
Abstract
Abstract
In machine learning, one of the important criteria for higher classification accuracy is a balanced dataset. Datasets with a large ratio between minority and majority classes face hindrance in learning using any classifier. Datasets having a magnitude difference in number of instances between the target concept result in an imbalanced class distribution. Such datasets can range from biological data, sensor data, medical diagnostics, or any other domain where labeling any instances of the minority class can be time-consuming or costly or the data may not be easily available. The current study investigates a number of imbalanced class algorithms for solving the imbalanced class distribution present in epigenetic datasets. Epigenetic (DNA methylation) datasets inherently come with few differentially DNA methylated regions (DMR) and with a higher number of non-DMR sites. For this class imbalance problem, a number of algorithms are compared, including the TAN+AdaBoost algorithm. Experiments performed on four epigenetic datasets and several known datasets show that an imbalanced dataset can have similar accuracy as a regular learner on a balanced dataset.
1. Introduction
C
An unequal distribution between classes of a dataset is known as the class imbalance problem (Japkowicz and Holte, 2001; Chawla et al., 2004; Weiss, 2004; He and Garcia, 2009). This problem is prevalent in many domains such as in credit card fraud detection (Chan and Stolfo, 1998), network intrusion (Cieslak et al., 2006), text categorization (Dumais et al., 1998), and classification of proteins (Radivojac et al., 2004) to name a few. The importance of the imbalanced class problem has been more visible recently with the introduction of this topic in several conferences and journals. Recently, a few workshops have been held mainly addressing this area such as the Workshop on Class Imbalances: Past, Present, Future (CIPPF, 2012) and the International Conference on Machine Learning workshop on Learning from Imbalanced Data Sets (ICML, 03) among others.
The current study addresses the imbalanced class problem in epigenetics (Waddington, 1953; Weber and Schubeler, 2007; Bock and Lengauer, 2008). The epigenetic data sets were obtained from epigenetic transgenerational inheritance experiments (Guerrero-Bosagna et al., 2010, 2013; Bhandari et al., 2012a; Manikkam et al., 2012a,b,c, 2013; Nilsson et al., 2012; Tracey et al., 2013). The gestating female (F0 generation) exposed to environmental compounds had offspring that were bred out three generations to the F3 (great grand-offspring), and the sperm was collected from the males for analysis. The number of altered sites with differentially DNA methylated regions (DMR) was identified in a comparison of F3 generation male sperm from exposure lineage and control lineage F3 generations. For each study observing changes in DNA methylation between control and exposure lineages, there are only a few DMR sites compared with thousands of sites that are not altered (non-DMRs). Therefore, using machine learning methods in this scenario creates a problem of data imbalance. For many biological datasets (e.g., disease outbreaks), this class imbalance problem is inherent.
One of the main issues with epigenetic datasets is that they are naturally imbalanced. A number of steps in the analysis such as stringent statistics, intersection between results, and other methods are used to make sure that the epigenetic sites retrieved from the analysis contain as few false positives as possible. Only a few of these sites are later confirmed using alternate procedures such as bisulfite sequencing (Chen et al., 2005). Since such stringent analysis methods pick only a very limited number of epigenetic sites from the whole genome, the rest of the sites all fall in the majority class and the epigenetic sites fall in the minority class.
Another issue from the machine-learning point of view is that most biological datasets come with high dimension and low volume. Each site may contain from a few hundred to a few thousand genomic features ranging from repeat elements to CpG islands (Gardiner-Garden and Frommer, 1987) to other characteristics. Among the many features, the relevant and important features need to be identified and kept as features in the dataset. Some of the selection of these features comes from biological knowledge of the dataset.
Both random oversampling (Han et al., 2005; Chawla et al., 2011) and random undersampling (Holte et al., 1989; Mease et al., 2007) have been used widely to address the class imbalance problem. Since they introduce overfitting and potential loss of subconcepts, many variants of these techniques have been proposed and used successfully. Using a synthetic dataset to overcome the minority class distribution is a unique technique. It uses the feature space in the minority class and creates new instances. One successful technique is synthetic minority oversampling technique (SMOTE) (Chawla et al., 2011). Tomek links is a data cleaning technique that can be used to create distinct clusters in the training set by removing overlapping examples, which helps create better classification rules (Tomek, 1976). Cluster-based oversampling (CBO) algorithms such as the one that uses K-means clustering create well-defined cluster boundaries and cluster means (Jo and Japkowicz, 2004). Cost-sensitive approaches based on the cost matrix have been used. Three cost-sensitive boosting methods, AdaC1, AdaC2, and AdaC3 (Sun et al., 2007), have been used where different costs are added in the weight update phase of the boosting algorithm.
