
Abstract
Abstract
The first step in the analysis of data produced by ultra-high-throughput next-generation sequencing technology is to map short sequence “reads” to a reference genome, if available. Sequencing errors, repeat regions, and polymorphisms may lead a read to align to multiple locations in the genome reasonably well. While ignoring such multimapping reads, or some of their alignments, will reduce the sensitivity of almost any type of downstream analysis (e.g., detecting structural variants), erroneous mappings will typically yield false positive predictions. Here we propose a framework that aims to identify true predictions among a large set of candidate predictions by selecting for each read a unique mapping that collectively imply conflict-free predictions. We formulate this problem as the maximum facility location problem, for which we propose LP-rounding heuristics. We provide a theoretic guarantee on the quality of the solution and demonstrate the utility of our algorithm in resolving conflicting deletions implied by simulated reads mapping ambiguously to Craig Venter's genome model and Illumina sequencing reads of the well-studied NA12878 individual.
1. Introduction
U
Simply ignoring ambiguously mapping reads in the reconstruction of, for example, genomic polymorphisms, alternative splicing, or DNA methylation, has a negative impact on the sensitivity of the prediction, especially in repeat regions of the genome. In Hach et al. (2010), for example, 100 bp reads mapped on average to 140 locations with at most six mismatches in the human reference genome. Not surprisingly, neglecting all but one arbitrary mapping in the downstream analysis will yield both false positive and false negative predictions.
A common approach to unify the (ambiguous) mappings of different reads is to derive an overall set of candidate predictions from all maximal groups of read mappings that support the same phenomenon. To improve sensitivity within repetitive regions of the genome, current methods for structural variant detection form clusters (or cliques) based on all good read alignments (Medvedev et al., 2009), not just one best alignment. Since segmental duplications define hotspots for large-scale variations (Cooper et al., 2007; Kim et al., 2008), these regions are of particular interest (Medvedev et al., 2009). The main challenge this soft clustering strategy has to cope with is that of maintaining a high precision. The candidate set it generates naturally contains a significant number of false positive predictions, since ambiguous mappings of a single read may participate in several predictions although at most one of them denotes the true origin.
In this work, we propose a model and algorithms to separate true predictions from candidate predictions that result from mapping artefacts. To be applicable to a wide range of interpretation problems of NGS read mappings, we solely employ the conflict of different predictions to resolve ambiguous mappings. We refrain from imposing additional assumptions like parsimony. We formulate the unique assignment of multimapping reads to conflict-free predictions as a global optimization problem that takes into account the entirety of all (ambiguous) read mappings. The algorithm we propose resolves conflicts among predictions efficiently based on the assumption that predictions can be represented by genomic intervals with respect to the reference, and that two predictions are in conflict if and only if the corresponding intervals overlap. For example, introns inferred from spliced alignments of RNA-seq reads, deletions in a donor genome with respect to a reference genome (see overlapping green and red deletion in Fig. 1), and other types of genetic variations like inversions naturally correspond to nonoverlapping genomic intervals. This does not only apply to haploid genomes, but also in diploid genomes, for example, overlapping (but different) deletions or introns represent rare events.
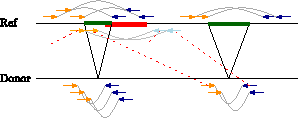
Alignments supporting conflicting deletions. An orange and a blue read connected by a gray line represent a paired-end read. The two reads map to the reference genome at a distance larger than the distance between the sequenced ends (reads) of the donor fragments, indicating a potential deletion. Alternative (wrong) alignments (red dotted lines) support a (wrong) deletion (red) that overlaps the green deletion to the left and thus the two deletions cannot occur simultaneously on the same allele.
1.1. Preliminaries
We formulate the problem of resolving conflicting predictions from multimapping reads as the maximum facility location problem, which we formally introduce in the next section. A set of clients has to be assigned (uniquely) to a set of nonconflicting facilities such that the total weight of the assignment is maximized. In this proof of concept, we illustrate the utility of our conflict resolution model in the prediction of deletions from paired-end reads (Fig. 1). Besides other types of mutations, larger deletions have been shown to be associated with diseases such as cancer (Pleasance et al., 2009). A popular approach to discover large-scale genetic variations including deletions is from paired-end reads sequenced from both ends of a donor's DNA fragments. A mapping of the two reads to the reference genome at a distance that is larger than what is to be expected from an empirically estimated fragment length distribution indicates a potential deletion in the donor genome. The confidence in a particular mapping of a read is expressed by an alignment score that captures, for example, mismatches, the probability of sequencing errors at each nucleotide base calls, and the likelihood of the implied fragment length.
