
Abstract
Abstract
Bayesian network model is widely used for reverse engineering of biological network structures. An advantage of this model is its capability to integrate prior knowledge into the model learning process, which can lead to improving the quality of the network reconstruction outcome. Some previous works have explored this area with focus on using prior knowledge of the direct molecular links, except for a few recent ones proposing to examine the effects of molecular orderings. In this study, we propose a Bayesian network model that can integrate both direct links and orderings into the model. Random weights are assigned to these two types of prior knowledge to alleviate bias toward certain types of information. We evaluate our model performance using both synthetic data and biological data for the RAF signaling network, and illustrate the significant improvement on network structure reconstruction of the proposing models over the existing methods. We also examine the correlation between the improvement and the abundance of ordering prior knowledge. To address the issue of generating prior knowledge, we propose an approach to automatically extract potential molecular orderings from knowledge resources such as Kyoto Encyclopedia of Genes and Genomes (KEGG) database and Gene Ontology (GO) annotation.
1. Introduction
where P(Gh|ξ) represents the prior probability of the hypothesis network and P(D|Gh, ξ) represents the marginal likelihood of data. Employing the Bayesian network model's definition and certain assumptions, the marginal likelihood can be calculated with a closed form formula (Heckerman and Chickering, 1995). The prior probability can also be decomposed into product of local conditional probabilities of all the variables as shown below:
In the above equation, Xi is the ith node in the network Gh, Pa(Xi) is the set of parent nodes of Xi, and n is the total number of nodes in Gh. This decomposition greatly improves the efficiency of the prior probability computation (Cooper and Herskovits, 1992; Heckerman and Chickering, 1995; Segal et al., 2005).
Since the number of possible network structures is super-exponential to the number of nodes in a network, it is computationally infeasible for a Bayesian network model to enumerate all the possible network structures and find the global optimum. Traditionally, heuristic approaches such as hill climbing have been used to find the local maximum (Imoto et al., 2002; Ko et al., 2009). An alternative approach is to apply the Monte Carlo Markov Chain (MCMC) methods to find the posterior probability distribution of network structures directly (Geier et al., 2007; Grzegorczyk et al., 2008; Kaderali et al., 2009).
An appealing feature of Bayesian network models is their capability to integrate prior knowledge into reconstruction of biological networks. Some previous studies have examined the effects of including direct molecular interactions into prior probability P(Gh|ξ) (Imoto et al., 2003; Tamada et al., 2003; Nariai et al., 2004; Imoto et al., 2006; Husmeier and Werhli, 2007; Werhli and Husmeier, 2007; Perrier et al., 2008). Our own previous work also has tackled the approach of including molecular orderings, in addition to the direct interactions, into explicitly computing the prior probability (Pei et al., 2008). Basically, we assign fixed weights to both the direct links and the orderings prior knowledge and show their positive impact on Bayesian network model learning by using synthetic data.
In the present study, we extend our previous work (Pei et al., 2008) by proposing three improvements. First, we introduce random weights to both direct links and ordering relations in computing the posterior probabilities. This eliminates the artifacts stemming from the fixed weights on model performance and allows the model to adapt to the knowledge and data automatically. Second, we automatically derive prior knowledge from public databases such as GO and KEGG. And finally, we evaluate the performance of our model with real biological data, which is for the human RAF signal transduction network published by Sachs et al. (2005).
2. Methods
2.1. Integration of prior knowledge
The prior knowledge for direct links is defined by an n × n matrix L, where n is the number of variables in the network and each entry Lij represents prior confidence about variable i affecting variable j directly, ranging from 0 to 1. In addition, we also use the term “ordering” in the present study to represent knowledge of one molecule i affecting another target molecule j in a biological network without a direct link. We denote i as an ancestor of j and summarize the ordering prior knowledge with an n × n matrix K, where each entry Kij ranging from 0 to 1 represents prior confidence about whether variable i is an ancestor of variable j. We thus define the prior probability of a hypothesis network structure Gh as
where Z is a partition function, and EL(Gh) and EK(Gh) represent “energies” of Gh, which are derived, respectively, from matrices L and K as follows:
In the above equations, Bij and
2.2. Partition function with random weights
The weights ωl and ωk in Equations (2) and (3) can be either constants or random variables. Constant weights simplify the computation but suffer from introducing a bias into the analysis outcome as we have already reported elsewhere (Pei et al., 2008). Hence we treat weights as random variables here and discuss how the partition function can be computed.
The partition function Z in Equation (1) is defined as
where
In the present study, we use an upper bound of Z as an estimate for model learning. It is easy to see that
The partition function computation above can be further simplified by ignoring the parent nodes and ancestor nodes whose probabilities in Equation (2) or (3) are 0.5, since they will be canceled out in prior probability computation. We also set the fan-in restriction on the number of parents and ancestors for each node. After the simplification, the final run time of Equation (5) is bounded by a polynomial in the number of nodes of the network.
