
Abstract
Abstract
1. Introduction
A
The GRN inference problem involves the discovery of complex regulatory relationships among biological molecules that can describe diverse biological functions and also the dynamics of molecular activities. Once the network is recovered, intervention studies can be conducted to control the dynamics of biological systems aiming to prevent or treat diseases (Shmulevich and Dougherty, 2014). Genes and proteins usually form an intricate complex network where often the behavior of a given gene, measured by means of its expression level (i.e., mRNA abundance), depends on a multivariate and coordinated action of other genes and their by-products (proteins) (Martins et al., 2008). Thus, GRN inference based on gene expression data analysis requires robust methods and algorithms, and new approaches are constantly under evaluation. The importance of GRN reconstruction can also be seen through many initiatives, such as the project DREAM (Dialogue for Reverse Engineering Assessments and Methods) (Marbach et al., 2012).
There are two main approaches to gene interaction modeling (Shmulevich and Dougherty, 2014): the continuous one and the discrete one. A continuous approach considers mainly differential equations to obtain a quantitative detailed model of biochemical networks (De-Jong, 2002; Hecker et al., 2009). Although continuous models provide a detailed understanding of the system, they require prior information about the kinetic parameters and a large number of experimental samples (Hecker et al., 2009). On the contrary, discrete models measure the gene interactions from a qualitative point of view. Popular discrete models include those based on graphs such as Bayesian networks (Friedman et al., 2000), Boolean networks (BNs) (Kauffman, 1969), and their stochastic versions, probabilistic Boolean networks (PBN) (Shmulevich et al., 2002) and probabilistic gene networks (PGNs), a PBN model with some constraints (Barrera et al., 2007). Discrete models can capture the overall behavior of system dynamics, requiring less data to be built and being easier to implement and analyze (Hecker et al., 2009). Discrete modeling has been successfully used in analysis and simulation of a myriad of biological networks, such as those for Drosophila melanogaster (Sánchez and Thieffry, 2001; Albert and Othmer, 2003), yeast cell cycle (Li et al., 2004; Zhang et al., 2006; Davidich and Bornholdt, 2008), Arabidopsis thaliana (Espinosa-Soto et al., 2004), mammal cell cycle (Faure et al., 2006), and Plasmodium falciparum (Barrera et al., 2007).
GRN inference is an ill-posed problem: for a given data set of gene expression profiles, there are many (if not infinite) networks capable of generating the same data set. This problem is further hampered due to the typically limited number of samples, the huge dimensionality (number of variables, i.e., genes), and the presence of noise (Hecker et al., 2009; Shmulevich and Dougherty, 2014). There is a vast literature dealing with the GRN inference problem (Bansal et al., 2007; Markowetz and Spang, 2007; Hecker et al., 2009; De-Smet and Marchal, 2010; Marbach et al., 2012). Some examples of methods that deal with this problem include entropy-based feature selection (Liang et al., 1998; Lopes et al., 2014), relevance networks (Margolin et al., 2006; Faith et al., 2007), feature selection by maximum relevance/minimum redundancy (Meyer et al., 2007; Hira and Gillies, 2015), and signal perturbation (Ideker et al., 2000; Carastan-Santos et al., 2017), among others.
In the specific context of discrete models, BNs and PBNs can generalize and capture the global behavior of biological systems (Kauffman, 1969; Shmulevich et al., 2002). These models are appropriate in experimental settings where the number of experiments is on the order of dozens and the dimensionality is on the order of thousands, as is the case of gene expression data experiments. The main disadvantage of these models is information loss as a consequence of the required data quantization. However, quantization makes BN and PBN models simpler to implement and analyze (Styczynski and Stephanopoulos, 2005; Ivanov and Dougherty, 2006), and many methods have been proposed to model GRNs through BNs or PBNs (Liang et al., 1998; Akutsu et al., 1999; Lahdesmaki and Shmulevich, 2003; Nam et al., 2006).
Although PBN genes have only two possible expression values, network inferences are still difficult, because the curse of dimensionality still shows its ugly head. Hence, the PGN model simplifies the inference process by local feature selection, to search for the best subsets of genes to predict the behavior of a given target gene (Barrera et al., 2007). Because exhaustive search is the only feature selection algorithm that guarantees optimality (Cover and van Campenhout, 1977), high-performance computing techniques are required when using this algorithm to search for predictor subsets of three or four dimensions (for larger dimensions, this technique is impractical) (Borelli et al., 2013; Carastan-Santos et al., 2017). An alternative to reducing the computational complexity of the exhaustive search is to apply some prior dimensionality reduction technique to restrict the search space of candidate predictor subsets for a given target. However, this is not trivial, as features that are weak individually may be strong in predicting a particular target when combined with others. Likewise, the best individual characteristics might not be as good at predicting the target when combined with others (Pudil et al., 1994; Martins et al., 2008).
In this article, we contribute with a new GRN inference framework for PGNs, called GeNICE (Gene Network Inference by Clustering, Exhaustive search, and multivariate analysis). This framework alleviates the inherent dimensionality curse of the GRN inference problem and, consequently, its computational cost. Our contribution is centered on the application of clustering techniques to reduce the search complexity when evaluating all possible predictor subsets, and thus to alleviate the computational complexity of the GRN inference. GeNICE performs a local feature selection for each target gene to obtain the best subsets of predictors given by the cluster representative genes. Besides, an intrinsically multivariate analysis is conducted to eliminate redundant features from each predictor subset (Martins et al., 2008) and, consequently, to obtain a minimal network.
Experimental results adopting data generated by SysGenSIM (Pinna et al., 2011), used by the DREAM 5 challenge (Marbach et al., 2012), show that the expression profiles (dynamics) produced by the minimum classification error logic of the selected predictor subsets with regard to the target are usually very close to the original expression profiles of the target cluster genes (about 90% of identity). Besides, experiments using P. falciparum (a malaria agent) temporal microarray data achieved even higher accuracies (97% in average). Regarding this same malaria data set, a topological analysis was conducted, displaying connected components for glycolysis and apicoplast functions with only one predictor subset for each target gene seed. Besides, the retrieved topological structure around the considered seeds displayed small-world and scale-free properties, which are commonly seen in biological networks (Strogatz, 2001; Barabási and Oltvai, 2004). In fact, the method displayed great computational efficiency on inferring networks and, at the same time, such networks produced better expression profiles and topologies than those generated by the networks inferred by the same process without involving clustering and multivariate analysis for removal of redundant features as initial and final steps, respectively.
