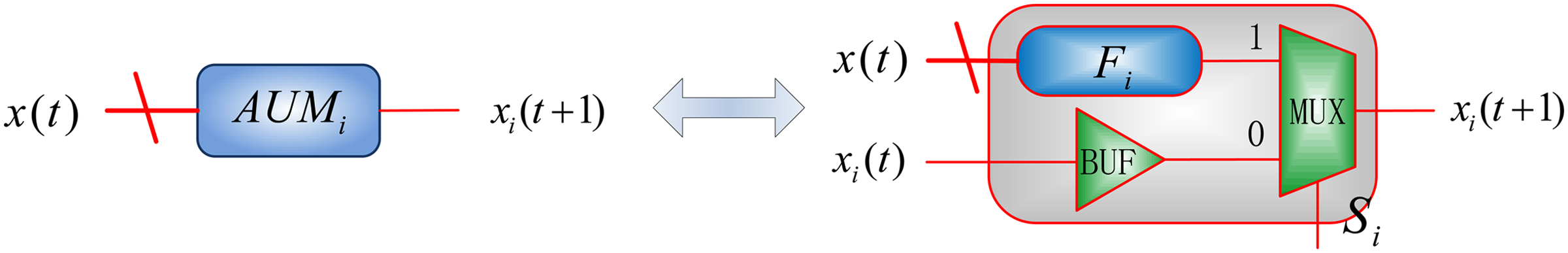Logical models have widely been used to gain insights into the biological behavior of gene regulatory networks (GRNs). Most logical models assume a synchronous update of the genes' states in a GRN. However, this may not be appropriate, because each gene may require a different period of time for changing its state. In this article, asynchronous stochastic Boolean networks (ASBNs) are proposed for investigating various asynchronous state-updating strategies in a GRN. As in stochastic computation, ASBNs use randomly permutated stochastic sequences to encode probability. Investigated by several stochasticity models, a GRN is considered to be subject to noise and external perturbation. Hence, both stochasticity and asynchronicity are considered in the state evolution of a GRN. As a case study, ASBNs are utilized to investigate the dynamic behavior of a T helper network. It is shown that ASBNs are efficient in evaluating the steady-state distributions (SSDs) of the network with random gene perturbation. The SSDs found by using ASBNs show the robustness of the attractors of the T helper network, when various stochasticity and asynchronicity models are considered to investigate its dynamic behavior.
1. Introduction
In gene regulatory networks (GRNs), interactions such as the activation and inhibition relationships between genes, protein transcriptional factors, and mRNA are often analyzed using computational models to obtain biological insights. Various methods have been proposed for modeling the genetic interactions; these include Boolean networks (BNs) (Kauffman, 1969), ordinary differential equation (ODE)-based methods (Chen et al., 2004; Li et al., 2008; Qian et al., 2008), and stochastic simulations at the molecular level (Gillespie, 1976, 1977). While the stochastic and ODE-based approaches provide a more accurate simulation of a biological system, they also require more detailed knowledge about many parameters a priori, such as the kinetic rate constants in a modeling (de Jong, 2002; Karlebach and Shamir, 2008). BNs model the relationships among genes through Boolean logic operations. To incorporate the effect of noise in the interactions of genes and molecules, probabilistic Boolean networks (PBNs) have been proposed and studied (Shmulevich et al., 2002a,b; Shmulevich and Dougherty, 2009). Recently, stochastic Boolean networks (SBNs) have been proposed for an efficient modeling of GRNs (Liang and Han, 2012). As in stochastic computation, an SBN employs random binary bit streams for the analysis of a PBN. To further exploit the simplicity of BNs, stochastic multiple-valued networks have been proposed for an efficient evaluation of gene networks with multiple discrete values (Zhu and Han, 2014). Context-sensitivity has also been considered (Zhu, et al., 2014).
For simplicity, the Boolean models usually consider a synchronous update of all genes' states in a network (Remy et al., 2006; Naldi et al., 2007). In biology, this is not necessarily the case because the expression of a gene is seldom an instantaneous process. Instead, it may require a few milliseconds or even up to a few seconds (Greil et al., 2007); this makes a synchronous model less realistic. In fact, an analysis of the stability of attractors has shown that some attractors may disappear in a BN model with gene perturbation (Klemm and Bornholdt, 2005). This indicates that these attractors may be the result of artifacts because of the synchronous updating rules. An asynchronous state update has therefore been suggested to reduce the artifacts. However, a larger number of transitory states are usually required for deriving an attractor with an asynchronous update strategy; thus, the determination of attractors becomes particularly difficult for a large network. In this article, stochastic computational models are utilized for deriving the steady-state distributions (SSDs) as estimates of the attractors of an asynchronous regulatory network.
Biological systems are susceptible to stochastic fluctuations, which present an important characteristic of gene networks, because it contributes to determine the SSDs of a cell population (Zhang et al., 2007). In the studies by Ribeiro and Kauffman (2007) and Willadsena and Wiles (2007), stochasticity is modeled as the perturbation of a gene's state that occurs with certain probability; however, this stochasticity in node (SIN) model overexpresses the effect of noise. A stochasticity in function (SIF) model is therefore proposed by Garg et al. (2009) and the differences between the SIN and SIF models are explicitly discussed. In a SIN model, the correlation between a node's current expression level and the probability of changing the expression is not taken into consideration; thus, a model of stochasticity with propensity parameters (SPP) is proposed by Murrugarra et al. (2012). In this model, two probabilities are assigned such that each indicates the likelihood that an update leads to an increase or decrease of the current state.
In this article, asynchronous SBNs (ASBNs) are proposed as asynchronous gene network models. In an ASBN, a number of genes are updated simultaneously or in a different order (Harvey and Bossomaier, 1997; Garg et al., 2008; Wu et al., 2009; Luo and Wang, 2013). An asynchronous update module (AUM) is first proposed to implement the asynchronous update of a gene's state. Various asynchronous update strategies that involve a different number of genes to be updated in certain order are then implemented by using randomly generated stochastic sequences. The long run behaviors of synchronous and asynchronous networks are investigated using ASBNs; comparisons between different asynchronous update strategies are performed. The efficiency of the ASBN is evaluated by a comparison to a simulation-based method (Garg et al., 2008). To analyze the long run behavior of an asynchronous network, the so-called time-frame expansion technique (Liang and Han, 2012; Zhu and Han, 2014) is applied to efficiently compute the SSD. The simulation results of a T helper network of 23 genes show the robustness of its attractors under various state-update strategies.
2. Synchronous and Asynchronous Boolean Networks
A BN can model the relationships among gene nodes by Boolean logic operations (Kauffman, 1969). A PBN of n genes is defined by G(V, F), where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$V = \{x_1 , x_2 , \ldots , x_n \} $$\end{document} with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$x_i \in \{0 , 1 \} $$\end{document} for \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$i \in \{1 , 2 , \ldots , n \} $$\end{document}, a set of binary nodes, and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$F = \{F_1 , F_2 , \ldots , F_n \} $$\end{document}, a list of sets of update functions: Fi, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$i \in \{1 , 2 , \ldots , n \} $$\end{document} (Shmulevich and Dougherty, 2009; Kim et al., 2002). For a BN, a node xi represents the state of gene i; if xi = 1 (or 0), then gene i is (or not) expressed. The predictor function Fi contains the rules that determine the next state of gene i. If the quantization level of the gene node is not limited to binary values, a multiple-valued network can be constructed to model the relationship among genes for reducing the inaccuracy incurred by the Boolean simplification (Kim et al., 2002; Li and Cheng, 2010).