In this particular instantiation of our framework, facilities correspond to candidate deletions and clients correspond to reads. A client (read) can be assigned to the facilities (deletions) that are supported by one of its mappings. The assignment of a client to a facility contributes the corresponding read alignment score to the overall weight. Starting from an initial set of candidate deletions provided by a state-of-the-art computational method for the discovery of structural variants, the optimal solution in our model seeks a set of nonoverlapping deletions (i.e., nonconflicting facilities) that reduce the number of false positive predictions while retaining most of the true positive deletions.
1.2. Related work
Conflicts between structural variants (SV) were first studied in Hormozdiari et al. (2009). While overlapping SVs were heuristically filtered in a post-processing step in Hormozdiari et al. (2009), the conflict resolution was integrated with their maximum parsimony model in a follow-up work (Hormozdiari et al., 2010). The authors show that the resulting combinatorial optimization problem is NP-hard and inapproximable and propose a heuristic greedy algorithm. A similar approach was used later in the joint analysis of multiple samples (Hormozdiari et al., 2011). Lee et al. (2008) and Wittler and Chauve (2011) study two components of the problem considered in this work individually. Lee et al. (2008) tries to resolve multiple mappings of a read probabilistically, ignoring potential conflicts among predicted SVs. At the other end, Wittler and Chauve (2011) refines the definition of conflicts between tumor-specific deletions and proposes a heuristic approach for their resolution, ignoring multimapping reads completely. The authors identify in Wittler and Chauve (2011) erroneous mappings from, for example, repeated genomic regions, as a potential source of false positive predictions and recognize the need for efficient algorithms that resolve the combinatorics of mappings and conflicting predictions.
As we will see, the maximum facility location problem is a special case of the problem of maximizing a monotone submodular function subject to an interval graph independence constraint. For this problem, Feldman (2013) gave a 0.25-approximation based on rounding a fractional solution of the so-called multilinear relaxation. Unfortunately, the current best algorithms for finding good solutions to the multilinear relaxation are impractical due to their high-degree-polynomial running time, even more so when the analysis involves hundreds of millions of reads (clients).
1.3. Our results
Our main technical contribution are two LP-rounding heuristics for the maximum facility location problem, and a theoretical analysis for the first that is a 0.19-approximation.
We confirm the practicability of our algorithms in experiments on both simulated reads from Craig Venter's genome and publicly available Illumina sequencing data from the well-studied NA12878 individual. Recall and precision achieved by our heuristics when resolving conflicting deletions demonstrate the biological significance of our framework.
The goal of this work is to show the feasibility of maintaining a high precision of “soft clustering” approaches that use ambiguous read mappings to call structural variants or other genomic interval features. We do not necessarily intend to provide a comprehensive method for the detection of structural variants.
2. Maximum Facility Location
In this section we formally define our abstract optimization problem, which we call the maximum facility location problem, and later give a linear relaxation that will be the basis of our algorithms.