2. Methods
In this study, we propose a new framework for GRN inference, named GeNICE (Gene Network Inference by Clustering, Exhaustive search, and multivariate analysis). GeNICE follows the PGN model (Barrera et al., 2007), which assumes that the temporal gene expression samples follow a first-order Markov chain where each target gene in a given time point depends only on its predictor subset values in the previous time instant. In addition, the transition function of the PGN model is homogeneous (it does not change over time), almost deterministic (from any state, the system has a preferential state to go), and conditionally independent (i.e., the expression value of a given gene is dependent only on its predictors, following the Markov hypothesis). These assumptions are important simplifications to deal with the limited number of samples typically available in real gene expression data. Fig. 1 shows the general workflow of GeNICE, the modules of which are described in the following.
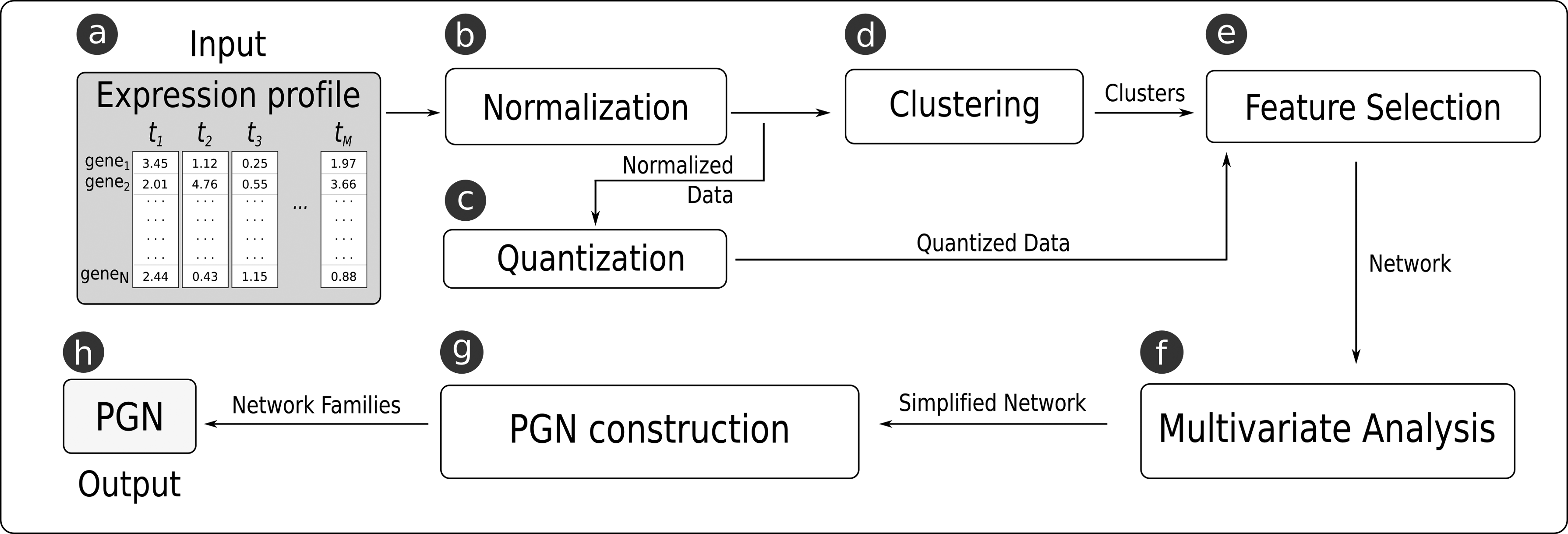
The main steps performed by GeNICE to infer gene networks following the PGN model. The box
2.1. Gene expression data
GeNICE starts with a gene expression time series data set as input (Fig. 1a) that consists of an N × M matrix showing the expression levels of the N genes at M consecutive time points (see Fig. 2a for an example).