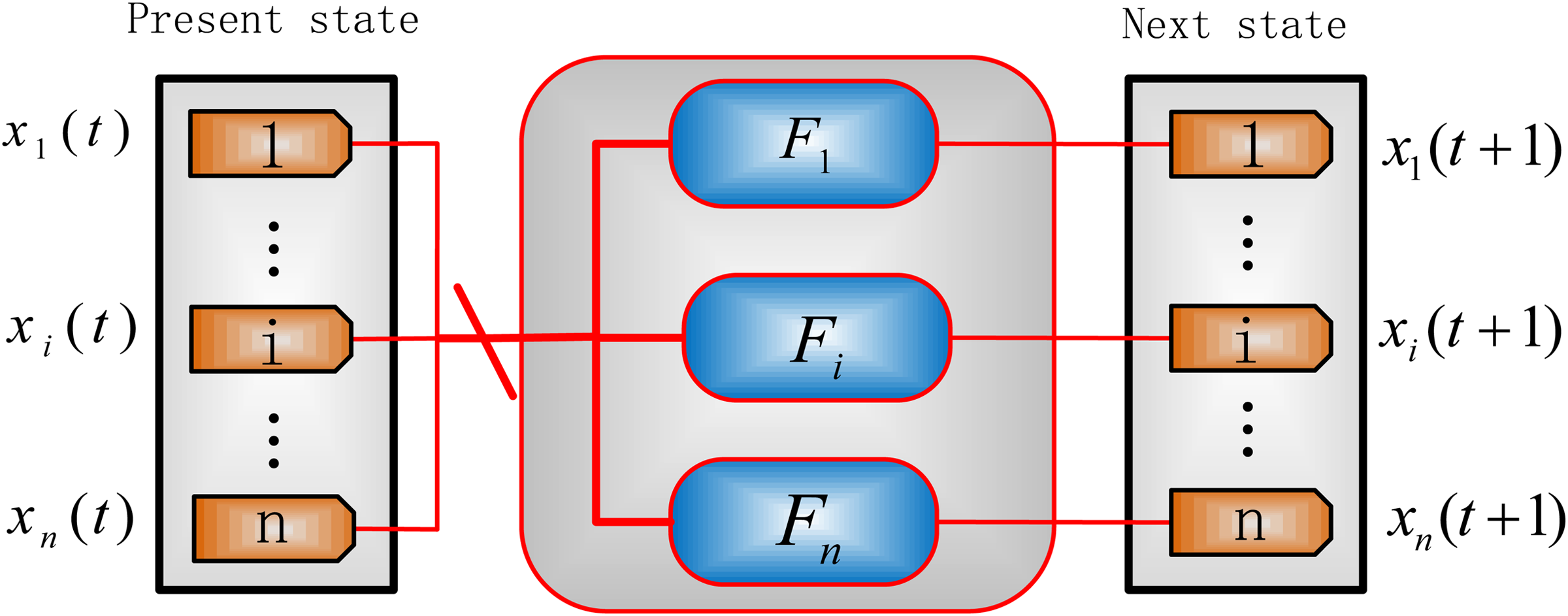
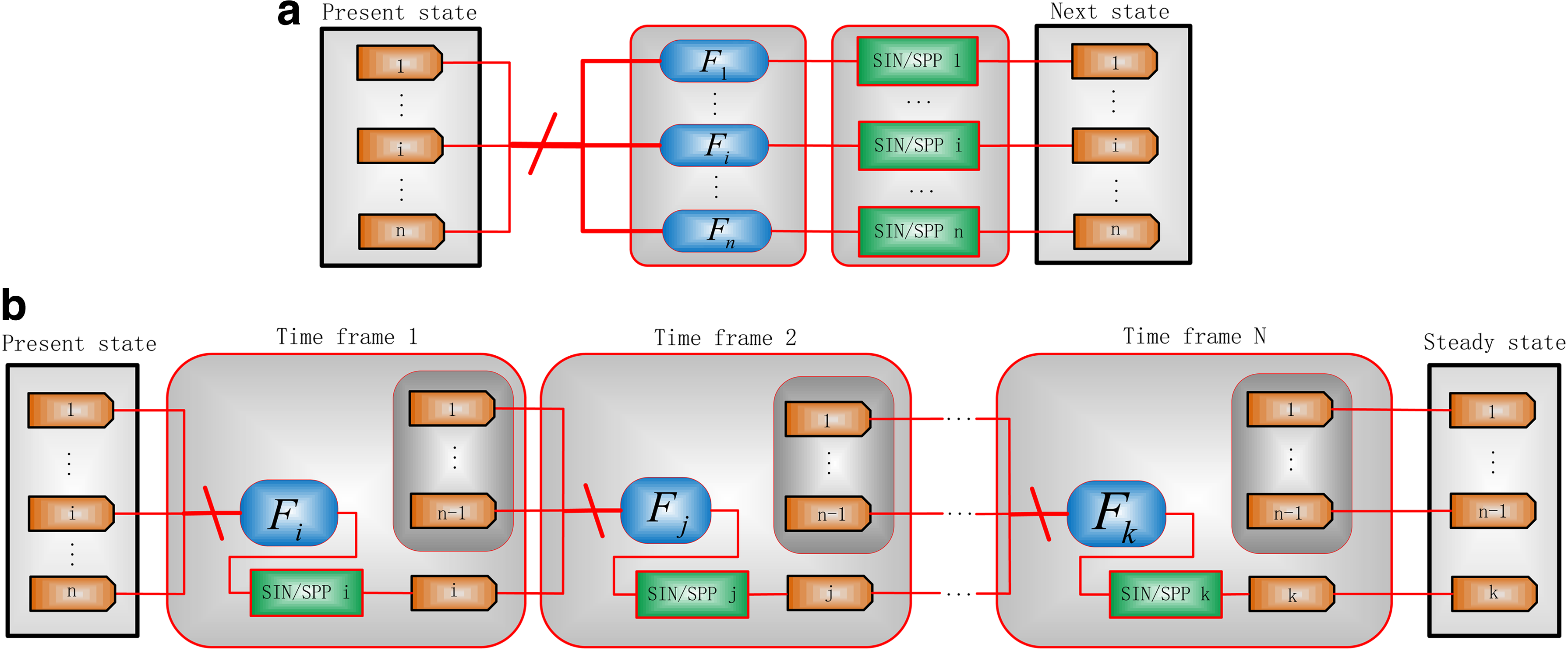
A network model is presented in Figure 1 for a deterministic synchronous update strategy. If Fi, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$i \in \{1 , 2, \ldots , n \} $$\end{document}, consists of several update functions with different selection probabilities, this network becomes a (synchronous) probabilistic network (Kim et al., 2002; Shmulevich and Dougherty, 2009).
A general synchronous gene network model. Fi denotes the update function for gene i; xi (t) and xi (t + 1) are the states of gene i at time t and t + 1, respectively, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$i \in \{1 , 2 , \ldots , n \} $$\end{document}. n is the number of genes in the investigated network.
When asynchronicity is considered, a deterministic-asynchronous PBN (DA-PBN) assumes that the state of each gene is independently updated according to its own updating period (Shmulevich and Dougherty, 2009). Whether the state of gene i is updated or not at a time is indicated by a binary variable c (either 1 or 0, respectively). The next state of gene i, xi(t + 1), is then given by
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}x_i ( t + 1 ) = \begin{cases}f^{( i )} ( x_1 ( t ) , \ldots , x_n ( t ) ) \quad \, if \ c = 1 , \\ \ \qquad x_i ( t ) \quad \qquad \qquad {\rm otherwise}\end{cases} \tag{1}\end{align*}\end{document}
where f (i) is the predictor function in the DA-PBN for gene i; c is a binary variable that determines whether a gene is to be updated or not.
Furthermore, a different number of genes can be selected in an asynchronous update process. The genes can be updated at the same time in one time step or following certain updating order. In the work of Harvey and Bossomaier (1997) and Garg et al. (2008), only one gene is randomly selected at a time for updating its state, while in Luo and Wang (2013), m gene nodes are randomly chosen for a simultaneous state update in one time step, where m is a randomly generated number. Even in one time step, however, the update of m genes is likely to be asynchronous and the state of a gene depends on the updating order of the inputs of its predictor function. In the study of Wu et al. (2009), all the gene nodes are asynchronously updated one by one, so an updated state will subsequently affect the other components' states, even within the same time step. Hence, an asynchronous update model is more realistic in modeling biological behaviors. Since the next state of a network is determined by the updated gene and the remaining genes, an updated gene state is determined by the current state vector and the corresponding predictor function (Garg et al., 2008).
