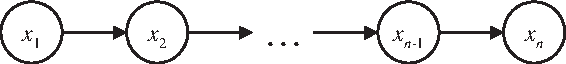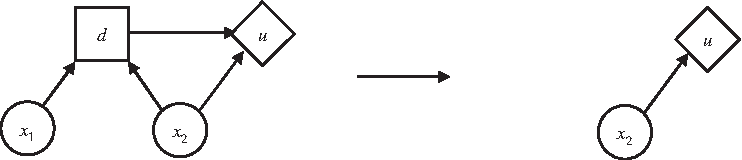There are several advantages to evaluating a problem using influence diagram operations. The analyst can use a representation that is natural to the decision maker, since the algorithm executes all of the inference and analysis automatically. The influence diagram solution procedure can also result in significant gains in efficiency. Conditional independence is clearly exhibited in the diagram, so the size of intermediate calculations can be reduced, resulting in considerable reductions in both processing time and memory requirements. However, when imprecise knowledge from data sets is involved in the systems, how to reason from approximate information becomes a main issue in evaluating influence diagrams effectively. This study develops an alternative knowledge model, rough-set influence diagrams (RSID), which combine rough-set decision rules and graphical structures of influence diagrams in medical settings. The proposed RSID provides a comprehensive schema for knowledge representation and decision support.
1. Introduction
There are several important capabilities of a medical reasoning system: diagnosis, prediction, treatment planning, etc. (Kao, 2008; Kao and Li, 2005; Kononenko, 2001; Leibovici et al., 2000; Li and Kao, 2005; Long, 2001). Diagnosis is the process of reconstructing past facts from observed evidence. Prediction is the process of projecting the evidence from hypotheses. Treatment planning is reasoning about the costs and effectiveness of treatments on patients. Usually, medical practice requires various kinds of reasoning to be carried out simultaneously. Hence, the capability for multiple reasoning tasks is critical to the performance of medical decision support systems. Moreover, medical expert systems become more complex when considering the mechanisms of the human body and their mutual interactions with environmental factors.
In the field of medical informatics, the graphical decision models such as Bayesian networks and influence diagrams have been widely used (Jensen, 2001; Kao, 2008; Kao and Li, 2005; Li and Kao, 2005; López-Díaz and Rodríguez-Muñiz, 2007; Neapolian, 2004; Nease and Owens, 1997; Oliver and Smith, 1990; Owens et al., 1997; Pearl, 1997). Influence diagrams are originally proposed as a compact representation of decision trees for symmetric decision scenarios, and are now regarded more as an extension of Bayesian networks (Pearl, 1997). Influence diagrams are a graphical technique for a decision problem under uncertainty (Howard and Matheson, 1981; Nease and Owens, 1997; Tatman and Shachter, 1990), and useful as knowledge representation and decision models (Jensen, 2001; Nease and Owens, 1997; Oliver and Smith, 1990; Shachter, 1986; Tatman and Shachter, 1990). Various methods have been developed for evaluating influence diagrams. In previous studies, the main numerical models of the influence diagrams used to be probability distributions (Howard and Matheson, 1981; Shachter, 1986).
There are several advantages in evaluating a problem using influence diagram operations. The analyst can use the representation that is natural to the decision maker and the algorithm executes the inference and analysis intelligently. The influence diagram solution procedure can also result in significant gains in efficiency. Conditional independence is clearly exhibited in the diagram, so the size of intermediate calculations can be reduced, resulting in considerable reductions in both processing time and memory requirements.
However, when imprecise knowledge from data sets is involved in the systems, how to reason from approximate information becomes a main issue in evaluating influence diagrams effectively. This study proposes an alternative numerical model for the knowledge in influence diagrams with rough sets. Rough set theory was first introduced by Pawlak (1982) as a tool for dealing with risk and impreciseness in decision making. The probabilistic approaches have been previously applied to rough set theory (Pawlak, 2002, 2003; Pawlak et al., 1988; Yao, 2003). Based on an approach recently proposed by Kao (2008), this study intends to propose an alternative numerical model for influence diagrams, which extends influence diagrams into rough-set influence diagrams. In rough-set influence diagrams, each chance node and value node is associated with the dependency, which expresses the uncertain features of the node. This study also develops rough-set-based influence diagrams that combine rough-set decision rules with the graphical structure of the influence diagrams found in medical settings.
The rest of this study is organized as follows. Section 2 illustrates the notations and the framework of influence diagrams. Section 3 describes the concept of rough sets and decision rules. Section 4 introduces how rough-set theory establishes the numerical model and decision support in influence diagrams. Section 5 illustrates the case studies of metastatic cancer and urinary tract infection. Section 6 gives the discussions and concluding remarks.