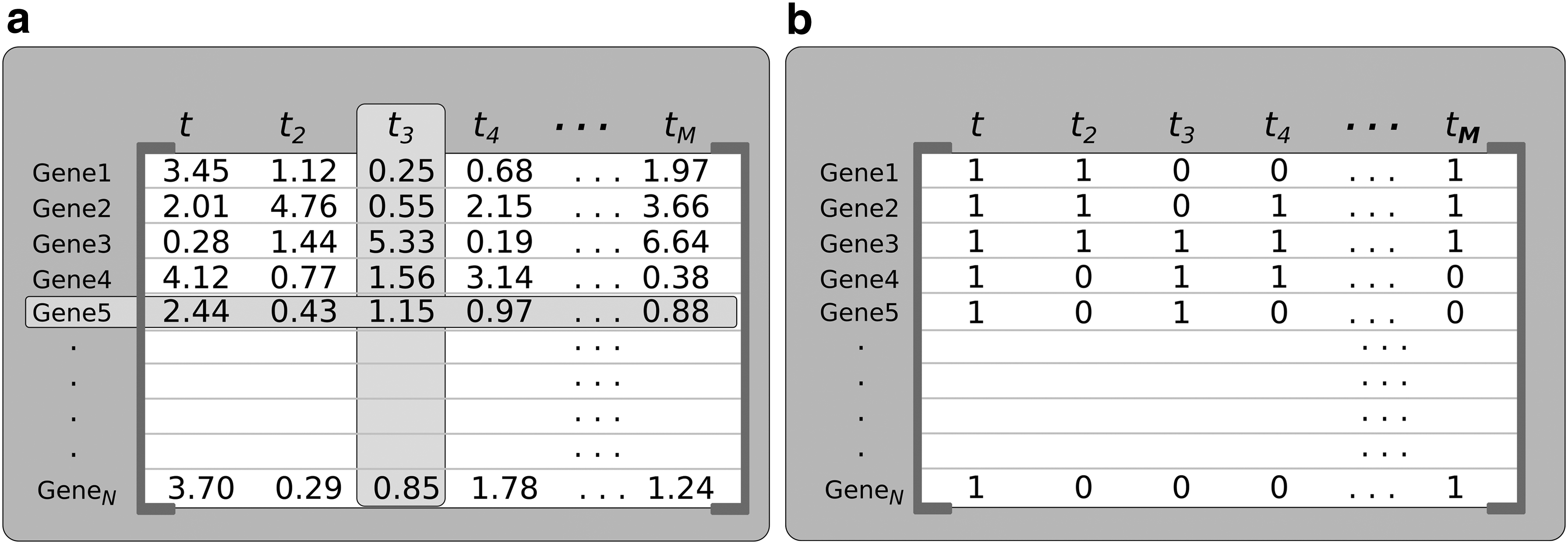
Example of a set of gene expression data:
2.2. Normalization
The data come from different experiments performed at each time point or may have fluctuations and noises in relation to the expression of each gene; so, a normalization operation (Fig. 1b) is required for the data to be comparable. A usual normalization procedure, which we adopt in GeNICE, is the normal transform or Z-score that transforms the data in such a way that each gene expression profile has zero mean and unitary standard deviation (Azuaje and Dopazo, 2005). Thus, the expression ei of a given gene i becomes
2.3. Quantization
Since GeNICE follows the PGN model, the gene expression data set must be quantized (Fig. 1c) so that each gene expression presents a finite set of possible values. In this study, we adopt the binary quantization where negative Z-scored values become 0, while positive Z-scored values become 1. An example of the result of this step can be seen in Fig. 2b.
2.4. Clustering
Gene expression data can be clustered based on genes, samples, or both at the same time (biclustering, coclustering, block clustering, or two-mode clustering) (Govaert and Nadif, 2013). Each clustering type has specific applications and presents specific challenges for the clustering task.
GeNICE focuses on gene clustering (Fig. 1d). The clustering step preceding feature selection is one of the novelties. This step is important to reduce the dimensionality of possible candidate gene predictors for each gene target (in the order of thousands) to the order of the number of resulting clusters k (ideally in the order of dozens). This can have a great impact in the feature selection process (see Section 2.5), since the number of clusters (k) becomes the resulting dimensionality of the feature selection inference process, which could drastically reduce the number of calculated criterion functions depending on the chosen feature selection algorithm.
After normalization, the time series data are clustered by grouping genes with similar normalized real-value expression profiles. Any clustering technique that returns a partition and a list of members per cluster, including their respective representative genes, can be used. Self-organizing map, k-means, hierarchical approaches, Fuzzy C-means, and others display very different results in some cases (Hu and Yoo, 2004). One of the most popular clustering techniques is the k-means algorithm. It partitions N observations (genes) into k clusters, in which each observation belongs to the cluster with the nearest mean value across the time points.
The k-means algorithm starts with k initial centroid values from randomly selected samples and then proceeds in two alternate steps: (1) an allocation step, where all samples are allocated to the cluster containing the centroid that yields the least within-cluster sum of squares (usually the squared Euclidean distance) and (2) a representation step, where a new centroid is constructed for each cluster, that is, new means are calculated to be the centroids of the samples in the new clusters (Pindah et al., 2015).
GeNICE uses a variant of this algorithm that initializes the k centroid values with a predefined set of points selected from the input data and adopts two within-cluster distance measures: Euclidean distance and absolute Pearson correlation. The distance measure chosen is very important because it defines different types of similarity among gene profiles. For instance, Fig. 3a and b represents gene expression signals belonging to the same cluster according to Euclidean distance and absolute Pearson correlation, respectively. In particular, clustering by absolute Pearson correlation tends to group genes whose expression profiles present both similar and opposite phase shapes in the same cluster. This criterion is more desirable than regular Pearson correlation or Euclidean distance for the specific purpose of deriving the best predictors for a given target gene, since strongly correlated candidate predictors (positive or negative) are redundant to each other. Thus, genes with strong negative correlation that compose the same cluster cannot participate in the same predictor subset for a given target, since only one representative gene for each cluster is admitted (and only this representative gene can be a candidate predictor in GeNICE).

Clustering gene expression profiles with the same relative patterns (Azuaje and Dopazo, 2005):
At the end of the clustering step, one representative gene from each cluster must be defined. These genes compose the set of candidate predictors
2.5. Feature selection
Feature selection is a crucial step in the PGN inference procedure. A feature selection problem consists in selecting a subset of features that best represents the objects under study. In the PGN inference context, a feature selection algorithm consists basically in searching for subsets of genes that best predict a given target gene according to a criterion function, which assigns a quality value for a candidate predictor subset according to its expression profiles and the target expression profile (Barrera et al., 2007, Borelli et al., 2013, Lopes et al., 2014).
In GeNICE, the feature selection algorithm is applied considering each target gene, aiming to achieve the best predictor subset for that target, according to a given criterion function. All representative genes (one gene per cluster achieved in the clustering step) are taken as potential predictor genes, and hence, all other genes are ignored.
There are many feature selection algorithms proposed in the literature, most of them are computationally efficient but suboptimal. In fact, in general, the unique algorithm that guarantees optimality is the exhaustive search (Cover and van Campenhout, 1977). This is due to the well-known nesting effect in which a feature included into the solution subset might never be removed by a suboptimal algorithm feature selection, even if that feature is not in the optimal solution set. Similarly, a previously removed feature might never be inserted again into the current subset solution, even if it belongs to the optimal solution set (Pudil et al., 1994).
GeNICE applies an exhaustive search for subsets of a given fixed dimension p, adopting two criterion functions popularly used in feature selection-based GRN inference methods (Martins et al., 2008; Lopes et al., 2014): (1) coefficient of determination (CoD), which is based on classification Bayesian error (Dougherty et al., 2000) and (2) mean conditional entropy, which is based on Shannon's entropy (Shannon, 2001).
