
Abstract
Abstract
1. Introduction
G
Rich trait structure arises from constraints in the physical world such as that time moves forward and is smoothly varying, or that the correlation between positions on the genome is slowly decreasing according to genetic distance on the chromosome. Modeling approaches in these settings should take into account such constraints while still allowing for flexibility in the shapes of the traits. Furthermore, it stands to reason that the genetic effect might alter the functional form of a trait, such as the shape of a growth curve, a pattern of weight gain, bone loss, or electrocardiogram signal. Thus, flexible modeling beyond linear genetic effects is also one of our goals. Figure 1 shows a set of simple canonical traits and genetic effects that we would like to be able to detect. These canonical traits will also serve as the basis of our synthetic experiments for comparing the behavior of several modeling approaches. In these examples, by design, a genetic effect that is constant or linear in time will fail to properly model the data. Although these traits are rather idealized, they present a good starting point with which to examine the problem.

Simulated traits with 100 time points taking on values uniformly spaced between 0 and 12. Each plot shows what the mean (noise-free) trait looks like for each of the SNP values 0 (blue), 1 (green), and 2 (red). The noise added (not shown) is iid with respect to both time and individuals. Note that we here display the maximum genetic effect for each kind of trait for visual clarity. SNP, single-nucleotide polymorphism.
The simplest problem we might tackle in our chosen setting is to find out which individual single-nucleotide polymorphisms (SNPs) are correlated to the trait of interest, a so-called marginal test. Those that are correlated are then assumed to have a reasonable probability of being causal for the trait, or of tagging a nearby SNP that is causal for the trait. Although it is also of interest to test sets of SNPs jointly (Wu et al., 2010; Listgarten et al., 2013; He et al., 2015), we here focus on marginal SNP testing, leaving a generalization to set tests for future work. The solution to this marginal testing problem entails (1) proposing a statistical model of the data and (2) obtaining some weight of evidence of a genetic effect such as a p value or Bayes factor. In this work, we focus primarily on the first task, but discuss our future directions for the second task in concluding.
Numerous approaches for analyzing function-valued genetic associations have been proposed in recent years (Zhang, 1997; Kendziorski et al., 2002; Smith et al., 2010; Das et al., 2011; Furlotte et al., 2012; Wang, 2012; Chung and Zou, 2014; Ding et al., 2014; Musolf et al., 2014; He et al., 2015; Jaffa et al., 2015; Shim and Stephens, 2015; Sikorska et al., 2015). However, these do not necessarily make effective use of the rich trait structure to increase power because they often assume restrictive forms of the genetic effect or the trait itself. Also, in some cases, the statistical efficiency does not scale well with the number of time points, which are expected to be quite numerous in the settings discussed earlier. Next we give a brief overview of some of these approaches and their weaknesses in tackling the kinds of problems we are interested in.
Sikorska et al. use an approximate linear mixed model that accounts for correlation in time and assumes that a trait evolves over time in a linear manner; they also assume that the SNP effect itself is additive. Musolf et al. first cluster the trait without accounting for genetics and then seek genetic effects on the cluster labels, thereby presupposing that all causal SNPs segregate the traits in a similar manner. Shim et al. first apply a wavelet transform to the trait data, thereby transforming the traits to lie in a coordinate system based on (hierarchical) scales and locations; they then perform association testing in this new space. Although this approach enables flexible functions of time to be modeled, the SNP effects are restricted to be linear because the wavelet transform itself is linear. Das et al. construct a different Legendre polynomial-based model to model the trait for each test SNP allele, learning each model in a largely independent manner. They then test whether the time-specific mean effects are different between the alleles, although it is not clear how they combine time points in their statistical testing framework. Also note that Das et al. remove SNPs with minor allele frequency (MAF) less than 10% from their experiments because the MAF dictates the amount of data available to each allele-specific model. Finally, there has been some related work on detecting differential expression using Gaussian process (GP) regression that shares many aspects of our approach, while differing in several respects, including parameter sharing, independence among individuals, and substantial differences in time complexity in the case of aligned time points, partly owing to the use of a different noise model and inference algorithm (Stegle et al., 2010).
