The problem of superposition of two corresponding vector sets by minimizing their sum-of-squares error under orthogonal transformation is a fundamental task in many areas of science, notably structural molecular biology. This problem can be solved exactly using an algorithm whose time complexity grows linearly with the number of correspondences. This efficient solution has facilitated the widespread use of the superposition task, particularly in studies involving macromolecular structures. This article formally derives a set of sufficient statistics for the least-squares superposition problem. These statistics are additive. This permits a highly efficient (constant time) computation of superpositions (and sufficient statistics) of vector sets that are composed from its constituent vector sets under addition or deletion operation, where the sufficient statistics of the constituent sets are already known (that is, the constituent vector sets have been previously superposed). This results in a drastic improvement in the run time of the methods that commonly superpose vector sets under addition or deletion operations, where previously these operations were carried out ab initio (ignoring the sufficient statistics). We experimentally demonstrate the improvement our work offers in the context of protein structural alignment programs that assemble a reliable structural alignment from well-fitting (substructural) fragment pairs. A C++ library for this task is available online under an open-source license.
1. Introduction
Optimal superposition of two corresponding vector sets is a commonly used method to measure spatial similarity of three-dimensional (3D) objects. In this method, treating both the vector sets as rigid bodies, one set is rotated and translated to fit on another. Such superposition of vector sets permits the evaluation of shape similarity both qualitatively and visually. A nearly universal criterion of optimality for the superposition problem is the one that minimizes the sum of squared deviations between the corresponding vectors after superposition (or least-squares superposition, in short). This yields a reliable quantitative measure of similarity, the root mean square deviation (or r.m.s.d.) between vector sets (Eidhammer et al., 2004; Lesk, 2000, 2001).
Many approaches to address the least-squares superposition problem in three dimensions (3D) have been proposed over the years (Cohen, 1997; Coutsias et al., 2004; Cox, 1967; Diamond, 1988; Kabsch, 1976, 1978; Kearsley, 1989; KenKnight, 1984; Koehl, 2001; Lesk, 1986; Mackay, 1984; McLachlan, 1972, 1982). It is indeed remarkable that this problem can be solved exactly and efficiently, and involves a computational effort that grows linearly with the number of correspondences in the vector sets. Noteworthy of the approaches to solve the superposition problem is the method by Kabsch (1976) that allows computing the optimal transformation via singular value decomposition of a covariance matrix derived from the coordinates of the corresponding vector sets. An equivalent, and more analytically elegant, approach for this problem proposed by Kearsley (1989) uses the algebra of quaternions (Hamilton and Hamilton, 1866). Quaternions are generalizations of complex numbers with direct applications to orthogonal transformations in three-dimensional (3D) space. Specifically, the space group corresponding to unit quaternions is equivalent to the group of all possible proper 3D rotations defined about an arbitrary origin. Any pure rotation in 3D by an angle θ about some normalized axis \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${\hat {\textbf{\textit{n}}}}$$
\end{document} passing through the origin can be represented using a unit quaternion denoted by \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\left[ \rm cos \left( \frac { \theta } { 2 } \right), {\hat
{\textbf{\textit{n }}}} \rm sin \left( \frac { \theta } { 2 }
\right) \right]$$
\end{document}. Among the key advantages of using Kearsley's method to solve the least-squares superposition problem are
1. the problem can be solved analytically as an eigenvalue and eigenvector problem in quaternion parameters, and
2. the method avoids problems with singularities (and rotary inversions) that can result from Kabsch's method, where these oddities are handled explicitly after the solution is found (Coutsias et al., 2004; Kearsley, 1989).
Structural molecular biology employs least-squares superposition to support a wide variety of tasks. An example is the role of superposition in programs for aligning protein 3D structures (Kolodny et al., 2005; Konagurthu et al., 2006; Lackner et al., 2000; Lesk, 1986; Shatsky et al., 2002, 2004; Shindyalov and Bourne, 1998; Vriend and Sander, 1991; Ye and Godzik, 2003). A structural alignment is the assignment of amino acid residue–residue correspondences between proteins based on the similarity of their structural contexts (Konagurthu et al., 2006). Among the commonly used heuristics to align protein structures are the ones that rely on identifying a library of well-fitting fragments (or contiguous substructures) within the protein structures being aligned. This library is then refined by jointly superposing the fragment pairs and determining the pairs that fit consistently, from which a structural alignment is finally assembled.
The joint superpositions in the current structural aligners are computed from scratch, even though previous superpositions of constituent fragment pairs provide a lot of information about the joint superposition. We can see that the number of joint superpositions grows quadratically in the size of the well-fitting fragment-pairs library, where each joint superposition takes a computational effort that is linear in the size of the combined vector sets. On average, when aligning a pair of homologous protein structures, there are well in excess of a thousand well-fitting fragment pairs, exhaustively requiring millions of joint superpositions before a structural alignment can be assembled. This exhaustive step poses a significant computational bottleneck for structural aligners, and, therefore, this problem is commonly mitigated by invoking joint superpositions rather restrictively, trading off potential structural alignment quality for speed.
In this article we explore the foundations of the orthogonal superposition problem and derive a set of statistics that are sufficient to compute the r.m.s.d. of the best superposition, and its corresponding rotation and translation parameters. We demonstrate that these sufficient statistics (Hogg and Craig, 1994) are additive. Therefore, these statistics can be used to compute new superpositions in constant time using the sufficient statistics of superpositions of constituent vector sets under addition and deletion operations. Using sufficient statistics results in a drastic speed up of tasks like joint superposition described above, compared to the current approaches that recompute these superpositions from scratch.