2.3. Model learning with MCMC
We use the MCMC algorithm to sample the network structures directly from their posterior probability distribution and then derive the probability of each edge in the network (Friedman et al., 2000). The sampling procedure follows the Metropolis-Hastings algorithm (Metropolis et al., 1953; Hastings, 1970) to perform state transitions of a Markov chain for network structures. At each state transition step, a new network structure
In the above equation, q(·|·), ql(·|·), and qk(·|·) are proposal probabilities for network structures, direct link weights, and ordering weights, respectively. To improve the MCMC convergence, we divide each transition into the following three separate steps (Husmeier and Werhli, 2007).
1. Sample the structure G with weights ωl and ωk fixed. 2. Sample the energy weight ωl with ωk and G fixed. 3. Sample the energy weight ωk with ωl and G fixed.
In the present study, we define the proposal probability of a new network as an inverse of the valid update number of the old network and assume both ωl and ωk follow a uniform distribution Uniform(0, 30), where a new weight value is proposed uniformly from an interval of length 6 and centered at the old value. The respective sampling probabilities R1, R2, and R3 for the above three steps are:
We set the burn-in iteration number of the MCMC to 5 × 104 and sample one network structure reached by the MCMC every 100 iterations to avoid structure correlations. The MCMC procedure is stopped when it converges or reaches 106 steps. We test the convergence of the MCMC procedure by carrying out two independent MCMC simulations in parallel chains and claim that the convergence is reached if and only if the two chains output consistent marginal posterior probabilities for all the edges (Werhli et al., 2006). The posterior probability of each edge is computed as the ratio of the number of structures containing the edge to the total number of structures sampled.
3. Data And Prior Knowledge For The Model
We introduce in this section how the synthetic dataset and real biological dataset are generated. Both datasets are used together with artificially or automatically generated prior knowledge in model-learning experiments to evaluate the model performance.
3.1. Synthetic data with artificial prior knowledge
In the present study, we use a subset of the ALARM (A Logical Alarm Reduction Mechanism) network (Beinlich et al., 1989), which is composed of 11 discrete variables and 14 directed edges as shown in Figure 1a, to generate a synthetic dataset. The conditional probability tables of all the variables in the graph are integrated from the original ALARM network definition. After data generation, we introduce noise into the data by randomly changing each node's value with a fixed probability. The resulting data consists of 100 datasets, and each dataset contains the expression levels for all the variables, among which 20% are configured to be random noise. We generate prior knowledge by randomly picking 50% direct links and various amounts of orderings from the structure given in Figure 1a. The data and prior knowledge are then used to test the model performance. This procedure is repeated multiple times to examine the general effects of prior knowledge on model performance.
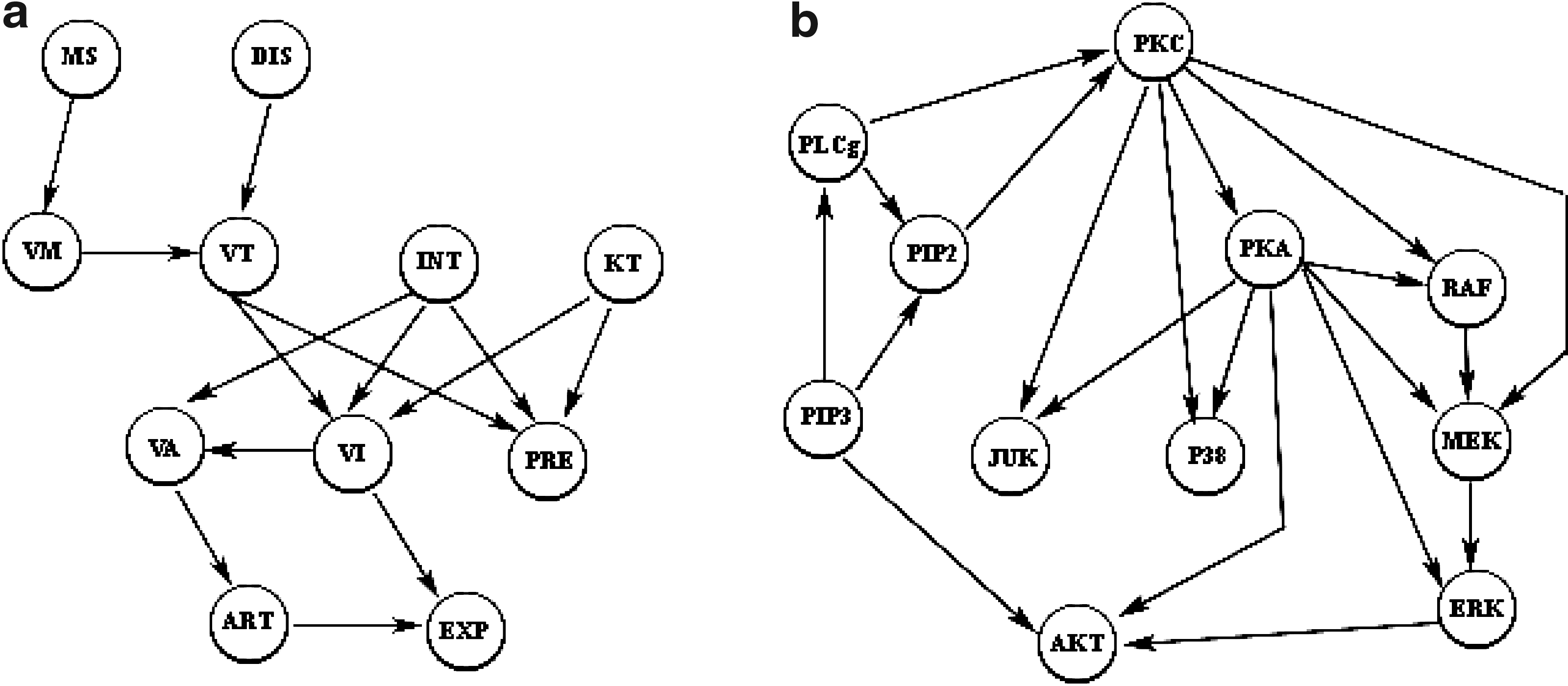
True network structures:
3.2. Real biological data with artificial prior knowledge
We also use the biological data for the RAF signaling pathway, whose schematic pathway structure is shown in Figure 1b. This data is from an intracellular multicolor flow cytometry experiment described in Sachs et al. (2005). In this experiment, quantities of all 11 phosphorylated proteins and phospholipids from the RAF signaling pathway are detected simultaneously under different perturbation conditions.