Let C be a set of clients and F be a set of facilities. Let
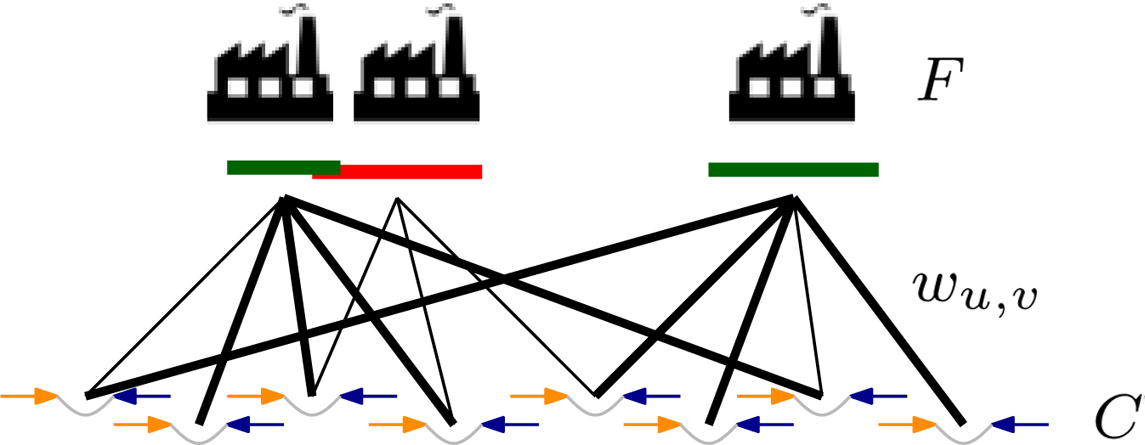
Clients C and facilities F represent paired-end reads and candidate deletions, respectively. Each facility is associated with an interval whose endpoints correspond to the breakpoints of the candidate deletion. Edges between clients and facilities indicate alignments supporting the corresponding deletion. Our confidence in the alignment is captured by a score w. A feasible solution (bold edges) to the maximum facility location problem assigns reads to an independent set of facilities.
Finally, for any nonempty subset S ⊆ F we define the value of S as
For completeness, we define
An instance of the maximum facility location problem is specified by a tuple (C, F, w, I). The objective is to choose an independent subset S ⊆ F maximizing f (S). We now prove an important property about this objective function.
Lemma 1
The function f defined in (1) is monotone nondecreasing and submodular.
To prove the submodularity of f, consider a facility v ∈F\B. We add v to both A and B and analyze gain in value due to some arbitrary client u ∈C:
Summing over all u ∈C we get f (A + v) − f (A) ≥ f (B + v) − f (B). Therefore, f is submodular. ■
2.1. Linear programming relaxation
Our linear programming relaxation (LP) uses two type of variables. For each facility v ∈F, we have a facility variable yv that indicates whether facility v is open. For each client u ∈C and facility v ∈F, we have a client-facility variable xuv that captures whether u is assigned to v.
The linear program has three types of constraints. For each client u∈C we have a constraint enforcing that u is assigned to at most one facility. For each client u∈C and facility v∈F we have a constraint enforcing that if u is assigned to v then v is open. Finally, for each interval endpoint p∈P we have a constraint enforcing that we choose at most one of the facilities whose intervals span p.
3. Algorithms
In this section we describe two algorithms for maximum facility location. Both algorithms solve the linear relaxation (LP) to get an optimal fractional solution and round it to a feasible integral solution using different approaches. The first algorithm uses independent rounding with alteration, while the second algorithm uses dependent rounding.
3.1. Independent rounding with alteration
Our first algorithm is very simple. First, we compute an optimal fractional solution (x, y) of the linear relaxation (LP). Then we create a set R ⊆ F by placing each facility v ∈F into R with probability αyv, where α ∈[0, 1] is a parameter that will be chosen later to maximize the approximation ratio in our analysis. Finally, we apply a filtering step that drops some facilities so as to obtain an independent set T ⊆ R.
It should be noted that the alteration step (where we go from R to T) is the same as the conflict resolution scheme of Feldman (2013) that was developed for the more general problem of maximizing a submodular function subject to the constraint that the set chosen is independent in an auxiliary interval graph. As mentioned in the introduction, while this algorithm is a 0.25-approximation, it is not practical as it requires that we solve the stronger multilinear relaxation rather than the much easier linear relaxation (LP).
Independent rounding with alterations.
The main result of this subsection is that this simple algorithm leads to a constant factor approximation.
Theorem 1
There is an LP-rounding 0.19-approximation for maximum facility location.
The proof of this theorem relies on a few auxiliary lemmas. First, we argue that solution T output is feasible. Then we argue that the expected value of the set R is at least a constant factor of the value of the fractional solution (x, y). Finally, we show that the expected value of T is at least a constant factor of the expected value of R.
Lemma 2
The set T returned by
Lemma 3
Let R be the set sampled by
Due to the technicality of the proof to Lemma 3, details are provided in Appendix A.
