
Abstract
Abstract
Ontology is widely used in semantic computing and reasoning, and various biomedicine ontologies have become institutionalized to make the heterogeneous knowledge computationally amenable. Relation words, especially verbs, play an important role when describing the interaction between biological entities in molecular function, biological process, and cellular component; however, comprehensive research and analysis are still lacking. In this article, we propose an automatic method to build interaction relation ontology by investigating relation verbs, analyzing the syntactic relation of PubMed abstracts to perform relation vocabulary expansion, and integrating WordNet into our method to construct the hierarchy of relation vocabulary. Five attributes are populated automatically for each word in interaction relation ontology. As a result, the interaction relation ontology is constructed; it contains a total of 963 words and covers the most relation words used in existing methods of proteins interaction relation.
1. Introduction
O
In hierarchy learning of ontology, Biemann (2005) presented a survey of learning ontology or ontology-like structures from unstructured text, and the comparisons of a clustering-based method and a classification-based method were analyzed in detail. Lin (1998) defined word similarity based on the distribution pattern by parsing the dependency relation of sentences, and found similar words by different similarity measures. Our hierarchy of words is partly inspired by those works. The word class methods, N-gram model and statistical algorithm, were discussed by Brown et al. (1992). Caraballo (1999) created the semantic lexicon and its hierarchy of nouns based on heuristic pattern. Cimiano et al. (2004) learned the taxonomies automatically by concept clustering based on Formal Concept Analysis, compared it with hierarchical agglomerative clustering and hierarchical divisive clustering, and represented the hypernym as a description label of the abstract concept by a verb-like identifier. Ushioda (1996) presented a greedy algorithm that tries to minimize average loss of mutual information of adjacent classes for hierarchical clustering of words using large texts, and pointed out that the hierarchy learning methods based on clustering lack significant class labels of clustering results.
Relation words, especially verbs, play important roles when describing the interaction between biological entities (protein, gene, etc.). The work of Rebholz-Schuhmann et al. (2010) provided a survey on the relation verbs, which was referred to by different research teams, and described the prediction capacity of different verbs for protein interaction extraction on the existing corpora. Observed by the online service iHOP (Information Hyperlinked Over Proteins) (Hoffmann and Valencia, 2005), about 90% of active relationships of proteins were expressed syntactically as “protein verb protein,” highlighting the importance of interaction verbs at relation navigation networks. Levin (1993) classified over 3,000 English verbs in a lexicon according to the rule with shared meaning and behavior, which assumed that the meaning of the verb influences its syntactic behavior, and then integrated it into a powerful tool. VerbNet (Schuler, 2005; Schuler et al., 2009), the largest on-line hierarchical verb lexicon, contains explicit syntactic and semantic information for classes of verbs with mappings to other lexical resources such as WordNet, Xta, and FrameNet. Each verb class in VerbNet is completely described by thematic roles, selectional restrictions of the arguments. Differentiating with the open verb research, we aim at interaction relation verbs between biological entities and extract them from PubMed abstracts, which locate the verbs in coordination relation, and filter the irrelevant by mutual information.
Syntactic patterns were widely exploited in information extraction. The entity relation oriented open domain was involved in Open Information Extraction (Etzioni et al., 2008, 2011) and StatSnowBall (Zhu et al., 2009) on large-scale corpora. By analyzing and summarizing the syntactic patterns, Etzioni et al. employed a rule-based method to extract relations and arguments. In our method, the syntactic patterns were used to explore the sentences of PubMed abstracts that contain candidate interaction relation words. The purpose of our work lies in exploring and organizing the verbs that express an interaction relation between biomedical entities. We present an interaction relation ontology learning method that consists of relation lexicon learning and hierarchy relation learning. In the first step, relation lexicon learning, the syntactic patterns are used to construct query expressions to search PubMed abstracts for retrieving the relevant sentences. Then syntactic analysis is performed to extract the candidate interaction relation words, and these words are assembled into the relation lexicon. In the second step, hierarchy relation learning, the words in the relation lexicon are organized by combing the WordNet hierarchy to form the interaction relation ontology; meanwhile, five attributes are populated for each word automatically. The meaning of the lower-level words in the relation ontology is more general than those in the higher level, and thus the lower the level in which the word is located, the more specific the relations expressed between biological entities.
