Alignment-free sequence comparison methods are attracting persistent interest, driven by data-intensive applications in genome-wide molecular taxonomy and phylogenetic reconstruction. Among all the methods based on substring composition, the average common substring (ACS) measure admits a straightforward linear time sequence comparison algorithm, while yielding impressive results in multiple applications. An important direction of this research is to extend the approach to permit a bounded edit/hamming distance between substrings, so as to reflect more accurately the evolutionary process. To date, however, algorithms designed to incorporate k ≥ 1 mismatches have O(n2) worst-case time complexity, where n is the total length of the input sequences. On the other hand, accounting for mismatches has shown to lead to much improved classification, while heuristics can improve practical performance. In this article, we close the gap by presenting the first provably efficient algorithm for the k-mismatch average common string (ACSk) problem that takes O(n) space and O(n logkn) time in the worst case for any constant k. Our method extends the generalized suffix tree model to incorporate a carefully selected bounded set of perturbed suffixes, and can be applied to other complex approximate sequence matching problems.
1. Introduction
Treating biosequences as “documents of evolution” (Zuckerkandl and Pauling, 1965) is one of the oldest ideas of molecular biology. In this vein, measures of sequence similarity and distance primarily emerged in coding theory have provided the natural backbone in the development of tools for deriving taxonomies and phylogenies from systematic biosequence comparison. Beginning with Fitch and Margoliash (Fitch et al., 1967), the established methods for automated inference of phylogeny have been based on sequence alignment of protein orthologues or their genes, tRNAs, 16S rRNAs, 23S rRNAs, etc. In 1994, the DIMACS special year on computational biology devoted one of its four main workshops to sequence comparison. By the end of which, more than 1200 noteworthy publications were counted on this subject (Apostolico and Giancarlo, 1998).
In subsequent years, the context has drastically evolved from the original condition of scarcity of data, and a plethora of new problems have emerged. To begin with, dithering the parameters involved in alignment proved not a simple task. Common orthologues are difficult to identify for prokaryotes due to their wide genetic diversity. Lateral transfer of proteins may lead to completely wrong results, for example the entire ribosomal operon (5S + 16S + 23S) in E. coli may be artificially replaced by that from other species (Asai et al., 1999). The resulting trees are prone to intrinsic biases brought about by the specific data being analyzed and so on. To summarize, classical alignment distances become both computationally expensive and scarcely significant when they are applied to entire genomes and are being complemented or even entirely supplanted by global (algebraic) similarity measures that refer, implicitly or explicitly, to the subword composition of sequences, sometimes collectively referred to as “alignment-free” comparisons (see, e.g., Apostolico and Cunial, 2011; Apostolico and Denas, 2008; Apostolico et al., 2010; Blaisdell, 1986; Clift et al., 1986; Cunial and Apostolico, 2012; Edgar, 2004; Ferragina et al., 2007; Gatlin, 1972; Hao and Qi, 2004; Höhl and Ragan, 2007; Höhl et al., 2006; Li et al., 2004; Morgenstern et al., 2014; Otu and Sayood, 2003; Qi et al., 2004; Ulitsky et al., 2006; Van Helden, 2004; Vinga and Almeida, 2003; Wu et al., 1997).
The average common substring measure proposed by Burstein et al. and Ulitsky et al. (Burstein et al., 2005; Ulitsky et al., 2006) is a simple alignment-free sequence comparison method that nevertheless achieved high accuracy in large-scale phylogenetic reconstruction. Formally, let X and Y denote two sequences over the alphabet Σ. We use the notation |X| to denote the length of X, X[i] (1 ≤ i ≤|X|) to denote its ith leftmost character, and X[i…j] to denote the substring X[i]X[i + 1]…X[j]. Let Xi denote the suffix of X starting at ith position, that is, Xi = X[i…|X|]. Let
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
\lambda ({\sf X}_i , { \sf Y} ) = \max\limits_{1 \leq j \leq \mid
{ \sf Y} \mid} \mid {\sf LCP} ({\sf X}_i ,{\sf Y}_j ) \mid ,
\end{align*}
\end{document}
where LCP(Xi, Yj) denote the longest common prefix between suffixes Xi and Yj. The average common substring, ACS(X, Y), is defined as:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*} { \sf ACS } ( { \sf X }
, { \sf Y } ) = \frac { 1 } { \mid {
\sf X } \mid } \mathop \sum \limits_ { i = 1 } ^ {
\mid { \sf X } \mid } \lambda ( {
\sf X } _i , { \sf Y } )\end{align*}
\end{document}
Therefore, ACS(X, Y) is the average of the length of the longest prefix of a suffix of X occurring in Y. One then takes ACS(X, Y) / log |Y| to normalize with respect to the length of Y. A distance metric based on ACS (Ulitsky et al., 2006) is obtained by first taking the inverse of the similarity measure ACS(X, Y) / log |Y| and then subtracting a term to guarantee the condition Dist(X, X) = 0. Specifically, this yields
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*} { \sf Dist } ^ { \prime } ( {
\sf X } , { \sf Y } ) = \frac { \log
\mid { \sf Y } \mid } { { \sf ACS } ( {
\sf X } , { \sf Y } ) } - \frac { \log
\mid { \sf X } \mid } { { \sf ACS } ( {
\sf X } , { \sf X } ) } \end{align*}
\end{document}
where the correction term log |X|/ACS(X, X) = 2log |X|/|X| vanishes as |X|→∞. Following this, one compensates for symmetry by taking
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*} { \sf Dist } ( { \sf X }
, { \sf Y } ) = \frac { { \sf Dist } ^ {
\prime } ( { \sf X } , { \sf Y } ) + {
\sf Dist } ^ { \prime } ( { \sf Y } , {
\sf X } ) } { 2 } \end{align*}
\end{document}
as the final distance. We can easily compute ACS (and then Dist′ and Dist) using a (generalized) suffix tree–based algorithm in time and space linear in the total length of X and Y.
