
Abstract
Abstract
1. Introduction
Among its many applications, the C1P has been widely used in molecular biology, in relation to physical mapping (Alizadeh et al., 1995; Atkins and Middendorf, 1996) and the reconstruction of ancestral genomes (Ma et al., 2006; Chauve and Tannier, 2008). In the reconstruction of ancestral genomes in particular, we are given a set of extant species and a phylogenetic tree on this set, and the goal is to infer possible genomes (or gene orders) of an ancestor at some internal node higher up in this phylogenetic tree. This problem is modeled, for example in Chauve and Tannier (2008), by a binary matrix M as follows. Each column of M represents a gene or (homologous) genomic marker (from the collection of genomic markers common to the set of extant descendant species), while each row of the matrix represents a subset of markers that is believed to be contiguous (this subset appears contiguous in at least two extant species, for example), called a synteny, in this ancestor. Any consecutive-ones order of M corresponds then to a potential genome (or gene order) of this ancestor. A common problem in such applications, however, is that matrices obtained from experiments do not have the C1P, often due to small errors in the data (Goldberg et al., 1995; Weis and Reischuk, 2000; Lu and Hsu, 2003; Chauve and Tannier, 2008). It is the lack of robustness of the C1P to small perturbations that led researchers to consider the following approaches for handling matrices that do not have the C1P.
A first general approach for handling a matrix M that does not have the C1P consists of transforming M into a matrix that has the C1P, while minimizing the modifications to M; such modifications can involve either removing rows, or columns, or both, or flipping some entries from 0 to 1 or 1 to 0. In all cases, the corresponding optimization problems have been proven to be NP-complete (Hajiaghayi and Ganjali, 2002; Dom et al., 2007; Dom, 2008).
A second general approach is to allow the columns of M to appear more than once in a consecutive-ones order of M. Such an approach was first introduced by Wittler and Stoye (2010), where the authors defined the following problem: given binary matrix M on columns
Here we propose several versions of a third approach to this problem, motivated by several scenarios within the reconstruction of ancestral genomes setting; however, similar motivations could be found in other applications; see Goldberg et al. (1995) for one example. The third general approach consists of relaxing the consecutivity condition of the 1's in each row by allowing gaps with some restriction on the nature of these gaps. The question is then to decide if there is an ordering of the columns of M that satisfies these relaxed C1P conditions. Goldberg et al. (1995) introduced the notion of the k-Consecutive-Ones Property (k-C1P). A binary matrix M has the k-C1P when its set of columns can be permuted such that each row contains at most k blocks. This version of the problem does not put any restriction on the size of the gaps between blocks. This version of the problem pertains to the reconstruction of ancestral genomes in that an observed synteny can consist of two or more syntenies if they were made contiguous by independent rearrangements in two (or more) species, which is referred to as a chimerism. This might happen especially in genomes such as yeasts where we generally see many translocations (Jinks-Robertson and Petes, 1986; Richardson and Jasin, 2000). Goldberg et al. (1995) show that deciding if a binary matrix M has the k-C1P is NP-complete, even if k = 2. Also, finding an ordering of the columns that minimizes the number of gaps in M is NP-complete, even if each row of M has at most two 1's (Haddadi, 2002).
Chauve et al. (2009b) then defined the Gapped C1P Problem, or the (k, δ)-C1P Problem: given binary matrix M and two integers k and δ, to decide if the columns of M can be ordered such that each row contains at most k blocks, and no two neighboring blocks of 1's are separated by a gap of size more than δ. This version of the problem is motivated by a different scenario. Even though a group of genomic markers is expected to appear together in the ancestral genome, over evolution, insertion among this group of several markers from outside this group could happen, resulting in a small gap. Another reason for considering small gaps is to handle errors in defining (homologous) genomic markers (paralogies inferred instead of orthologies in constructing this set of markers), errors from convergent evolution, etc., when these errors tend to be small. Finally, we note that, in the model of max-gap clusters (Pasek et al., 2005), another form of generalization of common intervals (i.e., the C1P), gaps, are of bounded size. So if ancestral syntenies are detected or inferred under this model, then the resulting matrix should have the (k, δ)-C1P for bounded δ. In Maňuch et al. (2011), it was shown that for every k ≥ 2, δ ≥ 1, (k, δ) ≠ (2, 1), the (k, δ)-C1P Problem is NP-complete, leaving open only the complexity of the (2, 1)-C1P case. The problem remains NP-complete even if one of the two parameters is unbounded: (i) for every k ≥ 2, the (k, ∞)-C1P Problem is just the problem of deciding if a matrix M has the k-C1P, and is thus NP-complete by Goldberg et al. (1995), and (ii) for every δ ≥ 1, the (∞, δ)-C1P Problem is NP-complete (Maňuch et al., 2011).