2. Influence Diagrams
Influence diagrams were originally introduced by Howard and Matheson (1981) as a compact representation of decision models. They are also thought of as an extension of Bayesian networks (Jensen, 2001; Pearl, 1997). An influence diagram is a directed acyclic graph (DAG) with three types of nodes: decision, chance, and value. A decision node, drawn as a rectangle, represents choices available to the decision makers. A chance node, drawn as a circle, represents random variables or uncertain quantities. A value node or utility node, shown as a diamond, represents the utility or the objective to be maximized in terms of expectation.
An influence diagram (ID) can be defined as
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}{ \rm ID} = ( V , L , P ) \tag{1}\end{align*}
\end{document}
where V denotes the set of nodes, L denotes the set of directed arcs, and P represents the numerical model. The composition of the node set V can be expressed as (2)
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}V = V_{D} \cup V_{R} \cup V_{U} \tag{2}\end{align*}
\end{document}
where VD denotes the decision node sets, VR represents the sets of chance nodes, and VU denotes the value nodes to be optimized. This study uses the uppercase letters to represent the nodes and lowercase letters for the value of a variable.
There are two types of directed arcs: conditional arcs (into chance and value nodes) and informational arcs (into decision nodes). The meanings of the directed arcs depend on their destinations. Arcs pointing to value nodes represent approximate or functional dependence. Arcs into decision nodes imply time precedence and are informational; that is, they show which variables will be known to the decision makers before the decision is made. Conventionally, the knowledge of chance nodes is expressed with probability distributions while the outcomes of the value node are projected with a value table.
An influence diagram satisfies the following conditions:
(i) The directed graph has no cycles.
(ii) The value node has no successors.
(iii) There is a directed path that contains all of the decision nodes.
An example of influence diagrams for metastatic cancer and treatment is modified from Cooper (1984) as shown in Figure 1, where V = VD ∪ VR ∪ VU, VD = {T}, VR = {B, C, I, M}, and VU = {Q}.
An example of influence diagrams for metastatic cancer and treatment.
Metastatic cancer is a possible cause of a brain tumor and is also an explanation for increased total serum calcium. In Figure 1, there is one decision node T (treatment), which has two alternatives to take: yes or no. Four chance variables are relevant to the biological test and treatment problems: B (brain tumor), C (coma), I (increased total serum calcium), and M (metastatic cancer). The utility function Q (quality-adjusted life expectancy) is to be maximized. The meaning and states of the nodes are summarized in Table 1.
The Descriptions and States of the Nodes inFigure 1
Node
Description
State
B
Brain tumor
B ∈ {0, 1}, 0: absent, 1: present
C
Coma
C ∈ {0, 1}, 0: absent, 1: present
I
Increased total serum calcium
I ∈ {0, 1}, 0: absent, 1: present
M
Metastatic cancer
M ∈ {0, 1}, 0: absent, 1: present
T
Treatment
T ∈ {Yes, No}
Q
Quality-adjusted life expectancy
[0, 150]
In Figure 1, the states of I and B determine the state of C. The states of I and B are conditioned on the manifestation of M. The outcome of M and the decision on T will determine the value of Q, where M provides the information prior to decision making. Usually, the causal relationships and decision rules in influence diagrams are expressed with probability distributions and a value table.
In medical informatics, influence diagrams are widely used knowledge representation and decision models under uncertainty. However, there are some limitations of utilizing the above approaches for solving medical reasoning problems:
(i) All associated probabilities are assumed to be non-fuzzy.
(ii) It is difficult to consider the constraints for the relationships among the nodes in Bayesian networks or influence diagrams in maximizing the utility functions.
(iii) Treatment decisions and diagnostic problems are not considered in one paradigm.
(iv) When imprecise knowledge is involved in medical systems, how to reason from the approximate information efficiently becomes a main issue in evaluating influence diagrams.
Hence, this study proposes an alternative approach for modeling the causal relationships in influence diagrams with rough sets.
3. Rough Sets
3.1. Information system
Rough set theory starts with information represented by a table called an information system (Pawlak, 1991). An information system is a 4-tuple S = (U, A, Va, fa), where:
(i) U is the universe, a nonempty finite set of objects.
(ii) \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$A = \{ a_{1} , a_{2} , \ldots , a_{m} \} $$
\end{document} is a nonempty finite set of attributes C ∪ D, where C and D is a finite set of condition and decision attributes, respectively.
(iii) Va is a domain of the attribute a, each attribute a : U → Va for a ∈ A.
(iv) fa : U × A → Va is the total decision function called the information function such that f (x, a) ∈ Va for \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\forall$$
\end{document}a ∈ A,\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\forall$$
\end{document}x ∈ U.
