
Abstract
Abstract
Observations depending on sums of random variables are common throughout many fields; however, no efficient solution is currently known for performing max-product inference on these sums of general discrete distributions (max-product inference can be used to obtain maximum a posteriori estimates). The limiting step to max-product inference is the max-convolution problem (sometimes presented in log-transformed form and denoted as “infimal convolution,” “min-convolution,” or “convolution on the tropical semiring”), for which no O(k log(k)) method is currently known. Presented here is an O(k log(k)) numerical method for estimating the max-convolution of two nonnegative vectors (e.g., two probability mass functions), where k is the length of the larger vector. This numerical max-convolution method is then demonstrated by performing fast max-product inference on a convolution tree, a data structure for performing fast inference given information on the sum of n discrete random variables in O(nk log(nk)log(n)) steps (where each random variable has an arbitrary prior distribution on k contiguous possible states). The numerical max-convolution method can be applied to specialized classes of hidden Markov models to reduce the runtime of computing the Viterbi path from nk2 to nk log(k), and has potential application to the all-pairs shortest paths problem.
1. Introduction
I
In all of these fields, the information on sums of random variables presents a singular obstacle to computational biology. And regardless of how infrequently we as scientists directly discuss our current inability to effectively utilize information about sums of random variables, the perception of our limited ability to meet the challenge has become firmly entrenched in our collective unconscious; the silent agreement on our inability to turn the sausage grinder backward and convert the sausage (information about the sum of several random variables) back into the pigs (information about those random variables that contributed to the sum) is so well established that it not only defines the way we address these data (i.e., mass spectra peaks containing multiple analytes, counts of non unique reads, etc.), but it also causes us to discard data and even limit research directions we might otherwise consider. For instance, in mass spectrometry, substantial effort is invested in chromatography (Barnes, 1992; James and Martin, 1952) and other separation techniques (Pringle, et al., 2007), which aim to distinguish and separate analytes so that they will not be measured by the mass spectrometer simultaneously (thereby reducing the chances of analytes resulting in overlapping peaks); the task of decomposing this useful aggregate information from overlapping peaks back into information about its contributing parts is eschewed in favor of significant investments in instrumentation [e.g., more and more advanced separation technologies and higher-resolution mass spectrometers (Polacco et al., 2011)], and still it is common practice to discard shared isotope peaks and shared peptides even though they may comprise a large percent of the data and contain additional information (Dost et al., 2009; Serang et al., 2013). Likewise, in genomics and transcriptomics it is common to simply discard all data from nonunique reads (Lefrançois et al., 2009; Zentner et al., 2011). In burgeoning fields such as metagenomics, this loss of data—and subsequent loss of information—can be even more pronounced, for instance when all data that map to two or more species of interest are discarded. In some cases, recovering this lost information will be the key to making strong conclusions, such as distinguishing between two closely related species (or bacterial strains) in a metagenomic mixture.
1.1. Sum-product inference
Fast Fourier transform (FFT)-based convolution can be used to dramatically improve the efficiency of computing the sum-product addition of two discrete random variables. For three discrete random variables where M=L+R and where
where * performs the convolution between the two k-length vectors storing each PMF.
