
Abstract
Abstract
Most of the existing research in assembly pathway prediction/analysis of viral capsids makes the simplifying assumption that the configuration of the intermediate states can be extracted directly from the final configuration of the entire capsid. This assumption does not take into account the conformational changes of the constituent proteins as well as minor changes to the binding interfaces that continue throughout the assembly process until stabilization. This article presents a statistical-ensemble-based approach that samples the configurational space for each monomer with the relative local orientation between monomers, to capture the uncertainties in binding and conformations. Further, instead of using larger capsomers (trimers, pentamers) as building blocks, we allow all possible subassemblies to bind in all possible combinations. We represent the resulting assembly graph in two different ways: First, we use the Wilcoxon signed-rank measure to compare the distributions of binding free energy computed on the sampled conformations to predict likely pathways. Second, we represent chemical equilibrium aspects of the transitions as a Bayesian Factor graph where both associations and dissociations are modeled based on concentrations and the binding free energies. We applied these protocols on the feline panleukopenia virus and the Nudaurelia capensis virus. Results from these experiments showed a significant departure from those that one would obtain if only the static configurations of the proteins were considered. Hence, we establish the importance of an uncertainty-aware protocol for pathway analysis, and we provide a statistical framework as an important first step toward assembly pathway prediction with high statistical confidence.
1. Introduction
V
Research at understanding the assembled arrangement of capsid proteins in a viral capsid builds on the work of Caspar and Klug (C-K) (Caspar and Klug, 1962). C-K characterize the symmetric organization of proteins in a spherical viral capsid, building on the mathematical foundations of spherical tilings given by Goldberg (1937). C-K show that the combinatorial arrangement of the capsid proteins can be characterized by using simple triangular tiles, each tile consisting of three copies of the protein (a trimer), that cover an icosahedron. Essentially, the entire capsid can be considered as 20T trimers; or as 12 pentamers and 10(T − 1) examers. This concept, called “quasi-equivalence,” states that all the viral protein chains that form a capsid are identical and have (quasi-) equivalent interfaces—essentially, all proteins are involved in the same number of interactions at similar binding sites.
Recent work (Janner, 2006; Keef and Twarock, 2009) has shown that certain aperiodic arrangements involving pentamers or other types of subassemblies are also possible. Other work (Pawley, 1961) has shown that several other symmetry classes also permit decomposition into symmetric subassemblies, and Rasheed and Bajaj (2015) proved necessary and sufficient conditions for such subassemblies to be possible. Brooks and colleagues, in a series of papers, have characterized the geometric conditions for symmetric capsids, provided methods to measure how much a specific capsid conforms to the concept of quasi-equivalence (Damodaran et al., 2002; Carrillo-Tripp et al., 2008; Mannige and Brooks, 2008), and hence how amenable it is to coarse-grained dynamics analysis as described later. Further, they present a simple classification that characterizes variations of hexamers within a capsid (Mannige and Brooks, 2010).
Many of the researchers working on predicting, analyzing, and/or simulating capsid assembly have taken either a set of trimers or a set of pentamers+hexamers as the building blocks of assembly. For instance, Rapaport et al. (1999) performed a coarse dynamics simulation where trimers were used as building blocks. It successfully showed that even simple shape and binding site conditions are sufficient to drive self-assembly. In their more recent work (Rapaport, 2004, 2010), the model was updated to include more complex energetics, and single proteins (monomers) were used as building blocks, instead of trimers.
Hagan et al. (Hagan and Chandler, 2006; Elrad and Hagan, 2008) applied Brownian dynamics simulation with a simplified force field. They modeled each capsomer (which can also be a monomer) by using a single bead model. Based on prior knowledge about the arrangement of such beads on the capsid, they parametrized each bead based on the angles between each pair of their neighbors, and designed a binding affinity function that allowed binding at specific orientations. This concept is similar to the “local-rules” introduced by Berger et al. (Berger and Shor, 1994; Berger et al., 1994), which has been adopted by other groups (Schwartz et al., 1998; Xie et al., 2012) for kinetics and dynamics analysis of capsids. A discussion contrasting the block-like beads used by Rapaport et al. with shape-driven assembly, and the ones used by Hagan et al. with neighborhood-driven assembly can be found in Hagan (2014). Bona and Sitharam also considered a bead-like model (Bona et al., 2011); however, they modeled the interaction of the beads by using geometric stability conditions and predicted the likelihood of binding based on the simplicity of solving the geometric constraints system (Sitharam et al., 2004).
Unlike the dynamics-based analysis techniques described earlier, Zlotnick (1994) applied the statistical thermodynamics law of mass action to relate the concentrations of the constituents and the product of a binding with the binding free energy. Using pentameric building blocks, he enumerated all unique compositions of one or more pentamers (each arranged exactly as it would be if the entire capsid was formed). This technique, and several following publications (Zlotnick, 2005, 2006), revealed various aspects of assembly for different viruses, including rates of assembly, effect of nucleation, detection of possible kinetic traps, etc. It also provided a simple tool to predict the effect of changing environment parameters and/or presence of other molecules, which can be applied to measure yields under different conditions, designing conditions that are amenable to specific assemblies, etc. (Burns et al., 2009; Zlotnick and Mukhopadhyay, 2011).
This article presents an approach to score and rank conformational ensembles of capsid protein capsomers and capsid subassemblies based on a new configurational sampling and energy analysis approach. The sampled configurations of capsid subassemblies represent the various potential intermediate states of a fully assembled viral capsid. In other words, we recognize that the tertiary structure (fold) of individual subunits as well as binding contacts between subunits may evolve over the span of the entire assembly process, and moreover, may exist in slightly different configurations for the same subassemblies. The presence of such uncertainties implies that any binding free energy computed solely based on the structure and interfaces that exist in the final matured state of the capsid is not always accurate. Similar uncertainty quantification and uncertainty propagation methods have recently been used for single-molecule models (Lei et al., 2014; Rasheed et al., 2015) but not for combinatorial arrangements of viral capsid proteins in various capsomeric states.
In our approach, given prior knowledge (in the form of statistical distributions) of the nature of uncertainty, we can provide additional theoretical upper bounds on the distributional moments (Hoeffding, 1963; Azuma, 1967; McDiarmid, 1989) for different properties of viral capsomers, and other quantities of interest (QOI, e.g., the binding free energy). (See for, e.g., Rasheed et al. (2015) for such Azuma-Hoeffding bounds applied to molecular modeling with atomistic positional uncertainty captured by B-factors.) In addition, if the space of configurations is sampled such that low discrepancy (and also low dispersion) is achieved, then a probability distribution of the QOI can be approximated with bounded error (Niederreiter, 1990; Hoogland et al., 1998). Such estimation of binding free energies, that is, as distributions instead of single values, makes it possible to sample energy landscapes through various configurational ensembles, and to analyze binding pathways in an efficient and robust way (Rasheed et al., 2015). We apply our efficient low-discrepancy product-space sampling technique reported in Bajaj et al. (2014) to generate such low-discrepancy sampled ensembles of viral capsomers. The configuration space for any subassembly of the capsid is a product space of the backbone torsion angles between relatively rigid domains, as well as three-dimensional affine transformations between each pair of neighbors.
We construct an assembly pathway graph consisting of all possible state transitions, and we define a Bayesian factor graph parameterized based on the distributions of binding free energies. The state transitions are designed to capture the effect of the binding free energy and the concentration of the constituents under equilibrium (similar to Zlotnick, 1994). This provides a robust approach to predicting and analyzing stable assembly pathways, and to predicting concentrations of all subassemblies, with quantified uncertainty.
1.1. Differences from the CSBW16 version
The findings reported in this article were originally published in the Computational Structural Bioinformatics Workshop (CSBW’16), held in conjunction with IEEE BIBM. In this JCB special issue version of the article, we have expanded on our presentation of the materials and methods for enhanced clarity. In particular, Section 2.1 has been expanded for clarity; seven paragraphs have been added under Section 2.2.2 with a heading “Sampling the configurational space of capsid assembly,” which exposes the application of sampling algorithms specifically for the viral capsid assembly space. A new section (Section 3.1) has been added, which establishes that the number of samples used to model each assembly state was sufficient. Further, Sections 3.3 and 3.4 describe a statistical ranking procedure and corresponding results for identifying likely subassemblies and pathways. We also report extended results on the N. capensis virus (PDBID:1OHF) (Helgstrand et al., 2004). In addition, we analyzed the capsid assembly of the feline panleukopenia virus (PDBID:1C8F) (Simpson et al., 2000), and showcases when this new capsid exhibits assembly behavior departing from intuition. Several new figures (Fig. 2, Fig. 3e–h, Figs. 4–6, Fig. 8, Fig. 12b, and Fig. 13b) and an additional table (Table 1) have been added.
Number of samples defined by Chernoff-like bounds for incremental sampling approach. Most of the subassemblies require fewer than 500 samples; only 1 of the subassemblies in either capsid required more than 900 samples.