The above NP-completeness results on the (k, δ)-C1P Problem involve constructions with many rows of high degree. After examining some data from experiments, we found that this is not always realistic. We considered here the ancestral syntenies dataset for the boreoeutherian ancestor of Chauve and Tannier (2008) at a resolution of 200 kb, with 1651 markers (i.e., columns) and 2515 syntenies (rows).1 In this dataset, we observed that 90% of the syntenies have low degree (less than or equal to 16, which is less than 1% of the number of columns of this matrix). Each of the remaining 10% of the syntenies (with degrees 17–99) contains between 16–144 syntenies with low degree. This is in agreement with the theoretical observations of Bouvel et al. (2009), where it was shown that the rows/syntenies with high degree with high probability contain some rows/syntenies with low degree. Hence, if the syntenies with high degree (10%) are discarded, the majority of the information is preserved, and so it makes sense to consider versions of the problem where the degree is bounded, especially, if this could help to turn an NP-complete problem to polynomial.
Formally, we have the (d, k, δ)-C1P Problem: given matrix M where the bound on the maximum degree of any row of M is d, decide if it has the (k, δ)-C1P. We call a permutation π of the columns of M that witnesses this property a (d, k, δ)-consecutive order; that the matrix M′ resulting from this permutation is (d, k, δ)-consecutive, or that it is consecutive w.r.t. π; and that M is (d, k, δ)-C1P, or has the (d, k, δ)-C1P. If all three parameters are fixed, the problem is related to the classical Graph Bandwidth Problem, and can be solved in polynomial time using a variant of an algorithm of Saxe (Saxe, 1980; Chauve et al., 2009b). However, this is practical only for very small values of the three parameters.
In this article, we study the complexity of the (d, k, δ)-C1P Problem when one or more of these parameters are unbounded. The cases with d unbounded were considered in Maňuch et al. (2011). Since fixing d also fixes k (k ≤ d), the only case left to consider is the case when δ is unbounded, or the (d, k, ∞)-C1P Problem. This case deals with the problem of chimerisms and assumes that we do not lose too much information by considering only syntenies with low degree as argued above. Here we show that in every non-trivial case, this problem is NP-complete, i.e., for every d > k ≥ 2, the (d, k, ∞)-C1P Problem is NP-complete. Note that if d = 2, the problem becomes the C1P Problem, and if d ≤ k, then any order of the columns of M is a valid solution, since no row can have more than d blocks of 1's.
This article is structured as follows. First, in Section 2, we give the definition of a type of hypergraph covering problem. In Section 3, we show that a special case of this hypergraph covering problem is NP-complete, and then in Section 4, we generalize this construction to show that the general case of this hypergraph covering problem is NP-complete. Finally, in Section 5, we show a direct correspondence of the general case of this hypergraph covering problem to the (d, k, ∞)-C1P Problem for every d > k ≥ 2 to give the result of this work. In Section 6, we conclude the article with some remarks and discuss future work.
2. A Hypergraph Covering Problem
We first define the following hypergraph covering problem. In the sections that follow, we will show that this problem is NP-complete, and that it corresponds exactly to the (d, k, ∞)-C1P Problem for the result of this article. Note that a hypergraph H = (V, E) is d-uniform when all its hyperedges are d-edges, that is, hyperedges that contain exactly d vertices.