In our work, we propose an extremely flexible approach for modeling function-valued traits with genetic effects. In particular, our approach, based on GP regression with a radial basis function (RBF) kernel (Rasmussen and Williams, 2005) at its core, can in principle capture any smoothly varying trait in time, where the smoothness is controlled by a “length scale” parameter. This length scale parameter is estimated using maximum likelihood, thereby effectively deducing the complexity of the trait functional form directly from the data. As for the genetic effect, similarly to Das et al., our model has three components corresponding to three partitions of the data, yielding an extremely nonrestrictive class of genetic effects because the GP for each allele can look completely different from the other alleles when no parameters are shared. In our experiments, we assume that basic properties such as the noise level and length scale are likely to be common to all alleles and hence tie these parameters together for more efficient statistical estimation. However, the model need not be used in this manner. Furthermore, because the RBF kernel effectively integrates out the time points, the number of model parameters does not scale with the number of time points, but is instead fixed—a desirable property when many time points are observed. We call our model the Partitioned GP for partitioned GP regression.
2. Partitioned Gaussian Processes
As already mentioned, our model uses at its core GP regression (Rasmussen and Williams, 2005), a class of models that encompasses linear mixed models, the more widely used concept in genetics (Yu et al., 2006; Kang et al., 2008; Listgarten et al., 2010; Lippert et al., 2011). The GP regression literature contains results not typically found in the genetics community that we make use of, including the use of RBF kernels and Kronecker product-based refactorizations of matrix-variate normal probability distributions, yielding computational efficiencies (Stegle et al., 2011) in the case of aligned and nonmissing time points. Also, although we have not yet implemented it, by virtue of using the GP machinery, we can immediately access variational approximations to reduce computational time complexity (Quiñonero Candela and Rasmussen, 2005; Titsias, 2009) in the case of missing data or unaligned time points. We now formally introduce our null model, followed by an exposition of how to do efficient computations in it before introducing the alternative model and computation of p values.
2.1. Null model
Our null model, M0, assumes that the SNP has no effect on the trait (and so does not enter the model), but does capture correlation in time by way of an RBF kernel. Let
Then
where
The RBF kernel models the dependence in time, whereas the identity kernel models the remaining environmental noise. Note that the RBF kernel here models not only correlation between time points within an individual but also equally across individuals. That is, we make the assumption that the trait at time point t is more correlated across individuals i and j than between time points t and
An example in which this might be a reasonable assumption would be growth curves in which on average the curves look the same for a species, but with a particular mutation the, curve suddenly changes trajectory. An example in which this is an unreasonable assumption would be unaligned electrocardiographic signals in which no two people would in general look the same at time t unless their signals had been rescaled and aligned. When the assumption of correlation in time between individuals is not believed to be reasonable, we can easily remove this restriction from the model, leaving time correlations only within an individual. In fact, as we explain in the next section, it is algebraically and computationally trivial to make such a change while retaining all efficient computations. However, by removing this assumption from the model, we lose statistical power if the assumption is actually valid in the data. In fact, when conducting our synthetic experiments, we found that removal of this assumption in the model substantially weakened the results (data not shown).
Note that for simplicity, we assume that covariates such as age and gender have been regressed out of the trait ahead of time, although these could easily be incorporated into the model, by way of the Gaussian mean (i.e., fixed effects). All remaining expositions (other than for the pseudo-inputs and variational inference) can be readily extended to having covariates directly included with no change to the computational time complexity. We make a similar assumption about population structure and family relatedness, which can be regressed out using either principle components (Price et al., 2006) or linear mixed models (Lippert et al., 2011), although investigating the best way to do this for function-valued traits is an open area for investigation. Finally, in Equation 1, we did not assume that traits for each person were measured at the same time points or that no trait values were missing. However, in the next section on efficient computations, we will need to make this assumption. In Section 2.4 we outline ways to relax this assumption.
