
Abstract
Abstract
One of the last steps in a genome assembly project is filling the gaps between consecutive contigs in the scaffolds. This problem can be naturally stated as finding an s-t path in a directed graph whose sum of arc costs belongs to a given range (the estimate on the gap length). Here s and t are any two contigs flanking a gap. This problem is known to be NP-hard in general. Here we derive a simpler dynamic programming solution than already known, pseudo-polynomial in the maximum value of the input range. We implemented various practical optimizations to it, and compared our exact gap-filling solution experimentally to popular gap-filling tools. Summing over all the bacterial assemblies considered in our experiments, we can in total fill 76% more gaps than the best previous tool, and the gaps filled by our method span 136% more sequence. Furthermore, the error level of the newly introduced sequence is comparable to that of the previous tools. The experiments also show that our exact approach does not easily scale to larger genomes, where the problem is in general difficult for all tools.
1. Introduction and Related Work
A
High-throughput sequencing technology cannot read the genome of an organism from the start to the end, but rather produces massive amounts of short reads. Genome assembly is the problem of reconstructing the genome from these short reads. In a typical genome assembly pipeline, the reads are first joined into longer contiguous sequences, called contigs. Using paired-end and mate pair reads, contigs are then organized into scaffolds, which are linear orderings of the contigs with the distance between consecutive contigs known approximately. In this work, we study the last stage in this pipeline, gap filling, where the gaps between consecutive contigs in scaffolds are filled by reusing the reads.
Many genome assemblers, like Allpaths-LG (Gnerre et al., 2011), ABySS (Simpson et al., 2009) and EULER (Pevzner and Tang, 2001), include a gap-filling module. There are also standalone gap-filling tools available, for example, SOAPdenovo's GapCloser (Luo et al., 2012) and GapFiller (Boetzer and Pirovano, 2012). All these tools attempt to identify a set of reads that could be used to fill the gap, and then perform local assembly on these reads. The local assembly methods vary from using overlaps between the reads in Allpaths-LG to using k-mer-based methods in GapFiller, or building a de Bruijn graph of the reads in SOAPdenovo's GapCloser. Some of these methods attempt to greedily find a filling sequence whose length approximately equals the gap length estimate, whereas others discard the length information. In order to identify the set of reads potentially filling the gap, these tools use the paired-end and mate pair reads having one end mapping to the flanking contigs. However, if the gap is long, paired-end reads might not span to the middle of the gap, while the coverage of mate pair reads may not be enough to close the gap. In a more theoretical study (Wetzel et al., 2011), the gap between two mates is considered as reconstructible if the shortest path in the assembly graph between the two flanking contigs is unique.
In this work, we formulate the gap-filling problem as the problem of finding a path of given length between two vertices of a graph [also called the exact path length (EPL) problem (Nykänen and Ukkonen, 2002)]. With respect to previous solutions, such a formulation allows us, on the one hand, to use all reads that are potentially useful in filling the gap, even if their pair does not map to one of the two flanking contigs. On the other hand, by solving this problem exactly, we do not lose paths that may have been ignored by a greedy visit of the graph.
The EPL problem is NP-hard in general, and we show that this is also the case with our variation for the gap-filling problem. Moreover, the EPL problem is known to be solvable in pseudo-polynomial time. We also show that the assembly graph instances are particularly easy by implementing a new and simpler dynamic programing (DP) algorithm and engineering an efficient visit of the entire assembly graph. This is based on restricting the visit only to those vertices reachable from the source vertex by a path of cost at most the upper-bound on the gap length. Moreover, our DP algorithm also counts the number of solution paths, information which might address some issues raised by Wetzel et al. (2011). We implemented the method in a tool called Gap2Seq and compared it experimentally to other standalone gap fillers on bacterial and human chromosome 14 data sets from GAGE (Salzberg et al., 2012) (thus, implicitly, also to the gap filling modules built into the assemblers). In total on the bacterial assemblies, we can fill 76% more gaps than the best of the previous tools, and the gaps filled by our method span 136% more sequence. Moreover, the error level of the newly introduced sequence is comparable to the previous tools. Our experiments on the GAGE assemblies of human chrromosome 14 show that our exact approach does not seem to scale easily to larger genomes. Even though more greedy approaches perform better on some assemblies, all tools have overall mixed results, underlining the difficulty of the problem on these instances. Gap2Seq is freely available online (Salmela et al., 2015).
