Contemporary workflow management systems are driven by explicit process models specifying the interdependencies between tasks. Creating these models is a challenging and time-consuming task. Existing approaches to mining concrete workflows into models tackle design aspects related to the diverging abstraction levels of the tasks. Concrete workflow logs represent tasks and cases of concrete events—partially or totally ordered—grounding hidden multilevel (abstract) semantics and contexts. Relevant generalized events could be rediscovered within these processes. We propose, in this article, an ontology-based workflow mining system to generate patterns from sequences of events that are themselves extracted from texts. Our system T-GOWler (Generalized Ontology-based WorkfLow minER within Texts) is based on two ontology-based modules: a workflow extractor and a pattern miner. To this end, it uses two different ontologies: a domain one (to support workflow extraction from texts) and a processual one (to mine generalized patterns from extracted workflows).
1. Introduction
Workflows (Taylor et al., 2014) are increasingly used as an efficient way of managing complex resolutions of domain problems (such as in bioinformatics). This caters to a growing popularity of workflow platforms offering a wide spectrum of analytical services (Blankenberg et al., 2001; Lord et al., 2012; Wolstencroft et al., 2013). However, to build successful workflows, the user must typically master a large variety of methods, tools, data formats, etc. In many cases, the ultimate success of the workflows depends on the right choice of included methods, software parameters, and versions, etc. In fact, such a demanding environment reduces the value of workflow management systems for nonexpert users. Facing these challenges, Process Mining (Ellis et al., 2006; Van der Aalst, 2016), a branch of Knowledge Discovery from Data (Fayyad et al., 1996), studies the discovery of reusable knowledge from databases of process records, in particular, from workflow representations such as execution logs. As workflows have an inherent graph structure, effective process mining methods face the related complexity issues. A workflow graph depicts an analytical resolution in terms of blocks and their interactions (control/data flows) drawn as nodes and links, respectively. Yet, given the large spectrum of possible inputs, it is unlikely for a recorded workflow to fully fit a new situation.
A solution could be to mine higher level of abstractions summarizing commonalities of a set of workflows. Representing abstraction levels using ontologies to assist mining of usage logs has proven popular in the last decade (Dai and Mobasher, 2002; Senkul and Salin, 2012). A complete framework for abstracting ontology-based patterns out of clickstreams (from the logs of a semantic web portal powered by a domain ontology) provides an alternative view (Adda et al., 2010). Yet, here, we deal with a comparable problem on a different type of input format. Instead of pure sequences, we consider workflows as direct acyclic graphs (DAGs). However, due to the complex nature1 of the underlying domain problem, the DAGs are split into ordered layers.
The rest of the article is organized as follows: Section 2 presents related work and background information on pattern mining. In Section 3, we define the pipeline of our approach to extract workflows from texts and thus mining abstract patterns from them. Section 4 presents the experimental evaluation and results on bioinformatic workflows, that is, Phylogenetics, and Section 5 concludes the article.
2. Background and Related Work
Given a universe of items O, a database \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal D} = \{ W \} $$
\end{document} of records (e.g., processes) \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$w \in W$$
\end{document} combining items from O, and a frequency threshold \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\sigma$$
\end{document}, the pattern mining goal is to extract the family \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \mathcal{F}_ \sigma }$$
\end{document} of patterns p present in at least \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\sigma$$
\end{document} records. Two binary relationships are generally used in the pattern mining problem combining hierarchies: the generality2 between patterns \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sqsubseteq _ \Gamma }$$
\end{document} (where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\Gamma$$
\end{document} is the pattern language) and the instantiation ∢ between a data record and a pattern.