2. Method
In this article, we explore the relation verbs and propose an automatic method to build interaction relation ontology, which consists of two steps, relation lexicon learning and hierarchy relation learning. The first step extracts relation verbs from the sentences of PubMed abstracts (www.ncbi.nlm.nih.gov/pubmed/) by analyzing the coordination relation of syntactic structure and then from a relation lexicon. The second one builds the hierarchy of relation lexicon by integrating the WordNet. Finally, five attributes of the relation word in interaction relation ontology are populated automatically.
2.1. Relation lexicon learning
This step performs the expansion of seed relation verbs from PubMed abstracts and constructs the relation lexicon, in which the seed verbs are selected from a particular corpus manually. At first, query expressions are submitted to PubMed for retrieving the relevant sentences. Then syntactic parsing of the sentence is performed to discover the coordination relation of the seed words. The iterative procedure terminates when either the iterative count reaches a threshold or the number of new generated words is less than a threshold.
Coordination constructions (Haspelmath, 2004) in linguistics can be categorized based on their meaning: conjunctive, additive, coordinative, cumulative (“and”), disjunctive (“or”), adversative (“but”). In our method, the syntactic pattern “verb + coordination word” is taken to capture coordination relation, which forms the query expressions such as “seed word + and,” “seed word + or,” and “seed word + but” of the PubMed search, and extracts 200 sentences for each query submission. As there may be repeated retrieved sentences, we eliminate the redundancy by using Levenshtein distance for the efficiency of sentence parsing. The Stanford parser (de Marnee and Manning, 2010) provided syntactic analysis for analyzing the coordination words of the seed words. We select typed dependencies with collapsed as our parsing style and collect 17 expression styles of coordination relation as listed in Table 1.
As an example, for the sentence “Here we report that in vivo IκBβ serves both to inhibit and facilitate the inflammatory response,” the following typed dependencies are obtained by the Stanford parser: “dep(report-3, Here-1); dep(report-3, we-2); root(ROOT-0, report-3); nsubj(serves-8, report-3); nn(IκBβ-7, vivo-6); prep_in(serves-8, IκBβ-7); rcmod(report-3, serves-8); dep(inhibit-11, both-9); aux(inhibit-11, to-10); ccomp(serves-8, inhibit-11); xcomp(serves-8, inhibit-11); ccomp(serves-8, facilitate-13); xcomp(serves-8, facilitate-13); conj_and(inhibit-11, facilitate-13); det(response-16, the-14); amod(response-16, inflammatory-15); dobj(inhibit-11, response-16).” As shown in Table 1, the selected typed dependencies of coordination relations contain “conj_and(inhibit-11, facilitate-13),” in which the word “facilitate” can be further retrieved as a candidate relation word.
The obtained coordination words are lemmatized by MorphAdorner (morphadorner.northwestern.edu/), and words with POS adjective or adverb in this stage are discarded. If one word has the same root verb or can be used as verb, its root verb or itself is regarded as a candidate word; otherwise, discard it. In addition, the stop words (snowball.tartarus.org/algorithms/english/stop.txt) do not express interaction relation generally and are also removed. Algorithm 1 shows the pseudo codes of the relation lexicon learning. In lines 5 to 16, the candidate relation words are retrieved by querying PubMed abstracts and analyzing the coordination relation of seed words. In lines 17 to 22, the point-wise mutual information between seed relation words and the candidate relation words is computed based on the typed dependencies according to Formula 1, as used by Hindle (1990). In lines 23 and 24, new retrieved words are taken as seed words instead of the original seed words, and the process is repeated until the number of new generated words is less than a threshold or the loop count reaches a specified threshold.
2.2. Hierarchy relation learning
The hierarchy of relation ontology is constructed with integrating WordNet into our method, and the pseudo codes are described in Algorithm 2. The root node of relation ontology is set to RelationEntity in line 1. From line 2 to line 7, we construct the children of root node. At first, we search for the nodes whose parents do not exist in the lexicon by querying WordNet and add them as child nodes of root node, which form the second layer of the ontology. However, if the word parents exist in the relation lexicon and the distance between the word and its parents is less than a threshold tdist, the word to the nodes of ontology is added as child correspondingly, which is performed from line 8 to line 14. From line 15 to line 24, the remaining words of the lexicon are regarded as child nodes that have the shortest distance with them. Here, if two or more nodes of the ontology have the same shortest distance with the word, the word is added as child of all of them. In the case of the word act, its parents do not exist in the relation lexicon, so it is added as child of the root node RelationWords. For example, the word interact has the same distance 0.3334 with intervene and treat in the lexicon; therefore, it is regarded as parent of intervene and treat.
