
Abstract
Abstract
The Smith-Waterman algorithm has a great sensitivity when used for biological sequence-database searches, but at the expense of high computing-power requirements. To overcome this problem, there are implementations in literature that exploit the different hardware-architectures available in a standard PC, such as GPU, CPU, and coprocessors. We introduce an application that splits the original database-search problem into smaller parts, resolves each of them by executing the most efficient implementations of the Smith-Waterman algorithms in different hardware architectures, and finally unifies the generated results. Using non-overlapping hardware allows simultaneous execution, and up to 2.58-fold performance gain, when compared with any other algorithm to search sequence databases. Even the performance of the popular BLAST heuristic is exceeded in 78% of the tests. The application has been tested with standard hardware: Intel i7-4820K CPU, Intel Xeon Phi 31S1P coprocessors, and nVidia GeForce GTX 960 graphics cards. An important increase in performance has been obtained in a wide range of situations, effectively exploiting the available hardware.
1. Introduction
G
Nowadays, heuristics such as the Basic Local-Alignment Search Tool (BLAST) (Altschul et al., 1990) are widely used for this purpose, because of its accuracy and relatively low execution-time. However, BLAST does not always provides the most accurate results (Shpaer et al., 1996). Indeed, recent implementations of optimal brute-force algorithms, such as the Smith-Waterman (SW) (1981) pairwise alignment with affine gaps (Gotoh, 1982), achieve near the same performance as heuristics by taking advantage of misused sources of computing-power available in stand-alone personal computers (PC), such as graphics cards, coprocessors, and multi-core microprocessors. Nonetheless, little effort has been made to integrate the simultaneous usage of these hardware in order to exceed heuristic performance in real-life benchmarks (Steinfadt, 2013; Rucci et al., 2014; Sluga et al., 2014).
Several implementations exploit the current multi-core and multi-thread microprocessors, as well as the internal set of MultiMedia eXtension (MMX) and Streaming Single-Instruction Multiple Data (SIMD) Extensions 3 (SSE3) instructions to achieve real parallelism and to increment performance. In addition to the early implementations of Wozniak (1997), Rognes (2001), and Farrar (2007), which only use the SIMD advantages, Rognes (2011) introduced a different parallel approach to exploit the available microprocessor resources. Thus, it executes many alignments in parallel, using an inter-task approach and Message Passing Interface (MPI) (Gropp et al., 1994), achieving a performance that can exceed BLAST under certain conditions.
On the other hand, the architecture of graphics processing units (GPU) adapts pretty well to the SW algorithms, so using graphics cards to execute them has received much attention from researchers (Schatz et al., 2007; Manavski and Valle, 2008; Liu et al., 2013). Thus, implementations such as Double Affine Smith-Waterman (DASW) (Liu et al., 2006), Manavski's (Manavski and Valle, 2008), Ligowski's (Ligowski and Rudnicki, 2009) and Compute-Unified Device Architecture Smith-Waterman Plus Plus (CUDASW++) (Liu et al., 2013) have progressively increased GPU performance by exploiting new architecture features and programming models: GPU libraries, CUDA, CPU-GPU hybrids, as well as Parallel Thread eXecution and Instruction Set Architecture (PTX ISA), respectively. Indeed, most recent implementations can exceed BLAST performance, albeit at the expense of using costly graphics cards and complex CPU–GPU hybrid approaches.
Coprocessors have been traditionally used to complement main microprocessors in mathematical operations. Fortunately, the recent introduction of Peripheral-Component Interconnect Express (PCIe) coprocessor cards have enhanced such an approach. They include TILExpress-20G from Tilera (Bell et al., 2008), Multi-Purpose Processor Array (MPPA)-256 from Kalray (de Dinechin et al., 2013), and Xeon-Phi with Many-Integrated Core (MIC) architecture from Intel (Jeffers and Reinders, 2013). They have effectively added more cores and memory to computers, as a way to increase their overall performance. Several efforts have been made to implement the SW algorithm in these cards, as we have demonstrated with Multicore64-NeedlemanWunsch/SmithWaterman (MC64-NW/SW) (Gálvez et al., 2010), and others with Smith-Waterman Algorithm on Intel Xeon Phi (SWAPHI) coprocessors (Yongchao and Schmidt, 2014).
Additionally, more general implementations deal with clusters of coprocessors and CPU-coprocessor hybrid systems, such as Bulk Synchronous-Parallelism Plus Plus (BSP++) (Hamidouche et al., 2013) and Smith–Waterman implementation on Intel's Multicore and Manycore (SWIMM) (Rucci et al., 2014). In fact, hybrid programming is facilitated by offload programming models. They allow the transparent execution of particular blocks of parallel code in a coprocessor, whereas the main program is executed by the CPU. There are other implementations that rely on specific hardware. They include the Cell Broadband Engine (Chen et al., 2007) or Field-Programmable Gate Array (FPGA) boards, as well as complex networks of computers such as clusters of servers and distributed grids, but they are out of the scope of this study.