2. Methods
One of the major goals of this work is to develop a method for viral self-assembly pathway analysis with statistical guarantees. We consider assembly from an equilibrium perspective, where, given prior knowledge of the final assembled structure, we can uniquely determine the possible subassemblies of different sizes and the possible ways they can be associated/disassociated. We assume, similar to the work of Zlotnick et al. (Zlotnick, 1994, 2005; Zlotnick, 2006; Burns et al., 2009; Zlotnick and Mukhopadhyay, 2011), that the binding free energy of the association governs the success and yield of the reaction. However, we apply a more robust estimation of the binding energy under an uncertainty quantification framework. In addition, we consider all possible assembly pathways starting from monomers, instead of assuming that trimers, pentamers, etc. are the basic building blocks.
The overall methodology for this research is as follows. First, we identify all unique interfaces and unique subassemblies of specific sizes (where “size” is defined as the number of constituent monomers) of a given virus. Second, we sample the space of configurations for each of these subassemblies with restricted range of motion to generate an ensemble of structures in an attempt to capture the uncertainty (flexibility, random perturbations, etc.) of the structure. Then, we compute the free energy of each sample of each subassembly to generate a distribution of the energy. Finally, we use these distributions of energies (instead of the traditional single value) to compare the stabilities of the subassemblies, model state transition, and concentrations by using a probabilistic factor graph representation, and we derive statistical predictions on likely pathways. In the following subsections, we discuss each of these in detail.
2.1. Unique subassemblies and transitions
Analysis of self-assembly focusing on only a predetermined set of pathways fails to take into account subassemblies caught into energy traps, which, nonetheless, may be part of a pathway that is globally favorable to the capsid as a whole (Hagan and Chandler, 2006; Elrad and Hagan, 2008). For this reason, we have sought to implement an exhaustive approach. We consider all possible unique subassemblies and all possible pathways for these subassemblies to be formed.
To begin, we consider each chain to be unique. Even though the chains have the same primary structure, in most cases they exhibit minor differences in their tertiary configuration and, hence, it is preferable to consider each of them as unique—especially when computing binding free energies. For subassemblies involving two or more monomers, we consider them to be equivalent if and only if all three following conditions (evaluated in this order) are met: (1) They have the same number of monomers of each type, (2) they have the same number of symmetric interfaces of each type, and (3) when the atoms of both subassemblies are aligned, the root mean square distance (RMSD) is small.
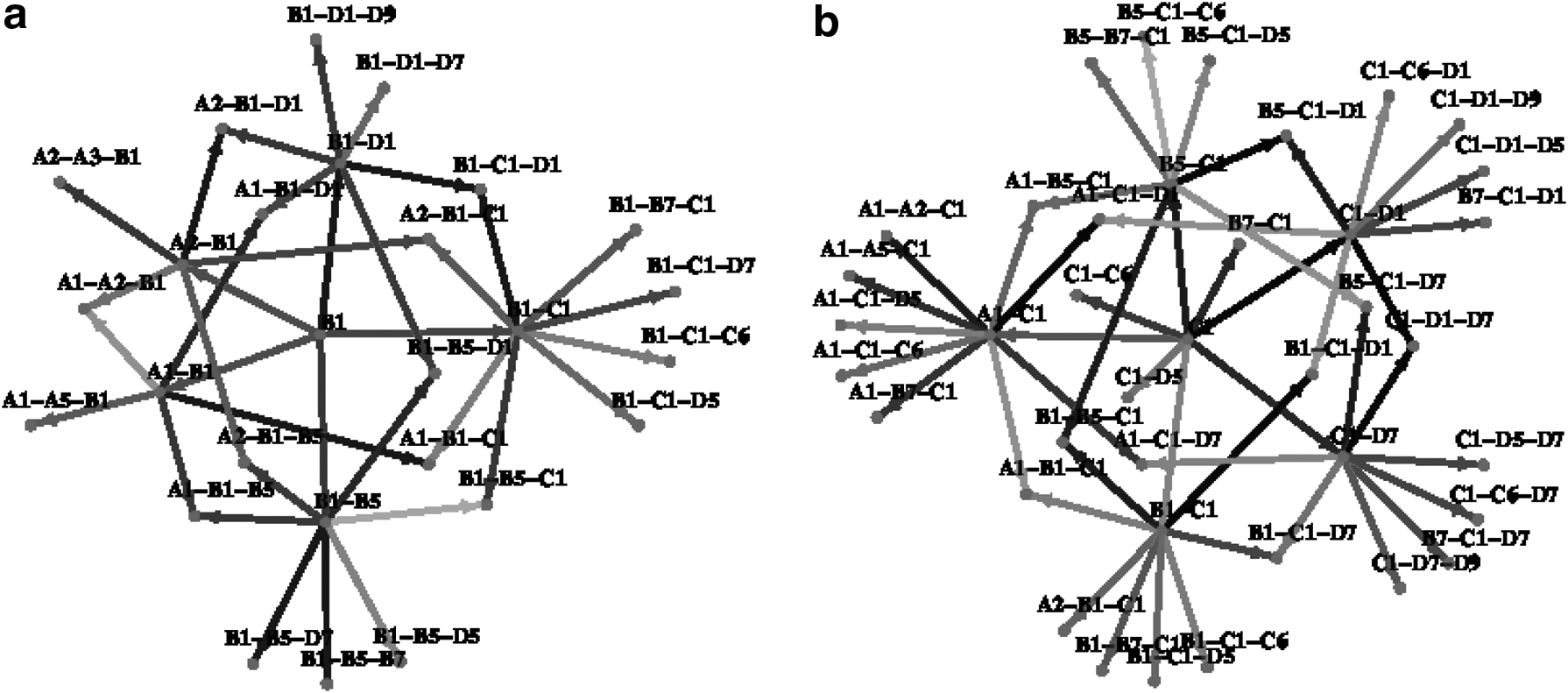
For example, the N. capensis virus (PDBID:1OHF) has 240 proteins on its capsid, and it has four unique monomers: A, B, C, and D. It has several unique symmetric interfaces, with each appearing multiple times on the capsid. In Figure 1, we show a portion of capsid where each of these unique interface types is present at least once. For example, fivefold between A1-A2, A2-A3, etc.; sixfold between C1-B5, B5-D5, C1-D7, etc; threefold between A1-B1, A1-C1, B1-C1, D1-D7, etc.; and twofold between C1-D1, A1-B5, etc. According to our criterion, A1-B1 and A5-B5 are equivalent to each other but not equivalent to A1-B5 (violates criterion 2). A4-A5-A1-B5 is equivalent to A5-A1-A2-B1 but distinct from A1-A2-A3-B1 (violates criterion 3). The panleukopenia virus (PDBID:1C8F; Fig. 2) contains 60 proteins on its capsid, with all proteins arising from the same genetic sequence. Even though this protein contains fewer monomers than the N. capensis capsid, the intertwining nature of the protein interface provides additional interfaces that would not otherwise be available, such as the repeated interface between A1 and A6.
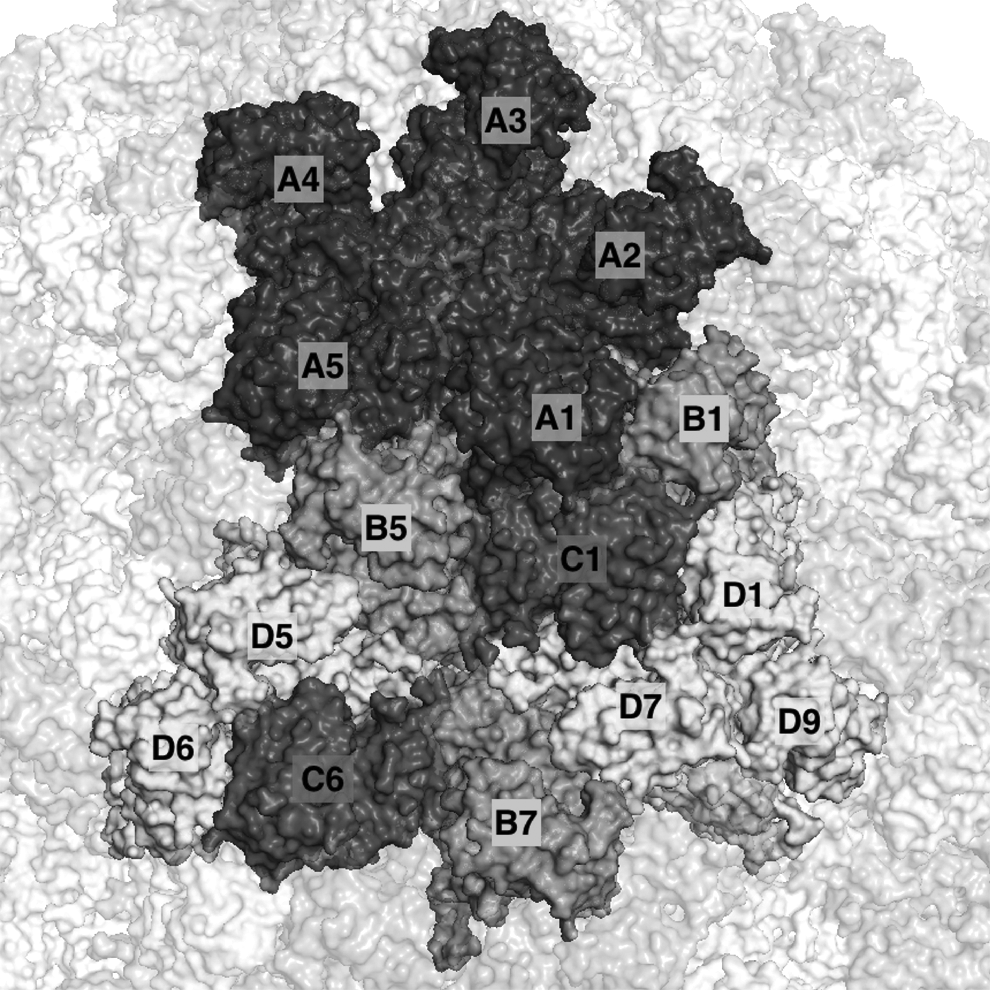
A portion of the Nudaurelia capensis virus capsid (PDBID:1OHF). Labels on the capsid show individual monomeric capsid proteins of different types (A, B, C, or D), at different locations, forming different local subassemblies. For instance, the capsomer A1-A2-A3-A4-A5 forms a pentameric configuration and contains four 5-fold interfaces of the same type. Similarly, A1-B1-C1 and D1-D7-D9 are two trimers, but they involve slightly different interfaces.