The distance of two words is calculated as shown below. First, locate the common parent cp of two words with lemmatization. If it exists, check each sense of each lemma; otherwise, return 1, which means that their distance is immeasurable. Second, calculate the shortest path from either lemma to cp, minDistToCommonParent. Third, calculate the length of the path from cp to the root node of the WordNet, distFromCommonParentToRoot. Finally, the distance of two words is shown in Formula 2.
2.3. Entity attributes population
After finishing the hierarchy learning of relation ontology, attributes of the relation words are created, which contain wordContext, distanceWithParent, nounForm, presentParticiple, and pastParticiple. The value of the attribute wordContext refers to the number of sentences in which the word occurs, which gives the instances of its usage. The value of the attribute distanceWithParent is the distance with its parent, which indicates the strength between them. Moreover, the attributes nounForm, presentParticiple, and pastParticiple populate the noun, present participle, and past participle of it, respectively, and the word form transformation is carried by MorphAdorner. A pseudo code of the attributes populating is described in Algorithm 3.
3. Experiments Evaluation
3.1 Relation lexicon learning
The relation verbs of protein interaction are extracted and summarized from the work of Chowdhary et al. (2009) as seed words. The total seed words retrieved from Chowdhary contain 293 words. After lemmatization and normalization, 32 words are selected as shown in Table 2. In Algorithm 1, the parameters of mutual information threshold tMI, iterative threshold titer, and the threshold number of new candidate words tnew are empirically set to 0.05, 10, and 10, respectively.
In Algorithm 1, the terminal conditions of the iterative contain the iterative threshold number and the threshold number of new candidate words. After four iterations, the algorithm terminates as the number of new generated words is less than the threshold tnew. The experimental results for four interactions are given in Table 3. Each row represents the results of one iteration. The column Generated candidate words represents the number of the generated coordination words without any processing, as described in lines 13 to 15 in Algorithm 1. The column Processed words represents the number of words after lemmatization and normalization. As a result, the learned relation lexicon contains 963 verbs.
The performance of the sentence parser influences the extraction of coordination relation words, but this is not always the case for some incorrect parsing. For example, in the sentence “Specifically, despite receiving the same mechanical perturbation causing muscle stretch, the strongest responses were produced when the contralateral arm was perturbed in the opposite direction (large tray tilt) rather than in the same direction or not perturbed at all,” two typed dependencies of coordination relation are generated by the Stanford parser, that is, “conj_or(perturbed-23, not-40)” and “conj_negcc(direction-27, direction-38),” and the two extracted candidate relation words, “not” and “direction,” are all discarded in the next step in that the word “not” does not have a corresponding verb form and the word “direction” is a duplicate.
3.2. Hierarchy relation learning and attribute populating
Relation ontology hierarchy learning forms the hierarchy of relation lexicon by combining the WordNet hierarchy into Algorithm 2. The parameter tdist that controls the distance between biological entities is set to 0.5. Five attributes are set automatically in experiments. The attribute wordContext populates the sentences in which the word occurs in the top five sentences of PubMed abstracts. The attribute distanceWithParent populates the distance between the word and its parent, which is calculated by Formula 2. The attributes nounForm, presentParticiple, and pastParticiple populate the noun, the present participle, and the past participle of the verb word by MorphAdorner. The snippet of the constructed relation ontology is generated by protégé (protege.stanford.edu) and presented in Figure 1. As an example, the five attributes of the relation word intervene are presented in Figure 2, in which the attribute wordContext can have more than one value.
