
Abstract
Abstract
We developed the cloud-based MOTIFSIM on Amazon Web Services (AWS) cloud. The tool is an extended version from our web-based tool version 2.0, which was developed based on a novel algorithm for detecting similarity in multiple DNA motif data sets. This cloud-based version further allows researchers to exploit the computing resources available from AWS to detect similarity in multiple large-scale DNA motif data sets resulting from the next-generation sequencing technology. The tool is highly scalable with expandable AWS.
1. Introduction
T
Existing tools such as STAMP (Mahony and Benos, 2007), TOMTOM (Gupta et al., 2007), MATLIGN (Kankainen and Loytynoja, 2007), CompariMotif (Edwards et al., 2008) and existing methods in Habib et al. (2008) and Xu and Su (2010), among others, for finding motif similarity do not allow extracting common significant motifs from more than two data sets concurrently. To compare more than two data sets, pairwise comparisons need to be performed first. The results are then checked against each other manually. This time-consuming process is manageable only for small data sets or for a few data sets. However, when the number of data sets increases or the size of a data set increases, the comparison rapidly becomes impractical. This difficulty led to the development and the initial releases of the command-line MOTIFSIM tool and the web-based MOTIFSIM tool (Tran and Huang, 2015)—both based on a novel algorithm for detecting similarity in multiple DNA motif data sets simultaneously. These are the first-ever tools developed for this purpose. In this work, we developed the cloud-based MOTIFSIM on Amazon Web Services (AWS) cloud (Amazon Web Services, 2006). This is an extended version from our web-based tool version 2.0 to further support detecting similarity in multiple large-scale DNA motif data sets generated from the next-generation sequencing technology.
Many cloud service providers such as AWS, Google cloud (2008), Microsoft Azure (2008), and Rackspace (1998) offer various services, including the elasticity for computing resources, unconstrained data storage, and powerful computing resources, among many others. AWS is the most popular one among these vendors and its services are most relevant for supporting our tool. We exploit these services to further assist researchers in finding similarity in large DNA motif data sets. The cloud-based MOTIFSIM provides users more online storage space for data sets and results. It accepts various input formats generated from several different motif detection tools. Users can use the tool with or without registration. Registered users can keep the data sets and results online for an extended period. Users can use existing data sets, upload data sets, or insert data sets on the browser to run the tool. Currently, it allows detecting similarity in as many as twenty DNA motif data sets simultaneously. The input formats can be mixed and matched. The tool can automatically detect the format for each motif. Since motifs produced by several different motif finding tools for the same data set vary significantly, our tool can assist users to identify common significant motifs and their best matches as well as to provide users the best matches for each motif for further analysis.
Users can filter motifs by selecting different input/output parameters, select as many as fifty top common significant motifs, and pick as many as fifty best matches to be created for each motif for analysis. In addition, users can specify the similarity between two motifs and designate the type of output to be created and the preferred output file format. Registered users are notified by e-mails for receiving of submitted data sets and when the results are available for download and viewing. All users can check the status of a submitted job on the Job Status page at the tool's website. The results reported to users include the combined motifs from all data sets, the global significant motifs, the global and local significant motifs, as well as best matches for every motif in each data set (Tran and Huang, 2015). The global significant motifs are top common significant motifs with their best matches from different data sets. The global and local significant motifs are top common significant motifs with their best matches from different data sets or within a data set. The results can be generated in HTML, PDF, Text, or in all three formats. The conversion of HTML to PDF is performed by using Prince software package (Prince, 2002). The sequence logos for each motif and its reverse complement are generated using WebLogo software package (Crooks et al., 2004). The results presented to users include two sections: Input and Results. The Input section includes input parameters and data set information. The Results section consists of three subsections for the global significant motifs, the global and local significant motifs, and best matches for each motif. Figures 1–4 show the Input and Results sections in HTML format.

Input section of the results. Input parameters, file names, and motif counts are included.