Lemma 4
Let R and T be the sets computed in
where the first inequality follows from union bound, and the second from the feasibility of (x, y). Therefore,
Vondrák et al. (2011, Theorem 1.3) showed
4
that Equation (2) implies that
when f is monotone submodular. From Lemma 1 we know that f is indeed monotone submodular. ■
where the first inequality follows from Lemma 4 and the second inequality from Lemma 3.
The best approximation ratio is attained at α = 0.44, where we get 0.199. ■
Algorithm engineering. We briefly discuss two ideas for improving the observed performance of
First, notice that our choice of α in the proof of Theorem 1 may not be the best for a particular instance. Instead of picking a single value of α we pick the “best” α as follows. For each v ∈F, we generate a random number rv ∈[0, 1). In
Second, recall that the algorithm resolves conflicts of R by keeping only those facilities whose start point is not contained in another interval in R. Consider a maximal subset A ⊆ R such that the union of their intervals forms a single interval. For each such A, the filtering step of
3.2. Dependent rounding
Our second algorithm uses a more refined rounding routine. Instead of sampling and removing intervals that have conflicts, we gradually shift the fractional solution to an integral using dependent rounding (Gandhi et al., 2006) routine.
Before we can describe the algorithm we need a few definitions. Given a solution (x, y) to (LP), let S = {v ∈F : 0 < yv < 1} be the set of facilities with a nonintegral value. For a point p∈P, let slack(p) denote the slack of its corresponding constraint in (LP):
We say p is tight if its constraint is tight; namely, if slack(p) = 0.

Our algorithm starts by finding an optimal fractional solution (x, y) to the linear relaxation (LP). Then we iteratively modify this solution as follows. First, we select two disjoint independent subsets M1, M2 ⊂ S. Then, we randomly update the y-values of facilities in M1 ∪ M2 so that at least one more facility is integral or at least one more point is tight. This is repeated until there are no more fractionally opened facilities.
Let us describe in more detail how the update is carried out. For i = 1, 2, let Pi ⊆ P be those points that intersect an interval in Mi. We compute the following two quantities
Finally, with probability
Otherwise, with complementary probability
The pseudocode of the main routine is given in Algorithm 2, while the pseudocode for picking M1 and M2 appears in Algorithm 3.
The following Theorem is the main result of this section.
Theorem 2
Let T be the set returned by
Creating subsets M1 and M2.
We break the analysis into a series of lemmas. First, we prove some properties of the output of
Lemma 5
Let M1 and M2 be the sets computed by
Now that we have shown the invariant holds after initialization, we aim to prove that M1 and M2 are independent. To do this, we need to show that the loop invariant also holds at the end of each iteration. Consider the next tight point t and facility v starting at t. Suppose t stabs
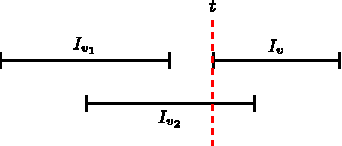
The case when only one of the intervals stabs the next tight point.
Now consider a tight point p ∈P. If p was never considered by the for loop, then p∉
Lemma 6
Consider an iteration of
A similar argument applies for facilities v ∈M2.
Notice that
Finally, let us now argue that y obeys the independence constraints of (LP). Let p ∈P be an arbitrary point. If p ∈P1∩P2 then its constraint is obeyed since the increase/decrease of a facility in M1 that it stabs is compensated with a corresponding decrease/increase of a facility in M2 that it stabs. If p ∈P1\P2 then by the definition of ɛ the independence constraint at p is obeyed. Similarly, if p ∈P2\P1 then by the definition of δ the independence constraint at p is obeyed. Finally, p ∉P1 ∪ P2 then the slack of p does not change so the independence constraint at p is obeyed as well. ■
Lemma 7
In each iteration of
Suppose that the algorithm replaces y with y′. Furthermore, assume that ɛ = yv for some v ∈M2. It follows that
By Lemma 6, in each iteration we maintain feasibility. It follows that the set
In terms of the differences between these two algorithms discussed, they both exhibit a trade-off in solution quality versus time. The first algorithm (independent rounding) presented has a theoretical bound, however will often be slower than the second; as for large instances we need to evaluate the objective function in Equation (1) many times. On the other hand, the runtime of the second algorithm (dependent rounding) is dependent on the number of tight points in the instance. Therefore for instances with a small number of tight points, the dependent algorithm will most likely have a faster running time.