3.2. Indiscernibility relation
Let S = (U, A, Va, fa) be an information system, B ⊆ A and X ⊆ U. With any subset of attributes B ⊆ A, a binary indiscernibility relation, is called B-indiscernibility relation, which is defined by:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}IND ( B ) = \{ ( x , y ) \in U \times U: a ( x ) = a ( y ) , \forall a \in B \} \tag{3}\end{align*}
\end{document}
For any subset X ⊆ U, the lower and upper approximation can be expressed as (4) and (5), respectively:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}\underline{B ( x ) } = \bigcup_{x \in U} \{ B ( x ) : B ( x ) \subseteq X \} \tag{4}\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*} {\overline{B ( x )}} = \bigcup_{x \in U} \{ B ( x )
: B ( x ) \cap X \neq \O \} \tag{5}\end{align*}
\end{document}
That is, the elements of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\underline{B ( x ) }$$
\end{document} are all the elementary objects certainly belonging to X. The elements of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\overline{B ( x ) }$$
\end{document} are at least one object belonging to X. With the lower and upper approximation of a set X ⊆ U, the universe can be divided into three regions, the boundary region BND(x), the positive region POS(x), and the negative region NEG(x):
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}BND ( x ) = \overline{B ( x ) } - \underline{B ( x ) } \tag{6}\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}POS ( x ) = \underline{B ( x ) } \tag{7}\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}NEG ( x ) = U - \overline {B ( x ) } \tag{8}\end{align*}
\end{document}
If the boundary region of X is an empty set, BND(x) = Ø, then X is a crisp set with respect to N; otherwise, if BND(x) ≠ Ø, then X is a rough (approximate) set with respect to N.
3.3. Decision rules
Let |C| denote the set of all objects from U that have the meaning of C in S where |*| indicates the cardinality of a (finite) set.
If a decision rule in S is C → D, meaning IF C THEN D, where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$C = \{ c_{1} , c_{2} , \ldots , c_{n} \} $$
\end{document} is the condition attribute, and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$D = \{ d_{1} , d_{2} , \ldots , d_{m} \} $$
\end{document}is the decision attribute of the decision rule, respectively, then the support of the decision rule C → D in S will be supp(C, D) = card(C ∩ D).
For any C in S its probability is defined by σ(C) = p(|C|). With the decision rule C → D in S the conditional probability is σ (D | C) = p(|D| | |C|).
The strength of the decision rule C → D in S, denoted by σ(C, D), is defined as
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}\sigma ( C , D ) = \frac { supp ( C , D ) } { card ( U ) } \tag { 9 } \end{align*}
\end{document}
The certainty factor of the decision rule C → D in S, denoted by cer(C, D), is defined as
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}cer ( C , D ) = \sigma ( D\, \mid\, C ) = \frac { supp ( C , D ) } { card ( C ) } = \frac { \sigma ( C , D ) } { \sigma ( C ) } \tag { 10 } \end{align*}
\end{document}
The certainty factor is interpreted as a conditional probability that y belongs to D given y belongs to C. It is easy to see that cer(C, D) ∈ [0, 1]. If cer(C, D) = 1, then the given decision rule is a deterministic or certain decision rule in S. Otherwise, 0 < cer(C, D) <1, the given decision rule is a nondeterministic or uncertain decision rule in S.
The coverage factor of the decision rule C → D in S, denoted by cov(C, D), is defined as
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}cov ( C , D ) = \sigma ( C \,\mid \,D ) = \frac { supp ( C , D ) } { card ( D ) } = \frac { \sigma ( C , D ) } { \sigma ( D ) } \tag { 11 } \end{align*}
\end{document}
3.4. Probabilistic properties
Let C → D be the decision rule in S, then the following properties (12)–(17) are valid (Pawlak, 2002, 2003; Yao, 2003). Note that (14) and (15) are referring to total probability theorem, (16) and (17) are referring to Bayes' theorem
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}\sum_{C^{ \prime} \in C ( x ) }cer ( C^{ \prime} , D ) = 1 \tag{12}\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}\sum_{D^{ \prime} \in D ( x ) }cov ( C , D^{ \prime} ) = 1 \tag{13}\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}\sigma ( C ) = \sum_{D^{ \prime} \in D ( x ) }cov ( C , D^{ \prime} ) \cdot \sigma ( D^{ \prime} ) = \sum_{D^{ \prime} \in D ( x ) } \sigma ( C , D^{ \prime} ) \tag{14}\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}\sigma ( D ) = \sum_{C^{ \prime} \in C ( x ) }cer ( C^{ \prime} , D ) \cdot \sigma ( C^{ \prime} ) = \sum_{C^{ \prime} \in C ( x ) } \sigma ( C^{ \prime} , D ) \tag{15}\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}cer ( C , D ) = \frac { \sigma ( C , D ) } { \sigma ( C ) } = \frac { \sigma ( C , D ) } { \sum_ { D^ { \prime } \in D ( x ) } \sigma ( C , D^ { \prime } ) } = \frac { cov ( C , D ) \cdot \sigma ( D ) } { \sigma ( C ) } \tag { 16 } \end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}cov ( C , D ) = \frac { \sigma ( C , D ) } { \sigma ( D ) } = \frac { \sigma ( C , D ) } { \sum_ { C^ { \prime } \in C ( x ) } \sigma ( C^ { \prime } , D ) } = \frac { cer ( C , D ) \cdot \sigma ( C ) } { \sigma ( D ) } \tag { 17 } \end{align*}
\end{document}
4. ROUGH-SET INFLUENCE DIAGRAMS (RSID)
Most studies on influence diagrams (Howard and Matheson, 1981; Nease and Owens, 1997; Pearl, 1997; Shachter, 1986) used to describe the dependency and its associated numerical model with probability distributions. However, when impreciseness is involved in the domain, the decision makers may need more flexible uncertainty measures for analysis. Rough set theory can be an alternative measure when faced with such a problem.
