
Abstract
Abstract
In genetics, it is often of interest to discover single nucleotide polymorphisms (SNPs) that are directly related to a disease, rather than just being associated with it. Few methods exist, however, for addressing this so-called “true sparsity recovery” issue. In a thorough simulation study, we show that for moderate or low correlation between predictors, lasso-based methods perform well at true sparsity recovery, despite not being specifically designed for this purpose. For large correlations, however, more specialized methods are needed. Stability selection and direct effect testing perform well in all situations, including when the correlation is large.
1. Introduction
Consider a study with n participants typed at p SNPs. The SNPs and the response are assumed to be related through
where
We consider the case where the predictors and response are binary. SNPs can be expressed in binary format despite having three levels by coding the dominant effect and recessive effect in two separate predictors. This allows us to capture dominant, recessive, and additive effects, where the latter is represented as an effect in both the dominant and recessive predictors. In genetic studies, the responses are also frequently binary as, for example, in case control studies.
In this article, we compare the lasso, screen and clean, stability selection, direct effect testing, and the elastic net; these methods are briefly described in Section 2. Of interest is their ability to recover true sparsity patterns in simulations. The methods are compared against Fisher's exact test, the standard test for binary association. Section 3 describes the simulations and presents the results. A comparison on real data is carried out in Section 4; we conclude in Section 5.
2. Sparsity Methods
2.1. Lasso
The lasso is a regression technique that performs variable selection (Tibshirani, 1996). Estimation is done by minimizing a penalized residual sum of squares function,
where λ is a tuning parameter. If λ = 0, the lasso is identical to ordinary least squares while a larger value of λ will make some coefficients zero, which corresponds to selection, and the remaining coefficients to be shrunk towards zero. The tuning parameter λ can be selected through cross validation or standard model selection criteria.
While lasso regression can be computed efficiently using the least angle regression algorithm (LARS) of Efron et al. (2004), it suffers from difficulty assigning significance to predictors. Meinshausen (2008) describes this notion as ill-posed; it may be obvious that an effect is present, but significance is lost in trying to assign the effect to a specific predictor. This leads to the naive inclusion of all those predictors with nonzero coefficients in the final sparse model.
2.2. Screen and clean
Screen and clean (Wasserman and Roeder, 2009) is an extension to the lasso that uses a two-stage approach to overcome two issues with the lasso: the difficulty of significance testing in the presence of a large number of potentially correlated predictors, and the tendency of the lasso to underestimate effect sizes (Radchenko and James, 2009). The “screen” stage fits a lasso regression to half of the data, producing a collection of predictors. The “clean” stage fits ordinary least squares regression to the other half of the data, using the predictors carried forward from the first stage. This reduced set of coefficients makes significance testing feasible and avoids effect sizes being underestimated. Significance testing is carried out with a Bonferroni correction on the reduced set.
2.3. Stability selection
Stability selection (Meinshausen and Bühlmann, 2010) tackles the problem of significance testing for predictors by resampling. Each resampled dataset is generated by selecting half of the observations at random (without replacement). For each subsample, lasso regression is fit, and the predictors with nonzero coefficients are recorded. Let mj be the count of times the jth predictor is nonzero. For each predictor
2.4. Elastic net
The elastic net (Zou and Hastie, 2005) combines lasso and ridge regression (Hoerl and Kennard, 1988). Like the lasso, it minimizes a penalised residual sum of squares function, but with an additional quadratic penalty term:
with the penalties relatively weighted by a tuning parameter α. Hence, amongst a set of highly correlated predictors, the elastic net tends to include either all or none of those predictors in the model. This is in contrast to the lasso, which tends to select a single predictor from a group of highly correlated predictors that are correlated with the response.
2.5. Direct effect testing
Direct effect testing (DET) (Sperrin and Jaki, 2010) detects independent associations, and calculates the probabilities that each predictor is the true origin of each independent association. The first stage of DET identifies independent associations using lasso regression to eliminate spurious association due to correlation between predictors. To calculate the significance of an effect, each independent association is attributed, automatically by the lasso, to a specific predictor. The second stage of DET then incorporates the uncertainty in the predictor that is the true origin of each independent association, by giving, for each predictor
for a collection of predictors
DET therefore provides a method to carry out fine mapping by identifying independent associations, and quantifying the uncertainty in their predictor of origin.
2.6. Pre-screening methods
In our simulations, we restrict the number of predictors to numbers in the thousands. Genetic data, however, frequently involve several hundred thousand predictors. Fan and Lv (2008) suggest an initial step in which the dimensionality is reduced to a more manageable level using “sure independence screening.” This is followed by application of the other methods described in this section. In our investigations, we will assume that, when appropriate, some dimension reduction approach has been applied first to reduce the number of predictors.