In this work, we introduce the Highly Heterogeneous Smith-Waterman (HHeterSW) algorithm, unifying the most efficient implementations of SW in a single environment. We have focused on readily available hardware for a stand-alone PC, as well as open-source code.
2. Materials and Methods
Standard hardware for research and development was used, including GeForce GTX 960 graphics cards (GPU) with 1024 Stream Processors Units (SPU; also known as CUDA cores at 1.127 GHz) from nVidia, as well as Xeon Phi 31S1P coprocessors (57 cores × 4 = 228 threads at 1.1 GHz), and Core i7-4820K CPU microprocessors (4 cores × 2 = 8 threads at 3.70 GHz) from Intel. On the other hand, several implementations of the SW algorithm were carefully chosen, according to the following criteria:
• No hardware-usage overlapping, taking into account that at least one thread of the main CPU must be used to control each attached hardware. • Standard hardware. • Compatibility between programs, drivers, and libraries. • Similar behavior and performance, when independently executed. • Open-source code.
The selected programs have been: i) SWAPHI (Yongchao and Schmidt, 2014) to be executed on Intel Xeon Phi 31S1P coprocessors; ii) the MPI version of Smith-Waterman database searches with Inter-sequence SIMD Parallelization Extension (SWIPE) (Rognes, 2011), to be executed in Intel i7-4820K CPU; and iii) CUDASW++ 2.0 (Liu et al., 2010) to be executed on the nVidia GeForce GTX 960 GPU. These programs have a peak performance of 42.43, 45.66, and 52.45 GigaCell-Updates per Second or GigaCUPS (GCUPS), respectively, when a search is executed into the Swiss Protein (Swiss-Prot; release 2015_09) protein database with the above-mentioned hardware. Other options such as CUDASW++ 3.0 or SWIMM have been excluded, because they focus on hybrid solutions that overlap CPU usage. Finally, the National Center for Biotechnology Information (NCBI) BLAST+ v2.2.31+ has been used for comparison purposes, and to prepare input data for SWIPE.
3. Results and Discussion
The database search problem must be partitioned into smaller parts, one for each program. Yet, it must be taken into account that the input-database file formats of the selected applications are incompatible. Thus, CUDASW++ uses Fast-Alignment Sequence Tools (FAST)-All (FASTA) files, whereas SWIPE requires the BLAST format, and SWAPHI works with its own database and index formats. Therefore, the database should be stored in all such formats, in order to use the three programs at the same time. Thus, FASTA files were transformed into both BLAST, by using the NCBI makeblastdb utility, as well as into SWAPHI, by using the index option provided by such program. Therefore, the database (or its indexes) were replicated three times in the database file system. Fortunately, this is easily done in current computers with storage disks of 1 TB or greater, albeit with the extra time overhead required for the format transformations. Table 1 shows the additional size and time taken to index the Swiss-Prot and Translated computer-annotated supplement of the database, containing all European Molecular-Biology Laboratory (EMBL) amino acid (aa) sequence entries not yet integrated in Swiss-Prot (TrEMBL) database.
Time represents the time taken to generate the database in the new format, being proportional to the size of the database. Size represents the percentage of the newly generated database, relative to the original FASTA). Complete TrEMBL cannot be managed by SWAPHI, and thus it was split into two equally sized pieces (sum of both are shown).
To alleviate these overheads of space and time, the FASTA database (instead of the query file) was split into three parts, further regenerating two of them for SWIPE and SWAPHI. The size of each partition depends on the computing power of the hardware used to execute each program. Several goals were achieved that way:
• Faster pre-processing of the FASTA database file. • Increased probability that the complete database file fits in the hardware memory (2 GiB in the GTX 960, 16 GiB in the i7, and 8 GiB in the Xeon-Phi). • Execution of a single splitting-stage for different searches over the same database, with different query files.
A Java program has been designed to integrate the calls to the selected programs and to gather the hits produced by them in the final step. Figure 1 shows the structure of such a program (HHeterSW). It shows the input data, options and parameters, the partitioned database generated, the execution flow among the main HHeterSW classes, the classes required to interact with the selected programs and, finally, the output result that includes both the hits and performance information.