An undersampling method called EasyEnsemble (Liu et al., 2009) has been used in this study. It converts the majority class instances of the training set into a number of subsets and allows a single classifier (AdaBoost is used to train each classifier) to be trained from each of these subsets plus the minority set. An ensemble learning system combines the outcome of these classifiers to create the final output. The approach proposed in this article also uses subset sampling optimization (SSO) (Yang et al., 2009, 2011) and the AdaBoost+TAN learning technique. These algorithms will be used in the current study.
2. Methods
2.1. EasyEnsemble
EasyEnsemble groups majority class instances into equal subsets of the same size of the minority class. After adding the entire minority class samples to each of these majority class subgroups, it trains a different learner on each subgroup. EasyEnsemble uses an ensemble-based approach that combines the output of these learners.
One of the characteristics of the EasyEnsemble algorithm is that it looks like an ensemble of ensembles. As shown in Algorithm 1, the majority class is divided into T balanced subsamples each containing the complete minority class P. In each iteration a classifier Hi is trained. Classification and regression trees (CART) (Breiman et al., 1984) are used as the base classifier in EasyEnsemble. Hi is actually an ensemble of si weak classifiers hij (CART) with weights αi,j. A weak classifier is one that achieves accuracy better than random guessing. If hi,j is assumed to be a set of features, then Hi is actually a linear classifier built on those features. So features in different subsets have information of different viewpoints of the majority class. Finally, all those features hi,j (
2.2. Subset sampling optimization
Subset sampling optimization (SSO) is based on the particle swarm optimization (PSO) hybrid system (Yang et al., 2009, 2011). The SSO algorithm divides the dataset into three sets. While the first two are used for internal cross validation to perform the internal optimization process, the third set is used for external cross validation. The internal dataset is again divided into three sets, two for training and the other for testing. Using the internal dataset the SSO algorithm takes different subset samples of the majority class and combines them with samples from the minority class for classifier learning (both sets are of equal size). Each of these sets is called a particle and has an index in the particle space. Each of these n particles also has a dimension m equal to the number of instances in it. A particle's velocity vi,j(t) (index
Here pbesti,j and gbesti,j are the previous best position and updated best position, w is the fitness weight, c1, R1, c2, and R2 are the learning rates and social coefficients, while function random provides pseudo-random numbers to create uniform distribution between 0 and 1. When the value xi,j is 1, then the jth sample is included in building the classification model, while a value of 0 will have it excluded from the training. Among these subsets the ones that create better classification accuracy are favored and optimized in each iteration. The overall fitness of each particle (subset) is evaluated with the following function.
L is the number of classifiers in the hybrid system (in the SSO algorithm five classifiers are used for the training; they are decision tree [J48], k-nearest neighbor [KNN], naive Bayes [NB], random forest [RF], and logistic regression [LOG]), and w1, w2, and w3 are the fitness weights with equal values w1 = w2 = w3 = 1/3 (
2.3. TAN-based AdaBoost
This method uses the tree augmented Bayesian network (TAN) as a base classifier for the AdaBoost algorithm, so this algorithm is called TAN+AdaBoost. First, the advantages of using TAN (Friedman et al., 1997) over regular naive Bayes classifier (NBC) need to be explained.
