This work revisits the classic problem of coverage in genomic shotgun assembly (the “Lander-Waterman statistics”). A novel formulation, based on the analysis of an autonomous Markov automaton, is presented, and two main conclusions are derived. The first is an evaluation of the minimum multiplicity (“coverage”) required to achieve uninterrupted covering (one single contig) with a prescribed confidence level. The second is a detailed analysis of the effect of replacing the hypothesis of fixed-length genomic fragments with that of an arbitrary distribution of lengths over a finite interval.
1. Preliminaries
This work addresses a classical problem in computational genomics: the assembly of a genomic sequence by merging together a collection of reliably overlapping sequence fragments (hereafter denoted segments). This feature is typical of both traditional shotgun assembly and of modern short-read sequencing. The objective is the determination of the “coverage” c required either to reconstruct the original sequence with no interruption (with a given confidence level P), or to estimate the resulting number of isolated uninterrupted intervals, originally denoted “islands” or “contigs” (Arratia et al., 1991; Lander and Waterman, 1998; Waterman, 1995). Coverage is defined as the total length of the segments used by the process divided by the length G of the genomic sequence.
The standard approach, commonly referred to as the Lander-Waterman statistics (Lander and Waterman, 1988), evaluates the number ν of uninterrupted intervals (called “contigs” in current genomic parlance) resulting from the collection of segments. Their analysis, and subsequent follow-ups (Arratia et al., 1991; Waterman, 1995), model the occurrences of the (beginnings of) the segments as a Poisson process along the genome and obtain a number of significant results concerning average contig length and number of contigs, providing the practitioner with very useful guidelines.
Although the traditional Poisson modeling is an effective and analytically powerful methodology, its continuous nature conceals the discrete structure of the underlying physical process, since each segment consists of an integer number of bases. In fact, the problem can also be cast in purely geometric terms: A random segment [x1, x2], with integer x1 and x2, is obtained by drawing integer x1 uniformly at random in some interval [1, G] and selecting x2 as x2 = x1 + L′, where integer L′ is in turn drawn from a distribution of mean value L.
This note presents an alternative approach to the genome coverage problem, based on the discrete nature of the genome and of its segments. The process is therefore viewed as the time-evolution of an autonomous probabilistic automaton. The analysis rediscovers the classical Lander-Waterman estimate of the average contig length for given genome length G, coverage c, and fixed segment length L. In addition, still under the hypothesis of fixed segment length, it characterizes the coverage needed to achieve uninterrupted cover of the genome with a prescribed confidence level P.
Finally, the discrete modeling can be naturally extended to the realistic case of variable segment length, under the hypothesis that the support of the distribution of the lengths be finite. To be noted is that such hypothesis is conceptually correct, because segments originate from a finite genome; morover, there may occasionally be practical interest in selecting a restricted range of segment lengths. The conclusion, previousy alluded to in Arratia et al. (1991) (Proposition 7, p. 812) under the Poisson modeling, is that there is always a precisely quantifiable, albeit minute, degradation going from fixed length to a nontrivial distribution with the same average length.
2. The case of constant segment length
We imagine scanning the genomic sequence from 1 to G in G consecutive time units. A generic segment [x1, x2] begins at (integer) time x1 and ends at (integer) time x2. In the interval [1, G], we study the evolution of a Markov model under the hypothesis of constant segment length L, which will be later relaxed.