The CoD (Dougherty et al., 2000) for a target gene
where
In its turn, the mean conditional entropy H(Y |
where P(
It is important to note that if the defined number of clusters is small enough (100 at most), an exhaustive search is applicable to search for trios or even subsets with larger dimensions (p = 4 or even p = 5). Following the PGN model, the criterion function needs to evaluate the prediction power of a candidate predictor subset with regard to the target expression at the next time point (first-order Markov chain). Fig. 4a illustrates the collection of samples (all pairs of consecutive time points) to estimate the conditional probability distribution table (P(Y |

Example of a conditional probability distribution (CPD) table for a given predictor subset of representative genes
Considering the set of possible candidate predictor genes
However, it is not enough to select the best subsets of predictors with fixed size, since redundant genes might be present in these subsets. So, it is important to perform a multivariate analysis of these predictors with the aim of reducing the number of predictors per target, thus simplifying the network.
2.6. Multivariate analysis
The multivariate analysis step is necessary to eliminate redundant genes from a predictor subset
where

An example of a collection of predictors per target gene as output from the multivariate analysis process.
2.7. PGN construction
This step enables to define the number of predictor subsets for each target that will compose the PGN. Families of PGNs with different numbers of subsets per target can be derived by this step. Fig. 6 exemplifies this process for the target Y: (a) including its best predictor subset

Three examples of different numbers of subsets for the target gene Y:
Once defined the final predictor subsets for each target, the dependence logics that rule the target expression profile based on its final predictor subset are derived, as shown in Fig. 4b. These dependence logics are retrieved from the conditional probability distributions
2.8. Computational complexity analysis
As the computational complexity of the framework is mainly given by the exhaustive search algorithm in the Feature Selection step (step d), we focus only on the analysis of the complexity of this step. The other steps have a negligible processing time in comparison, since they are processed in seconds even for very big data sets. Hence, the complexity is measured according to the number of times that the criterion function is calculated during the Feature Selection step (so let us assume that one criterion function calculation presents
Let N be the number of genes in the data set
2.9. Implemented software
The proposed framework was implemented as a Java plugin * for Cytoscape (Shannon et al., 2003). It allows advanced analysis of gene expression data through an intuitive graphical user interface, including two other frameworks: MultiExperiment Viewer (MeV) (Howe et al., 2011) and Environment for Developing KDD-Applications Supported by Index-Structures (ELKI) (Achtert et al., 2010). Such a plugin is an evolution of the DimReduction feature selection environment (Lopes et al., 2008).
3. Experimental Setup
To evaluate our framework, we performed experiments with two data sets: (1) simulated (in silico) data and (2) real microarray data. In this section, we describe the protocols adopted in these experiments and the assessment made. Fig. 7 gives an overview of the evaluation process.
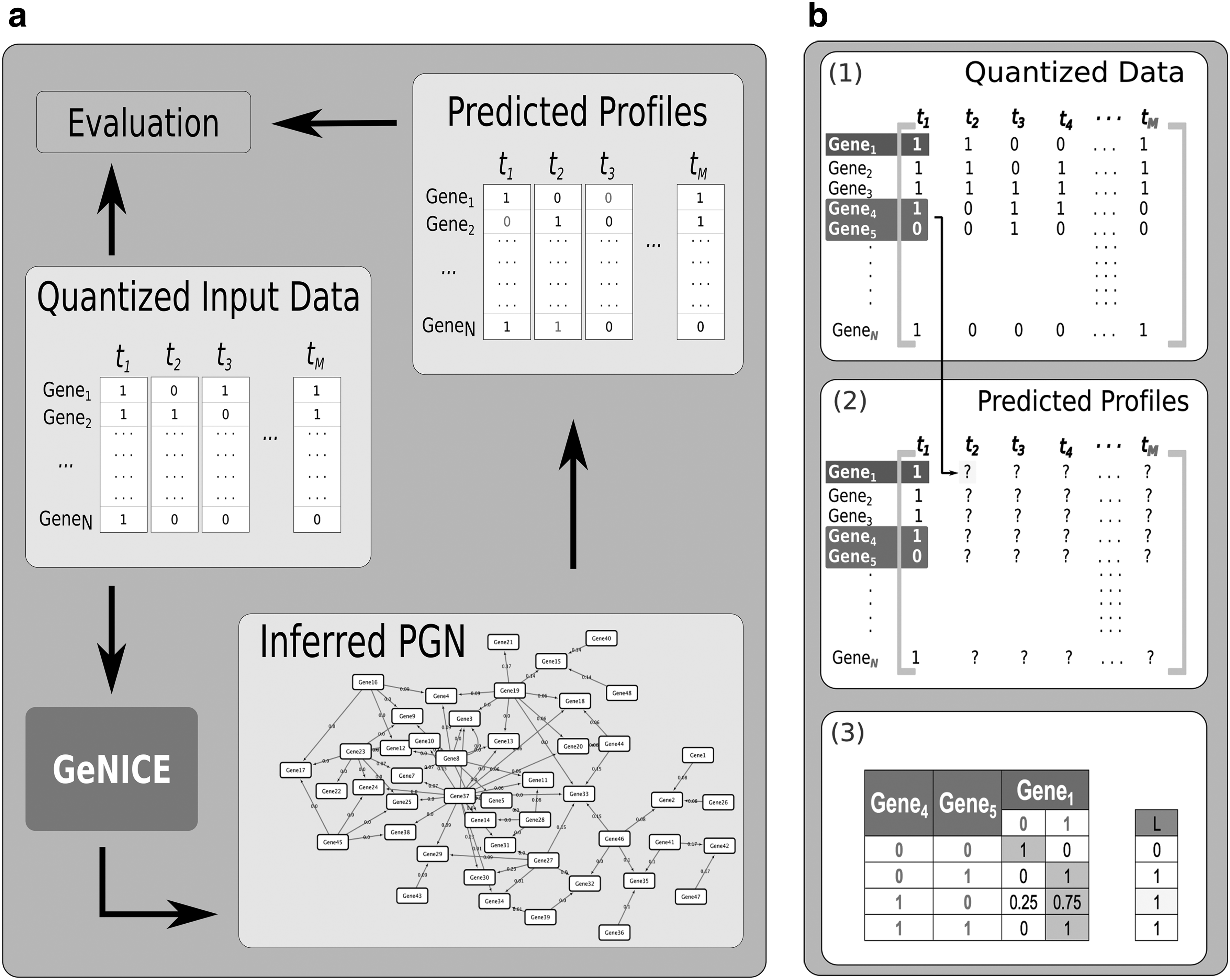
Evaluation of the framework:
3.1. In silico expression data
1. Input data generation: We adopted the SysGenSIM (Pinna et al., 2011) to generate expression data. It is an in silico method that generates gene expression profiles from nonlinear differential equations based on biochemical dynamics of yeasts. This method was applied to generate the DREAM5 Challenges database (Marbach et al., 2012). The following parameters were defined when generating the data sets: three different expression profiles were generated with 40 samples (M = 40) each. The Barabási-Albert scale-free model (Barabási and Albert, 1999) was adopted to generate the network topology, and the average input degree was set to 3. The number of genes was set to
2. Clustering step: In the clustering step, the Lloyd k-means algorithm (Lloyd, 1982), was adopted to group genes with similar expression profiles. The parameter k, which indicates the number of clusters, was varied considering
3. Feature selection: An exhaustive search for candidate predictor sets of size p = 3 for all N genes placed as target in their turns was applied, adopting the CoD [Eq. (1)] and entropy [Eq. (2)] as criterion functions. It is important to recall that candidate predictors are only the representative genes of the clusters retrieved in the clustering step (one for each of the k clusters).
4. Multivariate analysis: A predictor subset