Since its introduction, the ACS measure has gained considerable attention (Apostolico, 2010; Bonham-Carter et al., 2013; Chang and Wang, 2011; Comin et al., 2012; Domazet-Lošo and Haubold, 2009; Fracasso, 2014; Guyon et al., 2009). An important direction of research is to improve the measure by allowing a bounded number k of mismatches in sequence comparison. Define λk(Xi, Y) as:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}\lambda_k ( { \sf X}_i , {
\sf Y} ) = \max \limits_{1 \leq j \leq \mid {
\sf Y} \mid} \mid { \sf LCP}_k ( {
\sf X}_i , { \sf Y}_j ) \mid
,\end{align*}
\end{document}
where LCPk(Xi, Yj) denotes the longest common prefix between suffixes Xi and Yj with allowance for up to k mismatches. The k-mismatch average common substring of X and Y, denoted ACSk(X, Y), is defined as:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*} { \sf ACS } _k ( { \sf X
} , { \sf Y } ) = \frac { 1 } { \mid {
\sf X } \mid } \mathop \sum \limits_ { i = 1 } ^ {
\mid { \sf X } \mid } \lambda_k ( {
\sf X } _i , { \sf Y } )\end{align*}
\end{document}
An algorithm quite recently proposed by Leimeister and Morgenstern (2014) for computing ACSk(X, Y) requires O(|X|×|Y|×k) worst-case run-time, which is quadratic when |X| and |Y| are of the same order, even for k = 1 (also see Pizzi, 2015). However, it is amply documented in Horwege et al. (2014) and Leimeister and Morgenstern (2014) that the ACSk(X, Y) paradigm does yield better phylogenetic classification than both the exact version of the problem and classical approaches using multiple sequence alignment and maximum likelihood. Although Leimeister and Morgenstern (2014) (also see the recent work by Thankachan et al., 2015) proposed faster heuristics to approximate ACSk, designing a provably efficient algorithm remained open. Our goal in this work is to compute ACSk(X, Y) (hence also the naturally associated Distk(X, Y)) in time and space that is as close to linear in n = |X| + |Y| as possible. Our main contribution is summarized in the following theorem:
Theorem 1Let X and Y be two sequences of n characters in total. Let Xibe the suffix of X starting at location i, and λk(Xi, Y) be the length of the longest prefix of Xithat appears in Y with at most k mismatches. Then λk(Xi, Y) can be computed for all values of i in O(n logkn) overall time using O(n) working space for any constant k.
Using Theorem 1, we can compute ACSk(X, Y) in O(n logkn) time. As a byproduct, we also improved upon the best-known results for the k-mismatch longest common substring problem (LCSk), which previously took linear space and O(n log n) time for k = 1, but takes almost quadratic time otherwise (Babenko and Starikovskaya, 2008; Flouri et al., 2015; Grabowski, 2015). Notice that LCSk(X, Y) is the substring corresponding to max{λk(Xi, Y) ∣1 ≤ i ≤ |X|}, hence it can be computed within the same space-time complexity of Theorem 1.
Theorem 2 (k-mismatch longest common substring)Given two sequences of total length n, their longest common substring with at most k mismatches can be computed in O(n logkn) time using O(n) space for any constant k.
2. Key Concepts and Properties
A generalized suffix tree of X and Y (from now onward called GST) is a compact trie that stores all (nonempty) suffixes of X and Y. It takes O(n) space and can be constructed in O(n) space and time (McCreight, 1976; Weiner, 1973), where n = |X| + |Y|. Using GST, we can compute |LCP(Xi, Yj)| for any (i, j) pair in constant time. Specifically, |LCP(Xi, Yj)| is the string depth of the lowest common ancestor (LCA) of leaves representing suffixes Xi and Yj in the GST. Then, |LCPk(Xi, Yj)| for any (i, j) pair can be computed in O(k) time using the following recursion.
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}\mid { \sf LCP}_k ( { \sf
X}_i , { \sf Y}_j ) \mid = \begin{cases}z , { \rm
where} \ z = \mid { \sf LCP} ( {
\sf X}_i , { \sf Y}_j ) \mid \quad
\quad \quad \quad { \rm if} \ k = 0 \\ z + 1 + \mid {
\sf LCP}_{k - 1} ( { \sf X}_{i + z + 1}
, { \sf Y}_{j + z + 1} ) \mid \; \quad { \rm if} \ k
> 0\end{cases}\end{align*}
\end{document}
Therefore, ACSk(·,·) can be computed in O(n2k) time. Clearly, this approach is computationally expensive. To describe our faster approach, we first introduce some definitions and prove resulting useful properties. Throughout this article, we treat k as a constant.
2.1. Modified suffix
Definition 1Let Δ be a set of (position, character) pairs. Then, for any string X, a modified suffix\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sf X}_i^ \Delta$$
\end{document}of X is the string obtained by changing characters in Xias specified by Δ. Specifically, ∀(p, σ)∈Δ, p-th character in Xi (i.e., Xi[p] = X[i + p − 1]) is changed to σ.
For example, if X[1…7] = GATATTT, then X3 = TATTT and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sf X}_3^{ \{ ( 2 , G ) , ( 4 , C ) \} } = TGTCT$$
\end{document}.
Lemma 1Given two modified suffixes\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sf X}_i^ \Delta$$
\end{document}and\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sf Y}_j^{ \Delta^{ \prime}}$$
\end{document}, we can compute\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\mid { \sf LCP} ( { \sf X}_i^{ \Delta} , { \sf Y}_j^{ \Delta^{ \prime}} ) \mid$$
\end{document}in O(|Δ∪Δ′|) time using a generalized suffix tree of X and Y.