Definition 1 (p-Covering of a d-Uniform Hypergraph)
Given a d-uniform hypergraph H = (V, E) and an integer p, let K|V| be a complete graph on V and let • for every •
Here, we say that set
Informally, a p-covering of a d-uniform hypergraph is a graph constructed by picking p edges from each hyperedge.
Problem 1 (d-Uniform Hypergraph p-Covering by Paths Problem [d-UH-p-CP Problem])
Given a d-uniform hypergraph H = (V, E) and an integer p < d, is there a p-covering of H which consists only of disjoint paths?
Variations of this problem were defined in Gupta et al. (2007, 2008, 2009). The first variation allowed the hypergraph to have only 2-, 3-, and 4-edges, where 2- and 3-edges were covered by picking one edge, while 4-edges were covered by two parallel edges, and required that the covering contains only disjoint edges and vertices. This variation was shown to be polynomial-time solvable which provided an algorithm for a special version of haplotyping problem via galled-tree networks (Gupta et al., 2007). The second variation allowed only 3-uniform hypergraphs, and required all connected components of the covering to be paths of length at most 3. This variation was shown to be NP-complete (Gupta et al., 2009). A slightly more complex version of this was then used to show that, in general, the haplotyping problem via galled-tree networks is NP-complete (Gupta et al., 2008).
In the next section, we show that the special case, namely the 3-UH-1-CP Problem is NP-complete, which is then generalized in Section 4 to show NP-completeness of the d-UH-p-CP Problem for every d − 2 ≥ p ≥ 1.
3. The 3-Uniform Hypergraph 1-Covering by Paths Problem
We now show that the 3-Uniform Hypergraph 1-Covering by Paths (3-UH-1-CP) Problem is NP-complete.
Theorem 1
The 3-UH-1-CP Problem is NP-complete.
Proof
Clearly, the problem is in NP. We will show it is also NP-hard by reduction from 3SAT(3), a restricted version of 3SAT, proved NP-complete by Papadimitriou (1994), in which every variable has exactly two positive and one negative occurrence in the clauses.2 We will call a p-covering of a hypergraph valid if it consists only of disjoint paths. Note that a valid p-covering does not contain vertices of degree 3 or more and does not contain cycles. Given 3SAT(3) formula φ with variables
First we give an important building block that is used throughout this construction: the complete 3-uniform hypergraph D on 4 vertices. In any valid 1-covering of D, there is no isolated vertex. Indeed, assume for contradiction that v is the isolated vertex in a valid covering G of D. Let u1, u2, u3 be the remaining three vertices. Then there is a pair ui, uj such that {ui, uj} is not an edge in G. However, no edge is 1-covering hyperedge {v, ui, uj}, a contradiction. We will use several copies of D in the construction to introduce a dependency on 1-coverings of touching hyperedges and depict them as diamonds in the figures. For instance, consider the hypergraph in Figure 1a. Since in any valid 1-covering G of this hypergraph, v is a member of an edge in D, at most one of the hyperedges h1 and h2 can “pick” an edge involving v, otherwise vertex v would have degree 3 or more.