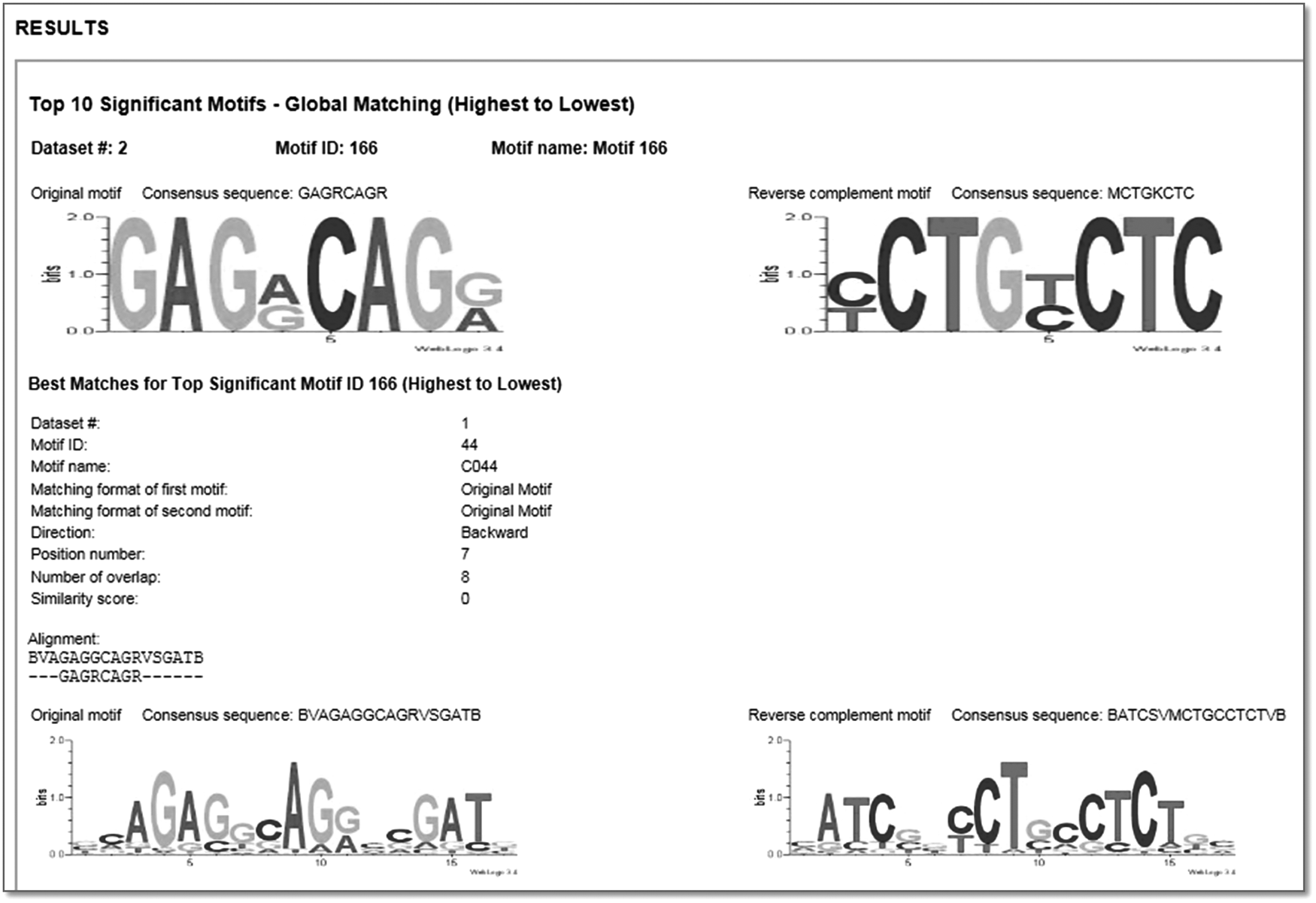
Subsection reports the global significant motifs. Top global significant motifs and their best matches are listed in descending order of similarity. Motif information and matching details are included.
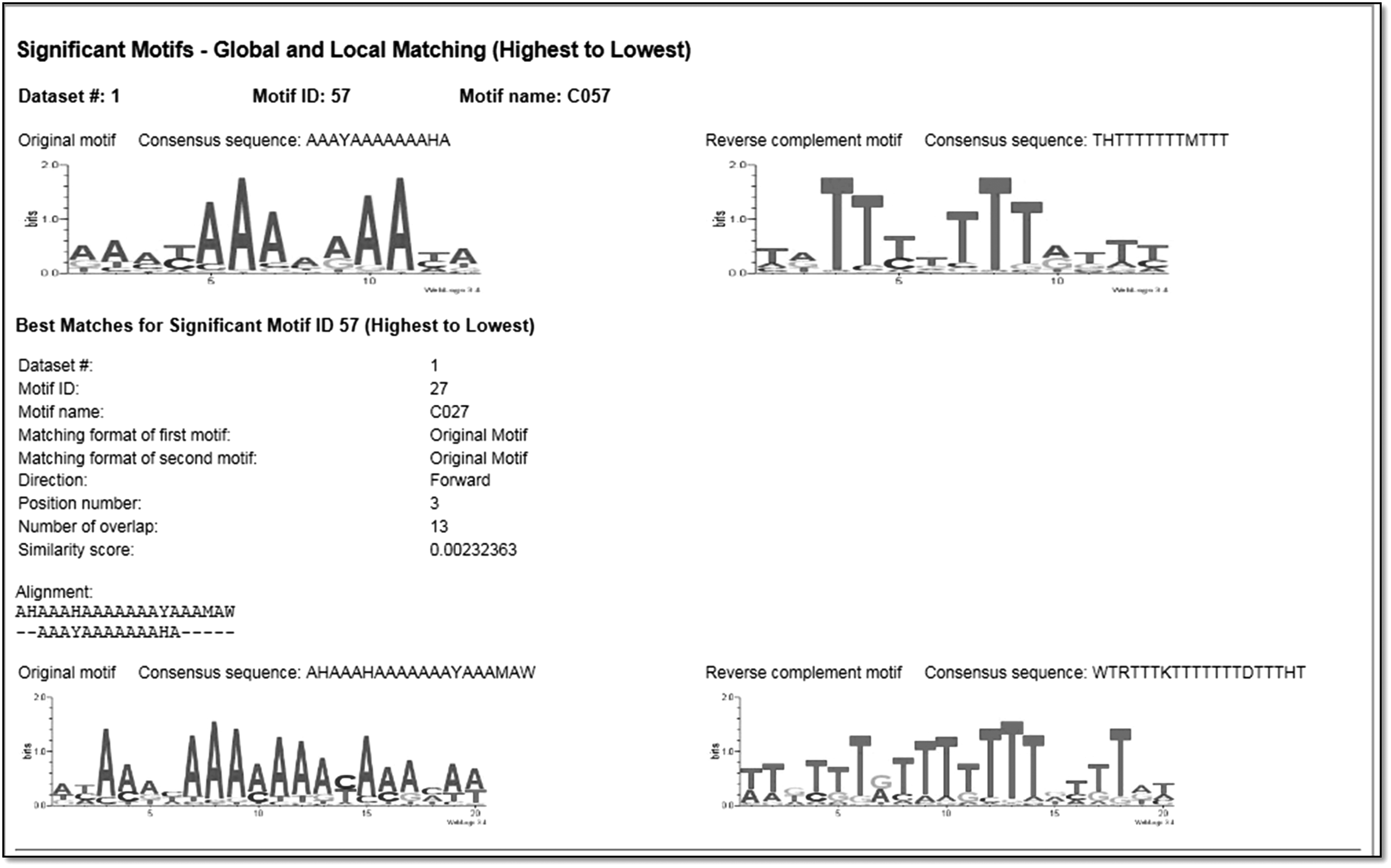
Subsection reports the global and local significant motifs. Top global and local significant motifs and their best matches are listed in descending order of similarity. Motif information and matching details are included.
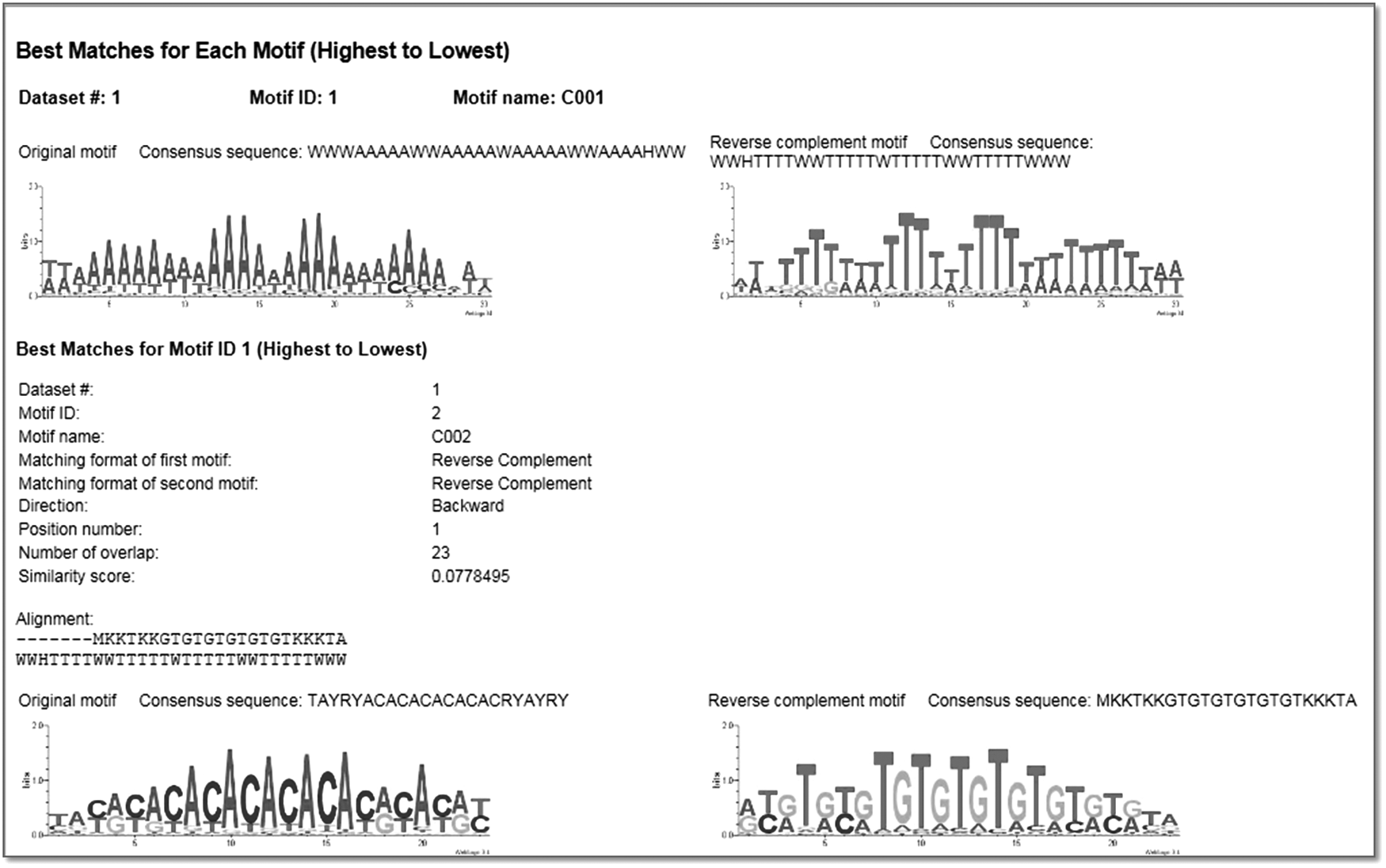
Subsection reports best matches for each motif. Motifs are listed by data sets and in the order the data sets are entered. Best matches for each motif are listed in descending order of similarity. Motif information and matching details are also included.
2. Materials and Methods
2.1. Algorithm
The web-based MOTIFSIM implemented a novel algorithm (Tran and Huang, 2015) for detecting similarity in multiple DNA motif data sets concurrently. In this extended cloud-based version of our web-based tool, we improved steps 4 and 5 of the original algorithm by allowing flexibility for choosing q number of top significant motifs. Since this improvement does not affect the overall quality of the original