Whereas naive convolution would compute pmf
M
in O(k×k) steps, FFT exploits the bijection of this convolution to the product between two polynomials (where the vectors being convolved are the coefficients of the polynomials being multiplied and the coefficients of their product forms the vector result); this bijection enables the use of alternative forms for representing the polynomials (each order k − 1 polynomial can be represented through k unique points through which it passes), which in turn permits elegant divide and conquer algorithms such as the Cooley-Tukey FFT to compute fast convolution in k log(k) steps. Subtraction in the sum-product (i.e., computing L=M − R) scheme can be performed by first negating R′=−R (this is done by reversing the vector storing the PMF pmfR′[r]=pmf
R
[−r]), and then adding L=M+R′ as before via FFT convolution
The task of processing information about the sum of n discrete variables (each with k bins) to retrieve information on the individual variables can be performed naively in O(kn) steps by simply enumerating the exponentially many possible outcomes; however, such brute-force techniques are wildly inefficient when either n or k become large. Fortunately, recent work proposes methods to decompose larger problems (e.g., into multiple sums and differences of pairs of discrete variables of the form M=L+R and L=M − R, very fast inference can be achieved). This has been derived for binary variables (k=2) in n log(n) log(n) (Tarlow et al., 2012), and was independently discovered for arbitrary discrete distributions (i.e., where k>2) and to multidimensional distributions (via matrix convolution, which can be decomposed into one-dimensional convolutions by the row-column algorithm) using the probabilistic convolution tree (Serang, 2014) (Algorithm 1). In the general case, distributions on all individual variables conditional on information about the sum can be computed in O(nk log(nk) log(n)) steps [whenever klog(k) fast convolution is available]:
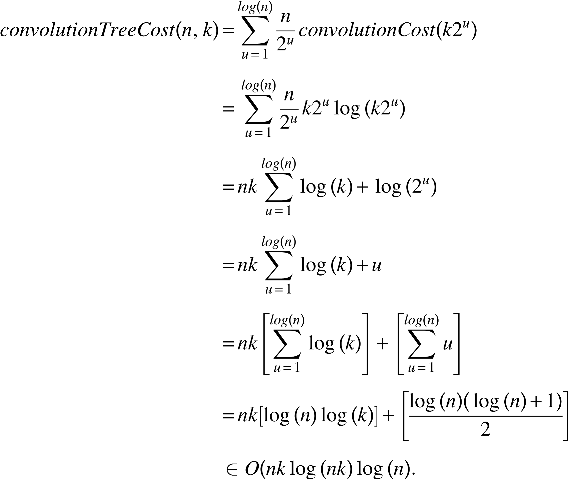
In practice, this can be significantly faster than the O(n2k2) steps required by dynamic programming when fast convolution is not available. For instance, when an observed transcript fragment could originate from n=256 species, and where the abundance of each species is discretized into k=1024 bins, then fast convolution makes inference more than 1800 times faster (the difference between one algorithm taking 1 sec and the other taking 30 min), and the disparity only grows for problems with larger values of n and k. It should be noted that these are only approximate runtimes calculated from the Big O form; in practice, it is fairly likely that methods based on fast convolution will be significantly faster, because of the method's inherent properties and the fact that very optimized implementations exist.
The probabilistic convolution tree algorithm utilizes fast convolution (or fast max-convolution) to efficiently turn information on sums of variables back into information on the individual variables. The first parameter

1.2. Max-product inference
Qualitatively, max-product inference is a close cousin to sum-product inference. Where sum-product inference considers each of the exponentially many joint events and allows each to contribute to the result (in hidden Markov models, this is analogous to the forward-backward algorithm), max-product inference allows only the highest-quality joint events to contribute (in hidden Markov models, this defines the Viterbi path). Both inference methods have complementary advantages and disadvantages: The advantage of sum-product inference is its democratized equal weighting of all joint events, the variety of which can provide a rich description of any high-probability joint events suggested by the data; however, this can also have disadvantages in that many low-quality joint events (i.e., those with low joint probability) may shape the result as much as a small number of high-quality results. Likewise, in sum-product inference, multiple mutually exclusive joint events can simultaneously contribute to the result, raising the potential to erroneously infer implausible conclusions, because both may be plausible before considering the other. It is because of these disadvantages in sum-product inference that max-product inference is widely used, because it forces the inferences to be jointly plausible (not simply individually, but as a whole), and because it drowns out noise from low-quality configurations that can diffuse and lower the certainty of conclusions in sum-product inference.
Specifically, efficient max-product inference on sums of random variables would be quite useful; in addition to the examples of shared peptides, nonunique reads, etc., found throughout computational biology (wherein we have information about the sum of variables, but want to draw conclusions about the variables themselves), more efficient max-product inference would make possible new inference algorithms on specialized classes of hidden Markov models (HMMs) where the transition probabilities from the state at index a to the state at index b depend on a function of either a+b or a−b or b−a. Such HMMs have applications in finance and time series analysis, where the k states at any layer are high-resolution discretizations of some quantity or price, and where the probability of a price moving up or down is influenced by the quantity up or down that it moved since the previous time point. In a general HMM with k states and n layers of those states, performing either sum-product (via the forward-backward algorithm) or max-product (via the Viterbi algorithm) inference requires O(nk2) steps; however, performing sum-product inference on the specialized class of HMMs mentioned above would require only O(nk log(k)) steps, because each layer can be processed as a two-node convolution tree. But finding the Viterbi path on such a model in O(nk log(k)) steps is not currently feasible, because doing so would require performing max-convolution (where the max of all valid pairings is chosen rather than the sum over all valid pairings) in O(k log(k)) steps.