Inspired from the work of Bamshad Mobasher (1995), including knowledge representations in pattern mining domain, Srikant and Agrawal (1996) propose to use hierarchies in their generalized sequential pattern algorithm which searches for \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \mathcal{F}_ \sigma }$$
\end{document} through the pattern space \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\langle \Gamma , { \sqsubseteq _ \Gamma } \rangle$$
\end{document} by exploring the monotony in frequency w.r.t the generality operator \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \sqsubseteq _ \Gamma }$$
\end{document}. Their Apriori miner performs a level-wise top-down traversal of the pattern space. On item sets, it examines patterns at level k—that is, of size k—on two points: the method computes the frequency of candidate patterns by matching them against the records in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal D}$$
\end{document}, whereas it generates \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$k + 1$$
\end{document} candidates by combining pairs of frequent k-patterns. However, their approach is expensive in terms of memory and computation. Their representation of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal D}$$
\end{document} becomes huge while exploring deeper levels on the hierarchy. Han and Fu (1995) use associations in one level at a time, while Fortin and Liu (1996) propose an oriented object (OO) representation to generate association rules of different levels of abstraction. Furthermore, Phillips and Buchanan (2001) propose prolog ontologies in an inference rule-based system using the first logic order language. Zhou and Geller (2007) propose a generalization impact measure based on support to estimate the sufficient level of abstraction to generate interesting generalized patterns.
Adda et al. (2010) propose a fully blown ontology. First, the data sequences are enriched with domain properties from the domain ontology. The resulting structures are akin to labeled digraphs, in which vertices are objects O and edges represent links \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\mathcal{L}$$
\end{document} between objects or the induced sequential order. Patterns are generalized ontological digraphs, that is, made of sets of ontology classes connected by properties (plus sequencing). Matching between data sequences and patterns is defined on top of the standard ontological instantiation between objects and classes and represents an order preserving injective graph morphism. Their proposed xPMiner method applies an Apriori-like level-wise mining whereby levels in the pattern space are defined w.r.t. the overall depth of the pattern elements within the ontology. Candidates of level \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$k + 1$$
\end{document} are generated from k-level frequent patterns by a refinement operator (see De Raedt, 2008). A major shortage of the proposed approach is the cost of the plain pattern-to-data matching operation. Indeed, as no optimization is proposed, the large number of labeled digraph morphism computations takes a significant toll on the method performances.
In our own study, we choose to enhance that approach by saving in the memory previous matched sequences (from level k) using the last operation information from the refinement operator. In addition, data records, that is, workflows (instead of sequences) that we deal with, are partially ordered multisets where sets (transactions) represent workflow steps, hence forming (double)-layered DAGs. In this study, DAG nodes represent tasks, parameters, data, and metadata items and edges represent the control and data flows. In addition, these elements are extracted automatically from scientific texts.
3. T-GOWler: Ontology-Based Workflow Pattern Acquisition from Texts
We describe, in this section, the pipeline of the methods to extract abstract patterns within texts. The proposed T-GOWler (see first Reference on page 807) system contains two main engines: (1) WfExtractor extracts workflows W from texts and builds a workflow database \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${{ \cal D}_W}$$
\end{document} and (2) WfMiner mines frequent generalized patterns \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\mathcal{F}$$
\end{document} from \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${{ \cal D}_W}$$
\end{document} (Fig. 1). The first module [developed on GATE platform3 by Cunningham et al. (2009)] requires plain text articles and a resource description framework (RDF)4 domain ontology representing the domain terminology (Gazetteer) categorizing, into abstract concepts and relationships, domain terms. The extraction pipeline is based on a simple natural language processing (NLP) chain and a specific workflow tagger to classify workflow components, that is, objects O and links \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\mathcal{L}$$
\end{document}, into their ontological categories, that is, concepts C and relationships \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\mathcal{R}$$
\end{document}, respectively. To preserve process order in workflows, abstract patterns from the processual ontology are used. Once the ontology is loaded and concrete workflows are reconstructed, the WfMiner tool deals with generation of frequent patterns using a level-wise pattern generation on the top of the ontology and a specific pattern-to-workflow matching algorithm to filter nonfrequent patterns.
T-GOWler system architecture.