algorithm, we do not reassess the algorithm here as it has been evaluated in Tran and Huang (2015). The algorithm, including the improvement in steps 4 and 5, can be found in the Supplementary Materials.
2.2. Implementation
AWS provides various services, including computing, storage, content delivery, database, networking, management tools, security and identity, and application services (Amazon Web Services, 2006). All current services provided by AWS as of this writing can be found in Supplementary Figure S1. The computing service offers the Elastic Compute Cloud (EC2) (Amazon EC2—Virtual Server Hosting, 2006) instances, which are virtual servers for building our tool's infrastructure. We utilize Amazon Simple Storage Service (Amazon S3) (2006) for backup of our application and database. We use MySQL from the database service for our back-end database. The web address of cloud-based MOTIFSIM was provided by Amazon Route 53 Domain Name System web service (Amazon Route 53, 2011). In addition, we implemented the AWS Identity and Access Management (IAM) service (AWS Identity and Access Management, 2006) to manage user's access to the tool. We also use Amazon SES (2011) to provide e-mail notifications to users for their submitted jobs and the results. Our tool's infrastructure was built and managed by using AWS OpsWorks, which is a configuration management service that allows configuring and operating applications using Chef (AWS OpsWorks Documentation, 2013).
The cloud-based MOTIFSIM was deployed on an AWS OpsWorks Linux application server stack with three layers, as shown in Figure 5 (AWS OpsWorks Documentation, 2013). The details for AWS OpsWorks and application server stack can be found in the Supplementary Materials. Each layer in the stack can be set up and managed independently. The layer can have as many instances as needed to handle the traffic or workload. AWS OpsWorks provides horizontal scaling as well as scaling up or down features to allow each layer to respond to a dynamic environment (AWS OpsWorks Documentation, 2013). The elastic load balancer layer of the tool runs on an EC2 t2.micro instance at the baseline and can be scaled up to a higher capacity instance. HAProxy (HAProxy—The Reliable, High Performance TCP/HTTP Load Balancer, 2015) is used in this layer to balance incoming traffic. AWS provides various EC2 instances with different capacities and prices. All current EC2 instances provided by AWS as of this writing can be found in Supplementary Table S1.