The data is discretized following an information-preserving discretization method developed by Hartemink (2001), which takes into account variable correlations. The final data we produced consists of 100 datasets in which each contains expression levels for all the molecules. A similar approach as described in Section 3.1 is used on the baseline network structure shown in Figure 1b to derive the prior knowledge for evaluating our model performance.
3.3. Prior knowledge derived from public databases
In both previous cases, generation of the prior knowledge depends on a known network structure. This is reasonable for evaluation purposes. However, a different approach is necessary for model-learning studies in which the network structure itself is aimed to be resolved. To address this issue, we devised an approach to identify prior knowledge regarding direct molecular links and orderings from Kyoto Encyclopedia of Genes and Genomes (KEGG) pathways and Gene Ontology (GO) annotation databases.
We retrieve direct links prior knowledge by searching interactions between each pair of molecules against the total 201 biological pathways in KEGG database. We assign the prior probability for an interaction as 0.5 if it is not identified in the database, or as
Ordering relations can also be derived from KEGG in a similar manner as discussed above. However, a problem with this approach is that the ordering relationships from KEGG may make sense only in some specific biological contexts and not necessarily in the network that one is interested in constructing. To address this concern, we apply a key helpful observation about molecular ordering; that is, biological signal transduction will, in general, favor a direction from one cellular component to another. For example, in a signal transduction pathway, information is more likely to transfer from a membrane-bound receptor to a transcription factor, which is located in cytoplasm and/or nucleus rather than the other way around. Based on this observation, we design a procedure called ordering from GO annotation and pathways (OGAP) to derive molecular orderings in a biological network. Essentially, this procedure first derives ordering relations of cellular components in biological networks, and then uses this information together with GO annotation of each molecule to find molecular orderings. The specifics of this procedure are presented as pseudo-code in Figure 2.

The pseudo-code of the OGAP algorithm.
The OGAP procedure consists of three steps. The first step, Correlation, identifies cellular component pairs that tend to coexist in the same biological pathway. The second step, AnnotationOrder, computes the ordering for each pair of cellular components that pass the test in the first step. Finally, the third step, ProteinOrder, uses the annotation ordering information to derive the probabilities of molecular ordering relations.
We applied the OGAP procedure to all the protein pairs in human KEGG pathways and found out 5% of them have ordering probabilities larger than 0.9. Using this as the threshold, we identified totally 11 protein pairs from the RAF signaling pathway showing ordering relations, as listed in Table 1. Comparing them with the pathway shown in Figure 1b, we can see that 9 out of 11 orderings are consistent with the pathway structure, 1 contradicts, and 1 is missing. The probability values in Table 1 are used in Equation (1) to compute the prior probability of a given network structure.