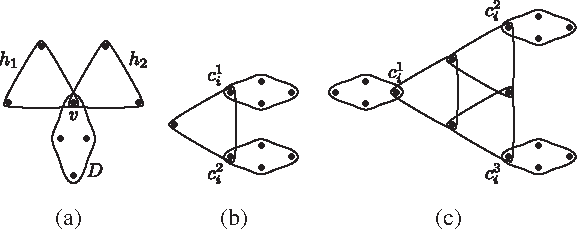
Now to the main construction. Consider the instance φ of 3SAT(3) with variables (1) every clause selects at least one literal, and (2) for every
then this selection can be used to build a satisfying truth assignment for φ as follows: for every
Figure 1b,c depicts the 2-clause and 3-clause gadgets, respectively. Given a valid 1-covering G of the clause gadget for clause ci with literals
Figure 2a depicts the variable gadget for variable
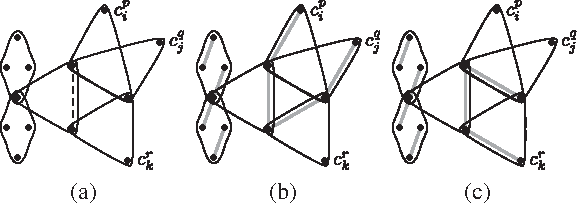
Conversely, if φ has a satisfying assignment τ, let us pick one literal for each clause which makes it satisfied in τ and build the 1-covering of Hφ as follows. In each clause gadget: (i) in each hyperedge of this clause gadget that contains a literal vertex, pick an edge containing the literal vertex if this literal was selected for this corresponding clause; and (ii) for each diamond, choose any of the 3 valid 1-coverings of this diamond that consist of 2 parallel edges. In the variable gadgets, pick the edges as depicted in Figure 2b if the variable has value false in τ, and otherwise, pick the edges as depicted in Figure 2c. By selecting edges in this fashion, every hyperedge of Hφ is 1-covered by an edge, and each literal vertex is adjacent to at most two edges in the 1-covering, one of them lying in the diamond. Hence, there is no vertex of degree 3 and no cycles in this 1-covering, i.e., this 1-covering is valid.
Since the number of hyperedges used in the construction is at most 15m + 12n, i.e., linear in the size of φ, this construction can be built in polynomial-time, and hence, the 3-UH-1-CP Problem is NP-hard. ■
In the following section, we generalize this construction to show that, for every d − 2 ≥ p ≥ 1, the d-UH-p-CP Problem is NP-complete.
4. The d-Uniform Hypergraph p-Covering by Paths Problem
We now show how the construction of Section 3 can be generalized to show that for every d − 2 ≥ p ≥ 1, the d-Uniform Hypergraph p-Covering by Paths (d-UH-p-CP) Problem is NP-complete. The main building block in this new construction is the following d-uniform hypergraph that generalizes the hypergraph D (the diamond) from the previous construction of Section 3.
Lemma 1
For any d − 2 ≥ p ≥ 1, there exists a d-uniform hypergraph Dd,p = (V, E) with a distinguished vertex 1. |V| = 2d − p − 1 and 2. in any valid p-covering of Dd,p, v is not isolated; and 3. hypergraph Dd,p has a valid p-covering in which v has degree 1.
Proof
Let Dd,p = (V, E) be the d-uniform hypergraph on the vertex set V = S ∪ P ∪ {v} where |S| = 2(d − p) − 1, |P| = p − 1, and v is the single distinguished vertex. For every subset S′ ⊆ S of size d − p, we add a hyperedge on the d vertices S′ ∪ P ∪ {v} to E, i.e.,
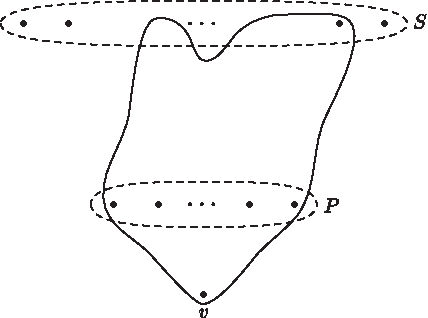
Hypergraph Dd,p: only one of the
Assume, for contradiction, that v is isolated in a valid p-covering G of Dd,p. Since G is some collection of paths on the vertex set S ∪ P, virtual edges can always be added to G to extend this collection to a single path G′ on this set. In what follows, we will find a hyperedge in Dd,p and show that it contains less than p edges in G′, and hence, less than p edges in G, and thus, is not covered by G.
Path G′ defines a total order on its vertex set S ∪ P (there are two such total orders, but we can choose either one, without loss of generality). Let
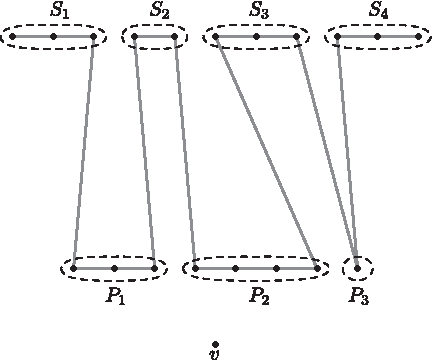
The path G′ through vertex set S ∪ P that alternates between subpaths completely in S and completely in P. Some of the shown edges may be virtual.
