
Abstract
Abstract
Scaffolding is an important subproblem in de novo genome assembly, in which mate pair data are used to construct a linear sequence of contigs separated by gaps. Here we present SLIQ, a set of simple linear inequalities derived from the geometry of contigs on the line that can be used to predict the relative positions and orientations of contigs from individual mate pair reads and thus produce a contig digraph. The SLIQ inequalities can also filter out unreliable mate pairs and can be used as a preprocessing step for any scaffolding algorithm. We tested the SLIQ inequalities on five real data sets ranging in complexity from simple bacterial genomes to complex mammalian genomes and compared the results to the majority voting procedure used by many other scaffolding algorithms. SLIQ predicted the relative positions and orientations of the contigs with high accuracy in all cases and gave more accurate position predictions than majority voting for complex genomes, in particular the human genome. Finally, we present a simple scaffolding algorithm that produces linear scaffolds given a contig digraph. We show that our algorithm is very efficient compared to other scaffolding algorithms while maintaining high accuracy in predicting both contig positions and orientations for real data sets.
1. Introduction
Computational genome assembly is typically performed in at least two stages—the contig building stage and the scaffolding stage. In this article we do not address the contig building problem but rather assume that we have access to a set of contigs produced by an independent algorithm. However, we discuss the relationship of the contig building and scaffolding stages later in the discussion. The scaffolding problem tries to string contigs into a chain such that the order of the contigs in the scaffold reflects their real order in the genome. For the scaffolding problem, the most popular strategy is to construct the contig graph in which nodes represent contigs and edges represent sets of mate pairs connecting two contigs (i.e., the two reads of the mate pair fall in the two different contigs). The edges are given weights equal to the number of mate pairs connecting the two contigs.
We then try to find a walk in the graph such that the minimum number of mate pairs are violated. A mate pair is violated when the contigs it is connecting do not have the relative orientation or position suggested by the mate pair. Just finding the optimal orientation assignment is reducible to the Maximum Cut problem, which is known to be NP-complete (Garey, 1979). Consequently, finding the optimal walk to get the optimal scaffolding is also NP-complete. The genome can (and often does) have repeated regions; e.g., approximately 50% of human genome is accounted for by repeats (Haubold and Wiehe, 2006). But the contig builder is likely to report one contig per repeated region. This repetitive structure of the genome makes scaffolding harder as it introduces loops and cycles in the contig graph. We also have false edges resulting from misassembly of reads into contigs. Unfortunately, the number of false edges is not negligible, and so, filtering them is a major preprocessing step.
A common procedure is to filter out unreliable edges by picking a small threshold (commonly 2–5) and removing all edges with weight less than that threshold. For the remaining edges, a majority vote is used to decide on the relative orientation and position of the contigs. This simple majority voting strategy is implemented in a number of commonly used assemblers and stand-alone scaffolders, including ARACHNE (Batzoglou et al., 2002), BAMBUS (Pop et al., 2004), SOPRA (Dayarian et al., 2010), and SOAPdenovo (Li et al., 2010), with various choices of threshold. Opera (Gao et al., 2011) and the Greedy Path-Merging algorithm (Huson et al., 2002) use a different strategy to bundle edges. Given a set of mate pairs connecting two contigs, these algorithms calculate the median and standard deviation of the insert lengths of the set of mate pairs and create a bundle using only mate pairs with insert length that are close to the median. ALLPATHS (Butler et al., 2008) and VELVET (Zerbino and Birney, 2008) do not build the contig graph and thus do not have a read-filtering step similar to the other assemblers mentioned. The majority voting procedure implicitly assumes that misleading mate pairs are random and independently generated and that majority voting should eliminate the problematic mate pairs. However, this assumption is often not true because of the complex repeat structure of large genomes, such as human.
In this article, we show that unreliable mate pairs can be reliably filtered using SLIQ, a set of simple linear inequalities derived from the geometry of contigs on the line. Thus, SLIQ produces a reduced subset of reliable mate pairs and thus a sparser graph, which results in a simpler optimization problem for the scaffolding algorithm. More importantly, SLIQ can be used to predict the relative positions and orientations of the contigs, yielding a directed contig graph. Our experiments show that both SLIQ and majority voting are very accurate at predicting relative orientations, but SLIQ is clearly more accurate at predicting relative positions for complex genomes.