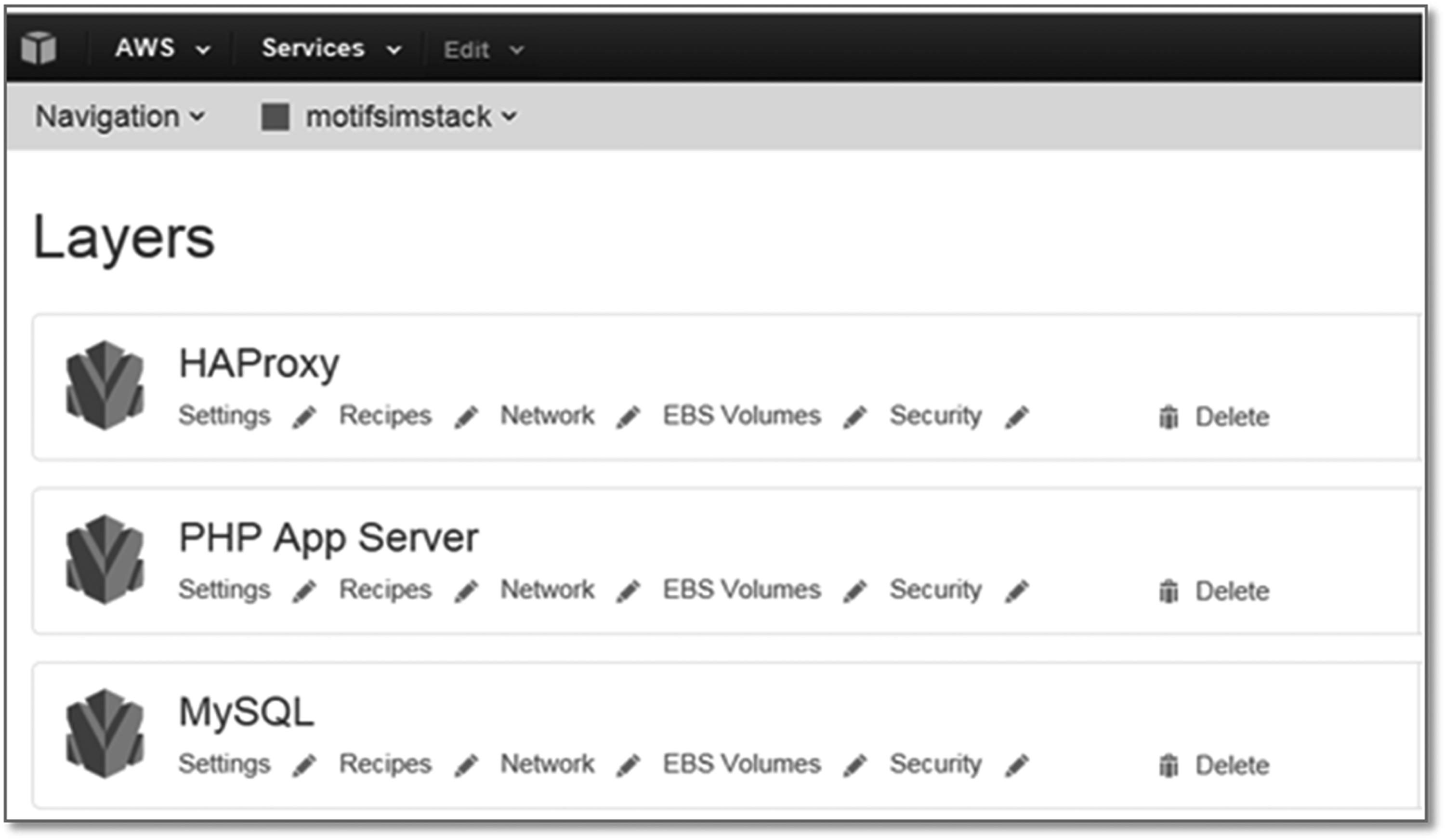
The three layers of the cloud-based MOTIFSIM stack. the elastic load balancer layer containing HAProxy load balancer; the application server layer containing PHP application servers; and the Amazon relational database server (RDS) layer containing MySQL. Each layer can be set up and managed independently (AWS OpsWorks Documentation, 2013).
To find the most relevant instances for running our PHP application server layer, we tested several instances of different types, including general purpose, compute optimized, and memory optimized instances. We found the EC2 r3 memory optimized instances are most relevant to our PHP application server layer. The results are presented in the Results and Discussion section. The master node in this layer runs on an EC2 r3.large instance, while the worker nodes run on EC2 r3.8xlarge instances. The database layer runs on an EC2 t2.micro instance at the baseline and can be scaled up to a higher capacity instance. We used Amazon CloudWatch to monitor EC2 instances to better respond to web traffic and workload via CloudWatch notifications (Amazon CloudWatch Documentation, 2010). The details for Amazon CloudWatch can be found in the Supplementary Materials. The front-end of the cloud-based MOTIFSIM was implemented in CSS, HTML, and JavaScript. Its back-end was implemented in PHP, SQL, and C++ with OpenMP for multithreading.
