they differ. For the purposes of this article, we will use the edit distance, where the edit operations we permit are the insertion of a single character; the substitution of a single character; or the deletion of a single character.
Given a set of allowed edit operations, such as those listed above, the edit distance from X to Y, d(X, Y), is the minimum number of allowable edit operations needed to transform X into Y. With the choice of permitted edit operations made above we note that d is a metric.
2.3. Tandem repeats and nested tandem repeats
An exact tandem repeat is a string of the form Xl for some l ≥ 2. Thus, an exact tandem repeat is a string comprised of two or more contiguous exact copies of the same substring X. This substring is called the motif of the tandem repeat. We obtain an approximate tandem repeat by allowing approximate rather than exact copies of the template motif X. More precisely, an approximate tandem repeat is a string of the form \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bf X}_1 { \bf X}_2 \cdots { \bf X}_l$$\end{document}, where d(X, Xi) ≤ k|X| for each i, for some fixed k < 1 and template motif X. Where the value of the parameter k is important we may say that we have a k-approximate tandem repeat (k-TR). For simplicity of notation, we will write \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \tilde{ \bf X}}^l$$\end{document} to mean an approximate tandem repeat, consisting of l approximate copies of X.
Given two motifs X and x such that \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$d ( { \bf X} , { \bf x} ) \gg 0$$\end{document}, an exact nested tandem repeat is a string of the form
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland,xspace}\usepackage{amsmath,amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}
{ \bf x}^{s_0}{ \bf X}^{t_0}{ \bf x}^{s_1}{ \bf X}^{t_1} \cdots {
\bf x}^{s_n}{ \bf X}^{t_n} ,
\end{align*}\end{document}
where n > 1, si ≥ 1 for each i > 0, and ti ≥ 1 for each i < n. We again obtain an approximate nested tandem repeat by allowing the copies of the motifs X and x to be approximate rather than exact. Thus, an approximate nested tandem repeat is a string of the form
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland,xspace}\usepackage{amsmath,amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}
{ \tilde{ \bf x}}^{s_0} { \tilde{ \bf X}}^{t_0} { \tilde{ \bf
x}}^{s_1} { \tilde{ \bf X}}^{t_1} \cdots { \tilde{ \bf x}}^{s_n} {
\tilde{ \bf X}}^{t_n} ,
\end{align*}\end{document}
where n > 1, si ≥ 1 for each i > 0, and ti ≥ 1 for each i < n, and such that \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \tilde{ \bf x}}^{s_0} { \tilde{ \bf x}}^{s_1} \cdots { \tilde{ \bf x}}^{s_n}$$\end{document} is an approximate tandem repeat with motif x, and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \tilde{ \bf X}}^{t_0} { \tilde{ \bf X}}^{t_1} \cdots { \tilde{ \bf X}}^{t_n}$$\end{document} is an approximate tandem repeat with motif X.
Note that the definition of an approximate nested tandem repeat includes exact nested tandem repeats as a special case. “Nested tandem repeat” (NTR) by itself will always mean an approximate nested tandem repeat, unless explicitly stated otherwise.
Remark
The definition of an NTR given here is slightly more general than that given in Matroud et al. (2011). In that paper, a nested tandem repeat is required to satisfy ti ≤ 1 for each i.
2.4. Alignment
Given an alphabet Σ, let \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bar{ \Sigma}}$$\end{document} be the alphabet Σ ∪ {−}, where “−” (“gap”) is a character that does not belong to Σ. We define \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$\phi:{ \bar{ \Sigma}}^* \rightarrow \Sigma^*$$\end{document} to be the function that deletes all gaps.
Given two strings \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bf A} , { \bf B} \in { \Sigma}^*$$\end{document}, an alignment of A and B is a choice of a pair of strings \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$( { \bar{ \bf A}} , { \bar{ \bf B}} ) \in { \bar{ \Sigma}}^* \times{ \bar{ \Sigma}}^*$$\end{document} satisfying the following conditions:
A3. there is no index i for which \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bar{ \bf A}} [ i ] = { \bar{ \bf B}} [ i ] = -$$\end{document}.
Thus, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bar{ \bf A}}$$\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bar{ \bf B}}$$\end{document} are obtained from A and B, respectively, by inserting gaps in such a way that the resulting strings have the same length, and do not both have a gap in the same position.