The simplicity of SLIQ makes it very easy to integrate as a preprocessing step to any existing scaffolders, including recent scaffolders such as MIP scaffolder (Salmela et al., 2011), Bambus 2 (Koren et al., 2011), and SSPACE (Boetzer et al., 2011). To illustrate the effectiveness of SLIQ, we implemented a naive scaffolding algorithm that produces linear scaffolds from the contig digraph. We show that despite its simplicity, our naive scaffolder provides very accurate draft scaffolds, comparable to or improving upon the more complicated state of the art, very quickly. These scaffolds can either be output directly or used as reasonable starting points for further refinement with more complex scaffolding algorithms. An implementation of naive assembler using the inequalities is available online.
2. Algorithms
We begin with a high level outline of our algorithm for constructing a directed contig graph (Algorithm 1). The crux of the algorithm is SLIQ, a set of simple linear inequalities that are used to filter mate pairs and predict the relative position and orientation of contigs. In subsequent sections, we will present proofs for the SLIQ inequalities and a detailed version of the digraph construction algorithm (Algorithm 2). Finally, we will present a simple scaffolding algorithm (Algorithm 3) that uses the contig digraph to construct draft scaffolds. Throughout the article, we will abbreviate mate-pair reads as MPR.
Construct Contig Digraph (Outline)
2.1. Definitions and assumptions
For the sake of deriving the SLIQ inequalities, we assume that we know the position of the contigs on the reference genome. However, this information cancels out later on, which allows us to analyze the MPRs without access to prior contig position information. For the derivation, we also assume that all the contigs have the same orientation. Later, we will not need this information.
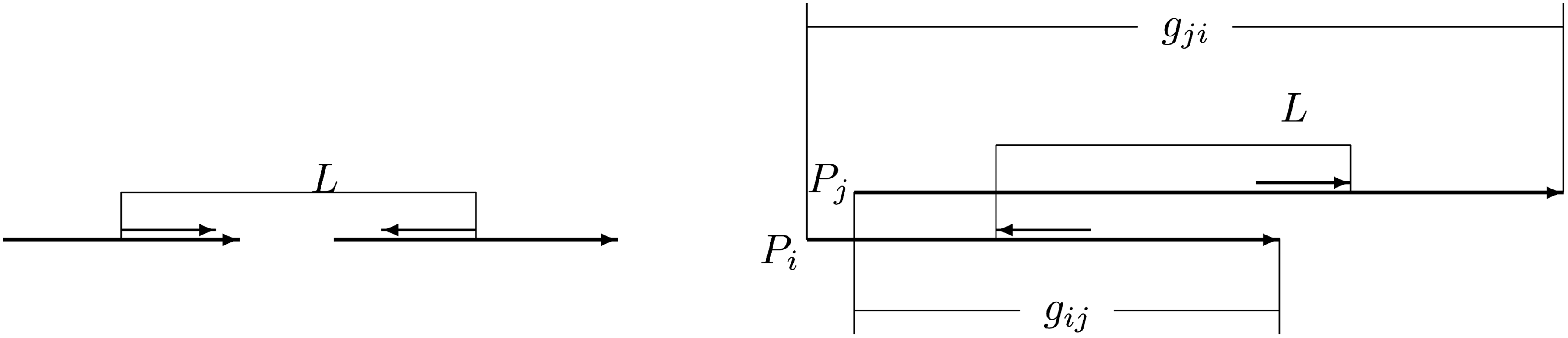
Let Pi be the position of contig Ci in the genome, and li be the length of the contig (Fig. 1). We define gap gij to be the difference between the start position of contig Cj, and the end position of contig Ci, and similarly for gji:

The geometry of two contigs, Ci and Cj, arranged on a line with relevant quantities indicated. Here, L is the insert length, Pi is the start position of contig Ci, li is the length of the contig Ci, oi is the offset of the read of the mate-pair read (MPR) that falls on Ci, R is the read length. gij = Pj−Pi−li. The quantities for Cj are defined similarly.