Let us order the elements of S according to total order t and let S′ be the odd numbered elements of S according to this order. Since |S| = 2(d − p) − 1, |S′| = d − p. Now, consider the d-edge h = S′ ∪ P ∪ {v} of Dd,p. Hyperedge h is indeed an edge in Dd,p since it contains P ∪ {v} and a subset, namely S′, of size d − p of S. Hyperedge h for the example of Figure 4 is depicted in Figure 5. We will show that this hyperedge contains less than p edges from G′.
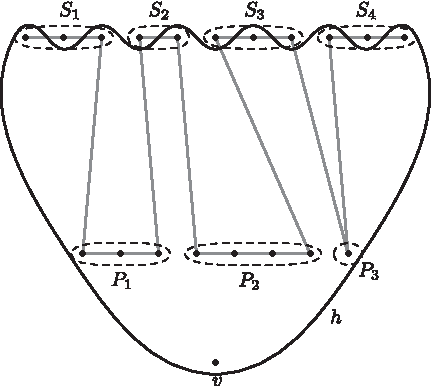
Hyperedge h of Dd,p which contains less than p edges from G′ depicted in Figure 4.
Let us count the number of edges of G′ that are contained in h. Each path
Finally, we show that Dd,p has a valid p-covering in which vertex v has degree 1. Consider the path G that starts at v and then visits all vertices in P and then all vertices in S (Fig. 6). Consider any hyperedge h = S′ ∪ P ∪ {v} where S′ is some subset of S of size d − p. The hyperedge h contains P ∪ {v}, and thus the subpath of G induced by these vertices. This subpath has p − 1 edges. Consider the subgraph of G induced by S′. If this subgraph contains at least one edge, we pick this edge for h, and hence, h is p-covered by G. Otherwise, S′ must consist only of odd numbered elements of the subpath of G induced by S, and thus it contains the first vertex of this subpath. Hence, h contains the edge of G connecting sets S and P, and we pick this edge for h, i.e., it is p-covered by G. ■
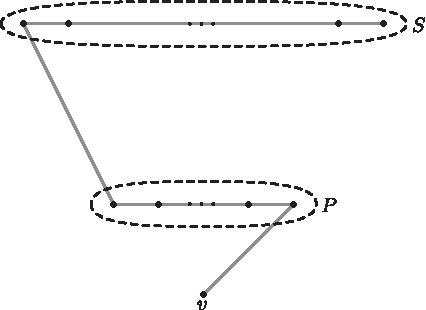
A valid p-covering of Dd,p in which vertex v has degree 1.
In the following theorem, we will use many copies of Dd,p to simulate the behavior of a 3-edge in the 1-covering problem with a d-edge in the p-covering problem.
Theorem 2
For every d − 2 ≥ p ≥ 1, the d-UH-p-CP Problem is NP-complete.
Proof
Clearly, this problem is in NP. We will show that it is also NP-hard by reduction from the 3-UH-1-CP Problem that was shown to be NP-complete in Section 3.
Given a 3-uniform hypergraph H = (V, E), we will construct a d-uniform hypergraph

Vertices and hyperedges added to
Now, assume that there is a valid p-covering
The graph G constructed above is obviously a 1-covering of H. Let us check that it is also valid. First, if there is a vertex
Conversely, assume there is a 1-covering G of H. We construct a p-covering
Finally, let us check that the construction is polynomial. The number of vertices of
5. The (d, k, ∞)-C1P Problem
We now show that for every d > k ≥ 2, the (d, k, ∞)-C1P is NP-complete, by showing the correspondence of this problem to the d-UH-(d − k)-CP Problem. A d-uniform hypergraph H = (V, E) can be represented as a binary matrix BH with |V| columns and |E| rows, where for each hyperedge
Lemma 2
A d-uniform hypergraph H = (V, E) can be (d − k)-covered by disjoint paths if and only if matrix BH has the (d, k, ∞)-C1P.