3.1. WfExtractor: workflow extraction from texts
The extraction process takes place in three different steps: (1) named entity (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$o \in O$$
\end{document}) extraction, (2) link (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$l \in \mathcal{L}$$
\end{document}) extraction, and (3) workflow \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$w \in {{ \cal D}_W}$$
\end{document} reconstruction from the extracted elements. Yet, before workflow component extraction, a classic NLP tool chain is executed to tag terms with their morphosyntactic tags, that is, grammatical classes within sentences. This chain comprises (1) the specialized biomedical tokenizer (Settles, 2004) and a simple sentence splitter (Bontcheva et al., 2013), (2) the MedPost/SKR POS (semantic knowledge representation part of speech) tagger (Smith et al., 2004), and (3) the lightweight OpenNLP chunker (Buyko et al., 2006) to identify active and passive verb phrases in texts.
For both named entity and link extraction, a domain ontology is applied as a gazetteer to recognize workflow elements in texts. However, this process faces some hurdles due to the syntactic and semantic ambiguities, that is, polysemy (Stevenson and Wilks, 2003), in some domain concepts. For instance, the program term MEGA (Kumar et al., 2016) could be used to either validate the phylogenetic hypothesis or to visualize output data, for example, phylogenetic trees. Thereof, we propose to use a supervised machine learning approach (Nadeau and Sekine, 2007) to disambiguate software contexts using specific Java Annotation Patterns Engine (JAPE) rules.5 For example, when the passive verb phrase (context) contains a program term in its object and the root verb is a synonym to valid (from the HypothesisValidation concept), then its probability to be a validation program is very high.
Hence, for each polysemic term in the texts, we create two rules: one for the active and the other for the passive voice phrases. In such way, a learning set is constructed. Next, two sets of features are calculated to annotate ambiguous terms automatically, that is, (1) POS annotations and (2) surrounded concepts (domain concepts in the context sentence of the ambiguous word) in a window of the five next and previous concepts and tokens. To represent our context-based extracted features, the Perceptron Algorithm with Uneven Margins (PAUM) model (Li et al., 2002) is applied to learn word sense disambiguation (Stevenson and Wilks, 2003) and relationship classifications from the extracted feature instances. PAUM is specifically designed to simulate the distance between positive and negative examples, which fits the nature of our features since positive and negative contexts are represented with distance-based features (in POS tags and concepts in the same sentence).
For the relationship side, we adopt the following hypothesis: a link between two related concepts exists in the same sentence evoking the instances of its domain (source term) and range (destination term). Such link is represented in the verb located between the concerned terms (depending on the sentence voice). Hence, to recognize links in texts, we map the couple \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${c_1} , {c_2}$$
\end{document}, from the triple \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\rho = ( {c_1} , r , {c_2} )$$
\end{document} in the ontology, on text sentences. For example, for the relationship instances of r: isRetrievedIn, defined with c1: DataType as the relationship domain and c2: Database as the relationship range, we tag the context of the link with its relationship type, for example, alined in in the text is tagged with the isRetrievedIn relationship. A PAUM model is then constructed using the following set of features: (1) token POS tags, (2) distance, (3) direction, and (4) the list of verbs between domain and range instances in the context phrase.
Finally, from the recognized links between named entities in texts, we build a concrete workflow knowledge database \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${{ \cal D}_W}$$
\end{document} where items are named entities ordered by the genInputTo properties (relationships) from the processual ontology. For example, from the tuples: (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \rho _1}$$
\end{document}) (16srRNA, “isInputOf,” ClustalW), (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \rho _2}$$
\end{document}) (ClustalW, “genInputTo,” PHYLIP), and (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \rho _3}$$
\end{document}) (PHYLIP, “genInputTo,” TreeView), we construct the sequence \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\langle$$
\end{document}{{16srRNA}, {ClustalW}, {PHYLIP}, {TreeView}}, {(1, “isInputOf,” 2)}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\rangle$$
\end{document} where 1 and 2 correspond to the domain and range positions, respectively, in the workflow sequence.