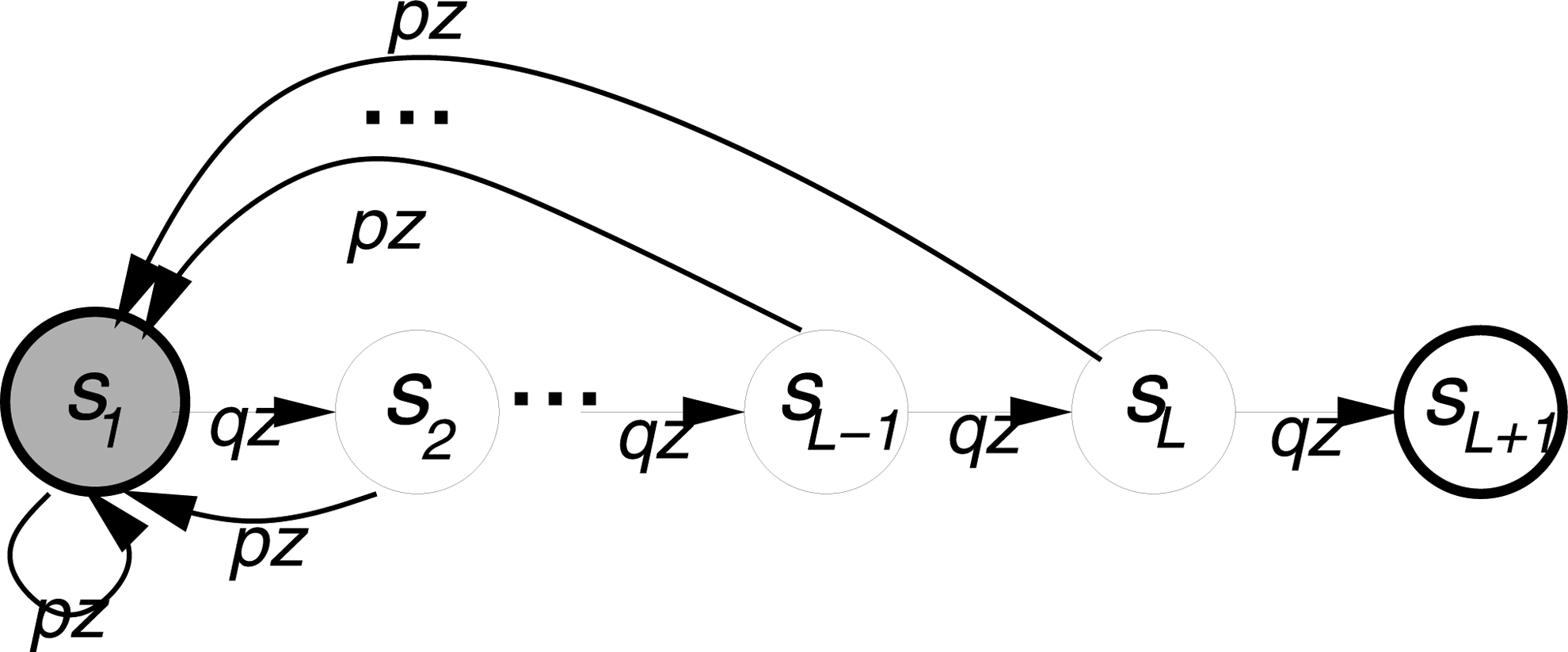
The Markov model is embodied by an automaton \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\cal A}$$\end{document} whose state diagram is given in Figure 1. The input to this automaton is binary, a 1 denoting a segment beginning (an “arrival,” with probability p = c/L, since there are about cG/L segments by hypothesis, and they are assumed to be placed uniformly and independently within the interval of length G) and a 0 the lack of it (with probability q = 1 − p).1
State diagram of automaton \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\cal A}$$\end{document}.
A contig is represented by a binary input string, starting with a 1, of the form \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$10^{r_1 - 1}10^{r_2 - 1}1 \ldots 10^{r_{h - 1} - 1} 10^{r_h - 1}$$\end{document}, where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$r_j \le L \ {\rm for} \ j = 1 , \ldots , h - 1$$\end{document} and rh = L + 1. The process is started by placing the automaton in state s1 (i.e., with probability 1; state s1 is the initial state and the reset state) and:
• Under input 0, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\cal A}$$\end{document} advances from si to si+1; under input 1, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\cal A}$$\end{document} reverts to state s1, so that a 1 (an arrival) acts as a “regenerating” event. If \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\cal A}$$\end{document} goes beyond state sL (i.e., it makes a transition under 0 to sL+1), then the contig terminates.
Let \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$r = r_1 + \cdots + r_h$$\end{document} be the length of the corresponding input string (i.e., of the contig). We wish to compute E[r].