Section 2 gives the background to the orthogonal superposition problem using the least-squares criterion. Section 3 introduces the notion of sufficient statistics and derives the full set of sufficient statistics for the orthogonal superposition problem. Section 4 provides the update rules to update the superposition parameters in constant-time, building on the sufficient statistics of constituent superpositions. Section 5 describes an approach to speed up the diagonalization step used in the Kearsley approach. Finally, the article ends with an experimental evaluation of performance gain achieved using the results of this work.
2. Orthogonal Superposition
Formally let \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal U} = \{ \textbf{\textit{u}}_1 , \cdots , \textbf{\textit{u}}_n \} $$
\end{document}and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal V} = \{ \textbf{\textit{v}}_1 , \cdots , \textbf{\textit{v}}_n \} $$
\end{document} denote two vector sets with one-to-one correspondence. In this article we consider vectors in three dimensions. Let the (x, y, z) components of each ui be represented here as (ui (x), ui(y), u(z)). (Similar representation holds for vi or any other vector.)
The least-squares superposition problem is an optimization problem that involves finding the orthogonal rotation R and translation t with the optimality criterion defined as follows:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}{ \cal E} = \min \parallel { \bf R} { \cal U} + \textbf{\textit{t}} - { \cal V} \parallel^2 = \min \sum_{i = 1}^n \parallel { \bf R} \textbf{\textit{u}}_i + \textbf{\textit{t}} - \textbf{\textit{v}}_i \parallel^2 = \min \sum_{i = 1}^n \left\langle { \bf R}\textbf{\textit{u}}_i + \textbf{\textit{t}} - \textbf{\textit{v}}_i , { \bf R}\textbf{\textit{u}}_i + \textbf{\textit{t}} - \textbf{\textit{v}}_i \right\rangle\end{align*}
\end{document}
where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\left\langle \cdot , \cdot \right\rangle$$
\end{document} denotes the inner product between the stated terms, R is a 3 × 3 pure rotation matrix, and t is a translation vector.
Under this least-squares criterion, the optimal translation can be made independent of the optimal rotation as follows. Differentiating \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal E}$$
\end{document} with respect to t and evaluating it at its extremum
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*} \frac { \partial { \cal E } } { \partial
\textbf{\textit{t}}} & = \frac {\partial}{\partial
\textbf{\textit{t}}} \sum_ { i = 1 } ^n \left\langle { \bf R }
\textbf{\textit{u}}_i + \textbf{\textit{t}} -
\textbf{\textit{v}}_i , \, {\bf R} \textbf{\textit{u}}_i +
\textbf{\textit{t}} - \textbf{\textit{v}}_i \right\rangle = 2
\sum_{i = 1}^n \frac{\partial({\bf R} \textbf{\textit{u}}_i +
\textbf{\textit{t}} - \textbf{\textit{v}}_i )} {\partial
\textbf{\textit{t}}} ( {\bf R} \textbf{\textit {u}}_i +
\textbf{\textit {t}} - \textbf{\textit {v}}_i) = 0 \\
& \Rightarrow \sum_ { i = 1 } ^n { \bf R } \textbf{\textit{u}} _i
+ \textbf{\textit{t}} - \textbf{\textit{v}}_i = 0 \Rightarrow
\textbf{\textit{t}} = \frac { \sum_ { i = 1 } ^n
\textbf{\textit{v}}_i } {n} - {\bf R} \frac{\sum_ { i = 1 } ^n
\textbf{\textit{u}}_i } { n } = { \bf Centroid } ( { \cal V } ) -
{ \bf R } \ { \bf Centroid } ( { \cal U } )
\end{align*}
\end{document}
It follows that moving each of the vector sets to an origin at its centroid, about which the rotation is defined, gives us a modified (but equivalent) objective, which is independent of the translation \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\textbf{\textit{t}}: { \cal E} = \min \sum \limits_{i = 1}^n \mid { \bf R} \textbf{\textit{u}}^ \prime_i - \textbf{\textit{v}}^ \prime_i \mid^2$$
\end{document}, where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\textbf{\textit{u}}_i^ \prime = \textbf{\textit{u}}_i - { \bf Centroid} ( { \cal U} )$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\textbf{\textit{v}}_i^ \prime = \textbf{\textit{v}}_i - { \bf Centroid} ( { \cal V} )$$
\end{document}.
As seen above, Q is a 4 × 4 square symmetric matrix and q = (q1, q2, q3, q4)T are the unknown (to be solved) quaternion components associated with a 3D rotation, and λ is an (unknown) eigenvalue. In the eigenvalue problem defined in Equation 1, the notation xm, a scalar quantity, denotes the component-wise difference \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\textbf{\textit{v}}^ \prime_i ( x ) - \textbf{\textit{u}}^ \prime_i ( x )$$
\end{document} (equivalent notations for ym and zm), and the scalar xp denotes the component-wise sum \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\textbf{\textit{v}}^ \prime_i ( x ) + \textbf{\textit{u}}^ \prime_i ( x )$$
\end{document} (equivalently, yp and zp). From this point onwards, we use the term quaternion matrix to refer to the 4 × 4 matrix Q shown in Equation 1.
Diagonalizing Q yields four eigenvalues and (corresponding) eigenvectors. Kearsley (1989) shows that the eigenvector corresponding to the smallest eigenvalue, λmin, corresponds to the best rotation producing the least squares error, and the r.m.s.d. is computed as \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\sqrt { \displaystyle \frac { \lambda_ { \min } } { n } } $$
\end{document}
The computational effort required to solve the rigid-body superposition problem using Kearsley's quaternion approach (or equivalently Kabsch's approach) grows linearly with the number of vectors being superimposed. In Kearsley's approach this is dominated by the computation of the quaternion matrix Q where each of 10 distinct terms in the matrix requires O(n) effort. The diagonalization of Q is independent of n and shows a rapid convergence with numerical methods such as Jacobi's diagonalization algorithm (Jacobi, 1846).