3.2. WfMiner: mining generalized workflows
In this study, we propose a new approach to generate generalized subgraphs of workflows out of concrete ones. We propose two descriptive languages to represent the pattern space. The data language \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \Delta _w}$$
\end{document} is derived from sequences of objects and sets of link IDs from the processual ontology \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\Omega$$
\end{document}. For instance, the workflow DAG w1 in Figure 2 is a poset \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$w. \zeta$$
\end{document} of object items \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$i \in \{ 1 , ..7 \} $$
\end{document} and a set of link triples \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$w. \theta$$
\end{document} with link types \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$l \in \{ 1 , ..6 \} $$
\end{document}. The second language \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \Gamma _w}$$
\end{document} is used to represent a pattern p as an abstraction of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$w \in {{ \cal D}_W}$$
\end{document} (e.g., w1∢p1: w1 instantiates p1). Hence, we represent a pattern p as a sequence of concept item sets \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$p. \zeta$$
\end{document} and a set of relationship triples \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$p. \theta$$
\end{document}.
Workflow and pattern representations.
Level-wise descent in the pattern space relies on the generation of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$k + 1$$
\end{document}-level patterns from k-level ones, which amounts to the computation of five canonical operations in a Depth-First search strategy from the ontology: (1) appC—appends a root concept to a new transaction, (2) addC—adds a root concept to the last transaction, (3) addR—adds a root relationship between a concept and the last one in the last transaction, (4) subC—specializes the last concept, and (5) subR—specializes the last relationship in the pattern. Hence, for each pattern p, we apply all the five canonical operations. Although these operations constitute an effective generation mechanism, their unrestricted use is redundancy-prone and hence would harm the efficiency of the global mining process. In the previous work of Adda et al. (2007), calculating the support of a pattern p amounts to match p with all the workflow concrete sequences in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${{ \cal D}_W}$$
\end{document}.
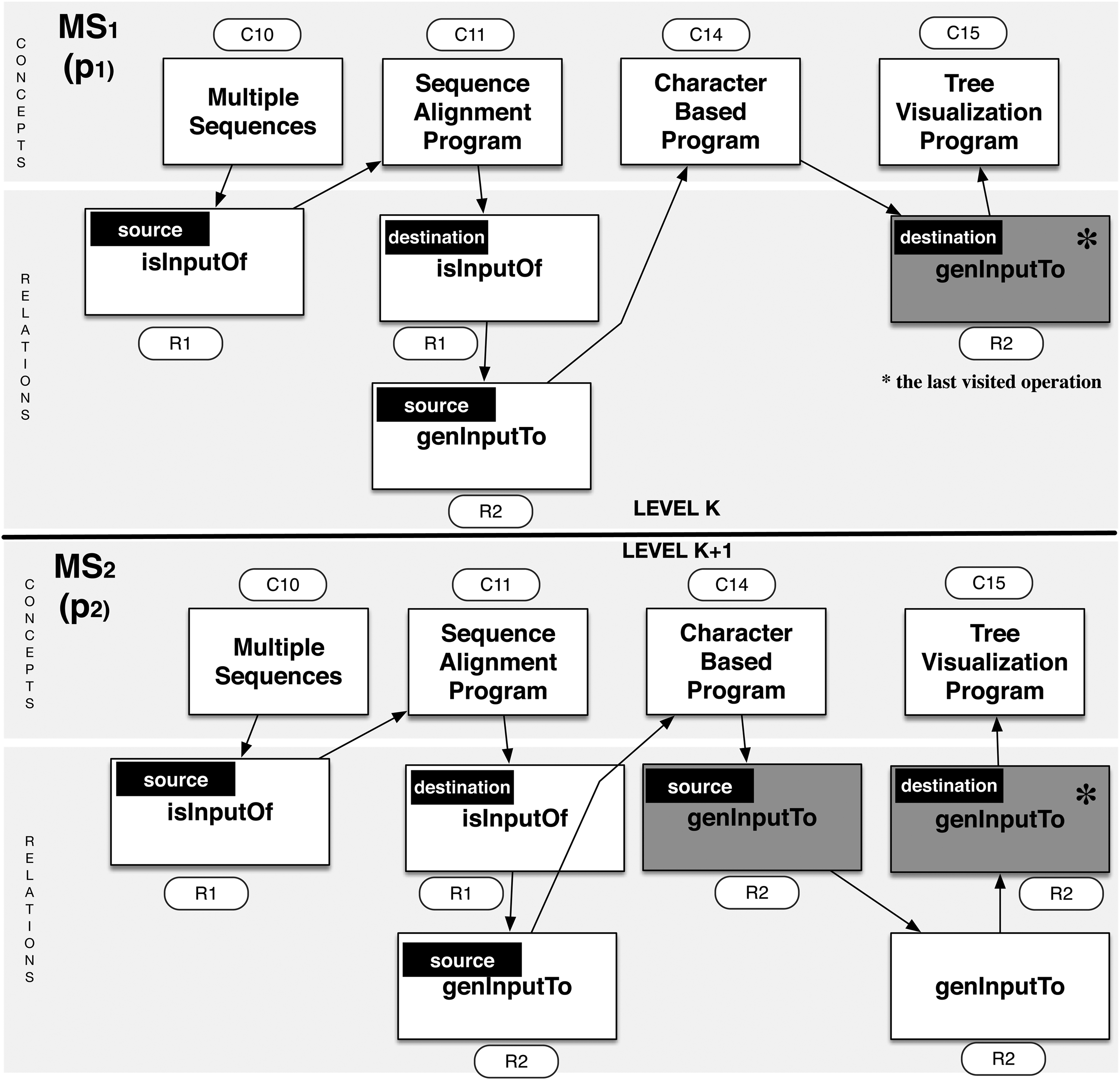
For this purpose, we introduce a new data structure to prune patterns while calculating their supports using the generality relationship between them. Calculating frequent patterns \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${p^{k + 1}}$$