2. Gap Filling as Exact Path Length Problem
2.1. Problem formulation
Let
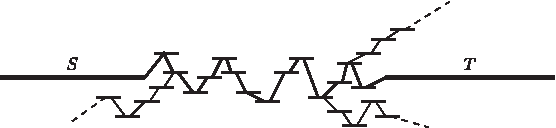
Gap filling.
To state this problem more precisely, consider the formalism of the overlap graph G of
A path v1,v2,…,vk in G spells a string of length
Given a path P = v1,v2,…,vk, with source s = v1 denoting start contig S and sink t = vk denoting end contig T, we say that the cost of P is cost(P)
We formulate the gap-filling problem below by requiring that the cost of a solution path belongs to a given interval [d′, d]. In practice, d′ and d should be chosen such that the midpoint (d′ + d)/2 reflects the same distance as the length of the gap between S and T, estimated from the scaffolding step.
and return one such path if the answer is positive.
We denote by #G
2.2. Complexity and the pseudo-polynomial algorithm
The problem of finding a path P in a directed graph with integer arc costs, such that the cost of P equals an integer d given in input was studied by Nykänen and Ukkonen (2002). In fact, Nykänen and Ukkonen (2002) considered the more general version in which the arc costs can also be negative. They showed this problem to be NP-hard, even when restricted to DAGs, and only with nonnegative costs. Their reduction is from the S
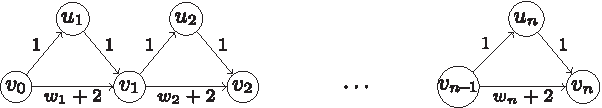
Reduction of a
Nykänen and Ukkonen (2002) also gave a pseudo–polynomial time algorithm running in time O(W2n3 + |d| min(|d|,W)n2), where n is the number of vertices of the graph and W is the maximum absolute value of the arc costs. (This algorithm is called pseudo-polynomial because if the input integers W and d are assumed to be bounded by a polynomial in the input size, then it runs in polynomial time.)
However, the G
Let N– (v) denote the set of in-neighbors of v in V (G), that is,
We initialize a(s, 0) = 1, a(v, 0) = 0 for all v ∈V (G)\{s}, and a(v, ℓ) = 0 for all v ∈V (G) and ℓ < 0. The values a(·,·) can be computed by dynamic programming using the recurrence
The values a(·,·) can be computed by filling a table A[1, |V |][0, d] column-by-column. Let m denote the number of arcs of the graph. This DP computation can be done with O(dm) arithmetic operations, since for each ℓ ∈[0, d], each arc is inspected only once. The gap-filling problem admits a solution if there exists some ℓ ∈[d′, d] such that a(t, ℓ) ≥ 1. One solution path can be traced back by repeatedly selecting the in-neighbor of the current vertex that contributed to the sum in Equation (1).
Observe that, since there are O(md) s-t paths of length d, then the numbers a(·,·) need at most d log m bits, and each arithmetic operation on such numbers takes time O(d log m). Therefore, we have the following result.
For the G
3. Engineered Implementation
In this section we describe an efficient implementation of the above gap-filling algorithm. In particular, we show how to reduce the above complexity O(dm), where m is the number of arcs of the entire assembly graph, down to O(dm′), with a meet in the middle strategy such that m′ can be much smaller than m. Namely, m′ is now the number of arcs of the assembly graph on the union of all paths starting at s and of cost at most d/2 and of all paths starting at t and of cost at most d/2 on the graph with reversed arcs. A similar meet in the middle approach has been proposed by Jackman et al. (2015).
We first describe a simplified variant of our actual implementation, which achieves the same complexity but is easier to describe in detail. Then we sketch how our implementation differs from this.
We use a de Bruijn graph (DBG) as the assembly graph. The DBG of a set of reads is a graph where each k-mer occuring in the reads is a vertex and there is an arc between two vertices if the k-mers overlap by k – 1 bases. Conceptually, a DBG can be thought of as a special case of an overlap graph where the reads are of length k and an arc is added only for overlaps of length k – 1. We implemented DBGs using the Genome Assembly and Analysis Tool Box (GATB) (Drezen et al., 2014), which includes a low memory implementation. By default, we set k = 31, which works well for bacterial genomes, but for larger genomes a larger k should be chosen.