3. Stochastic Logic
Stochastic computation has been utilized to perform probabilistic analysis through the application of Boolean logic by encoding a real number or probability into a random binary bit stream (Gaines, 1969). These random binary bit streams introduce inevitable stochastic fluctuations into the computation, thus making the computational result nondeterministic. However, the use of non-Bernoulli sequences of fixed numbers of 1's and 0's for encoding initial input probabilities can reduce the stochastic fluctuation and produce more accurate results than the use of Bernoulli sequences (Han et al., 2013). Moreover, a stochastic computational approach efficiently handles signal correlation in a logic network.
Stochastic computational models are first utilized in SBNs for modeling GRNs (Liang and Han, 2012). To reduce the inaccuracy incurred in a binary analysis, multiple-valued logic has been considered to generalize the stochastic analysis (Zhu and Han, 2014). In a k-valued gene network, randomly permuted sequences of fixed numbers of the k values are used. The use of the randomly permuted sequences as initial inputs can reduce the inevitable stochastic fluctuation and produce more accurate results than using randomly generated sequences.
The stochastic logic elements used in this article are listed in Figure 2, including a buffer, an inverter, AND, OR, and a multiplexer (MUX) (Liang and Han, 2012). For synchronous and asynchronous networks, stochastic architectures can be constructed for GRNs with update functions implemented by the stochastic logic gates in Figure 2.
Stochastic logic: (a) a buffer, (b) an inverter, (c) an AND gate, (d) an OR gate, (e) an XOR gate, and (f) a multiplexer. Stochastic logic performs a probabilistic analysis by encoding probabilities into random bit streams as proportional numbers of different values.
4. Stochastic Computational Models for Asynchronous Update Strategies
In a biological system, some cells may update their states immediately, while it may take longer for other cells to respond. This phenomenon corresponds to a variable reaction time or rate for each cell. To model this asynchronous process, a 2-to-1 multiplexer is used to determine whether a gene's state is updated or not, as determined by the value of the control bit Si, shown in Figure 3. If the control bit Si is 1, where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$i \in \{1 , 2 , \ldots , n \} $$\end{document} and n is the number of genes, then the ith gene's state is determined by the input genes' states and the predictor function Fi [i.e., \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$F_i ( x_1 ( t ) , \ldots , x_n ( t ) )$$\end{document}]. If Si = 0, the gene remains at its current state, indicated by the application of the buffer in Figure 3 [i.e., xi (t + 1) = xi (t)]. Hence, the stochastic model in Figure 3 accurately implements the function of Equation 1.
An asynchronous update module (AUM) for gene i, referred to as AUMi, consists of a 2-to-1 multiplexer (MUX) with a control bit Si. Fi is the predictor function for gene i. \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$x ( t ) = \{x_1 ( t ) , \ldots , x_i ( t ) , \ldots , x_n ( t ) \} $$\end{document} with xi (t) being the state of gene i at time t, while xi (t + 1) indicates the next state of gene i, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$i \in \{1 , 2 , \ldots , n \} $$\end{document}. n is the number of genes in the investigated network.
Stochastic architectures for asynchronous networks can be constructed with the control sequences of the MUX that are generated according to the updating rules. The state transition matrices (STMs) are usually applied to derive the SSD by an iterative evaluation, especially for synchronous models. However, a matrix-based analysis becomes cumbersome to perform because of the size of STMs for a large network; an analysis using STMs becomes even more challenging for asynchronous networks. Hence, the SSD is evaluated by using the so-called time-frame expansion technique (Liang and Han, 2012). By this technique, the temporal evolution of an asynchronous network is simulated using a spatially iterative structure of the asynchronous network model.
Different strategies of updating one gene or m genes synchronously or in a random order are presented as follows:
• The ROG (randomly one gene) model (Garg et al., 2008): At each time step, only one gene node is randomly selected for a state update, while the remaining nodes stay at their present states.
• The RMG (randomly m genes) model (Luo and Wang, 2013): At each time step, m gene nodes are randomly selected and synchronously updated, while the remaining nodes preserve their present values. Here, m can be either a random number or a fixed value. If m = 1, the RMG model is simplified to the ROG model.
• The ARO (all genes updated in a random order) model (Wu et al., 2009): At each time step, all gene nodes are updated; however, the state update of each gene occurs one by one in a random order. The update is carried out immediately and a state change will affect the change of other genes' states, even within the same time step.
• The MRO (m genes updated in a random order) model: At each time step, only m gene nodes are randomly selected for updating their states, and each state update occurs in a random order, while the other genes remain at their present states. If m = 1, this is simplified to the ROG model. If m = n, the result will be the same as the ARO model.
The general architectures are similar for the ROG and RMG models; the only difference lies in the control sequences \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$\{S_1 , S_2 , \ldots , S_n \} $$\end{document} for the 2-to-1 MUXs, where Si indicates the control sequence for gene \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$i \in \{1 , 2 , \ldots , n \}$$\end{document}. For the control sequences of AUMs in the ROG model, if the kth bit in the control sequence Si is 1, that is, Si,k = 1, then Sj,k = 0 for j ≠ i, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$i , j \in \{1 , 2 , \ldots , n \}$$\end{document}, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$k \in \{1 , 2 , \ldots , L \}$$\end{document} with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$\sum \nolimits_{i = 1}^n S_{i , k} = 1$$\end{document} as only one gene is selected for updating its state, where L indicates the length of the control sequences. In contrast, the requirement of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$\sum \nolimits_{i = 1}^n S_{i , k} = m$$\end{document} must be met for the RMG model as m gene nodes are randomly selected for updating the states using the control sequences.
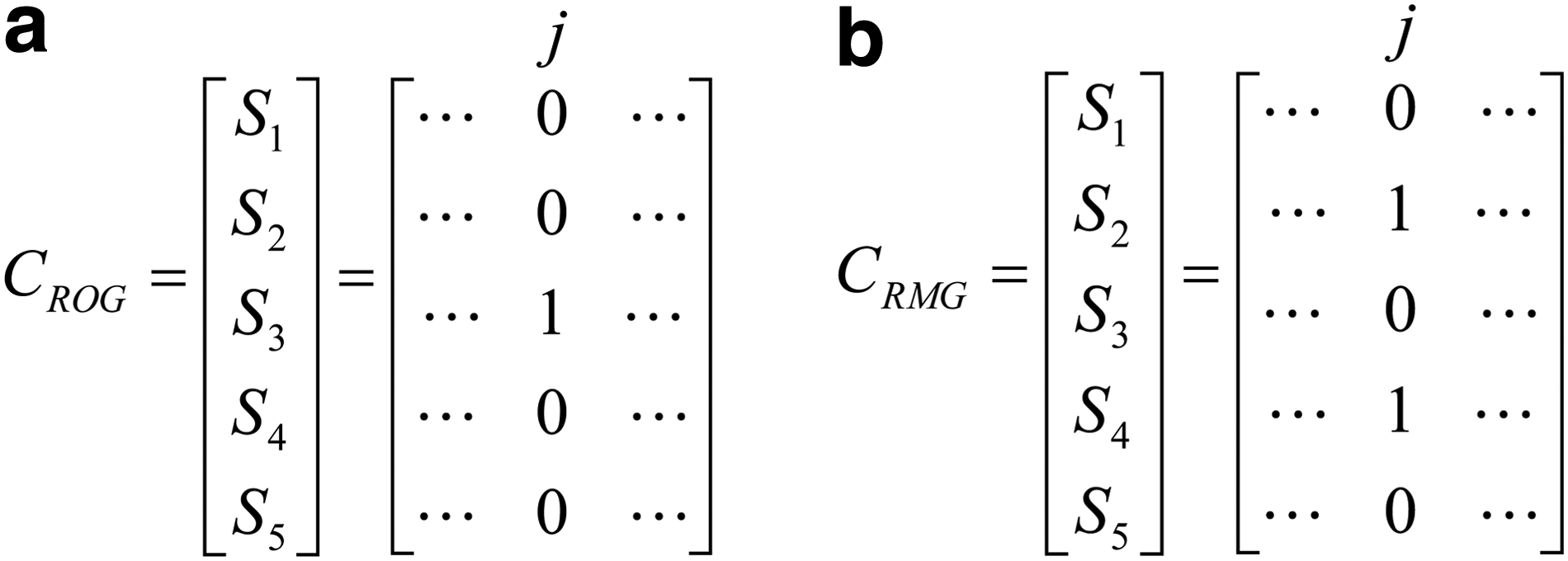
The generation of the stochastic control sequences for the AUMs is explained next with an example of a five-gene network using the ROG and RMG models. Let the number of genes to be updated for the RMG model, that is, m, be 2. For each column of the generated sequence matrix, only one gene is updated for the ROG model while two gene nodes are randomly selected to be refreshed for \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$j \in \{1 , 2 , \ldots , L \}$$\end{document} for the RMG model. At certain time step, let the generated control sequences be CROG and CRMG for the ROG and RMG models, respectively, as illustrated in Figure 4.