4. Results
4.1. Model learning with synthetic data
We first examine the performance of our Bayesian network model on the synthetic data and artificial prior knowledge introduced in Section 3.1. In this study, we integrate ≤20% (low), 20%–60% (medium), or ≥60% (high) of ordering relations from Figure 1a as prior knowledge into our Bayesian network model. Figure 3 shows the receiver operating characteristic (ROC) curves from all the model-learning outcomes, where each curve is an average of model outputs from 10 experiments. ROC curves plot true positive rate (i.e.,
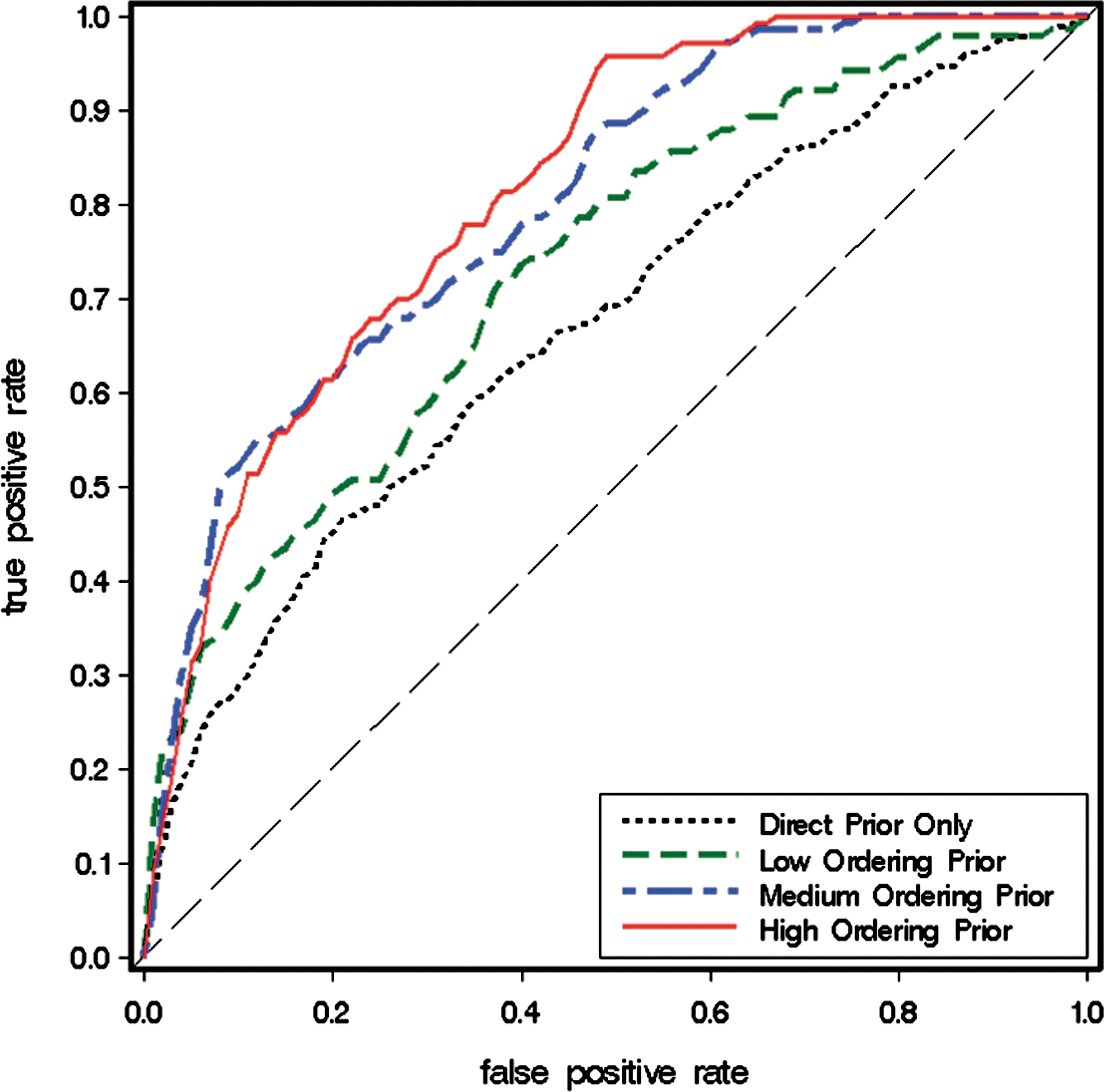
ROC curves of Bayesian network models' learning results under different settings.
Figure 3 shows that when ordering relations are included into the model learning, the Bayesian network model performs significantly better, as shown by the larger area under the ROC and the steeper slope at the left side of the curve. Furthermore, when the quantity of the ordering relations continuously increases, the model performance also keeps improving until it reaches a saturation point. This makes sense because the effect of prior knowledge will have a limit. For example, if the prior knowledge already contains orderings from A to B and B to C, then the ordering from A to C is redundant and adding it to the model will have little effect.
In addition to the average comparison results shown in Figure 3, we also carried out pairwise comparisons between two models with the same data, making one model trained with only direct-edge prior knowledge and the other with additional ordering knowledge beyond direct-edge prior knowledge. The outputs from the two models are compared by their differences in areas under ROC curves (AUC). The results are summarized in a bar chart with 95% confidence interval, as shown in Figure 4. The figure also suggests that addition of prior ordering knowledge would lead to a better model performance, but its effects would be saturated if prior knowledge is continuously added.