Given the influence diagrams structure and the original data sets, rough set theory provides a basis for extracting the knowledge and expressing the dependency among nodes in the influence diagrams. To represent the ontology, we define that a rough-set influence diagram is a directed acyclic graph RSID = (U, A, f ), where:
(i) U is the universe, a nonempty finite set of objects.
(ii) A is a set of nodes where A ≡ VD ∪ VR ∪ VU ≡ VD ∪ (C ∪ D) ∪ VU.
(iii) f is the flow function representing the strength, certainty factor, and coverage factor of the decision rule.
With every branch of (xi, xi+1) there is a directed arc from node xi to xi+1 as shown in Figure 2. The certainty, coverage, and strength of a branch (xi, xi+1) are defined as cer(xi, xi+1), cov(xi, xi+1), and σ(xi, xi+1), respectively.
A directed arc from node xi to xi+1.
A directed path from x1 to xn for x1, xn ∈ A denoted [x1, xn], is a sequence of nodes \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$x_{1} , x_{2} , \ldots , x_{i} , \ldots , x_{n} , 1 \leq i \leq n$$
\end{document}, as shown in Figure 3.
A directed path [x1, xn] from node x1 to xn.
Then, the certainty of a directed path [x1, xn] is defined as
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}cer [ x_{1} , x_{n} ] = \mathop \prod \limits_{i = 1}^{n - 1} cer ( x_{1} , x_{n} ) \tag{18}\end{align*}
\end{document}
The coverage of a directed path [x1, xn] is defined as
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}cov [ x_{1} , x_{n} ] = \mathop \prod \limits_{i = 1}^{n - 1} cov ( x_{1} , x_{n} ) \tag{19}\end{align*}
\end{document}
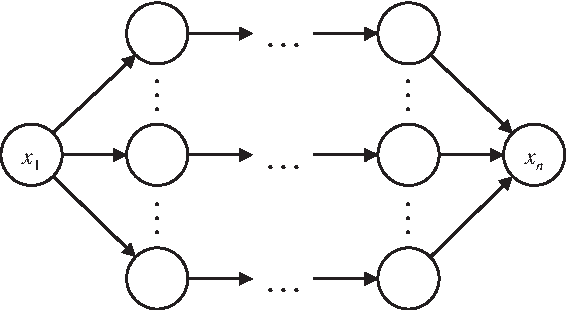
The set of all directed paths from x1 to xn denoted 〈x1, xn〉 as shown in Figure 4, where [x1, xn] ∈ 〈x1, xn〉.
The set, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\langle x_{1} , x_{n} \rangle$$
\end{document}, of all directed paths from node x1 to xn.
The main objective of an influence diagram with a value node is to maximize the expected value (Shachter, 1986; Tatman and Shachter, 1990). To perform this, the following transformations are introduced. Consider the following cases:
Case 1: Removal of a chance node by summing it out of the joint can be accomplished, as shown in Figure 5. This corresponds to
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
\begin{split} \sigma ( x_{5} \mid x_{1} , x_{2} , x_{3} ) \leftarrow \sum_{x_{4}} \sigma ( x_{4} , x_{5} \mid x_{1} , x_{2} , x_{3} ) \\ = \sum_{x_{4}} \sigma ( x_{5} \mid x_{2} , x_{3} , x_{4} ) \sigma ( x_{4} \mid x_{1} , x_{2} ) \end{split}
\tag{24}\end{align*}
\end{document}
Case 3: Removal of a chance node by expectation, as shown in Figure 7, can be accomplished as
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}E [ U ( u \mid x_{1} , x_{2} , x_{3} ) ] \leftarrow E [ U_{x_{4}} ( E [ U ( u \mid x_{2} , x_{3} , x_{4} ) ] \mid x_{1} , x_{2} ) ] \tag{27}\end{align*}
\end{document}
Removal of a chance node x4 into u by expectation.
Case 4: Removal of a decision node by maximization, as shown in Figure 8, can be accomplished as
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}E [ U ( u \mid x_{2} ) ] \leftarrow \max_{d} E [ U ( u \mid d , x_{2} ) ] \tag{28}\end{align*}
\end{document}
Removal of a decision node d by maximization.
According to the cases above, the alternative numerical model based on rough set can be constructed for influence diagrams.
5. Numerical Examples
Example 1. Consider an influence diagram as shown in Figure. 1. According to (9), and (10), the certainty factors and value functions can be obtained in Table 2.