In the state diagram of automaton \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\cal A}$$\end{document}, input label 1 is replaced by transition probability p and input label 0 by probability q = 1 − p. Moreover, the multiplicative label z has been added to each probability label, to denote a “one time-unit” transition. Note that in the diagram state s1 is displayed shaded, to denote the fact that it is the only one to which a backward transition may occur.
A path of length r > L from the initial state s1 to the final state sL+1 is described by some binary sequence of s 1's and r − s 0's corresponding to a degree-r monomial psqr−szr. Such path can be interpreted as transmitting probability psqr−s from s1 to sL+1 in r time units. The sum of the (countable) set of such monomials for all values of r can therefore be called the transmission function Q(z) associated with the state diagram of Figure 1. Note that function Q(z) is exactly the generating function of the probability mass function pr = Pr(path length = r).
Function Q(z) can be derived from the diagram of Figure 1 by interpreting it as a signal-flow-graph (Zadeh and Desoer, 1963), and by reducing it, one state at a time, applying repeatedly the standard signal-flow-graph reduction rule illustrated in Figure 2 below.
Signal-flow-graph reduction rule (the shaded state is eliminated).
The result of this process is the following expression:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}Q ( z ) = {\frac {( qz ) ^ {L } ( 1 - qz ) } {1 - z + pz ( qz ) ^ {L } } } \tag {1 } \end{align*}\end{document}
By a standard property of generating functions, the expected contig length E[r] is
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*} {\rm E } [ r ] = Q^ {\prime } ( 1 ) = {\frac {1 } {( 1 - p ) ^ {L } p } } - \frac {1 } {p } \tag {2 } \end{align*}\end{document}
Remark 1
If we add to E[r] the average value of a gap between consecutive contigs, which is easily found2 to be 1/p, we obtain that the average number \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\rm E}[\nu]$$\end{document} of contigs within the interval [1, G] is (since p = c/L)
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*} {\rm E } [ \nu ] = {\frac {G} {{\rm E} [r] + 1 / p}} = Gp ( 1 - p ) ^L = Gp \left( 1 - \frac {c } {L } \right) ^L \approx \frac {Gce^ {- c } } {L } \end{align*}\end{document}
which is the classical result of Lander-Waterman.
Parameter \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\rm E}[\nu]$$\end{document} provides a useful measure of the adequacy of the adopted coverage. However, we now seek a more significant measure.
The right-hand side of Equation (1) can be used to derive an expression for pr, since
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}Q ( z ) = {\frac {( qz ) ^ {L } ( 1 - qz ) } {1 - z + pz ( qz ) ^ {L } } } = ( qz ) ^ {L } ( 1 - qz ) \cdot {\rm MacLaurin } \left( {\frac {1 } {1 - z + pz ( qz ) ^ {L } } } \right)\end{align*}\end{document}
The following conclusions can be derived from this expression:
1. The first L − 1 terms \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$p_1 , \ldots , p_{L - 1}$$\end{document} of the probability mass function are 0 and pL = qL;
2. It can be verified analytically that \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$p_{L + 1} , \ldots , p_{2L}$$\end{document} have constant value pqL. This fact can also be justified combinatorially, since the binary input sequences leading to sL+1 are, in regular-expression notation, the set 1(0 + 1)j−L−110L for \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$j = L + 1 , \ldots , 2L$$\end{document}.
3. For j > 2L, consider the set of input binary sequences leading to sL+1 in j steps, described by \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$1{\cal R}_j 10^L$$\end{document}, where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\cal R}_j$$\end{document} is a regular expression (such as (0 + 1)j−L−1 in number 2 above). Set \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\cal R}_j$$\end{document} is obtained from \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\cal R}_{j - 1}$$\end{document} by extending each of its sequences with either 0 or 1, except those ending in 10L, which are in turn described by the expression \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\cal R}_{j - L}10^{L}$$\end{document}. Since \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\rm Pr} ( {\cal R}_{j - 1} ( 0 + 1 ) ) = {\rm Pr} ( {\cal R}_{j - 1} )$$\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\rm Pr} ( {\cal R}_{j - L}10^{L} ) = {\rm Pr} ( {\cal R}_{j - L}) pq^L$$\end{document}, we have the recurrence
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}p_j = p_{j - 1} - pq^Lp_{j - L}\end{align*}\end{document}
whose characteristic equation is D(z) = zL − zL−1 + pqL = 0 [notice that zLD(1/z) is the denominator of rational function Q(z)].