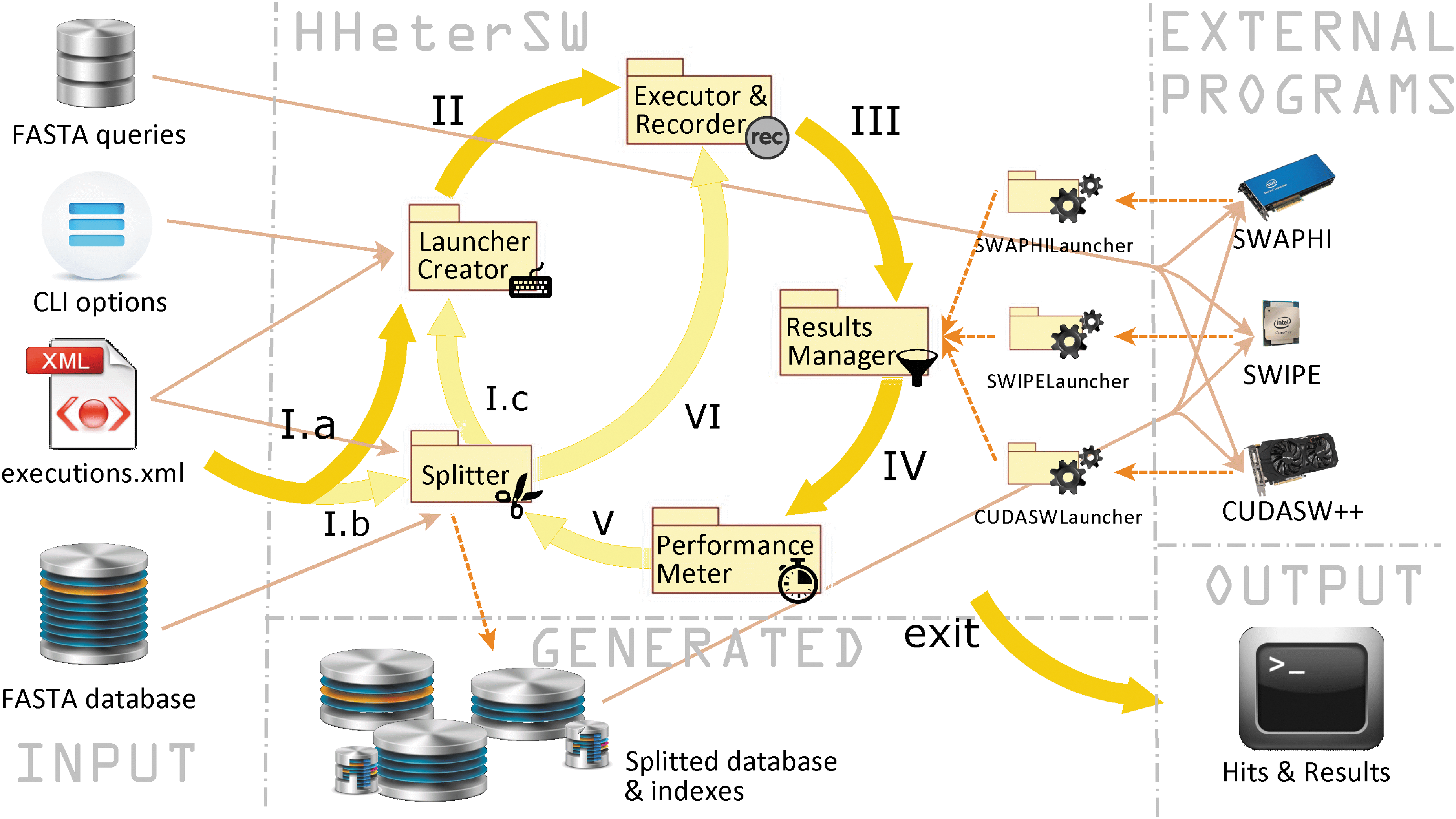
HHeterSW execution diagram. The main execution flow (I.a, II, III, IV, and exit) is marked as thick dark arrows. Thin solid arrows represent the input taken by each class and program, whereas dotted arrows correspond to the generated output. The produced output by each program (CUDASW++, SWIPE, and SWAPHI) is filtered by a specialized Launcher that is created by the Launcher Creator and executed by an Executor and Recorder. The hits already filtered are the input of the Results Manager, which produces a homogeneous set of hits. Finally, a Performance Meter displays the result, as well as useful information on execution times, on the console. A secondary execution flow (I.b, I.c, II, III, IV, V, VI, and so on) is shown as thick light arrows tuning up the partitioning percentages of the FASTA database through several loops.
Splitting the database (entry point I.b) may not be required. For instance, if different searches are executed against the same database, then it should be split only once, in the first search, because the generated files can be reused. In I.a (and in I.c, after the splitting operation), a Launcher Creator takes an executions.xml configuration file, and reads how many implementations must be executed; one per <algorithm> tag (Fig. 2). The user must adapt this text file to the hardware in use, including or removing <algorithm> tags. Thus, a program will not be executed if the corresponding hardware is missing. Alternatively, it will be launched as many times as cards available. The Creator replaces the gaps in the <<execution>> tag text, to adapt the input options of HHeterSW to those of each particular program. Following Figure 2, if HHeterSW is called with the −d example.fasta parameter, the Creator will replace [-d|-db ]_0.out with −db example.fasta_0.out. Once the execution command line is built, the Creator generates an instance of the class specified in the launcherClass attribute, which will be in charge of the execution of every algorithm, in order to extract the hits information from its standard output.
