
Abstract
Abstract
Model parameter inference has become increasingly popular in recent years in the field of computational epidemiology, especially for models with a large number of parameters. Techniques such as Approximate Bayesian Computation (ABC) or maximum/partial likelihoods are commonly used to infer parameters in phenomenological models that best describe some set of data. These techniques rely on efficient exploration of the underlying parameter space, which is difficult in high dimensions, especially if there are correlations between the parameters in the model that may not be known a priori. The aim of this article is to demonstrate the use of the recently invented Adaptive Metropolis algorithm for exploring parameter space in a practical way through the use of a simple epidemiological model.
1. Introduction
M
The term on the left-hand-side is the posterior distribution, the calculation of which is the goal of the inference. On the right-hand-side, the numerator is the product of the likelihood and the prior and the denominator serves to ensure that the posterior PDF integrates to unity.
The process of fitting model parameters to observed data is not without difficulty, as there is no single technique for determining the model parameters that best describe observed data with several techniques recently invented to aid this inference. Additional complexity is involved if there exists some correlation between the parameters in the model as it affects the efficiency of how parameters are sampled. The aim of this article is to demonstrate the use of a novel algorithm (Haario et al., 1999, 2001), called the Adaptive Metropolis algorithm, that takes into account possible correlations without having to store the information on all the sampled parameters, thus increasing the efficiency that the parameter space is explored. We will demonstrate the method using a practical example of inferring the parameters in a simple disease model with several parameters. We will use an algorithmic approach to demonstrate the algorithm with Markov chain maximum a posteriori estimates to demonstrate how this method may be used to estimate the parameters in a disease model. We refer the reader to more theoretical treatments of the techniques in this article to other work (Haario et al., 2001; Gauvin and Lui, 1994; Andrieu and Atchad, 2007).
2. Adaptive Metropolis Algorithm
As a demonstration of the technique we will use the SEIR model without recruitment and with frequency dependent transmission (Equation 2) and recover parameters that create a known outbreak pattern. This model divides a population into four categories—susceptible, S, those who may be infected but currently are not; exposed, E, those that are infected but not able to infect others; infectious, I, those who are able to infect others and finally recovered; and R are those that have had the disease and have recovered. It is assumed, in this model, that individuals pass from S→E→I→R in a linear manner.
We will create the disease pattern by observing the numbers of S, E, I, and R in a population of 10000 individuals. In this rather contrived example we start with S=9999, I=1 with β=0.287, σ=0.67, and γ=0.16, and solve the equations using the fourth order Runge-Kutta method with a step-size of 0.1. At t=100 we record the numbers of susceptible and recovereds as 4583 and 4349, respectively, and record those infected and exposed together as 1068.
Despite its simplicity, this model demonstrates a problem confronting computational epidemiologists; having observed disease data and a phenomenological understanding of the transmission dynamics, what are the transmission parameters? Knowing these parameters allows us to design control measures to combat the spread of the disease.
Firstly, let us write the parameters of the model as
Maximum a posteriori (MAP) estimation is very similar to ML estimation but allows the inclusion of some a priori belief on the parameters by weighting them with a prior distribution p(
where the integral in the denominator is over the domain of g, the prior distribution of the parameters
Thus our problem is to find those parameters,
Suppose, in our example, we are able to test every individual in a population to determine their disease state for some transmissible disease and were able to categorize these correctly as being susceptible (for example, no antibodies were found in their blood), infected (in either contagious or subcontagious stage), and recovered. Since our test is not capable of determining those in the E class from I in our model, the correlation between σ and γ will need to be taken into account in any method of calculating
Calculating the probability in Equation (3) for most models is intractable and is often approximated using Monte Carlo methods, which performs the integration by sampling
In this example, we wish to maximize the likelihood
where NS are the numbers of susceptibles observed in the population for the parameters
The steps to perform the MCMC algorithm are:
1. Select a starting point in the parameter space, effectively choose a β, σ, γ from a known distribution. In Bayesian terms this distribution is known as the prior distribution and represents the knowledge we have about these parameters, for example, the range of values they can take and how they are distributed. In this case we will assume very little knowledge and assume a uniform distribution over quite a large range, [0.05, 1.0] for each parameter. The efficiency of this approach is improved if the range can be decreased or a known distribution is used. 2. Calculate the required statistic that is being optimized. In this case we calculate the likelihood from Equation (5). Calculating this statistic is usually the most computationally intensive part of the algorithm as it typically may involve Monte Carlo simulation to obtain the output values (in this case NS, NI, NR). 3. Take a trial step by selecting a new set of parameters 4. Compare the statistic for this trial step to the previous step and accept according to a rejection algorithm, if the trial is accepted the the parameters are updated The Metropolis-Hastings algorithm is commonly used to determine whether or not to accept the trial step. The basic algorithm is to compare the statistics of the trial step to the current one ( 5. This process of making trial step and accepting/rejecting them performs a random walk through parameter space that has the properties of a Markov chain. Several such chains are run, each with a different initial
MCMC will generate parameters while exploring parameter space in a manner that spends the most time in the important regions. In the parlance of inference methods, the samples (parameters) mimic samples drawn from the target distribution (i.e., those parameters we are trying to find).
The efficiency of the MCMC is determined by how well the random walk (Markov chain) explores the parameter space. A frequently used method for choosing a trial step is to sample from a symmetric distribution centerd on the current step (known as the symmetric random walk method, SRWM) as it is easy to implement and is often efficient enough for practical purposes, even for high-dimensional distributions. This is the method outlined in step 3 above using the normal distribution. Finding a good choice of proposal distribution is not an easy task however. For many problems a possible choice is the multivariate normal distribution with means,
In practice this covariance is calculated by storing all the values,
where the covariance between the parameters x and y is given by cxy=E [(x–E[x]) (y–E[y])] (E [x] denotes the expected value of x).
