
Abstract
Abstract
In a network orientation problem, one is given a mixed graph, consisting of directed and undirected edges, and a set of source-target vertex pairs. The goal is to orient the undirected edges so that a maximum number of pairs admit a directed path from the source to the target. This NP-complete problem arises in the context of analyzing physical networks of protein-protein and protein-DNA interactions. While the latter are naturally directed from a transcription factor to a gene, the direction of signal flow in protein-protein interactions is often unknown or cannot be measured en masse. One then tries to infer this information by using causality data on pairs of genes such that the perturbation of one gene changes the expression level of the other gene. Here we provide a first polynomial-size ILP formulation for this problem, which can be efficiently solved on current networks. We apply our algorithm to orient protein-protein interactions in yeast and measure our performance using edges with known orientations. We find that our algorithm achieves high accuracy and coverage in the orientation, outperforming simplified algorithmic variants that do not use information on edge directions. The obtained orientations can lead to a better understanding of the structure and function of the network.
1. Introduction
While PDIs are naturally directed (from a transcription factor to its regulated genes), PPIs are not. Nevertheless, many PPIs transmit signals in a directional fashion, with kinase-substrate interactions (KPIs) being one of the prime examples. These directions are vital to understanding signal flow in the cell, yet they are not measured by most current techniques. Instead, one tries to infer these directions from perturbation experiments. In these experiments, a gene (cause) is perturbed and as a result other genes change their expression levels (effects). Assuming that each cause-effect pair should be connected by a directed pathway in the physical network, one can predict an orientation (direction assignments) to the undirected part of the network that will best agree with the cause-effect information.
The resulting combinatorial problem can be formalized by representing the network as a mixed graph, where undirected edges model interactions with unknown causal direction, and directed edges represent interactions with known directionality. The cause-effect pairs are modeled by a collection of source-target vertex pairs. The goal is to orient (assign single directions to) the undirected edges so that a maximum number of source-target pairs admit a directed path from the source to the target. We call this problem MAXIMUM-MIXED-GRAPH-ORIENTATION.
Previous work on this and related problems can be classified into theoretical and applied work. On the theoretical side, Arkin and Hassin (2002) studied the decision problem of orienting a mixed graph to admit directed paths for a given set of source-target vertex pairs and showed that this problem is NP-complete. The problem of finding strongly connected orientations of graphs can be solved in polynomial time (Boesch and Tindell, 1980; Chung et al., 1985). Recently we proved that MAXIMUM-MIXED-GRAPH-ORIENTATION admits a sub-linear polynomial-time approximation (Elberfeld et al., 2011). For a comprehensive discussion of the various kinds of graph orientations, we refer to the textbook of Bang-Jensen and Gutin (2008).
For the special case of an undirected network (with no pre-directed edges), the orientation problem was shown to be NP-complete and hard to approximate to within a constant factor of 11/12 (Medvedovsky et al., 2008). On the positive side, Medvedovsky et al. (2008) provided an ILP-based algorithm, and showed that the problem is approximable to within a ratio of Ω(1/log n), where n is the number of vertices in the network. The approximation ratio was later improved to Ω(log log n / log n) (Gamzu et al., 2010). Dorn et al. (2011) studied the parameterized complexity of orienting undirected networks.
On the practical side, several authors studied the orientation problem and related annotation problems. Yeang et al. (2004) were the first to use perturbation experiments to annotate protein networks. They proposed a probabilistic model and an accompanying inference approach to predict edge directions and signs of activation and repression from cause-effect data. Ourfali et al. (2007) provided an ILP formulation for the problem of inferring edge signs that maximize the expected number of explained cause-effect pairs. Gitter et al. (2011) used SATISFIABILITY-based approximations to tackle the orientation problem. The main caveat of all these approaches is that they depend on enumerating all possible paths between a pair of genes and, hence, they are limited to paths of very short length (3 for the first two works and 5 for the latter).