3. Design And Results Of Simulations
A range of simulations are carried out to study the properties of the methods introduced above. Situations involving strong and weak correlations, including both serially correlated and clustered data, are considered, and consistency properties of the methods on these simulated data are investigated. We begin by explaining how the various methods are applied, how significance is determined, and introduce some of the measures used to compare the methods.
For the lasso, the penalty is selected using cross validation; a find is recorded when a predictor receives a nonzero coefficient. For screen and clean, the lasso penalty is selected by cross validation and significance is determined using a Bonferroni correction. The results for stability selection are based on 100 resamples with the lasso penalty determined by cross validation and the significance threshold set at πthr = 0.75. We calculate elastic net solutions for three values of α: 0.9, 0.75, and 0.5. The penalty term λ is chosen via cross validation. Only α = 0.5 is displayed in the proceeding simulations. As α → 1, the elastic net solution becomes identical to the lasso; hence, elastic net solutions with larger α fall between the elastic net solutions displayed, and the lasso solutions. For DET, significance of each predictor is calculated using a Bonferroni correction. For stage two, let pmax be the probability of the best contender for the origin of a given independent association, then a “find” is defined as any other predictor that has a probability of origin that is at least 10% as large as the best contender (i.e., 0.1 pmax). We also include results for Fisher's exact test, with a Bonferroni correction, as a baseline comparison.
The comparisons are not an indicator of which methods are universally best. Each method is designed to deal with different scenarios, and here only the ability of the methods to recover true sparsity patterns is considered. Moreover, it is difficult to make the comparisons fair; for example, DET has multiple chances to make a find per significant effect identified, while formal significance testing is not used in declaring significance for the lasso.
The response for each individual observation, Yi, is generated according to Pr[Yi = 1] = μi, where
so that the response is related to a subset of K predictors with indices
Data are generated in a reasonably simple fashion, for example, by considering first-order auto-regressive predictors. More realistic correlation patterns for genetic data can be generated using real LD patterns. However, this does not give us the flexibility to change the extent of the correlation that we get here. Simulations based around real datasets, which therefore contained more realistic LD patterns, were also undertaken. As the results were qualitatively the same as those under the simpler situations, they are not presented.
If a method finds a predictor that was truly used to generate the response, this is called a “true find.” Any other predictors found are declared “false finds.” A “strong false find” is recorded whenever at least one incorrect predictor is included in the model; a “strong true find” means all the causal predictors are recovered. A “perfect find” means the model includes all causal predictors and no other predictors (i.e., occurrence of a strong true find and non-occurrence of a strong false find). A standard definition of false discovery rate (FDR),
Since in genetics it is often of interest to detect predictors in high LD with a causal variant, we also carry out simulations in which the definition of a “true find” is relaxed so that a true predictor is declared to have been found provided any predictor with a correlation of at least 0.9 to the true predictor has been found. We denote the results corresponding to this definition the HCT (highly correlated with the true predictor) cases. These results are only included for some cases, as the omitted scenarios were qualitatively the same. To enhance readibility, in all figures, false finds are displayed on a log scale, whilst the remaining measures are displayed on a linear scale.
The “glmnet” function in the “glmnet” library (Friedman et al., 2011) in R (R Development Core Team, 2008) was used to calculate lasso and elastic net solutions. All other code was written by the authors.
3.1. Serially correlated data
To generate serially correlated data, denoting the correlation by ρ, the approach used is:
1. Generate random binary realisations for
2. For
3. Randomly assign a causal predictor with coefficient 0.81, and run the sparsity procedures. Repeat ten times on each dataset.
4. Repeat steps 1–3 for 100 times to obtain 100 different datasets, and hence 1000 simulations in total.
This procedure is repeated for a range of serial correlations, from ρ = 0 to ρ = 0.99.
Figure 1 illustrates the simulated true finds, perfect finds, false finds, and FDRs for serial correlations ranging from 0 to 1. For small to moderate correlation, stability selection gives the highest perfect find rate and lowest FDR. Most of the methods deteriorate in fairly similar ways as the correlation approaches one. Once the correlation becomes close to one, DET has the highest number of perfect finds. This is a consequence of the second stage of DET accounting for the high correlation by giving a large set of potential predictors for each detected effect. It is only once ρ > 0.75, however, that including stage two of DET gives additional benefits over stage one alone (DET stage one not shown). Figure 1 also demonstrates poor false find control of the elastic net and Fisher test, although the Fisher test, unsurprisingly, copes well at low correlations.