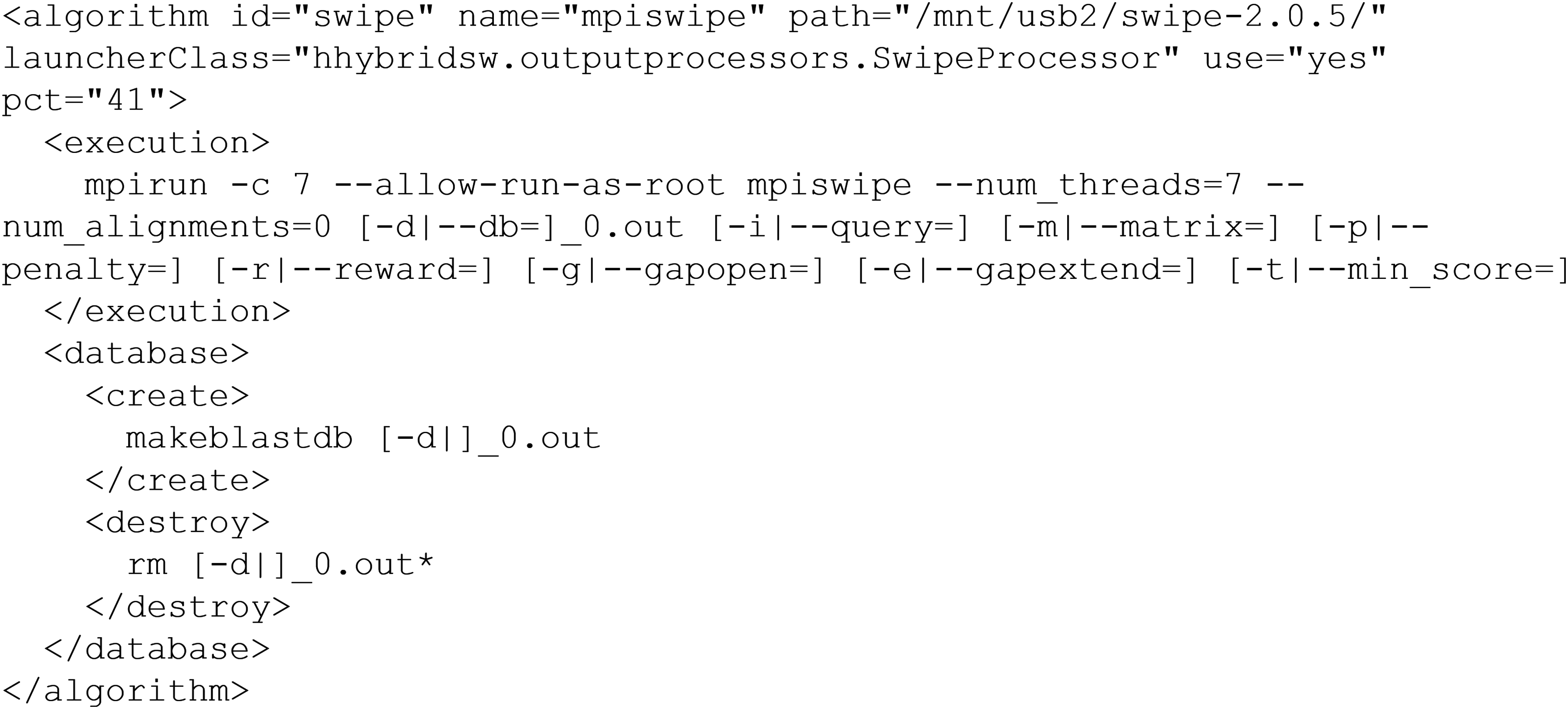
Excerpt of executions.xml. Description of how HHeterSW deals with the SWIPE program.
The execution.xml file is also used when the sequence database must be split. Two steps are followed to create the partitioned databases. In the first one, the FASTA database is divided into pieces whose size is given by the pct attribute, which indicates the percentage of the database that shall be managed by each particular program. The generated pieces are stored in sequentially-numbered files: example.fasta_0.out, example.fasta_1.out, and so on. In a second step, the commands under the <database> tag are used to generate (and destroy) the final database and indexes, once the original one is partitioned. Figure 2 shows that SWIPE requires makeblastdb to generate its database, and the option [-d|]_0.out shows that this is the first program (position 0) in the file executions.xml. After transition II, an Executor runs in parallel the particular Launcher of each program that, in turn, runs in a transparent way its associated application: CUDASW++, SWIPE and SWAPHI. All the hardware resources are fully used at this point. The standard output and error are recorded, and useful information on performance and execution time is registered.
Once every program has finished, after transition III, each Launcher extracts from its record the hits information produced by its program. Then, a Results Manager integrates all these results into a single and homogeneous set of hits, making transparent to the final user the program that has originated each result. Finally, after transition IV, a Performance meter takes the whole set of hits, calculates relative execution-times and displays these results on the console, thus finishing the program. Apart from this, HHeterSW can be used to affine the percentage of the original database that must be given to each program. In this case, the Performance meter calculates a new set of percentages, whose purpose is that the execution of every simultaneous program takes the same amount of time. In this case, control is given again to the Splitter in transition V, a new splitting operation is executed (using the newly computed percentages, instead of the ones in executions.xml). Then, control is passed to the Executor in step VI (avoiding to create the launchers again). This loop can be executed several times, to fine-tune the partitions percentages as much as possible (option −s num_loops).