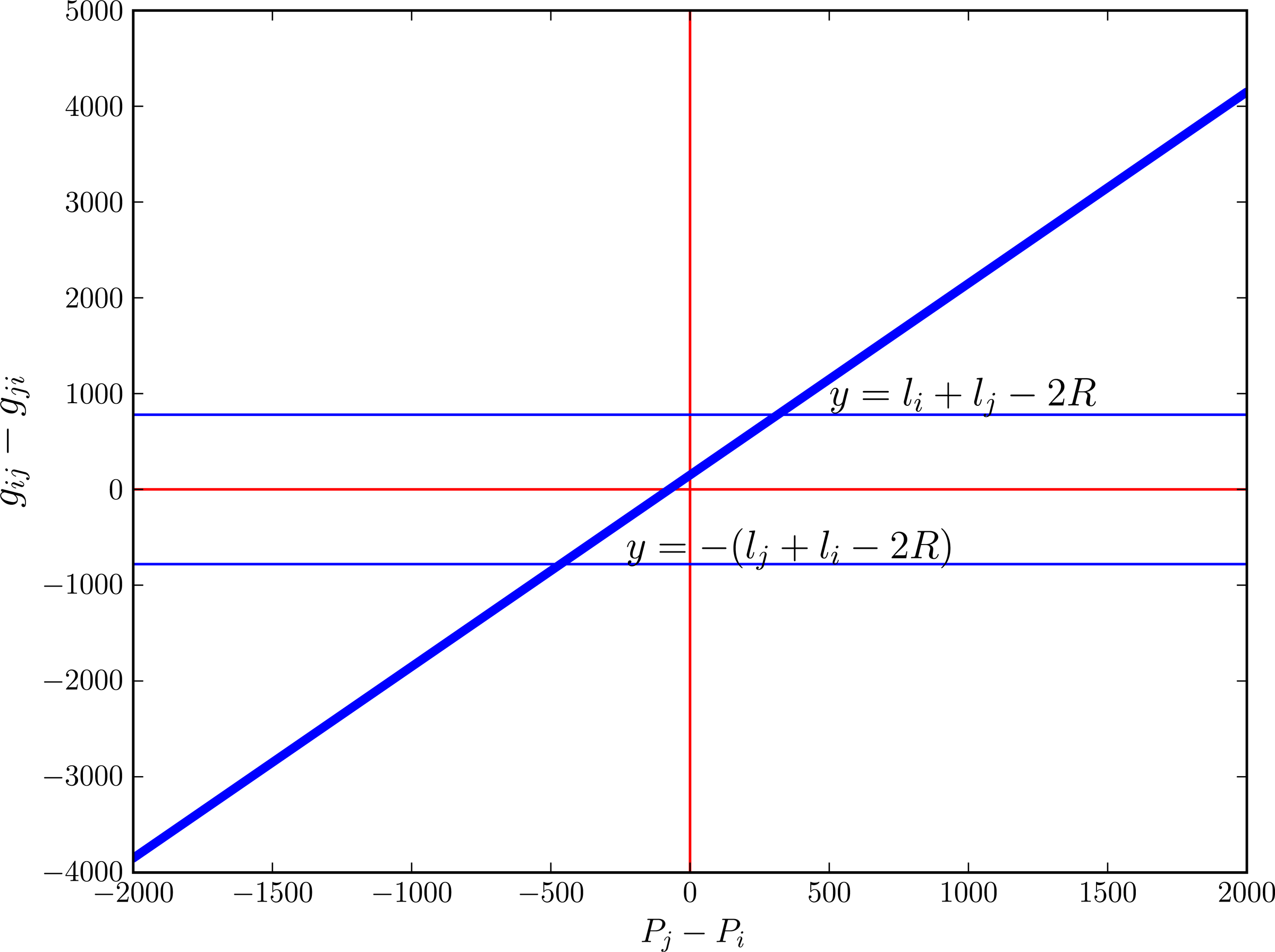
Plot of Equation (5) showing the dependence of the quantity gij−gji on the relative positions of the contigs.
We assume that the maximum overlap of two contigs is one read length, R. In practical contig-building software based on De Bruijn graphs, the maximum overlap is usually one k-mer where R > k, so our assumption is valid.