3. Sufficient Statistics
We note that this rigid-body superposition problem is a geometric instance of the general regression problem using total least-squares, where a regression line has to be determined that minimizes the sum-of-squares error with respect to the observed data points.
The error terms of this regression problem are assumed to be normally distributed as \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal N} ( 0 , \sigma )$$
\end{document}, where the mean μ is 0 and σ is the standard deviation, which is minimized by the problem. In fact, the least squares estimator of σ is also its maximum likelihood estimator.
More formally, consider the standard normal distribution of some random variable x:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*} { \cal N } ( x \mid \mu , \sigma ) = \frac { 1 } { \sqrt { 2 \pi } \sigma } \exp \left[ - \frac { ( x - \mu ) ^2 } { 2 \sigma^2 } \right]\end{align*}
\end{document}
This normal density can be reparameterized into a general form denoting the family of exponential distributions: f (x|η)=h(x)g(η) exp(ηTU(x)) where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$h ( x )\, =\, \frac { 1 } { \sqrt { \pi } } , g ( \eta_2 ) =
\sqrt { - \eta_2 } \rm exp \left( \frac { \eta^2_1 } { 4 \eta_2 }
\right) , { \bold {\eta} } ^T = ( \frac { \mu } { \sigma^2 } , -
\frac { 1 } { 2 \sigma^2 } ) $$
\end{document}, and UT(x) = (x, x2).
This transformation can be used to show certain important properties that allows efficient computation of maximum likelihood estimators of μ and σ.
Considering a sample set of observations that are normally distributed \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \bf X} = \{ x_1 , x_2 , \cdots , x_n \} $$
\end{document}. The likelihood for these samples is given by:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}f ( { \bf X} \mid { \boldsymbol {\eta}} ) = \left(
\prod_{i = 1}^n h ( x_i ) \right) ( g ( { \boldsymbol {\eta}} ) )^n
\rm exp (( { \boldsymbol {\eta}}^T \sum_{i = 1}^{n}u ( x_i )
)\end{align*}
\end{document}
Taking natural logarithms on both sides gives us the log likelihood:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}\log ( \,f ( { \bf X} \mid { \boldsymbol {\eta}} ) ) =
\kappa + n \log \left( g ( { \boldsymbol {\eta}} ) \right) + { \boldsymbol
{\eta}}^T \sum_{i = 1}^n \textbf{\textit{U}} ( x_i )\end{align*}
\end{document}
where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\kappa = \sum \limits_{i = 1}^n \log ( h ( x_i ) )$$
\end{document} is a term independent of η.
To find the maximum likelihood estimators \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${\hat{ \boldsymbol {\eta}}}$$
\end{document}, take the gradient with respect to η and set to 0. This results in:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}n \nabla_ { { \hat { \boldsymbol {\eta} } } } \left[ \log
\left( g ( { \hat { \boldsymbol {\eta} } } ) \right) \right] +
\sum_ { i = 1 } ^n \textbf{\textit{U}} ( x_i ) = 0 \Rightarrow -
\nabla_ { { \hat { \boldsymbol {\eta} } } } \left[ \log \left( g (
{ \hat { \boldsymbol {\eta} } } ) \right) \right] = \frac { 1 } {
n } \sum_ { i = 1 } ^n \textbf{\textit{U}} ( x_i ) = \frac { - 1 }
{ g ( { \hat { \boldsymbol {\eta} } } ) } \nabla_ { { \hat {
\boldsymbol {\eta} } } } g ( { \hat { \boldsymbol {\eta} } } ) =
\frac { 1 } { n } \sum_ { i = 1 } ^n \textbf{\textit{U}} ( x_i
)\end{align*}
\end{document}
Notice that maximum likelihood estimate \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \hat{\boldsymbol {\eta}}}$$
\end{document} depends on the statistic \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\sum \limits_{i = 1}^n{ \bf U} ( x_i )$$
\end{document} rather than the individual data. This suggests that to obtain the maximum likelihood estimate we do not need the data explicitly as it can be derived from that statistic. This sufficiency to derive the maximum likelihood estimator without explicit consideration of data makes \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\sum \limits_{i = 1}^n{ \bf U} ( x_i )$$
\end{document} a sufficient statistic for the exponential family of functions. For normal distribution, we saw earlier that U(xi) = (xi, xi2) gives the sufficient statistics of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\sum \limits_{i = 1}^n x_i$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\sum \limits_{i = 1}^n x_i^2$$
\end{document} (Hogg and Craig, 1994).