We close this section by noting that while the output set T is independent and Pr[v ∈T] = yv, we cannot prove the guarantee of Lemma 3 for E[f (T)] since the rounding decisions are not independent of one another.
4. Hardness
In this section we discuss the inapproximability of maximum facility location. In particular, we show that there is no polynomial time α-approximation for α > (1 − 1/e) unless P = NP.
Theorem 3
For any ɛ > 0, there is no (1 − 1/e+ɛ)-approximation algorithm for maximum facility location, unless P = NP.
It has been shown that there is no polynomial time algorithm for this problem with an α-approximation for
To begin the reduction to maximum facility location, we create a client cu for each element
If an element
all with weight 1 (Fig. 4). This means that once we choose to open the facility φS,i, we are essentially covering all of the elements u′ ∈ S, by assigning all of the clients
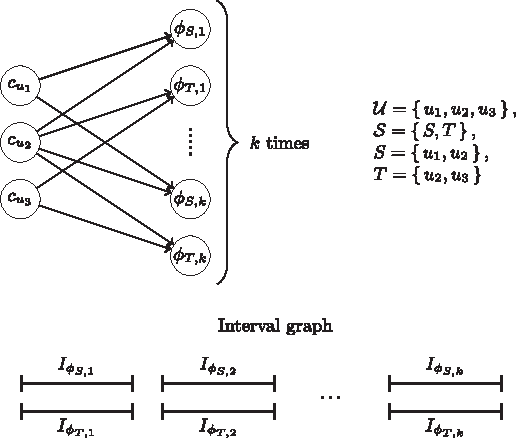
An example of a reduction from the maximum coverage problem to the maximum facility location problem. In this instance, there are three elements (u1, u2, and u3) and two subsets (S and T). Given an integer k, we create k intervals for each subset and create k cliques. In each clique, every pair of intervals overlaps. This means we can select at most k subsets.
We now argue that the value of the maximum facility location instance equals the value of the maximum coverage instance. Let Φ be the set of facilities opened and
In order to argue that the values are the same, we observe that by opening a facility φS,i, we allow all of the clients connected to φS,i to be assigned. Since all of the edge weights are 1, this corresponds to how many elements we cover if we select the subset S. The second observation is that the instance cannot benefit by opening the facility φS,i and φS, j for j≠i, as a client can only be assigned to a single open facility. This directly corresponds to covering no new elements.
Then from the discussion above and the inapproximability result (Feige, 1998; Khuller et al., 1999) for maximum coverage, we arrive at the theorem. ■
5. Experiments
While we believe that our general scheme can be useful in the analysis of various biological questions by *Seq assays, in this proof of concept we focus on the detection of deletions in a donor genome with respect to a reference genome. We implemented the engineered independent rounding with alteration (Independent) and the dependent rounding algorithm (Dependent). Our implementation was done in Java 1.8, using Gurobi gur (2015) to solve the linear program. We also solve the integer program (IP) for benchmarking purposes.
To mimic the conflict resolution approach of VariationHunter (Hormozdiari et al., 2010) (see the section Related Work), we further implemented two simple greedy algorithms. The first method chooses a facility at each iteration that leads to the highest increase in value [according to the objective in Eq. (1)] that does not conflict with the current set (wGreedy). The second method picks the facility that covers the largest number of new clients (Greedy). Experiments were run on a quad-core Intel Core i7 processor running at 2.7 GHz with 16 GB of RAM. In the following, we evaluate the performance of our method on both simulated data and a real Illumina sequencing data set.