To score an alignment we use a scoring matrix σ, which specifies the reward or penalty for aligning any two characters of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bar \Sigma}$$\end{document} against each other (Table 1). We will assume throughout that σ penalizes gaps (that is, σ(−, α) and σ(α,−) are both negative for all \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$\alpha \in { \bar \Sigma}$$\end{document}), and we set σ(−,−) = −∞ to reflect condition A3 above. Given an alignment \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$( { \bar{ \bf A}} , { \bar{ \bf B}} )$$\end{document} for which \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$\mid { \bar{ \bf A}} \mid = \mid { \bar{ \bf B}} \mid = L$$\end{document}, the alignment score of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$( { \bar{ \bf A}} , { \bar{ \bf B}} )$$\end{document} is then defined to be
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland,xspace}\usepackage{amsmath,amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}
\sigma ( { \bar{ \bf A}} , { \bar{ \bf B}} ) = \sum_{i = 1}^{L}
\sigma ( { \bar{ \bf A}} [ i ] , { \bar{ \bf B}} [ i ] ) .
\end{align*}\end{document}
A Sample Scoring Matrix for DNA Sequences
σ
−
A
C
G
T
−
−∞
−2
−2
−2
−2
A
−2
1
−1
−1
−1
C
−2
−1
1
−1
−1
G
−2
−1
−1
1
−1
T
−2
−1
−1
−1
1
This matrix rewards matching characters from Σ with a score of +1, and penalises mis-matching characters from Σ with a score of −1. The penalty for aligning a gap against a character from Σ is −2. The value σ(−,−) = −∞ reflects condition A3, which prohibits a gap being aligned against a gap.
An optimal global alignment is an alignment of A and B, which maximizes the alignment score over all such alignments. For a survey of this and other alignment problems, see Navarro (1999).
3. The Motif Alignment Problem for Approximate Nested Tandem Repeats
3.1. The problem
The motif alignment problem for approximate nested tandem repeats is the following:
Given
(1) a string T and motifs x and X over the alphabet Σ, and
(2) a scoring matrix σ defined over \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bar{ \Sigma}} \times { \bar{ \Sigma}}$$\end{document},
find an optimal alignment of T against substrings of strings of the form
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland,xspace}\usepackage{amsmath,amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}
{ \bf x}^{s_0}{ \bf X}^{t_0}{ \bf x}^{s_1}{ \bf X}^{t_1} \cdots {
\bf x}^{s_k}{ \bf X}^{t_k}.
\end{align*}\end{document}
Thus, given a string T that is presumed to contain an approximate nested tandem repeat with motifs x and X, and a scoring matrix σ, the problem is to find a optimal alignment of T against substrings of exact nested tandem repeats with motifs x and X.
3.2. Solution to the problem via nested wrap-around dynamic programming
The motif alignment problem for NTRs is closely related to the corresponding problem for tandem repeats, which was solved by Fischetti et al. (1993) using wrap-around dynamic programming. We solve the problem by adapting their technique. The key differences are the introduction of a second matrix, to hold information relating to the second motif, and a modification to the update rule used between the first and second passes.
In what follows, we let n = |T|, m = |x|, and l = |X|. An optimal alignment will be calculated using two matrices D(1) and D(2). The matrix D(1) is (m + 1) × (n + 1), and will record scores related to aligning portions of T against x, while the matrix D(2) is (l + 1) × (n + 1), and will record scores related to aligning portions of T against X. Both matrices will be indexed starting from 0, and we will denote the (i, j) entry of D(k) by D(k)[i, j]. We write D(k)i, j for the upper-left (i + 1) × (j + 1) submatrix of D(k).
The score matrices D(1) and D(2) are filled as follows:
(1) We initialize the two matrices by setting
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland,xspace}\usepackage{amsmath,amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}
D^{ ( k ) } [ 0 , j ] : = 0 , \qquad D^{ ( k ) } [ i , 0 ] : = 0
\end{align*}\end{document}
for all i, j and k.
(2) We compute each column of the matrices (starting from j = 1) in two rounds. In the first round, we compute D(1)[i, j] using the recursive function
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland,xspace}\usepackage{amsmath,amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}
D^{ ( 1 ) } [ i , j ] : = \max \left\{ \begin{matrix}D^{ ( 1 ) }
[ i - 1 , j - 1 ] + \sigma ( { \bf x} [ i ] , { \bf T} [ j ] ) ,
\\ D^{ ( 1 ) } [ i - 1 , j ] + \sigma ( { \bf x} [ i ] , - ) , \\
D^{ ( 1 ) } [ i , j - 1 ] + \sigma ( - , { \bf T} [ j ] )
\end{matrix} \right\} .