Proof Let t = |Δ∪Δ′|. Consider breaking each suffix X i and Yj into at most (t + 1) segments by using the t position values in Δ∪Δ′ as breakpoints. Note the substrings of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sf X}_i^ \Delta$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sf Y}_j^{ \Delta^{ \prime}}$$
\end{document} between any two consecutive breakpoints are substrings of X and Y, respectively. By preprocessing GST of X and Y to answer lowest common ancestor queries in constant time, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\mid { \sf LCP} ( { \sf X}_i^{ \Delta} , {\sf Y}_j^{ \Delta^{ \prime}} ) \mid$$
\end{document} can be computed using at most (t + 1) such queries. We remark that the result holds true even if both modified suffixes are from the same string.
Lemma 2Given a set\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S}$$
\end{document}of modified suffixes, where the number of modifications in each suffix is a constant, we can lexicographically sort them all in\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$O ( \mid { \cal S} \mid \log \mid { \cal S} \mid )$$
\end{document}time.
Proof Using Lemma 1, we can compute the |LCP(·,·)| between any two strings in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S}$$
\end{document} in constant time. Therefore, by comparing their next characters, we can determine the lexicographic ordering between them. Since two strings can be compared in constant time, an efficient comparison-based sorting (e.g., merge sort) can be used.
2.2. (i, j)h-Maxpair
Definition 2Let l1< l2< … < lh be the first h positions in which suffixes Xiand Yjdiffer, i.e., Xi[lm] ≠ Yj[lm] (or equivalently, X[i + lm − 1] ≠ Y[j + lm − 1]) for all 1 ≤ m ≤ h. If the modifications specified in Δ and Δ′are performed only at positions l1,l2,…lh in such a way that ∀m,\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sf X}_i^{ \Delta} [ l_m ] \mid = { \sf Y}_j^{ \Delta^{ \prime}} [ l_m ]$$
\end{document}, then we term\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sf X}_i^ \Delta$$
\end{document}and\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sf Y}_j^{ \Delta^{ \prime}}$$
\end{document}an (i, j)h-maxpair, and the following is true:\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\mid { \sf LCP}_h ( { \sf X}_i , {
\sf Y}_j ) \mid = \mid { \sf LCP} ( { \sf X}_i^{ \Delta} , { \sf
Y}_j^{ \Delta^ \prime} ) \mid$$
\end{document}.
Let q = |LCPh(Xi, Yj)|. Then the prefixes X[i…i + q − 1] and Y[j…j + q − 1] of Xi and Yj respectively, differ in (at most) h positions. An (i, j)h-maxpair contains modifications to Xi and Yj so that the characters in these positions no longer differ. As there are |Σ| possible ways of effecting this change for each position, the total number of potential (i, j)h-maxpairs is |Σ|h. For example, if Xi = AATT…, Yj = AAAT…, and Σ = {A, C, G, T}, then (i, j)1-maxpair's are \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$( { \sf X}_i^{ \{ ( 3 , A ) \} } , {
\sf Y}_j ) , ( { \sf X}_i , {
\sf Y}_j^{ \{ ( 3 , T ) \} } ) , {
\sf X}_i^{ \{ ( 3 , C ) \} } , {
\sf Y}_j^{ \{ ( 3 , C ) \} } )$$
\end{document}, and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$( { \sf X}_i^{ \{ ( 3 , G ) \} } , { \sf Y}_j^{ \{ ( 3 , G ) \} } )$$
\end{document}.
3. An Overview of Our Algorithm
Definition 3For a fixed k, auniverse (denoted by\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal U}$$
\end{document}) is a set of modified suffixes, such that for any 1 ≤ i ≤ |X| and 1 ≤ j ≤ |Y|, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal U}$$
\end{document}contains two modified suffixes that together form an (i, j)k-maxpair. Apartitionof\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal U}$$
\end{document}is a collection of its subsets\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal P}_1 , { \cal P}_2 , \ldots , { \cal P}_t$$
\end{document}such that ∀i, j, ∃ an (i, j)k-maxpair in at least one\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal P}_f , 1 \leq f \leq t$$
\end{document}.
The key intuition behind our algorithm is that by processing a given \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal U}$$
\end{document} in time and space linear (or near-linear) to its size, we can compute ACSk. Partitioning \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal U}$$
\end{document} provides a more convenient way to compute ACSk by splitting the potentially large \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal U}$$
\end{document} into multiple smaller sets and processing them independently. Clearly, there exists a universe of size O(n2). However, our algorithm is based on the existence of a partition as summarized in the following lemma.
Lemma 3There exists a universe\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal U}$$
\end{document}and its partition\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\{ { \cal P}_1 , { \cal P}_2 , \ldots , { \cal P}_t \} $$
\end{document}, such that\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}\max \limits_{1 \leq f \leq t} \mid { \cal P}_f
\mid = O ( n ) \ \ { \rm and} \ \ \sum \limits_{1 \leq f \leq t}
\mid { \cal P}_f \mid = O ( n \log^k n )\end{align*}
\end{document}
Our algorithm can be viewed as consisting of two phases. In the first phase, we generate members of the partition, one at a time. The second phase takes each member \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal P}_f$$
\end{document} separately and extracts information necessary for computing ACSk. We show that using O(n) working space, members can be generated one after the other in overall O(n logkn) time. Similarly, using O(n) working space, members can be processed one after the other in overall O(n logkn) time. Therefore, by interleaving phase 1 and phase 2 (i.e., as soon as a member is generated, process it and then discard it from the working space), we achieve the space–time complexities in Theorem 1. We now present the phases in detail.
4. Phase 1: Constructing the Partition
Our method for constructing the partition borrows from ideas in Cole et al. (2004) on string indexing for approximate pattern-matching queries, which itself relies on the classic heavy path decomposition strategy invented by Sleator and Tarjan (1981). The procedure is recursive, which can be best explained as constructing a tree (TREE) as follows:
Definition 4 TREEis of depth k and each node x in TREE is associated with a set\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S}_x$$
\end{document}of modified suffixes. The set associated with root consists of all n suffixes of X and Y. Then, starting with x = root, the sets associated with the children of any internal node x are generated from\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S}_x$$
\end{document}using a recursive procedure maintaining the following properties:
1. The size of the set associated with any child node of x is\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$O ( \mid { \cal S}_x \mid )$$
\end{document}.