We build the DBG of the whole read set. To leave out erroneous k-mers, only k-mers that occur at least r times in the reads are included (by default r = 2). The computation for each gap will then be performed on the appropriate subgraph of this DBG.
The gap-filling subroutine takes as input the bounds on the length of the gap, d′ and d, and the left and right k-mers flanking the gap, which will be the source and target vertices in our computation. We start a breadth-first search from the target vertex backward toward the source vertex to discover vertices that can reach the target within the allowed maximum gap length divided by two. We mark all vertices reached in this initial backward traversal. Then we continue with another breadth-first search from the source vertex forward toward the target vertex to discover vertices that are reachable from the source within the allowed maximum gap length divided by two. After reaching this limit, we continue the forward traversal only on the marked vertices; we then know that unmarked vertices do not belong to an s-t path of length at most d.
We note that this latter search traverses the vertices in an order that corresponds to the column-by-column filling of the DP table A defined in the previous section. Therefore the computations can be interleaved, resulting in an outer loop on the distance from the source vertex, and an inner loop on vertices at a specific distance from the source.
We use a hash table to link the reachable vertices to their DP table rows. The rows of the DP table may be sparse, since not all path lengths are necessarily feasible. For example, in the S. aureus test data with scaffolds constructed by SGA (Simpson and Durbin, 2012), 92% of the entries in the entire table were zero. We exploit this sparsity simply by listing all nonzero entries in every row. Because of the breadth-first search, the entries are added so that the lists will be sorted by the distance from the source vertex. Since we use a DBG, we always use the current distance minus one when accessing the table A, so we are only accessing the two last elements in the list. Therefore, this access can be implemented in constant time resulting in the O(dm′) complexity of the algorithm as claimed above. However, for tracing back the solution, one needs to binary search the corresponding elements. Hashing could be used for avoiding the binary search, but since tracing back is a negligible part of the total running time, this optimization was not implemented.
It is possible that there are several paths between the source and the target vertices. We then need to choose one of them to recover the sequence that will close the gap. We first choose paths whose length is closest to the estimated gap length. If there are still multiple possible paths, our current implementation chooses a random feasible in-neighbor when tracing back in the DP table.
Sometimes the k-mers immediately flanking gaps are erroneous (Boetzer and Pirovano, 2012). To be more robust, we allow paths to start or end at up to e of the k-mers that flank the gap (by default e = 10). This can be easily implemented by counting the length of a path always from the left-most possible starting k-mer. In the first e rounds of the breadth first search we add the appropriate starting k-mer to the reachable set with the number of paths equal to 1 at that distance. The searched path lengths can now be 2e bases longer, and we need to search for the ending right k-mer among the first e k-mers after the gap.
Observe that instead of just marking the reached vertices on the backward traversal, one can readily fill a DP table corresponding to the reverse paths. Then the forward traversal and DP computation can be stopped at level d/2, and the results of these two DP tables can be combined. This is the variant we actually implemented. Note that this approach is analogous to the standard dynamic programming technique known as forward and backward algorithms in HMM parameter estimation (Durbin et al., 1998).
Our implementation allows parallel gap filling on the scaffold level. We also utilize a limit on the memory usage of the DP table. If this limit is exceeded before a path is found, we abandon the search.
4. Experimental Setup
We evaluated our tool Gap2Seq against GapFiller (Boetzer and Pirovano, 2012) and SOAPdenovo's (Luo et al. (2012)) stand-alone tool GapCloser. For the experimental evaluation we used the GAGE (Salzberg et al., 2012) data sets Staphylococcus aureus, Rhodobacter sphaeroides, and human chromosome 14 (hereafter named staph, rhodo, and human14, respectively) using a wide range of assemblers. The details of the read sets available to gap fillers are shown in Table 1. For details of the different assemblies we refer the reader to GAGE (Salzberg et al., 2012). Since gaps tend to be introduced in complex areas (e.g., repeated regions or low coverage areas), it is important to evaluate the quality of the sequence inserted by a tool, in addition to the number and length of gaps filled. The quality of the scaffolds on the original assembly as well as of the gap-filled scaffolds was assessed using QUAST (Gurevich et al., 2013). QUAST evaluates assemblies by parsing nucmer (Kurtz et al., 2004) alignments computed between the assembly and the reference sequence.