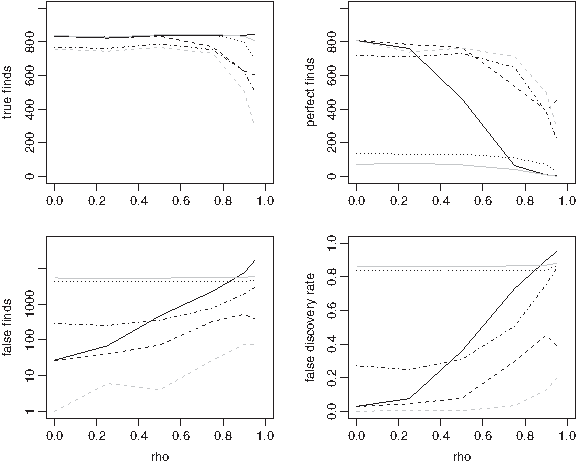
Serial correlation. Comparing true finds
Figure 2 illustrates the HCT case. Stability selection benefits the most from this relaxation of the definition of a find: the deterioration in its accuracy for large correlation is prevented. Lasso, the elastic net, and the Fisher test do not appear to benefit.
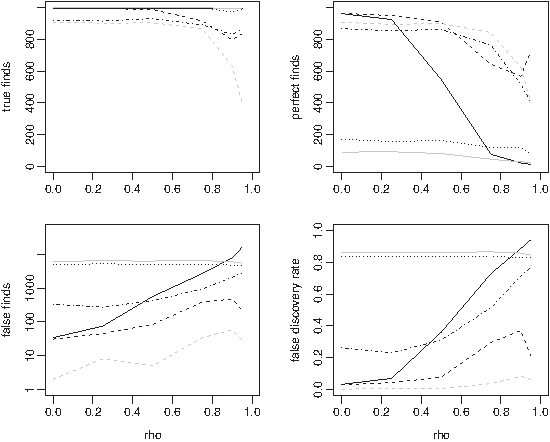
Serial correlation (HCT case). Comparing true finds
To study consistency, the same data generation as above was used and the correlation fixed while the sample size, n, varied. Figure 3 gives true finds, perfect finds, false finds, and FDRs for the methods with correlation ρ = 0.95. Figure 4 gives the same for correlation ρ = 0.5. In both cases, the number of predictors p = 400.
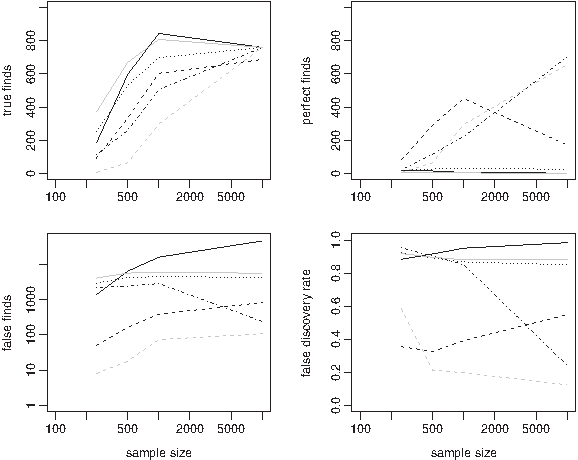
Comparing true finds
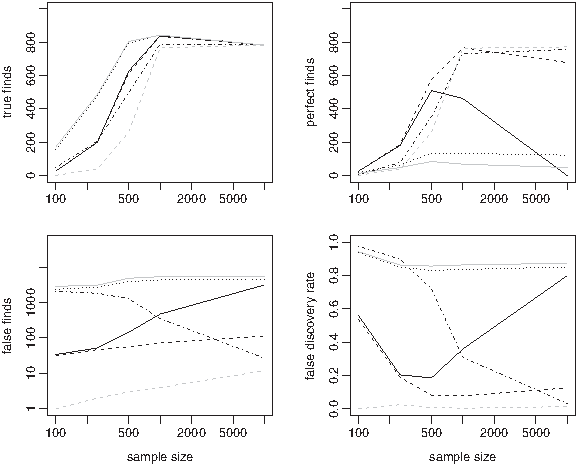
Comparing true finds
Screen and clean has the best consistency properties in the high correlation scenario, since the perfect find rate increases and the false discovery rate decreases as the sample size increases. Stability selection also performs well in the high correlation scenario since the perfect find rate increases and the false discovery rate is controlled (although it does not appear to decrease as fast when n increases). DET performs poorly as sample size increases in the large correlation case; a large number of false finds are generated for large n, and the perfect find rate does not increase. For lasso, elastic net, and the Fisher test, there appears to be no gain in having a sample size larger than 1000.
For the low correlation case (Fig. 4), all the methods considered have good consistency properties. DET outperforms the other methods in terms of perfect finds for small n; stability selection and screen and clean are the better performers on these measures for larger sample sizes n.
3.2. Clustered data
Clustered data is generated with p = 400 predictors, divided into clusters of size k, for a range of cluster sizes from k = 1 to k = 10. When necessary, extra predictors are added to fill the last cluster. Within cluster correlation is set to ρ and while different clusters are independent. The data generation procedure is as follows:
1. Generate random binary realizations for
2. For each subsequent
Hence, this is carried out k − 1 times in each cluster.