4. Therefore, for moderately large j, pj decreases geometrically with rate α, where α < 1 is the largest positive root of D(z) = 0. An excellent approximation of α is obtained by noting that D(1) = pqL is very close to 0 and that D′(1) = 1, so that α≈1 − pqL.
With this background, we shall adopt the following approximation3 (which yields a legitimate probability mass function):
Using the introduced approximation, the analytical form of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$p^*_{L + j}$$\end{document} (a geometric distribution for j ≥ 1) allows us to evaluate \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$\sum\nolimits_{j = J}^{K}p^*_j$$\end{document} for arbitrary J, K. In particular, we may obtain a reliable estimate of
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}\sum_{j = G}^{\infty}p^*_j\end{align*}\end{document}
that is, the probability that the automaton's path extends beyond length G, that is, the probabilility of uninterrupted coverage of [1, G]. The latter is certainly a more significant parameter than \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\rm E} [\nu]$$\end{document}. In fact, for any chosen confidence level P ≤ 1, the condition
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}\sum_{j = G}^{\infty}p^*_j \ge P\end{align*}\end{document}
allows the evaluation of the required coverage c.
Remark 2
For the interested reader, the coverage required to achieve a single contig with confidence P can be estimated as follows:
From the definition of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$p_j^*$$\end{document} we obtain:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}\sum_ {j = G } ^ {\infty } p^*_j = \sum_ {i = G - L } ^ {\infty } p^*_ {L + i } = p q^L ( 1 - q^L ) \sum_ {i = G - L } ^ {\infty } \alpha^ {i - 1 } = \frac {pq^L ( 1 - q^L ) } {\alpha ( 1 - \alpha ) } \alpha^ {G - L } = \frac {1 - q^L } {1 - pq^L } \alpha^ {G - L } \end{align*}\end{document}
It can be verified that, for realistic values of c and L, (1 − qL)/(1 − pqL)≈1. Then, making repeated use of limn→∞(1 + a/n)n = ea, we obtain
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}\alpha^{G - L} \approx e^{- pq^L ( G - L ) } \approx e^{- p ( G - L ) e^{- pL}} \ge P ,\end{align*}\end{document}
whence p ≥ (ln p(G − L) − ln ln(1/P))/L. Recalling that p = c/L, we finally have
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}c \ge \ln \frac {c ( G - L ) } {L } + \ln \frac {1 } {\ln ( 1 / P ) } \end{align*}\end{document}
The second term represents the increase of coverage over the Lander-Waterman result based on \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\rm E} [\nu]=1$$\end{document}.
3. The case of variable segment length
Capitalizing on the results obtained for constant length, we wish to characterize the length L* of a constant-length process behaving like a given variable-length process. We assume that the segment length is a random variable defined on an interval [L − n + 1, L]. The analysis is summarized by the following theorem:
Theorem 1
If the segment lengths are restricted to an interval [L − n + 1, L], with mean value\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$L - \mu + 1 \ ( \mu \in [ 1 , n ] )$$\end{document}, the covering process is analogous to a fixed-length process of length L* = L −μ + 1 − γ, where the correction γ satisfies the bounds\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}0 < \gamma < \frac {( n - 1 ) c } {8L } \quad for \ n > 1\end{align*}\end{document}
and γ = 0 for n = 1.
Remark 3
To estimate γ in the context of genomic analysis, assume, for example, L = 104, n = 5·103, c = 30. This choice yields γ < 1.875 ≪ n. Theorem 1 shows that the usual choice L* = E[L] (see, e.g., Ewens and Grant, 2005, Chapter 5.1), although theoretically inaccurate, is practically quite adequate.