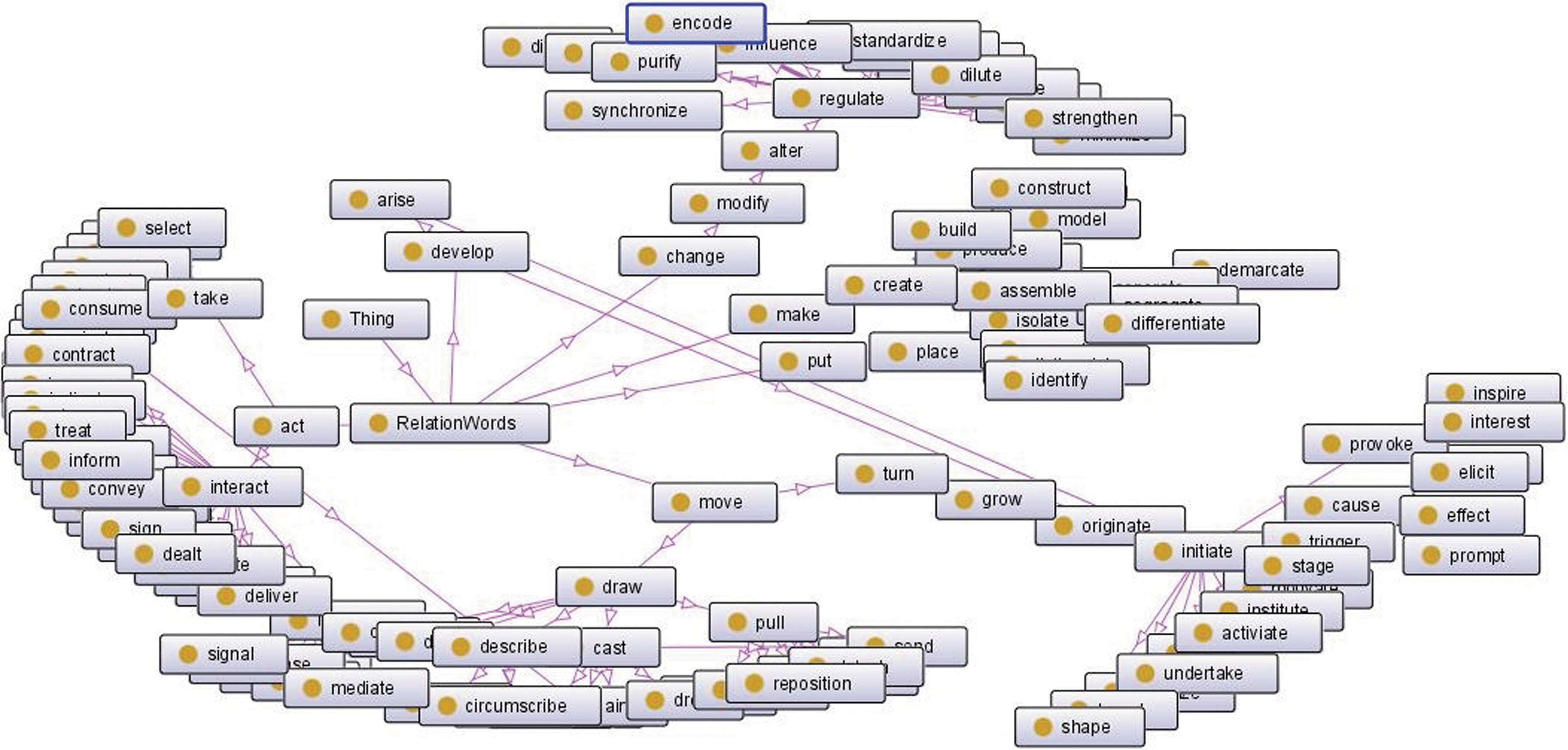
Interaction relation ontology snippet.
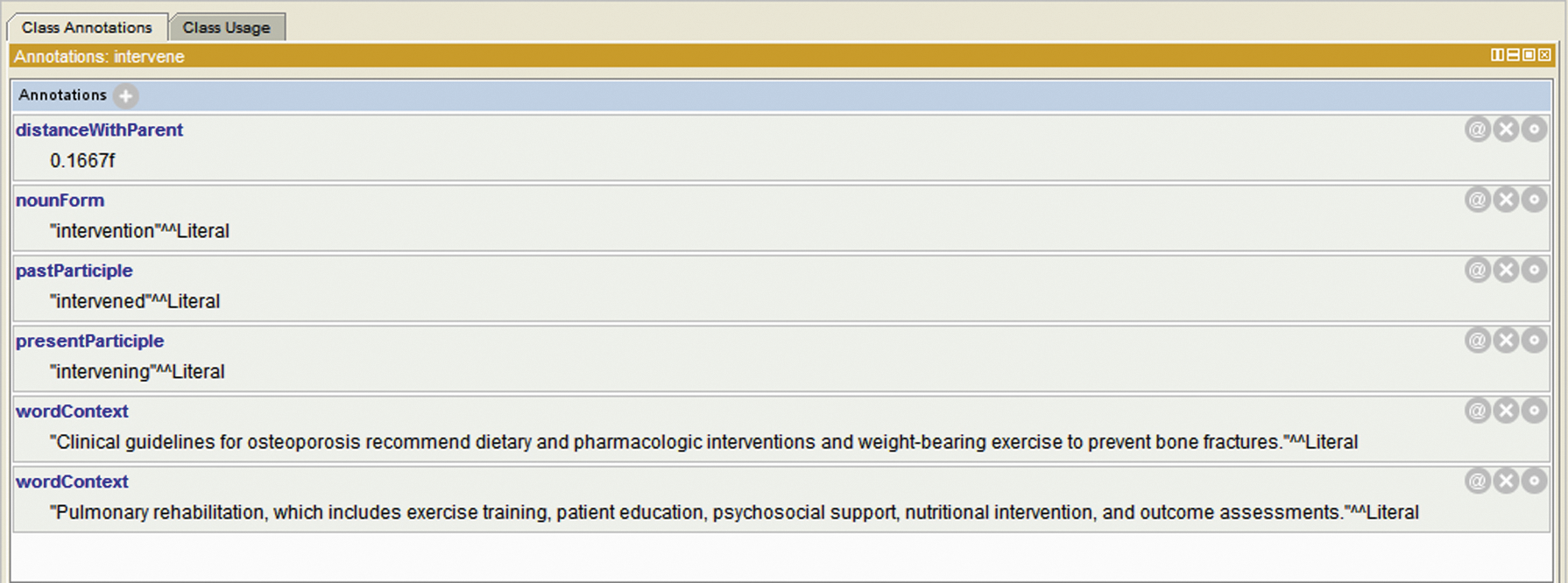
The attributes of relation word intervene.
3.3. Coverage evaluation
We compare our relation ontology with the protein interaction relation words that are extracted from corpora BioInfer (Pyysalo et al., 2007), BioCreAtIvE-PPI (Plake et al., 2005), LLL05 (Hakenberg et al., 2005), Hakenberg (Hakenberg et al., 2006), RelEx (Fundel et al., 2007), Temkin (Temkin and Gilder, 2003), and Kabiljo (Kabiljo et al., 2009), in which the singular and plural of verb and noun are ignored. As in Table 4, the columns Extracted relation words, Ignored, and Recall represent the total number of extracted relation words, the number of omitted words by our method, and the recall of our ontology that is computed in Formula 3, respectively.
In Table 4, the constructed relation ontology can cover most of the relation words of the selected corpora. In BioInfer, the compound word “CROSS-LINK-AP” is missed, because we do not consider this word style. The words “ligand-independent” and “formalin-fixed” in BioCreAtIvE are missed for the same reason in BioInfer, and the word “enhancer's” is ignored as we could not lemmatize the word correctly. Adjective and adverb are discarded in our ontology, which induces the words “misc,” “actively,” and “inducible” missed in LLL05. In corpus (Hakenberg et al., 2006), all words can be covered by our ontology, except for “see,” “be,” and “give, make,” which are filtered out as stop words, after they are lemmatized and presented in the style of past participle. In RelEx, the lemmatization of 175 words is presented, and all the words are captured except for “ligand” and “use” when lemmatizing the word in our ontology, where “ligand” as a noun without corresponding verb and “use” as stop words are ignored. The words used in Temkin (Temkin and Gilder, 2003) and Kabiljo (Kabiljo et