However, despite the promise of max-product inference on sums of random variables, a fast practical solution that utilizes O(klog(k)) max-convolution (i.e., one with speed roughly comparable to FFT-based standard convolution) is not yet available for the general max-convolution problem. One special case, for use only when k=2 (Gupta et al., 2007; Tarlow et al., 2010), can solve the problem in nlog(n) time by sorting the n variables in descending order of probability
Adapting the probabilistic convolution tree algorithm from
where *max is the max-convolution operator. The loss of the bijective polynomial representation prevents the exploitation of the Lagrange form of polynomials, and thus there is no known klog(k) algorithm for performing max-convolution.
Excluding such highly specialized methods as the rank method of Babai Babai and Felzenszwalb (2009) [which achieves a runtime of
The method from Bussieck has a O(k2) runtime in the worst case, but under a certain distribution, values in the two vectors being convolved, the authors demonstrate an expected runtime of O(k log(k)) (Bussieck et al., 1994). The approach works by starting the result
The method of Bremner et al. [which was subsequently extended by Williams (2014)] draws a relationship between min-convolution and the necklace alignment problem, wherein two collections of beads, each on its own circular string, are rotated to optimally align (Bremner et al., 2006). Their method is the most sophisticated in existence and consists of a highly complicated exploitation of similarity to the all-pairs shortest paths problem to achieve a method with a subquadratic worst-case runtime of
Thus, even with significant mathematical sophistication of these two state-of-the-art methods, practically efficient max-product inference may be out of reach for even moderately sized problems.
2. A Numerical Method for Efficiently Estimating Max-Convolution
Here I will introduce a numerical method for estimating the max-convolution in k log(k) time, which can be applied easily using existing high-performance numerical software libraries. This is essentially performed by transforming both the inputs and outputs of the FFT to achieve p-norm convolution, which in turn is used as an approximation for max-convolution via the Chebyshev norm.
For a max-convolution between pmf
L
and pmf
R
at each m value, the shifted product's terms can be rewritten as a simple vector u(m) where elements are defined by
Furthermore, because PMFs consist of nonnegative real values (or machine-precision representations), then this can be rewritten using the Chebyshev norm, which computes the maximum absolute value in the vector u(m). Because u(m) comes from the product of PMF terms, it is also nonnegative and thus absolute values can be ignored in both the computation and the result:
And then each element of u(m)[ℓ] can be expanded back into its original factors:
At this point, a sufficiently large value p* is used in place of the limit p→∞ :
At this point, it can be observed that every time elements of the PMFs pmf
L
[ℓ] and pmf
R
[m − ℓ] appear, they are raised to the p* power; thus, it is possible to change variables and let
yielding
A similar strategy can be made for
And thus it becomes clear that vM is the result of standard convolution (not a max-convolution) between vL and vR. This suggests a numerical algorithm that can make use of existing FFT convolution libraries to compute vM=vL * vR in O(k log(k)) steps (Algorithm 2).
Numerical max-convolution (initial version), a numerical method to estimate the max-convolution of two PMFs or nonnegative vectors. The parameters are two PMFs, pmf L and pmf R (by definition nonnegative), and the numerical value p* used for computation. The return value is a numerical estimate of the max-convolution pmf L *max pmf R .

2.1. Reducing underflow
The main caveat for numerical methods is often the loss of precision due to underflow when raising small probabilities to the power p* (in this case, no overflow occurs because the inputs are probabilities); such losses may not be undone later when raising to the
Numerical max-convolution (normalized version), a numerical method to estimate the max-convolution of two PMFs or nonnegative vectors (revised to reduce underflow). The parameters are two PMFs pmf L and pmf R (by definition nonnegative) and the numerical value p* used for computation. The return value is a numerical estimate of the max-convolution pmf L *max pmf R .

Note that, like standard implementations of fast convolution *, in implementing the fast *max operator it is possible to automatically choose between a naive implementation or the fast numerical implementation depending on the size of the problem; on very small problems (e.g., k=8), the naive operation will have less overhead and can be a bit faster [the specific threshold can be chosen roughly by comparing the expected running time from the fast numerical method O(k′log(k′))—where k′ is double the next integer power of two and the log is base two—to the O(k2) naive method]; this can reduce numerical error further.