Gap2Seq v1.0, GapFiller v1.10, and GapCloser v1.12 were run with default parameters on a 32 GB RAM machine equipped with 8 cores. Table 2 summarizes the parameters used by Gap2Seq. GapFiller v1.10 is coupled with BWA (Li and Durbin, 2009) v0.5.9 and with Bowtie (Langmead et al., 2009) v0.12.5. We used both aligners in the evaluation. To better evaluate the gap-filling results, we modified the output produced by QUAST v2.3 with respect to the classification of “misassemblies” and local “misassemblies.” Consider a scaffold ABC (consisting of subsequences A, B, and C) where sequence B is misplaced. Originally, QUAST would give in this case two breakpoints (between AB and BC respectively), thus two misassemblies would be reported. If both the length of B, and the distance between A and C, are shorter than Nbp (suggesting a local erroneous inserted sequence), we instead classify it as one local misassembly and compute its length. We chose N = 4000, since it is a rough upper bound of the insert size of the mate pair libraries. Thus, gaps are not expected to be longer than this. This change implies that we can measure in more detail the size of the erroneous sequences instead of simply classifying them as misassembly errors.
For each assembly, we used our modified version of QUAST to compute:
1. 2. 3. 4. 5. 6.
5. Discussion
5.1. Bacterial data sets
Tables 3 and 4 present the gap-filling performance for the bacterial data sets provided by GAGE. With the evaluation metrics introduced in the previous section, Gap2Seq produces favorable results. Gap2Seq is able to close more and longer gapped sequences in almost all cases. For example, on the ABySS, ABySS2, Allpaths-LG, and SOAPdenovo assemblies, Gap2Seq closes more than 90% of the total gap length, which is a large improvement over GapCloser and GapFiller. In the rhodo data set, Gap2Seq closes on average 25% of the total gap length, but it performs in general more than twice as well as the other two tools. Moreover, for both datasets there is no general increase in misassembled sequences. In fact, in total Gap2Seq also has the highest NGA50 on both genomes. We see that the results on these data sets support a general gain in quality from gap filling and thus, the motivation for using Gap2Seq.
The results shown are relative differences with respect to the results of the original assembly. The bottom section of the table (TOTAL) is obtained by summing up the results of each gap filler for all assemblies. For each row, the best result is bolded and the worst result is shown in italics.
The results shown are relative differences with respect to the results of the original assembly. The bottom section of the table (TOTAL) is obtained by summing up the results of each gap filler for all assemblies. For each row, the best result is bolded and the worst result is shown in italics.
We believe that the good performance of Gap2Seq is due to solving the problem exactly with dynamic programming and using all the reads for filling the gap, instead of only reads whose pair maps on the contigs flanking the gap. In fact, as we will discuss in the next section, using all available reads does not seem to be computationally feasible in the case of larger genomes and less correct scaffolds.
Figures 3 and 4 show runtime and peak memory usage of the gap fillers. On the staph dataset, Gap2Seq and SOAPdenovo's GapCloser are the fastest, while SOAPdenovo's GapCloser is the fastest on the rhodo data set. Gap2Seq is the most memory consuming on the rhodo data set, and SOAPdenovo's GapCloser is the most memory consuming on the staph data set.