al., 2009) are all covered by our ontology. As the discussed hierarchy in WordNet, the meaning of the lower-level word in the relation ontology is more general than that of the corresponding higher-level one, i.e., the lower the level where the word is located, the more specific the relations expression between biological entities the word has. For instance, the word mediate is used to express the interaction relation more frequently and specifically than its parent draw in experiments.
4. Conclusions And Future Works
In this article, we propose an automatic method to build an interaction relation ontology, which explores the relation words that represent the interaction between biological entities, by analyzing the syntactic relation of PubMed sentences to learn the vocabulary. The lexicon hierarchy is formed with the help of WordNet, whose word position is determined by the distance between the word and its parents. The constructed interaction relation ontology contains a total of 963 verbs. By experimental evaluation, the ontology covers the most relation words used in existing methods of protein interaction relation extraction. On the ontology hierarchy, the words in the lower level tend to express relations between biological entities more specific than those in the higher level. At the same time, five attributes, wordContext, distanceWithParent, nounForm, presenParticiple, and pastParticiple, are populated automatically. In the future, we will explore the detailed usage of the interaction words in a particular aspect of molecular function, biological process, and cellular component.
Footnotes
Acknowledgments
This research was supported by the National Natural Science Foundation of China (Nos. 61300058 and 61374181). This work was also supported in part by the National Key Technology R&D Program under grant no. 2011BAH10B03.
Disclosure Statement
The authors declare that no competing interests exist.