2.2. Derivation of two gap equations
If we assume that Pi < Pj as in Fig. 1, and that the maximum overlap between two contigs is R (i.e., the minimum gap gij is −R), then
Now consider the quantity gij−gji. Using Equation (1), we can derive the following inequality, which we call Gap Equation 1
Therefore, we have shown that (Pi < Pj) ⇒ (gij−gji ≥ li+lj−2R). Next consider the quantity gij+gji. We can easily derive Gap Equation 2:
Now, we will prove the other direction of the implication in Gap Equation 1, and show that (gij−gji ≥ li+lj−2R) ⇒ (Pi < Pj). Using Gap Equation 1 and Equation (1), we get
No contig length can be less than R, the length of a read. In practice, contigs of lengths R are not very reliable. Our experiments show that such contigs almost always fail to align to the reference. We suggest scaffolders enforce a minimum contig length, which is > R. We make the assumption li−R > 0 and that gives us Pj−Pi > 0 or Pi < Pj. Therefore, (gij−gji ≥ li+lj−2R) ⇒ (Pi < Pj) and together we have proven,
2.3. Using the gap equations to predict relative positions
Our definitions in Equation (1) used the quantities Pi and Pj, which are not available in practice in de novo assembly. Thus, we need to define the gaps gij and gji in terms of quantities we know, such as the insert length L and the read offsets relative to the contigs oi and oj. Note that the insert length for each MPR is an unknown constant, so treating it as a constant in the proof is justified. In practice, we use L =
Let L be the insert length, oi and oj be the offsets of the start positions of the paired reads in Ci and Cj, respectively, and Θ
i
and Θ
j
be the orientations of Ci and Cj, respectively. To simplify the notation we abbreviate Θ
i
= Θ
j
as Θi=j and Θ
i
≠ Θ
j
as Θ
i≠j
. Then, if Pi < Pj and Θi=j (Fig. 3), we can redefine the gaps gij and gji without using the contig start positions Pi and Pj:

The geometry of two contigs arranged on a line in terms of quantities known in de novo assembly.
Note that these definitions remain consistent with Gap Equation 2 [Equation (4)]. Taking the difference of Equations (6) and (7), we can similarly remove Pi and Pj from Gap Equation 1:
Using Equations (8) and (5), we derive the following inequality:
Consequently, we obtain that (Pi < Pj) ∧ Θi=j ⇒ L+(oi−oj) ≥ li. Negating the implication gives
Now, without loss of generality, we can assume that Θ
i≠j
is false. This is possible because our experiments later show that the SLIQ or majority voting procedures are both very accurate at predicting relative orientation (Table 2) so we can first determine the relative orientations of the contigs and flip the orientation of one contig if required. Thus we have
n, total number of edges connecting two different contigs; we, minimum wieght of an edge for SLIQ prediction; no, the number of edges for which we can predict relative orientation, eo, the accuracy of relative orientation prediction, np, the number of edges for which we can predict relative position; ep, the accuracy of relative position prediction; wm, minimum weight of an edge for majority prediction. The same notations are used for majority filtering except with prime.
In addition, we introduce two filters that are very useful in practice for removing unreliable MPRs. To derive the first filter, if Pj < Pi,
The second filter is to discard an MPR if it passes the test for both Pi < Pj and Pj < Pi.
2.4. Using the Gap Equations to Predict Relative Orientations
So far, we have only predicted relative positions when Θi=j. Now we show that we can also use the gap equations to infer the relative orientations of the contigs. First, if (Pi < Pj) and the minimum gap is −R, then we have
Similarly, if (Pj < Pi), then we define
Note that
Since (Pi < Pj) and (Pj < Pi) are mutually exclusive and exhaustive neglecting Pi = Pj, at least one of the Equations (11) and (12) will be true. Note that possibly also both could be true. For example, if Pi<Pj then gij≥−R. Now (Pj < Pi) must be false, but that does not imply that
Recalling again that at least one of the Equations (11) and (12) are true, we see that 2L < li+lj is a sufficient condition for mutual exclusion (the XOR relation is denoted by ⨁):
If we use this equation only when the MPR and contigs satisfy the inequality 2L < li+lj, we can then make the relative orientation prediction
Intuitively, the condition 2L < li+lj means that the contig lengths should be large relative to the insert length in order for the SLIQ method to work. To find contigs of the same orientation, we arbitrarily flip one contig and run the above tests again, only this time if Equation (13) holds, then we conclude that the contigs were actually of the same orientation. Say we flip Ci. We call the new offset
Again, we introduce two additional filters that are very useful in practical applications. First, if we find an MPR that predicts both Θ i≠j and Θi=j, then we leave it out of consideration. Second, if the SLIQ equations imply Θ i≠j , then we require that both the reads of the MPR have the same mapping directions on the contigs and similarly for Θi=j.