A portion of the feline panleukopenia virus capsid (PDBID:1C8F). Labels on the capsid shows individual monomeric subunits at different locations. Since all subunits are composed of the same sequence, each monomer is colored different. Capsomer A1-A2-A3-A4-A5 forms a pentameric configuration and contains four 5-fold interfaces of the same type. Also present is the trimeric interface between A1-A7-A9 and the dimeric interfaces between A1-A6 and A1-A7.
We select a set of subassemblies such that no member of the set is equivalent to any other member. For the N. capensis virus, this resulted in 985 unique subassemblies involving up to six monomers. This set includes some of the more distinct capsomers of this capsid: the trimers (A1-B1-C1) and (D1-D7-D9), the pentamer (A1-A2-A3-A4-A5), and the hexamer (B5-C1-D7-B7-C6-D5). There were 199 unique subassemblies for the panleukopenia virus.
We consider a transition from subassembly
2.2. Sampling of subassemblies
As mentioned earlier, instead of considering a static model for a subassembly, we are interested in modeling subassemblies as a distribution of possible structures that have minor differences, but represent the same state. One way to think of this is to consider an energy well that contains the specific subassembly and many others that are just slightly different—in such case, one should not focus on only one of them to characterize the well, but should consider the entire distribution. In this regard, we consider both small changes inside subunit conformation (the natural shift in structure of the protein backbone) and slight perturbations of the interface. We now describe a parameterization of these spaces.
2.2.1. Configuration space of a subassembly
Although, in principle, backbone torsional angles are all relevant for internal flexibility of a protein, for the sake of tractability (especially for the multitude of subassemblies of the capsid), we applied a coarse-grained approach based on domain decomposition. We limited the sampling space to flexible backbone torsion angles between relatively rigid subdomains. To determine the set of flexible backbone torsion angles, we used HingeProt (Emekli et al., 2008) to identify hinge residues, designating the corresponding
We parametrize the space of local affine perturbations of each pairwise interface between every pair of monomers in a subassembly by using 6 degrees of freedom, defined by three Euler angle twists and three translational shifts. Hence, for a subassembly with t pairwise interfaces, the space is equivalent to
2.2.2. Sampling
Recall that we want to estimate the distribution of free energy over configurations in a local neighborhood of a given subassembly. Computing such distributions analytically over such a space is beyond the scope of our current work. Here, we provide an approximation of the distribution through discrete sampling of the configurational space. We also show that if the set of samples fulfill certain conditions, then the estimated distribution approximates the correct distribution.
where
We use the following adaptation from Theorem 2.13 of Niederreiter (1992):
Essentially, if one ensures that
However, generating such low-discrepancy sampling in a high-dimensional space is nontrivial.
This technique was previously applied in Rasheed et al. (2015) to bound the uncertainties of different proteins and complexes under large conformational shifts as well as local perturbations. It was found that even with high degrees of freedom, if the range of perturbations and flexible motions are constrained within a neighborhood, a relatively small number of samples are sufficient in providing low approximation error for the distribution of different QOI. In this study, we generated 1000 samples for each subassembly.
We then used low-discrepancy sampling to generate a set of possible conformations for each subunit:
We used low-discrepancy sampling to generate a set of t permutation matrices,
In addition, as capsids consist of many copies of the same protein chain, each subunit can be constructed by a matrix multiplication with the original protein chain. For example, if Ti is the ith capsid transformation matrix, then the pentamer for 1OHF can be constructed by rigid-body transformations of the same protein, PA:
Once both the individual conformations and permutation matrices were generated, each unit of a subassembly can be constructed with a single transformation matrix, Ta, applied to a single subunit conformation,
As each transformation matrix and conformation are generated independently, it is possible that certain sampled subassemblies will not preserve the correct interface. To ensure that all interfaces are still considered “native” (i.e., within 4Å RMSD from the original), we computed the atomic RMSD between interface atoms, r, and used rejection sampling with the following acceptance criteria:
1. Let r be the RMSD to native for the interface atoms of the sample 2. Let t be a random draw from a normal distribution with stdev 2Å, that is, 3. Accept if
This ensured that a high percentage of samples had low RMSD to native, and were presenting the correct interface. We then computed the energy of each valid subassembly sample, and the change in free energy was calculated as
2.3. Distribution of E and ΔE
Given a set of samples with low discrepancy, we first compute the free energy for each of the samples. We use Gibbs model of free energy defined as
We used MolEnergy (Bajaj and Zhao, 2010; Bajaj et al., 2011) to compute the surface area and volume, and a graphical processing unit (GPU)-accelerated algorithm, PMEOPA (Cha et al., 2015), for computing the van der Waals, Coulombic, and polarization energies. The accuracy of these algorithms was established in Cha et al. (2015) by comparison with AMBER (Case et al., 2005).
It is trivial to compute binding free energies simply as the difference of the total free energies before and after binding, whereas it is nontrivial when the input is in the form of distributions. The general idea, however, is still the same. First, we define the binding free energies for static cases, as follows: Given a complex or assembly,
Now, since each of the components in the earlier equation is a distribution instead of a scalar, we use a probabilistic definition for the distribution of
2.4. Comparing distributions with rank assemblies and transitions
Analyzing assembly pathways requires the ability to quantify and rank different paths in terms of their likelihood, which is most often related to the binding free energy. Since we are dealing with distributions of such energies (rather than simple scalars), we need a slightly involved technique to compare and rank such distributions. One possible approach is to compare the moments (mean and variance, for instance), but this loses information such as whether the distribution is unimodal or bimodal. The pairwise Wilcoxon signed-rank test (Wilcoxon, 1945) uses the entire distribution and provides a way to generate a total ordering among a set of distributions.
For any pair of distributions, X and Y with N points, the Wilcoxon statistic, 1. Let 2. Order each di from smallest to largest, and let Ri be the rank from this ordering 3. Calculate the Wilcoxon signed-rank statistic,
It is easy to see that this statistic is symmetric, and that
This can be extended to multiple distributions,
For distributions of energy, a lower value of W is more favorable; thus, the most optimal distribution will have the most negative W statistic. Worse (less favorable) distributions will have an increasingly positive W statistic.
3. Results and Discussion
3.1. Sufficiency of sampling
The first and most important question is to determine whether the number of samples we have generated (1000) is sufficient for accurate methods of moments calculations. In previous work (Rasheed et al., 2015), we used an incremental sampling approach to determine when our sampling was sufficient enough to obtain confident representative distributions. For all of the single proteins in the study, less than 400 samples was sufficient to provide high confidence in error bounds. As capsid protein complexes consist of many different protein subunits, the uncertainty in a single sample can propagate and influence the stability of the complex as a whole. It is important to ensure we have achieved sufficient sampling.
Table 1 shows the required number of samples across all protein complexes when using total free energy as the measured statistic. Most of the subassemblies (86%) required fewer than 500 samples before saturation was reached. Only two of the subassemblies from either capsid required more than 900 samples, and the most unstable subassembly was A1-B5-C1-D1-D5 from 1OHF, requiring 973 samples. (On closer inspection, this subassembly had a single spurious outlier with energy values that were several orders of magnitude larger than the average, possibly due to clashes in the input model.) In our previous study, we showed that even an incremental additive procedure (samples were added until saturation had been reached) with as few as 10 additional samples provided an upper bound on the number of samples needed, so we can safely conclude that the number of samples was sufficient to obtain accurate representative distributions.