2. The sum of sizes of sets associated with all children of x is\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$O ( \mid { \cal S}_x \mid \log \mid { \cal S}_x \mid )$$
\end{document}.
3. If there exists an (i, j)h−1-maxpair in\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S}_x$$
\end{document}, where x is at depth (h – 1), then the set associated with one of the children of x must contain an (i, j)h-maxpair.
By unfolding the recursion k times, we have the following bounds for any constantk.
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}\max \limits_{x \in\;{ \rm NODES}} \mid { \cal
S}_x \mid = O ( n ) \ { \rm and} \sum \limits_{x \in { \rm NODES}}
\mid { \cal S}_x \mid = O ( n \log^k n )\end{align*}
\end{document}
Here NODES is the set of nodes in TREE. Additionally, the collection of sets associated with the leaves of TREE form the partition in Lemma 3. We now present details of the recursion.
4.1. Details of recursion
Let \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S}_x$$
\end{document} be the set associated with a node x at depth (h − 1) in TREE. Then, we create its children and the sets associated with them as follows: construct a patricia trie \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal T}$$
\end{document} over the strings in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S}_x$$
\end{document} (Gusfield, 1997), which consists of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\mid { \cal S}_x \mid$$
\end{document} leaves and at most \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$( \mid { \cal S}_x \mid - 1 )$$
\end{document} internal nodes such that the degree of any internal node is at least two. Corresponding to each string in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S}_x$$
\end{document}, there will be a unique leaf node in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal T}$$
\end{document} and vice versa.* We then classify the nodes in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal T}$$
\end{document} as either light or heavy using the following rule: the root is always light and exactly one child of every internal node is heavy. The heavy child of any internal node is the one with the maximum number of leaves in its subtree (break ties arbitrarily). Essentially we are doing a decomposition of the tree based on heavy and light nodes (a.k.a heavy path decomposition). For any node w in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal T}$$
\end{document}, let str(w) be the set of strings in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S}_x$$
\end{document} corresponding to all the leaves in the subtree of w. The following result is by Sleator and Tarjan (1981).
Lemma 4The number of light ancestors of any node in\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal T}$$
\end{document}is\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\leq \log \mid { \cal S}_x \mid$$
\end{document}.
Proof Note that for any light node w, with w′ being its heavy sibling and v being their parent, |str(v)|≥|str(w)| + |str(w′)|≥ 2 ×|str(w)|. If the number of light ancestors exceeds \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\log \mid { \cal S}_x \mid$$
\end{document}, then |str(root)| >\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\mid { \cal S}_x \mid$$
\end{document}, which is a contradiction.
A path, starting from w to a unique leaf in its subtree, where all nodes on this path are heavy is called the heavy path of w. We use heavypath(w) to denote the string corresponding to that unique leaf node. Corresponding to each light internal nodew in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal T}$$
\end{document}, we create a child for x (say x′) in TREE and the set \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S}_{x^{ \prime}}$$
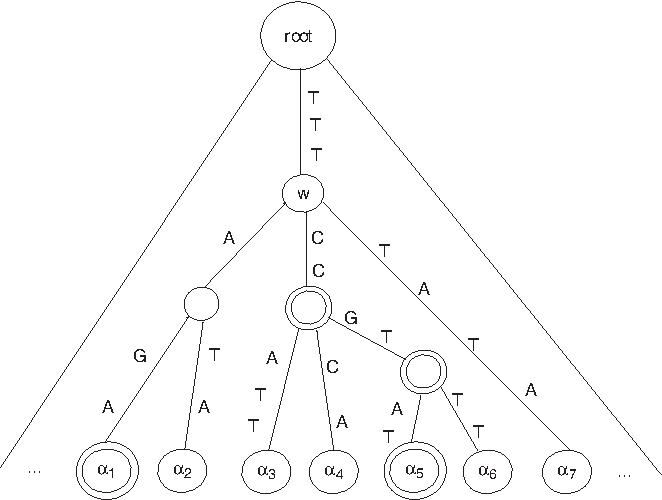
\end{document} is obtained as follows (see Fig. 1 for an illustration):
1. For each string α ∈ str(w) except heavypath(w), find p = 1 + |LCP(α, heavypath(w))|, that is, the position where the first mismatch occurs while matching the prefixes of α and heavypath(w).
2. Obtain a new string α′ from α by changing the character of α at position p to the character of heavypath(w) at the same position p. Specifically, α′ = α{(p,heavypath(w)[p])}. Therefore, |LCP1(α, heavypath(w))| = |LCP(α′, heavypath(w))|.
3. Then \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S}_{x^{ \prime}}$$
\end{document} is the union of str(w) and the set of (|str(w)|−1) newly created strings with respect to heavypath(w).
The heavy nodes are drawn as double circles. Here α1 = TTTAGA, α2 = TTTATA, α3 = TTTCCATT, etc. str(w) = {α1,…,α7}, and heavypath(w) = α5 = TTTCCGTAT. Therefore, set corresponding to w is str(w) \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\cup \ \{ \alpha_1^{ \prime} , \alpha_2^{ \prime} , \alpha_3^{ \prime} , \alpha_4^{ \prime} , \alpha_6^{ \prime} , \alpha_7^{ \prime} \} $$
\end{document}, where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\alpha_1^{ \prime}$$
\end{document} = TTTCGA,\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\alpha_2^{ \prime}$$
\end{document} = TTTCTA,\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\alpha_3^{ \prime}$$
\end{document} = TTTCCGTT,\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\alpha_4^{ \prime}$$
\end{document} = TTTCCGA,\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\alpha_6^{ \prime}$$
\end{document} = TTTCCGTAT, and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\alpha_7^{ \prime}$$
\end{document} = TTTCATA.