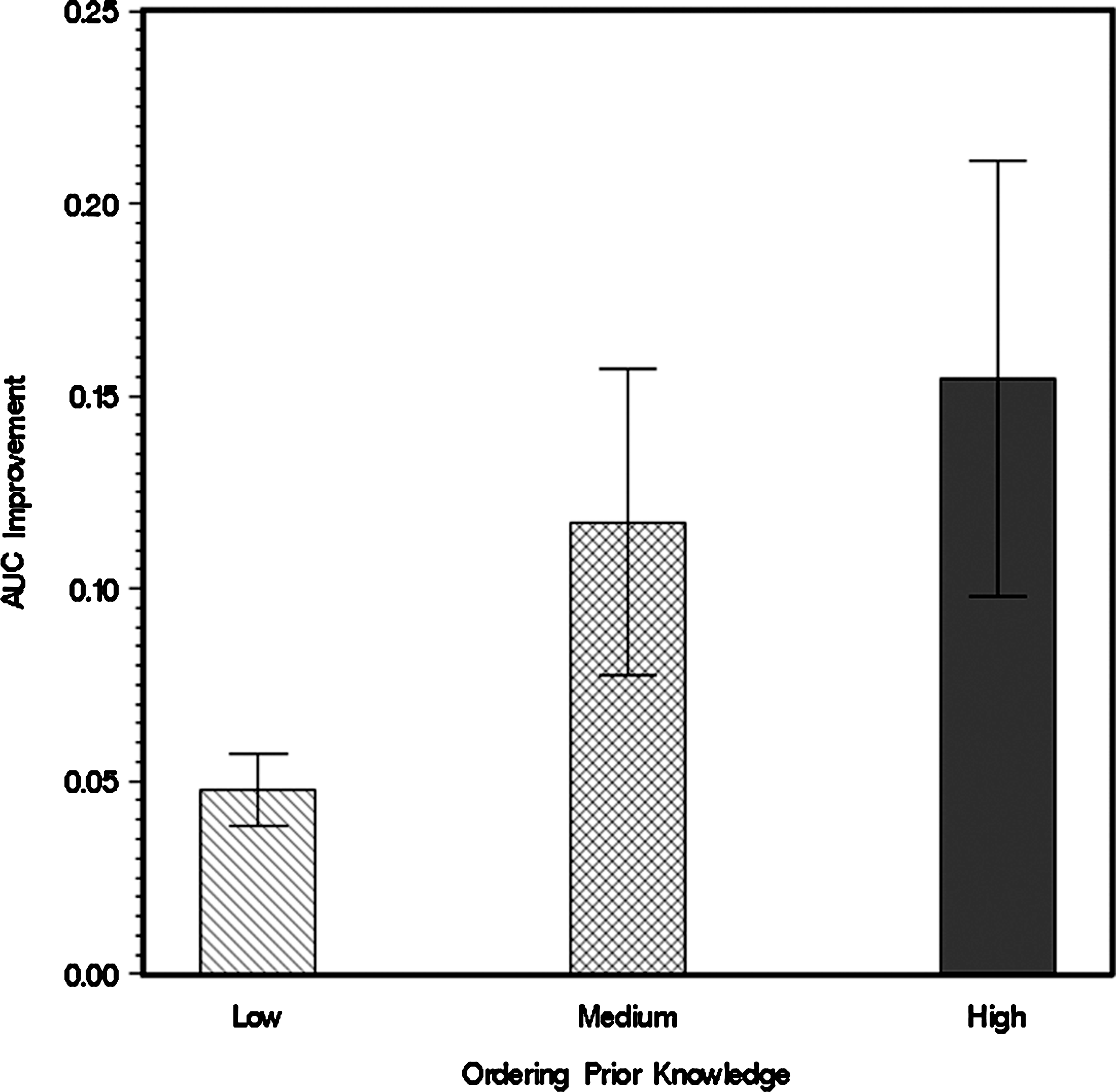
AUC of Bayesian network models with different abundance of ordering prior knowledge.
4.2. Model learning with real biological data
We ran our Bayesian network models on the biological data from the RAF signaling pathway introduced in Section 3.2. Again, we carried out pairwise tests between models with or without randomly picked orderings from the signal transduction pathway, given the same biological data and a fixed set of direct-link prior knowledge. The AUC improvement of their ROC curves are plotted against the quantity of ordering relations, as shown in Figure 5a.