Our main contribution in this article is a first efficient ILP formulation of the orientation problem on mixed graphs, leading to an optimal solution of the problem on current networks. We implemented our approach and applied it to a large data set of physical interactions and knockout pairs in yeast. We collected interaction and cause-effect pair information from different publications and integrated them into a physical network with 3,658 proteins, 2,639 PPIs, 4,095 PDIs, along with 53,809 knockout pairs among the molecular components of the network. We carried out a number of experiments to measure the accuracy of the orientations produced by our method for different input scenarios. In particular, we studied how the portion of undirected interactions and the number of cause-effect pairs affect the orientations. We further compared our performance to that of two layman approaches that are based on orienting undirected networks, ignoring the edge directionality information. We demonstrate that our method retains more information to guide the search, achieving higher numbers of correctly oriented edges.
The article is organized as follows: In Section 2, we provide preliminaries and define the orientation problem. In Section 3, we present an ILP-based algorithm to solve the orientation problem on mixed graphs. In Section 4, we discuss our implementation of this algorithm, and in Section 5, we report on its application to orient physical networks in yeast.
2. Preliminaries
We focus on simple graphs with no loops or parallel edges. A mixed graph is a triple G = (V, EU, ED) that consists of a set of vertices V, a set of undirected edges EU ⊆ {e ⊆ V | |e|=2}, and a set of directed edges ED ⊆ V × V. We assume that every pair of vertices is either connected by a single edge of a specific type (directed or undirected) or not connected. For convenience, we also use the notations V(G), EU (G), and ED (G) to refer to the sets V, EU, and ED, respectively. A mixed graph G is a directed graph if EU (G) = ∅ (the empty set). It is an undirected graph if ED(G) = ∅. A directed graph is strongly connected if every vertex has a directed path to every other vertex.
Let G1 and G2 be two mixed graphs. The graph G1 is a subgraph of G2 if and only if the relations V(G1) ⊆ V(G2), EU(G1) ⊆ EU(G2), and ED(G1) ⊆ ED(G2) hold; in this case we also write G1 ⊆ G2. Similarly, an induced subgraph G[V′] is a subset V′ ⊆ V of the graph's vertices and all their pairwise relations (directed and undirected edges).
A path in a mixed graph G of length m is a sequence
Let G be a mixed graph. An orientation of G is a directed graph G′ = (V(G),∅,ED(G′)) over the same vertex set whose edge set contains all the directed edges of G and a single directed instance of every undirected edge, but nothing more. We are now ready to state the main optimization problem that we tackle:
Problem 2.1 (MAXIMUM-MIXED-GRAPH-ORIENTATION)
3. An Ilp Algorithm For Orienting Mixed Graphs
In this section, we present an integer linear program (ILP) for optimally orienting a mixed graph. The inherent difficulty in developing such a program is that a direct approach, which represents every possible path in the graph with a single variable (indicating whether, in a given orientation, this path exists or not), leads to an exponential program. Below we will work toward a polynomial size program.
Many algorithms for problems on directed graphs first solve the problem for the graph's strongly connected components independently and, then, work along the directed acyclic graph (DAG) of strongly connected components to produce a solution for the whole instance. Our ILP-based approach for orienting mixed graphs has the same high level structure: In Section 3.1, we define a generalization of strongly connected components to mixed graphs, called strongly orientable components, and show how the computation of a solution for the orientation problem can be reduced to the mixed acyclic graph of strongly orientable components. For MAGs, in turn, we present, in Section 3.2, a polynomial-size ILP that optimally solves the orientation problem.