Regular naive Bayes assumes conditional independence among different attributes. Figure 1a shows a simple network where each feature is pointed to by the parent class node and each attribute can be only a child node. The joint probability can be calculated through the class probabilities multiplied by the class conditional probability
The naive Bayes assumes conditional independence among different attributes. 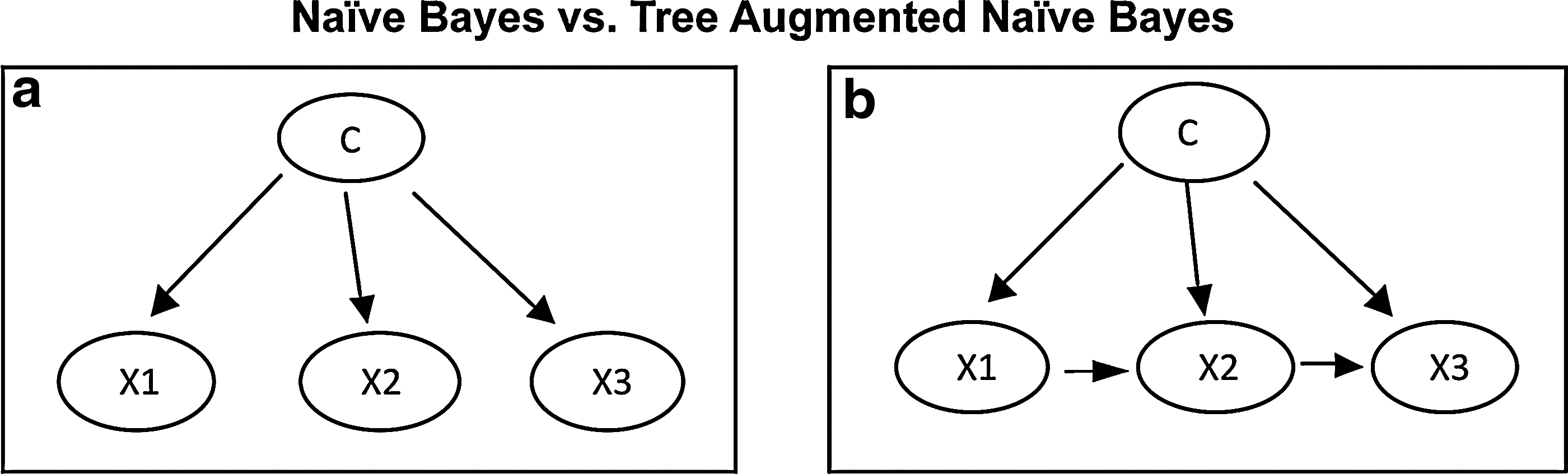
A tree-augmented naive Bayes classifier (TAN) augments the standard NBC by allowing each attribute to have an additional incoming edge (Fig. 1b). This augmented edge is created by statistical dependencies that show the correlation among the features. The TAN outperforms naive Bayes while maintaining computational simplicity by avoiding double accounting, which is present in naive Bayes where multiple features are used that have a high correlation value. The TAN model can be created as follows (Hong-Bo et al., 2002).
1. Compute the conditional mutual information (CMI) between each pair of features,
where C represents the class variable and
2. A complete undirected graph is created where the nodes represent the features. Each edge label represents the value of the CMI between the features.
3. Construct a maximum weighted spanning tree [e.g., Kruskal's algorithm (Kruskal, 1956)] from the graph.
4. Pick any arbitrary node as the root and have all the edges be outward from this root node. This creates a directed tree T out of an undirected tree.
5. Construct the TAN model by adding a vertex labeled by C (class) and having an arc from C to each variable xi.
6. So what we have is the TAN model, which is the NB model augmented by edges in T.
7. Now calculate joint probability, which depends upon the conditional probability not only on the class but also on the feature's parent node parentx.
TAN is used as the base classifier for the AdaBoost algorithm. The details of the TAN+AdaBoost algorithm are given in Algorithm 3.
AdaBoost is based on the boosting approach and is named as one of the top 10 data-mining algorithms (Wu et al., 2008). In AdaBoost, initially, all instances are given an equal weight. All the classifiers are trained with the same number of instances. After each iteration AdaBoost increases the weight of the incorrectly classified instances while decreasing the weight of the correctly classified instances. The goal is to try to correctly label the more difficult instances that the classifier labeled incorrectly. At the same time, each classifier is also assigned a weight based on its classification accuracy. This weight is used in the test phase, where more accurate classifiers get more confidence. When testing a new instance, each classifier gives a weighted vote, and the final label of the instance is based on the majority vote. Schapire proved that any weak classifier can be converted into a strong classifier by following the probably approximately corrected (PAC) learning framework (Freund and Schapire, 1996, 1997). A weak learner is one that achieves accuracy better than random guessing. Although TAN is considered better than NBC, we still consider TAN as a weak classifier and use it as the base classifier for AdaBoost. We name our approach TAN+AdaBoost.