\end{document} begins from the last visited concept/relationship in the parent pattern pk and hence we do not need to recalculate all the matching possibilities for each concept and relationship previously matched at level k. The proposed matching structure MS is a stack of operation results (adding/specializing concepts/relationships) on parent patterns. For example, the arrows in Figure 3 show the way we obtain a pattern p2 using the refinement operator. Calculating the support of p2 is done starting from the last operation on p1, that is, addR(r2, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${c_{11}}$$
\end{document}). If the next operation in the \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$k + {1^{th}}$$
\end{document} iteration is to add another relationship addR(r3, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${c_{14}}$$
\end{document}) to p2, then the matching structure of p2 (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$MS ( {p_2} )$$
\end{document}) puts relationship blocks (source and destination relationship blocks s) in their proper positions and calculates the possible matchings from the matching set of the parent pattern \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$MS ( {p_1} )$$
\end{document}.
Pattern matching structures over levels k and k + 1.
4. Experiments and Results
4.1. Case study: phylogenetic analyses
Phylogeny (Anne-Mieke, 2009) represents the evolutionary history of a group of organisms having a common ancestor. Inferred from nucleic acid (DNA or RNA) or protein sequences, phylogenetic relationships are discovered with tools detecting different evolutionary phenomena such as duplications, insertions, and deletions (see Anisimova et al., 2013). We downloaded more than 3000 scientific articles (published from 2013 until April 2015) about phylogenetic studies from the PubMed Central (PMC) repository6 in XHTML format. In addition, we constructed a terminology from different well-known databases in the phylogenetic literature such as the UniprotKB7 (for gene and protein names), Gene Ontology (Ashburner et al., 2000), Taxonomy Browser,8 and the Felsenstein web site.9 This gazetteer is then reorganized in a domain ontology to recognize terms and relationships in texts such as described in the WfExtractor module. Next, we build, manually, a processual ontology with the help of experts. An example of an abstract processual knowledge is (1) Protein collected from the PDB database10are fed to (2) a homology search program and (3) a phylogenetic inference one. Finally, both domain and processual ontologies are merged into one11 (Fig. 4) to mine frequent patterns from the workflow database using the WfMiner engine.