An illustrative example of the generated control sequences at a time step for a network of five genes. (a) The control sequences for the randomly one gene (ROG) model. (b) The control sequences for the randomly m genes (RMG) model. Si indicates the control sequence for gene i, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$i \in [ 1 , 5 ]$$\end{document}; j is for the jth bit in each sequence, which can be considered as the jth trial of the L experiments, and L indicates the length of the stochastic sequences and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$j \in \{1 , 2 , \ldots , L \} $$\end{document}. Si,j = 0 indicates that the control bit is 0 for the AUM in Figure 3, so the state of gene i remains, while Si,j = 1 means that the next state is determined by the predictor function Fi. For the RMG model, the number of genes to be updated for the jth trail is assumed to be two; thus, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$\sum \nolimits_{i = 1}^5 S_{i , j} = 2$$\end{document} in (b).
For the ARO and MRO models, similarly, the evolution of an asynchronous network is simulated by the time-frame expansion technique. In the ARO model, as all genes are updated in a random order, each time step is divided into n substeps and only one gene is chosen to be updated at each substep, while the other genes maintain their present states. Assume at time t, only one gene is updated at each substep (n substeps in total); hence, after the evolution of n substeps, all the genes are updated, followed by the evolution at time t + 1. The ARO model is implemented with only one AUM with a control bit of 1 at each substep for the gene to be updated (the AUM is simplified to a buffer as the control bit is 0 for the other genes). If m genes are to be updated in a different order, there will be n–m buffers (or AUMs with a control bit of 0) for the n substeps. This becomes an MRO model.
For the ARO model, at each substep, only one gene is updated, while the others preserve their present states. If Si,k = 1, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$i \in \{1 , 2 , \ldots , n \} $$\end{document}, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$k \in \{1 , 2 , \ldots , L \}$$\end{document}, the ith gene's state is updated by the predictor function; otherwise, the current state remains. For the MRO model, the total number of 1's for the n substeps at time step t is equal to the number of genes to be updated for the MRO model. All genes remain at their present states if the control bits for the AUMs are 0 at a time step. The updating order is indicated by the different position of 1's in the generated sequences.
An example of the random updating order for the AUMs at time t is illustrated for a network of five genes. Following the previous analysis, time step t is divided into five substeps. The control sequences of CARO and CMRO for the ARO and MRO models are shown in Figure 5a and b, respectively.
An illustrative example of the generated control sequences at a time step for a network of five genes. (a) The control sequences for the all genes updated in a random order (ARO) model. (b) The control sequences for the m genes updated in a random order (MRO) model. t is for the tth time step and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$t_1 , \ldots , t_5$$\end{document} are the substeps at time t. \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$C_{ARO_{t}}$$\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$C_{MRO_{t}}$$\end{document} are the generated control sequences at the substeps within time t. An entry of 0 indicates that the state of gene i remains, while a value of 1 indicates that the next state is determined by the predictor functions. The number of genes to be updated at time t is three (in a random order); thus, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$\sum \ C_{MRO_{t}} = 3$$\end{document} in (b).
The updating order of the ARO model at time t is given by the control sequences in Figure 5a, that is, x1 →x4 → x5 → x3 → x2, while the updating order of the MRO model at time step t is x3 → x5 → x1, as given by the control sequences in Figure 5b. For genes x2 and x4, the present states at time t remain the same.
5. Asynchronous Stochastic Boolean Networks
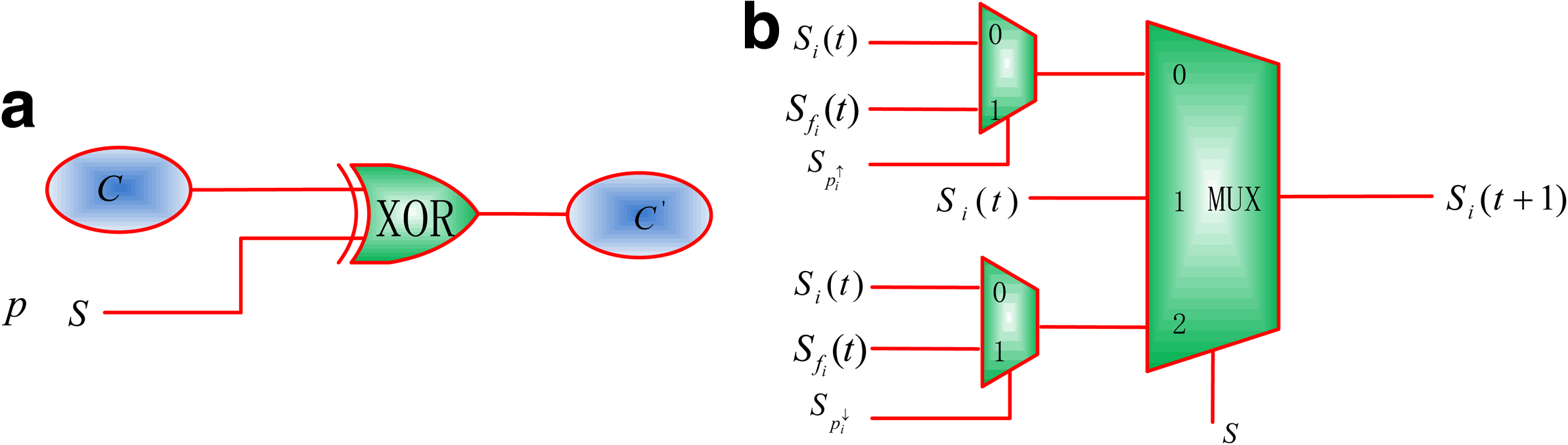
Any gene in a GRN can change the expression level because of noise or a gene perturbation that occurs with certain probability. The perturbation probability can be encoded as a perturbation flag vector γ with each element indicating whether a gene is to be perturbed or not. When a perturbation occurs, the state of the perturbed gene is determined by the present state and the perturbation flag vector. In the SIN model (Garg et al., 2009), therefore, the effect of perturbation can be modeled by an XOR gate (Liang and Han, 2012), by which the gene state at time t will be flipped with a probability of p, as shown in Figure 6a.
Stochastic architectures for the models of stochasticity in node (SIN) and stochasticity with propensity parameter (SPP). (a) The stochastic architecture of the SIN model for a binary gene node (Liang and Han, 2012). (b) The stochastic architecture of the SPP model for updating the state of a gene.