Several experiments have been carried out to test HHeterSW performance, by varying three variables: score matrix (BLOSUM50, BLOSUM62, and BLOSUM80), query length, and database length. Changes in the score matrix revealed a minor impact in most executions, though the performance of the tests with BLOSUM50 showed an unstable behavior when applied to long proteins. Figure 3 shows the performance when a list of query sequences of increasing length [the proteins used by Rognes (2011)] were searched in Swiss-Prot using the BLOSUM62 matrix. Partition of 54%, 34%, and 12% for CUDASW, SWIPE, and SWAPHI were used, respectively. The BLAST+ performance when using the same hardware resources has been included for comparison purposes. Figure 3 shows that BLAST+ outperforms HHeterSW in only seven of the 32 tests. It must be noted that BLAST+ performance is highly affected by the score matrix used (see supplementary material).
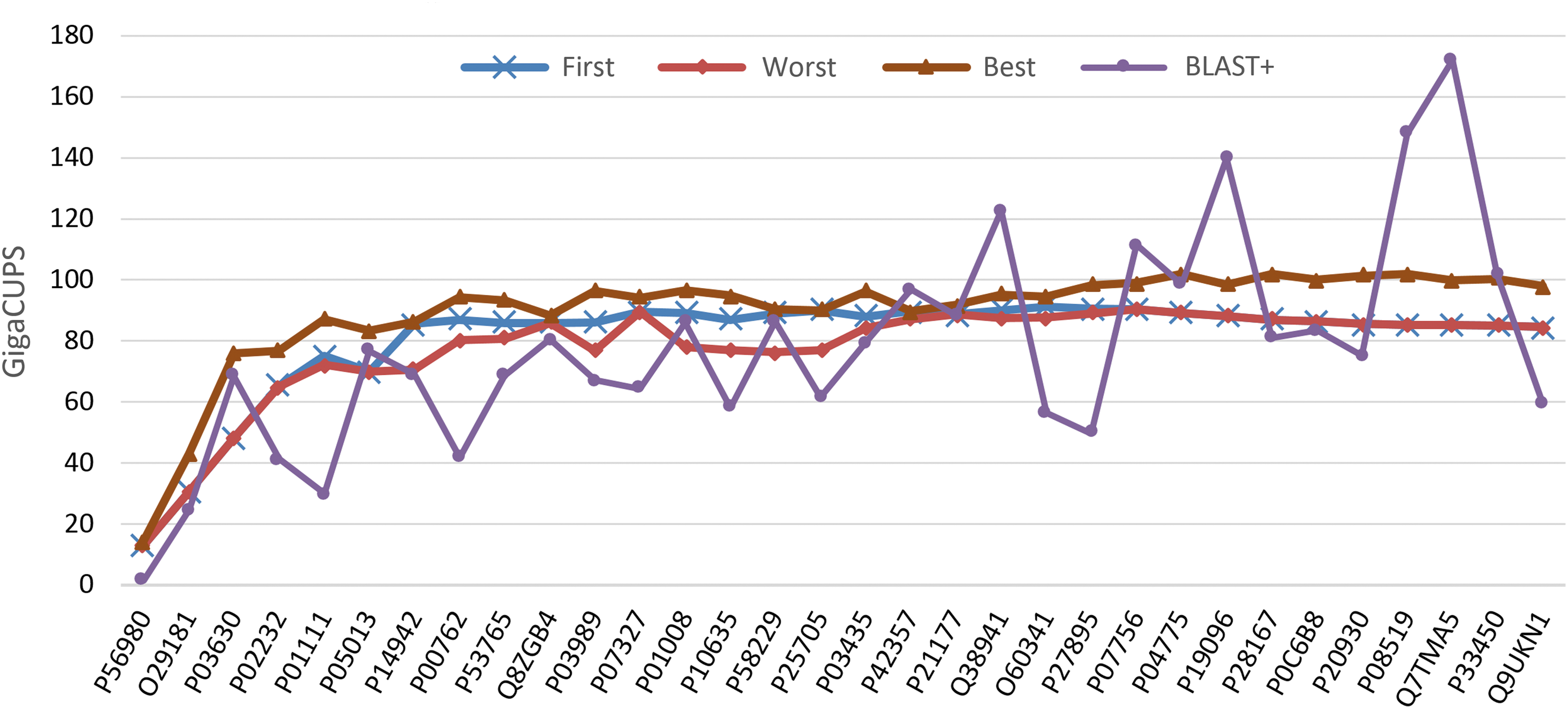
HHeterSW Performance. The BLOSUM62 score matrix and a list of proteins of increasing size were used. It exceeded 40 GCUPS with the P03630 protein, which has 191 amino acid residues, stabilizing at around 90 GCUPS with the P07327 protein (511 aa). Starting with the P07756 protein (1,725 aa), the initial 54%, 34%, and 12% partitions (CUDASW++, SWIPE, and SWAPHI) behaved the worst. BLAST+ performance is also shown for comparison.