3.1. A reduction to a mixed acyclic graph
Let G be a mixed graph. The graph G is strongly orientable if and only if it can be oriented so that every vertex is reachable from every other vertex (i.e., the resulting directed graph is strongly connected). The strongly orientable components of G are its maximal strongly orientable subgraphs. It is straightforward to prove that a graph can be partitioned into its strongly orientable components (by noting that if the vertex sets of two strongly orientable graphs intersect, then their union is also strongly orientable). The strongly orientable component graph, or component graph, GSOC of G is a mixed graph that is defined as follows: Its vertices are the strongly orientable components
To complete the reduction we need to specify the new set of source-target pairs. This also involves a slightly more general definition of the orientation problem where the collection of input pairs is allowed to be a multi-set. Let P be the input multi-set for the original graph G. The multi-set PSOC for the reduced graph is constructed as follows: for every pair
Lemma 3.1.
Let G be a mixed graph and P a set of vertex pairs from G. For every
Proof
For the “only if”-direction, let G′ be an orientation of G that satisfies k pairs from P. Due to the maximality of the components, there are no directed edges back and forth between different strongly orientable components of G in G′. We can orient the edges of GSOC as follows: For every undirected edge {Ci, Cj} of GSOC, we choose the orientation (Ci, Cj) if there exist vertices
For the “if”-direction, we consider an orientation
A mixed acyclic graph GSOC = (V, EU, ED) is, in general, neither a forest nor a directed acyclic graph. Its structure inherits from both of these concepts: The undirected graph (V, EU, ∅) is a forest whose trees are connected by the directed edges ED without producing cycles. This observation gives rise to the following definition of topological sortings for mixed graphs: A mixed graph G admits a topological sorting if (1) the connected components of (V, EU, ∅) are trees and (2) they can be arranged in a linear order
3.2. An ILP formulation for mixed acyclic graphs
Given an instance of a MAG G and a multiset of vertex pairs P, our ILP consists of a set of binary orientation variables, describing the edge orientations, and binary closure variables, describing reachability relations in the oriented graph. The objective of satisfying a maximum number of vertex pairs can then be phrased as summing over closure variables for all pairs from P.
The ILP relies on a topological sorting
The orientation variables in (1) are used to encode orientations of the edges: an assignment of 1 to o(v,w) means that the undirected edge {v, w} is oriented from v to w. The closure variables in (2) are used to represent which vertex pairs of the graph are satisfied: an assignment of 1 to c(v, w) will imply that there exists a directed path from v to w in the orientation. During the construction we will set closure variables c(v, w) with
The ILP contains the constraints
and the objective
Constraints in (4) force that each undirected edge is oriented in exactly one direction. The remaining constraints in (5) to (7) are used to connect closure variables to the underlying orientation variables. They force that a closure variable c(v, w) can only be set to 1 if the orientation variables describe a graph that allows a directed path from v to w. Whenever v and w are in the same undirected component (which is a tree since the whole graph is a MAG), they can only be connected via an orientation of the unique undirected path between them. For vertex pairs of these kind constraint (5) ensures the above property. If v and w are in different components Ti and Tj with i < j, we need to associate c(v, w) with all possible paths from v to w. This is done by using the path variables: If there is a path from v to w, then it must visit a directed edge (v′, w′) that starts in some component that precedes Tj and ends at T j (constraint (6)). Path variables are, in turn, constrained by (7). The objective function maximizes the number of closure variables with assignment 1 that correspond to pairs from P. The following lemma formally establishes the correctness of the ILP.
Lemma 3.2
The following properties hold:
Proof
Let Ii be the ILP from above for Gi and Pi. We prove the completeness and soundness properties via induction over increasing values of
For i = 1, Gi is the tree T1. Due to the constraints in (4), which assure that for every edge exactly one orientation is chosen, and in (5), which describe paths in trees, both properties hold. To prove the completeness property, we assume that it holds for some
To prove the induction step for the soundness property, let a : variables(Ii) → {0, 1} be an assignment that satisfies all constraints from Ii. By the induction hypothesis, there exists an orientation
The ILP has polynomial size and can be constructed in polynomial time. The construction starts by sorting the MAG topologically. Constant length constraints in (4) are constructed for all undirected edges. For every ordered pair (v, w) of vertices v and w that are inside the same undirected component Ti, we construct at most |EU| constraints of type (5) using reachability queries to Ti. The sum constraints in (6) are constructed for all ordered vertex pairs (v, w) where the undirected component of v comes before the undirected component of w in the topological sorting of the MAG. Each sum iterates over the directed edges that lead into the component of w. Thus, each sum's length is bounded by O(|ED|) and it can be written down in polynomial time. The constraints in (7) of constant length are constructed by iterating over the same vertex pairs and directed edges. In total, the size of the ILP is at most O(|V(G)|2(|ED| + |EU|)).