\end{align*}\end{document}
We then compute D(2)[i, j] in a similar fashion.
In the second round, we update both D(1)[0, j] and D(2)[0, j] with the value max{D(1)[m, j], D(2)[l, j]}, and then update D(1)[i, j] for 1 ≤ i ≤ m using the formula above, which simplifies to
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland,xspace}\usepackage{amsmath,amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}
D^{ ( 1 ) } [ i , j ] : = \max \left\{ D^{ ( 1 ) } [ i , j ] , D^{
( 1 ) } [ i - 1 , j ] + \sigma ( { \bf x} [ i ] , - ) \right\}
\end{align*}\end{document}
during the second round. The entries D(2)[i, j] for 1 ≤ i ≤ l are then updated in a similar fashion.
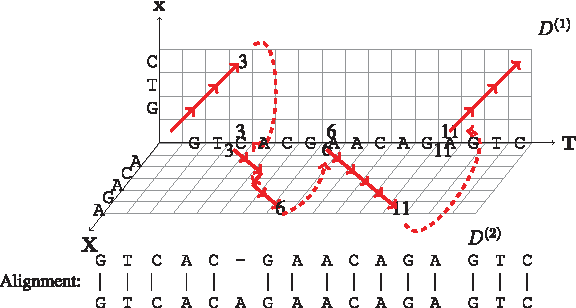
The visualization of the algorithm is shown in Figure 1. Pseudo-code for the matrix-filling algorithm appears below:
Visualization of the algorithm applied to the string T = GTCACGAACAGAGTC, with template motifs x = GTC, X = ACAGA. The matrix D(1) lies in the (x, T) plane, while D(2) lies in the (X, T) plane. The majority of the matrix entries have been omitted for clarity. Solid arrows represent the optimal alignment path, whereas dashed arrows indicate that the value at its tail is fed to the location at its head. The corresponding alignment appears below the diagram.
Once the matrices are filled, an optimal alignment is found using the standard trace-back procedure for dynamic programming (Fischetti et al., 1993), beginning from the largest entry in the right-hand columns of D(1), D(2). The algorithm clearly has space complexity O(n(m + l)), and the matrices D(1) and D(2) are filled in time O(n(m + l)).
3.3. Correctness of the algorithm
We now prove by induction that the matrices D(1) and D(2) have been calculated correctly to produce the optimal alignment. In what follows, let NTR(x, X) denote the set of all strings N that occur as substrings of exact NTRs with motifs x and X.
Suppose that the two sub-matrices \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$D_{m , j - 1}^{ ( 1 ) }$$\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$D_{l , j - 1}^{ ( 2 ) }$$\end{document} have been correctly computed for some j ≥ 1. That is, assume that D(1)[i, j − 1] is the optimal alignment score of any alignment of T[1, j − 1] against a string \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bf N} \in NTR ( { \bf x} , { \bf X} )$$\end{document} that ends with a suffix of x[1, i], and similarly that D(2)[i, j − 1] is the optimal alignment score of any alignment of T[1, j − 1] against a string \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bf N} \in NTR ( { \bf x} , { \bf X} )$$\end{document} that ends with a suffix of X[1, i]. When i = 0 our assumption is that
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland,xspace}\usepackage{amsmath,amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}
D^{ ( 1 ) } [ 0 , j - 1 ] = D^{ ( 2 ) } [ 0 , j - 1 ] = \max \{
D^{ ( 1 ) } [ m , j - 1 ] , D^{ ( 2 ) } [ l , j - 1 ] \} ,
\end{align*}\end{document}
so that this common value is the optimal score of an alignment of T[1, j − 1] against a string \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bf N} \in NTR ( { \bf x} , { \bf X} )$$\end{document} ending in either x[m] or X[l].