2.4. Data sets
A total of nine different datasets were used in the experiments, all with 10-fold cross-validation. These datasets are from diverse domains. Five are taken from the University of California Irvine (UCI) repository (Bache and Lichman, 2013) and four are from the Skinner laboratory at Washington State University. The epigenetics datasets are from epigenetic transgenerational inheritance experiments and F3 generation somatic cells or sperm from various exposure lineages, including (i) Sertoli and granulosa somatic cells (Nilsson et al., 2012; Guerrero-Bosagna et al., 2013), (iii) dioxin (Hip), jet fuel (Jip), and vinclozolin (Vip) (Guerrero-Bosagna et al., 2010; Manikkam et al., 2012a, c; Tracey et al., 2013), and (iv) plastics (Bip) and pesticide (Pip) (Manikkam et al., 2012b, 2013). Another data set, (ii) Sox9-Sry-Tcf21 (Bhandari et al., 2012a,b), will be used as a negative control for the epigenetic datasets and is a transcription factor binding data set, but was obtained with similar technology. The Sertoli and granulosa datasets consist of adult vinclozolin lineage F3 generation somatic cells that influence the onset of testis and ovarian disease, respectively. The dioxin, jet fuel, and vinclozolin datasets consist of ancestral environmental exposures of these three compounds individually and are associated with the epigenetic transgenerational inheritance of adult onset diseases. Similarly, the plastics and pesticide datasets consist of ancestral environmental exposures of these compounds and are associated with the epigenetic transgenerational inheritance of adult onset diseases. The Sox9, Sry, and Tcf21 are transcription factors involved in the induction of Sertoli cell differentiation and testis development and the datasets are the specific transcription factor binding sites for these factors, so are not epigenetic data and are used as a negative control dataset. Among these datasets the epigenetic datasets (as well as the negative control dataset) are naturally imbalanced. However, the UCI datasets have been modified to create imbalance datasets by labeling one of the smaller classes as the minority class and the rest of the classes as the majority class. Details of these datasets are given in Tables 1 and 2. Table 1 shows the dataset name, features, total instances, number of features, and the percentage of the minority class to the total class distribution. Table 3 shows the general description of the datasets and also shows the target class.
The table contains dataset names, types of features, total instances, number of features, and the total percentage of the minority class of the entire dataset.
Table contains the name and short description of each dataset.
Table contains the minority–majority class for each dataset (nine in total). The AUC values of the different classifiers applied to these datasets. SSO first balanced the dataset to equal class examples and then the same classifiers are applied as unbalanced dataset to calculate the AUC values. The last row contains the AUC values of TAN+AdaBoost approach on all datasets. AUC, area under the curve; SSO, subset sampling optimization. Bold indicates best classifier(s).
Genomic feature extraction (data collection) mining of epigenetic profiles starts with extraction of interesting properties from the DNA sequence data near DMR. After retrieving the training set, often the DMR locations are annotated to find the nearest gene name and the orientation of the gene. FASTA files are created from upstream and downstream of the target genes up to 100 kb. After construction of FASTA files for extraction of genomic features, tools such as RepeatMasker (Smit et al., 1996–2010) are used to find SINE, LINE, ERVL, ERV, and other repeat elements to the upstream and downstream of the DMR locations. One of the common ways of extracting genomic features from sequences is through identification of repeat elements. Identifying repeat elements and consensus sites helps to detect interesting patterns from these sites. Other genomic features are GC content (% of G [guanine] and C [cytosine] in the sequence) and CpG sites and density. Tools such as CpGislandSearcher (Takai and Jones, 2003) can be used to find CpG islands in these regions. CpG islands denote high frequency of CpG sites. A CpG site is denoted by a C followed immediately by a G. Epigenetic sites have been found in low CpG density regions, and therefore identification of a decrease in CpG density in interesting sites will be helpful.
Another important genomic feature is DNA sequence motifs (Stormo, 2000; Das and Dai, 2007). Common patterns among biologically relevant sites can be identified using motif findings. Motifs are DNA sequences that come with a probability matrix for each base position such that a certain combination of those sequences matches with every subsequence. These motifs are usually constructed by running DMR sites from related experiments through some of the popular motif-finding tools. The amount of genomic features can be enormous, and finding relevant genomic features that help to identify DMR sites is a challenge. For the murine imprinted gene project, the authors initially looked into 4 million genomic features (Luedi et al., 2005). Most of these features were constructed by combining different variations of features, ranking them based on which are more relevant, and then picking 4,000 of the most statistically significant ones for the final analysis (Luedi et al., 2005). For this study several motif-finding algorithms were used in order to discover motif sites and consensus sequence binding sites in the DMR regions that were used as important features in the extracted datasets.
3. Results
The three algorithms (EasyEnsemble, SSO, and TAN+AdaBoost) were applied on the nine imbalanced datasets. Among them, three are epigenetic datasets (Guerrero-Bosagna et al., 2010, 2013; Manikkam et al., 2012a,b,c, 2013; Nilsson et al., 2012; Tracey et al., 2013), one dataset (nonepigenetic) for specific DNA sequence binding site for Sry and Sox9 (Bhandari et al., 2012a,b), and five others are UCI datasets (Bache and Lichman, 2013).
