
Abstract
Abstract
Large amounts of rich, heterogeneous information nowadays routinely collected by healthcare providers across the world possess remarkable potential for the extraction of novel medical data and the assessment of different practices in real-world conditions. Specifically in this work, our goal is to use electronic health records (EHRs) to predict progression patterns of future diagnoses of ailments for a particular patient, given the patient's present diagnostic history. Following the highly promising results of a recently proposed approach that introduced the diagnosis history vector representation of a patient's diagnostic record, we introduce a series of improvements to the model and conduct thorough experiments that demonstrate its scalability, accuracy, and practicability in the clinical context. We show that the model is able to capture well the interaction between a large number of ailments that correspond to the most frequent diagnoses, show how the original learning framework can be adapted to increase its prediction specificity, and describe a principled, probabilistic method for incorporating explicit, human clinical knowledge to overcome semantic limitations of the raw EHR data.
1. Introduction
T
Considering that this research is still in its early stages, it is undeniably wise to refrain from overly ambitious predictions regarding the type of knowledge that may be discovered in this manner, at the very least it is true that few domains of application of the aforesaid techniques hold as much promise for impact. It is sufficient to observe the potential benefits that an increased understanding of complex interactions of lifestyle diseases in the economically developed world could deliver in terms of personalized medicine or healthcare policy (Fan et al., 2016) on the one hand, and a wiser utilization of resources, aid, and educational material in the economically deprived countries on the other (RGI-CGHR Collaborators, 2009), to appreciate the global and overarching potential.
Public healthcare is an issue of major global significance and concern. On one end of the spectrum, the developing world is still plagued by “diseases of poverty,” which are nearly nonexistent in the most technologically developed countries; on the other end, the health risk profile of industrially leading nations has dramatically changed in recent history with an increased skew toward so-called “diseases of affluence,” as illustrated in Figure 1 [data taken from Murray et al. (2001)].
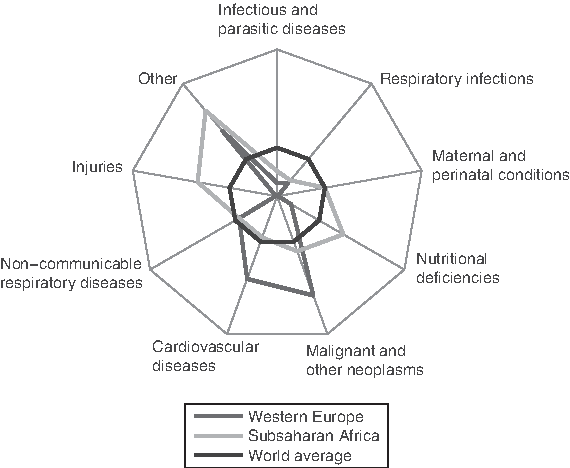
Causes of death for the developed world (western Europe), developing nations (Sub-Saharan Africa), and the world average.
Hence, healthcare management poses challenges in both the sphere of policy making and scientific research. Considering the complexity of problems at hand, it is unsurprising that there is an ever-increasing effort invested in a diverse range of promising avenues. Yet, the available resources are inherently limited. To ensure their best usage, it is crucial both to develop an understanding of the related epidemiology and to be able to communicate this knowledge effectively to those who can benefit from it: governments (Berwick and Hackbarth, 2012), the medical research community (Beykikhoshk et al., 2015a, 2016; Andrei and Arandjelović, 2016), healthcare practitioners (Arandjelović, 2015a; Osuala and Arandjelović, 2017), and patients (Beykikhoshk et al., 2014; Barracliffe et al., 2017).
The associations between diseases and a wide variety of risk factors are underlain by a complex web of interactions. This is particularly the case for the diseases of the developed world. The key premise of this work is to facilitate the understanding of this complexity and the discovery of meaningful patterns within it, it is crucial to make use of the vast amounts of data routinely collected by health services in industrially and technologically developed countries.
Our specific aim is to develop a framework that allows a health practitioner (e.g., a doctor or a clinician) to manipulate the available patient information in an intuitive yet powerful manner. Such a framework would, on one end of the utility spectrum, facilitate a deepening of disease understanding and, on the other, provide the practitioner with a tool that can be used to incentivize the patient at risk to make the required lifestyle changes.
1.1. Data: electronic medical records
This work leverages large amounts of medical data routinely collected and stored in electronic form by health providers in most developed countries. This is a rich data source that contains a variety of information about each patient, including the patient's age and sex, mother tongue, religion, marital status, profession, etc. In the context of this work, of main interest is the information collected each time a patient is admitted to the hospital (including out-patient visits to general practitioners or specialists). The format of these data is explained next.