3. Results
I briefly compare the speed and accuracy of the fast numerical max-convolution method as compared to naive max-convolution. Both methods are implemented in the Python programming language using floating point math and the numpy package (the fast numerical max-convolution method is implemented from Algorithm 3.
3.1. Practical efficiency of fast numerical max-convolution
The speed of naive max-convolution is compared to the fast numerical estimate. For each k ∈{32, 64, 128, 256, 512, 1024, 2048, 4096, 8192}, random pairs of vectors with uniform elements [i.e., each element is drawn from uniform(0, 1)]. The result of the max-convolution

Runtime comparison between naive and fast numerical convolution. Note the increasing gap between the two curves indicates a nonlinear speedup due to the log scaling of both axes (because the runtime of the fast numerical method is dominated by Fast Fourier transform (FFT) calculation).
3.2. Accuracy of fast numerical max-convolution compared to naive max-convolution
A cursory empirical test of the numerical stability as a result of p* and the vector length k was performed. In Figure 2, the numerical stability was demonstrated on 64 random pairs of vectors for each length k ∈128, 256, 512, 1024. For all p* ∈{2, 4, 8, 16, 32, 64}, and the relative absolute error of each element in the result of the max-convolution is computed
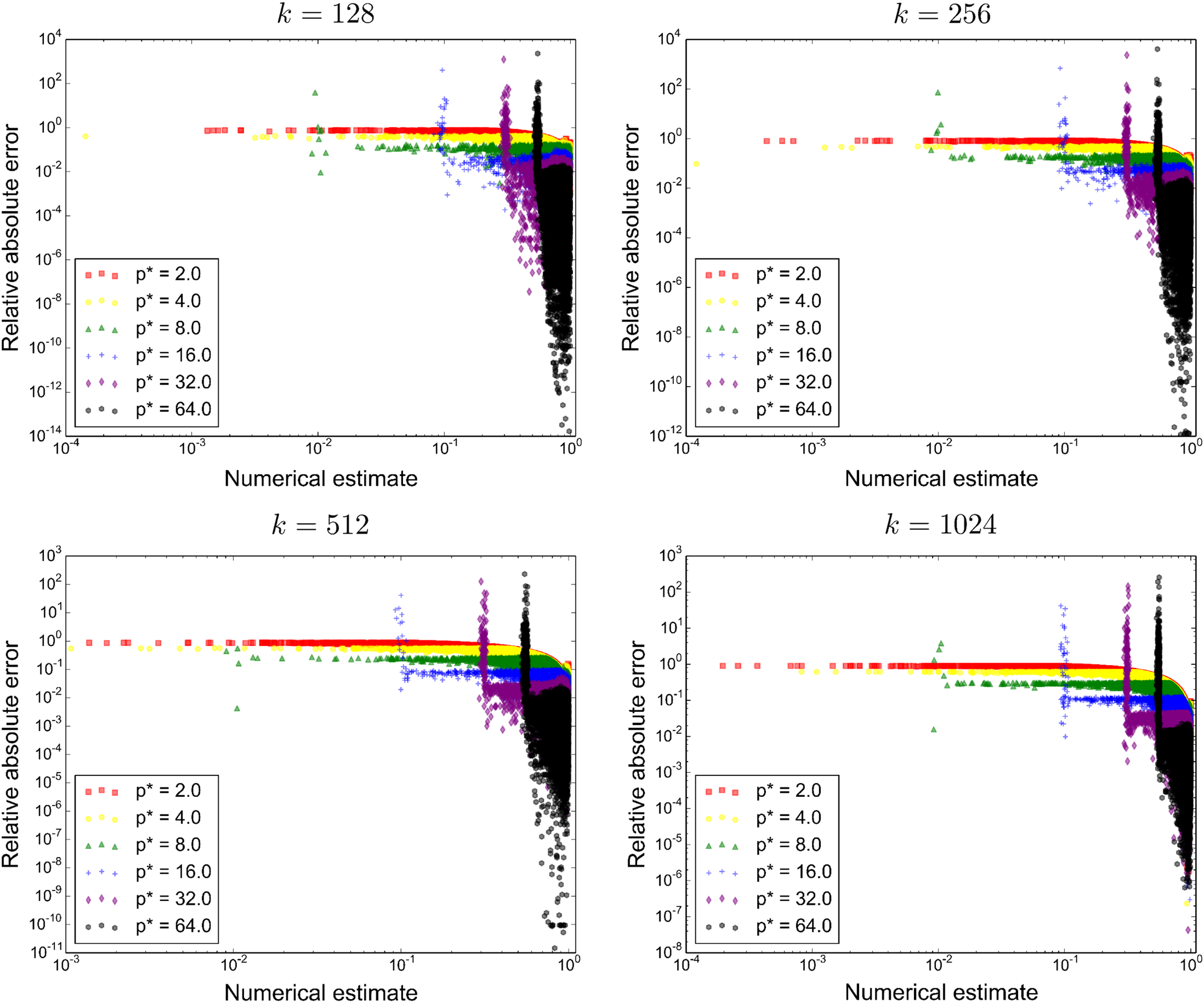
The influence of the parameter p* on max-convolution accuracy. For each k ∈{128, 256, 512, 1024}, 64 replicate max-convolutions are performed to compare the relative error of the fast numerical method compared to the naive method. This is performed for different values of p*; lower values of p* perform well when the exact result is close to zero, and higher values of p* perform better otherwise, and this relationship is invariant of k when the data are scaled in the manner presented (they are scaled so that the largest element has value 1).