The random samples for our next step
where
Haario et al. (1999, 2001) proposed a novel method, referred to as the Adaptive Metropolis algorithm, to replace the costly calculation of the covariance matrix by updating the matrix on-the-fly using only the current k-th step in the chain and the previous
with the parameters being drawn from the multivariate distribution
To compare the SRWM, N-SRWM, and Adaptive Metropolis algorithm, we will infer the parameters in our SEIR model from a set of observed data. We create the observed data by running the SEIR model with β=0.287, σ=0.67, γ=0.16, and S0=9999, E0=0, i0=1, R0=0 for t=[0, 1] with a step size of 0.1 using the 4th order Runge-Kutta. This resulted in S=4583, R=4349, E+I=1068.
For each algorithm we start with 1. Let θ
i
be the coordinates of the current step (so θ1=β, θ2=σ, θ3=γ) and μ
k
be the mean values of the parameters after the k-th step ( 2. Update the covariance matrix where
It is possible to obtain a singular matrix using these formulae; to avoid this we can set Γ
i,j
=Γ
i,j
*ε for some small value ε. 3. Obtain the next step
For each method, we solve the SEIR model in t=[0, 1] with the same initial conditions and stepsize as the model that generated the observed data. (We admit this is rather an artificial construct but enough to demonstrate the method. The goal here is to show how the Adaptive Metropolis algorithm may be used in a Bayesian context). We generate the Markov chain by drawing 150000 samples from the prior distribution of the parameters [U(0.05,1.0) for each parameter].
We can see that the simulations using the Adaptive Metropolis method was the quickest to converge on the posterior distribution (Fig. 1), though once it reaches the target distribution its efficiency in sampling from this distribution decreases. In all the above chains 150,000 samples were drawn, but despite the Adaptive Metropolis algorithm reaching the target distribution quicker than the other two methods it failed to select efficiently from this distribution. The other two methods were, nonetheless, untuned, in that changing the variance used in the sampling strategy (in effect limiting the size of the step) would result in a more efficient exploration of the local environment. Decreasing the variance in these algorithms once the target distribution is identified (often referred to as adaptive or sequential MCMC) would increase the sampling rate from the posterior distribution.
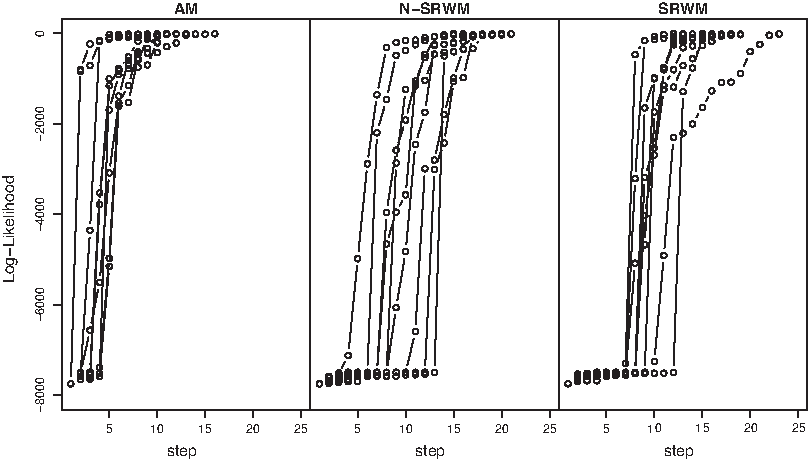
Log-likelihoods for the Markov chain using the Adaptive Metropolis method, N-SRWM, and SRWM algorithms. At each step of the chain the SEIR model was solved using the Runge-Kutta method and the log-likelihood calculated at each step. Each trial step was accepted according to the Metropolis-Hastings algorithm. Convergence is significantly faster for the Adoptive Metropolis algorithm than either of the others.
Due to the inefficiency of the sampling strategies we have only one or two points from each chain from which to obtain the posterior distribution (Fig. 2). In practice this is not enough points to generate a posterior distribution, especially when there are known correlations between the parameters in the underlying model, but we present it here for illustrative purposes. In all inference techniques used the observed values were recovered but the fitted (or inferred) parameter values were not. This is entirely due to the correlations between the parameters, as there is a wide range of {β, σ, γ} that will recreate the observed output. This should serve as a warning on the use of inappropriate priors, if we restricted the range of our priors, or specified a particular distribution for these priors we would have been more successful in obtaining the parameters.

Posterior distributions of the parameters for Adaptive Metropolis method, N-SRWM, and SRWM. For each algorithm the chains converged on an area of parameter space that was able to recreate the observed output. Each chain was started with a value of β=0.287, σ=0.67, and γ=0.16 and created from 150000 draws from the sample distribution. The posterior distributions were smoothed using the density() function in R, the statistical computing language.
3. Conclusions
Parameter inference, especially in models with a large number of parameters, is a difficult and time-consuming task. Efficient exploration of the parameter space is key to obtaining good posterior estimates. Identifying and using correlations between the parameter in the fitted models is key to achieving this efficiency, but calculating these correlations comes with an additional computational effort. The Adaptive Metropolis algorithm is an efficient method, in both memory and CPU, to account for these correlations. We have demonstrated that this algorithm is faster than naive SRWM and N-SRWM methods, though these methods may be considerably improved with a degree of tuning obtained by trial and error. The Adaptive Metropolis algorithm requires no tuning to reach the target distribution.
Footnotes
Author Disclosure Statement
No competing financial interests exist.