The nine datasets were run using five popular nonimbalanced classifiers: (1) SVM, (2) logistic, (3) decision tree, (4) RandomForest, and (5) AdaBoost. Then, the nine datasets were run using the three imbalanced classifiers: (1) EasyEnsemble, (2) SSO, and (3) AdaBoost+TAN. For all algorithms, classifier accuracy measurements were done using area under the curve (AUC), F-measure, and G-mean. These results are given in Table 4 (AUC), Table 5 (F-measure), and Table 6 (G-mean).
Table contains F-measure values from the algorithms applied to the nine datasets. Bold indicates best classifier(s).
Table contains G-measure values from the algorithms applied to the nine datasets. Bold indicates best classifier(s).
For all datasets, 10-fold cross-validation was used to evaluate each of the three imbalanced class algorithms, EasyEnsemble, SSO, and TAN+AdaBoost. The SSO algorithm converts the data into a balanced distribution by selecting some examples from the majority class while keeping the minority class examples intact. This converted dataset was again input to the same five classifiers (SMO, Logistic, J48, RandomForest, and AdaBoost) using 10-fold cross-validation, and the results are given in the tables. Figures 2, 3, and 4 are barplots created from Tables 3, 4, and 5 for better visualization.
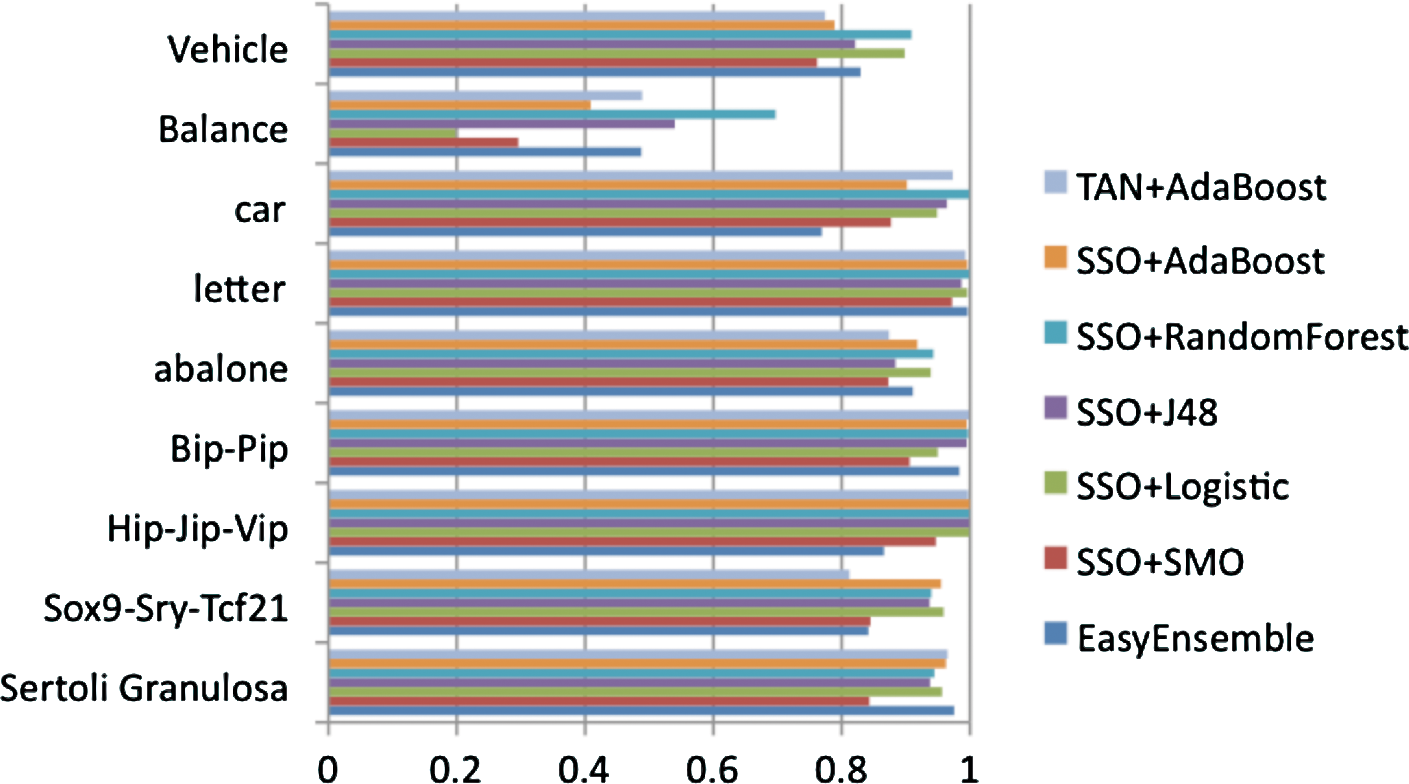
The AUC scores (from Table 3) of three imbalanced class learners (TAN+AdaBoost, SSO, and EasyEnsemble) on the nine datasets. The x-axis is the calculated AUC score. AUC, area under the curve; SSO, subset sampling optimization.