3. Randomly assign a causal predictor with coefficient 0.81, and run the sparsity procedures. Repeat ten times on each dataset.
4. Repeat steps 1–3 for 100 times to obtain 100 different datasets, and hence 1000 simulations in total.
Figure 5 visualizes the results of various cluster sizes, for a within cluster correlation ρ = 0.9. Stability selection controls the FDR and maintains a large number of perfect finds, out-performing all the other methods. Cluster size has little effect on the performance of lasso and elastic net, but a large detrimental effect on the performance of the Fisher test.

Comparing true finds
Figures 6 repeats the cluster size study, but within cluster correlation is set to ρ = 0.95. The larger correlation makes stability selection struggle to make perfect finds, but it does continue to control the FDR. DET now achieves the largest number of perfect finds, and the second best FDR control. Comparing Figures 5 and 6 shows that increasing the correlation has little effect on the performance of the lasso, elastic net, or Fisher test.
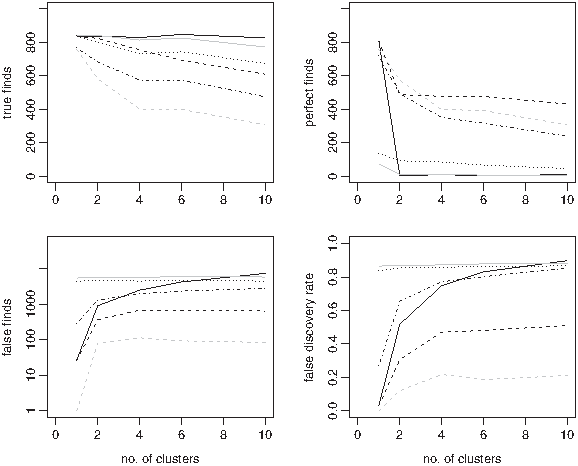
Comparing true finds
Consistency of the various methods was also considered in the clustering framework. The results are qualitatively similar to those in the serial correlation framework and hence are omitted.
4. Real Data Example
We compare the methods on a dataset arising from a case-control study investigating whether there are SNPs that act as biomarkers for hypersensitivity (yes or no) to abacavir, a treatment for HIV (Kelly et al., 2006). We will use the combined data from two global trials (Hetherington et al., 2002) in our investigation.
The initial dataset consisted of 856 SNPs that have been arbitrarily numbered and are spread across the 22 autosomal chromosomes. To obtain binary data, we separate the dominant and recessive effect of each SNP into two predictors and then remove any binary predictor whose prevalence of 0s or 1s is below 5% giving p = 1373 binary predictors for our evaluations. The methods are applied, and the SNPs that have been declared “finds” are recorded in Table 2. “Perfect finds” cannot be considered here, as the true relationship is unknown.
The most conservative methods are DET and stability selection, both of which find the same two SNPs significant—the dominant effects on SNP 229 and SNP 336. The same two SNPs are identified with all other methods except screen and clean. There is large agreement between the methods on which SNPs to include, although some methods detect more SNPs than others. Screen and clean is the exception: it identifies SNPs that are not found with other methods, not even the Fisher test which identifies by far the most SNPs (i.e., 24). Only four of the nine SNPs found with screen and clean are identified with any of the other methods.
5. Discussion
This article presents a thorough simulation study of the performance of various methods at recovering true sparsity patterns, specifically with application in genetic studies. Many of these methods are not designed for the objective of true sparsity recovery but still performed well in recovering true predictors. For lasso, elastic net, and the Fisher test, this is at the expense of a large number of false finds; stability selection and DET achieve the true finds without too many false finds. Once the correlation becomes high, all methods struggle; DET copes relatively well, but unfortunately its performance does not improve notably with sample size. In our simulations, screen and clean benefits most from larger sample sizes.
Stability selection performed extremely well. At first glance, it seems that, because of the bootstrapping approach used, even moderate correlation may cause problems for the method. Whilst it does fail for very large correlations, datasets with neighboring correlations as high as ρ = 0.95 are handled well. Indeed, until the correlation reaches this high level, stability selection also controls the type one error. Meinshausen and Bühlmann (2010) proved type one error control for exchangeable coefficients; this work represents further empirical evidence that similar control is achieved in many non-exchangeable situations. Indeed, when the definition of a true find is relaxed to declaration of a predictor with correlation of at least 0.9 with the true predictor, stability selection performs best in all scenarios.
As the density of information collected increases, measured predictors will become increasingly correlated. So, methods that are specifically designed to handle this are needed.
Footnotes
Disclosure Statement
No competing financial interests exist.