Each time a patient is admitted to the hospital, the reason for admission, as determined by the medical practitioner in primary charge during the admission, is recorded in the patient's medical history. This is performed using a standardized coding schema such as that provided by the International Statistical Classification of Diseases and Related Health Problems (ICD-10) (World Health Organization, 2004) and the related Australian Refined Diagnosis-Related Groups.
These have hierarchical structures (Arandjelović, 2016). ICD-10, for example, contains 22 chapters, each chapter encompassing a spectrum of related health issues (usually symptomatically rather than etiologically related). For example, ICD-10 Chapter 4, which includes codes E00-E90, covers “endocrine, nutritional, and metabolic diseases.” At each subsequent depth level of the tree, the grouping is refined and the scope of conditions narrowed down. In this article, we use the classification attained at the depth of two of ICD-10, which achieves a good compromise between specificity and frequency of occurrence. This results in each diagnosis being given a three character code that comprises a leading capital letter (A–Z, first grouping level), followed by a two digit number (further refinement). For example, E66 codes for “obesity” within the broader range of “endocrine, nutritional, and metabolic diseases.”
2. Modeling Comorbidity Progression
The major contribution of this work is a novel disease progression model. The principal challenge is posed by the need for a model that is sufficiently flexible to be able to capture complex patterns of comorbidity development, while at the same time constrained enough to facilitate learning from a real-world data corpus.
2.1. Bottom-up modeling
The problem of modeling disease progression has already attracted a considerable amount of research attention. Most previous research focuses on specific individual diseases, such as type 2 diabetes mellitus (Topp et al., 2000; De Gaetano et al., 2008) or heart disease (Ye et al., 2012). These methods are inherently “low-level” based, in the sense that they explicitly model known physiological changes that affect disease progression. For example, the modeling of the progression of type 2 diabetes may include low-level models of
The low-level approach to disease modeling has several limitations. First, by their very nature, these models are limited to specific diseases only and cannot be readily adapted to deal with conditions with entirely different etiologies. Second, the modeling is practically constrained usually to a single condition, two at the most, as the complexity of modeled system increases dramatically with the inclusion of a greater number of conditions. This observation is of major significance as most diseases of the developed world are most often accompanied and affected by multiple comorbidities. Lastly, the range of diseases that can be modeled in this manner is limited to diseases that are sufficiently well understood and studied to allow for the free model parameters to be set reliably; even for type 2 diabetes, which has been studied extensively, at present some parameters must be set in an ad hoc manner and others using in vitro rather than in vivo data (Topp et al., 2000).
2.2. Direct high-level modeling
Given the significance of the disadvantages of low-level-based disease progression models, in this article an alternative approach is pursued, that of seeking to describe disease progression as well as the interplay of different comorbidities directly on the “high-level” as observed by a medical practitioner. Previous research in this area is far scarcer than that on low-level modeling; a possible reason for this is probably to be found in the until recently limited availability of large-scale medical records data. The central idea of the existing corpus of work is to regard disease progression as a discrete sequence of events, with the progression governed by what is assumed to be a first-order Markov process (Jackson et al., 2003; Sukkar et al., 2012).
A high-level view of disease progression is seen as being reflected by a patient's diagnostic history
Alternatively, it may be used to estimate the probability of a particular diagnosis
or to sample the space of possible histories:
The primary purpose of the Markovian assumption is to constrain the mechanism underlying a specific process and thus formulate it in a manner that leads to a tractable learning problem. Although it is seldom strictly true, that it is often a reasonable approximation to make is witnessed by its successful application across a diverse range of disciplines; examples of modeled phenomena include meteorological events (Gabriel and Neumann, 1962), software usage patterns (Whittaker and Thomason, 1994), breast cancer screening (Duffy and Yau, 1995), human motion and behavior (Lee et al., 2005; Arandjelović, 2011), and many others. Nonetheless, the key premise motivating the model in this article is that the Markovian assumption is in fact not appropriate for the high-level modeling of disease progression (note that this does not reject its possible applicability in disease progression modeling on different levels of abstraction). Indeed, we demonstrate this empirically. The aforementioned premise is readily substantiated using a theoretical argument as well. Consider a patient who is admitted for what is diagnosed as a serious chronic illness. If the same patient is subsequently admitted for an unrelated ailment, possibly a trivial one, the knowledge of the serious underlying problem is lost and the power to predict the next related diagnosis is lost. The model proposed in the following section solves this problem, while simultaneously retaining the tractability of Markov process-based approaches.