5. PGN construction: Only the best subset for each target gene was considered to compose the network and to generate the prediction logics.
6. Evaluation: To evaluate the inferred gene expression profile dynamics, first the expression data of a gene at the time
The percentage of correctly predicted time points for a given gene defines its accuracy (it is equivalent to the Hamming distance between two binary profiles divided by the number of time points present in the data set). The average of accuracies obtained for all target genes is taken as the overall accuracy of the inferred data set (values between 0 and 1, where 1 means perfect accuracy and 0.5 is the expected value obtained by random guesses of the binary gene expression profile values) (Qian and Dougherty, 2013).
3.2. P. falciparum microarray expression data
In this experiment, we adopted gene expression data from the transcriptome of the intraerythrocytic developmental cycle (IDC) of the P. falciparum (a malaria agent). This transcriptome was generated by relative measurements of abundance levels of mRNA from samples collected from a strain called HB3, which is well characterized and originated from Honduras (Bozdech et al., 2003). The quality control data set (called QC data set) containing 48 time point samples with N = 5080 genes was used in this experiment. These 48 samples were extracted hourly, corresponding to the 48 hours (time instants) of IDC. The time points corresponding to the 23rd and 29th hours were discarded due to bad quality (so we considered time point 22 as predecessor of time point 24, and time point 28 as predecessor of time point 30), which led to M = 46 time point samples. This expression data set contains oligonucleotides from the glycolytic pathway, ribonucleotide synthesis, deoxyribonucleotide synthesis, DNA replication machinery, TCA cycle, proteasome, plastid genome (apicoplast), merozoite invasion, actin myosin motility, early ring transcripts, mitochondrial genes, and organellar translational group.
We adopted seed genes (target genes) from two functional modules, glycolytic pathway and plastid genome (apicoplast), as done in a study (Barrera et al., 2007) to obtain the minimum number of predictors that interconnect all seeds of the same module. The list of seeds, including their respective annotations, is shown in Table 1. It is expected that just a few predictor genes per seed are enough to connect all seeds of the same module and its corresponding predictors in a single connected component. Besides, it is expected that the glycolysis and apicoplast modules form separate components or a single component with a very small intersection of genes predicting seeds from both modules (these genes would be bridges connecting the two modules). In summary, besides expression signal dynamics assessment, here we conduct topological structure assessment to check whether the final network around the seeds presents high intramodularity and small intermodularity, attending an important property of small-world topological model (Strogatz, 2001).
For the clustering step, regarding expression profile dynamics assessment, we considered
For the feature selection step, we applied exhaustive search for predictor subsets of dimension p = 3 for every target. We adopted CoD and entropy as criterion functions [Eqs. (1) and (2)].
For the multivariate analysis, we adopted IS (
Finally, for the network construction, we considered the best subset per target gene when performing the expression profile dynamics analysis. Considering the topological structure analysis involving glycolytic and apicoplast seeds, we retrieved the best predictor subset per seed.
3.3. Hardware and software used in the experiments
For the PGN inference, we used the framework implementation (Cytoscape plugin) briefly described in Section 2.9. Experiments were executed on a computer Intel® Xeon® 8 core CPU E7-2870 2.40 GHz with 32 GB RAM, under Linux Ubuntu 64-bit operating system.
4. Results and Discussion
In this section, we present gene expression data prediction.
4.1. In silico data experiment
4.1.1. Comparison between GeNICE and pure exhaustive search inference
Here we compare both accuracies and execution times of GRN inference by pure exhaustive search (without clustering step) and by our proposed framework. The pure exhaustive search was performed only for data sets composed of N = 100 genes, since this method requires much computational effort for N > 100 (see Section 2.8). In contrast, GeNICE was executed for data sets composed of
Fig. 8 shows the average prediction accuracy of the inferred expression profiles taking the quantized generated data set as ground truth for different numbers of clusters, involving the comparison between our framework and the pure exhaustive search with N = 100. The corresponding execution times elapsed to obtain the best predictor subsets for a single target are shown in Table 2. For the pure exhaustive search, the time elapsed for N = 1000 was estimated, since it was not executed until completion.