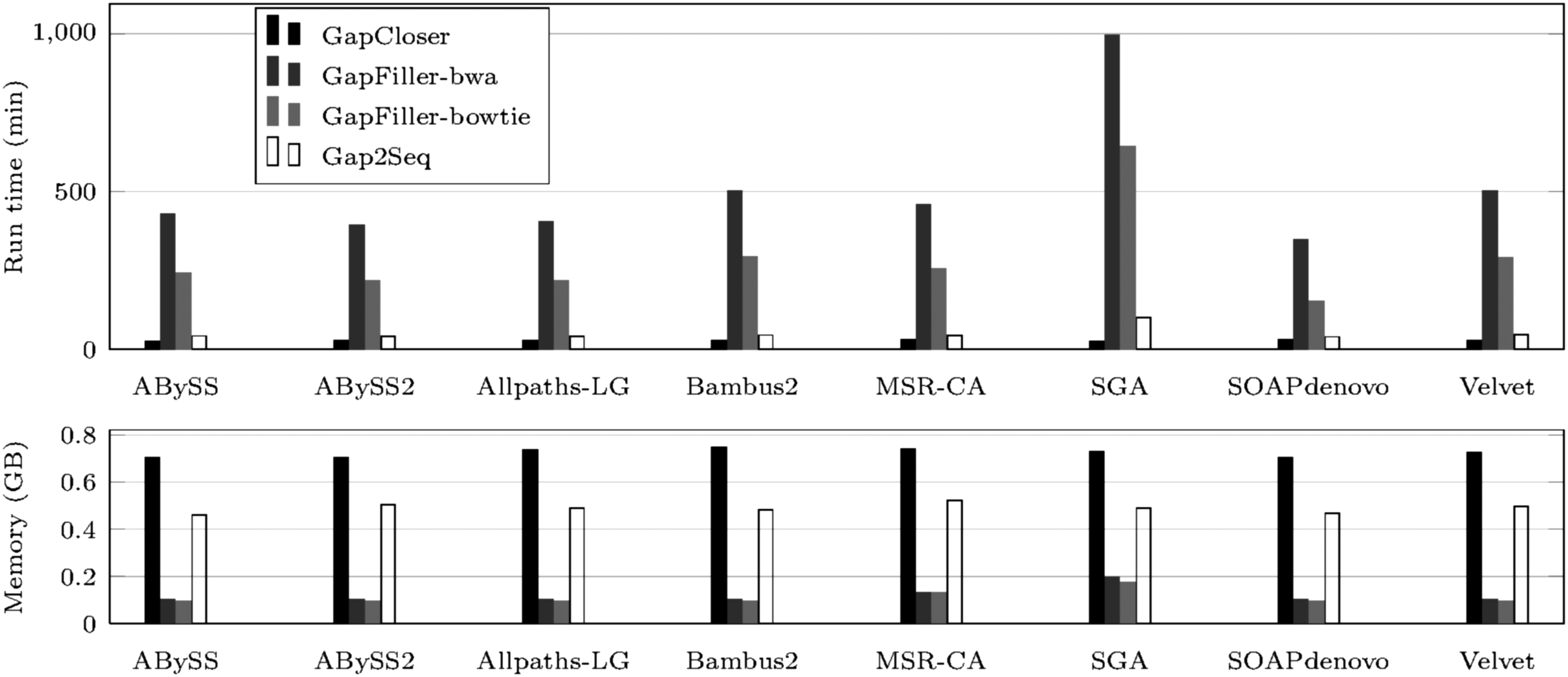
Staph: run time in minutes (above), and peak memory usage in GB (below).
Rhodo: run time in minutes (above, logarithmic scale), and peak memory usage in GB (below).
5.2. Human chromosome 14 data set
The performance of any gap filler depends on the quality of the previous contig assembly and scaffolding phases. Accordingly, we categorized the different assemblies in the human14 GAGE data sets according to their number of misassemblies: conservative assemblies are those with at most 10 misassemblies (and NGA50 at most 10000); moderate assemblies are those with at most 100 misassemblies (and NGA50 at most 100000); and aggressive assemblies are those with more than 1000 misassemblies.