In the SIN model, the correlation between a gene node's current expression level and the probability of changing the expression value is not taken into consideration. Even if the expression level of the input node for an update function guarantees the activation or degradation, there still exists a probability that the process will not occur because of stochasticity. Hence, a stochasticity model is proposed by Murrugarra et al. (2012) with propensity parameters,
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}F = \{f_i , p_i^ \uparrow , p_i^ \downarrow \} _{i = 1}^n , \tag{2}\end{align*}\end{document}
where fi indicates the update function for node xi, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${{0}} \le {p_i^ \uparrow} \le {1}$$\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$${{0}} \le {p_i^ \downarrow} \le {1}$$\end{document} denote the activation propensity and degradation propensity, and n is the number of genes. A model of SPP is described by Murrugarra et al. (2012).
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}x_i \rightarrow f_i ( x ) = \begin{cases}p_i^ \uparrow \qquad x_i < f_i ( x ) \\ p_i^ \downarrow \qquad x_i > f_i ( x ) \\ 1 \qquad x_i = f_i ( x ) \end{cases} \tag{3}\end{align*}\end{document}
In order to implement the function of Equation 3, a multiplexer is used here to simulate the behavior of stochasticity with parameters. A general structure is shown in Figure 6b.
For the architecture in Figure 6b, the output is determined by the value in the control sequence S. S consists of ternary values {0, 1, 2}, which indicate the three cases of Si(t) < Sfi(t), Si(t) = Sfi(t) and Si(t) > Sfi(t) for any \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$i \in \{1 , 2 , \ldots , n \} $$\end{document}. Si(t) and Si(t + 1) are the stochastic sequences encoding the probabilities of gene i at time t and t + 1, respectively. Sfi(t) is the stochastic sequence encoding the expected probability for the state of gene i at time t. This probability is calculated from fi(x(t)), where fi indicates the update function for gene i and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$x ( t ) = \{x_1 ( t ) , \ldots , x_i ( t ) , \ldots , x_n ( t ) \}$$\end{document} with xi(t) being the state of gene i at time t. \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$S_{p_{i}^{\uparrow}}$$\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$S_{p_{i}^{\downarrow}}$$\end{document} are the stochastic sequences encoding the propensity parameters.
Let (Si(t))j, (Sfi(t))j, and (Si(t + 1))j be the jth value in Si(t), \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$S_{f_{i}} ( t )$$\end{document}, and Si(t + 1). For a ternary case, if \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$( S_i ( t ) ) _j = ( S_{f_{i}} ( t ) ) _j$$\end{document}, the output (Si(t + 1))j is the same as (Si(t))j, because the transition \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$( S_i ( t ) ) _j \rightarrow ( S_{f_{i}} ( t ) ) _j$$\end{document} occurs with a probability of 1. However, if \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$( S_i ( t ) ) _j < ( S_{f_{i}} ( t ) ) _j$$\end{document}, (Si(t + 1))j is determined by the output of a 2-to-1 multiplexer with Si(t) and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$S_{f_{i}} ( t )$$\end{document} as input sequences and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$S_{p_{i}^{\uparrow}}$$\end{document} as the control sequence. If \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$( S_i ( t ) ) _j = 0 < ( S_{f_{i}} ( t ) ) _j = 1$$\end{document}, for example, then (Si(t + 1))j = 1 with a probability of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$p_{i}^{\uparrow}$$\end{document} and (Si(t + 1))j = 0 with a probability of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$1-p_{i}^{\uparrow}$$\end{document}. If \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$( S_i ( t ) ) _j > ( S_{f_{i}} ( t ) ) _j$$\end{document}, then \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$( S_i ( t + 1 ) ) _j = ( S_{f_{i}} ( t ) ) _j$$\end{document} with a probability of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$p_{i}^{\downarrow}$$\end{document} or (Si(t + 1))j = (Si(t))j with a probability of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$1 - p_{i}^{\downarrow}$$\end{document}. These functions are implemented by the 2-to-1 multiplexers in the model in Figure 6b. Let a and b be the values in (Si (t))j, and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$( S_{f_{i}} ( t ) ) _j$$\end{document}, respectively; the next state of the gene i is obtained as
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}\begin{align*}S_i ( t + 1 ) = \begin{cases} \qquad \qquad \qquad S_i ( t ) , \ {\rm if} \ a = b \\ S_{f_{i}} ( t ) \ {\rm with} \ p_{i}^{\uparrow} , \ {\rm or} \ S_i ( t ) \ {\rm with} \ 1 - p_{i}^{\uparrow} , \ {\rm if} \ a < b , \\ S_{f_{i}} ( t ) \ {\rm with} \ p_{i}^{\downarrow} , \ {\rm or} \ S_i ( t ) \ {\rm with} \ 1 - p_{i}^{\downarrow} , \ {\rm if} \ a > b\end{cases} \tag{4}\end{align*}\end{document}
which is equivalent to the function of Equation 3. This shows that the stochastic model in Figure 6b accurately computes the function of the SPP model. The model in Figure 6b is applicable in the general case when multiple-valued gene states are considered.
In order to analyze the long run behavior of gene networks with different stochasticity effects, synchronous and ASBNs are presented in Figure 7 for the SIN and SPP models. The synchronous network is obtained by implementing the stochasticity models (either the SIN in Fig. 6a or the SPP in Fig. 6b) into the architecture in Figure 1. For simplicity, only the ROG model is illustrated in Figure 7b for an ASBN. For RMG or a different updating order, the stochastic networks can be obtained by applying a stochasticity model (either the SIN in Fig. 6a or the SPP in Fig. 6b) into the stochastic architecture in Figure 7. Although discussed within the context of BNs, multiple-valued networks such as those in the work of Zhu and Han (2014) can also be used to construct an asynchronous network. In a stochastic network, randomly permuted sequence and perturbation vectors are generated for different signal probabilities. With these stochastic sequences as inputs to the stochastic architectures, the stochastic behavior of a gene network can be efficiently analyzed.
Synchronous and asynchronous stochastic Boolean networks (ASBNs) for different stochasticity models. (a) A synchronous SBN. (b) An ASBN for the ROG model. Fi: predictor function for gene i, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$i \in \{1 , 2 , \cdots , n \} $$\end{document}. n is the number of genes in the investigated network. The detailed structures and inputs of the SIN and SPP modules are shown in Figure 6a and b, respectively.