Consider an alignment \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$( { \bar{ \bf N}} , { \bar{ \bf S}} )$$\end{document} of S = T[1, j] against a string \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bf N} \in NTR ( { \bf x} , { \bf X} )$$\end{document} ending in x[1, i] or X[1, i]. We consider three cases, according to the final characters of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bar{ \bf S}}$$\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bar{ \bf N}}$$\end{document}:
(1) If \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bar{ \bf S}}$$\end{document} ends in T[j] and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bar{ \bf N}}$$\end{document} in x[i], then deleting these characters gives an alignment of T[1, j − 1] against a string \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bf N}^{ \prime} \in NTR ( { \bf x} , { \bf X} )$$\end{document} ending in x[i − 1] if i > 1, or in either x[m] or X[l] if i = 1. It follows that
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland,xspace}\usepackage{amsmath,amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}
\sigma \left( { \bar{ \bf N}} , { \bar{ \bf S}} \right) \leq D^{ (
1 ) } [ i - 1 , j - 1 ] + \sigma ( { \bf x} [ i ] , { \bf T} [ j ]
) ,
\end{align*}\end{document}
with equality when \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bar{ \bf N}}$$\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bar{ \bf S}}$$\end{document} are obtained by appending x[i] and T[j] to an optimal alignment at D(1)[i − 1, j − 1]. A similar argument applies if \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bar{ \bf N}}$$\end{document} ends in X[i].
(2) If \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bar{ \bf S}}$$\end{document} ends in T[j] and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bar{ \bf N}}$$\end{document} in a gap, then deleting these characters gives an alignment of T[1, j − 1] against N. If N ends in x[i] then
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland,xspace}\usepackage{amsmath,amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}
\sigma ( { \bar{ \bf N}} , { \bar{ \bf S}} ) \leq D^{ ( 1 ) } [ i
, j - 1 ] + \sigma ( - , { \bf T} [ j ] ) ,
\end{align*}\end{document}
with equality when \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bar{ \bf N}}$$\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bar{ \bf S}}$$\end{document} are obtained by appending “−” and T[j] to an optimal alignment at D(1)[i, j − 1]. A similar argument applies if N ends in X[i].
(3) If \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bar{ \bf S}}$$\end{document} ends in a gap then we may express \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bar{ \bf S}}$$\end{document} in the form
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland,xspace}\usepackage{amsmath,amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}
{ \bar{ \bf S}} = { \bar{ \bf S}}^{ \prime} ( - ) ^s ,
\end{align*}\end{document}
where s ≥ 1 is as large as possible. Let \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${ \bar{ \bf N}} = { \bar{ \bf N}^{ \prime}} {\bf M}$$\end{document} with |M| = s. Then \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$( { \bar{ \bf N}}^{ \prime} , { \bar{ \bf S}}^{ \prime} )$$\end{document} is an alignment of one the types considered in cases 1 and 2 above, so
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland,xspace}\usepackage{amsmath,amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}
\sigma ( { \bar{ \bf N}} , { \bar{ \bf S}} ) & = \sigma ( { \bar{
\bf N}}^{ \prime} , { \bar{ \bf S}}^{ \prime} ) + \sigma ( { \bf
M} , ( - ) ^s ) \\ & \leq D^{ ( k^{ \prime} ) } [ i^{ \prime} , j
] + \sigma ( { \bf M} , ( - ) ^s )
\end{align*}\end{document}
for integers i′ ≤ 1 and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$k^{ \prime} \in \{ 1 , 2 \} $$\end{document} determined by the tail of N′.
For conciseness, let Y1 = x and Y2 = X. Then the string M is an element of NTR(x, X) of length s ending with Yk[i] and beginning with
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland,xspace}\usepackage{amsmath,amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}
{ \bf M} [ 1 ] = \begin{cases}{ \bf Y}_{k^{ \prime}} [ i^{ \prime}
+ 1 ] \qquad { \rm if} \ i^{ \prime} < \mid { \bf Y}_{k^{ \prime}}
\mid , \\ { \bf x} [ 1 ] \ { \rm or} \ { \bf X} [ 1 ] \quad \ {
\rm if} \ i^{ \prime} = \mid { \bf Y}_{k^{ \prime}} \mid
.\end{cases}
\end{align*}\end{document}
So what we must show is that for such strings we have
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland,xspace}\usepackage{amsmath,amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}
D^{ ( k ) } [ i , j ] \geq D^{ ( k^{ \prime} ) } [ i^{ \prime} , j
] + \sum_{a = 1}^s \sigma ( { \bf M} [ a ] , - ) .