The Certainty Factors and Value Functions ofFigure 1
σ(m = 1) = 0.2
cer(m, i) : σ(i = 1|m = 1) = 0.8
σ(i = 1|m = 0) = 0.2
cer(m, b) : σ(b = 1|m = 1) = 0.7
σ(b = 1|m = 0) = 0.2
cer((b, i), c) : σ(c = 1|b = 1, i = 1) = 0.9
σ(c = 1|b = 1, i = 0) = 0.6
σ(c = 1|b = 0, i = 1) = 0.6
σ(c = 1|b = 0, i = 0) = 0.05
Q = q(m = 0, t = No) = 100
Q = q(m = 1, t = No) = 20
Q = q(m = 0, t = Yes) = 80
Q = q(m = 1, t = Yes) = 70
The objective of this problem is to maximize the expected utilities as follows.
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}\max_{t} E [ U ( q \mid m , t ) ] = \max_{t} \sum q ( m , t ) \sigma ( m \mid b , c , i ) \tag{29}\end{align*}
\end{document}
where σ(m|b, c, i) is the posterior (belief) function of m, and
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
\begin{split} \sigma ( m \mid b , c , i ) = \frac { \sigma ( m ,
b , c , i ) } { \sigma ( b , c , i ) } \\ = \frac { \sigma ( m )
\sigma ( b \mid m ) \sigma ( i \mid m ) \sigma ( c \mid b , i ) }
{ \sum \limits_ { m } \sigma ( m ) \sigma ( b \mid m ) \sigma ( i
\mid m ) \sigma ( c \mid b , i ) } \end{split} \tag { 30 }
\end{align*}
\end{document}
Suppose the observation c = 0 then:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}\sigma ( m = 1 \mid c = 0 ) = \frac { { \sum \limits_ { b , c = 0 , i } \sigma ( m = 1 ) \sigma ( b \mid m = 1 ) \sigma ( i \mid m = 1 ) \sigma ( c = 0 \mid b , i ) } } { \sum \limits_ { b , c = 0 , i , m } \sigma ( m ) \sigma ( b \mid m ) \sigma ( i \mid m ) \sigma ( c = 0 \mid b , i ) } \tag { 31 } \end{align*}
\end{document}
The numerator and denominator of (31) can be computed as
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*} \sum_{b , c = 0 , i} \sigma ( m = 1 ) \sigma ( b \mid m = 1 ) \sigma ( i \mid m = 1 ) \sigma ( c = 0 \mid b , i ) \\ = \sigma ( m = 1 ) \sigma ( b = 1 \mid m = 1 ) \sigma ( i = 1 \mid m = 1 ) \sigma ( c = 0 \mid b = 1 , i = 1 ) + \\ \sigma ( m = 1 ) \sigma ( b = 1 \mid m = 1 ) \sigma ( i = 0 \mid m = 1 ) \sigma ( c = 0 \mid b = 1 , i = 0 ) + \\ \sigma ( m = 1 ) \sigma ( b = 0 \mid m = 1 ) \sigma ( i = 1 \mid m = 1 ) \sigma ( c = 0 \mid b = 0 , i = 1 ) + \\ \sigma ( m = 1 ) \sigma ( b = 0 \mid m = 1 ) \sigma ( i = 0 \mid m = 1 ) \sigma ( c = 0 \mid b = 0 , i = 0 ) \\ = 0.2 \times 0.7 \times 0.8 \times 0.1 + 0.2 \times 0.7 \times 0.2 \times 0.4 + \\ 0.2 \times 0.3 \times 0.8 \times 0.4 + 0.2 \times 0.3 \times 0.2 \times 0.95 \\ = 0.053\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*} \sum_{b , c = 0 , i} \sigma ( m = 0 ) \sigma ( b \mid m = 0 ) \sigma ( i \mid m = 0 ) \sigma ( c = 0 \mid b , i ) \\ = \sigma ( m = 0 ) \sigma ( b = 1 \mid m = 0 ) \sigma ( i = 1 \mid m = 0 ) \sigma ( c = 0 \mid b = 1 , i = 1 ) + \\ \sigma ( m = 0 ) \sigma ( b = 1 \mid m = 0 ) \sigma ( i = 0 \mid m = 0 ) \sigma ( c = 0 \mid b = 1 , i = 0 ) + \\ \sigma ( m = 0 ) \sigma ( b = 0 \mid m = 0 ) \sigma ( i = 1 \mid m = 0 ) \sigma ( c = 0 \mid b = 0 , i = 1 ) + \\ \sigma ( m = 0 ) \sigma ( b = 0 \mid m = 0 ) \sigma ( i = 0 \mid m = 0 ) \sigma ( c = 0 \mid b = 0 , i = 0 ) \\ = 0.8 \times 0.2 \times 0.2 \times 0.1 + 0.8 \times 0.2 \times 0.8 \times 0.4 + \\ 0.8 \times 0.8 \times 0.2 \times 0.4 + 0.8 \times 0.8 \times 0.8 \times 0.95 \\ = 0.592\end{align*}