Clearly, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\mid { \cal S}_{x^{ \prime}} \mid = ( 2 \mid { \sf str} ( w ) \mid - 1 ) = O ( \mid { \cal S}_x \mid )$$
\end{document}. The number of sets (associated with the children of x) in which a particular string in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S}_x$$
\end{document} or a modified version of it belongs to is bounded by the maximum number of light ancestors of any node in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal T}$$
\end{document}, which is \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\log \mid { \cal S}_x \mid$$
\end{document}. This gives an upper bound \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$2 \mid { \cal S}_x \mid \log \mid { \cal S}_x \mid$$
\end{document} on the sum of sizes of the sets associated with the children of x. Finally, let \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sf X}_i^{ \Delta}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sf Y}_j^{ \Delta^{ \prime}}$$
\end{document} be two modified suffixes in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S}_x$$
\end{document} that form an (i, j)h−1-maxpair, and let u (resp., w) be the lowest common ancestor (resp., light ancestor) of the leaves corresponding to them in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal T}$$
\end{document}. Then, our method creates a set corresponding to w, such that it contains two modified suffixes \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sf X}_i^{ \Delta^{ \prime \prime}}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sf Y}_j^{ \Delta^{ \prime \prime \prime}}$$
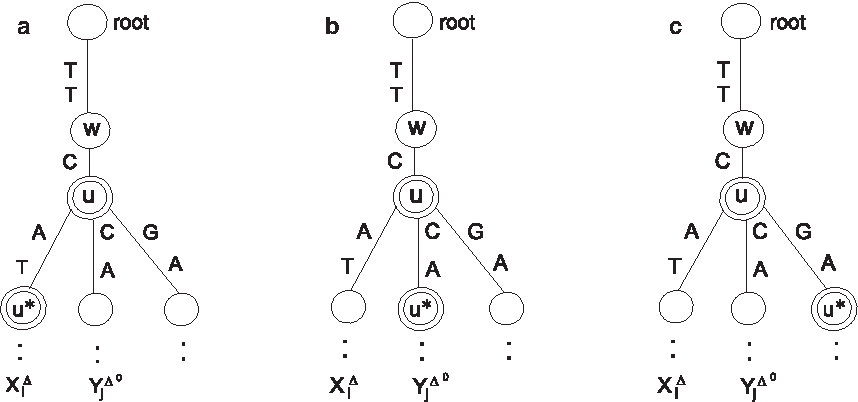
\end{document} that form an (i, j)h-maxpair. Specifically, Δ″ and Δ′″ are as follows (see Fig. 2 for an illustration):
(a) If the heavy child of u, say u*, is an ancestor of the leaf corresponding to \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sf X}_i^{ \Delta}$$
\end{document}, then Δ′′ = Δ and Δ′′′ = Δ′∪{(p, Xi[p])}, where p = 1 plus string depth of u.†
(b) If u* is an ancestor of the leaf corresponding to \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sf Y}_j^{ \Delta^{ \prime}}$$
\end{document}, then Δ′′ = Δ ∪{(p, Yj[p])} and Δ′′′ = Δ′.
(c) If neither of the above is true, then we have Δ″ = Δ ∪{(p, heavypath(w)[p])} and Δ′′′ = Δ′∪{(p, heavypath(w)[p])}.
Heavy nodes are drawn as double circles. In this example, u is heavy, the string depth of u is 3, and p = 4. Then, Δ′′′ = Δ′∪{[4, A]} in case(a), Δ′′ = Δ ∪{[4, C]} in case(b), and Δ′′ = Δ ∪{[4, G]}, Δ′′′ = Δ′∪{[4, G]} in case(c).
4.1.1. Time and space complexity
The above recursive step can be executed as follows: First, construct \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal T}$$
\end{document} using the following steps.
1. Lexicographically sort all modified suffixes in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$O ( \mid { \cal S}_x \mid )$$
\end{document}. We shall use the result in Lemma 2 and perform this step in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$O ( \mid { \cal S}_x \mid \log \mid { \cal S}_x \mid )$$
\end{document} time.
2. Compute |LCP(·,·)| between all consecutive pairs of modified suffixes in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S}_x$$
\end{document}. Using GST, we can execute this step in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$O ( \mid { \cal S}_x \mid )$$
\end{document} time using Lemma 1.
3. Finally, to construct \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal T}$$
\end{document} using the results from Step (1) and Step (2), we borrow well-known techniques from the suffix tree construction literature [Farach-Colton et al., 2000): a patricia tree over a set of strings can be constructed in time linear in the number of strings, given the lexicographical ordering of all strings and length of the longest common prefix of all pairs of consecutive leaves of the tree. Therefore, time complexity is \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$O ( \mid { \cal S}_x \mid )$$
\end{document}.
Once \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal T}$$
\end{document} is constructed, all light internal nodes can be identified by a linear time tree traversal. Each light node w is then visited and the set corresponding to it is constructed in O(|str(w)|) time. The total time is proportional to the \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S}_x$$
\end{document} plus the sum of sizes of all newly created sets, that is, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$O ( \mid { \cal S}_x \mid \log \mid { \cal S}_x \mid )$$
\end{document}. Therefore, time for constructing TREE is \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\sum \nolimits_{x \in { \rm NODES}} \mid { \cal S}_x \mid = O ( n \log^k n )$$
\end{document}.
Since we are not interested in storing the members of the partition, but just create, process, and discard them, the nodes in TREE can be created in the order of depth first search, so that at any point in time, we need to maintain nodes (and associated sets) in only one root to leaf path. Therefore, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$O ( k \times \max \nolimits_{x \in { \rm NODES}} \mid { \cal S}_x \mid ) = O ( n )$$
\end{document} working space is sufficient. This completes phase 1 of our algorithm.