The above mentioned partition was selected after a preliminary set of tests with Swiss-Prot, using proteins with median length taken from (Brocchieri and Karlin, 2005), corresponding to eukaryotic, bacterial, and archaeal organisms: Arabidopsis thaliana (P43295.2), Haemophilus influenza (WP_015701954.1), and Thermoplasma acidophilum (WP_048161637.1). Ten executions were launched for each protein. The first five converged into a good partition by using the modifier −s 5. The final five used the same good partition to test the stability of HHeterSW; the best and worst performance series of them are shown in Figure 3. The difference between these two series were mainly due to the latency in memory transfers in SWAPHI, as well as memory contention between SWAPHI and SWIPE. The average performance achieved by HHeterSW in the best case was ∼89 GCUPS.
On the other hand, Figure 4 shows the performance gain in GCUPS achieved by HHeterSW when compared to the selected algorithms executed separately. CUDASW++ 2.0 was the one that most contributed to the HHeterSW performance, mainly when short queries were used. However, the performance provided by the algorithms becomes similar when increasing the size of the query.
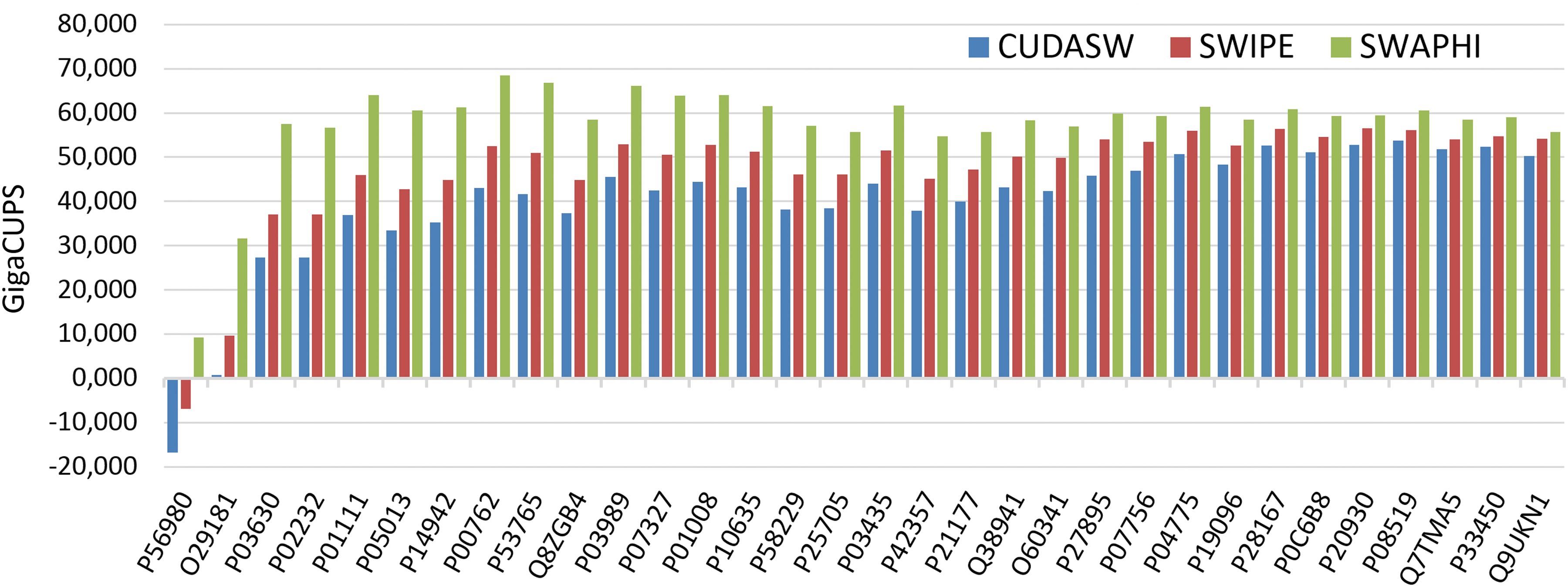
HHeterSW gain of performance. Swiss-Prot and a list of query proteins of increasing length were used to compare executions of CUDASW++, SWIPE, and SWAPHI.
The HHeterSW behavior when applied to databases of different lengths was tested by using portions of TrEMBL, with an increasing size from 16 Mega amino acids (Maa) to 8 Giga amino acids (Gaa). In addition, given that the performance depends on the length of the query sequence, queries with representative lengths (both short and long) were used: P03630 (191 aa), P07327 (511 aa), P07756 (1,725 aa), and P28167 (3,211 aa). The obtained results showed a notable peak performance of 139.65 GCUPS when the longest protein was searched in a database of 1 Gaa length, using a partition of 39%, 26%, and 35% (Fig. 5). In general, the best performance was achieved when the database length was in the range 512 Maa–2 Gaa and the query sequence was large (up to 4 Gaa in the case of short queries). Clearly, executing a SW algorithm on such a range of big databases requires a high computational power and takes a long time. Hence, it greatly benefits from the high performance gained by HHeterSW. The partitions used in these executions ranged from 60%, 28%, 12% (query P03630 against a 512 Maa database) to 35%, 33%, 32% (4 Gaa database); see Figure 6.