3. Results and Discussion
3.1. Data sets
We evaluated the cloud-based MOTIFSIM on various single and combined motif data sets of different sizes produced by different motif detection tools, including CisFinder (Sharov and Ko, 2009), DREME (Bailey, 2011), MEME-ChIP (Machanick and Bailey, 2011), PScanChIP (Zambelli et al., 2013), and RSAT peak motifs (Thomas-Chollier et al., 2012). The data sets are organized into groups 1–9 in Table 1. Those within a group were produced by different motif detection tools for the same peak data set, which was created from the ChIP-Seq data that came from ChIP-Seq experiment.
Each group can have a single or multiple data sets. Data in groups 1–5 came from experiments in Tran and Huang (2014).
PSSM, position-specific scoring matrix.
Groups 1–5 were created from trimmed peak data sets in the experiments described in Tran and Huang (2014) as some motif detection tools accept limited peak data set size. They are single data sets of substantial sizes and combined data sets required for evaluating the tool. To acquire larger data sets, we used full peak data sets produced by the MACS (Zhang et al., 2008) peak caller using the procedure described in Tran and Huang (2014). These full peak data sets came from three ChIP-Seq data sets generated by the experiments in Shen et al. on mouse liver tissue for histone H3 lysine 4 monomethylation (H3K4me1), insulator binding protein (CTCF), and histone H3 lysine 27 acetylation (H3K27ac) (Shen et al., 2012). The ChIP-Seq data sets can be found in Table 2.
The data sets were generated from ChIP-Seq experiments on mouse liver tissue (Shen et al., 2012).
We ran CisFinder on the full peak data sets as this tool accepts large data sets and produces a large number of motifs. Groups 6–8 came from these full peak data sets. Group 9 is a combination of data sets from different groups, so that it allows forming a large combined data set containing 20,534 motifs used for evaluating the tool as well as for finding the most suitable EC2 instances for supporting the PHP application server layer.
3.2. Results
We ran experiments on data in groups 1–9 using various EC2 instances, including general purpose, compute optimized, and memory optimized instances as shown in Table 3. These instances range from medium to high capacity. The runtimes were collected for different groups on different instance types. Supplementary Table S2 shows the runtimes for groups 1–9 on several instance types. The graph in Figure 6 compares the runtimes between different EC2 instance types for groups 1–9. The EC2 r3.8xlarge instance is capable for processing large data sets, while other instances were not able to complete the large jobs. Hence, the EC2 r3.8xlarge instance is the most suitable instance for supporting our PHP application.