5.1. Simulated reads: Craig Venter
We use the benchmark data set designed in Marschall et al. (2012) for the evaluation of algorithms that reconstruct structural variants (SV) from NGS reads. In short, Craig Venter's genome is modeled by inserting annotated structural variants (Levy et al., 2007) into the reference genome. From the resulting two different alleles, 100 bp paired-end reads from fragments of mean length μ = 312 (σ = 15) were simulated using UCSC's SimSeq. All reads (30×) were aligned to reference genome hg 18 using BWA (Li and Durbin, 2009), allowing up to 25 alignments per read. The read alignments were provided in Marschall et al. (2012) as input to the proposed method CLEVER and all competing state-of-the-art SV discovery methods. The performance of the different tools in predicting insertions and deletions was measured in terms of recall = TP/(TP+FN) and precision = TP/(TP+FP), where a predicted deletion counts as true positive (TP) if it overlaps a true deletion and differs in length by no more than 100 bp (∼ mean distance between reads of same fragment). In this metric, CLEVER performed particularly well in the prediction of deletions of size 20–99 bp, compared to previous insert size-based approaches. The authors observed, however, a large fraction of false positive calls (30% in the 20–49 bp range) caused by misalignments and mapping ambiguities.
Here, we demonstrate the ability of our method to guide the selection of a core subset of deletions among many candidate predictions by resolving conflicts resulting from ambiguous mappings. More specifically, we compile CLEVER's output of statistically significant deletions into an instance of the maximum facility location problem. From the opened facilities we derive our final prediction of deletions in Venter's genome. Since we do not intend to provide a comprehensive method for the detection of structural variants, we refrain from comparing the overall performance to alternative SV discovery methods. On the contrary, our scheme can be applied to the set of candidate predictions computed by any soft clustering-based SV caller.
Table 1 shows recall and precision achieved by the different algorithms. In the defintion of TP we avoid a single deletion to be explained by several (different) predictions and a single prediction to explain multiple true deletions by computing a maximum cardinality matching between predicted deletions and true deletions. Each method was provided with all significant deletions called by CLEVER (Marschall et al., 2012) (CLEVER-cand). Analogously to the evaluation in Marschall et al. (2012), we consider deletions of size 20–49 (8,502 true del.), 50–99 (1,822 true del.), and 100–50,000 bases (2,996 true del.). Deletions of size less than 20 bases are difficult to discover by an insert-size-based scheme as implemented by CLEVER. CLEVER also offers a script to filter variants that are located too close to each other. We include the evaluation of this filtered set of predictions (CLEVER-filter).
Recall and precision achieved by the different algorithms when provided with the candidate predictions of CLEVER (Marschall et al., 2012) (CLEVER-cand) on the simulated Craig Venter data set. We report recall for deletions of different length in a-b bases (Rec. a-b) as well as overall recall and overall precision. The last column gives the total running time in minutes.
All methods are able to reduce the number of false postive calls made by CLEVER significantly, at only a small cost in recall. The very similar accuracy of the predictions obtained by the maximum facility location algorithms and the greedy algorithms is remarkable, since they are based on different mathematical models. While the latter seeks a minimal set of deletions (facilities) to explain all reads, the algorithms developed in this work rely exclusively on alignment scores and conflicts between deletions and do not impose any further assumptions. In contrast, the post-processing step optionally applied by CLEVER suffers from a significant loss in recall, in particular in the relevant range of 20–99 base-long deletions. Although this filtering scheme targets (a relaxed definition of) conflicts, it neglects ambiguous mappings of reads.
In terms of runtime performance, the most notable trend is that the greedy heuristics were two orders of magnitude slower than the LP-rounding heuristics, taking days rather than minutes to find a solution. This is because the greedy algorithms need to evaluate the objective function (1) many times, which can be expensive for large instances. Compare this to our solutions, which solve an LP and evaluate the objective function a few times. Surprisingly, the IP solver showed a performance comparable to our heuristics. This is probably due to the fact that the IP approach involves a single call to the highly optimized Gurobi software library written in C, while our implementation uses Java. Nevertheless, we expect our rounding algorithms to scale better on larger instances.
5.2. Illumina reads: NA12878
Real data pose unique challenges like PCR artefacts or chimeric reads to a computational analysis. We thus evaluate the performance of our method on publicly available Illumina sequencing data of the well-studied NA12878 individual (European Nucleotide Archive, ERA172924). In total, 101 bp reads were sequenced (50×) from the ends of fragments whose mean length μ was empirically estimated by CLEVER to be 320.89 bp (σ = 66.56).