A portion from the phylogenetic PHAGE ontology (which merges domain and processual ontologies). Step concepts (a) represent processual tasks (activities). Parameter concepts (b) are program parameters from the step subhierarchy. Datatype concepts (c) are input/output data and data sources (d) are annotations on data. PHAGE (phylogenetics analyses ontologies).
4.2. Named entity learning results
An expert has annotated, manually, 100 phylogenetic sections to build a reference workflow database. Each extracted term has been compared with the proposed PAUM model's results to validate (with 10-fold cross-validation) their accuracies in terms of precision and recall and fMeasure (Table 1). Models' context features have well-learned and applied several top-level domain relationship and concept terms, that is, data types, gene ontology annotations, phylogenetic methods, and phylogenetic inference programs. In total, 1469 workflow objects have been extracted from the phylogenetic analysis sections with an average of 71% of fMeasure. In the relationship side, the system annotated 325 links with 72% of precision and 84% of recall (78% of fMeasure). Hence, workflow overall fMeasure is 73%. Indeed, with only context POS tags and concept neighbors, we did recognize workflow components in texts with good accuracy.
Evaluation Results of the Extracted Workflow Elements Based on the Expert-Curated Dataset from the PubMed Central Articles (Published from January 2013 to April 2015)
Concept/Relationship
No. of instances
Precision
Recall
fMeasure
DataType
597
0.68
0.75
0.71
GeneOntology
139
0.94
0.44
0.60
Taxon
202
0.72
0.58
0.64
Method
326
0.84
0.84
0.84
InferenceProgram
205
0.56
0.88
0.68
Overall (concepts)
1469
0.74
0.69
0.71
Overall (relationships)
325
0.72
0.84
0.78
Overall
1794
0.74
0.72
0.73
The table shows the number of annotated instances of (some—from the top level of abstraction) concepts and relationships and their precision, recall, and fMeasure evaluation values.
4.3. Generalized pattern results
For the rest of our experiments, we consider only expert-curated datasets (that we call here PhyloFlows) to assess the WfMiner module. This database comprises 300 workflows with an average of 11 object items and 9 links per workflow. In addition, we use the eTP-tourism (Electronic Tourism Platform) workflow database, which is a portion of a log file describing Web page navigation of 56 different users in a Web travel site (Adda et al., 2010). This database has an average of 19 different items and 6 links per sequence enhanced by an ontology of 157 concepts and 35 object properties.
Figure 5A shows the difference in mining time between the PhyloFlows and eTP-tourism databases. Running time does eventually increase when more concepts and links are mined. Our system spends ∼10 times the mining time to generate patterns with more than 500 items and 100 links. While eTP-tourism database presents more dense graphs, matching subgraphs and mining processes become heavier to handle. However, taking 23 seconds to do the whole process of matching and generating ∼6000 frequent graph patterns is still a reasonable time. In addition, our WfMiner outperforms xPMiner by Adda et al. (2010) (Fig. 5B) with twice the order of magnitude in high threshold supports (>0.8). With 60% of minimum support, our approach executes ∼10 times faster the mining algorithm than xPMiner.
(A) Varying support for PhyloFlows and e-TP tourism databases. (B) Comparing the mining running time of WfMiner and xPMiner.
Finally, we present in Table 2 a sample from the generated set of patterns obtained from the PhyloFlows database. These patterns could be used in a semantically rich recommendation framework considering the diversity of levels of abstraction in pattern representations. For instance, if we know that the \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$16s$$
\end{document}rRNA gene is used as input in the ClustalW alignment program (Thompson et al., 2002), then a concrete recommendation could offer, for example, MrBayes (Ronquist and Huelsenbeck, 2003), as a phylogenetic inference tool (∼1% frequent). However, offering any character-based inference program (see second pattern in Table 2) is a more relevant recommendation due to its (pattern) higher frequency (∼10%) in the database since it contains more general concepts.