5. Phase 2: Processing the Partition
In this section, we describe how to process each member \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal P}_f$$
\end{document} of the partition independently. Let \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\Lambda [ 1 , \mid { \sf X} \mid ]$$
\end{document} be an integer array of length |X| with all its entries initialized to 0. While processing the members, we update this array in such a way that after processing all members in the partition, we obtain \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\lambda_k ( { \sf X}_i , { \sf Y} ) = \Lambda [ i ]$$
\end{document}. To process a particular \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal P}_f$$
\end{document}, we follow the steps below:
Here δ is a set of (position, character) pairs and x, y are integers in [0, k].
2. Then process each \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\Pi_{ ( \delta , x , y ) }$$
\end{document} as follows: For each \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sf X}_i^{ \Delta} \in \Pi_{ ( \delta , x , y ) }$$
\end{document}, find the \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${\sf Y}_j^{ \Delta^{\prime}} \in \Pi_{ ( \delta , x , y ) }$$
\end{document}, that maximizes the length of their longest common prefix. Then update
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}\Lambda [ i ] \gets \max \{ \Lambda [ i ] , \mid { \sf LCP}_k ( { \sf X}_i , { \sf Y}_j ) \mid \} \end{align*}
\end{document}
In other words, first sort all modified suffixes in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\Pi_{ ( \delta , x , y ) }$$
\end{document}. Then for each \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sf X}_i^{ \Delta} \in \Pi_{ ( \delta , x , y ) }$$
\end{document}, find the closest modified suffixes of Y (say, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sf Y}_{j_l}^{ \Delta_l}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sf Y}_{j_r}^{ \Delta_r}$$
\end{document}) toward, the left as well as the right side of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sf X}_i^{ \Delta}$$
\end{document}, then update \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\Lambda [ i ] \gets \max \{ \Lambda [ i ] , \mid { \sf LCP}_k ( { \sf X}_i , { \sf Y}_{j_l} ) \mid , \mid { \sf LCP}_k ( { \sf X}_i , { \sf Y}_{j_r} ) \mid \} $$
\end{document}.
Correctness: To prove that λk(Xi, Y) = Λ[i] after processing all members, consider a fixed i, where λk(Xi, Y) = |LCPk(Xi, Yj*)|. While processing the member that contains an (i, j*) k-maxpair (say \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sf X}_i^{ \Delta_1}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sf Y}_{j^*}^{ \Delta_2}$$
\end{document}), a pi-set \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\Pi_{ ( \Delta_1 \cap \Delta_2 , \mid \Delta_1 \mid , \mid \Delta_2 \mid ) }$$
\end{document} will be created, and while processing this particular pi-set, Λ[i] will be updated to \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\mid { \sf LCP}_k ( { \sf X}_i , { \sf Y}_{j^*} ) \mid$$
\end{document}.
Analysis: Step 1 can be implemented as follows.
1. For each \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sf X}_i^{ \Delta} \in { \cal P}_f$$
\end{document}, generate a (set, string) pair of the form (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$( \delta , { \sf X}_i^{ \Delta} )$$
\end{document} ) for each δ ⊆ Δ. Similarly, for each \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sf Y}_j^{ \Delta^{ \prime}} \in { \cal P}_f$$
\end{document}, generate pair (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$( \delta , { \sf Y}_j^{ \Delta^{ \prime}} )$$
\end{document} ) for each δ ⊆ Δ′. Therefore, the number of pairs is \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\leq 2^k \mid { \cal P}_f \mid$$
\end{document}.
2. Partition pairs into buckets, such that all pairs of the form (δ,·) are in the same bucket, say Bδ. This step can be reduced to sorting by first defining a total ordering among sets. For example, pairs can be first sorted based on the size of the set (smaller set first). Then, among the sets of the form {(l1, σ1), (l2, σ2)…, (lm, σm)}, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$l_1 < l_2 < \cdots < l_m$$
\end{document}, where m is fixed, first sort them with respect to l1, break ties with respect to σ1, break further ties with respect to l2, and so on. This way, pairs within the same bucket form a contiguous region in the sorted list, hence can be easily separated.
3. Now creating pi-sets \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\Pi_{ ( \delta , x , y ) }$$
\end{document} from Bδ for all 0 ≤ x, y ≤ k is straightforward. Note that the sum of sizes of all pi-sets created is \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\leq ( k + 1 ) 2^k \mid { \cal P}_f \mid = O ( \mid { \cal P}_f \mid )$$
\end{document}
Essentially, step 1 involves sorting and scanning several sets of integers of total cardinality \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$O ( \mid { \cal P}_f \mid )$$
\end{document}. The key operations involved in step 2 are also the same. Therefore, a particular \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal P}_f$$
\end{document} can be processed in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$O ( \mid { \cal P}_f \mid \log \mid { \cal P}_f \mid )$$
\end{document} time using \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$O ( n + \mid { \cal P}_f \mid )$$
\end{document} working space. Therefore, we can implement phase 2 in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$O ( n + \max \nolimits_f \mid { \cal P}_f \mid ) = O ( n )$$
\end{document} space and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$O ( n \log^k n + \sum \nolimits_f \mid { \cal P}_f \mid \log \mid { \cal P}_f \mid ) = O ( n \log^{k + 1}n )$$
\end{document} time.
5.1. Improving the run-time complexity
In this section, we show how to improve the run time of phase 2 (thus overall time) to O(n logkn). Following is a key result (proof will be detailed later).
Lemma 5The sorting of strings within a member\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal P}_f$$
\end{document}can be reduced to the sorting and scanning of several sets of integers in [0, O(n)] of total cardinality\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$O ( \mid { \cal P}_f \mid )$$
\end{document}.
Notice that the processing of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal P}_f$$
\end{document} essentially consists of sorting and scanning of several sets of integers or strings of total cardinality \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$O ( \mid { \cal P}_f \mid )$$
\end{document}. However, by applying Lemma 5 once, we can associate each string in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal P}_f$$
\end{document} with its lexicographic rank in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal P}_f$$
\end{document}, and all time-consuming steps in the processing of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal P}_f$$
\end{document} can be reduced to integer sorting as follows.