3.1. Sufficient statistics for orthogonal superposition
For the orthogonal superposition problem, each error term, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\varepsilon_i = {\textbf {R}}{\textbf{\textit{u}}_\textbf{\textit{i}}}^{\prime} -
{\textbf{\textit{v}}_\textbf{\textit{i}}}^ \prime$$
\end{document}, is also assumed to be normally distributed, that is, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\varepsilon_i \sim { \cal N} ( \mu = 0 , \sigma )$$
\end{document}. We now derive the sufficient statistics for σ of ɛi terms, which is equivalent to the r.m.s.d. after least-squares superposition. The likelihood of the observed normally distributed errors after superposition, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \bf E} = \{ \varepsilon_1 , \ldots , \varepsilon_n \} $$
\end{document}, can be written as:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}f (\varepsilon_{1} , \ldots , \varepsilon_{n} |
\sigma ) = \prod_ { i = 1 } ^n ( 2 \pi \sigma^2 ) ^ { - \frac {1}
{2}} {\rm exp} \left( - \frac {1} { 2 \sigma^2 }
\parallel \textbf{R} {\textbf{\textit{u}}_{\textit{i}}}^{\prime} -
\textbf{\textit{v}}_{\textit{i}}^{\prime} \parallel^2 \right) = (2
\pi \sigma^2 ) ^ { - \frac { n } {2}} {\rm exp} ( - \frac
{1} { 2 \sigma^2 } \sum_ { i = 1 } ^n \parallel {\textbf{R}}
\textbf{\textit{u}}_{\textit{i}}^{\prime} -
\textbf{\textit{v}}_{i}^{\prime} \parallel^2 )\end{align*}
\end{document}
From Equation 1, the matrix Q is made up of terms of the form \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$A_m = v_i^{ \prime} ( A ) - u_i^{ \prime} ( A )$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$A_p = v_i^{ \prime} ( A ) + u_i^{ \prime} ( A )$$
\end{document} where each A and B take the values x, y, or z denoting the vector components. Rewriting, we get \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$v_i^ { \prime } ( A ) = \displaystyle \frac { A_p + A_m } { 2 } $$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$u_i^ { \prime } ( A ) = \displaystyle \frac { A_p - A_m } { 2 } .$$
\end{document} The first two terms on the right-hand side of Equation 2 can be expanded as follows:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*} \parallel \textbf{\textit{u}}_\textbf{\textit{i}}
^{\prime} \parallel^2 +
\parallel \textbf{\textit{v}}_\textbf{\textit{i}}^{\prime}
\parallel^2 = & ( u_i^{\prime} ( x )^2 + u_i^ {\prime} ( y )^2 +
u_i^{\prime} ( z ) ^2 ) + (v_i^ {\prime} ( x )^2 + v_i^ {\prime} (
y )^2 + v_i^{ \prime} ( z )^2 ) \\ & = \frac{1}{2} (x_m^2 + x_p^2
+ y_m^2 + y_p^2 + z_m^2 + z_p^2) = \frac{1}{2} \sum_{A \in \{ x ,
y , z \} } A_m^2 + \frac {1}{2} \sum_{A \in \{ x , y , z \} }
A_p^2 \tag{3}\end{align*}
\end{document}
The last term on the right-hand side of Equation 2 can be expanded as \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\textbf{\textit{v}}_\textbf{\textit{i}}^{{\prime}^{\rm T}} {\bf R}
\textbf{\textit{u}}_\textbf{\textit{i}}^{{ \prime}} =
v_\textbf{\textit{i}}^{{ \prime} {\rm T}} [ { \bf r}_{\bf 1} { \bf
r}_{\bf 2} { \bf r}_{\bf 3} ]
\textbf{\textit{u}}_\textbf{\textit{i}}^{ \prime}$$
\end{document} where r1, r2, r3 are column vectors of the 3 × 3 rotation matrix R. Therefore,
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}\textbf{\textit{v}}_\textbf{\textit{i}}^{{\prime}^{\rm T}}{\bf R}
\textbf{\textit{u}}_\textbf{\textit{i}}^{\prime} = (
\textbf{\textit{v}}_\textbf{\textit{i}}^{\prime} . {\bf r_1} ) {
u_i}^{\prime} ( x ) + ( \textbf{\textit{v}}_\textbf{\textit{i}}^{
\prime} \ . \ { \bf r_2} ) {u_i}^{ \prime} ( y ) + ( { \bf
v}_\textbf{\textit{i}}^{\prime}. { \bf r_3} ) {u_i}^{ \prime} ( z
) \tag{4}\end{align*}
\end{document}
where r11, r12, r13 are the terms in the r1 column vector in R. More generally,
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}(\textbf{\textit{v}}_\textbf{\textit{i}}^{\prime} . { \bf r_1} )
u_i^{ \prime} ( x ) = c_1 A_p^2 + c_2 A_m^2 + c_3 A_p B_p + c_4
A_m B_m + c_5 A_m B_p \tag{5}\end{align*}
\end{document}
where ck are constants in terms of components of r1.
Similarly, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$(\textbf{\textit{v}}_\textbf{\textit{i}}^{\prime} .\, { \bf r_2} ) u_i^{ \prime} ( y )$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$(\textbf{\textit{v}}_\textbf{\textit{i}}^{ \prime} . \,{ \bf r_3} ) u_i^{ \prime} ( z )$$
\end{document} can be expanded as above and will have the same form as Equation 5, but with different constants. Therefore, combining Equations 3 and 4, Equation 2 can expressed as
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}\varepsilon_i^2 = \zeta_1 \sum_{A} A_p^2 + \zeta_2 \sum_{A} A_m^2 + \zeta_3 \sum_{ \forall A \neq B} A_p B_p + \zeta_4 \sum_{ \forall A \neq B} A_m B_m + \zeta_5 \sum_{ \forall A \neq B} A_m B_p\end{align*}
\end{document}
where ζk are constants. Hence, the likelihood function can be written as
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}f ( \varepsilon_1 , \ldots , \varepsilon_n \mid \sigma ) = ( 2 \pi \sigma^2 ) ^ { - \frac { n } { 2 } } \rm exp \left( - \frac { 1 } { 2 \sigma^2 } { \bf U } \right) \tag { 6 } \end{align*}
\end{document}
where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \bf U} = \sum \limits_{i = 1}^n \left( \zeta_1 \sum \limits_{A} A_p^2 + \zeta_2 \sum \limits_{A}A_m^2 + \zeta_3 \sum \limits_{ \forall A \neq B}A_p B_p + \zeta_4 \sum \limits_{ \forall A \neq B}A_m B_m + \zeta_5 \sum \limits_{ \forall A \neq B}A_m B_p \right)$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$A , B \in \{ x , y , z \} $$
\end{document}.