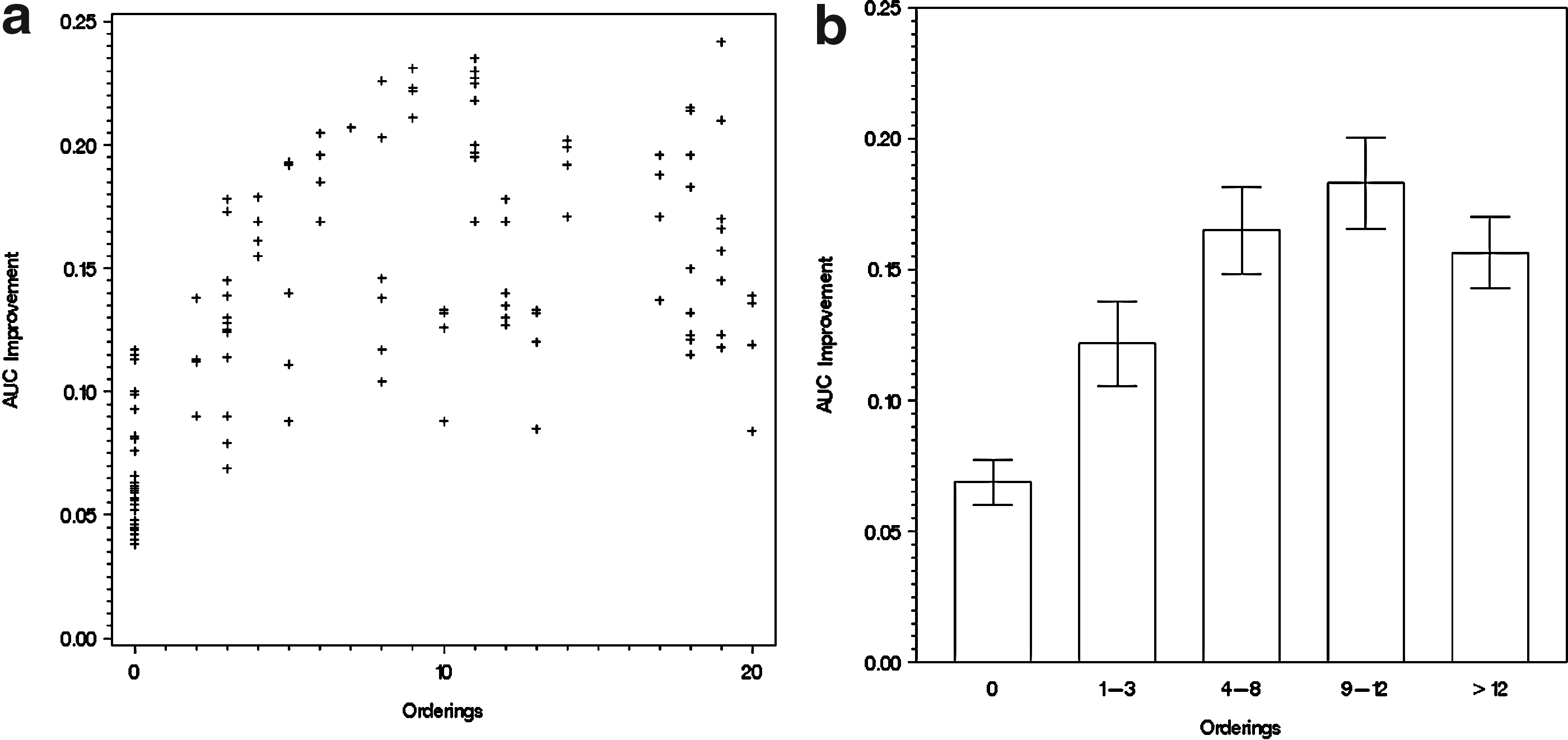
AUC improvement given a specific local priori. (
The scatter plot in Figure 5a shows a linear relationship between the AUC improvement and the number of ordering relations when the latter is at a lower level. However, when more ordering relations are supplied into the model, the improvement is saturated, just like Figure 4 with the synthetic data. This pattern can also be seen clearly in Figure 5b, in which all the crosses in Figure 5a are put into different bins for different quantity of ordering relations. In Figure 5a and b, the improvement at x = 0 (i.e., no ordering relations provided) comes from orderings derived from existing direct links. For example, direct links from A to B and B to C imply an ordering from A to C.
Next, we examine some particular network structures generated by the Bayesian network model. Figure 6 shows two specific network reconstruction results—6a from the model with only direct-link prior knowledge and 6b from the model with additional ordering prior knowledge. We recover, in both cases, the network structures with 90% specificities. It can be seen that with integration of ordering prior knowledge, the Bayesian network model recovers 75% true positive edges (shown by solid arrows) in the signaling pathway, while without that prior knowledge, the percentage drops to 40%. The edges in both networks are color coded according to their consistencies with the RAF signaling pathway. Green, red, and yellow indicate consistent, contradictory, and missing relations in the known network structure, respectively. The results in Figure 6 illustrate that the integration of ordering prior knowledge can help the Bayesian network model recover more true edges and less false edges.