We summarize our results in the following lemmas and Algorithm 2.
Construct Contig Digraph
Lemma 1
If the maximum overlap between contigs is R and 2L < li+lj, then
Lemma 2
If the maximum overlap between contigs is R, the contigs have the same orientation, (i.e., Θi=j), then
We also summarize the SLIQ inequalities,
2.5. Illustrative cases and examples from real data
In this section, we present two illustrative cases that provide the intuition underlying the SLIQ equations. The ideal case for an MPR connecting two contigs is illustrated in Figure 1. In that case, the contigs are long compared to the insert length, and the reads are mapped to the ends of the contigs. However, this situation does not always occur. Suppose the contigs are short such that the two reads of an MPR fall exactly in the center of the contigs. Then, the right-hand side of Equation (8) reduces to 2L−2R. So for both cases, Pi < Pj and Pj < Pi, the right-hand side of Equation (8) has the same value, making it impossible to predict the relative positions of the two contigs. This situation is illustrated in Figure 4 on the left. It is easy to see that prediction becomes easier as the contigs get longer and the reads move away from the center of the contigs.
Illustrative cases in which both reads of the MPR fall in the center of the contigs (left) and the contigs have reversed positions (right).
Now assume that the working assumption is Pi < Pj but in reality, the reverse (Pj < Pi) is true. Then given that the contigs are long and reads map to the edges of the contigs, the insert length L would suggest the scenario depicted in Figure 4 (right side). This would make both gij and gji [as calculated from Equations (6) and (7)] smaller than they should be. In reality, the position of the contigs is similar to that shown in Figure 1, where we see that both gij and gji are larger than in Figure 4 (right side). These wrong values would then be too small to satisfy the left-hand side of Equation (5) and this would demonstrate that the working assumption of Pi < Pj is wrong.
It is also instructive to consider examples from real data. We show three cases from a real data set: One in which SLIQ made a correct prediction, one in which SLIQ made a wrong prediction, and one where SLIQ did not make any predictions (Fig. 5). We explain precisely which inequalities are violated in the figure caption. The real examples show the difficulties of making SLIQ predictions when the reads fall close to the center of a contig or when the contig lengths are small relative to the insert size.

Three real examples of SLIQ predictions from the PSY dataset. For the correct prediction, the equation L+(oi−oj)< li evaluates to 3385<5043. In the wrong prediction, it should have satisfied L+(oj−oi)< lj but one of the contigs is smaller than the insert length so it evaluates to 262<217 (false). However L+(oi−oj)<li evaluates to 498<863 so the wrong prediction is made. In the no-prediction case, the condition oi−oj <−lj+L is violated. Even if that did not fail, since one of the offsets falls almost in the center of a contig, both the conditions L+(oj−oi)<lj, (299<1384) and L+(oi−oj)<li, (461<506) are satisfied, and we would not give a prediction for this MPR. To simplify the calculations we used L=80.
2.6. Naive scaffolding algorithm
The contig digraph constructed in Algorithm 2 can be directly processed to build linear scaffolds. To illustrate this point, here we present a naive scaffolding algorithm (Algorithm 3).
Naive Scaffolder
To analyze the computational complexity of the naive scaffolding algorithm, let N be the number of MPRs in the library. Constructing G takes O(N) time. Finding articulation points takes O(n+m) time, where n = |V | and m = |E|(Hopcroft and Tarjan, 1973). If we have a articulation nodes, then finding junctions takes O(an) time. Identifying and breaking simple cycles takes O((n+m)(c+1)) time, where c is the number of simple cycles (Johnson, 1975). Finally, topological sorting takes O(n+m) time. In total, the complexity of the naive scaffolding algorithm is O(N)+O(n+m)+O(an)+O((n+m)(c+1)) = O(N)+O(an)+O((n+m)(c+1)). In practical data sets, a and c are small constants and N ≫n,m. Thus, for practical purposes the time complexity of the algorithm is O(N).