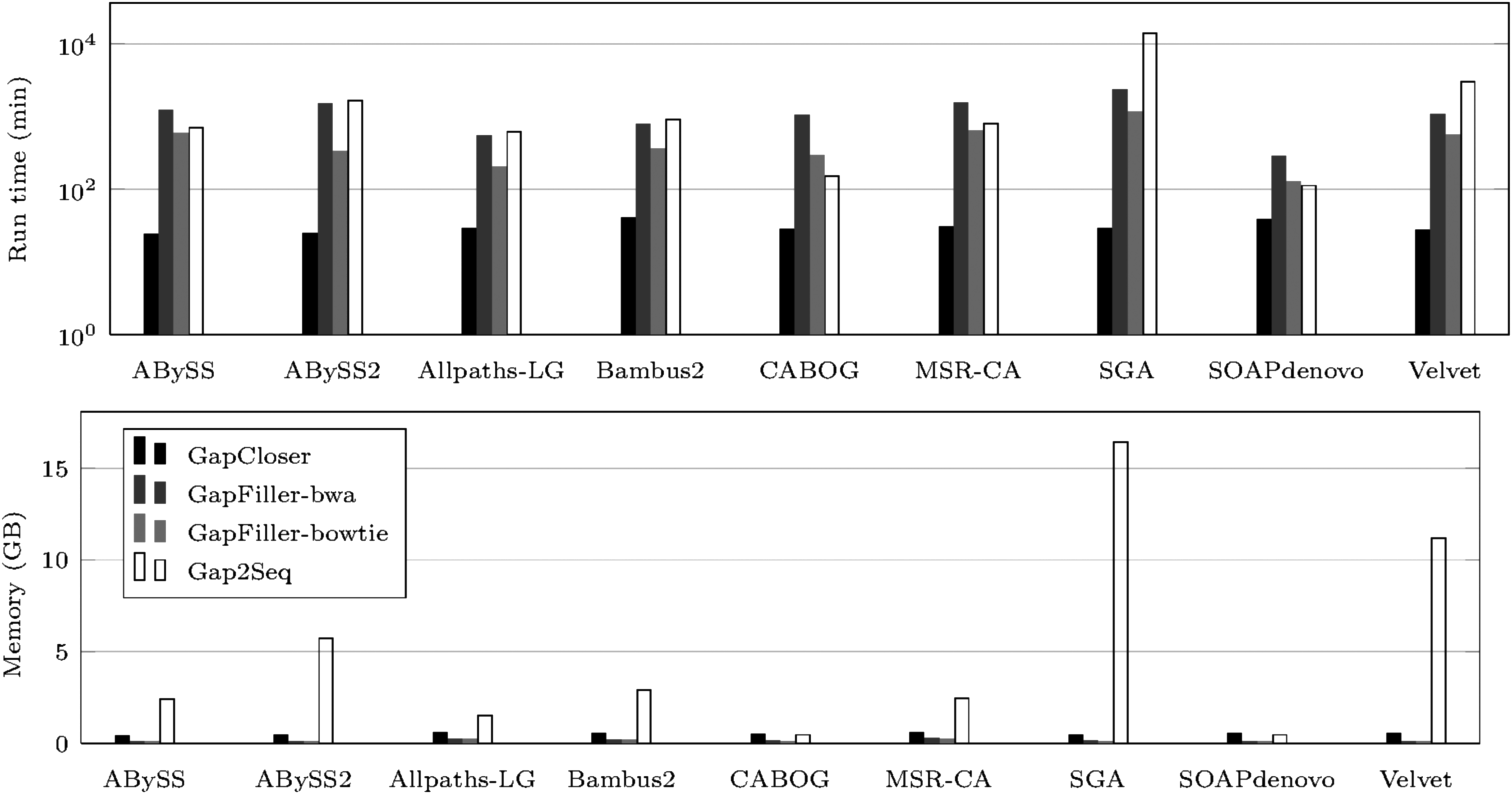
Tables 5–7 present the performance of the gap fillers on the GAGE human14 data sets. As a general comment, we observe that the resulting erroneous sequence after filling the gaps with Gap2Seq is always the smallest, or close to the smallest, independent of the quality of the original assembly. This is most clearly seen on the conservative and moderate assemblies, where Gap2Seq exhibits the best trade-off between resulting erroneous length and filled gap length. While on the aggressive assemblies GapCloser performs the best with respect to most of the metrics, there is no clear best tool in the other two assembly categories. For example, GapFiller-bwa appears to be the best on the CABOG assembly, and GapFiller-bwa and Gap2Seq appear to be the best on the ABySS assembly.
The formatting is the same as in Table 3.
The formatting is the same as in Table 3.
The formatting is the same as in Table 3.
We also investigated how the length of the gap influences Gap2Seq's performance. We chose the assembly where it performs best as compared to the other gap fillers, ABySS (a conservative assembly), and an assembly where it performs worst as compared to the other gap fillers, SOAPdenovo (an aggressive assembly). We then computed the number of gaps that are filled, where there was no path whose length would fall in the required interval, and where Gap2Seq abandoned the search because it exceeded the memory limit. We plot these numbers in Figure 5. In the ABySS assembly, Gap2Seq generally fills the gaps or reports that no path exists. This is contrary to the SOAPdenovo assembly, where Gap2Seq abandons many longer gaps because it exceeds the memory limit. On the one hand, this implies that aggressive assemblies exhibit a too complex behavior to be handled by an exact algorithm running on the graph of all available reads. On the other hand, when the graph between the two flanking contigs does have a manageable size, then such an exact algorithm seems to produce indeed better results than the competing strategies.