A segment of length L − j + 1 is to be viewed as a pair of integers [j, L], that is, with its left extreme at position j and its right extreme at position L. Therefore, the sample space of the segments is the interval \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$1 , 2 \ldots , n$$\end{document}, and we let πj denote the probability of a segment of length L − j + 1.
Again, the process is described by an automaton \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\cal A}^*$$\end{document} with states \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$s_1 , s_2 , \ldots , s_{L + 1}$$\end{document} whose state diagram is given in Figure 3. The meaning of state sj, for \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$j \in [ 1 , L ]$$\end{document}, is that after L − j + 1 steps (transitions) the current segment will terminate.
State diagram of automaton \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\cal A}^*$$\end{document}.
The input to \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\cal A}^*$$\end{document} is binary, with the same meaning as for automaton \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\cal A}$$\end{document}, the only difference being that the segment length is now a random variable rather than a constant L. Structurally, whereas in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\cal A}$$\end{document}, only state s1 was the destination of “backward” transitions from all automaton states, in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\cal A}^*$$\end{document} state si, for \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$i = 1 , 2 , \ldots , n$$\end{document}, is the destination of backward transitions from each state sj with j ≥ i. For simplicity, only “forward” transitions from sj to sj+1 (j ≥ n) are labeled in Figure 3; the probability of a backward transition to state \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$s_{i} \ ( i = 1 , \ldots , n )$$\end{document} is the probability of a segment of length i, and the forward transition probabilities of states \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$s_1 , \ldots , s_{n - 1}$$\end{document} are described below.
A contig is represented by a binary string as in the preceding constant-length case. The process is initialized by placing the automaton in state si with probability \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$\pi_i \ ( i = 1 , \ldots , n )$$\end{document}. The one-step transitions occur according to the following rules:
• Under input 0 (i.e., in the absence of an event corresponding to a segment beginning), \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\cal A}^*$$\end{document} advances from si to si+1;
• Under input 1 (i.e., when a segment beginning occurs), the same forward transition from si to si+1 occurs if the new segment is fully covered by the current segment, that is, if the new segment has length L − j for j > i, otherwise \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\cal A}^*$$\end{document} reverts to state sj. This observation is summarized by saying that, since 1 − q is the probability that no segment begins (at the generic time unit of the process), the probability of a transition from state si to state si+1 has value
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}q_i = q + ( 1 - q ) \left( 1 - \sum_{h = 1}^i \pi_h \right) = 1 - ( 1 - q ) \sum_{h = 1}^i \pi_h \tag{3}\end{align*}\end{document}
• If \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\cal A}^*$$\end{document} goes beyond state sL, that is, it makes a transition under 0 to sL+1, then the process terminates.
Note that in the diagram of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\cal A}^*$$\end{document} (Fig. 3) states \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$s_1 , \ldots , s_n$$\end{document} are shown shaded, again to evidence the fact that they can be reached by backward transitions. Thus, the previously analyzed automaton \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\cal A}$$\end{document} can be viewed as a special case of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${\cal A}^*$$\end{document} for n = 1.
To establish the equivalence with a fixed-length process, rather than focusing on the probability of contig termination, we concentrate on the probability of visiting the automaton states. Specifically, we denote by fi the normalized frequency of the event that the process is in state si. In other words, if an experiment of the random walk consists of K steps before reaching the absorbing state sL+1, and in this process state si is visited ni times, then in this experiment the normalized frequency of si is ni/K. We now interpret fi as the average of such measured frequencies over a very large number of experiments, that is, we assimilate it to a discrete probability.
We now claim:
Theorem 2
The probability mass function\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$( f_j \mid j = 1 , 2 , \ldots , L )$$\end{document}is given by\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}f_{j} = ( 1 - q ) \left( \sum_{i = 1}^j \pi_i \right) \Pi_{h = 1}^{j - 1} q_h \tag{4}\end{align*}\end{document}
(with the convention that\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$\Pi_{h = 1}^{0}q_h = 1$$\end{document}).