2.3. Proposed approach
In this article, our aim is to predict the probability of a specific diagnosis a following the patient history H:
The difficulty of formulating this as a tractable learning problem lies in the fact that the space of possible histories is infinite as H can be of an arbitrary length. Even if the length
where D is the set of diagnosis codes,
The disease progression modeling problem at hand is thus reduced to the task of learning transition probabilities between different patient history vectors:
It is important to observe that unlike in the case of Markov process models working on the diagnosis level when the number of possible transition probabilities is close to
The converse does not hold however. Moreover, possible transitions can be only those that include either no changes to the history vector (repeated diagnosis) or that encode exactly one additional diagnosis:
This gives the upper bound for the number of nonzero probability transitions of
The final aspect of the proposed model concerns transitions with probabilities that do not vanish but that are nonetheless very low. These transitions can be reasonably considered to be noise in the sense that the corresponding probability estimates are unreliable because of low sample size. Hence diagnosis history vectors are constructed using only the

Frequency (red line) and cumulative frequency of different diagnoses. The plot illustrates the highly uneven distribution, with the top 30 most frequent diagnoses accounting for 75% of the entire data corpus.
A conceptual illustration of the method is shown in Figure 3.

Conceptual illustration of the method proposed by Arandjelović (2015b), which superimposes a Markovian model over a space of history vectors used to represent the medical state of a patient.
2.4. Limitations and questions
One of our contributions of this work is in the form of an analysis that scrutinizes the expectation that the method would scale well. In the original work (Arandjelović, 2015b), it was argued that the predictive performance of the method, reported with explicit modeling of the 30 most frequent diagnosis types only, could be maintained as a greater number of diagnosis types is included in the model as most practical applications would demand. The original article did not investigate this; rather, the number of salient, explicitly modeled diagnoses was set in an ad hoc manner to 30, explaining ∼75% of the data corpus (Arandjelović, 2015b). If our expectation of performance deterioration with an increased number of explicitly modeled diagnoses is correct, and if the rate of deterioration is high, the model could end up being of little practical significance: on the one end of the parameter spectrum, the model would provide high accuracy but insufficient specificity for its predictions to be practically useful, and on the other, the model would provide high specificity but poor accuracy for its predictions to be relied upon. Thus an analysis of this aspect of the original method is necessary before any practical use can be considered; our experiments as regards this issue are presented in Section 4.3.
3. Further Technical Contributions
In this section, we introduce our two main technical contributions. Our third contribution in the form of novel analyses and empirical results that highlight important and promising future research directions is presented in Section 4.
3.1. Improving the specificity of the model
The first major contribution of this work goes to the very heart of the learning framework underlying the diagnostic progression model, and concerns the issue of the space over which learning is performed. In other words, we propose a paradigm change in terms of what is explicitly learnt.
Recall from the previous section that the method described by Arandjelović (2015b) learns the probabilities of transitions from the space of history vectors to the same space of history vectors, that is, it learns
The method introduced in this article solves the described problem by changing the space over which learning is performed. In particular, rather than learning the probabilities of transitions between history vectors themselves, we learn the probabilities of follow-up diagnoses directly. It can be readily seen that this is a stronger learning task in the sense that knowing the follow-up diagnosis d allows for the computation of the next Markov chain state
3.2. Risk-driven inference
Our second key technical novelty concerns a major challenge in the development of models underlain by data from EHRs, which emerges from the pervasive problem known as the semantic gap (Vasiljeva and Arandjelović, 2016c). In colloquial terms, the problem is readily understood as arising from the lack of understanding of, say, disease etiology and physiology that an automatic method has in the interpretation of data from EHRs. For example, a human expert (such as a general practitioner or a specialist) who does have such knowledge may be readily able to discount even the consideration of certain disease interactions, which may be difficult to infer using a purely data-driven approach that machine methods generally employ. To overcome this challenge, some means of interaction, that is, information provision between an expert and a computer algorithm are needed. Yet, this interaction has to be intuitive and requires little effort and computing expertise.
The original authors correctly point out and thereafter empirically demonstrate that a major limitation in the use of Markovian models lies in their “forgetfulness.” This feature seemingly makes them inappropriate for the modeling under consideration here. They overcome this limitation by incorporating memory into the state representation itself. In particular, they describe what they term a history vector, which is a representation of a patient's diagnostic history in the form of a binary vector that encodes the types of diagnoses that the patient has been given in the past.