6. Results and Discussion
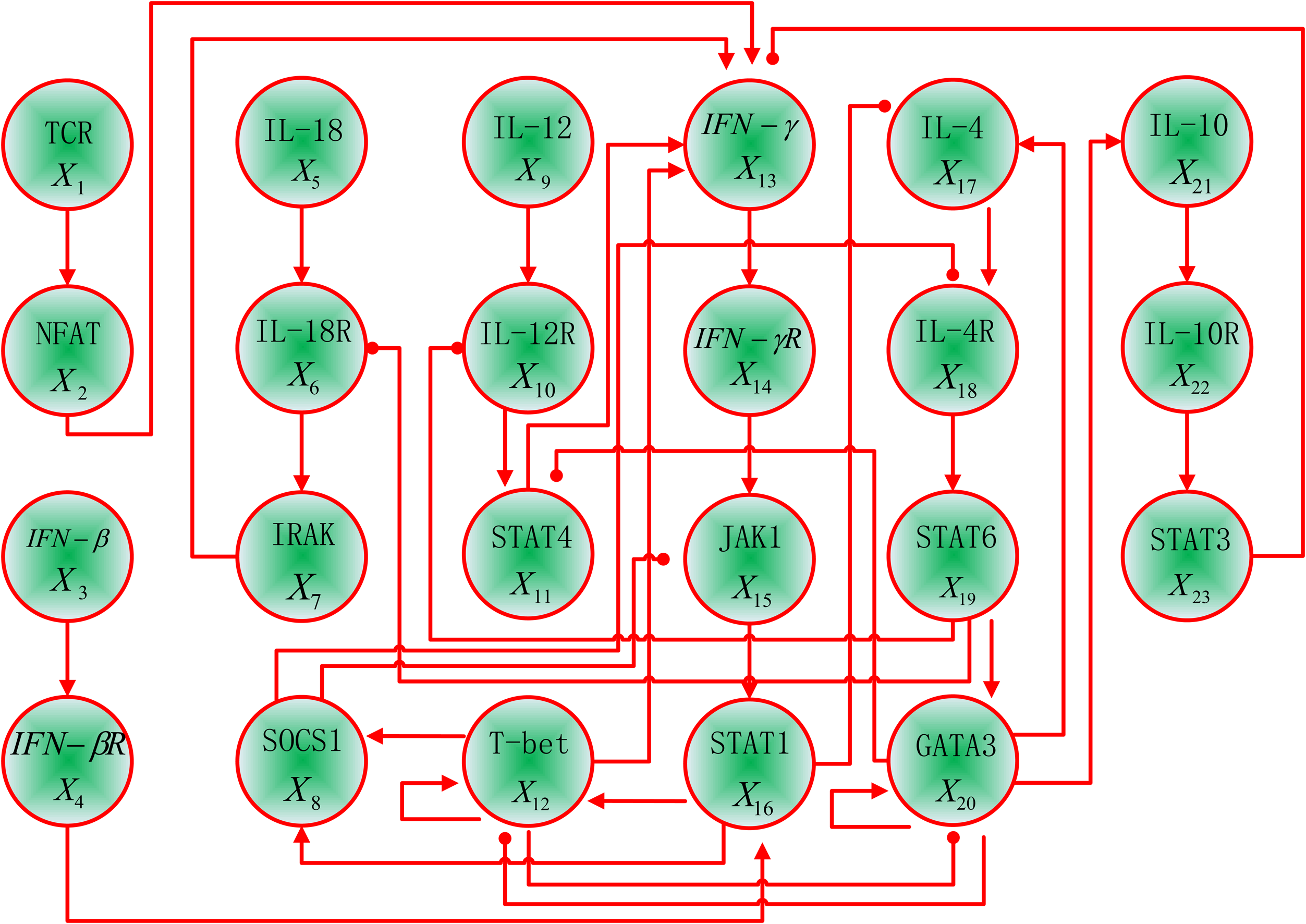
A T helper network of 23 genes with 35 regulatory interaction relationships (Fig. 8) (Mendoza and Xenarios, 2006) is considered to show the robustness of the attractors under the various asynchronous update schemes. The functional molecules or molecular complexes are listed as TCR, NFAT, IFN – β, IFN – βR, L – 18, IL – 18R, IRAK, SOCS1, IL – 12, IL – 12R, STAT4, T – bet, IFN – γ, IFN – γR, JAK1, STAT1, IL – 4, IL – 4R, STAT6, GATA3, IL – 10, IL – 10R, and STAT3.
A T helper network. A positive regulatory interaction is indicated by a regular arrow, while a negative interaction is represented by a blunted arrow (Mendoza and Xenarios, 2006).
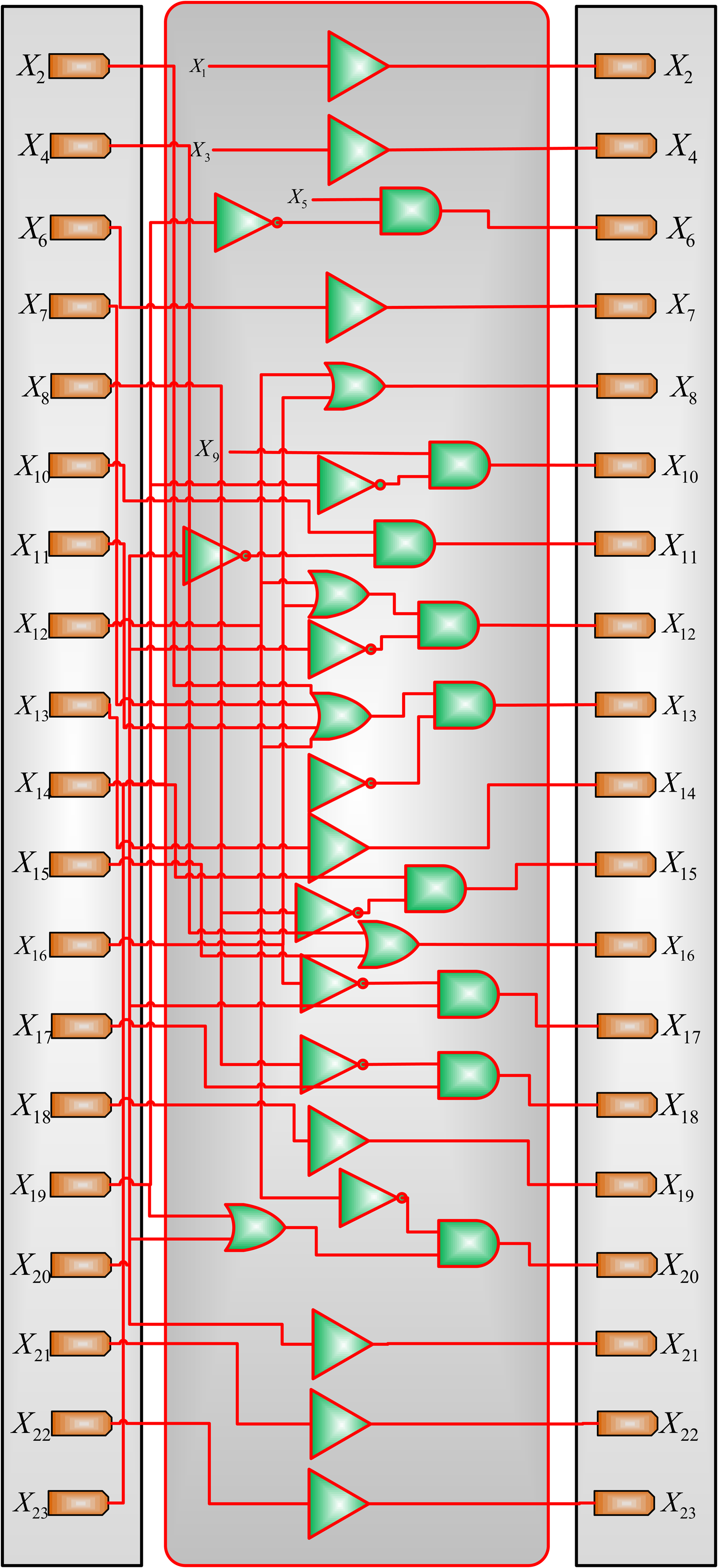
There is no input for four gene nodes, namely, IL – 12, IFN – β, IL – 18, and TCR, in the T helper network. As in the study of Mendoza and Xenarios (2006), hence, these four elements are considered to be consistently at state 0. The network in Figure 8 can be implemented by the BN model shown in Figure 9.
A deterministic BN model for the 23-gene T helper network, with X1 = 0, X3 = 0, X5 = 0, and X9 = 0. Xi, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$i \in \{1 , 2 , \ldots , 23 \} $$\end{document}, indicates a gene node in Figure 8.
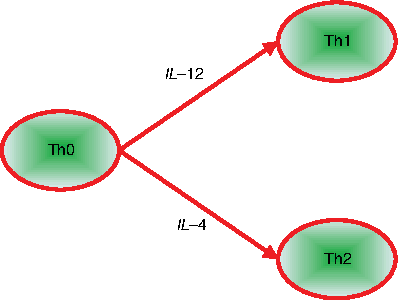
The cell population may fall into different subgroups on exposure to input stimuli—this is referred to as a cellular differentiation (Kaern et al., 2005). For the 23-gene T helper network in Figure 8, IL – 2 functions as a key cytokine in the Th0 to Th1 differentiation process, while a large perturbation of IL – 4 forces the network to switch from state Th0 to Th2, as illustrated by Figure 10.