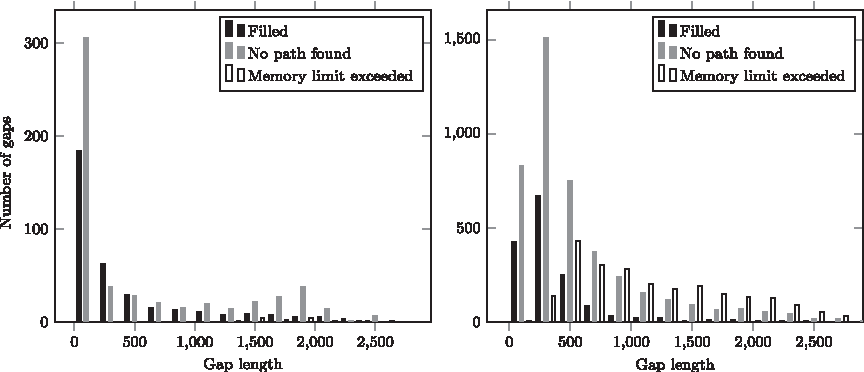
Classification of gaps as reported by Gap2Seq: filled, no path found, or memory limit exceeded. Left: human14 ABySS assembly. Right: human14 SOAPdenovo assembly. Bins of size 200 bp have been used in generating the histograms. The longest gap in the human14 SOAPdenovo assembly is 34,745 bp but the x axis has been cut at 2900 bp for easier comparison with the human14 ABySS assembly where the longest gap is 2758 bp.
Figure 6 shows the runtime and peak memory usage of the gap fillers on the human14 assemblies. GapCloser is the fastest of the methods, while GapFiller-bwa and GapFiller-bowtie are the most memory efficient ones. For Gap2Seq we see that the memory limit of 20 GB excluding the DBG is indeed reached in most cases, and except for the ABySS assembly this also translates to a long runtime.

Human14: run time in minutes (above, logarithmic scale), and peak memory usage in GB (below).
6. Conclusion
In this work we have shown that Gap2Seq has a good performance on bacterial data sets in terms of the quality of the results, with moderate computational requirements. However, such performance does not seem to scale easily to eukaryotic genomes. In fact, our experiments on moderate and aggressive assemblies of human chromosome 14 indicate that many gaps are left unfilled because of running out of resources (Fig. 5). Gap2Seq does generally have the smallest erroneous length of the resulting sequence, but since many gaps are left unfilled we cannot draw a general conclusion about the robustness of our problem formulation. Moreover, all tools exhibit varying behaviors with respect to the number of misassemblies and the number or length of the gaps closed, highlighting the difficulty of the problem in larger genomes.
For cases with many solutions to the gap-filling problem, our current traceback routine could be improved as follows. Using forward and backward computation as in hidden Markov models, one can compute for each vertex v and gap length d, the number of s-t paths of length d passing through that vertex. With one more forward sweep of the algorithm, taking the maximum of these counts, one can traceback a most robust path (see Durbin et al., 1998, Chapter 4, for an analogous computation) that involves vertices most often seen in paths of the correct length.
We note that our definition of gap filling, and hence also the algorithms presented here, are directly applicable to other related problems. For example, the method applies to finding a sequence to span the gap between the two ends of paired-end reads (Nadalin et al., 2012). However, the practical instances for this problem tend to be easier, since paired-end reads are randomly sampled from the genome, whereas in gap filling the easy regions of the genome have already been reconstructed by the contig assembler, and thus only the hard regions are left. Nevertheless, one should be more conservative in filling such gaps, as errors in this phase will be cumulated to later phases of the assembly.
Another example is in variant analysis (Pabinger et al., 2014). In projects with known reference genome, one can sequence the donor and map the reads to the reference. If there is a long insertion in the donor, paired-end read-mapping anomalies and drops in read coverage can predict where an insertion is located in the reference and how long that is. Running gap filling on the unmapped reads can be used to discover this inserted sequence.
Footnotes
Acknowledgments
This work was supported by the Academy of Finland (grants 284598 [CoECGR], 267591 to L.S., and 274977 to A.I.T.), by KTH opportunities fund (grant V-2013-019 to K.S.) and in part by the Swedish Research Council (grant 2010-4634).
Author Disclosure Statement
No competing financial interests exist.