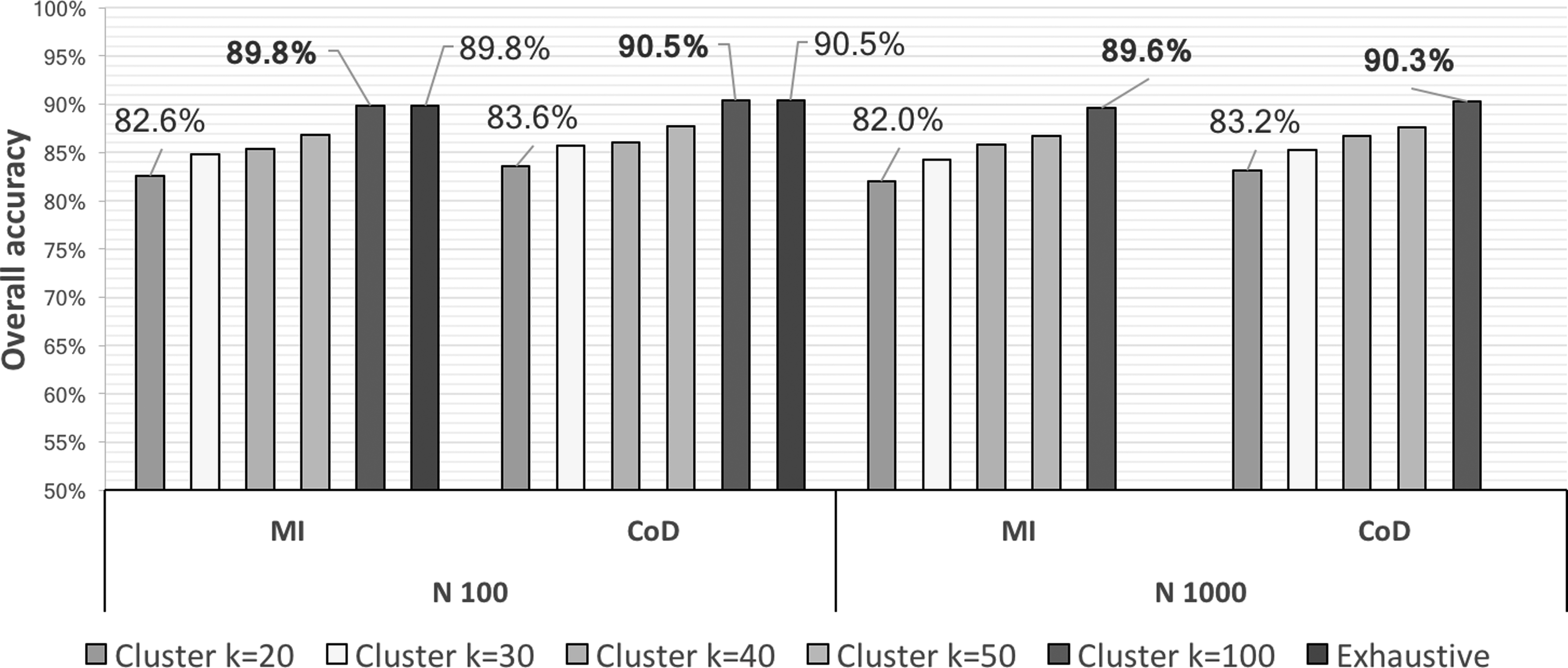
Overall accuracy of GeNICE framework for
It is noteworthy that the accuracy loss was very small when using GeNICE, specially for k = 50 (for N = 100 and k = 1000 are equivalent to pure exhaustive search, since no clustering was involved in this particular case), while the processing time was substantially reduced when compared to the pure exhaustive search. GeNICE spent <30 minutes for all cases, regardless of the number of genes (N), which means that GeNICE is scalable in terms of number of genes.
As predicted by the theoretical complexity analysis (see Section 2.8), in GeNICE, the execution time is only affected by the number of clusters, while the overhead introduced by the clustering and multivariate steps is negligible. In this experiment, the pure exhaustive search, in its turn, is unfeasible to execute for a larger number of genes. According to our estimates, if the pure exhaustive search was fully processed for a single target gene considering N = 1000 genes, it would spend about 28,800 minutes (20 days), which is roughly 1000 times longer than the processing time required by GeNICE framework considering N = 1000 and k = 100. Finally, it is also noteworthy that the accuracies of our framework for N = 1000 and k = 100 were almost identical to the accuracies of the pure exhaustive search for N = 100, even though our framework was applied to a network that was 10 times larger in terms of the number of genes than the one considered for the pure exhaustive search. This observation is remarkable, since real expression data sets usually present dimensionality in the order of thousands, which means that GeNICE can be an useful method in other domains where the exhaustive search is unfeasible.
Regarding the impact of the criterion function in the prediction accuracies achieved, the CoD and mean conditional entropy implied in very close accuracies for all N and k values considered.