\end{document}
Then (31) can be obtained as
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*} \sigma ( m = 1 \mid c = 0 ) = \frac { \sum_ { b , c = 0 , i } \sigma ( m = 1 ) \sigma ( b \mid m = 1 ) \sigma ( i \mid m = 1 ) \sigma ( c = 0 \mid b , i ) } { \sum_ { b , c = 0 , i , m } \sigma ( m ) \sigma ( b \mid m ) \sigma ( i \mid m ) \sigma ( c = 0 \mid b , i ) } \\ = \frac { 0.053 } { 0.053 + 0.592 } = 0.0822 \end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*} \sigma ( m = 0 \mid c = 0 ) = \frac { \sum_ { b , c = 0 , i } \sigma ( m = 0 ) \sigma ( b \mid m = 0 ) \sigma ( i \mid m = 0 ) \sigma ( c = 0 \mid b , i ) } { \sum_ { b , c = 0 , i , m } \sigma ( m ) \sigma ( b \mid m ) \sigma ( i \mid m ) \sigma ( c = 0 \mid b , i ) } \\ = \frac { 0.592 } { 0.053 + 0.592 } = 0.9178 \end{align*}
\end{document}
Hence
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*} & E [ U ( q \mid m , t = { \rm Yes} ) ] \\ & = \sum_{b , i} q ( m = 1 , t = { \rm Yes} ) \sigma ( m = 1 \mid c = 0 ) + \sum_{b , i} q ( m = 0 , t = { \rm Yes} ) \sigma ( m = 0 \mid c = 0 ) \\ & = q ( m = 1 , t = { \rm Yes} ) \sum_{b , i} \sigma ( m = 1 \mid c = 0 ) + q ( m = 0 , t = { \rm Yes} ) \sum_{b , i} \sigma ( m = 0 \mid c = 0 ) \\ & = 70 \times 0.0822 + 80 \times 0.9178 \\ = 79.178\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*} & E [ U ( q \mid m , t = { \rm No} ) ] \\ & = \sum_{b , i} q ( m = 1 , t = { \rm No} ) \sigma ( m = 1 \mid c = 0 ) + \sum_{b , i} q ( m = 0 , t = { \rm No} ) \sigma ( m = 0 \mid c = 0 ) \\ & = q ( m = 1 , t = { \rm No} ) \sum_{b , i} \sigma ( m = 1 \mid c = 0 ) + q ( m = 0 , t = { \rm No} ) \sum_{b , i} \sigma ( m = 0 \mid c = 0 ) \\ & = 20 \times 0.0822 + 100 \times 0.9178 \\ & = 93.424\end{align*}
\end{document}
Hence, the optimal decision to maximize the utilities is
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}\max_{t}E [ U ( q \mid m , t ) ] = \max_{t} \{ 79.178 , 93.424 \} = 93.424\end{align*}
\end{document}
where the optimal decision is t = No (no treatment).
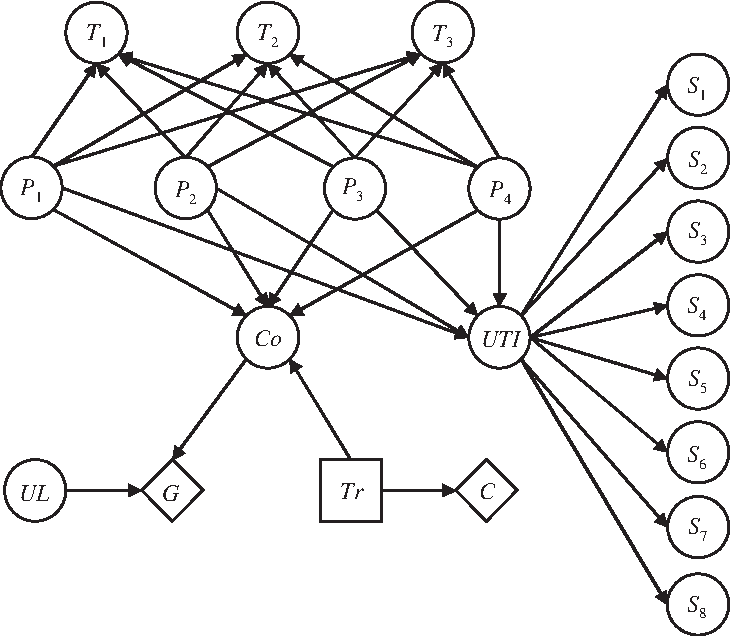
Example 2. Consider a case of urinary tract infection (UTI) modified from Leibovici et al. (2000), as shown in Figure 9.
A case of urinary tract infection (UTI).
There are one decision node VD = {Tr}, two value nodes Vu = {C, G}, and eighteen chance nodes VR = {Co, UL, UTI, P1, P2, P3, P4, T1, T2, T3, S1, S2, S3, S4, S5, S6, S7, S8} relevant to the urinary tract infection and treatments. The descriptions and states of the nodes are listed as below.