We need to perform efficient computation of the likelihood in order to obtain a p value for each genetic marker. Computing the maximum likelihood over and over again for each hypothesis is a nontrivial goal in the sense that general kernel-based methods have time complexity that scales cubically in the dimension of the kernel (here NT), and space complexity that is quadratic in that dimension. However, in some cases, structure in the kernel can be leveraged to gain substantial speedups [e.g., Lippert et al. (2011)]. For Partitioned GPs, such structure arises when there is no missing data and all traits are measured at the same time points for all individuals. In this case, the likelihood can be rewritten with Kronecker products in the covariance term, yielding dramatically reduced time and space complexities. Later we discuss how to achieve speedups in the face of missing or unevenly spaced time points using the Partitioned GP, which can require some approximations, whereas the present exposition requires no approximation.
The RBF kernel (dimension
where here we have overloaded
It is also easy to generalize this expression and its derivative when the mean of the Gaussian is nonzero; we do so to make one of the models we compare against (Furlotte et al., 2012) significantly faster than in their original presentation (they could not do the same because they jointly model population structure) (Furlotte et al., 2012).
Note that the individuals are not identically and independently distributed (iid) in our null model because of the term
As described earlier, we have assumed that population structure and family structure have already been accounted for, but these could instead be incorporated into the model by adding to
For parameter estimation, we use gradient descent to obtain the maximum likelihood solution in parameters
2.2. Alternative model
Now that we have fully described the null model and how to efficiently compute its log likelihood, we generalize this model to an alternative model that handles a wide range of genetic effects. To do so, we create a separate GP for each partition of the data, in which the partition is defined by the alleles of the test SNP (using whatever encoding of the data we desire, such as a
where S denotes the number of alleles in the SNP encoding,
The same efficient computations outlined earlier for the null model can just as well be applied to this alternative model, and so the time complexity of computing the alternative model likelihood has as an upper bound that of the null model, which happens only when all individuals are assigned to the same partition. Note too that the null model can be computed just once and then cached across all SNPs tested for increased efficiency.
Beyond data sharing across partitions by virtue of shared parameters, the model has good statistical efficiency owing to the fact that GPs operate in the kernel space (Rasmussen and Williams, 2005) where the number of parameters does not depend on the number of time points. All in all, we find in our experiments that as few as seven samples per partition appear to be sufficient, which with cohort sizes in the tens if not hundreds of thousands impose little restriction on the MAF.
2.3. Hypothesis testing
Standard frequentist hypothesis testing uses a null model that is nested in the alternative model, which then allows us to use a LRT or score test, for example. However, even when models are nested, these tests require that model assumptions are met, and typically that sample sizes are large enough for asymptotics to be valid. In cases in which model or asymptotic assumptions are unmet, we can appeal to various forms of permutation testing to obtain calibrated p values. Because our models are not nested, we cannot rely on standard theories to compute p values, and could therefore turn to permutation testing. However, as it turns out, when we apply a standard
The precise way in which we apply a standard
2.4. Handling traits with missing data or that are unevenly sampled across individuals
In a model with a vector Gaussian likelihood, such as Equation 1, missing trait data can readily be handled by simply removing any rows with missing data, because this procedure is equivalent to marginalization in a Gaussian (Rasmussen and Williams, 2005). In such a manner, if using Equation 1, we could take T to be the number of uniquely observed time points across all individuals, even if many individuals were missing many of these time points. This procedure could also capture the case in which different individuals were measured at different time points. However, in the Kronecker version of the likelihood written for computational efficiency gains (Equation 2), we can no longer perform this arbitrary marginalization by simply removing an element of the phenotype vector, because with the Kronecker-factorized covariance matrix, we would have to either remove all individuals missing a time point, or all time points missing an individual. Therefore, if we want both computational efficiency and a means to readily marginalize over missing data, we must appeal to alternative formulations and/or approximations.