Numerical max-convolution (piecewise version), a numerical method to estimate the max-convolution of two PMFs or nonnegative vectors (further revised to strategically choose p*). The parameters are two PMFs, pmf
L
and pmf
R
both with k outcomes (and both by definition nonnegative). The return value is a numerical estimate of the max-convolution pmf
L
*max pmf
R
. This algorithm calls the revised method maxConvolutionRevised from Algorithm 3. Note that the values of

Qualitatively, optimizing the numerical performance involves satisfying competing ideals: when p* is large, the problem solved converges to the max-convolution inference, but underflow becomes significant. When p* is too small, nonmaximal terms contribute to the result (more similar to a standard convolution).
Although more sophisticated numerical analysis would almost certainly yield larger improvements to the method, a simple improvement is exploited: Generally the relative error is fairly low, but only becomes high in these experiments when the exact value at that index is close to zero (this is intuitive from the formula for relative absolute error). Since underflow allowed to propagate through the FFT is the only numerical consideration (overflow before the FFT does not occur because the values are normalized to the maximum), then it follows that a result that is not close to zero at some index is a high-quality estimate when p* is substantially large (if it suffered from too much underflow, then it would approach zero quickly). Therefore, when using a high value of p*, indices where the numerical solution is close to zero indicate the potential for numerical error and suggest that a smaller value of p* could be used for those indices. This yields a further improvement where a more accurate result can be constructed from two calls of Algorithm 3; this improved method is shown in Algorithm 4, and runs in roughly twice as many steps as Algorithm 3 [still ∈O(klog(k))]. Note that this piecewise method could be trivially extended to use more than two values of p*, increasing accuracy at the expense of additional runtime (although, assuming the results using the different values of p* are computed in decreasing order, then the routine could potentially terminate once the result has been estimated at all indices with adequate numeric stability).
3.3. Using fast numerical convolution to solve a probabilistic subset sum problem
Lastly, a three-way piecewise implementation of max-convolution similar to the one shown in Algorithm 4 but using p* ∈{4, 32, 64} (the Python code of this three-way piecewise method is given in the accompanying Python demonstration code) is used to solve a simulated probabilistic generalization of the the subset sum problem [note that even the deterministic subset sum problem is very similar to the definition of the knapsack problem from Karp's 21 NP-complete problems and is itself NP-complete (Karp, 1972)]. In this problem, n=32 people go shopping and each person j in
Data are generated as follows: At each variable
On each problem instance, likelihoods for all inputs (
A single likelihood distribution
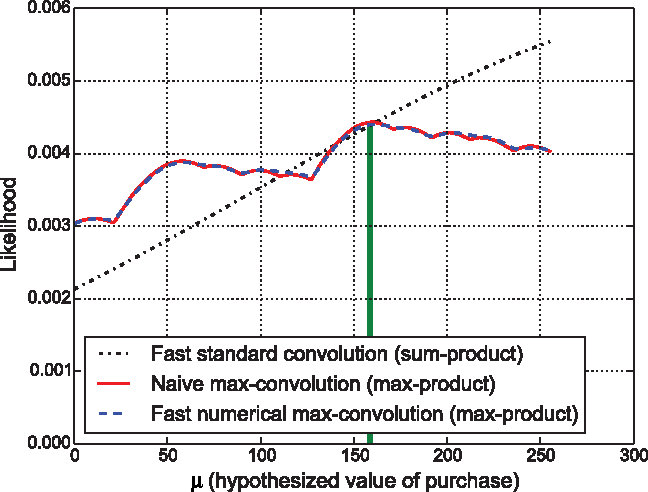
Using fast numerical max-convolution for max-product inference. A single likelihood distribution for an arbitrary
4. Discussion
Although its ethos may ultimately limit the utility of this method to numerical settings where small errors are tolerable [as opposed to the to more general theoretical articles previously mentioned (Bussieck et al., 1994; Bremner et al. 2006)], the numerical method proposed here gives a simple and very fast estimate of the max-convolution result, which could allow use of numerical max-convolution (or max-product inference on the sums and differences between discrete distributions) in settings where it is currently far too computationally expensive. The largest caveat to the method is the inaccuracy that can occur due to numerical bottlenecks (e.g., underflow); however, for many problems (e.g., practical applications of the max-product inference problem in Fig. 3), the numerical method is sufficient to perform high-quality inference, but in a dramatically faster time.