Using Equation 6, the negative log-likelihood is given as:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*} { \cal L } ( \varepsilon_1 , \ldots , \varepsilon_n \mid \sigma ) = \frac { n } { 2 } \log ( 2 \pi ) + n \log \sigma + \frac { 1 } { 2 \sigma^2 } { \bf U } \tag { 7 } \end{align*}
\end{document}
The maximum likelihood estimate \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\hat{ \sigma}$$
\end{document} can be determined by minimizing Equation 7 and evaluating the corresponding σ, that is, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$ \frac { \partial { \cal L } } { \partial \sigma } = 0 \Rightarrow { \hat { \sigma } } ^2 = \frac { \displaystyle { \bf U } } { n } $$
\end{document}.
U involves statistics that do not take into account the data (the coordinates of vector sets) explicitly, and are sufficient to estimate σ (or r.m.s.d.). Therefore, the set of sufficient statistics for the least-squares superposition problem can be defined as:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}{ \Psi} = \left\{ \sum \limits_{i = 1}^n A_m B_m , \quad \sum \limits_{i = 1}^n A_m B_p , \quad \sum_{i = 1}^n A_p B_p \right\} \tag{8}\end{align*}
\end{document}
where A and B take the values {x, y, z}, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$A_m = \textbf{\textit{v}}_\textbf{\textit{i}}^ \prime ( A ) - \textbf{\textit{u}}_\textbf{\textit{i}}^ \prime ( A )$$
\end{document} is the component-wise difference (similarly Bm), and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$A_p = \textbf{\textit{v}}_\textbf{\textit{i}}^ \prime ( A ) + \textbf{\textit{u}}_\textbf{\textit{i}}^ \prime ( A )$$
\end{document} is the component-wise sum (similarly Bp). Altogether, the set Ψ consists of 18 distinct statistics. Since we translated the original vector sets, these terms are sufficient to compute the best rotation for the least-squares superposition problem. Further, the sufficient statistics to compute the translation are simply the component-wise sums for each of the two (untranslated) vector sets \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal U}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal V}$$
\end{document}.
4. Updating Sufficient Statistics
4.1. Updating sufficient statistics under an addition operation
Consider two pairs of corresponding vector sets: \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal Q} \leftrightarrow { \cal R}$$
\end{document} containing n1 correspondences and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S} \leftrightarrow { \cal T}$$
\end{document} containing n2 correspondences. Let \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal U}$$
\end{document} be defined as a combination of vectors \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal Q}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S}$$
\end{document}, and similarly \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal V}$$
\end{document} as a combination of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal R}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal T}$$
\end{document}. Let Ψ1 denote the sufficient statistics of the first pair after superposition and Ψ2 denote the same for the second pair. Define these as:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}{ \Psi}_1 = \left\{ \sum_{i = 1}^{n_1} C_{m} D_{m} , \sum_{i = 1}^{n_1} C_{m} D_{p} , \sum_{i = 1}^{n_1} C_{p} D_{p} \right\} , { \Psi}_2 = \left\{ \sum_{i = 1}^{n_2} E_{m} F_{m} , \sum_{i = 1}^{n_2} E_{m} F_{p} , \sum_{i = 1}^{n_2} E_{p} F_{p} \right\} \tag{9}\end{align*}
\end{document}
Where C, D, E, and F take the values x, y, or z, denoting the respective components of vectors in the sets. Consistent with the previous notation (see Eq. 8), Cp and Cm (similarly Dp and Dm) are the component-wise sums and differences between corresponding vectors in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal Q}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal R}$$
\end{document}. The same definitions hold for Em (and Ep) and Fm (and Fp), with respect to corresponding vectors in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal T}$$
\end{document}.
We want to use Ψ1 and Ψ2 to compute a new set of sufficient statistics Ψ (defined in Eq. 8) for the superposition of vector sets \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal U} = { \cal Q} + { \cal S}$$
\end{document} with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal V} = { \cal R} + { \cal T}$$
\end{document}. Below we derive the construction of the new sufficient statistics. The statistics involved in computing the new centroids of the sets \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal U}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal V}$$
\end{document}, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\sum \limits_{i = 1}^{n = n_1 + n_2} \textbf{\textit{u}}_i ( A )$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\sum \limits_{i = 1}^{n = n_1 + n_2} \textbf{\textit{v}}_i ( A )$$
\end{document}, can be trivially updated using the statistics \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\sum \limits_{i = 1}^{n_1} \textbf{\textit{q}}_i ( C ) , \sum \limits_{i = 1}^{n_1} \textbf{\textit{r}}_i ( D ) , \sum \limits_{i = 1}^{n_2} \textbf{\textit{s}}_i ( E )$$
\end{document}, and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\sum \limits_{i = 1}^{n_2} \textbf{\textit{t}}_i ( F )$$
\end{document}. To compute the remaining statistics in Ψ, we define the following vectors:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}{ \bf \alpha}_1 = { \bf Centroid} ( { \cal U} ) - { \bf Centroid} ( { \cal Q} ) \qquad { \bf \beta}_1 = { \bf Centroid} ( { \cal V} ) - { \bf Centroid} ( { \cal R} )\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}{ \bf \alpha}_2 = { \bf Centroid} ( { \cal U} ) - { \bf Centroid} ( { \cal S} ) \qquad { \bf \beta}_2 = { \bf Centroid} ( { \cal V} ) - { \bf Centroid} ( { \cal T} )\end{align*}
\end{document}
Also define \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\Delta_{m}^C = { \bf \beta_1} ( C ) - { \bf \alpha_1} ( C ) , \Delta_{m}^D = { \bf \beta_1} ( D ) - { \bf \alpha_1} ( D ) , \Delta_{m}^E = { \bf \beta_2} ( E ) - { \bf \alpha_2} ( E )$$
\end{document}, and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\Delta_{m}^F = { \bf \beta_2} ( F ) - { \bf \alpha_2} ( F )$$
\end{document}, where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$A = C = E \in \{ x , y , z \} $$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$B = D = F \in \{ x , y , z \} $$
\end{document}. These vectors define the corrections (or updates) required to the constituent centroids so that the new centroid can be constructed. Using these definitions, the lemma and corollaries below show the computation of Ψ from Ψ1 and Ψ2.