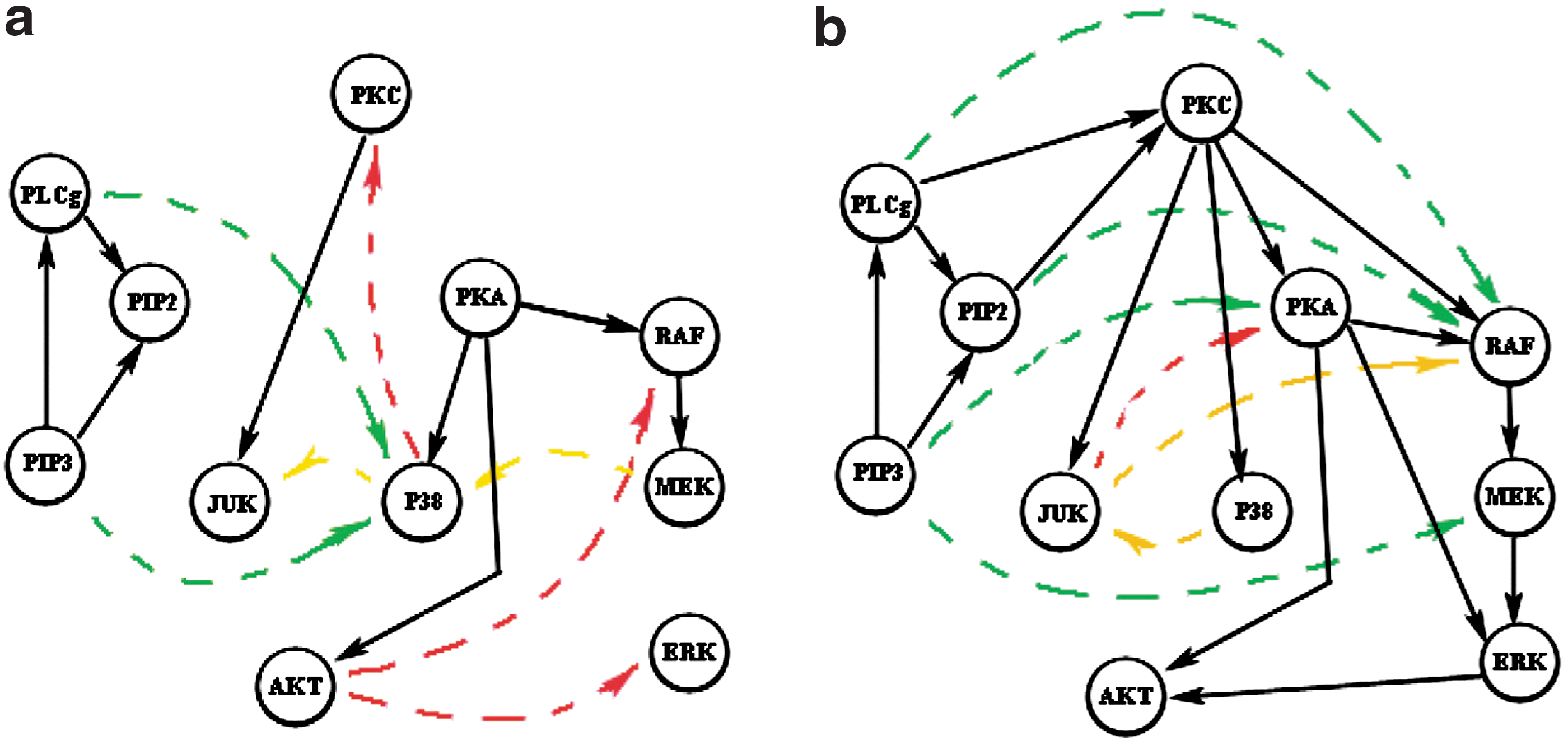
RAF signaling pathway reconstruction. (
Finally, we discuss the results of using both the flow cytometry data for RAF signaling pathway and the prior knowledge automatically generated from the OGAP process introduced in Section 3.3. Figure 7a shows the average ROC curves from 10 model-learning results. In the figure, we can see that the integration of extra ordering prior knowledge clearly improves the model performance. Figure 7b shows a bar chart of the AUC of ROC curves, which also shows a significant improvement in AUC with the integration of ordering prior knowledge.