One may ask if it is possible to apply the ILP construction to general mixed graphs instead of MAGs. The MAG-based construction explores a mixed acyclic graph G iteratively by using a topological sorting
4. Implementation Details
Our implementation is written in C++ using BOOST C++ libraries (version number 1.43.0) and the commercial IBM ILOG CPLEX optimizer (version number 12) to solve ILPs. The input of our program consists of a mixed graph G = (V, EU, ED) and a collection P of vertex pairs from G. The program predicts an orientation G′ for G that satisfies a maximum number of pairs from P.
The program starts by computing strongly connected orientations for all strongly orientable components of the input graph. This can be done in polynomial time, as described in Section 3.1. Our program implements a linear time approach for this step that is based on combined ideas from Tarjan (1972) and Chung et al. (1985). Next, the program computes the acyclic component graph GSOC of G and transforms the collection of pairs P into the collection of pairs PSOC. Finally, the program computes an optimal orientation for the resulting instance (GSOC, PSOC) via the ILP approach from Section 3.2. This results in an orientation for all undirected edges that are not inside strongly orientable components and the number of satisfied pairs, which is optimal. Altogether, the program outputs an optimal orientation for the input instance and, if desired, the satisfied pairs and their number. The resulting computational pipeline is shown in Figure 1, and an example of it is provided in Figure 2.
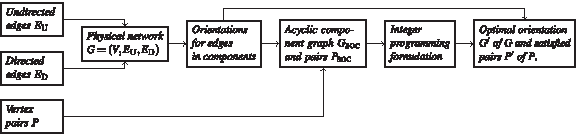
The computational pipeline. The input consists of a network of undirected and directed physical interactions between proteins, and a collection of cause-effect vertex pairs. The program (1) computes a partial orientation of the graph by orienting all edges that lie inside strongly orientable components, (2) contracts the components to produce an acyclic component graph, (3) solves the problem for this instance optimally by using an ILP formulation, and (4) outputs the predicted orientation along with the satisfied pairs.
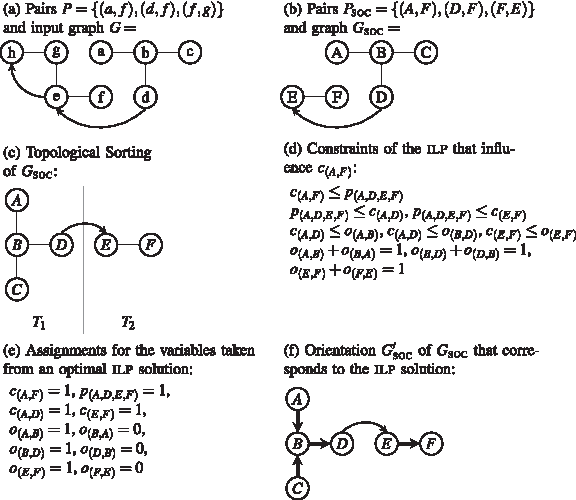
The computational pipeline working on an example input.