3.2. Statistical distribution for subassemblies
We computed the following quantities for each sample of each subassembly: exposed surface area, enclosed volume, Leonard Jones (LJ) and Coulombic potentials, the solute-solvent polarization energy
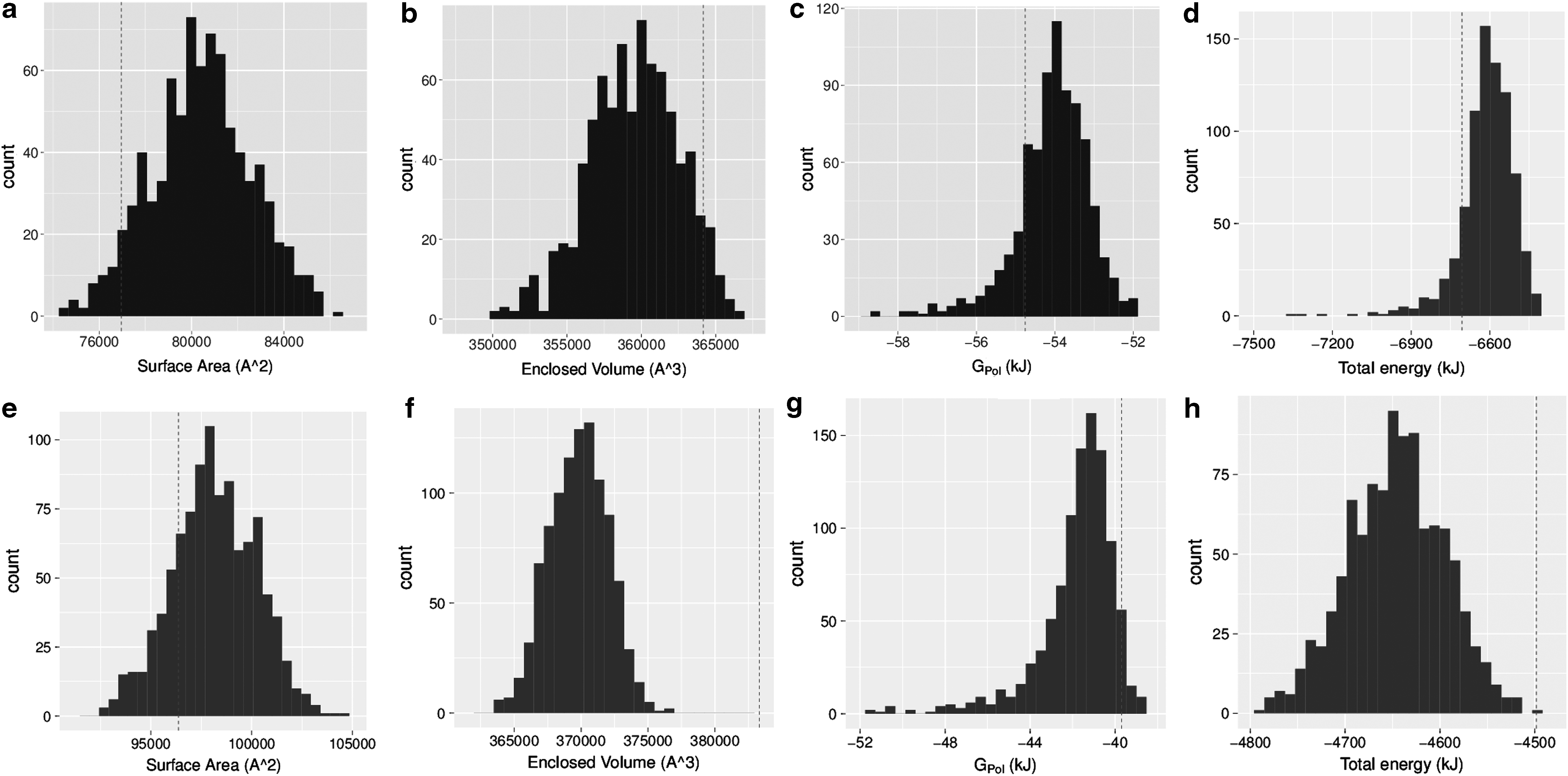
Histogram plots of exposed surface area, enclosed volume,
The second observation from these plots is one major motivation for using distributions of quantities instead of single values. In Figure 3, the dotted red line shows the quantity computed on the non-perturbed subassembly. For the pentamer, these values vary wildly from the mean. For the panleukopenia virus (Fig. 3e–h), the energy computed on the original molecule is far worse (more positive) than the majority of the energy values from the sampling protocol. In fact, analyzing the Z-scores for all subassemblies shows that many of them (42%) differ greatly from the sampled mean by more than 1 standard deviation, and many (∼3%) are more than 2 standard deviations away. In addition, subassemblies with a larger number of subunits do not necessarily have higher variance. So, correctly accounting for uncertainty requires distributions of configurations, instead of single molecules.
3.3. Comparing capsomers
Given the distributions of a number of subassemblies for a specific property, we can compare them by using the Wilcoxon signed-rank test and generate a total ordering. This is especially useful in gaining insights (with quantified uncertainty bounds) into the relative binding affinities or stabilities of different capsomers. As the number of potential pathways for the panleukopenia virus are far fewer than those of the N. capensis virus, we will limit the discussion in this section to those of the latter capsid.
Figures 4 and 5 show the distribution of total energy for single subunits and dimer subassemblies of PDBID:1OHF (see Fig. 6 for a surface representation of these complexes), and the top 10 subassemblies of size 3, respectively. According to this test, the most stable subunit is B, the most stable subassembly of size 2 is the B5-C1 dimer, and the most stable subassembly of size 3 is the A1-B1-B5 complex. The least stable complexes are A, the C1-D1 dimer, and the C1-D1-D7 complex (not pictured).
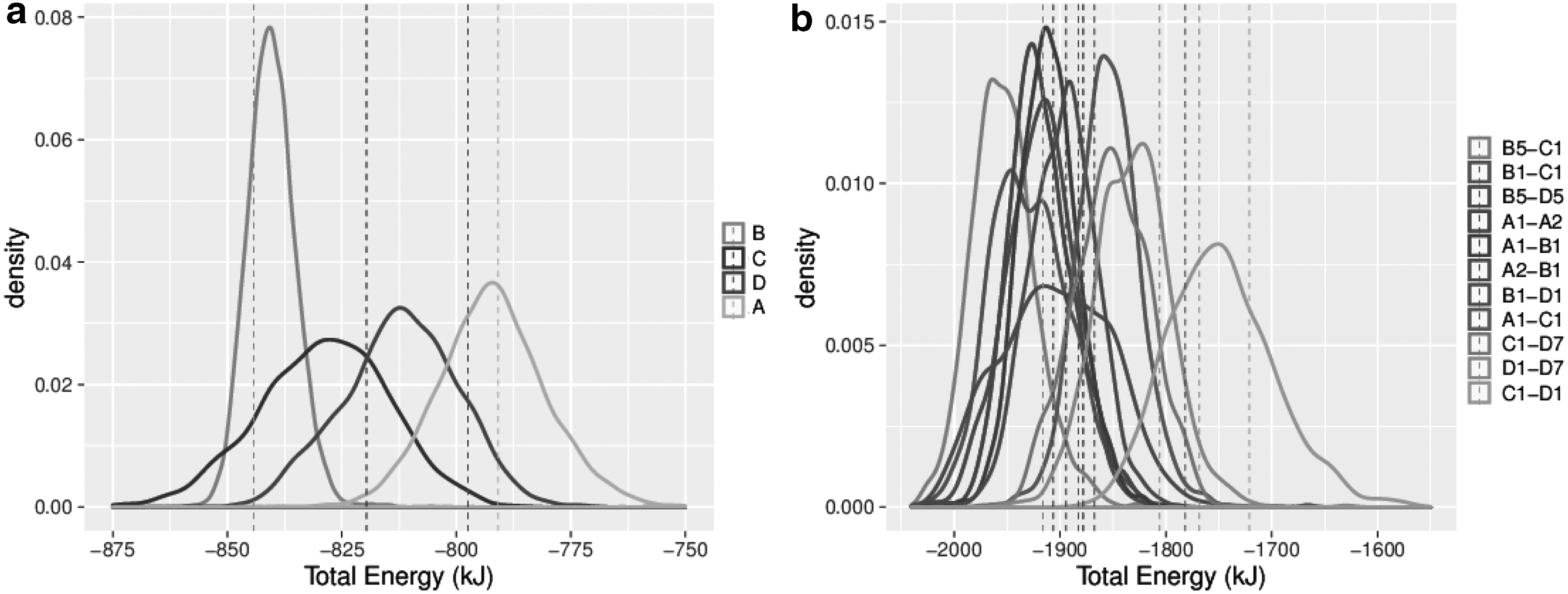
Density plots of distribution of all energy values for all single subunits
Density plots of distribution of energy values for top 10 subassemblies of size 3 for PDBID:1OHF. Legend is ranked according to the Wilcoxon signed-rank test (top is best), as given in Equation (4).