A Sample from the Phylogenetic Extracted Patterns Within the Texts in the PubMed Central Database (Articles Published from January 2013 to April 2015)
Generated DAG patterns are sequences of concept multisets and sets of relationship triples. For instance, in the first pattern: (1, isInputOf, 2) represents the input relationship between the first concept (DataType) and the second one (DataCollection) in \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$p. \zeta$$
\end{document}.
DAG (direct acyclic graph).
5. Conclusion
Our ontology-based approach to mining generalized patterns from texts proves that different kinds of knowledge could be extracted from the phylogenetic literature. Processual and domain knowledge from articles shows interesting patterns to mine. Different ontologies have been used to represent the different types of knowledge into concepts and relationships. Extracted workflows are enhanced with ontological annotations to produce generalized frequent patterns. These latter, covering a wider range of values then concrete elements, could be used to assist practitioners during their problem-solving task with a richer vocabulary. The proposed system could also be applied to different domains when expertise is confronted to domain knowledge. Video games, for example, are a good domain application to our approach when gamers constantly face cognitive processual gestures. Workflows of events could be then extracted from game sessions and mined to recommend and predict generalized patterns such as what type of event is going to happen during a game based on gamer logs or what kind of item a player is willing to buy to accomplish a mission.
Footnotes
Acknowledgment
This work has been partially supported by the NSERC Discovery Grants of Canada to the second and third authors.
AddaM., ValtchevP., MissaouiR., et al.2007. Toward recommendation based on ontology-powered web-usage mining. IEEE Internet Computing., 11:45–52.
3.
AddaM., ValtchevP., MissaouiR., et al. 2010. A framework for mining meaningful usage patterns within a semantically enhanced web portal. In Proceedings of the Third C* Conference on Computer Science and Software Engineering, pp. 138–147. ACM.
4.
AnisimovaM., LiberlesD.A., PhilippeH., et al.2013. State-of the art methodologies dictate new standards for phylogenetic analysis. BMC Evol. Biol., 13:161.
5.
Anne-MiekeL.P.S.M.V.2009. The Phylogenetic Handbook: A Practical Approach to Phylogenetic Analysis and Hypothesis Testing. Cambridge University Press, Cambridge, UK.
6.
AshburnerM., BallC.A., BlakeJ.A., et al.2000. Gene ontology: Tool for the unification of biology. Nat. Genet., 25:25–29.
7.
Bamshad MobasherS.S.A.1995. The role of domain knowledge in data mining. In Proceedings of the 4th International Conference on Information and Knowledge Management, pp. 37–43. ACM.
8.
BlankenbergD., KusterG.V., CoraorN., et al.2001. Galaxy: A Web-Based Genome Analysis Tool for Experimentalists. Curr Protoc Mol Biol Chapter 19:Unit 19.10.1–21.
9.
BontchevaK., DerczynskiL., FunkA., et al.2013. Twitie: An open-source information extraction pipeline for microblog text. In RANLP, pp. 83–90. Association for Computational Linguistics, Hissar, Bulgaria.
10.
BuykoE., WermterJ., PopratM., et al.2006. Automatically adapting an nlp core engine to the biology domain. In Proceedings of the Joint BioLINK-Bio-Ontologies Meeting. A Joint Meeting of the ISMB Special Interest Group on Bio-Ontologies and the BioLINK Special Interest Group on Text Data Mining in Association with ISMB, pp. 65–68. Intelligent Systems for Molecular Biology.
11.
CunninghamH., MaynardD., BontchevaK., et al.2009. Developing Language Processing Components with GATE Version 5: (a User Guide). University of Sheffield.
12.
DaiH., and MobasherB.2002. Using ontologies to discover domain-level web usage profiles. Presented at Semantic Web Mining 2nd Workshop at ECML/PKDD, Finland.
13.
De RaedtL.2008. Logical and relational learning. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), volume 5249 LNAI, p. 1. Springer Verlag, Secaucus, NJ.
14.