Furthermore, the connection between the max-convolution problem and the all-pairs shortest path problem from graph theory (Bremner et al. 2006) means that the fast numerical method can be used to compute fast numerical approximations to that important computer science problem. Such fast numerical estimates could complement theoretical solutions to that problem.
A more in-depth theoretical analysis of the algorithm's error would likely yield multiple opportunities to modify the algorithm in order to decrease error. For example, one possible improvement could be performed by using log-transformed real values: in log-transformed space, raising to the power p* would be equivalent to scaling by p* and would not produce significant underflow. Furthermore, the operations required by FFT convolution could be performed in log-space by translating the ring (+, ×) on real values to its equivalent ring (log+, log×)=(log+, +) on log-transformed values, where the operation log+(x, y) is performed by dividing out the greater of the two arguments x (w.l.o.g.) and then computing
In a similar vein, more sophisticated techniques for locally choosing among a small number of values for p* (compared to a simple piecewise function on two possible values of p*). For instance, under roughly uniform distributions of values in the two vectors being max-convolved, the values closest to zero (and thus having higher chance of having high relative absolute error) will occur more commonly at the first and last indices of the numerical estimate (because those indices take the maximum over smaller collections of elements, and are thus more likely to be smaller values). Similar attention could be put toward scaling the vectors prior to taking elements to the p* (compared to the current procedure of dividing by the maximum element value) may minimize the underflow on a large number of points with large values. A most exciting possibility would be that having an accurate estimate of the max-convolution result somehow could be used to compute a more accurate result (e.g., using approximate results from different p* and exploiting the property ‖·‖ p ≥‖·‖p+δ when p≥1 and δ > 0). Such directions of future research could possibly solving the max-convolution iteratively over a bounded or constant number of subproblems where each subproblem requires O(klog(k)), by first computing initial estimates of the max-convolution result with the numerical method presented here, and then using those initial estimates to parameterize a subsequent call to the numerical method in a manner reminiscent of the QR algorithm for eigendecomposition (Francis, 1961, 1962). From Algorithm 4, it seems highly likely that there will be more ways by which an initial result can be used to obtain a higher-accuracy result.
Furthermore, even pursuing methods for obtaining very high accuracy with large values of p* may not always be of substantial interest. Indeed, even if no improvement to accuracy is ever presented, the design and parameterization of machine learning methods (including graphical models) has traditionally been empirically driven, and the use of exact max-product inference is hardly sacrosanct in every application (as opposed to inference somewhere between sum-product and max-product). From this perspective, rather than choosing p* as a static constant value p*=1 (i.e., performing sum-product inference) or p*→∞ (i.e., performing max-product inference), p* could be viewed as a hyperparameter that is used to position inference on a continuum somewhere between all joint events contributing equally to the end result (sum-product) and only the best joint event contributing (max-product), and intermediate values of p* would establish a preference for the top few joint events. In this sense, the value chosen for p* could be driven by the data, and the problem of p-norm convolution (where a finite p is desired, rather than max-convolution where p→∞ ) can already be solved with very high accuracy by the proposed numerical method for any moderate choice of p*.
Acknowledgments
Thanks to Mattias Franberg and Ryan Emerson for the helpful comments.
Footnotes
Author Disclosure Statement
No competing financial interests exist.