1. Tr (antibiotic treatment): A decision node that the treatment will be suitable if it matches the in vitro susceptibility of the pathogens. In this case, we consider one state for no treatment and five antibiotic drugs. There are six alternatives, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$Tr = \{ tr \} , tr = 0 , 1 , \ldots , 5$$
\end{document} , where tr = 0 means no treatment; \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$tr = i , i = 1 , 2 \ldots , 5$$
\end{document} stands for the ith treatment prescribed.
2. C (costs of antibiotic treatment): A value node associated with costs of antibiotic treatments, tri.
3. G (gain in life expectancy): A value node associated with the gain in life expectancy obtained by prescribing an antibiotic drug, which is a function of the coverage of urinary tract infection (Co) and the underlying disorder of the patient (UL).
4. Co (coverage of urinary tract infection): The percent of pathogens of urinary tract infection impressionable to an antibiotic drug. The states of Co are not covered (Co = 0) and covered (Co = 1), Co ∈ {0, 1}.
5. Pi (pathogen): A microorganism capable of causing urinary tract infection. In this case, four pathogens are considered: P1 (Klebsiella pneumoniae), P2 (Pseudomonas aeruginosa), P3 (Escherichia coli), and P4 (proteus). The states of Pi are not severe (Pi = 0) and severe (Pi = 1), Pi ∈ {0, 1},i = 1, 2, 3, 4.
6. Si (symptoms of urinary tract infection): The manifestations caused from urinary tract infection. In this case, eight symptoms are considered: S1 (suprapubic pain), S2 (frequent micturition), S3 (flank pain), S4 (urinary), S5 (serum albumin), S6 (fever), S7 (leucocyturie), and S8 (hematuria). The states of Si are absent (Si = 0) and present \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$( S_i = 1 ) , \ S_i \in \{ 0 , 1 \} , i = 1 , 2 , \ldots , 8$$
\end{document}.
7. T1 (bacteriological tests): Three bacteriological tests are considered: T1 (growth of microorganisms in blood), T2 (growth of microorganisms in urine), and T3 (nitrite test). The states of Ti are negative (Ti = 0) and positive (Ti = 1), Ti ∈ {0, 1}, i = 1, 2, 3.
8. UL (underlying disorder of the patient): This will be illustrated by an equivalent base years of the remaining life.
9. UTI (urinary tract infection): The states of UTI are not infected (UTI = 0) and infected (UTI = 1), UTI ∈ {0, 1}.
The descriptions and states of the nodes are summarized in Table 3. Consider the evidence that a patient has suffered from frequent micturition (S2 = 1), flank pain (S3 = 1), urinary symptoms (S4 = 1), and leucocyturie (S7 = 1), but has not fallen into a suprapubic pain (S1 = 0), serum albumin (S5 = 0), fever (S6 = 0), or hematuria (S8 = 0). The evidence set is {S1 = 0,S2 = 1,S3 = 1,S4 = 1,S5 = 0,S6 = 0,S7 = 1,S8 = 0}. We intend to maximize the expected net gain of life expectancy according to the symptoms as below
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}\max_{tr} Gain = E [ G ( co , ul ) - C ( tr ) ] \tag{32}\end{align*}
\end{document}
Following the assumption (Kao and Li, 2005) that the underlying disorder and health status can be converted to an equivalent base year; in this case, 35 years base and 1 year gained in life can be regarded as equivalent to $55,000 (given ul) (Leibovici et al., 2000). The gain can be computed as below
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
\begin{split} & Gain \\ & = 55 , 000 \times \sigma ( co \mid s_{1} , s_{2} , \ldots , s_{8} ) - C ( tr ) \\ & = 55 , 000 \times \sum_{ \scriptstyle p_{1} , p_{2} , p_{3} , p_{4} , \atop \scriptstyle tr , uti} \sigma ( co \mid p_{1} , p_{2} , p_{3} , p_{4} , tr , uti , s_{1} , s_{2} , \ldots , s_{8} ) - C ( tr ) \end{split}
\tag{33}\end{align*}
\end{document}
Selected rough sets of this case are shown in Table 4.
We adopt the stochastic simulation method as shown in Table 5 to obtain the optimal treatment and utility. The results are shown in Table 6. The optimal treatment is tr3, which brings about $22,820 equivalent net gain.
The Stochastic Simulation Algorithm
for i=1 to simulation_ no do:
Choose the current node X from UnknownNodeList.
If EOF, then X=the first node in UnknownNodeList
and proceed to next iteration.
Compute \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$ \frac { \sigma ( X = 1 \mid W_x ) } { \sigma ( X = 0 \mid W_x ) } $$
\end{document}, where Wx is the conditions of all
neighboring nodes (Markov blanket) of X without X itself.