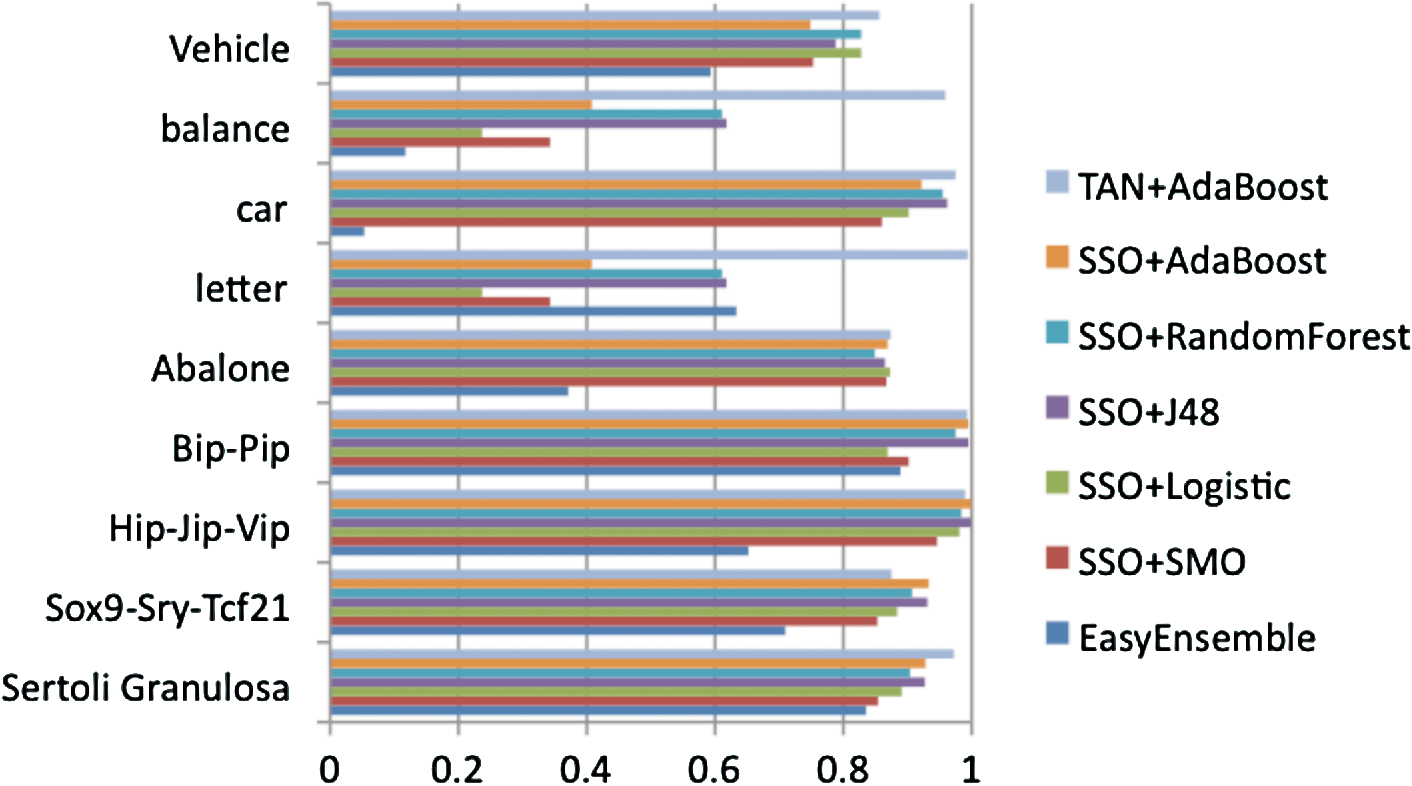
The F-measure (from Table 4) of three imbalanced class learners on nine datasets (x-axis is the F-measure score).