4.1.2. Assessment of individual gene expression profile accuracies for increasing k values
In this study, the objective is to assess the prediction accuracy of the dynamics of each individual gene expression profile for increasing k values
Distribution (box plot) of individual gene expression profile prediction accuracies for every triple (k,
4.2. P. falciparum microarray expression data
4.2.1. Assessment of individual gene expression profile accuracies for increasing k values
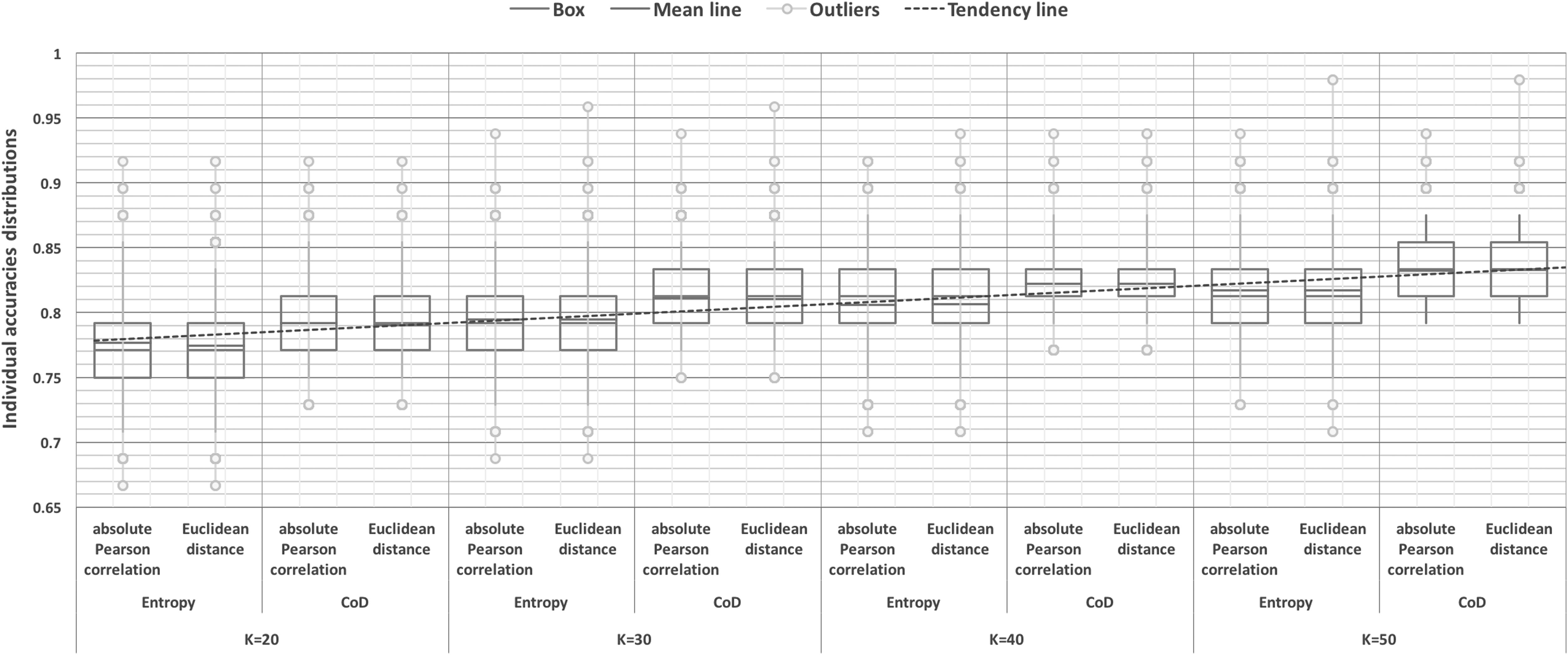
As done for in silico data, here the objective is to assess the prediction accuracy of the dynamics of each individual gene expression profile for increasing k values

Distribution (box plot) of individual gene expression profile prediction accuracies for every triple (k,
4.2.2. Topological assessment involving glycolytic and apicoplast seeds
In this study, the objective is to assess if the network construction considering 10 glycolytic and 27 apicoplast seeds produces large intramodular connection and small intermodular connection, one of the main small-world properties (Strogatz, 2001). Table 3 shows the characteristics of networks retrieved for
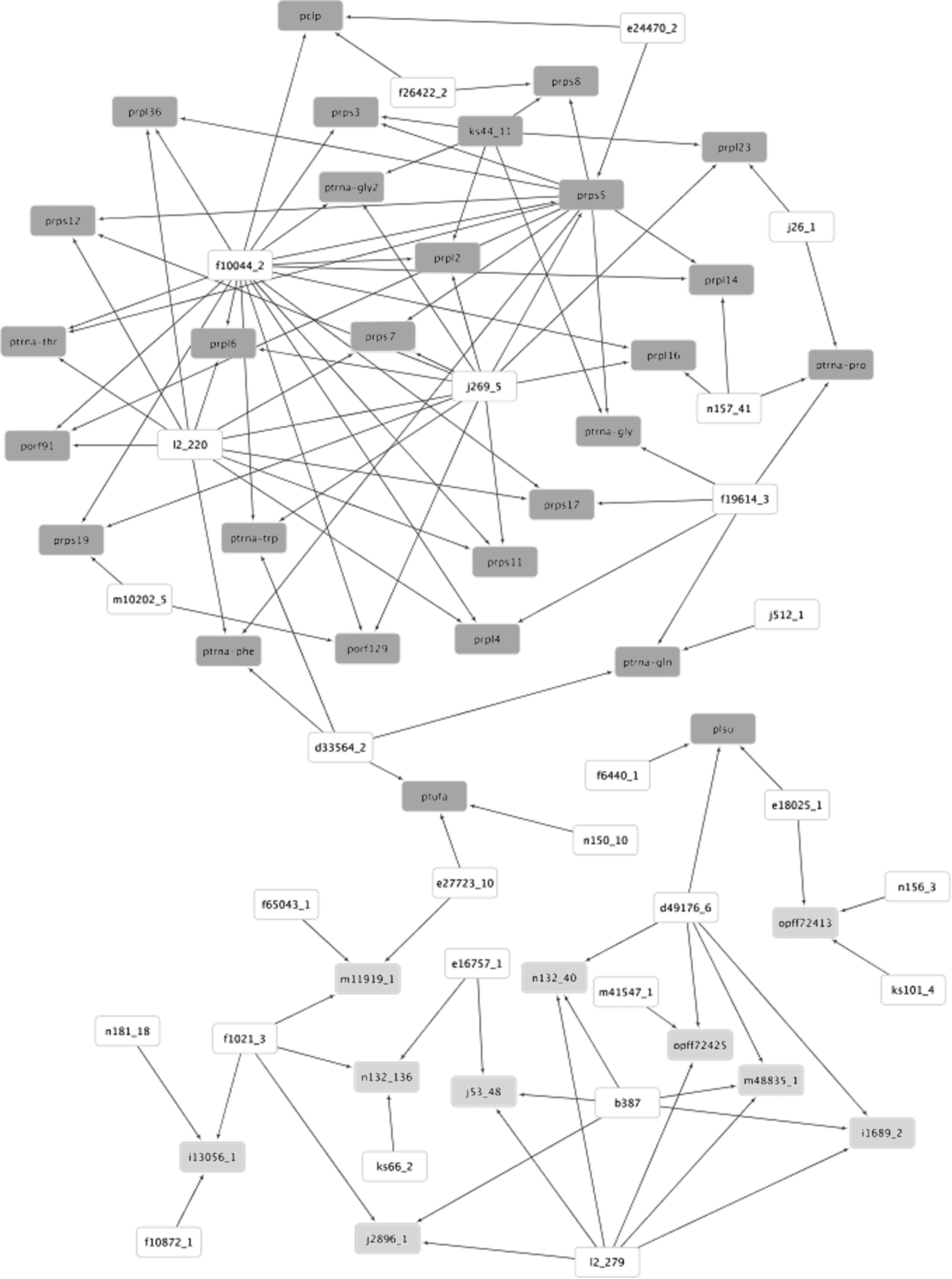
PGN inferred for the glycolytic (light gray nodes) and apicoplast (dark gray nodes) seeds for k = 50, absolute Pearson correlation and CoD. White nodes indicate predictor genes that are not seeds. Network visualization generated in Cytoscape (Shannon et al., 2003).