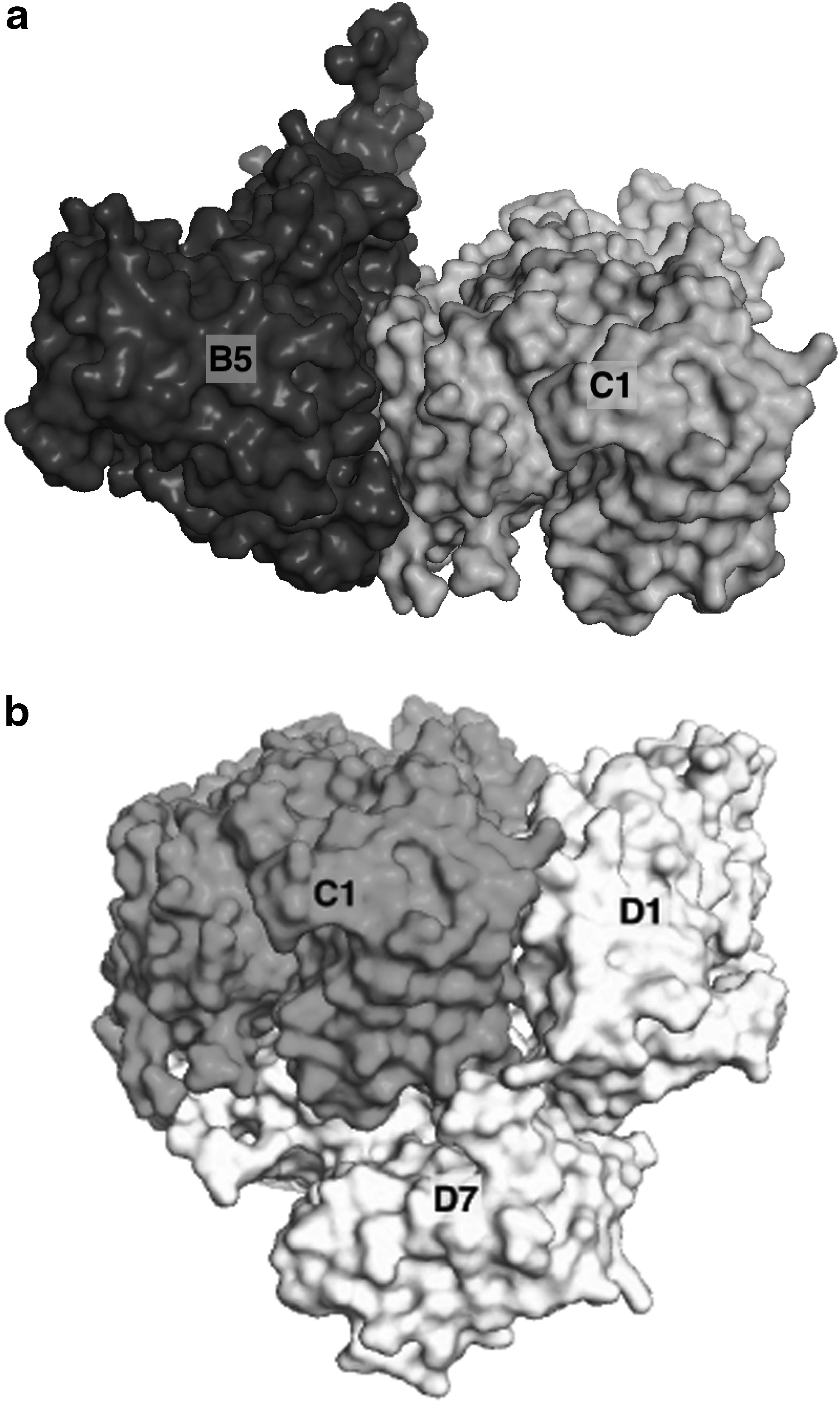
Labeled surface representation of B5-C1
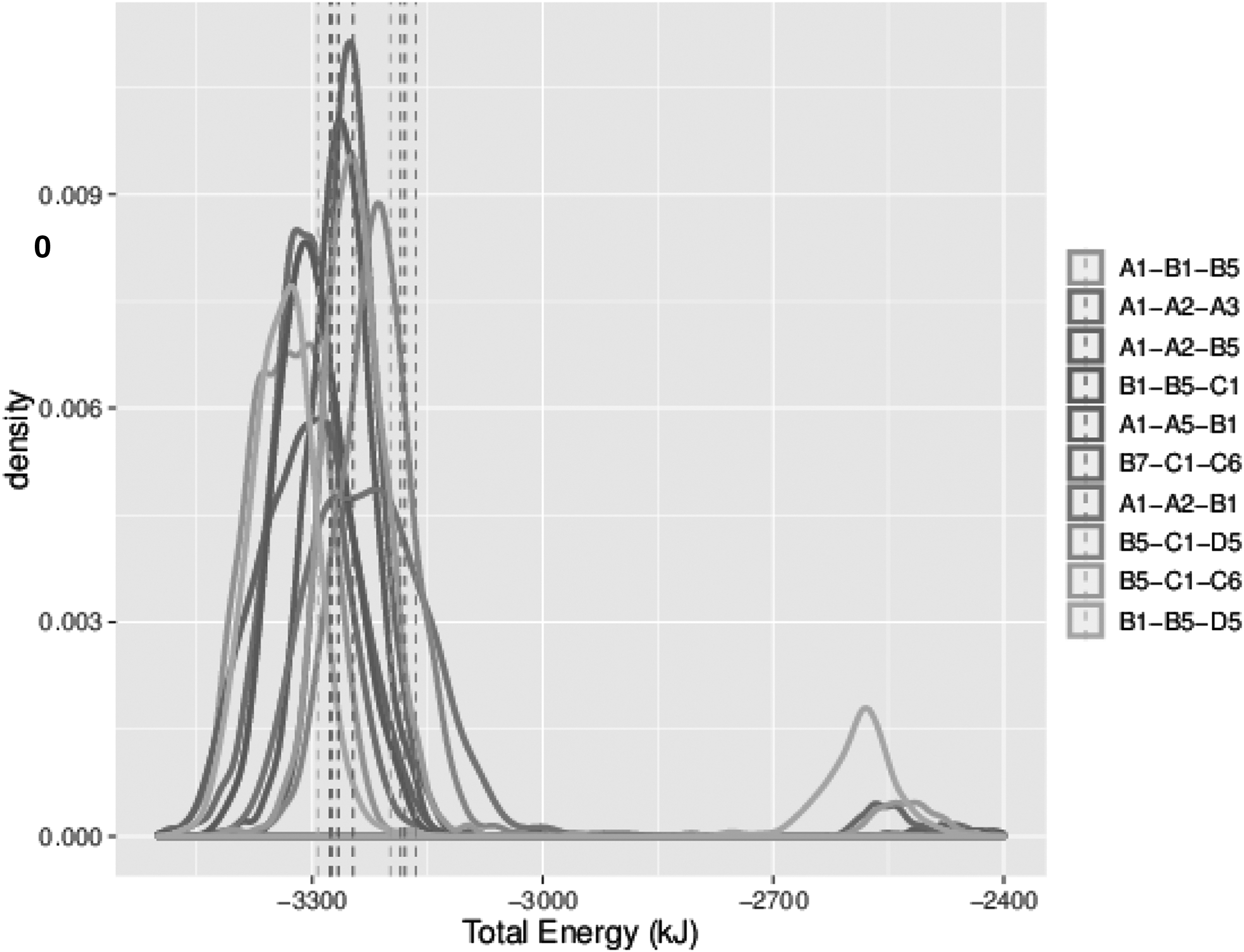
We also applied the Wilcoxon signed-rank test to rank all possible transitions from any given subassembly, which is a crucial step in predicting/analyzing the assembly pathway. For example, Figure 7 shows the possible state transitions of the N. capensis capsid assembly starting at C1-B5-B1. If only the native configurations were used, one would have reached the conclusion that adding B7 would be the best transition. However, this is an incorrect conclusion since the interface between B7 and B5 has low contact area and is only stable if D7 is also present (see Supplementary Fig. S4 of Clement et al., 2016). That sensitivity is exposed through sampling the local configuration space, which resulted in some configurations with more favorable binding configurations and others that were pulled apart (apparent from the bimodal nature of the distribution). Our method successfully accounted for this uncertainty and, as the Wilcoxon test is robust to these kinds of errors, correctly ranked it lower than other subassemblies.