3. Experimental Results
To demonstrate the performance of our algorithms in practice, we ran them on five real data sets and two synthetic data sets. The data sets represent genomes ranging in size from small bacterial genomes (3 Mb) to large animal genomes (3.3 Gb) (see Table 1 for details). More importantly, they also vary in repetitiveness—from almost nonrepetitive bacteria to moderately repetitive drosophila to highly repetitive human genomes.
R, read length; cov, coverage; L, reported insert length; Lr, the real insert length calculated by mapping reads to the reference genome; σ, standard deviation of Lr.
For each data set, we obtained a publicly available mate-pair library. We used publicly available pre-built contigs for the Drosophila simulans (DS) and human (HS) (Gnerre et al., 2011) data sets. Pre built contigs were not available for the three microbial data sets—P. suwonensis (PSU), P. syringae (PSY), and P. stipitis (PST) — so we used the short read assembler VELVET (Zerbino and Birney, 2008) to construct contigs. All software parameters and sources for the data are provided in Table 4. For the two synthetic datasets, C. elegans (SY_CE) and human (SY_HS), we constructed contigs by mapping reads back to the reference genome and declaring high-coverage regions to be contigs. So, for these experiments, we have synthetic contigs but real reads. We will discuss the performance of the algorithms on the synthetic data sets at greater length in the Discussion. We mapped the reads to the contigs using the program Bowtie (v. 0.12.7) (Langmead et al., 2009). Below we only report results for the uniquely mapped reads because we know the ground truth for them.
v is the number of mismatches allowed in read mapping (Bowtie v.0.12.7).
3.1. Comparison of SLIQ and majority voting predictions
On all the real data sets, SLIQ was highly accurate in predicting both relative orientation (>75%) and position (>80%) (Table 2). For orientation prediction, SLIQ and majority filtering produced almost identical accuracies except for the case of P. stipitis (PST), where SLIQ had lower accuracy (75% vs 97%). One possible reason might be that the PST library used long mate-pair reads, which may be more inaccurate than the other libraries we tested. Conversely, for PST, majority voting gave far worse accuracy (16.5%) than SLIQ (75%) in relative position prediction, confirming that this data set is an outlier.
Focusing only on the position predictions, SLIQ showed a significant advantage in both the number and accuracy of the predictions compared to majority voting for the more complex genomes — D. simulans and human (Fig. 6). Importantly, the improvement was particularly large for the human genome.
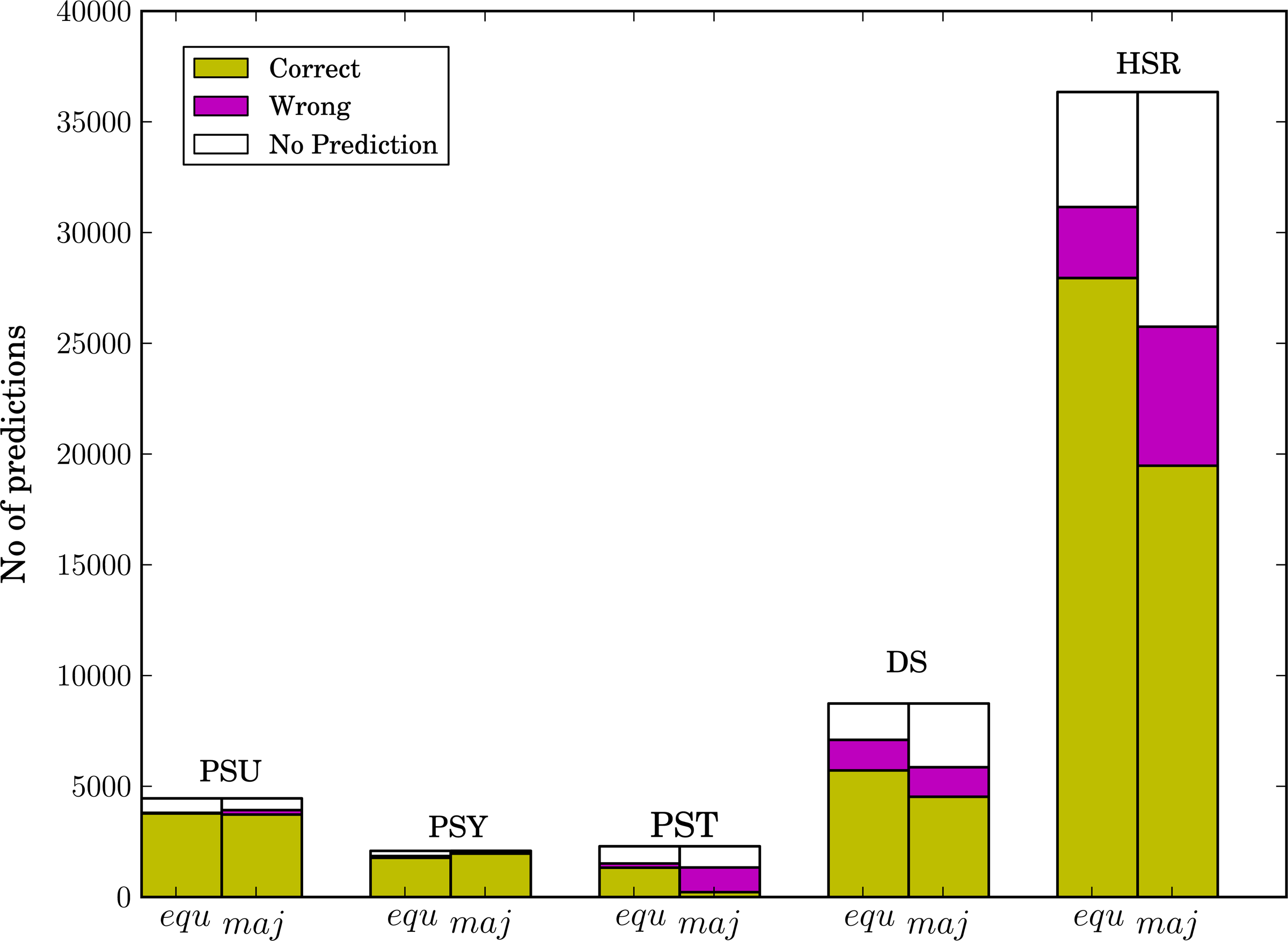