The approach we propose is to keep the Gaussian likelihood in vector form, as in Equation 1, but to augment the model with latent inducing inputs (Quiñonero Candela and Rasmussen, 2005; Titsias, 2009), which are points in time (or space, depending on the type of trait) that are included in the model. Inducing inputs can be thought of as pseudo-observations in time (or space) that are included in the RBF kernel inputs; when conditioned on, these pseudo-observations make any observed data conditionally independent of each other. This has the effect of reducing the time complexity from
3. Results
As discussed in the introduction, many models have been developed to perform genome-wide association studies with function-valued traits. However, these models tend to have constraints on the type of genetic or time effect that can be recovered (e.g., only constant or linear effect in time, or only linear in the SNP), or are limited to relatively few time points because the number of parameters scales with the number of time points. For our experiments, we have chosen a set of baseline models to test particular hypotheses about which kinds of models work and where they fail, in the settings we care about—in particular, exploring what happens when there are a large number of time points such as would be collected by wearables and other sensors. The models we compare and their short-hand notation are as follows.
1. Partitioned GP: as described earlier, using the (exact) Kronecker product implementation.
2. Furlotte et al.: a linear mixed model in which correlation in time is modeled using an autocorrelation kernel (here we use an RBF as we do with our Partitioned GP), and in which in the alternative model, the SNP is a fixed effect, shifting the trait at all time points by the same amount (Furlotte et al., 2012). A standard LRT is used for the one-degree-of-freedom test. Note that we here do not use the population structure kernel used in Furlotte et al. (2012) as our experiments are not affected by such factors.
3. Inverse linreg: To examine how models for which the number of parameters increases with the number of time points, we use inverse linear regression model, wherein the SNP is modeled as the dependent variable and each trait in time is an independent variable. Testing is done with a
4. Inverse K score: This model can be viewed as a Bayesian equivalent to Inverse linreg, in which the time effects are integrated out, yielding a linear mixed model. In this way, the model does not depend on the number of time points. We then apply a score test to obtain a p value [e.g., Wu et al. (2010)].
We systematically explore each of these approaches on simulated phenotypic data in which we know the ground truth, examining type 1 error control, power, and ability to rank hypotheses regardless of calibration. We based our simulated data on the actual SNPs in the CARDIA data set (dbGaP phs000285.v3.p2), which, after filtering out individuals missing more than 10% of their SNPs, any SNPs missing more than 2% of individuals, or with MAF less than 5%, left 1441 individuals with 540,038 SNPs. The only covariate we use is an offset, which we regress on as a preprocessing step before applying the models.
To simulate time-varying traits, we used a set of canonical functions that were representative of the types of signal we were interested in exploring. In particular, we used a wave, linear, bias, and a stretch as shown in Figure 1. For null data, we generated noisy versions of these, in which the noise was iid in time and individual. For non-null data, we modified the noise-free trait in a smoothly varying way as a function of genotype before adding iid noise. For the wave (a sin wave), the amplitude increased as a linear function of the SNP; for the line (a straight line), the slope changed as a linear function of the SNP; for the bias, the horizontal intercept changed as a linear function of the SNP; and for stretch (a sin wave), the frequency changed as a linear function of the SNP. We varied both the SNP effect intensities and the amount of noise. We can summarize the strength of the SNP effect at each time point by the fraction of variance explained by the genetic signal at each time point (i.e., the variance of the noiseless trait divided by total variance, all at a given time point) as shown in Figure 4. Because we were interested specifically in seeing which models could handle many time points, we conducted experiments with 10, 50, 100, and 150 time points.

Power curves as a function of time for all methods. Vertical axis represents the median
Our first goal was to establish whether our Partitioned GP controls type 1 error so that we could use its p values at face value for power comparisons, even if they are not calibrated. First we used 8000 tests at each of 10, 50, 100, and 150 time points, finding that the smallest number of time points (10) was always the least conservative (Fig. 2). Therefore, we ran much larger scale simulations of null-only data for 10 time points, obtaining 390,272 test statistics. With just under half a million tests, we had resolution to check for control of type 1 error up to a significance level of

Paired plot of the
Fraction of p values less than that threshold, with absolute numbers in parentheses.
Having established that our method controls type 1 error, we next set out to see whether it had more power to detect associations than the other methods. Figure 3 shows the median test statistic for both our null (lower plot) and non-null (upper plot) experiments, and demonstrates that our methods have maximum power for the traits and methods chosen. Because our type 1 error control experiments only went down to

Average fraction of variance accounted for by genetics at each time point in each canonical function over the range of settings used, for the traits with 100 time points.