4.2. Updating sufficient statistics under a deletion operation
Let us consider the case where we want to find a superposition under a deletion operation. Let \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal U} \leftrightarrow { \cal V}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal Q} \subset { \cal U} \leftrightarrow { \cal R} \subset { \cal V}$$
\end{document} denote two pairs of vector sets that are in correspondence. We want to compute the superposition of the vector sets \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S} = { \cal U} \backslash { \cal Q}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal T} = { \cal V} \backslash { \cal R}$$
\end{document}.
Using the same notations as in the previous section, it is straightforward to rearrange Lemma 1 and Corollaries 1 and 2 to derive the sufficient statistics Ψ2 of the superposition of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S}$$
\end{document} with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal T}$$
\end{document} using the sufficient statistics Ψ (of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal U}$$
\end{document} with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal V}$$
\end{document}) and Ψ1 (of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal Q}$$
\end{document} with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal R}$$
\end{document}) as follows.
5. Computing The R.M.S.D. From Updated Sufficient Statistics And Other Optimizations
It is easy to see that Kearsley's 4 × 4 symmetric quaternion matrix Q given in Equation 1 can be constructed using the updated sufficient statistics derived from the constituent sufficient statistics of previously superposed vector sets under addition and deletion operations in constant time.
In practice, Q is diagonalized and its eigenvalues and eigenvectors are computed using the numerical approach of Jacobi, where rotations are applied to \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal Q}$$
\end{document} iteratively, where each rotation annihilates (that is, sets to zero) a symmetric pair of off-diagonal entries in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal Q}$$
\end{document}. This approach has a fast convergence, and the smallest diagonal element (or eigenvalue) is used to derive the r.m.s.d. term, as described in section 2.
However, in some cases, for instance, when a current superposition is extended by just one correspondence, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal Q}$$
\end{document} changes marginally. Therefore, diagonalization of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal Q}$$
\end{document} can build on the previous solution. Let Q denote the quaternion matrix corresponding to the superposition of corresponding vector sets \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal U}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal V}$$
\end{document}. From the eigenvalue decomposition theorem, we have Q = SΛS−1, where S is the matrix of eigenvectors and Λ is the diagonal matrix of eigenvalues. Also note that Q is a positive semidefinite matrix with the property QTQ = QQT. This implies that all the eigenvectors are orthogonal to each other. This further simplifies the decomposition to Q = SΛST. Also, since S is an orthogonal matrix, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \bf Q} = S \Lambda S^T \Rightarrow \Lambda = S^T { \bf Q}S$$
\end{document}.
Now, assume that the corresponding vector sets are augmented from \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal U}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal V}$$
\end{document} to \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal U}^{ \prime}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal V}^{ \prime}$$
\end{document}, resulting in an updated Kearsley's matrix Q′. We want to diagonalize this matrix into \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$S^ \prime \Lambda^ \prime {S^{ \prime}}^T$$
\end{document}. Instead of starting the Jacobi's iterative process from scratch, we will use the previously computed eigenvectors (before the vector sets were augmented), S, and compute \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$ \tilde{ \Lambda}$$
\end{document} as \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$S^T { \cal Q}^ \prime S$$
\end{document}. Notice that if the augmentation does not include drastic changes, then \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$ \tilde{ \Lambda}$$
\end{document} is nearly diagonal (that is, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$ \tilde{ \Lambda} \approx \Lambda{^ \prime} )$$
\end{document}), thus requiring very few iterations to fully diagonalize \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$ \tilde{ \Lambda}$$
\end{document}. This provides a further optimization to the diagonalization step under update operations on vector sets.
6. Results
6.1. Source code
We wrote a C++ library that allows superposition of vector sets. Superpositions can be carried out from scratch (using the raw coordinates), or, alternatively, using the sufficient statistics of constituent vector sets by operating on them using set addition or deletion operations. The source code is available freely under a GNU public license online (visit corresponding author's webpage).
6.2. Consistency of superpositions using sufficient statistics
To validate the consistency of superpositions generated using sufficient statistics (under both addition and deletion operations discussed in section 4) we undertake the following experiment: 8992 ASTRAL SCOP (Chandonia et al., 2004; Murzin et al., 1995) domains were used as the source structures from which superposable fragments were randomly sampled. The general procedure of sampling is as follows. From the list of source structures, randomly choose any structure. Within this structure choose two random fragments of lengths l1 and l2, where each fragment has between 10 and 40 residues. These chosen fragments form the sets \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal Q}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S}$$
\end{document}. Yet another structure is again chosen randomly from our source list, and two fragments are randomly extracted from it with exactly the same length, l1 and l2. These form the sets \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal R}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal T}$$
\end{document}. Assuming one-to-one correspondence between \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal Q} \leftrightarrow { \cal R}$$
\end{document}, we compute the sufficient statistics Ψ1 of their orthogonal superposition. Similarly the sufficient statistics Ψ2 is computed for the orthogonal superposition between \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S} \leftrightarrow { \cal T}$$
\end{document}. Define \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal U} = { \cal Q} + { \cal S}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal V} = { \cal R} + { \cal T}$$
\end{document}. Iterating this random sampling 100 million times, we computed:
1. the r.m.s.d. of superposition of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal U} \leftrightarrow { \cal V}$$
\end{document} from scratch (using the raw coordinates in the vector sets); denote this r.m.s.d. as ρ1
2. the r.m.s.d. of superposition of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal U} \leftrightarrow { \cal V}$$
\end{document}, but using the sufficient statistics Ψ1 and Ψ2 of superpositions of constituent vector sets \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal Q} \leftrightarrow { \cal R}$$
\end{document}, and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S} \leftrightarrow { \cal T}$$
\end{document}; denote this r.m.s.d. as ρ2.