Proof
Assume first that H has a valid covering G. Since G consists of disjoint paths, there is a Hamiltonian path P on V containing all edges of G. This path defines an order on the vertices in V. Consider the ordering of the columns of matrix BH based on this order (V is the set of columns BH). We will show that this ordering is (d, k, ∞)-consecutive. Since each row of BH contains exactly d 1's, it is enough to show that d − k pairs of these d columns are adjacent in this ordering. The d columns containing 1's in each row form a hyperedge in H. Since G is a valid (d − k)-covering, there are edges between d − k pairs of these d columns in G. Since P contains all edges of G, it contains also these d − k edges and hence, each of the corresponding d − k pairs of columns are adjacent in the ordering. It follows that the ordering of BH is (d, k, ∞)-consecutive.
Conversely, assume that matrix BH is (d, k, ∞)-consecutive. Let
By Theorem 2 and Lemma 2, it follows that for every d > k ≥ 2, the (d, k, ∞)-C1P Problem is NP-complete.
Theorem 3
For every d > k ≥ 2, the (d, k, ∞)-C1P Problem is NP-complete.
6. Conclusion
In this work, we have studied the weakest formulation of the C1P Problem with gaps: indeed, in the (d, d − 1, ∞)-C1P case of the problem, it is required that only two of the d 1's in each row are adjacent, while the other 1's can end up arbitrarily far away from this pair. It is thus surprising that this problem is still NP-complete for any d ≥ 3 as implied by the general result of this paper. This article closes the case of the complexity of the (d, k, δ)-C1P Problem, with the exception of the (∞, 2, 1)-C1P case, or just the (2, 1)-C1P case (Maňuch et al., 2011), which remains open.
There are several directions we would like to follow in the future work: (i) Is it possible to find a nice characterization of non-(d, k, δ)-C1P matrices in terms of forbidden structures, such as Tucker submatrices (Tucker, 1972), especially, for small values of d? It has recently been shown that such a characterization could be used in the design of algorithms related to the C1P (Dom, 2008; Chauve et al., 2009a; Blin et al., 2010). (ii) When all three parameters are fixed, the (d, k, ∞)-C1P is related to the classical Graph Bandwidth Problem, and thus can be solved in polynomial time (Chauve et al., 2009b) using a variant of a relatively brute-force algorithm of Saxe (1980) for deciding if a graph has bandwidth k. Caprara et al. (2002) provide a linear time algorithm for the special case of deciding if a graph has bandwidth 2. It would be useful to investigate if the algorithm of Caprara et al. (2002) can be extended for deciding bandwidth for small values k ≥ 2, in an attempt to improve the algorithm of Chauve et al. (2009b) for deciding the (d, k, ∞)-C1P. (iii) The problem of covering hypergraphs with a collection of paths played a key role in the results of this paper article. Perhaps considering other conditions on the covering could give rise to other new interesting problems. (iv) Assuming that k is close to d, for each row there are many orders of columns which make this row (d, k, ∞)-consecutive. Hence, for a small number of rows, random instances of matrices have the (d, k, ∞)-C1P almost always. Conversely, for a large number of rows, random instances of matrices that have the (d, k, ∞)-C1P would have very few column orderings that witness this property. We would like to investigate the ratios between the number of rows and columns for which this is the case, with the goal of developing heuristics for both of these types of instances.
Footnotes
Acknowledgments
We would like to thank Cedric Chauve for the helpful remarks on this article. Research was supported by a NSERC Discovery Grant (to J.M.) and NSERC PGS-D3 (to M.P.).
Disclosure Statement
No competing financial interests exist.
2
We remark that the exact formulation of 3SAT(3) in Papadimitriou (![]() ) allows also variables with one positive and two negated occurrences, but these can easily be converted to the other type of variables by replacing them with their negations in all clauses. Clearly, this does not affect the complexity of the problem.
) allows also variables with one positive and two negated occurrences, but these can easily be converted to the other type of variables by replacing them with their negations in all clauses. Clearly, this does not affect the complexity of the problem.