Differentiation of T helper [adapted from Kaern et al. (2005)]. Th1 cells express IFN – γ and T – bet, while Th2 expresses GATA3 and IL – 4.
In the state space of the T helper network, the basins draining to different attractors are not evenly distributed; the distribution of initial states leading to the attractors is shown in Table 1. As revealed in Table 1, a random initial state evolves into Th1 with the largest probability for each state update strategy. The attractor Th0 is reached with the lowest probability. For the asynchronous update strategies, the probability of reaching Th0 is even lower than that for the synchronous state update.
The Distribution of Initial States (in Percentages) Leading to the Attractors of a Wild-Type T Helper Cell: 200,000 States Are Randomly Chosen for Simulation
Wild type
Th0 (%)
Th1 (%)
Th2 (%)
Synchronous
6.86
58.65
36.89
ROG
3.75
50.07
46.19
RMG (m = 10)
2.94
51.42
45.65
RMG (m = 21)
5.32
54.51
40.17
ARO
3.06
50.70
46.25
MRO (m = 10)
3.79
50.21
46.01
ARO, all genes updated in a random order; MRO, m genes updated in a random order; RMG, randomly m genes; ROG, randomly one gene.
The effect of perturbation on different gene nodes has been shown by experiments of the differentiation of T helper cells (Bergmann et al., 2001; Agnello et al., 2003). The stochastic simulations using synchronous and asynchronous update strategies correctly identify the attractors for a wild-type T helper network, in which no perturbation exists. Table 2 shows the steady states found by the stochastic approach for several scenarios of the wild type (no gene suppression or overexpression; the initial states are randomly generated with a probability of 0.5), IL – 12 overexpressed, and IL – 4 overexpressed. These steady states are good estimates of the attractors found in the works of Murphy and Reiner (2002) and Garg et al. (2008).
Steady States of the T Helper Network Found by the Stochastic Approach
Perturbed genes
Active genes in steady states
Attractors
Wild type
All genes are inactive
Th0
IFN – γ
T – bet
SOCS1
IFN – γR
Th1
IL – 10
IL – 10R
GATA3
STAT3
STAT6
IL – 4
IL – 4R
Th2
IL – 12 overexpressed
IFN – γ
T – bet
SOCS1
IFN – γR
IL – 12
IL – 12R
STAT4
Th1
IL – 10
IL – 10R
GATA3
STAT3
IL – 12
STAT6
IL – 4
IL – 4R
Th2
IL – 4 overexpressed
IFN – γ
T – bet
SOCS1
IFN – γR
IL – 4
Th1
IL – 10
IL – 10R
GATA3
STAT3
STAT6
IL – 4
IL – 4R
Th2
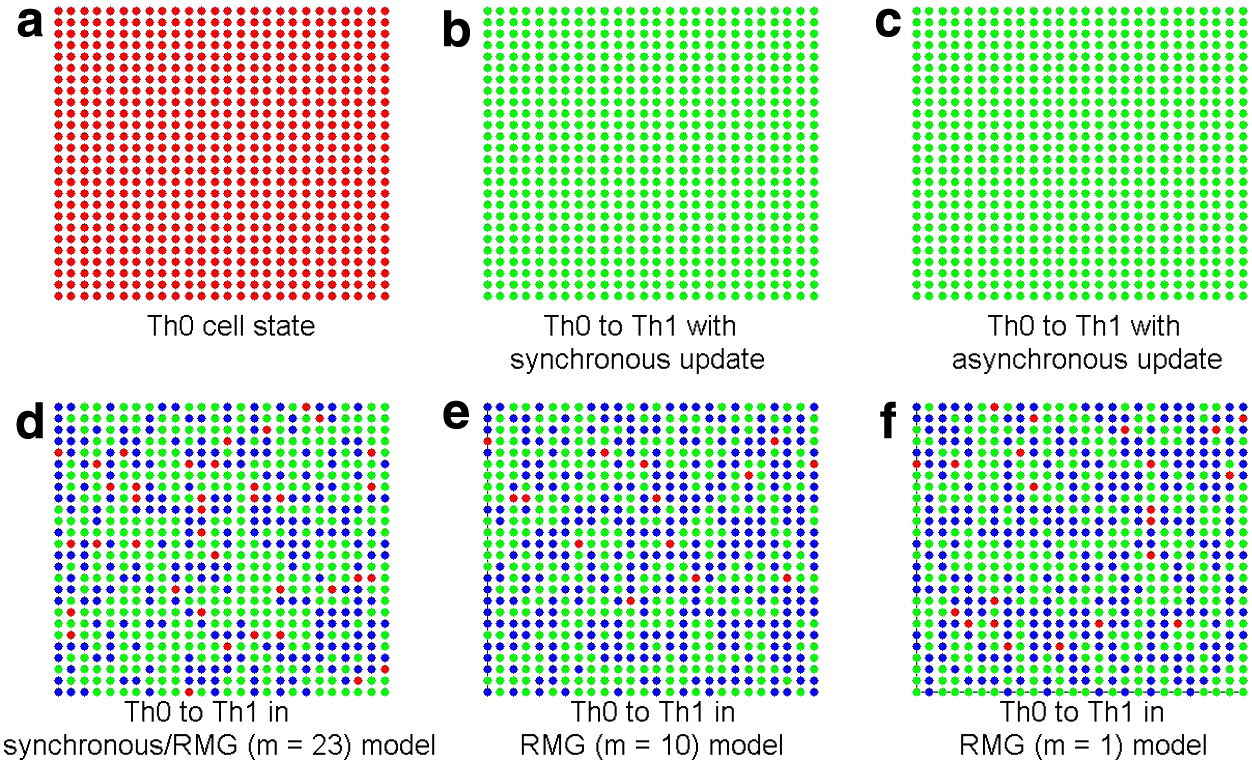
In the work of Garg et al. (2009), at most one perturbation is considered to occur at a time. In this work, k time frames are considered with the stochasticity models (k = 5 in Fig. 11). If the initial state of the T helper network is Th0, after the constant activation of IL – 12, the state will transit into Th1. As shown in Figure 11b and c, the state remains even after the inactivation of IL – 12 if no perturbation occurs. For the SIN model, the Th0 cells derive into Th1 and Th2, while a few cells remain at their current states. The almost equally likely cellular differentiation of steady states has been analyzed by Kadanoff et al. (2003). However, it has been shown that under IL-12, a Th0 cell cannot transfer into a Th2 cell (Murphy and Reiner, 2002). Hence, the SIN model could be the main reason for this discrepancy, because Th1 and Th2 are evolved from Th0 with nearly equal probability, as revealed in Figure 11d–f for the synchronous and RMG models.
Transitions between attractors during the differentiation process of the T helper network with an external stimulus of IL – 12 for the synchronous and RMG models. Each dot indicates a T helper cell and each cell is independent of the neighboring cells. A red dot represents an undifferentiated cell at Th0, a green dot indicates the cell state of Th1, and a blue dot indicates the state of Th2. (a) All cells are in the initial Th0 state. (b and c) The transitions from Th0 to Th1 by synchronous and asynchronous updating rules (without perturbation to the network). (d–f) The transitions from Th0 for the SIN model with perturbation probability of 0.5 for each node: the percentage of the corresponding nodes indicates the percentage of the cells deriving into an attractor. For the first five time frames, each of the gene nodes is subject to the effect of SIN. The obtained transition probabilities from Th0 to different attractors are similar to the values in Table 1, because it is equivalent to setting the initial state as the wild type by having each of the nodes under SIN for several time frames.
For the SPP model, the next state of a gene is closely related with the activity of other nodes, the predictor function, and the present states. The simulation results for this model are shown in Table 3 for an initial state of Th0. As revealed in the results, nearly all the nodes of Th0 differentiate into Th1 cells under the dosage of IL – 12. Similar results can be obtained for the dosage of IL – 4 and for the other asynchronous update strategies. The instability of Th0 is in agreement with the experimental results of Kaern et al. (2005).