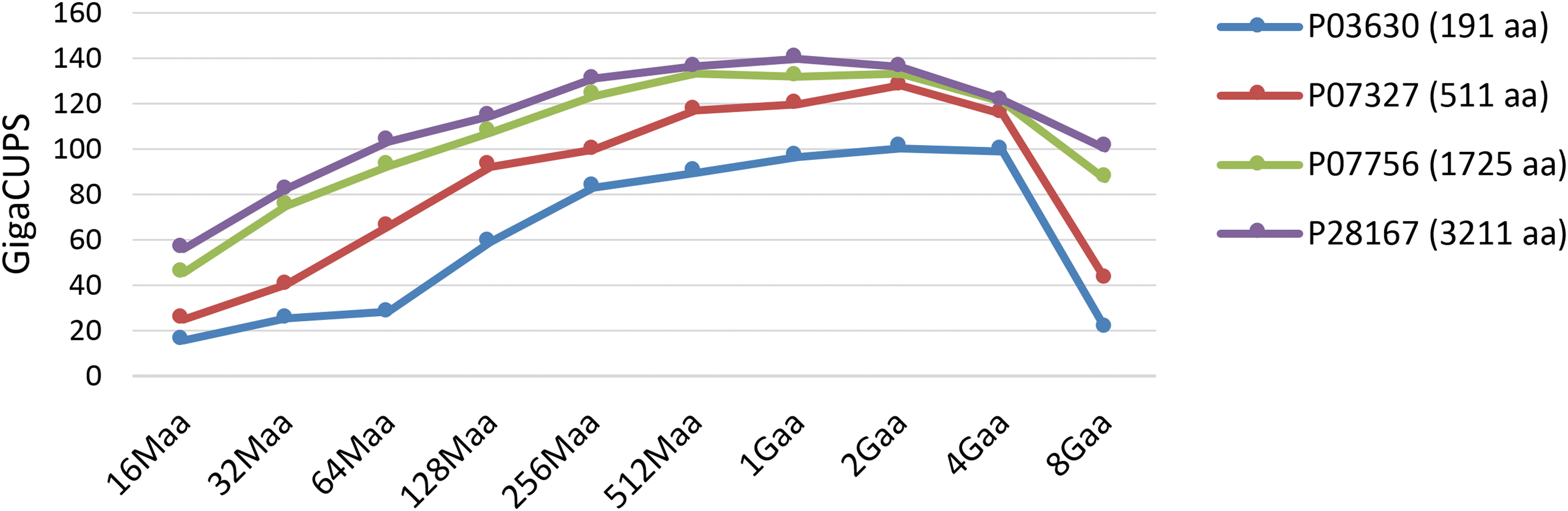
HHeterSW performance with different query sizes. A range of 16 Maa to 8 Gaa database lengths were used.
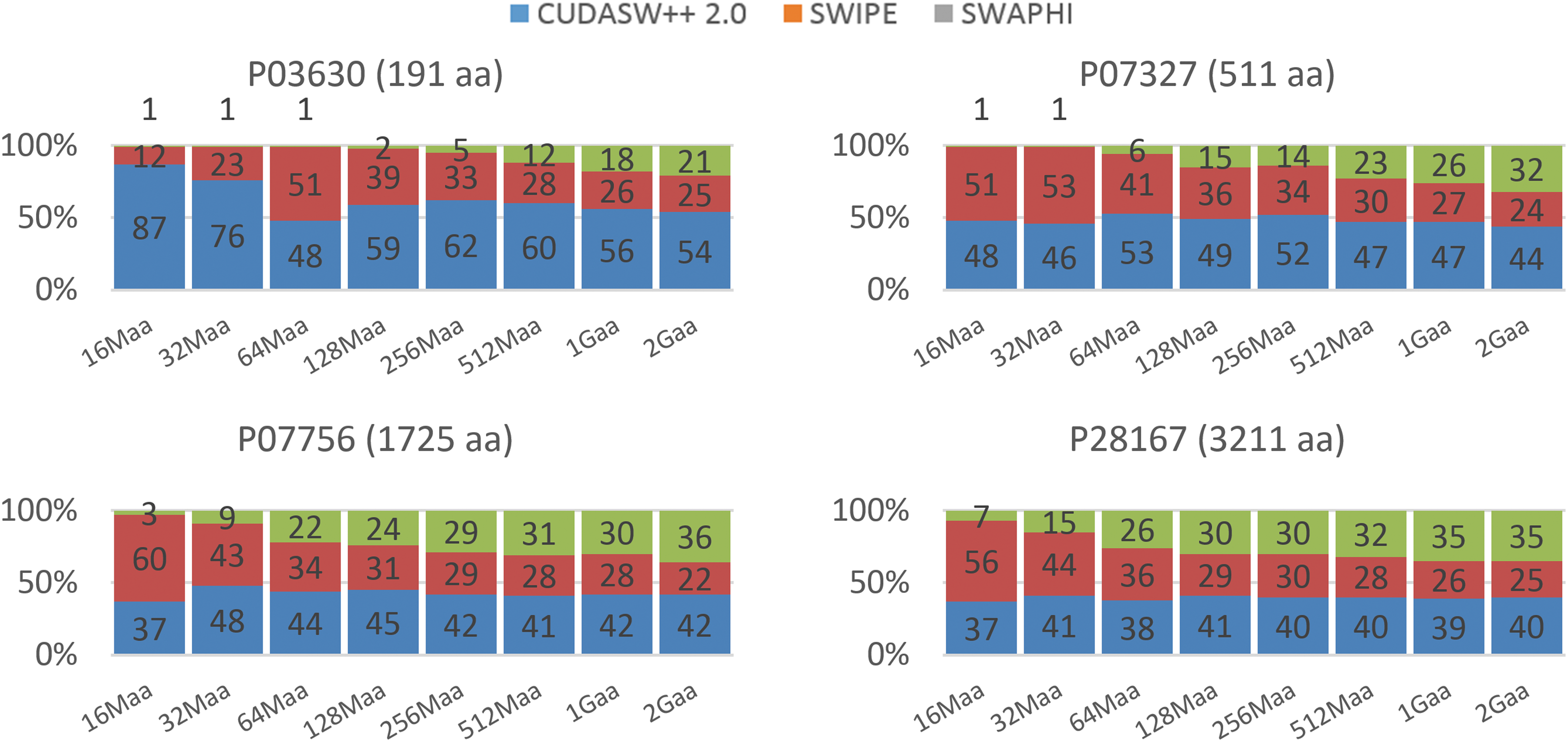
HHeterSW partitions on databases and queries of different lengths. Partition percentages to achieve the maximum performance in HHeterSW were dependent on the database size and query length.
Unfortunately, HHeterSW cannot assign to CUDASW++ a database partition whose size is bigger than ∼1.5 Gaa (the GTX 960 graphics card has just 2 GiB of memory) and, therefore, the partition used in the 4 Gaa database has had to be set to 35%, 33%, and 32% (and to 18%, 37%, and 55% in a 8 Gaa database). The rest of partitions used to obtain the results of Figure 5 are shown in Figure 6. Because of the CUDASW++ limitation, and due to the performance penalty with very-large databases, the complete TrEMBL database (16 Gaa) was not used. A comparison among Figure 5 and the performance of each selected algorithm when individually executed (see Supplementary Figs. S1 and S2; supplementary material is available online at www.liebertpub.com/cmb) reveals that HHeterSW performance was up to 2.58-fold higher than any of them in the case of a database of 1 Gaa size and long queries, and up to 2.12-fold in the case of short queries.
Finally, to verify the consistency of these results, we searched for 100 Swiss-Prot random proteins in the full TrEMBL database. To do this, the TrEMBL FASTA file (∼16 Gaa) was divided into eight files of ∼2 Gaa length, and the proteins were independently searched in each block. HHeterSW achieved a performance of 113.59 GigaCUPS using a partition of 44%, 24%, and 32%, which is consistent with the previous results, taking into account that the median size of the proteins in Swiss-Prot is 292 aa.