Proof
By induction on j. We wish to prove the following two statements:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}f_{j} = ( 1 - q ) \left( \sum_{i = 1}^j \pi_i \right) \Pi_{h = 1}^{j - 1} q_h \ {\rm and} \ 1 - \sum_{h = 1}^j f_h = q_1q_2 \ldots q_j\end{align*}\end{document}
The basis is readily established for j = 1. In fact, state s1 is visited exactly when a segment of length L begins. Since the product \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$\Pi_{h = 1}^{0} q_h = 1$$\end{document} by convention, then
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}f_{1} = ( 1 - q ) \pi_1 \ {\rm and} \ 1 - f_1 = 1 - ( 1 - q ) \pi_1 = q_1\end{align*}\end{document}
Assume both statements true for i < j. State j is visited either when
1. the automaton transitions from state sj−1 to state sj (an event of probability fj−1qj−1), or when
2. a segment of length L − j begins (an event of probability (1 − q)πj) and the process is visiting a state sh for h ≥ j (whose probability is \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$1 - \sum\nolimits_{h = 1}^{j - 1}f_h$$\end{document}).
This is summarized as
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}f_{j} = f_{j - 1}q_{j - 1} + ( 1 - q ) \pi_j \left( 1 - \sum_{h = 1}^{j - 1}f_h \right)\end{align*}\end{document}
Our objective is now to construct a “concentrated” process (i.e., a process whose segments have all identical length \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$L^* \in [ L ^\prime , L ] )$$\end{document} equivalent to the one just described, in the sense that in state sj for j ≥ n the two processes are indistinguishable in the following sense. If we denote the normalized frequencies (probabilities) of the concentrated process with the notation \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$f_j^*$$\end{document}, then for j ≥ n, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$f_j^* = f_j$$\end{document}. To achieve this objective, the following two conditions must be satisfied (we assume n > 1, since the case n = 1 is trivial, because it corresponds itself to a concentrated process):
1. Since only the beginning of a segment of length L* can bring the automaton to state \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$s_{L - L^* + 1}$$\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}f^*_{L - L^* + 1} = 1 - q\end{align*}\end{document}
This relation4 is the key of our analysis, and it easily lends itself to a numerical evaluation of the parameter L* for any given distribution \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$\pi_1 , \ldots , \pi_n$$\end{document}.
Letting \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$\mu = \sum\nolimits_{i = 1}^n i \pi_i$$\end{document}, we wish to show that, in general, L* deviates only minutely from the (mean) value L − μ + 1. First, we note:
Lemma 1
L* is a downward-convex function of the distribution\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$( \pi_1 , \ldots , \pi_n )$$\end{document}.
as a consequence of the inequality between the arithmetic and the geometric means. ■
Theorem 3
For given mean μ, the distribution\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$( \pi_1 , \ldots , \pi_n )$$\end{document}, which minimizes L* is\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}\pi_1 = \frac {n - \mu } {n - 1 } , \ \pi_j = 0 \
for \ j = 2 , \ldots , n - 1 , \ and \ \pi_n = \frac {\mu - 1 }
{n - 1 } \end{align*}\end{document}
Proof
By Lemma 1, we seek a distribution \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$\pi_1 , \ldots , \pi_n$$\end{document}, which minimizes \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$- \sum\nolimits_{h = 1}^{n - 1} \ln ( q_h )$$\end{document}, which is a function of the variables \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$\pi_1 , \ldots , \pi_n$$\end{document}. We have a situation of constrained optimization, with constraints
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}\sum_{i = 1}^n \pi_i \ {\rm and} \ \sum_{i = 1}^n i \pi_i = \mu\end{align*}\end{document}