The Transition Probability from the Initial State Th0 to an Attractor Using the Synchronous and RMG Models with an External Stimulus of IL– 12
Update strategies
Th0 → Th1
Th0 → Th2
Synchronous or RMG (m = 23)
1
0
RMG (m = 10)
1
0
ROG or RMG (m = 1)
1
0
If m = 1, the RMG model is simplified to the ROG model. The propensity parameters \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$p_{i}^{\uparrow}$$\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}$$p_{i}^{\downarrow}$$\end{document} are assumed to be 0.5 for each node in the model of stochasticity with propensity parameters.
7. Conclusion
In this article, ASBNs are proposed for an efficient modeling of GRNs. Various asynchronous updating rules are considered, including the models of ROG, RMG, ARO, and MRO. In an ASBN, if the control bits for an AUM are all 0's, an asynchronous network becomes the same as a synchronous update network. Stochastic analyses are carried out for the asynchronous models of SIN and SPP. The expected long run behavior of a GRN is studied by the stochastic approach for various asynchronous state update strategies.
For an asynchronous gene network, an accurate analysis becomes difficult because of the limitation of computational resources, especially when the number of genes or the quantization level of gene states increases. In the stochastic approach, a simulation-based time-frame expansion technique is used for an efficient analysis of the SSD of a network. The obtained SSDs can be used to estimate the attractors of, especially, a large network. This is shown by the study of a T helper network of 23 genes. The robustness of the attractors for the T helper network is demonstrated for a number of synchronous and asynchronous state update strategies. The effect of different asynchronous updating rules on the distribution of initial states leading to an attractor is investigated for the T helper network. It is shown that the model of SPP accurately reveal the state transition from Th0 to Th1 under the dosage of IL – 12.
Footnotes
Author Disclosure Statement
No competing financial interests exist.
References
1.
AgnelloD., LankfordC.S.R., BreamJ., et al. 2003. Cytokines and transcription factors that regulate T helper cell differentiation: new players and new insights. J. Clin. Immunol., 23, 147–161.
2.
BergmannC., Van HemmenJ.L., and SegelL.A.2001. Th1 or Th2: how an appropriate T helper response can be made. Bull. Math. Biol., 63, 405–430.
3.
ChenK.C., et al. 2004. Integrative analysis of cell cycle control in budding yeast. Mol. Biol. Cell, 15, 3841–3862.
4.
de JongH.2002. Modeling and simulation of genetic regulatory systems: a literature review. J. Comput. Biol., 9, 67–103.
5.
GainesB.R.1969. Stochastic computing systems. In TouJ., ed. Advances in Information Systems Science, Vol. 2. New York: Plenum Press, pp. 37–172.
6.
GargA., Di CaraA., XenariosI., et al. 2008. Synchronous versus asynchronous modeling of gene regulatory networks. Bioinformatics, 24, 1917–1925.
7.
GargA., MohanramK., Di CaraA., et al.2009. Modeling stochasticity and robustness in gene regulatory networks. Bioinformatics, 25, i101–i109.
8.
GillespieD.T.1976. A general method for numerically simulating the stochastic time evolution of coupled chemical reactions. J. Comput. Phys., 22, 403.
9.
GillespieD.T.1977. Exact stochastic simulation of coupled chemical reactions. J. Phys. Chem., 81, 2340–2361.
10.
GreilF., DrosselB., and SattlerJ.2007. Critical Kauffman networks under deterministic asynchronous update. N. J. Phys., 9, 373.
11.
HanJ., ChenH., LiangJ., et al. 2013. A stochastic computational approach for accurate and efficient reliability evaluation. IEEE Trans. Comput. In press.
12.
HarveyI., and BossomaierT.1997. Time out of joint: attractors in asynchronous random Boolean networks. In Proceedings of the Fourth European Conference on Artificial Life (ECAL97). MIT Press, New York, pp. 67–75.
13.
KadanoffL., et al. 2003. Boolean Dynamics with Random Couplings. Springer Applied Mathematical Sciences Series, Special Volume. Springer, New York, pp. 23–89.
14.
KaernM., et al. 2005. Stochasticity in gene expression: from theories to phenotypes. Nat. Rev. Genet., 6, 451–464.
15.
KarlebachG., and ShamirR.2008. Modelling and analysis of gene regulatory networks. Nat. Rev. Mol. Cell Biol., 9, 770–780.
16.
KauffmanS.A.1969. Metabolic stability and epigenesis in randomly constructed genetic nets. Theor. Biol., 22, 437–467.
17.
KimS., LiH., DoughertyE.R., et al.2002. Can Markov chain models mimic biological regulation?. J. Biol. Syst., 10, 337–357.
18.
KlemmK., and BornholdtS.2005. Stable and unstable attractors in Boolean networks. Phys. Rev. E, 72, 055101.
19.
LiS., et al. 2008. A quantitative study of the division cycle of Caulobacter crescentus stalked cells. PLoS Comput. Biol., 4, e9.
20.
LiZ., and ChengD.2010. Algebraic approach to dynamics of multivalued networks. Int. J. Bifurcation Chaos, 20, 561–582.
21.
LiangJ., and HanJ.2012. Stochastic Boolean networks: an efficient approach to modeling gene regulatory networks. BMC Syst. Biol., 6, 113.
22.
LuoC., and WangX.2013. Dynamics of random Boolean networks under fully asynchronous stochastic update based on linear representation. PLoS One, 8, e66491.
23.
MendozaL., and XenariosI.2006. A method for the generation of standardized qualitative dynamical systems of regulatory networks. Theor. Biol. Med. Model., 3, 13.
24.
MurphyK.M., and ReinerS.L.2002. The lineage decisions on helper T cells. Nat. Rev. Immunol., 2, 933–944.
25.
MurrugarraD., Veliz-CubaA., and AguilarB.2012. Modeling stochasticity and variability in gene regulatory networks. EURASIP J. Bioinform. Syst. Biol., 1, 5.
26.
NaldiA., et al. 2007. Decision diagrams for the representation and analysis of logical models of genetic networks. LNCS/LNBI, 4695, 233–247.
27.
QianL., WangH., and DoughertyE.2008. Inference of noisy nonlinear differential equation models for gene regulatory networks using genetic programming and Kalman filtering. IEEE Trans. Signal Process., 56, 3327–3339.
28.
RemyE., et al. 2006. From logical regulatory graphs to standard petri nets: dynamical roles and functionality of feedback circuits. Springer LNCS, 4230, 56–72.
29.
RibeiroA.S., and KauffmanS.A.2007. Noisy attractors and ergodic sets in models of gene regulatory networks. J. Theor. Biol., 247, 743–755.
30.
ShmulevichI., and DoughertyE.R.2009. Probabilistic Boolean Networks: The Modeling and Control of Gene Regulatory Networks. SIAM, Philadelphia.
31.
ShmulevichI., DoughertyE.R., and ZhangW.2002a. From Boolean to probabilistic Boolean networks as models of genetic regulatory networks. Proc. IEEE, 90, 1778–1792.
32.
ShmulevichI., DoughertyE.R., and ZhangW.2002b. Gene perturbation and intervention in probabilistic Boolean networks. Bioinformatics, 18, 1319–1331.
33.
WilladsenaK., and WilesJ.2007. Robustness and state-space structure of Boolean gene regulatory models. J. Theor. Biol., 249, 749–765.
34.
WuM., YangX., and ChanC.2009. A dynamic analysis of IRS-PKR signaling in liver cells: a discrete modeling approach. PLoS One, 4, e8040.
35.
ZhangS., et al. 2007. Simulation study in probabilistic Boolean network models for genetic regulatory networks. Int. J. Data Min. Bioinformatics, 1, 217–240.