3.2.1. Identifying confounding factors
Consider two history vectors, Hx and Hy, which differ in the presence of only a single past diagnosis dd. In other words, all bits in Hx and Hy are the same except for exactly one. A specific follow-up diagnosis df causes the transition of Hx and Hy to, respectively,
Consider what happens if Hx and Hy are indeed merged in the context of the prediction of df. In such a case, the number of observed transitions from Hx to
This risk emerges as a consequence of the fact that the empirical nature of EHRs inherently involves a degree of stochasticity, which means that there can never be absolute certainty that dd is indeed entirely inconsequential in the context of this prediction. Instead, employing Bayesian framework, it is necessary to integrate over the latent probability of df following Hx and Hy and weigh this with the associated relative risk. In this manner for
What this expression captures can be readily understood as follows. The first term quantifies the risk of z underestimating the true probability x of df following Hx (hence the integration is for
Continuing from Equation (9), using Bayes theorem, the term
where nx is the number of cases in which df was the next diagnosis following Hx of the total of Nx transitions present in the EHRs database. Since the method has no means of establishing an informative prior on the transition probability x, an uninformative prior
where
Notes and remarks on practical application: It is insightful to highlight several important practical aspects of the proposed technique. First, once implemented as software, it is intuitive to use—the tradeoff between overdiagnosis and underdiagnosis is a concept routinely dealt with by medical professionals, and it is simply set using a single constant that balances the two risks. The risk is also readily interpretable. For example, for a terminal diagnosis the integrand in Equation (9) can be interpreted as computing the number of individuals who would be incorrectly expected to have a terminal diagnosis—an undesirable mistake considering the potential emotional stress, to begin with. Similarly, for a terminal diagnosis, the integrand in Equation (10) estimates the number of individuals who would experience a terminal episode that would not be predicted—arguably an even more serious mistake in that it ipso facto involves the loss of life. The acceptable tradeoff can be made by a clinician either on the level of an individual patient, for a specific diagnosis, or for an entire class of diagnoses (e.g., the same baseline risk tradeoff could be set for an entire ICD chapter, such as chapter IX that covers circulatory system diseases). In summary, the proposed technique is simple and intuitive to use, and it allows a high degree of flexibility in the choice of specificity or generality in application.
4. Evaluation
In this section, we summarize some of the experiments we conducted to evaluate the proposed framework and derive useful insights that illuminate possible avenues for improvement and future work.
4.1. EHR data
In an effort to reduce the possibility of introducing variability because of confounding variables, we sought to standardize our evaluation protocol as much as possible with that adopted by previous work. Hence, we requested access to the large collection of EHRs described by Arandjelović (2015b) and were kindly provided 75% of the records used in the aforementioned article. For completeness, here we summarize the key features of this subset.
The EHRs adopted for evaluation were collected by a large private hospital in Fife, Scotland. The distribution of patient age in the database is
4.2. Baseline model validation
Interestingly, on our data set, the patient's age was found not to be associated with the number of admissions on record, whereas a low positive correlation


4.2.1. Next diagnosis prediction
To evaluate the predictive power of the proposed model, we examined its performance in the prediction of the next diagnosis based on a patient's prior diagnosis history, and compared this with the performance of the Markov process-based approach described previously; see Equations (1)–(3). Both methods were trained using an 80–20 split of data into training and test. Specifically, 80% of the data corpus were used to learn the model parameters—conditional probabilities
A summary of the results is given in Figure 7, which shows the cumulative match characteristic (CMC) curves corresponding to the two methods—each point on a curve represents the proportion of cases (ordinate) for which the actual correct diagnosis type is at worst predicted with a specific rank (abscissa). The first thing that is readily observed from the plot is that the proposed method (blue line) vastly outperforms the Markov process-based approach (red line). What is more, the accuracy of our method is rather remarkable—it correctly predicts the type of the next diagnosis for a patient in 82% of the cases (rank-1). Already at rank-2, the accuracy is nearly 90%. In comparison, the Markov process-based method achieves only 35% accuracy at rank-1, less than 50% at rank-2, and reaches 90% only at rank-17.
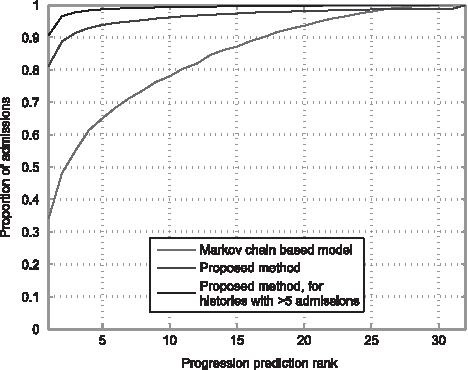
Cumulative match characteristics (CMCs) for the prediction of the next diagnosis from a patient's history.