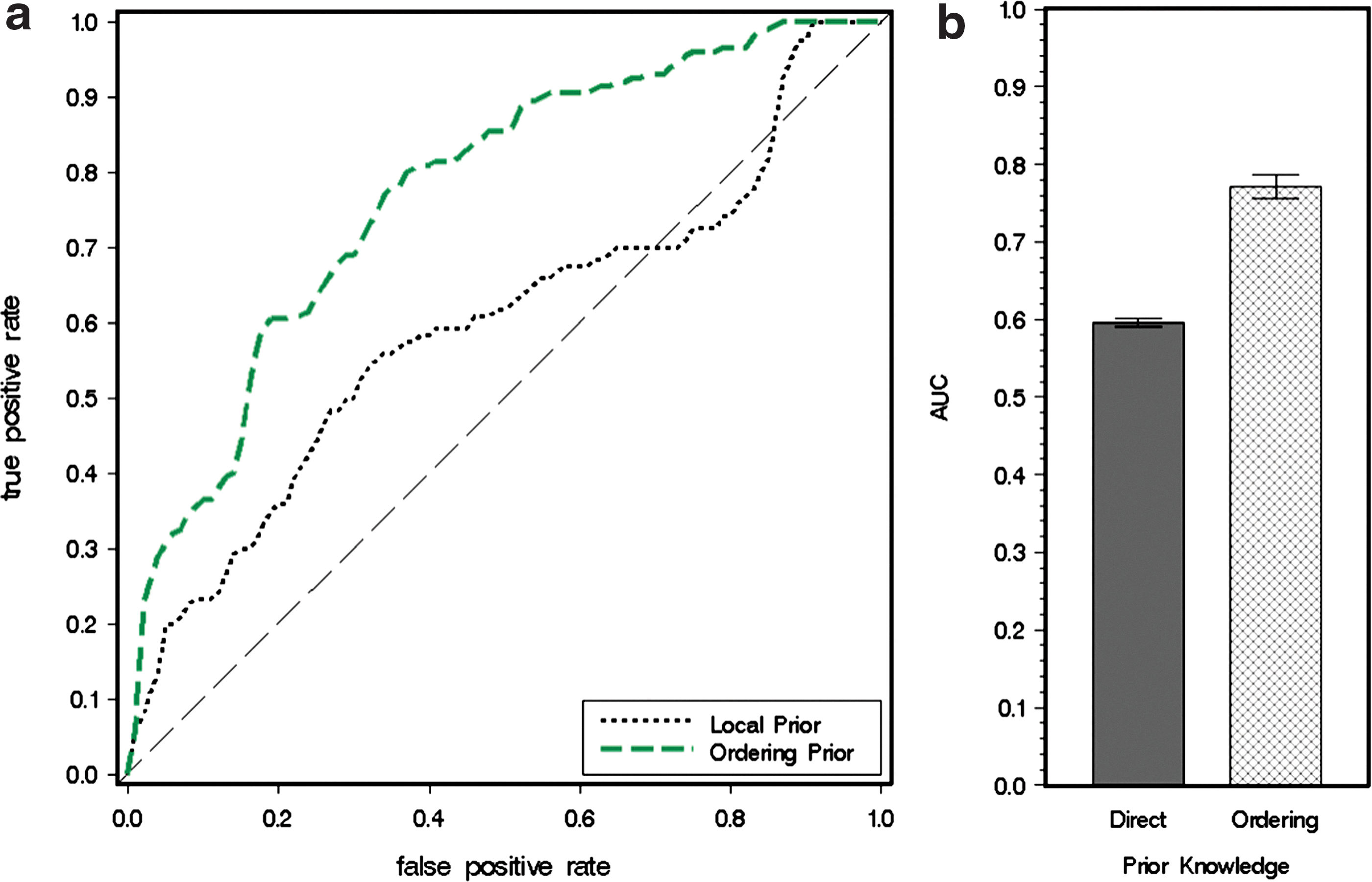
Model learning results with RAF data and automatically generated prior knowledge. (
5. Conclusions
In the present study, we examined the effects of incorporating ordering prior knowledge on reconstructing a biological network with Bayesian network models. Two contributions of this work are (i) the approach that outlines how to explicitly integrate both direct links and ordering relations as prior knowledge into Bayesian network models, and (ii) the OGAP method that automatically derives ordering relations among biological molecules by analyzing their biological annotations.
In regard to the Bayesian network model, we proposed and demonstrated that the reverse engineering of biological network structures can be improved by integrating direct links and indirect ordering relations known a priori. Each type of prior knowledge is assigned random weights so that the model can adapt itself automatically with given prior knowledge and data. We carried out computational experiments evaluating our methods with both synthetic data and real biological data. We showed that the integration of ordering prior knowledge can significantly improve the sensitivity and specificity of the Bayesian network model and also the fact that the degree of improvement is correlated with the abundance of ordering relations integrated into the model.
In regard to the OGAP method, we aimed to show that the method can derive biological molecule orderings from knowledge resources such as KEGG and GO annotation. Specifically, the orderings of molecules are inferred from their cellular component information in GO annotations and the pathway structures from the KEGG database. We applied this approach to a real biological signaling network and have demonstrated that the method can recover ordering information with reasonable sensitivity and high specificity. This automatically mined information was then used in reverse engineering of a network structure, and we showed that application of such derived information can indeed result in a significant improvement in model learning.
Footnotes
Acknowledgment
This work was supported in part by a grant from NIH/NIGMS, grant no P20 GM65764-04. The authors also thank Dr. David Rowe, Dr. Lynn Kuo, and Dr. Ion Mandoiu for insightful discussions.
Disclosure Statement
The authors declare no competing financial interests exist.