We measure the difference between the two r.m.s.d. values, Δρ = ρ1 – ρ2. Over the 100 million samples, the mean and standard deviation of Δρ was found to be zero to a very high precision (< 10−17).
We repeat the same experiment to validate superpositions under deletion operation using sufficient statistics, where, in each iteration, we compute the superposition of vector sets \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S} \leftrightarrow { \cal T}$$
\end{document}, with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S} = { \cal , U} \backslash { \cal Q}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal T} = { \cal V} \setminus { \cal R}$$
\end{document}. This experiment again confirms the same consistency as observed in the test on addition operation.
6.3. Measuring the performance gain using sufficient statistics for superpositions
We demonstrated in section 4 that superpositions under addition and deletion can be updated in constant time, building on the sufficient statistics of the constituent sets. This was also validated empirically using the experiments above. We will now measure the gain in performance using this approach by comparing it with superpositions built from scratch.
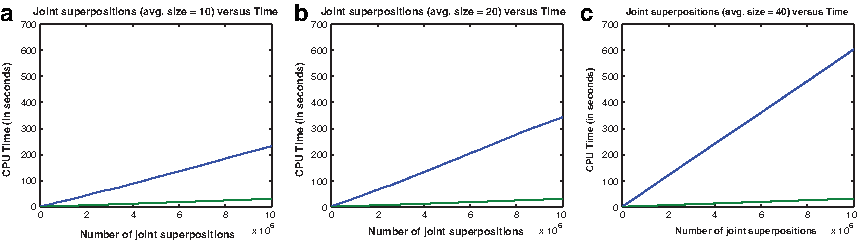
Figures 1a–c show the runtime plots of three sets of randomly chosen 10 million joint superpositions carried out from scratch (blue line) and compared against the same superpositions updated using sufficient statistics (green line). We note that these three sets vary in the (average) size of the joint superpositions being carried out, as indicated in the plot titles.
The CPU times (in seconds) performing joint superpositions from scratch (blue line) compared to the same using sufficient statistics (green line) over 10 million random fragment data sets derived from ASTRAL SCOP domains. The three plots vary in the average superposition size as indicated in the title.
Notice that when joint superpositions are carried out from scratch ignoring the sufficient statistics, the average size of the superpositions introduces a constant factor to the run time. This is expected as each superposition is linear in the size of the vector sets being superposed. Consequently, the slopes of those blue lines across the three plots in Figure 1 become steeper with the increase in the superposition size. On the other hand, when the joint superpositions are updated in constant time, the updates are independent of the superposition size. This is because any update involves recomputing only a small (fixed) number of sufficient statistics. This is clearly reflected in the slopes of the green lines being unchanged across the three plots in Figure 1.
More formally, if |J| is the number of joint superpositions and l is the (average) number of vectors being superposed, then the first method (blue line in Fig. 1) grows as O(l|J|). Since l ≪ |J| we see a linear trend (with a steeper gradient accounting for the multiplier l in the complexity term). In comparison, the results with sufficient statistics (green line in Fig. 1) grow simply as O(|J|), independent of the superposition size.
6.4. Using sufficient statistics of superposition in the setting of structural alignments
As discussed in the introduction, a common heuristic employed to compute a structural alignment between pairs of structures involves collecting a library of well-fitting fragments. This library is refined by jointly superposing pairs from this library, and a final structural alignment is assembled from these results.
To test the potential performance gain by using sufficient statistics, we computed the time taken to undertake an exhaustive joint superposition on libraries of well-fitting fragments corresponding to a small collection of structural pairs. For each pair of structures chosen, the well-fitting fragments are identified as those that superpose maximally within an r.m.s.d. threshold of 2 Å. By maximal, we mean those fragment pairs that cannot be extended any further without violating the r.m.s.d. threshold.
Table 1 shows the run times of joint superpositions performed exhaustively on a small set of protein structural pairs. As can be seen from the table, using sufficient statistics for superpositions results in up to an order of magnitude improvement in the run time to carry our these superpositions exhaustively. Since performing this task without sufficient statistics creates a computational bottleneck, existing structural alignment programs attempt to drastically restrict the number of superpositions, often trading off structural alignment quality for speed. We note that the improvements gained from using sufficient statistics for superpositions will allow these restrictions to be generously relaxed without any effect on the current run times, but potentially improving the structural alignment quality.
Time Taken to Perform Exhaustive Joint Superpositions on a Library of Well-Fitting Fragment Pairs between Two Structures from Different Families.
Protein Family
Structural pair wwPDB IDs
Number of joint superpositions
Average size of superpositions
Time in seconds (from scratch)
Time in seconds (sufficient stats)
Serine proteinases
3EST vs. 2PKA
18,486,240
14
419.6
56.0
Calmodulin-like
1NCX vs. 2SAS
67,820,481
18
1618.4
178.2
Serine proteinases
3EST vs. 2SNV
71,025,321
16
1328.0
187.8
Globins
1HHOA vs. 1HHOB
74,890,441
20
1923.3
194.6
All the above experiments were carried out on a standard laptop with 2.2GHz Intel® CPU and 4GB RAM.