Another important observation is that there are module hubs (predictors that connect very large number of nodes in comparison to the average), such as the gene f10044_2 (output hub in apicoplast module) and 12_279 in the glycolysis module. These three combined facts (small number of predictors connected to seeds from both modules, large number of predictors inside each module, and some hub modules) suggest that this network presents both small-world and scale-free properties, corroborating other biological network studies (Strogatz, 2001, Barabási and Oltvai, 2004).
In addition, only three or less predictors per seed were enough to connect each module. In comparison, Barrera et al. (2007) (original PGN inference approach, which did not include clustering and multivariate analysis steps) needed 10 best individual predictors or 5 best predictor pairs (10 in total) per seed to connect the glycolytic seeds in a single connected component, while 6 best individual predictors or 3 best pairs (6 in total) per seed were needed to connect the apicoplast seeds. This shows that the PGN approach combined with clustering and multivariate analysis steps is more promising in capturing the existing biological network modularities.
Finally, the gene expression signals for each of the k = 50 clusters generated using Euclidean distance and absolute Pearson correlation for P. falciparum data are shown in Fig. 12. It is noteworthy that most of clusters have strong sinusoidal shape, which corroborates the study by Bozdech et al. (2003) which discovered that the P. falciparum expression data present unusually large number of gene expression profiles with strong sinusoidal shapes (at least 50%). This is an indicative that the decisions taken in the clustering step are leading to biologically meaningful clusters, with beneficial impact to the next steps.

Gene expression signals present in each of the k = 50 clusters based on the P. falciparum data set for
5. Conclusion
In this study, we proposed GeNICE, a new framework for GRN inference, in which the main novelty consists in the application of a clustering method to reduce the complexity of the search for the best predictor subsets per target gene, considering the PGN model. We demonstrated the applicability of GeNICE in experiments using synthetic and P. falciparum gene expression data, for which it was able to preserve the gene expression profile prediction accuracy obtained by the pure exhaustive search while substantially reducing the computational complexity of the search.
Regarding the synthetic data sets involved in the experiments, they were generated by a complex and detailed model (nonlinear differential equations based on biochemical dynamics of yeasts (Pinna et al., 2011)), while the PGN model on which our framework relies is much simpler. Even assuming a simpler model, our framework described the synthetic expression profiles with great accuracy (about 90%) considering data sets with 1000 genes. On the contrary, for much larger networks (5000 genes), the accuracies were smaller. This fact might be related to the choice of parameters to generate the data, especially regarding noise. Besides, PGN assumes strong simplification assumptions to deal with the limitations imposed by the data at hand, which might not be suitable for complex models. However, further studies need to be conducted to confirm these hypotheses.
When considering the gene expression signal prediction accuracies by taking P. falciparum data as input, the results were notably superior to the ones achieved by in silico experiment, reaching about 97% on average for a number of clusters as small as only 30. Moreover, topological structure assessment involving glycolytic and apicoplast seeds displayed large modularity connecting seeds of the same function and a small interconnection between the subnetworks corresponding to the two aforementioned functions. This was achieved with only the best predictor gene subset per seed (at the most three genes). Hub genes were observed in both modules. Such observations are meaningful from the biological point of view, since even a small inferred network was able to display complex network features, usually present in biological networks (small-world and scale-free properties) (Strogatz, 2001; Barabási and Oltvai, 2004).
Besides, as GeNICE consists of a framework, several aspects regarding the different steps involved can be improved. For example, other clustering algorithms can be tested as well as other distance metrics and methods to define the representative genes. Also, the clustering algorithm can be applied after the quantization step, which might lead to clusters with less variability among their respective gene expression profiles. Regarding the multivariate analysis for removal of redundant features, Chen and Braga-Neto (2015) developed a method for automatic determination of the IMP score threshold. The application of this method in this step might lead to better topological structures.
Even though completely understanding and modeling the properties and structures of real biological systems are still an open problem, GeNICE showed promise in assisting professionals of biomedicine and related areas in decision-making regarding the control of the gene regulatory systems dynamics. GeNICE also provides a viable system in environments with limited computing resources, which was not possible considering previous works that applied exhaustive search as a way to guarantee the best predictor subset for each target. In this way, the implementation of this framework as a plugin for Cytoscape (Shannon et al., 2003) is currently under development.
Finally, GeNICE showed to be scalable, since we were able to increase 50 times the number of genes in the input expression data without increase in the processing time of exhaustive feature selection for a single target gene, which implies that the processing time linearly increases with the number of genes in the whole network.
Footnotes
Acknowledgments
We gratefully acknowledge funding from CAPES, CNPq (grants 304955/2014-0, 311608/2014-0), and São Paulo Research Foundation, FAPESP (grants 2011/50761-2, 2015/01587-0, 2015/16310-4, 2016/21047-3).
Author Disclosure Statement
No competing financial interests exist.