It is interesting to observe a particular feature of the CMC plot for the proposed method. Notice its tail behavior—at rank-25 and higher, the Markov process-based approach catches up and actually performs better. Although performance at such a high rank is not of direct practical interest, it is insightful to consider how this observation can be explained, given that it is highly unlikely for it to be a mere statistical anomaly, considering the amount of data used to estimate the characteristics. The answer is readily revealed by considering the plot in Figure 8, which shows the dependency between the average rank of the proposed method's prediction and the length of the partial history used as input. Specifically, notice that higher ranks (i.e., worse performance) are associated with short histories. Put differently, when there is little information in a patient's history, there is more uncertainty about the patient's possible future ailments. This observation too strongly supports the validity of our model as it shows that accumulating evidence is used and represented in a more meaningful and robust way, which allows for the learning of complex interactions between conditions and their development. Finally, this is illustrated in Figure 7, which also shows the plot of the proposed method's CMC curve restricted to test histories containing at least five prior diagnoses. In this case, rank-1 and rank-2 performances reach the remarkable accuracy of 91% and 97%, respectively.

Partial history length versus next diagnosis prediction rank.
4.2.2. Long-term prediction
Given the outstanding performance of our method in predicting the type of the next diagnosis given the patient's current medical history, we next considered how the proposed model performs in long-term predictions. Considering that we are now dealing with sequences of future diagnoses and thus a much greater space of possible options, the characterization of performance using CMC curves is impractical. Rather, we now compare our approach with the Markov process-based method by using the corresponding conditional probabilities for the actual progression observed in the data. In other words, for the prediction following a partial history
A positive value of
A summary of the results is presented in Figure 9. Specifically, the plot shows the cumulative distribution function (CDF) of the log ratio
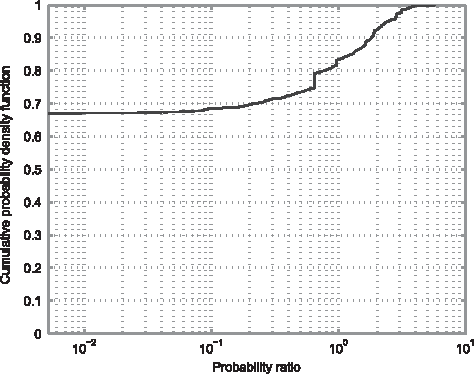
Cumulative density function of the ratio of the probabilities of true patient medical history progression for the diagnoses-level Markov process approach and the proposed method.
4.3. Assessing model scalability
Our primary goal here is to examine how the predictive performance of the history vector-based model is affected by the choice of the number of salient diagnostic codes (Vasiljeva and Arandjelović, 2016a). As in Arandjelović (2015b), we too assess the quality of a specific prediction by considering the rank of the ground truth diagnostic code in the probability ordered list of predictions. Formally, let dt be the ground truth diagnostic code that follows a particular history H. Then the rank r of dt is given by the number of diagnostic codes that the model predicts as following H with at least the probability
We used the same granularity of codes as the original work described in Arandjelović (2015b).
Furthermore, we adopt the usual “leave one out” evaluation protocol, whereby the performance of the method is tested with each patient's data in turn and the model trained using the data of all other patients. To quantify the aggregate performance of the model for specific model parameter values (i.e., the number of salient diagnoses included in the history vector representation), we use two well-known measures. These are the average rank (a special case of the average normalized rank (Salton and McGill, 1983) when the set of target matches is exactly equal to 1) and the normalized area under the CMC curve. For each possible rank r (
We started by looking at the effect that changing the number of salient diagnosis types, that is, diagnosis codes with the corresponding (1-to-1) elements in the history vector, has on the area under the CMC curve. Our experimental results are captured by the plot in Figure 10a. The plot can be readily seen to support our hypothesis that predicted a decay in the adopted model's prediction performance for an increasing number of explicitly modeled diagnoses. Notwithstanding this unwelcome qualitative observation, the major result is of a quantitative nature—the rate of the aforementioned decay is very slow indeed. Like many other natural phenomena, the decay exhibits a power law form with the associated exponent value, which differs from 1 by only 5 parts in 100,000, that is, it is equal to
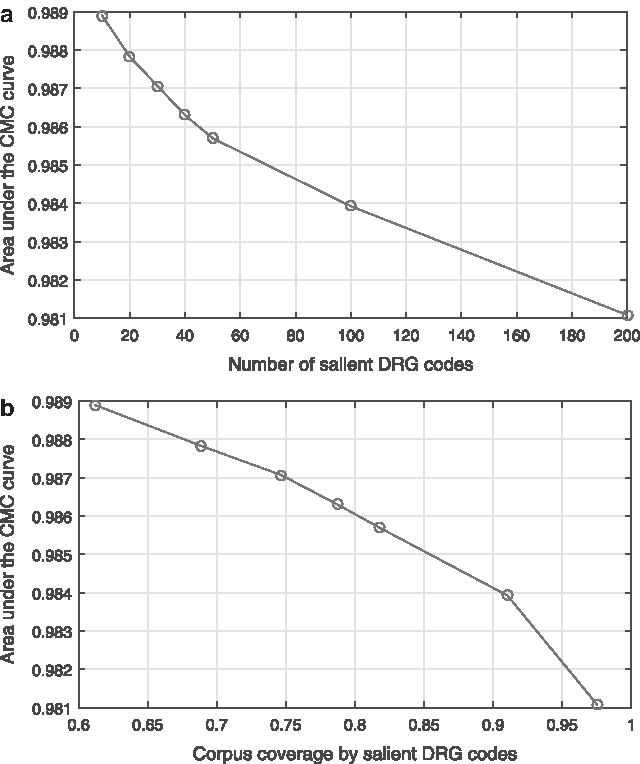
The normalized area under the CMC curve.