7. Conclusions
Optimal superpositions of vector sets are central to identify similarities and differences between spatial objects. We derived a set of sufficient statistics for the orthogonal superposition problem under the least squares criterion. These statistics provide an efficient way to operate (via addition and deletion of vectors) on previously computed superpositions. Our results demonstrate a drastic improvement in the computational effort required to compute r.m.s.d. based on sufficient statistics. These results are relevant to many analyses involving structural data. These include the plethora of algorithms to construct pairwise and multiple protein structural alignments by assembling fragment pairs. Source code (written in C++) to undertake superpositions implementing our work can be downloaded online.
Footnotes
Author Disclosure Statement
The authors declare that no competing financial interests exist.
References
1.
ChandoniaJ.-M., HonG., WalkerN. S., et al.2004. The ASTRAL compendium in 2004. Nucleic Acids Res., 32, D189–D192.
2.
CohenG.1997. ALIGN: a program to superimpose protein coordinates, accounting for insertions and deletions. Journal of Applied Crystallography, 30, 1160–1161.
3.
CoutsiasE.A., SeokC., and DillK.A.2004. Using quaternions to calculate RMSD. J. Comput. Chem., 25, 1849–1857.
4.
CoxJ.M.1967. Mathematical methods used in the comparison of the quaternary structures. J. Mol. Bio. 28, 151–156.
5.
DiamondR.1988. A note on the rotational superposition problem. Acta Crystallographica Section A: Foundations of Crystallography, 44, 211–216.
6.
EidhammerI., JonassenI., and TaylorW.R.2004. Protein Bioinformatics: An algorithmic Approach to Sequence and Structure Analysis. J. Wiley & Sons, Hoboken, New Jersey.
7.
HamiltonW.R., and HamiltonW.E.1866. Elements of Quaternions. Longmans, Green, & Company, New York.
8.
HoggR.V., and CraigA.1994. Introduction to Mathematical Statistics. Prentice Hall, Upper Saddle River, New Jersey.
9.
JacobiC.G.J.1846. Über ein leichtes Verfahren, die in der Theorie der Säkularstörungen vorkommenden Gleichungen numerisch aufzulösen. Journal für die Reine und Angewandte Mathematik, 30, 51–95.
10.
KabschW.1976. A solution for the best rotation to relate two sets of vectors. Acta Crystallographica Section A: Crystal Physics, Diffraction, Theoretical and General Crystallography, 32, 922–923.
11.
KabschW.1978. A discussion of the solution for the best rotation to relate two sets of vectors. Acta Crystallographica Section A: Crystal Physics, Diffraction, Theoretical and General Crystallography, 34, 827–828.
12.
KearsleyS.K.1989. On the orthogonal transformation used for structural comparisons. Acta Crystallographica Section A: Foundations of Crystallography, 45, 208–210.
13.
KenKnightC.1984. Comparison of methods of matching protein structures. Acta Crystallographica Section A: Foundations of Crystallography, 40, 708–712.
14.
KoehlP.2001. Protein structure similarities. Current Opinion in Structural Biology, 11, 348–353.
15.
KolodnyR., KoehlP., and LevittM.2005. Comprehensive evaluation of protein structure alignment methods: scoring by geometric measures. J. Mol. bio., 346, 1173–1188.
16.
KonagurthuA.S., WhisstockJ.C., StuckeyP.J., and LeskA.M.2006. MUSTANG: a multiple structural alignment algorithm. Proteins: Structure, Function, and Bioinformatics, 64, 559–574.
17.
LacknerP., KoppensteinerW.A., SipplM.J., and DominguesF.S., 2000. Prosup: a refined tool for protein structure alignment. Protein Engineering, 13, 745–752.
18.
LeskA.1986. A toolkit for computational molecular biology. II. On the optimal superposition of two sets of coordinates. Acta Crystallographica Section A: Foundations of Crystallography, 42, 110–113.
19.
LeskA.M.2000. The unreasonable effectiveness of mathematics in molecular biology. The Mathematical Intelligencer, 22, 28–37.
20.
LeskA.M.2001. Introduction to protein architecture: the structural biology of proteins. Oxford University Press, New York.
21.
MackayA.L.1984. Quaternion transformation of molecular orientation. Acta Crystallographica Section A: Foundations of Crystallography, 40, 165–166.
22.
McLachlanA.D.1972. A mathematical procedure for superimposing atomic coordinates of proteins. Acta Crystallographica Section A: Crystal Physics, Diffraction, Theoretical and General Crystallography, 28, 656–657.
23.
McLachlanA.D.1982. Rapid comparison of protein structures. Acta Crystallographica Section A: Crystal Physics, Diffraction, Theoretical and General Crystallography, 38, 871–873.
24.
MurzinA.G., BrennerS.E., HubbardT., and ChothiaC.1995. SCOP: a structural classification of proteins database for the investigation of sequences and structures. J. Mol. Bio., 247, 536–540.
25.
ShatskyM., NussinovR., and WolfsonH.J.2002. Flexible protein alignment and hinge detection. Proteins: Structure, Function, and Bioinformatics, 48, 242–256.
26.
ShatskyM., NussinovR., and WolfsonH.J.2004. A method for simultaneous alignment of multiple protein structures. Proteins: Structure, Function, and Bioinformatics, 56, 143–156.
27.
ShindyalovI.N. and BourneP.E.1998. Protein structure alignment by incremental combinatorial extension (ce) of the optimal path. Protein Eng., 11, 739–747.
28.
VriendG., and SanderC.1991. Detection of common three-dimensional substructures in proteins. Proteins: Structure, Function, and Bioinformatics, 11, 52–58.
29.
YeY., and GodzikA.2003. Flexible structure alignment by chaining aligned fragment pairs allowing twists. Bioinformatics, 19, ii246–ii255.