Power curves as in Figure 4, but separated by trait types shown in Figure 1. *Again, as noted in the main text, the numerical routine used to get p values for Inverse K score does not yield numeric values less than around
Note that the inverse kernel score test appears to have extremely poor power. However, this plot is perhaps misleading in the sense that this method uses a numerical routine (Davies method) that has limited precision, yielding many 0's for tiny p values (usually those smaller than
Figure 5 shows the ROC curves for each method, where we now see that the inverse kernel score test performs extremely well, although not as well as the Partitioned GP. Note that inverse linear regression, although showing inflated test statistics in the lower panel of Figure 3, here demonstrates that it maintains the ability to properly rank the hypotheses from most to least significant, although again, not as well as the Partitioned GP. Note that the performance of the model by Furlotte et al. is not terribly surprising because it is only able to capture shifts in the mean of the functional trait, whereas our simulation scheme is deliberately testing richer SNP effects.
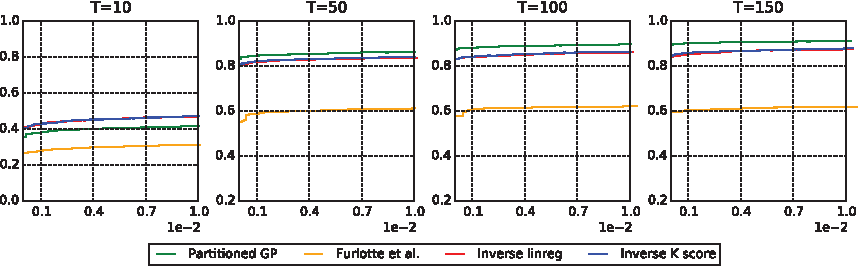
ROC curves for the simulated data with T equal to 10, 50, 100, and 150 time points, for small false positive rates (<0.01). The vertical axis represents the false positive rate and the horizontal axis the true positive rate. ROC, receiver operating characteristics.
4. Discussion
We have introduced a new method for performing GWAS on function-valued traits. Our model is extremely flexible in its capacity to handle a wide range of functional forms. This flexibility is achieved by using a nonparametric statistical model based on RBF GPs. Computations in this model are efficient when time points are aligned and traits are not missing, here scaling only cubically with the number of time points as opposed to cubic in the product of number of time points times individuals, as would be the case in a naive computation. We have also outlined how to do efficient computations even in the presence of missing trait data or unaligned samples. In a comparison against three other models on synthetic data, each with different characteristics and ways of handling the problem, we achieved maximal power, and maximal ability to discriminate null versus alternative tests as judged by an ROC curve. Our model is especially good at handling traits with many time points.
One downside of the model as presented is that the null model is not nested inside the alternative model, making computation of calibrated p values without permutations most likely impossible. We were able to bypass this issue by demonstrating empirically that naive application of a likelihood ratio test controls the type 1 error, yielding extremely conservative p values. However, we are currently investigating a version of the Partitioned GP model that has its null model nested in the alternative model and is, therefore, likely to yield calibrated p values and, therefore, potentially a larger power gain. In this model, the partitions of the alternative model are all placed within a single Gaussian, with correlation parameters for each pair of alleles dictating how similar the GP for each allele should be. When these parameters are equal to 1, we obtain the present alternative model. When these parameters are 0, we obtain the null model, thereby making it nested inside of the alternative. Other directions of interest are to extend this type of modeling approach to testing sets of SNPs rather than only SNPs, and to incorporate model-based warping of the phenotype so as to coerce the data to better adhere to the Gaussian residual assumption (Fusi et al., 2014).
Footnotes
Acknowledgments
We thank Leigh Johnston, Ciprian Crainiceanu, Bobby Kleinberg, and Praneeth Netrapalli for discussion, the anonymous reviewers for helpful feedback, and Carl Kadie for allowing use of his HPC cluster code. Funding for CARe genotyping was provided by NHLBI, contract N01-HC-65226.
Author Disclosure Statement
N.F. and J.L. are employees of Microsoft.