The G-mean (from Table 5) of three imbalanced class learners on nine datasets (x-axis is the G-mean score).
From Table 3, comparing AUC values across the four experiments, the AUC value improves for subset sampling optimization after SSO has converted the imbalanced distribution to a balanced class distribution. However, overall EasyEnsemble has a better AUC value on the four UCI datasets, while TAN+AdaBoost has better AUC values on the epigenetic datasets. The bold entry shows the best result obtained by a classifier for that particular dataset. The F-measure has decreased after having used SSO on the imbalanced dataset (Table 4). Considering F-measure, EasyEnsemble performs poorly on the five UCI datasets (Fig. 3). TAN+AdaBoost has a better F-measure on the epigenetic datasets. Comparing the G-mean score in Table 5, SSO again improves over imbalanced class distribution and closely matches EasyEnsemble on G-mean scores. The G-mean is zero for many of the unbalanced classes, because the classifier predicts only the majority class correctly while predicting all the minority class incorrectly. This shows the power of imbalanced class learning over nonimbalanced. This also justifies the need for using the proper evaluation method. On the three epigenetic datasets, Sertoli-granulosa, Hip-Jip-Vip, and Bip-Pip, TAN+AdaBoost had a higher AUC, F-measure, and G-mean than the rest of the algorithms. While on the negative-control dataset Sox9-Sry-Tcf21, TAN+AdaBoost underperforms in comparison with the others. The reason is that a biologically and molecularly different dataset is used for Sertoli cell transcription factor–binding sites (Bhandari et al., 2012a,b), and its motif and consensus binding sites differ from DMR sites. The datasets (Sertoli-granulosa, Hip-Jip-Vip, and Bip-Pip) consist of DMR sites that have differential DNA methylation changes between the F3 generation treatment and control lineages cells. These epigenetic data come from investigations of the actions of environmental factors during fetal development that induce epigenetic change in the germ line and promote epigenetic transgenerational inheritance of adult-onset diseases (Skinner et al., 2010). The other dataset (Sox9-Sry-Tcf21) consists of genome-wide transcription factor–binding sites in fetal Sertoli cells for Sry and Sox9. The Sox9-Sry-Tcf21 dataset includes identification of direct binding targets using a modified Chip–Chip comparative hybridization analysis (Bhandari et al., 2012a,b) and so is not an epigenetic dataset but only a transcription factor–binding site set of data. The genomic features of this dataset are distinct from the epigenetic dataset. So the analysis should not perform well with this negative dataset. This dataset is used as a negative control for the epigenetic dataset to show that the classifier TAN+AdaBoost has a lower combined average (as we expect) compared with other imbalanced class learners (e.g., SSO) on this negative dataset. An explanation as to why TAN+AdaBoost underperforms compared with SSO in conjunction with the other five classifiers is that SSO has the advantage of initially being trained on the entire dataset to undersample the majority class to create a balanced class distribution. So it has already been trained on the dataset, whereas TAN+AdaBoost gets to examine the test set only after the training is completed on the training set. So TAN+AdaBoost performs better for the epigenetic datasets and underperforms for the negative dataset (as expected), in contrast to the other imbalanced class learners (Table 6).
For each dataset all three performance criteria (AUC, F-measure, and G-mean) were averaged (Table 6). Then, an additional column is created based on the combined average performance on the three epigenetic datasets (Sertoli-granulosa, Hip-Jip-Vip, and Bip-Pip). Sox9-Sry-Tcf21 was left out as it is not an epigenetic dataset. Then, another column was created out of the combined average performance of all the classifiers on the five UCI datasets. Then, a combined average performance of all nine datasets is created. From here it is evident that TAN+AdaBoost performs better on the three epigenetic datasets (score 0.9801) while total performance based on the nine datasets degrades as the performance of Sox9-Sry-Tcf21 (0.8032) alone pulls down its performance (0.8251). The pair-wise t-test results are given in Table 7 with statistically significant values with p-value < 0.05 in bold. The values show statistical significance of the classifiers in rows compared with the classifier in the columns. For example, the TAN+AdaBoost row shows that TAN+AdaBoost significantly outperforms SMO, AdaBoost, and EasyEnsemble on the nine datasets. The ANOVA result did not show any of the classifiers to be statistically significant with a p-value of 0.3989.