We next examined the average prediction rank of the correct diagnosis type, which offers further insight into the performance of the adopted method. As expected from the previous set of findings, the results summarized by the plots in Figure 11a and b corroborate the observation that an increase in the dimensionality of history vectors, a key parameter of the method, worsens performance. In this experiment, this worsening is exhibited as an increase in the average rank (i.e., a greater number of incorrect predictions are made with a higher probability than the actual ground truth diagnosis type). It is interesting to note the significance of what appears to be a much more rapid performance deterioration in terms of this performance measure in comparison with the area under the CMC curve discussed previously. For example, although the use of 200 versus 10 most frequent diagnosis codes effects a reduction of only 0.5% in the area under the CMC curve, the corresponding change in the average rank of the correct diagnosis type increases fivefold (from ∼1.5 for 10 salient codes to ∼7.3 for 200 salient codes). The explanation for this apparent discrepancy is in fact reassuring as it demonstrates that the most dramatic changes in the predicted rank happen for predictions that are already not very good, that is, the small number of bad predictions becomes even worse, rather than good predictions becoming bad.
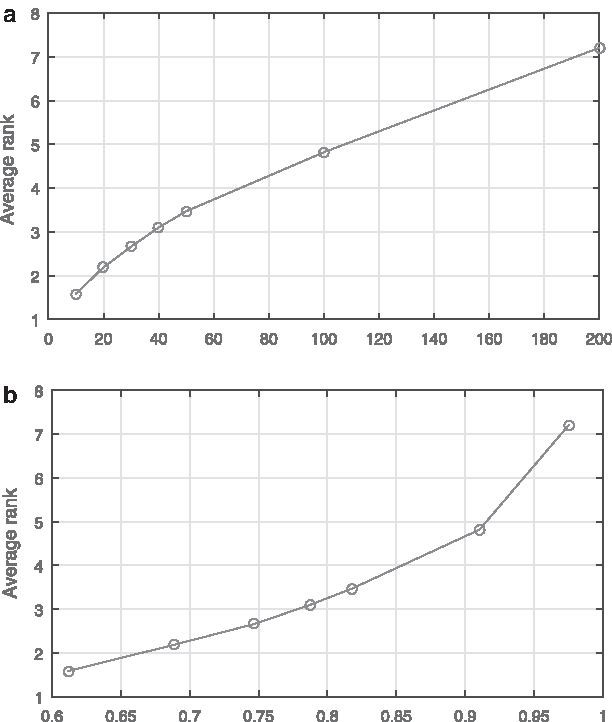
The average prediction rank of the correct diagnosis type.
Lastly, to examine in additional detail of how an increase in the number of explicitly modeled diagnosis types affects predictions, we looked at prediction rank histograms for different diagnosis codes and the corresponding changes as their number was changed. Figure 12a and b contrasts the histograms for 20 and 50 salient diagnosis types. It is remarkable to observe that in both cases the histograms are virtually identical across different codes within the same model. Rather than being effected by subpar histograms of the added codes, the (small, as demonstrated previously) deterioration in predictive performance as the number of salient diagnosis types is increased is effected by slightly worse predictive performance uniformly distributed across different diagnoses. This is highly preferable in practice as it implies that for a fixed model, complexity predictive power remains the same regardless of the patient's ailment. Were it otherwise, the predictions would be more difficult to interpret and the model complexity more challenging to set appropriately as the model's predictive performance would exhibit dependence on the nature of the health problems affecting a specific patient.