We followed the same protocol as with the simulated benchmark. We cast statistically significant deletions predicted by CLEVER as our input facilities F. From facilities opened by our algorithm(s) we derive our final prediction of deletions in NA12878's genome. We measured recall and precision of deletion calling on chromosomes 1 through X with respect to two truth sets made available by Layer et al. (2014). The first truth set (1000G) contains 3,376 nonoverlapping deletions validated in NA12878 by the Mills et al. study (2011). The second truth set (long-read) comprises 4,095 predicted deletions that were validated by PacBio or Illumina Moleculo long-read sequencing data [for details see Layer et al. (2014)].
Since for this real data set not the complete set of true deletions is known, we applied the following precision correction to the output of all benchmarked methods. Predicted deletions
The number of (validated) true deletions for NA128787 in the relevant ranges of 20–49 and 50–99 are with 47 and 156 for 1000G and with 101 and 522 for long-read relatively small and thus the precise recall values have to be considered with care. The overall trend, however, seems to agree with the results on the simulated data set (Table 2).
Recall and precision with respect to truth sets 1000G and long-read achieved by the different algorithms when provided with the candidate predictions of CLEVER (Marschall et al., 2012) (CLEVER-cand) on the Illumina data set for NA12878. We report recall for deletions of different length in a-b bases (Rec. a-b) as well as overall recall and overall precision. The number of true deletions in the three different size ranges are shown in brackets for the two truth sets. The last column gives the total running time in minutes.
Again, with a rather modest loss in recall we are able to increase the precision with respect to truth sets 1000G and long-read from 8.8% to around 69%, and from 9.9% to around 79%, respectively. Similar to the results on the simulated data set, the approximate or optimal solutions our algorithms find for the maximum facility location formulation are similar in terms of recall and precision to the ones returned by the greedy heuristics. In contrast to the greedy approach, however, our algorithms compute these solutions in the order of minutes rather than days. Compared to the heuristic filtering strategy optionally applied by CLEVER we increase the precision with respect to truth sets 1000G and long-read by ∼30% and ∼11%, respectively.
6. Conclusion and Discussion
We presented a universal framework for resolving conflicting predictions from ambiguous read mappings and demonstrated, as proof of concept, its utility in reporting a final set of deletions given a large set of candidate deletions. Since our model formulates conflicts as overlaps of intervals but does not impose any further assumptions like parsimony, we expect it to be useful in a wide range of reference-based NGS data analysis.
For instance, the algorithm proposed in Eslami Rasekh et al. (2015) clusters clones (fosmids or bacterial artificial chromosomes, BACs) split by a (putative) inversion breakpoint to discover large inversions. The authors observed that a parsimony objective similar to the one applied in VariationHunter (and evaluated in our experiments) fails to properly resolve ambiguities among breakpoints located in highly repetitive regions. Furthermore, our model might be useful in identifying tumor-specific deletions from matched tumor/normal samples based on their conflict and ambiguous mappings (Wittler and Chauve, 2011) as well as in resolving intersecting quasi-cliques enumerated to cluster metagenomic sequences (Yang et al., 2013). In contrast to a more restrictive definition of candidates as single cliques in each connected component (Ratan et al., 2015), the ability to resolve conflicts allows a more sensitive prediction of candidates.
The key assumption of our model that determines the range of potential applications is that conflicts can be formulated as the overlap of genomic intervals. It captures many features of haploid and diploid organisms, except for rare overlapping events on different alleles, which require a specialized treatment (Wittler, 2013). Conflicts in a mixture of cancerous and healthy cells, however, are inadequately covered by simple interval overlaps (Wittler, 2013) and will require a generalization of our model. Also, features like the DNA methylation status naturally relate to individual bases rather than genomic intervals.
7. Appendix: A Missing Proofs
We aim to show that E[w(u)], the contribution of u to E[f (R)], is at least a constant times
Let
where the last inequality follows from the arithmetic-mean geometric-mean inequality and the feasibility of (x, y).
Let
We now express E[w(u)] in terms of Pr[w(u) ≥ wuvi]
Now we can use our bound on Pr[w(u) ≥ wuvi] to lowerbound the expected value of w(u)
Finally, by linearity of expectation, we have
which is precisely what we needed to prove. ■
Footnotes
Acknowledgments
We thank Tobias Marshall for valuable support in the interpretation of CLEVER's output.
Author Disclosure Statement
The authors declare that no competing financial interests exist.