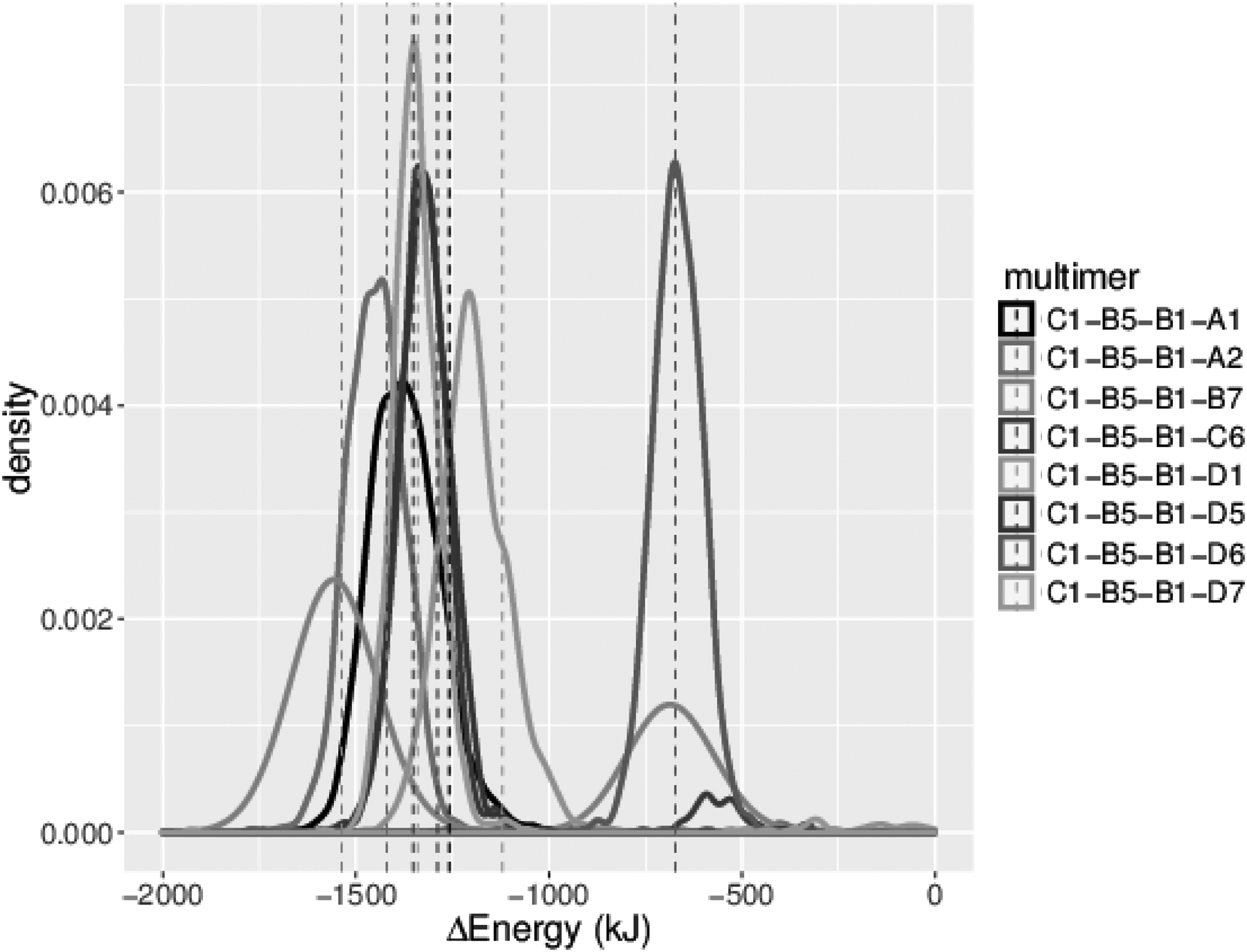
Density plots of distribution of energy values for all possible 4-unit capsomers starting with C1-B5-B1 of PDBID:1OHF. Legend is ranked according to the Wilcoxon signed-rank test (top is best), as given in Equation (4). Dotted vertical lines show the value computed on only the native structure.
3.4. Transitions
Finally, after ranking each transition based off its Wilcoxon score, we construct a complete transition graph showing all possible pathways leading from monomeric subassemblies to the largest subassemblies. Since the entire graph is too large to visually inspect, we present snippets of it here. In addition, limit the discussion in this section to only the N. capensis capsid subassembly. Figure 8 shows transition sub-graphs starting with subunits B5-C1 and C1-D1-D7, respectively. Note that these two were determined to be very stable states according to our analysis presented in the previous subsection. Starting with (C1-B5), the most likely pathway is (C1-B5)
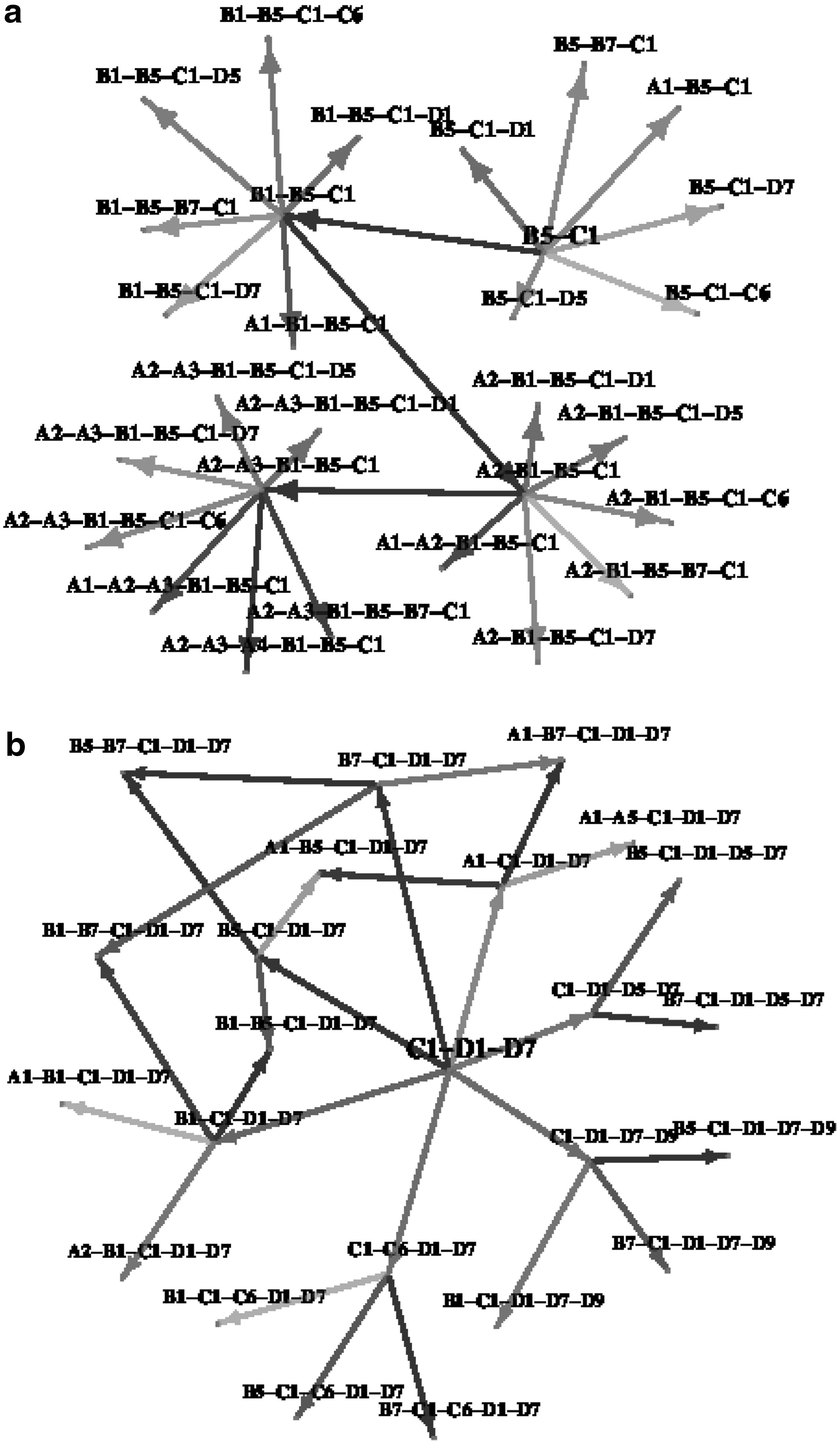
Network graph of possible subassemblies formed when starting from most likely starting points for PDBID:1OHF [
There are several observations that can be made from generating likely pathways. One observation is that A1-A2-A3-A4 is a very stable four-subunit subassembly, whereas A1-A2-A3-A4-B5 is more stable than A1-A2-A3-A4-A5, the pentamer (Fig. 9). This indicates that the pentamer is not fully stabilized until the addition of the B subunit. Such reliance on dimeric interactions may correlate with the size specificity of the virus capsids, since such an interface will not be present in a T = 1 shell. Another insight is that the A-C interface is not at all stable (the C-B or C-D interfaces are much better), and probably does not happen until much later in the assembly process or until other partners on hexameric interfaces provide necessary stabilization.