\end{align*}\end{document}
By the update rules we have
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland,xspace}\usepackage{amsmath,amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}
D^{ ( k^{ \prime \prime} ) } [ a , j ] \geq D^{ ( k^{ \prime
\prime} ) } [ a - 1 , j ] + \sigma ( { \bf Y}_{k^{ \prime \prime}}
[ a ] , - )
\end{align*}\end{document}
for k″ = 1, 2 and a ≥ 1, so the necessary inequality will be true by induction provided we can show that we still have
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland,xspace}\usepackage{amsmath,amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{equation*}
D^{ ( k^{ \prime \prime} ) } [ 0 , j ] = \max \{ D^{ ( 1 ) } [ m ,
j ] , D^{ ( 2 ) } [ l , j ] \} \leqno ( 1 )
\end{equation*}\end{document}
after the second update round. This equality follows from the fact that the larger of D(1)[m, j], D(2)[l, j] is unchanged during the second round. Indeed, if the value D(1)[m, j] is changed during the second round then it must have been increased to
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland,xspace}\usepackage{amsmath,amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}
D^{ ( 1 ) } [ m , j ] = D^{ ( 1 ) } [ 0 , j ] + \sum_{b = 1}^m
\sigma ( { \bf x} [ b ] , - ) ,
\end{align*}\end{document}
and this is strictly less than D(1)[0, j], because σ(α,−) < 0 for all α. A similar argument applies to D(2)[l, j], so the larger of these is unchanged and remains the maximum.
By the above, we have \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$\sigma ( { \bar{ \bf N}} , { \bar{ \bf S}} ) \leq D^{ ( k ) } [ i , j ]$$\end{document}. It remains to show that there is in fact an alignment with score D(k)[i, j] when D(k)[i, j] = D(k)[i − 1, j] + σ(Yk[i],−). Consider the trace back procedure beginning from D(k)[i − 1, j]. This must eventually reach an (i′, j)-entry of either D(1) or D(2) that derives from column j − 1 (since for example the largest entry in each column of each matrix must be derived this way), and we obtain the desired alignment by appending suitable strings to an optimal alignment at this point.
Cases 1–3 above show that D(1)[i, j] and D(2)[i, j] have been correctly computed for i ≥ 1, and equation (1) shows that D(1)[0, j] and D(2)[0, j] have been too. It follows by induction that both matrices D(1) and D(2) have been correctly computed.
3.4. Extension to nested tandem repeats with three or more motifs
Our algorithm is easily adapted to the motif alignment problem for more complex NTRs built from three or more motifs \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$\bf{X}_1 , \bf{X}_2 , \cdots , \bf{X}_r$$\end{document}. For each \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$k = 1 , \ldots , r$$\end{document} we introduce an |Xk| × |T| matrix D(k),where |T| is the text containing the NTR, and we initialise these as in Section 3.2. After the jth column of each matrix has been filled as in the first round above we update D(k)[0, j] with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$\max \{ D^{ ( i ) } [ \mid \bf{X}_{i} \mid , j ] \mid i = 1 , \ldots , r \} $$\end{document} for each k, and then run a second round as above to update the jth column of each matrix. Once the matrices have been filled, an optimal alignment may then be found using the standard trace-back procedure. The time and space complexity for the r-motif alignment algorithm is \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$O ( \mid \bf{T} \mid ( \mid \bf{X}_{1} \mid + \mid \bf{X}_{2} \mid + \cdots + \mid \bf{X}_{r} \mid )$$\end{document} as it takes O(Xk) time and space to fill each matrix D(k). In the case where the motifs have the same length |X|, then the complexity would be O(|T|(k|X|)).
4. Conclusion
In this article, we presented an algorithm to solve the problem of the alignment of nested tandem repeats. This algorithm has O(|T|(|x| + |X|)) time complexity. The nested WDP alignment is incorporated in the program NTRFinder (Matroud et al., 2011), which we are developing as part of the verification phase. It has been tested on both simulated and real data, and has proved to be effective.
Footnotes
Disclosure Statement
No competing financial interests exist.
References
1.
FischettiV.A., LandauG.M., SellersP.H.et al.1993. Identifying periodic occurrences of a template with applications to protein structure. Inform. Process. Lett., 45:11–18.
2.
GusfieldD.1997. Algorithms on Strings, Trees, and Sequences: Computer Science and Computational Biology. Cambridge University Press: New York.
3.
MatroudA.A., HendyM.D., TuffleyC.P.2011. NTRFinder: an algorithm to find nested tandem repeatsarXiv:1006.1730v2.
4.
NavarroG.1999. A guided tour to approximate string matching. ACM Comput. Surv., 33:2001.
5.
NeedlemanS.B., WunschC.D.1970. A general method applicable to the search for similarities in the amino acid sequence of two proteins. J. Mol. Biol., 48:443–453.
6.
SmithT.F., WatermanM.S.1981. Identification of common molecular subsequences. J. Mol. Biol., 147:195–197.