Table contains pairwise t-test with 0.05 statistical significance applied on the combined average (Table 6). Shows statistical significance of TAN+AdaBoost over 3 other algorithms (two regular and one imbalanced class learner). Bold indicates the statistically significant classifiers.
4. Discussion
Although the goal of this study is to focus on epigenetic datasets and show which algorithm performs best, we make a number of observations involving imbalanced datasets. Preprocessing the data does not always result in increased performance. The imbalanced class problem can be addressed at the data level or at the algorithm level. While both EasyEnsemble and SSO initially preprocessed the data through intelligent undersampling and then perform algorithm-level class balancing, when compared with TAN+AdaBoost on epigenetic datasets, the advantage of using data preprocessing instead of just doing algorithmic-level class balancing is not obvious.
Not all algorithms perform well with data having high dimension. With datasets containing many features (the epigenetic datasets have 52, 74, and 75 features), the performance of TAN+AdaBoost is superior (combined average of 0.9801; Table 5) over other imbalanced class learners. One explanation is that the TAN-based classifier has high bias, and adding features helps increase its classification accuracy compared with other tree-based classifiers that have lower bias.
Labeling any dataset to be imbalanced is not always an easy task. How to know if the dataset is imbalanced or at what ratio of majority and minority class it can be said comfortably that the class is imbalanced? While some datasets are often called imbalanced when the minority class can be 33% of all examples, more extreme imbalance cases often occur, where the minority class is a few hundred- or a thousand-fold smaller than the majority class. Correctly labeling a dataset to be imbalanced is difficult, and whether an imbalanced learner will perform better than any regular learner is a difficult question. There has been a study in which the level of imbalance has been changed in order to find the best ratio for using the C4.5 classifier (Weiss and Provost, 2003). Authors of the EasyEnsemble approach mention that if an ordinary (nonimbalanced) classifier has an AUC score of >0.95, then class imbalanced learning will not be helpful for those kind of datasets regardless of the majority minority class ratio (Liu et al., 2006). In a previous study (Chan and Stolfo, 1998), the authors found that for a regular learner 50:50 class ratio is best for training.
Some algorithms perform better on naturally imbalanced dataset than others. By running the algorithms on a number of different imbalanced datasets, these algorithms have shown better performance than regular classifiers on naturally imbalanced datasets. Correctly labeling a dataset to be imbalanced and applying an imbalanced class learner on them is important. Previous work shows that if imbalanced class learners are applied to regular balanced datasets, then often the results show performance degradation (Weiss and Provost, 2003). This is why it is often important to notice whether the given dataset is balanced or not, and only such algorithms should be applied to imbalanced datasets.
Ensemble-based approaches have advantages on imbalanced class learning. Although many different novel algorithms have been used to counter the imbalanced class problem, an ensemble-based approach using multiple standard classifiers often performs better than more complex algorithms. An ensemble-based approach is usually one in which the data are partitioned into subgroups and a separate classifier is run on each subgroup of data. Finally, the results of these classifiers are combined and voting is used to label an instance in the test set. Using a combined approach often leads to performance enhancement rather than using single classifiers. Also, several boosting approaches have been used and found to be successful in the imbalanced class problem.
5. Conclusion
This study introduces the imbalanced class problem present in epigenetics and tries to address this issue by using well-known algorithms that have been applied to the imbalanced class problem in other biological datasets. Five regular classifiers (nonimbalance learners) were tested on the imbalanced datasets and showed that by using algorithms designed for imbalanced problems we can achieve better results. Algorithms EasyEnsemble, Subset Sampling Optimization, and AdaBoost+TAN were compared with each other and with the five nonimbalanced class learners.
Evaluation is based on the AUC, F-measure, and G-mean, three popular performance measures for the imbalanced class problem. Experimental results show that SSO improves over imbalanced datasets from the UCI repository, and while AdaBoost+TAN gives overall better accuracy on the epigenetic datasets, the SSO+RandomForest is better than the other algorithms on the five UCI datasets and the combined result based on all the datasets. Future work will involve improving the AdaBoost+TAN method to classify epigenetic datasets so that it will be comparable against the other methods. One approach is to use TAN as a base classifier for the EasyEnsemble method that uses both boosting and bagging. Another approach is to have the majority class examples, which are easily predicted, be removed in further iterations to speed up training.
Footnotes
Author Disclosure Statement
No competing financial interests exist.