Comparison of the accuracy of SLIQ and majority voting for relative position prediction using that same data shown in Table 2.
Finally, Table 3 gives a more detailed comparison of cases in which the SLIQ and majority voting predictions disagreed. When the two methods disagreed, SLIQ clearly outperformed majority voting procedure. For example, for human, when the methods disagreed, SLIQ was right in 1852 cases and majority voting in only 165 cases. SLIQ was also generally more accurate when considering only the predictions made uniquely by each method, except in one case (PSY).
na, the number of predictions where the methods agreed; nd, the number of predictions where the methods disagreed; nde, the number of predictions not in agreement where SLIQ was correct, ndm, the number of predictions not in agreement where majority voting was correct;
3.2. Computing the optimal insert length
In our experiments, we found that using a slightly larger value for L (e.g., 20 bp for PSY) than that reported or estimated increased both np(by 49), the number of MPRs for which we could make a relative position prediction, and ep (by 2%), the accuracy of relative position prediction. This may seem surprising at first given Equation (9). However, for np, it can be seen from Figure 1 that underestimating L would reduce gij, which would lead to more overlaps between contigs. Since we assume that the maximum contig overlap is R, underestimating L would remove many MPRs from the predictions. However, at the moment we do not have an explanation for the observed increase in ep, the prediction accuracy.
On the other hand, using a slightly smaller value for L increased no, the number of MPRs for which we could make a relative orientation prediction, while eo, the prediction accuracy for orientation, remained constant. We suspect that a lower L makes Equations (11) and (12) harder to pass and thus less MPRs are excluded by the mutual exclusion test.
3.3. Computing the rank of MPRs
Our experimental results also agree with our illustrative cases (section 2.5) in that the prediction accuracy decreases as 2(oi−oj) gets closer to (li−lj) which intuitively means that the reads are falling closer to the center of the contigs. To address this issue we can rank the MPRs by the minimum value of c for which they fail to pass the more stringent inequality |2(oi−oj)−(li−lj)|>cR. We say that an MPR has rank c if and only if c is the smallest positive integer such that |2(oi−oj)−(li−lj)|≤cR, and MPRs with higher rank are considered more confident with regards to their prediction. Figure 7 shows how the prediction accuracy depends on the rank of the MPRs in the PSY dataset.

Change in the prediction accuracy, ep, as we restrict our analysis to MPRs of higher rank (c).