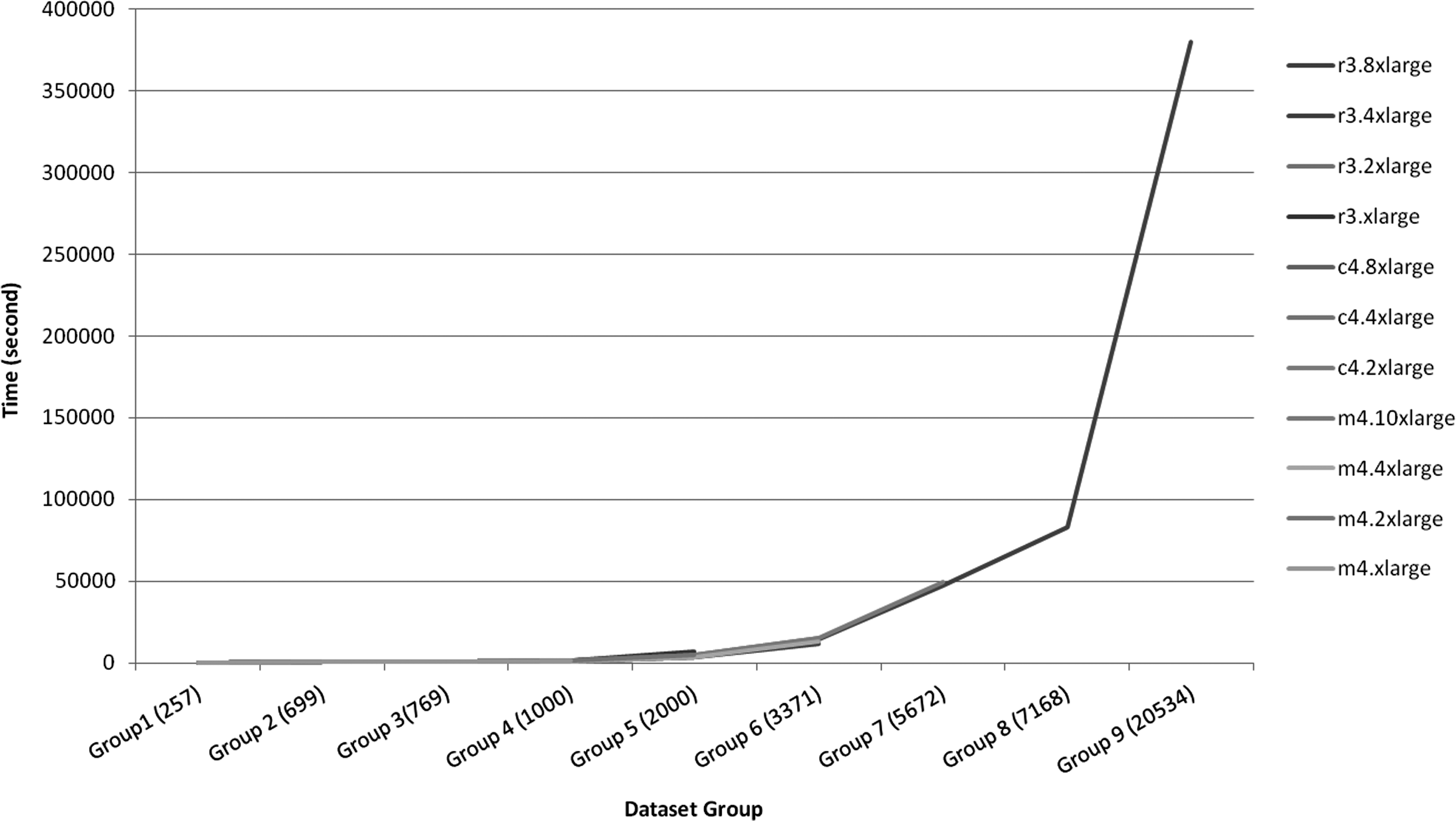
Runtime comparison between different EC2 instance types for groups 1–9. The number in parentheses indicates the total number of motifs within a group. The EC2 r3.8xlarge instance is capable of handling large data sets.
Instance property and price provided by AWS are included as of this writing.
The experimental results showed that the memory optimized instance types are the most pertinent for the tool, as large data sets require a more powerful EC2 instance with a considerable amount of memory and several virtual CPUs to process the massive comparisons. The EC2 r3.8xlarge instance shows this capability for processing large data sets in groups 6–9.
3.3. Comparison of runtimes between the web-based MOTIFSIM and the cloud-based MOTIFSIM implementations
To evaluate the performance of the cloud-based MOTIFSIM over the web-based MOTIFSIM, we compared the runtimes between both tools on three groups of data sets in Tran and Huang (2015). Each group in Tran and Huang (2015) consists of multiple motif data sets. We previously evaluated our web-based tool using these groups of data sets (Tran and Huang, 2015). Our web-based tool is powered by a Linux cluster of Apache web servers. Each Apache web server node consists of 4 cores and 8 GiB of memory. Since we use the EC2 r3.8xlarge instance for our PHP application, this instance is more powerful than the Apache web server node supporting the web-based tool. Thus, the performance of the cloud-based MOTIFSIM was expected to be higher than the web-based tool on these groups of data sets. We ran the cloud-based MOTIFSIM on these groups of data using the same input parameters as previously used in (Tran and Huang, 2015). As expected, the runtime is over two times faster than the web-based tool, as shown in Table 4 and in Figure 7. The performance of the cloud-based tool is obviously higher than the web-based tool but it is not substantial in terms of memory and the number of cores comparing to the web-based tool since these data sets are small. However, for larger data sets, it is expected to show a substantial higher performance than the web-based tool.