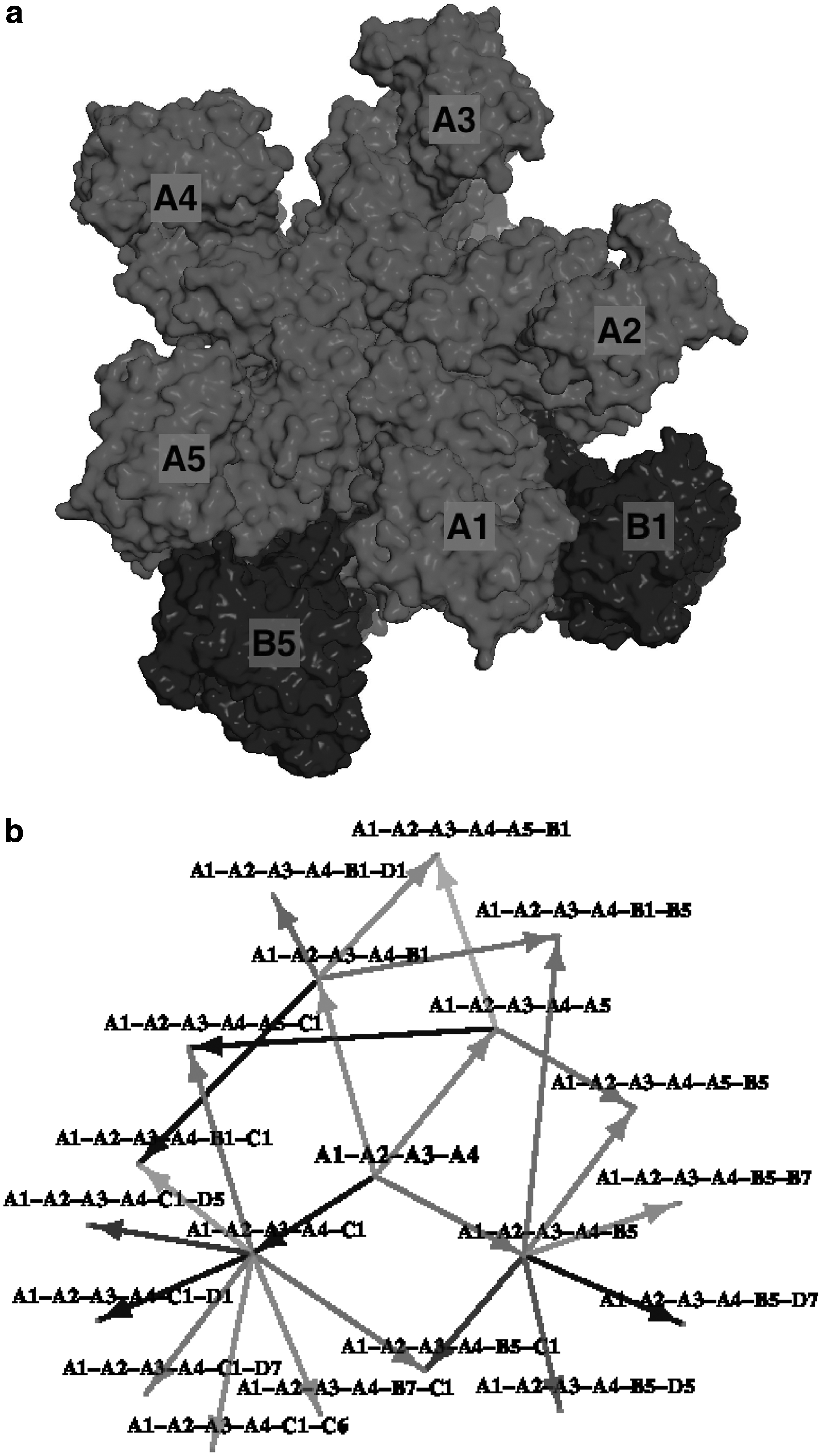
Labeled surface representation of A1-A2-A3-A4-A5-B1-B5
Finally, we can construct a complete transition graph showing all possible pathways leading from monomeric subassemblies to the largest subassemblies. See Figure 10 for an example where the likely transition pathways based on ΔE are highlighted.
Network graph of possible subassemblies formed up to size 3, when starting from subunit B1
3.5. Steady-state concentration calculations
Although ΔE is a useful predictor for determining the most likely step in a single-step reaction, it does not take into account one of the major driving forces for chemical reactions: concentrations of the necessary reactants and products. If no reactants are available in a chemical reaction, it cannot take place; likewise, if the concentration of products is too high, the reaction will not proceed. For this reason, we additionally provide a global view of the viral assembly in terms of concentrations of products and reactants.
If the concentration of the reactants,
This can be extended to subassemblies with generic reactants, such as
It should be noted here that for many chemical reactions, the rate of the reaction is determined by kinetics (
Based on Equation (5), it is easy to see that the concentration of a single product is dependent on the concentration of one or more reactants. If concentrations of subassemblies are represented by vertices in a graph, then dependencies can be represented by directional edges in this graph, which have weights proportional to the
3.5.1. Representing capsid assembly as a graph maximum a posteriori probability problem
It is easy to represent the formation of a virus as a Bayesian network consisting of m nodes, where each node represents a possible subassembly, sk, and the transition probabilities are the rates of formation. A node in the network,
However, a limitation of the traditional Bayesian network is that a simple edge weight does not contain all the information necessary to determine forward and backward effects. Instead of a Bayesian network, we can represent the viral assembly process as a Bayesian factor graph, where the factor nodes are states that contain this additional information (Fig. 11). Since we are modeling the creation of a virus from the addition of single subunits, we will enforce an additional constraint that each factor node must have exactly two incoming edges and exactly one outgoing edge.
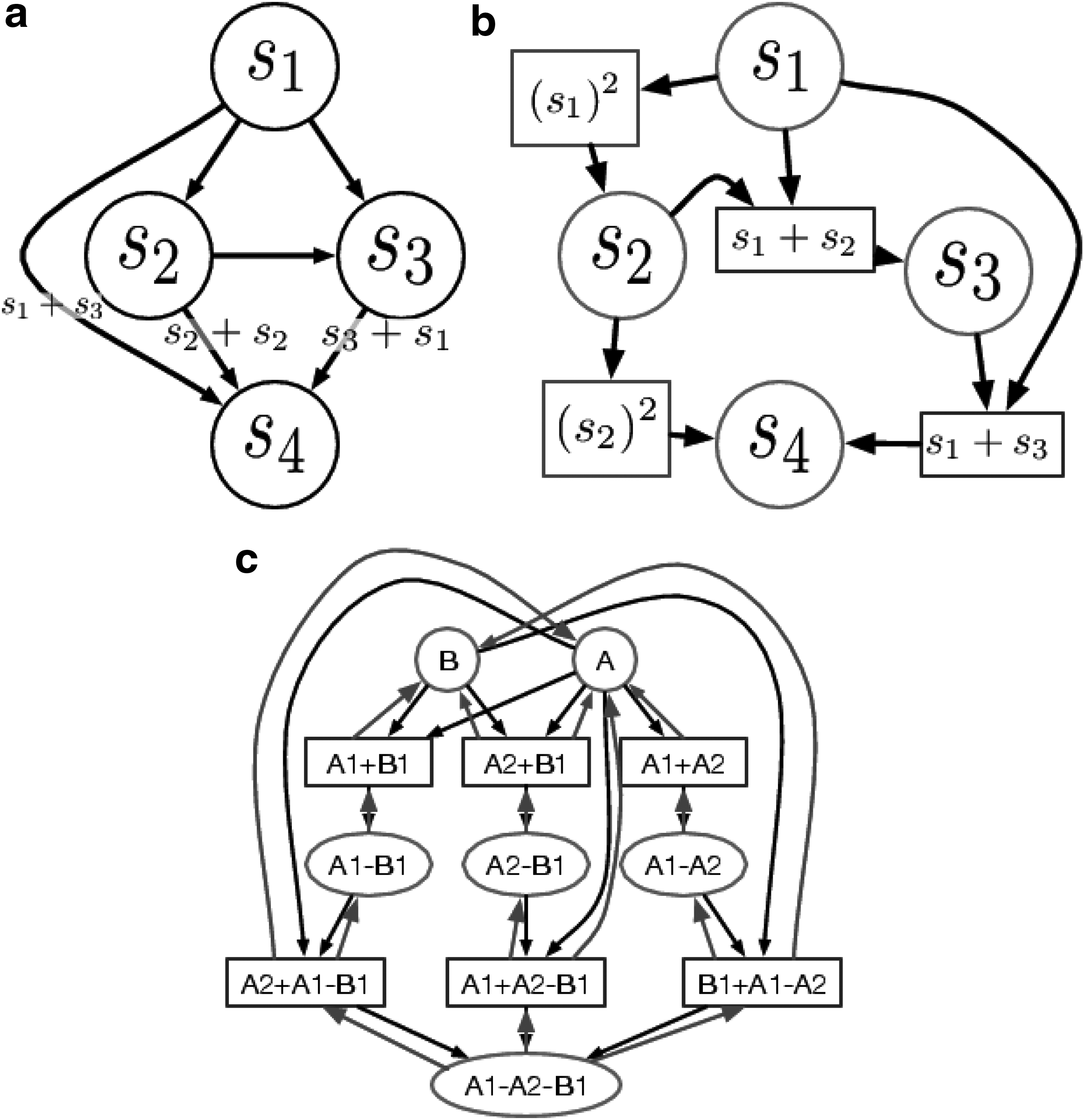
Two different graphical representations of virus formation.
3.5.2. Parametrization and solving
Let r be a subunit used to produce more than one product, for example, r and r1 form p1, and r and r2 form p2. Then, the ratio of the two products can be determined from Equation (5). If we assume that the concentrations of r1 and r2 are equal, then:
where
For a set of k potential products,
Denoting the reverse exponent amount of reactant r as
Let
The traditional method for solving the steady state of a Bayesian factor graph is through a technique called belief propagation or message passing, where each node in the graph will “propagate” its “belief” about the current state of the network to its neighbors (Yedidia et al., 2003). We adopted the traditional sum-product belief propagation method to our problem (Kschischang et al., 2001). Please see Clement et al. (2016) for further details.