EllisC.A., RembertA.J., KimK.-H., et al.2006. Beyond workflow mining. In DustdarS., FiadeiroJ.L., and ShethA.P. eds. Business Process Management, volume 4102 of Lecture Notes in Computer Science, pp. 49–64. Springer, Berlin, Germany.
15.
FayyadU.M., Piatetsky-ShapiroG., SmythP., et al.1996. Advances in Knowledge Discovery and Data Mining, volume 21. AAAI Press, Menlo Park.
16.
FortinS., and LiuL.1996. An object-oriented approach to multi-level association rule mining. In Proceedings of the Fifth International Conference on Information and Knowledge management, pp. 65–72. ACM.
17.
HanJ., and FuY.1995. Discovery of multiple-level association rules from large databases. In VLDB, volume 95, pp. 420–431. Morgan Kaufman Publishers, Inc. San Francisco, CA.
18.
KumarS., StecherG., and TamuraK.2016. Mega7: Molecular evolutionary genetics analysis version 7.0 for bigger datasets. Mol. Biol. Evol., 33:1870–4.
19.
LiY., ZaragozaH., HerbrichR., et al.2002. The perceptron algorithm with uneven margins. In ICML, volume 2, pp. 379–386. Morgan Kaufman Publishers, San Francisco, CA.
20.
LordE., LeclercqM., BocA., et al.2012. Armadillo 1.1: An original workflow platform for designing and conducting phylogenetic analysis and simulations. PLoS One, 7:e29903.
21.
NadeauD., and SekineS.2007. A survey of named entity recognition and classification. Lingvisticae Investigationes, 30:3–26.
22.
PhillipsJ., and BuchananB.G.2001. Ontology-guided knowledge discovery in databases. In Proceedings of the 1st International Conference on Knowledge Capture, pp. 123–130. ACM.
23.
RonquistF., and HuelsenbeckJ.P.2003. Mrbayes 3: Bayesian phylogenetic inference under mixed models. Bioinformatics., 19:1572–1574.
24.
SenkulP., and SalinS.2012. Improving pattern quality in web usage mining by using semantic information. Knowl Inf Syst., 30:527–541.
25.
SettlesB.2004. Biomedical named entity recognition using conditional random fields and rich feature sets. In Proceedings of the International Joint Workshop on Natural Language Processing in Biomedicine and its Applications—JNLPBA ’04, p. 104. Association for Computational Linguistics, Stroudsbourg, PA.
26.
SmithL., RindfleschT., WilburW.J., et al.2004. Medpost: A part-of-speech tagger for biomedical text. Bioinformatics. 20:2320–2321.
27.
SrikantR., and AgrawalR.1996. Mining sequential patterns: Generalizations and performance improvements. In Proceedings of the 5th International Conference on Extending Database Technology: Advances in Database Technology, EDBT ’96, pp. 3–17, London, United Kingdom. Springer-Verlag.
28.
StevensonM., and WilksY.2003. Word sense disambiguation. In The Oxford Handbook of Computational Linguistics, pp. 249–265.
29.
TaylorI.J., DeelmanE., GannonD.B., et al.2014. Workflows for e-Science: Scientific Workflows for Grids. Springer Publishing Company, Incorporated. London, UK.
30.
ThompsonJ.D., GibsonT., HigginsD.G., et al.2002. Multiple sequence alignment using clustalw and clustalx. Curr Protoc Bioinformatics. Chapter 2:Unit 2.3.
31.
Van der AalstW.2016. Process mining software. In Process Mining, pp. 325–352. Springer.
32.
WolstencroftK., HainesR., FellowsD., et al.2013. The taverna workflow suite: Designing and executing workflows of web services on the desktop, web or in the cloud. Nucleic Acids Res. 41:W557–W561.
33.
ZhouX., and GellerJ.2007. Raising, to enhance rule mining in web marketing with the use of an ontology. In Data Mining with Ontologies: Implementations, Findings and Frameworks, pp. 18–36. Idea Group Inc., Hershey, PA.