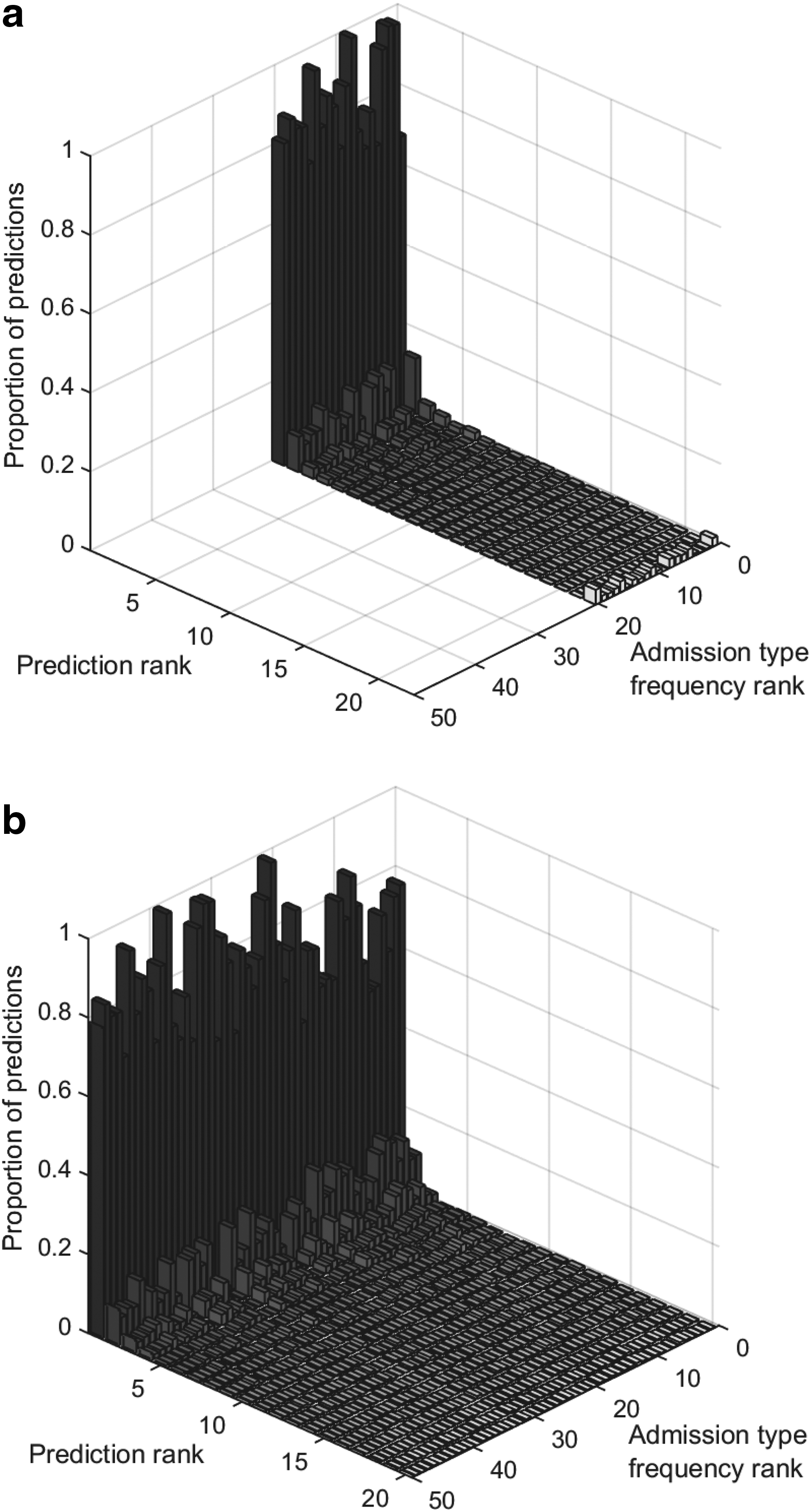
Prediction rank histograms across different diagnosis codes using
4.3.1. Assessing the effects of incorporating explicit clinical knowledge
First, we examined how the number of transition merges changes with the variation in the values of the two free parameters, namely the merging threshold tm and the relative risk weighting constant Cx in Equations (9) and (10). We applied our method to the entire EHRs data set, although, as noted in the previous section, in practice it is likely that different parameters would be applied to different subtrees of the diagnosis coding hierarchy.