3.4. Effect of the number of Mate Pairs
More mate pairs connecting different contigs give better confidence in scaffolding. But we observed that this improvement is significant up to a certain threshold (4–5 for majority voting and 2–3 for the SLIQ equations). After that, the improvement in correctness in scaffolding is not worth the reduction in number of edges in the contig graph. For example, for the DS dataset, if we increase the cutoff by 1, the position prediction improves by 3% but reduces the number of edges by 1520. This reduction also depends on the coverage of the read library. For the high coverage PSU dataset, an increase of 1 in cutoff has almost no effect– a reduction of 50 edges. And of course, all this is assuming that the contigs are of reasonable quality. If you have mis-assembled or chimeric contigs, more mate pairs can create more loops and high-degree nodes in the contig graph, which are not removed by the cutoff threshold and result in worse scaffolding.
3.5. Performance of the naive scaffolder
We summarize the results of our naive scaffolder on the five real data sets in Table 6 and Table 7. For all data sets, the orientation accuracy was very high (>97%) and the position accuracy was also high (>89%). While the genome coverages of PSU and DS may appear surprising, note that the PSU library had a very high coverage while the DS library had low coverage and was also made up of a number of different D. simulans strains. It is likely that the PSU contigs include misassembled fragments in the contigs, making the total length of the contigs larger than the genome size. For DS, the combination of low coverage and relatively high rates of sequence differences between the different D. simulans strains likely resulted in lower genome coverage.
N50 is the length n such that 50% of bases are in a scaffold of length at least n. The position accuracy measures how many neighboring contigs in the scaffold were placed in the correct order.
All times are the sum of the user and system times reported by the Linux time command. We ran all software on a 48 core Linux server with 256GB of memory.
4. Discussion
In conclusion, we have presented a mathematical approach and an algorithm for constructing a contig digraph that encodes the relative positions of contigs based on mate-pair read data. Our main insight is the derivation of a set of simple linear inequalities derived from the geometry of contigs on the line that we call SLIQ. We can use SLIQ both to efficiently filter out unreliable mate-pair reads (MPR) and predict the relative positions and orientations between contigs. We have shown that SLIQ outperforms the commonly used majority voting procedure for the prediction of relative position of contigs while both methods are very accurate for orientation prediction. The contig digraph can also be directly processed into a set of linear scaffolds and we have presented a simple scaffolding algorithm for doing so. Our naive scaffolder has high accuracy on all data sets tested and is very efficient—for practical purposes, as it takes time linear in the size of the mate pair library and it is also very fast compared to other state-of the art scaffolders. The output of our naive scaffolder can either be used directly as draft scaffolds or used as a reasonable starting point for refinement with more complex optimization procedures used in other scaffolders.
One interesting and unexpected finding of our experiments was that the simple majority voting procedure performs very well for predicting the relative positions of contigs if the contigs have few errors. This can be seen by the performance of the majority voting procedure when using synthetic contigs that are not constructed using de novo assembly tools but rather by mapping the reads back to a reference genome and identifying regions of high coverage, which is expected to produce much higher quality contigs (Table 5). This observation suggests a novel way to approach the scaffolding problem in which the contig builder would output smaller but higher quality contigs and allow the scaffolder to handle the remainder of the assembly. We believe this is a significant change in philosophy of genome assembly programs to date in which during the contig building step, one generally attempts greedily to build contigs that are as long as possible. This viewpoint also differs considerably from previous approaches to scaffolding in which the focus was on resolving conflicts between mate pairs that gave conflicting information about the relative orientation and position of contigs.
n, total number of edges connecting two different contigs; wm, minimum weight of an edge for majority prediction; no, the number of edges for which we can predict relative orientation; eo, the accuracy in relative orientation prediction; np, the number of edges for which we can predict relative position; ep, the accuracy in relative position prediction.
Finally, we are exploring several possible extensions of the SLIQ method. The first extension is to find the optimal value for L, the insert length, so that we optimize the number and accuracy of relative position and orientation predictions. The second extension is to assign numerical values to the accuracy of prediction of MPRs of a particular rank. Finally, for the multiply mapped MPRs, which were not included in the results, we plan to identify the most likely mapping for the MPR, for example, by using their ranks.
Footnotes
Disclosure Statement
No competing financial interests exist.