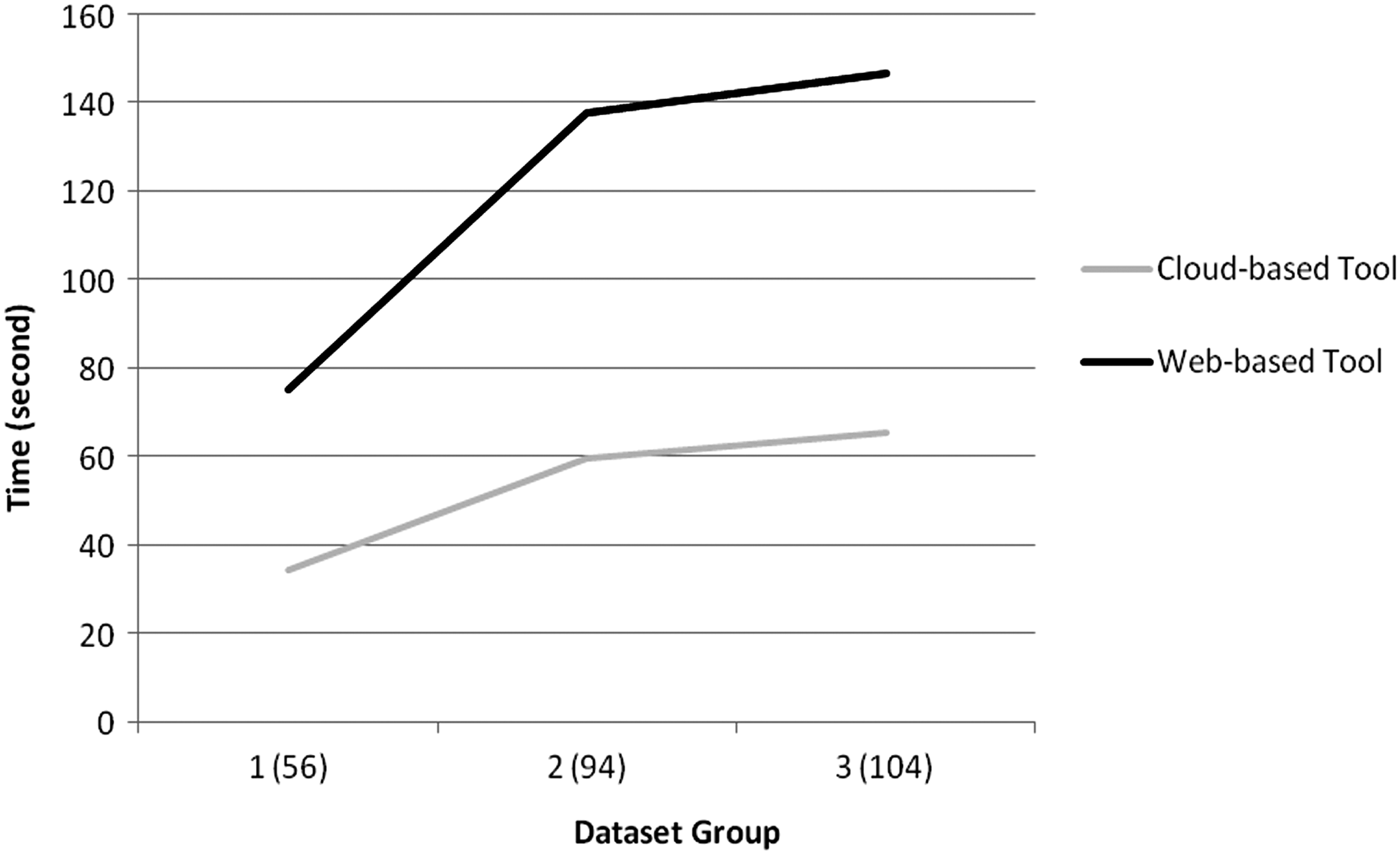
Comparison of runtimes between the web-based MOTIFSIM and the cloud-based MOTIFSIM for data groups 1–3 in Tran and Huang (2015). The number in parentheses indicates the total number of motifs within a group. The experiment was run on a Linux Apache web server node and on an EC2 r3.8xlarge instance. Same input parameters were used for both tools.
Input parameters are included.
3.4. Discussion
Different motif detection tools report different results for the same peak data set. The data sets in group 1 were produced by five different motif detection tools. The number of motifs reported differs from one tool to another. CisFinder obviously reported many more motifs than other tools. Thus, it is helpful to know which motifs these tools commonly reported. The global significant motifs identified by our tools are such motifs. The cloud-based MOTIFSIM can identify these motifs in large multiple DNA motif data sets. The top ten global significant motifs for group 1 can be found in Supplementary Table S3. In addition, the tool provides users the global and local significant motifs reported by any motif finder. Furthermore, it provides the best matches for every motif in each data set for users to analyze any motif.
4. Conclusions
The cloud-based MOTIFSIM inherits all features of its web-based tool. The application server layer of the tool is leveraged by the latest EC2 r3 memory optimized instances. The worker node runs on an r3.8xlarge instance, which has 32 virtual CPUs and 244 GB of memory, to allow massive comparisons on large data sets. The tool can be scaled out to handle heavy traffic and workload. Its capability can be expanded as AWS constantly offers better services, including latest technologies to the users. The cloud-based MOTIFSIM is the first and currently only tool to allow finding similarity in large single or multiple DNA motif data sets simultaneously with its unique features. The tool was designed to further assist researchers in using the latest and powerful computing resources available from AWS (see first Reference for availability).
Footnotes
Acknowledgments
This work was supported, in part, by the National Science Foundation (NSF) (Grant OCI-1156837 to C-HH) and the U.S. Department of Education Graduate Assistance in Areas of National Need (GAANNs) (Grant P200A130153 to NTLT). The cloud services are supported by AWS in Education Research Grant Award to NTLT.
Author Disclosure Statement
The authors declare that no competing financial interests exist.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.