Due to the combinatorial nature of our approach, there is possibly more than one orientation that results in an optimal number of satisfied pairs. To determine if an undirected edge e = {v, w} has the same orientation in all maximum solutions, one can utilize our computational pipeline as follows: First compute the number sOPT of satisfied pairs in an optimal solution. Let (v, w) be the orientation of e in this solution. Then run the experiment again, but this time with {v, w} replaced by the directed edge (w, v) in the input network. After that set a confidence value ce = sOPT − se, where se is the maximum number of satisfied pairs for the modified instance. The edge e is said to be oriented with confidence if and only if ce ≥ 1; in this case its direction is the same in all optimal orientations of the input.
5. Experimental Results
5.1. Data acquisition and integration
We gathered protein-protein interactions and cause-effect pair information for Saccharomyces cerevisiae from different sources. We used the protein-protein interaction (PPI) data set “Y2H-union” from Yu et al. (2008), which contains 2,930 highly-reliable undirected interactions between 2,018 proteins. The protein-DNA interaction (PDI) data were taken from MacIsaac et al. (2006), an update of which can be found at http://fraenkel.mit.edu/improved_map/. We used the collection of PDIs with p < 0.001 conserved over at least two other yeast species, which consists of 4,113 unique PDIs spanning 2,079 proteins. The kinase-substrate interactions (KPIs) were collected from Breitkreutz et al. (2010) by taking the directed kinase-substrate interactions out of their data set. This results in 1,361 KPIs among 802 proteins. A set of 110,487 knockout pairs among 6,228 proteins were taken from Reimand et al. (2010).
We integrated the data to obtain a physical network of undirected and directed interactions. We removed self loops and parallel interactions; for the latter, whenever both a directed and an undirected edge were present between the same pair of vertices, we maintained the former only. Pairs of edges that are directed in opposite directions were maintained, and will be contracted into single vertices in later phases of the preprocessing. The resulting physical network, which we call the integrated network, spans 3,658 proteins, 2,639 PPIs, 4,095 PDIs, and 1,361 KPIs. For some of the following experiments, we wish to investigate the contribution of the directed edges to the orientation in a purified manner. To this end, we will also use the subnetwork of 2,579 proteins of the integrated network that is obtained by taking only the directed PDIs and PKIs, leaving the PPIs out; we call it the refined network. To orient the physical networks, we use the set of 110,487 knockout pairs and consider the subset of pairs with endpoints being in the physical network. The integrated network contains 53,809 of the pairs; the refined network contains 34,372 of the pairs.
5.2. Application and performance evaluation
To study the behavior and properties of our algorithm, we apply it to the physical networks and monitor properties of the instance from the intermediate steps and the resulting orientations. For the former, we examine the contraction step, monitoring the size of the component graph obtained (numbers of vertices, directed edges, and undirected edges), and the number of cause-effect pairs after the contraction. For the latter, we run the algorithm in a cross-validation setting, hiding the directions of some of the edges and testing our success in orienting them.
The component graph for the integrated network contains 763 undirected edges and 2,910 directed edges among 2,569 vertices. We filter from the corresponding set of pairs PSOC those pairs that have the same source and target vertices; these pairs lie inside strongly orientable components and are already satisfied. About 85% (44,825) of the initial pairs remain in the contracted graph and can be used to guide the orientation produced by our ILP.
Investigating the runtime further, we found that while the preprocessing time is approximately constant (a few seconds), the ILP solution time is variable. It is influenced by a number of factors, among which are the amount of undirected edges to which the solver assigns a direction, and the number of undirected components in the contracted graph, which directly influences the number of constraints in the ILP. The dominant factor was the number of pairs that have a source to target path, which constitutes the objective of the program.
The computational intensive part is the computation of confidence scores. These entail rerunning the steps of the computational pipeline for each of the oriented edges, resulting in about 3.4 hours for the integrated network and 5 hours for the refined network (in which more test edges remain after the cycle contraction).
In the left two columns, the 1,361 KPIs are used as test edges; in the right two columns, the 4,095 PDIs are used as test edges.