4. Conclusions
The HHeterSW tool allows taking the most from all available hardware when using the Smith-Waterman algorithm. It can be considered a coarse-grained heterogeneous approach. We have tested algorithms developed for widely used hardware, though HHeterSW is flexible enough to give support to any other existing hardware, provided a SW implementation is available for it (FPGA, Cell Broadband Engine, etc.). In addition, CUDASW++ 2.0, SWIPE, and SWAPHI may be substituted by most efficient solutions, as they become available. As an example, a new release of CUDASW++ 3.0 could be tested on the Maxwell architecture of the GTX 960.
The three selected algorithms provide a similar throughput in GCUPS when executed on the tested hardware. The performance increment converges to 3x (we achieved up to 2.58x) on optimal balance-load. Clearly, the percentages of the partitions must be carefully chosen in order to obtain good results. Any researcher may test the performance of any other implementation, including commercial and open source ones, offload Xeon Phi solutions, or hybrid CPU-GPU algorithms, just by including a new launcher in the HHeterSW architecture.
Footnotes
Acknowledgments
Supported by Ministerio de Economía y Competitividad (MINECO Grants AGL2010-17316 and BIO2011-15237-E) and Instituto Nacional de Investigación y Tecnología Agraria y Alimentaria (MINECO and INIA RF2012-00002-C02-02); Consejería de Agricultura y Pesca (041/C/2007, 75/C/2009 and 56/C/2010), Consejería de Economía, Innovación y Ciencia (P11-AGR-7322 and P12-AGR-0482), and Grupo PAI (AGR-248) of Junta de Andalucía; and Universidad de Córdoba (Ayuda a Grupos), Spain.
Author Disclosure Statement
No competing financial interests exist.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.