Our findings are summarized by the surface plot shown in Figure 13. Although it is inherently the case that increasing tm cannot reduce the number of merges made, the characteristics of the corresponding change are insightful to the clinician in that they can be used to guide the choice of the risk weighting constant. Notice, for example, that the number of effected merges increases approximately linearly across the entire range of tm for Cx smaller than ∼0.5, whereas for Cx greater than 0.5, there is a much more sudden increase.
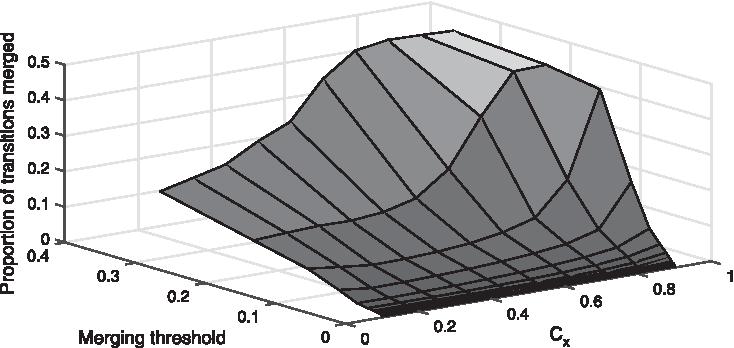
Surface plot showing the number of pair-wise merges performed (as the proportion of all possible transitions pairs that could possibly be merged) as a function of the adjustable parameters of the proposed method, namely the merging threshold tm and the relative risk weighting constant Cx in Equations (9) and (10).
Next we examined salient diagnoses df (see Section 3.2) associated with the greatest number of merges. We noticed that the diagnosis of stroke was one of the particularly represented diagnosis among these, across different values of tm and Cx, so we examined the corresponding merging behavior in more detail. Interpreted intuitively, this means that on average the diagnosis of stroke has the least effect on (from the set of salient diagnoses included in the history vector) the prognosis of other ailments. The family of curves for different values of Cx, showing the variation of the number of merges (as the proportion of all possible transitions pairs that could possibly be merged and associated with transitions effected by the diagnosis of stroke) as a function of the merging threshold tm, is shown in Figure 14. It is insightful to observe that much like as shown in Figure 13, an increase in Cx results in more merges for the same value of tm. A careful consideration of characteristics such as this one is crucial in the practical deployment of the proposed method, and the choice of granularity (in the context of the diagnosis coding hierarchy) at which the method is applied and its parameters.
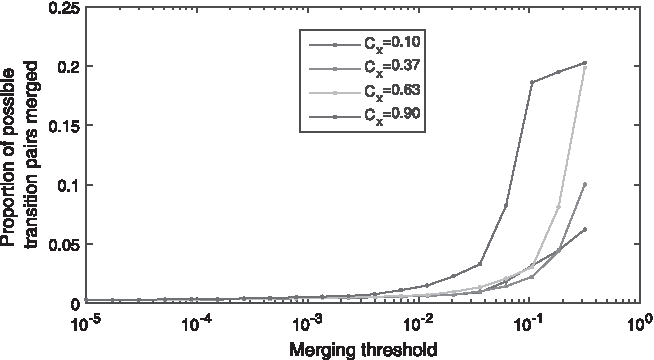
The number of effected merges associated with the diagnosis of stroke (as df in Section 3.2) as the proportion of all possible transitions pairs that could possibly be merged and associated with transitions effected by the diagnosis of stroke.
5. Summary and Future Work
In this article, we introduced a novel algorithm that uses machine learning on EHR collections for the discovery of longitudinal patterns in the diagnoses of diseases. The two key technical novelties are (i) a novel learning paradigm that enables greater learning specificity and (ii) a method for risk-driven identification of confounding diagnoses. A series of experiments were presented to demonstrate the effectiveness of the proposed techniques. Novel insights resulting from our experimental findings were also discussed and highlighted.
As regards possible future work directions, a number of possibilities were proposed by the authors of the original history vector-based approach that the present method was partly inspired by. Although we agree with most of these in broad terms, our contributions, experiments, and results suggest what we believe to be more promising immediate alternatives. In particular, although we agree with the authors of the original method that the presence of a particular episode of care is a predictive factor not much weaker than the exact number of episodes (which would require a prohibitively large amount of training data to learn), we believe that history vector binarization is an overly harsh step for the reduction of the learning space. Following the spirit of the method introduced in this article, we intend to explore the possibility of automatically detecting chronic types of episodes of care (dialysis, for example) and then using a binary representation for nonchronic and a more graded representation for chronic conditions.
Footnotes
Author Disclosure Statement
No competing financial interests exist.