Lemma 6Processing of\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal P}_f$$
\end{document}can be reduced to the sorting and scanning of several sets of integers in [0,O(n)] of total cardinality\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$O ( \mid { \cal P}_f \mid )$$
\end{document}.
Using the above lemma, we have the following result: processing of several \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal P}_f$$
\end{document}'s of total cardinality O(n) can be reduced to sorting and scanning of several sets of integers in [0, O(n)] of total cardinality O(n), and solved in O(n) space and time. Using this result as a black box, we can process all members in the partition in O(n) space and O(n logkn) time.§ This completes phase 2 of our algorithm.
In summary, both Phase 1 and Phase 2 can be executed in O(n logkn) time using O(n) working space. This completes the proof of Theorem 1.
5.1.1. Proof of Lemma 5
From section 4.1, recall that each node x in TREE is associated with a set \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S}_x$$
\end{document}, and it corresponds to a member in the partition if x is a leaf node. Therefore, it suffices to prove the result for an arbitrary \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S}_x$$
\end{document}. Let \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal T}$$
\end{document} be the trie over the strings in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S}_x$$
\end{document} and root be its root node, then
1. For any string \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\alpha \in { \cal S}_x$$
\end{document}, the string obtained by deleting the |LCP(α, heavypath(root))|-long prefix of α is a proper suffix (i.e., suffix without any modification) of X or Y. The result can be proven using mathematical induction: the base case (i.e., x is root) is trivially true. For any other node x, the result easily follows from the construction procedure detailed in section 4.1, provided that the result holds true for the set associated with the parent of x.
2. For two strings α,β, we denote α < β if α comes before β in lexicographic order. Then, the set \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal S}_x$$
\end{document} can be partitioned into sets BEFORE(d)'s and AFTER(d)'s for several values of d, where
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}BEFORE ( d ) = \{ \alpha \in { \cal S}_x \parallel
{ \sf LCP} ( \alpha , { \sf heavypath} (
root ) ) \mid = d , \alpha < { \sf heavypath} ( root )
\} \end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}AFTER ( d ) = \{ \alpha \in { \cal S}_x \parallel
{ \sf LCP} ( \alpha , { \sf heavypath} (
root ) ) \mid = d , \alpha > { \sf heavypath} ( root )
\} \end{align*}
\end{document}
Each proper suffix can be uniquely mapped to its lexicographic rank among all suffixes of X and Y. Therefore, a collection of proper suffixes can be sorted via integer sorting. Additionally, all strings within a particular BEFORE(d) [resp., AFTER(d)] share the same d-long prefix, and its removal will result in a set of proper suffixes, which can be sorted via integer sorting. In summary, we can categorize the strings in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal P}_f$$
\end{document} into sets BEFORE(·)'s and AFTER(·)'s with the strings within it sorted.
3. Finally, observe the following:
(a) If α∈BEFORE(·) and β∈AFTER(·), then α < β,
(b) If α∈BEFORE(d) and β∈BEFORE(d′), then α < β iff d < d′, and
(c) If α∈AFTER(d) and β∈AFTER(d′), then α < β iff d > d′.
In light of the above three observations, we can obtain a sorted \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal P}_f$$
\end{document} by concatenating sorted BEFORE(d)'s in the ascending order of d's followed by sorted AFTER(d)'s in the descending order of d's.
This completes the proof of Lemma 5.
6. Conclusions
We present an efficient algorithm for the k-mismatch average common substring problem that runs in O(n logkn) time and O(n) space. This constitutes a significant improvement over the O(n2) worst case run-time of the prior state of the art. In the absence of the proposed space-saving technique, our algorithm would have taken O(n log kn) space, which would be impractical for even small values of k. Our algorithm achieves linear working space by decomposing the set of modified suffixes so that they can be processed and discarded independently, while preserving the ability to bring pairs of modified suffixes together. Note that the biological applications of ACSk are well documented in Leimeister and Morgenstern (2014). The vastly improved efficiency in computing ACSk by our algorithm should naturally impact these applications positively.
Footnotes
Acknowledgment
This research is supported in part by the U.S. National Science Foundation under IIS-1416259.
Author Disclosure Statement
No competing financial interests exist.
References
1.
AluruS., ApostolicoA., and ThankachanS.V.2015. Efficient alignment free sequence comparison with bounded mismatches, 1–12. Proceedings of Research in Computational Molecular Biology—19th Annual International Conference, RECOMB 2015, Warsaw, Poland, April 12–15, 2015.
2.
ApostolicoA.2010. Maximal words in sequence comparisons based on subword composition, 34–44. In Algorithms and Applications. Springer, New York.
3.
ApostolicoA., and CunialF.2011. Sequence similarity by gapped lzw, 343–352. Data Compression Conference (DCC), 2011. IEEE, New York.
4.
ApostolicoA., and DenasO.2008. Fast algorithms for computing sequence distances by exhaustive substring composition. Algorithms Mol. Biol. 3, 1756.
5.
ApostolicoA., and GiancarloR.1998. Sequence alignment in molecular biology. J. Comput. Biol., 5, 173–196.
6.
ApostolicoA., DenasO., and DressA.2010. Efficient tools for comparative substring analysis. J. Biotechnol., 149, 120–126.
7.
AsaiT., ZaporojetsD., SquiresC., and SquiresC.L.1999. An Escherichia coli strain with all chromosomal rRNA operons inactivated: Complete exchange of rRNA genes between bacteria. Proc. Natl. Acad. Sci., 96, 1971–1976.
8.
BabenkoM.A., and StarikovskayaT.A.2008. Computing longest common substrings via suffix arrays, 64–75. In Computer Science—Theory and Applications. Springer, New York.
9.
BlaisdellB.E.1986. A measure of the similarity of sets of sequences not requiring sequence alignment. Proc. Natl. Acad. Sci., 83, 5155–5159.
10.
Bonham-CarterO., SteeleJ., and BastolaD.2013. Alignment-free genetic sequence comparisons: A review of recent approaches by word analysis. Brief. Bioinform. 15, 890–905.