Assign X the random number generator favoring 1 by the ratio
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$ \frac { \sigma ( X = 1 \mid W_x ) } { \sigma ( X = 0 \mid W - x ) } $$
\end{document}.
If X=1, then count(X)=count(X)+1.
Assign X the next node in UnknownNodeList.
End. /* of for */
Compute BEL(*) the ratio of the target value of every node * in UnknownNodeList. Then check BEL(*) with test data to validate the accuracy of classification.
The Result of Urinary Tract Infection (UTI)
Treatment
Certainty Co
Gain
Cost
Net gain
tr0
0.360
19800
5000
14800
tr1
0.770
42350
20000
22350
tr2
0.835
45925
25000
20925
tr3
0.924
50820
28000
22820
tr4
0.795
43725
32000
11725
tr5
0.898
49390
32000
9390
6. Conclusions and Future Plans
This study proposes an alternative numerical framework for influence diagrams, rough sets, and develops the rough-set influence diagrams that combine decision rules with the graphical structure in medical settings. Considering the imprecise knowledge, this study formulates the causal relationships and the decision rules among the nodes (attributes) with rough sets from information systems. The proposed knowledge model provides a comprehensive schema for knowledge representation and decision support.
For future studies, there are several potential themes: (1) to integrate analysis with rough sets in various graphical decision models, including Bayesian networks, decision trees, and influence diagrams; (2) hybrid decision analysis with fuzzy sets and rough sets in graphical decision models; and (3) potential applications of intelligent decision support with rough sets, such as supply chain management, business strategic analysis, and biomedicine.
Footnotes
Acknowledgments
The author would like to appreciate the anonymous referees for their careful reading and fruitful comments on the manuscript. Also special thanks to the National Science Council, Taiwan, for financially supporting this research under grant no. NSC 100-2410-H-141-006-MY2 and 102-2410-H-141-012-MY2.
Author Disclosure Statement
The author declares that there is no conflict of interest regarding the publication of this article. No competing financial interests exist.
References
1.
CooperG.F.1984. NESTOR: a computer-based medical diagnostic aid that integrates causal and probabilistic knowledge [PhD dissertation].Department of Computer Science, Stanford University.
2.
HowardR.A., and MathesonJ.E.1981. Influence diagrams, 719–762. In HowardR.A., and MathesonJ.E., eds. The Principles and Applications of Decision Analysis. Strategic Decisions Group, Menlo Park, CA.
3.
JensenF.V.2001. Bayesian Networks and Decision Graphs. Springer-Verlag, Inc., New York.
4.
KaoH.Y.2008. Diagnostic reasoning and medical decision-making with fuzzy influence diagrams. Comput. Meth. Prog. Bio., 90, 9–16.
5.
KaoH.Y., and LiH.L.2005. A diagnostic reasoning and optimal treatment model for bacterial infections with fuzzy information. Comput. Meth. Prog. Bio., 77, 23–37.
6.
KononenkoI.2001. Machine learning for medical diagnosis: history, state of the art and perspective. Artif. Intell. Med., 23, 89–109.
7.
LeiboviciL., FishmanM., SchunheyderH.C., et al.2000. A causal probabilistic network for optimal treatment of bacterial infections. IEEE Trans. Knowl. Data Eng., 12, 517–528.
8.
LiH.L., and KaoH.Y.2005. Constrained abductive reasoning with fuzzy parameters in bayesian networks. Comput. Oper. Res., 32, 87–105.
9.
LongW.J.2001. Medical informatics: reasoning methods. Artif. Intell. Med., 23, 71–87.
10.
López-DíazM., and Rodríguez-MuñizL.J.2007. Influence diagrams with super value nodes involving imprecise information. Eur. J. Oper. Res., 179, 203–219.
NeaseR.F., and OwensD.K.1997. Use of influence diagrams to structure medical decisions. Med. Decis. Making, 17, 263–275.
13.
OliverR.M., and SmithJ.Q.1990. Influence Diagrams, Belief Nets and Decision Analysis, John Wiley & Sons, New York.
14.
OwensD.K., ShachterR.D., and NeaseR.F.1997. Representation and analysis of medical decision problems with influence diagrams. Med. Decis. Making, 17, 251–262.
15.
PearlJ.1997. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference. Morgan Kaufmann Publishers, Inc., Burlington, MA.
16.
PawlakZ.1982. Rough sets. Info. J. Info. Comput. Sci., 11, 341–356.
17.
PawlakZ.1991. Rough Sets-Theoretical Aspects of Reasoning About Data. Kluwer Academic Publishers, Dordrecht.
18.
PawlakZ.2002. Rough sets, decision algorithms and Bayes' theorem. Eur. J. Oper. Res., 136, 181–189.
19.
PawlakZ.2003. Probability, truth and flow graph. Electron. Notes Theor. Comput. Sci., 82, 1–9.
20.
PawlakZ., WongS.K.M., and ZiarkoW.1988. Rough sets: probabilistic versus deterministic approach. Int. J. Man Mach. Stud., 29, 81–95.