Coverage (squares) and accuracy (circles) as a function of the percentage of the 1,361 KPIs

The number of covered and accurately oriented test edges as a function of the percentage of cause-effect pairs guiding the orientation.
5.3. Comparison to layman approaches
In this section, we wish to compare our method to previous approaches. As mentioned in the introduction, the probabilistic approach of Yeang et al. (2004) and the SATISFIABILITY-approximation approach of Gitter et al. (2011) suffer from an exponential blow-up that grows with the number of paths between the end vertices of cause-effect pairs. This limits the applicability of these methods to pairs of distance at most 3–5. We have not tried to tweak these methods to work on our data sets in which the distance bound is much larger (distance of 14). Instead we adapted methods for orienting undirected graphs to the mixed graph case and compared them to our approach.
We compared to the method for orienting undirected graphs with unbounded distances between pairs from Medvedovsky et al. (2008). In our terminology, it first contracts all cycles in the input undirected graph, obtaining a tree. It then applies an ILP-formulation, using the fact that there is at most one path between any two vertices in the tree. We consider two ways of transforming mixed graphs into undirected graphs to which this method can be applied. Both approaches take their action after the construction of the component graph for the mixed input graph. While our approach, which we call MIXED, uses an ILP at this point, the DELETION approach removes all directed edges from the component graph, yielding a forest of its undirected components to which an ILP is applied. The UNDIRECTED approach considers all directed edges as being undirected and applies a second component contraction step to produce a forest to which the ILP is applied. The same forest can be obtained by starting from the input graph, making all directed edges undirected, and applying a single contraction step.
The behaviors of the intermediate steps of the three approaches when applied to the integrated network are shown in Table 2a. In comparison to UNDIRECTED, MIXED maintains a higher number of vertices in the component graph, as less cycles are contracted. In comparison to DELETION, MIXED maintains a much higher amount (6-fold) of pairs that are reachable in the component graph and, therefore, can potentially affect the orientation process. This is due to the fact that the edge deletion separates large parts of the graph. Overall, one can see that MIXED retains more information for the ILP step in the form of vertices in the component graph and causal information from the knockout pairs.
To compare the orientations produced by the three approaches, we applied them to the refined network using the KPIs as test edges and different portions of the cause-effect pairs. As the baseline for computing the coverage of the three approaches should be the same—the number of test edges after the initial contraction—we report in the following the absolute numbers of covered (confidently oriented) and correctly oriented interactions, rather than the relative coverage and accuracy measures. Table 2b presents these results, comparing the numbers of remaining, covered and correctly oriented test edges among the three approaches. Evidently, MIXED yields higher numbers of test edges, covered edges, and correctly oriented edges. The differences between DELETION and MIXED are more pronounced when the input set of cause-effect pairs is smaller. This nicely corresponds to the dramatic difference between the numbers of pairs that are reachable in the corresponding component graphs.
6. Conclusion
We presented an ILP algorithm that efficiently computes optimal orientations for mixed graph inputs. We implemented the method and applied it to the orientation of physical interaction networks in yeast. Depending on the input, the method yields very high coverage and accuracy in the orientation. Our experiments further show that the algorithm works very fast in practice and produces orientations that cover (accurately) larger portions of the network compared to the ones produced by previous approaches that ignore the directionality information and operate on undirected versions of the networks. Nevertheless, all these methods suffer from the ambiguity of direction assignment to edges on cycles; as a result, only 12–22% of the undirected edges in the network are confidently oriented in our experiments.
While in this article we concentrated on the computational challenges in network orientation, the use of the obtained orientations to gain biological insights on the pertaining networks is of great importance. As demonstrated by Gitter et al. (2011), the directionality information facilitates pathway inference. It may also contribute to module detection; in particular, it is intriguing in this context to map the correspondence between contracted edges (under our method) and known protein complexes.
Footnotes
Acknowledgments
Disclosure Statement
No competing financial interests exist.