11.
BursteinD., UlitskyI., TullerT., and ChorB.2005. Information theoretic approaches to whole genome phylogenies, 283–295. Research in Computational Molecular Biology, 9th Annual International Conference, RECOMB 2005.
12.
ChangG., and WangT.2011. Phylogenetic analysis of protein sequences based on distribution of length about common substring. Protein J. 30, 167–172.
ColeR., GottliebL.-A., and LewensteinM.2004. Dictionary matching and indexing with errors and don't cares, 91–100. STOC ’04: Proceedings of the Annual ACM Symposium on the Theory of Computing.
15.
CominM., VerzottoD., et al.2012. Alignment-free phylogeny of whole genomes using underlying subwords. Algorithms Mol. Biol. 7, 34.
16.
CunialF., and ApostolicoA.2012. Phylogeny construction with rigid gapped motifs. J. Comput. Biol., 19, 911–927.
17.
Domazet-LosoM., and HauboldB.2009. Efficient estimation of pairwise distances between genomes. Bioinformatics, 25, 3221–3227.
18.
EdgarR.C.2004. Local homology recognition and distance measures in linear time using compressed amino acid alphabets. Nucleic Acids Res. 32, 380–385.
19.
Farach-ColtonM., FerraginaP., and MuthukrishnanS.2000. On the sorting-complexity of suffix tree construction. J. ACM, 47, 987–1011.
20.
FerraginaP., GiancarloR., GrecoV., et al.2007. Compression-based classification of biological sequences and structures via the universal similarity metric: Experimental assessment. BMC Bioinform. 8, 252.
21.
FitchW.M., MargoliashE., et al.1967. Construction of phylogenetic trees. Science, 155, 279–284.
22.
FlouriT., GiaquintaE., KobertK., and UkkonenE.2015. Longest common substrings with k mismatches. Inf. Process. Lett., 115, 643–647.
23.
FracassoG.1972. Genome composition with mismatches and its application to phylogeny. 2014.
24.
GatlinL.L.1972. Information theory and the living system.
25.
GrabowskiS.2015. A note on the longest common substring with k-mismatches problem. Inf. Process. Lett., 115, 640–642.
26.
GusfieldD.1997. Algorithms on Strings, Trees and Sequences: Computer Science and Computational Biology. Cambridge University Press, Cambridge, UK.
27.
GuyonF., Brochier-ArmanetC., and GuénocheA.2009. Comparison of alignment free string distances for complete genome phylogeny. Adv. Data Anal. Classif. 3, 95–108.
28.
HaoB., and QiJ.2004. Prokaryote phylogeny without sequence alignment: From avoidance signature to composition distance. J. Bioinform. Comput. Biol., 2, 1–19.
29.
HöhlM., and RaganM.A.2007. Is multiple-sequence alignment required for accurate inference of phylogeny?. Syst. Biol., 56, 206–221.
30.
HöhlM., RigoutsosI., and RaganM.A.2006. Pattern-based phylogenetic distance estimation and tree reconstruction. Evol. Bioinform. Online, 2, 359.
31.
HorwegeS., LindnerS., BodenM., et al.2014. Spaced words and kmacs: Fast alignmentfree sequence comparison based on inexact word matches. Nucleic Acids Res. 42, W7–W11.
32.
LeimeisterC.-A., and MorgensternB.2014. kmacs: The k-mismatch average common substring approach to alignment-free sequence comparison. Bioinformatics, 30, 2000–2008.
33.
LiM., ChenX., LiX., et al.2004. The similarity metric. IEEE Trans. Inform. Theory., 50, 3250–3264.
34.
McCreightE.M.1976. A space-economical suffix tree construction algorithm. J. ACM, 23, 262–272.
35.
MorgensternB., ZhuB., HorwegeS., and LeimeisterC.-A.2014. Estimating evolutionary distances from spaced-word matches, 161–173. Algorithms in Bioinformatics—14th International Workshop, WABI.
36.
OtuH.H., and SayoodK.2003. A new sequence distance measure for phylogenetic tree construction. Bioinformatics, 19, 2122–2130.
37.
PizziC.2015. A Filtering approach for alignment-free biosequences comparison with mismatches, 231–242. Proceedings of Algorithms in Bioinformatics—15th International Workshop, WABI 2015, Atlanta, GA, September 10–12, 2015.
38.
QiJ., WangB., and HaoB.-I.2004. Whole proteome prokaryote phylogeny without sequence alignment: A k-string composition approach. J. Mol. Evol., 58, 1–11.
39.
SleatorD.D., and TarjanR.E.1981. A data structure for dynamic trees, 114–122. STOC: Proceedings of the Annual ACM Symposium on the Theory of Computing.
40.
ThankachanS.V., ChockalingamS., LiuY., et al.2015. A greedy alignment-free distance estimator for phylogenetic inference. 5th IEEE International Conference on Computational Advances in Bio and Medical Sciences, 2015.
41.
UlitskyI., BursteinD., TullerT., and ChorB.2006. The average common substring approach to phylogenomic reconstruction. J. Comput. Biol., 13, 336–350.
42.
Van HeldenJ.2004. Metrics for comparing regulatory sequences on the basis of pattern counts. Bioinformatics, 20, 399–406.
43.
VingaS., and AlmeidaJ.2003. Alignment-free sequence comparison—A review. Bioinformatics, 19, 513–523.
44.
WeinerP.1973. Linear pattern matching algorithms, 1–11. 14th Annual IEEE Symposium on Switching and Automata Theory.
45.
WuT.-J., BurkeJ.P., and DavisonD.B.1997. A measure of DNA sequence dissimilarity based on mahalanobis distance between frequencies of words. Biometrics, 53, 1431–1439.
46.
ZuckerkandlE., and PaulingL.1965. Molecules as documents of evolutionary history. J. Theor. Biol., 8, 357–366.