where we let \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$g_h = - ( 1 - q ) / ( 1 - ( 1 - q ) \sum\nolimits_{k = 1}^h \pi_k )$$\end{document}. We picture these equalities as written on n consecutive lines. Adding, side by side, line s and s + 2 and subtracting twice line s + 1, we obtain the n − 2 equations
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}g_s = g_{s + 1} \quad {\rm for} \ s = 1 , 2 \ldots , n - 2\end{align*}\end{document}
or πs = 0 for \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$s = 2 , \ldots , n - 1$$\end{document}. Therefore, we are left with π1 ≠ 0 and πn ≠ 0 leading to the system
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*} \pi_1 + \pi_n & = 1 \\ \pi_1 + n \pi_n & = \mu\end{align*}\end{document}
Using the distribution specified by Theorem 2, we obtain qh = 1 − (1 − q)(n − μ)/(n − 1) for \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$h = 1 , \ldots , n - 1$$\end{document}, so that plugging this into Equation (5) we obtain
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}L^* \ge L - n + 1 + ( n - 1 ) {\frac {\ln ( 1 - ( 1 - q ) \frac {n - \mu } {n - 1 } ) } {\ln q } } \end{align*}\end{document}
The sum of the first two terms of its Taylor expansion provides an excellent approximation to ln(1 − Ax)/ ln(1 − x) for real A > 0, that is,
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*} {\frac {\ln ( 1 - Ax ) } {\ln ( 1 - x ) } } \simeq A + \frac {A^2 - A } {2 } x.\end{align*}\end{document}
Expressing q as (1 − p) and using this approximation we obtain
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*} L^* & \ge L - n + 1 + ( n - 1 ) {\frac {\ln ( 1 - p \frac {n - \mu } {n - 1 } ) } {\ln ( 1 - p ) } } \\ & \approx L - n + 1 + ( n - 1 ) \left( \frac {n - \mu } {n - 1 } - \frac {1 } {2 } \frac {n - \mu } {n - 1 } \frac {\mu - 1 } {n - 1 } p \right) \\ & = L - n + 1 + n - \mu - ( n - \mu ) \frac {\mu - 1 } {2 ( n - 1 ) } p \\ & = L - \mu + 1 - {\frac {( n - \mu ) ( \mu - 1 ) } {2 ( n - 1 ) } } p \ge L - \mu + 1 - \frac {( n - 1 ) p } {8 } \end{align*}\end{document}
so that the minute quantity (n − 1)p/8 = (n − 1)c/8L is an upper bound to the decrement with respect to the mean L − μ + 1, for any distribution with given n and p.
Footnotes
Acknowledgments
Insightful suggestions of an anonymous referee are gratefully acknowledged.
Author Disclosure Statement
The author declares that no competing financial interests exist.
1
In this modeling, L denotes the effective length of the segment, i.e., the actual segment length decreased by a suitable overlap, needed in genomic applications to ensure the verifiability of overlap.
2
Indeed, a gap of length k may be modeled as a binary sequence 00k−11 of probability qk−1p, since the initial 0 is deterministic. The generating function of the gap-length distribution is therefore P(z) = pz/(1 − qz), whence Q′(1) = p/(1 − q)2 = 1/p.
3
Note that the approximation corresponds to replacing in Q(z) the denominator (1 − z + pz(qz)L) with (1 − z + pzqL). To obtain a better appraisal of the approximation, it is straightforward to verify that the new value of E[r] exceeds by L the correct value, which is acceptable under the hypothesis G ≫ L.
4
Note that L* = L − n + 1 (the mean value) occurs exactly when qh = 1 for \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$h = 1 , \ldots , n - 1$$\end{document}. Referring to , this in turn occurs when πh = 0 for \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$h = 1 , \ldots , n - 1$$\end{document} and πn = 1 (i.e., we have a constant-length process).
References
1.
ArratiaR., LanderE.S., TavaréS., WatermanM.S.1991. Genomic mapping by anchoring random clones: a mathematical analysis. Genomics, 11:806–827.
2.
EwensW.J., GrantG.R.2005. Statistical Methods in Bioinformatics. An Introduction. Springer Verlag: Berlin/Heidelberg.
3.
LanderE.S., WatermanM.S.1988. Genomic mapping by fingerprinting random clones: a mathematical analysis. Genomics, 2:231–239.
4.
WatermanM.S.1995. Introduction to Computational Biology: Maps, Sequences and Genomes. CRC Press: Boca Raton, FL.
5.
ZadehL.A., DesoerC.A.1963. Linear System Theory: The State Space Approach. McGraw-Hill Book Company: New York.