To analyze the steady-state (MAP) estimate of the two viral capsids considered in this study, we set the initial concentration of all monomers (A, B, C, and D) to typical micromolar ranges (100 nM). Weights for the factor graph were set to a single
3.5.3. Steady-state concentrations
Figure 12 shows the distribution over successive steps of the message-passing algorithm for both capsids, which attempts to model the self-assembly of the capsid. For the most part, the assemblies with higher concentrations at the steady state (final step of the algorithm) are those with more subunits (e.g., the concentration of the hexamer B5-B7-C1-C6-D5-D7 for PDBID:1OHF was 26 nM, several orders of magnitude higher than the other subassemblies; the concentrations of most dimer and trimer subassemblies for PDBID:1C8F have a quick spike, then rapidly decrease; etc.). This observation would suggest that the subassembly formation largely proceeded toward completion of products, and that the limiting factor was concentration of the products, as was expected. However, not all of the results were consistent with this intuition. Notably, the dimeric interface A1-A6 from the panleukopenia virus was extremely strong (having more than one binding footprint), and it had the highest final concentration (26 nM) (the second highest final concentration was 23 nM for A1-A2-A5-A6-A7-A9, which still did not contain the pentamer).

Change in concentration over time for several subassemblies of the N. capensis
An important point to note is that this graph would be somewhat different if subassemblies of size greater than 6 were also included, as the intermediate products would be quickly consumed. From Figure 12, this phenomenon can already be observed on both viral capsids; for example, the intermediate product A1-C1 of PDBID:1OHF has an initial high concentration, but then quickly drops off as it is used for later products, such as A1-B1-C1-D1. This also explains why the concentration of monomer C decays so slowly, as there are fewer beneficial reactions involving C (see, for e.g., Fig. 5, where the products involving C are not highly ranked). This might suggest that the configuration of C with the rest of the capsid is meant as a stabilizing subassembly, and is not used until much later in the assembly process.
Finally, we can also plot the distribution of all possible steady-state concentrations, shown in Figure 13. For this plot, initial values of
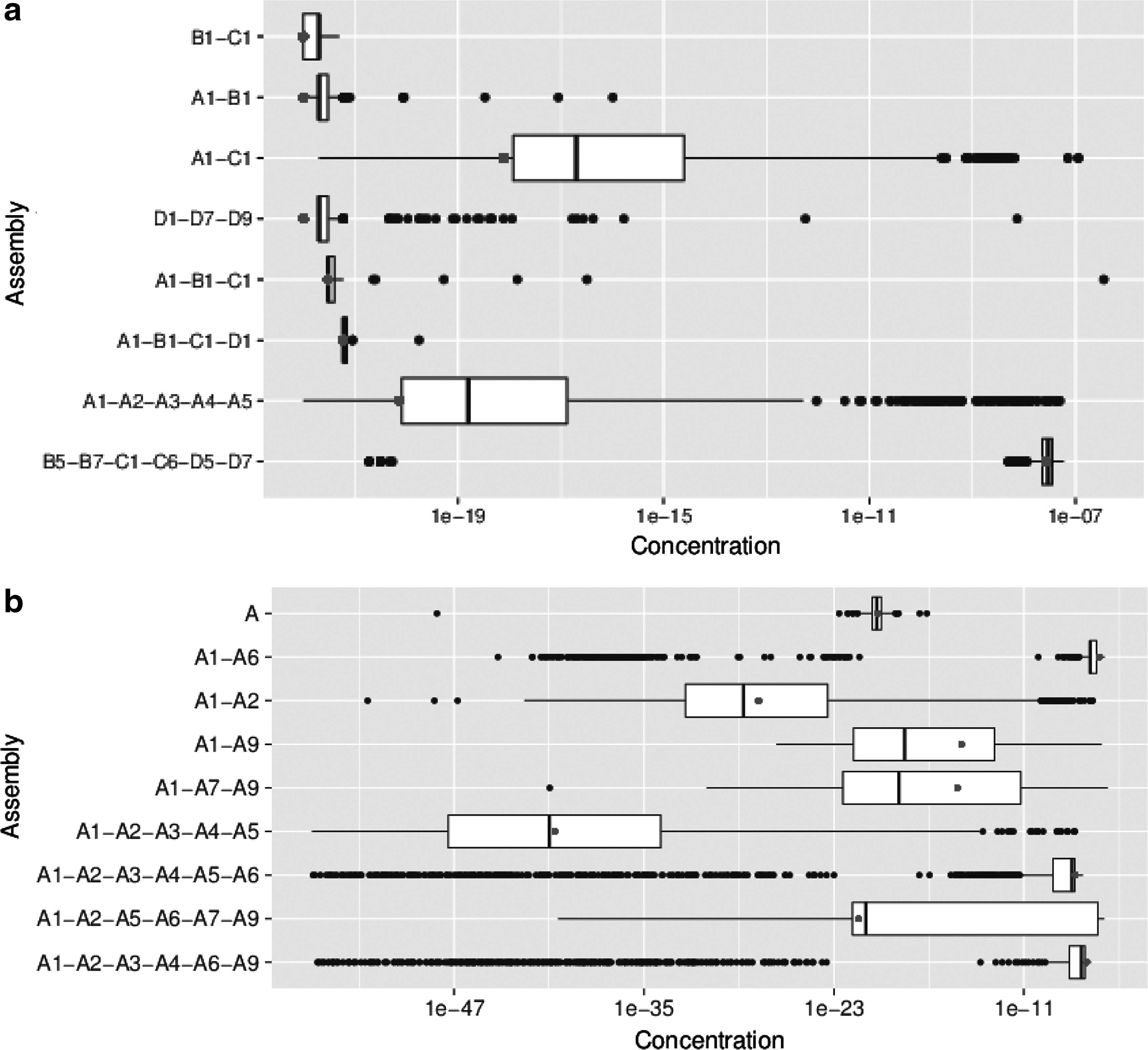
Distribution of concentrations over different input
This kind of plot illuminates several things: first, that the distributions of final concentrations can differ greatly across subassemblies. If only a single input model is used and only a single statistic is reported, the entire landscape of possible values is overlooked. Second, the value computed on the original PDB does not represent the true average across all samples, further supporting the need to analyze capsid assembly through distributions of values.
4. Conclusions
Most of the existing research in assembly pathway prediction/analysis of virus capsids has relied on the final configuration of the capsid to determine the configuration of the intermediate states. This assumption is overly simplified since the capsid proteins may undergo conformational changes, binding interfaces adjustments to allow binding with another subassembly, etc., throughout the assembly process until stabilization. To better capture this phenomenon, we have developed a statistical-ensemble-based approach that sufficiently samples the configurational space of each monomer and the relative local orientation between monomers to capture the uncertainties in their binding. Instead of modeling each subassembly as a static configuration, we model them as distributions of possible configurations. This allows us to compute distributions of free energy over many subassembly samples, and to use distributions of binding free energy on a possible assembly edge instead of a single quantity so that statistical guarantees of accuracy can additionally be derived for each of the resulting assemblies.
Unlike traditional approaches where pentamers, hexamers, or trimers are used as fundamental building blocks in the assembly pathway analysis, we use individual monomers as our starting constituents, and consider all possible unique subassemblies (modulo symmetry), of sizes up to 6. The primary aim is to quantitatively understand the formation of the larger building blocks (i.e., trimers, pentamers, and hexamers).
We additionally adapted the Wilcoxon measure to provide a way to compare the distributions and determine the most likely subassemblies that can be generated in any step. Using this score as weights on an assembly graph revealed that there are some low-energy subassemblies that are unlikely to be formed because there are poor transitions along the path that form the said subassembly. We proposed an assembly prediction algorithm that utilizes both binding free energy and equilibrium concentrations, and we applied it to two different capsid assembly problems. The algorithm uses a Bayesian factor graph where the final concentrations of the subassemblies are posed as a graphical maximum a posteriori problem. Transition probabilities were set up based on the equilibrium constant computed from the binding free energy, and both forward (association) and backward (dissociation) reactions were allowed. The result showed expected patterns, for example, dimers A1-B1, A1-A2, etc., being produced at a fast rate initially and then being consumed as other subassemblies become available, forming the larger subassemblies A1-B1-C1 (trimer), A1-A2-A3-A4-A5 (pentamer), etc. As the concentrations reach their steady state, larger particles had higher final concentrations, as was expected. The algorithm also highlighted several differences between the two viruses considered, some of which were contrary to intuition.
In summary, we contend that the use of ensemble distributions of molecules, instead of single conformations, allows one to make statistical inferences about the stability of molecular subassemblies. We have shown that a full distribution of possible subassemblies is not obtainable if one was to use assembly combinations only from the original PDB conformation. This could often lead to erroneous conclusions. Use of a statistically rigorous procedure, such as the one advocated in this article, yields inferences on capsid assembly that can be made with statistical confidence.
Footnotes
Acknowledgments
This research was supported in part by NIH-R01GM117594, NIH-R41GM116300 and a grant from SETON-Dell Medical 201602388.
Author Disclosure Statement
No competing financial interests exist.