2.1. Sequence alignment and score distributions
Pairs of sequences are aligned with the Needleman and Wunsch (1970) (for global alignments) and the Smith and Waterman (1981) (for local alignments) algorithms. Pairs of letters
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$( a , b )$$
\end{document}
are scored according to
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
s ( a , b ) = \begin{cases} \begin{matrix} { + 1 , } & {a = b} \\ { - 3 , } & {a \ne b{ \rm{.}}} \\ \end{matrix} \end{cases}. \tag{2}
\end{align*}
\end{document}
This means that matching letters increase the score by 1, mismatches decrease it by 3. Gaps are penalized with affine gap costs using
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \gamma _i} = 5$$
\end{document}
as gap initiation penalty and
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \gamma _e} = 2$$
\end{document}
as gap extension penalty.
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$s ( a , b )$$
\end{document}
,
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \gamma _i}$$
\end{document}
, and
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \gamma _e}$$
\end{document}
are chosen in accordance with Messer et al. (2007).
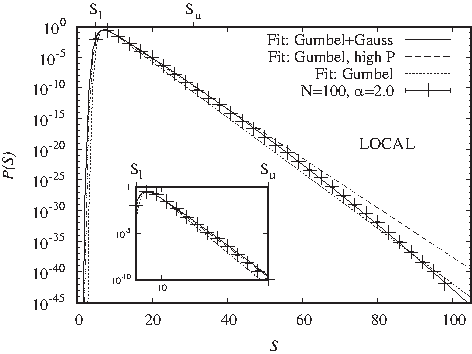
Score distributions for the gapless local alignment of infinitely long sequences have been analytically found to follow a Gumbel distribution (Karlin et al., 1990). Transferred to pairwise alignment of two sequences of identical length L the distribution is assumed to follow
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
P ( S ) = \lambda \exp \left( { - \lambda ( S - {S_0} ) - {e^{ - \lambda ( S - {S_0} ) }}} \right) , \tag{3}
\end{align*}
\end{document}
with constant
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\lambda$$
\end{document}
. Numerical studies have found this to be a good estimate for the high-probability region (Altschul and Gish, 1996). However, such studies with a simple sampling approach can only sample sequences to cover probabilities higher than
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$P ( S ) \ge {10^{ - 10}}$$
\end{document}
. Numerical large deviation analyses of score distributions yielded a deviation from the Gumbel distribution in the low-probability tail (Wolfsheimer et al., 2007; Fieth and Hartmann, 2016). An adjusted form for the distribution can be given by
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
\begin{split}& P ( S ) = {P_{{ \rm{Gumbel}}}}{ \kern 1pt} {e^{ -
{ \lambda _2}{{ ( S - {S_0} ) }^2}}} \\ & = \lambda \exp \left( {
- \lambda ( S - {S_0} ) - {e^{ - \lambda ( S - {S_0} ) }} - {
\lambda _2}{{ ( S - {S_0} ) }^2}} \right) ,\end{split}
\tag{4}
\end{align*}
\end{document}
with a new parameter
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \lambda _2}$$
\end{document}
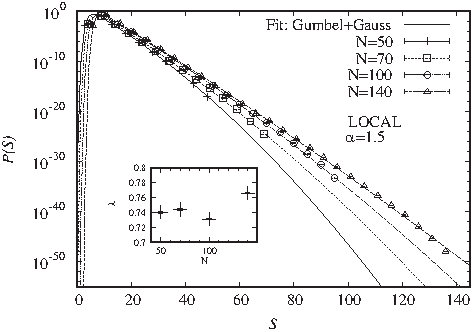
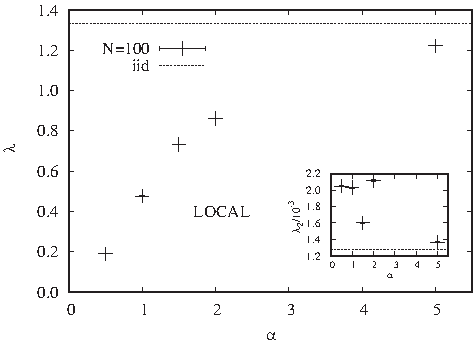
which indicates the strength of a Gaussian correction.
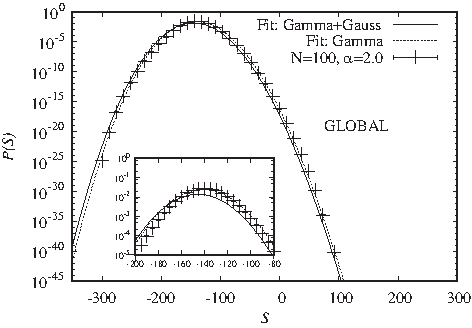
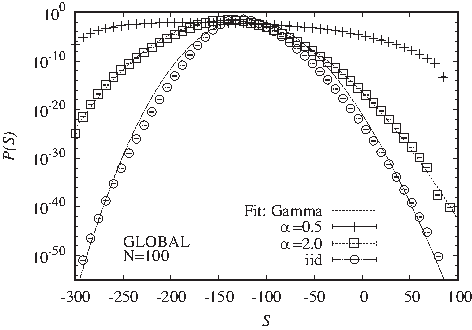
For global alignment, numerical studies of the high-probability region have yielded the Gamma distribution as a heuristic estimate for the score distribution (Pang et al., 2005)
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
{ P_ { { \rm { gamma } } } } ( S ) = \begin{cases} \begin{matrix}
{ { \frac { { \lambda ^ \gamma } { { ( S - \mu ) } ^ { \gamma - 1
} } { e^ { - \lambda ( S - \mu ) } } } { \Gamma ( \gamma ) } } }
& { S > \mu } \\ 0 & { S \le \mu , } \\ \end{matrix}
\end{cases} \tag { 5 }
\end{align*}
\end{document}
with the Gamma function
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\Gamma ( x )$$
\end{document}
and constants
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\lambda$$
\end{document}
,
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\gamma$$
\end{document}
, and
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\mu$$
\end{document}
. Large deviation studies yielded again a deviation for lower probabilities (Fieth and Hartmann, 2016)
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
{ P_ { { \rm { gc } } } } ( S ) = \begin{cases} \begin{matrix} { {
\frac { { \lambda ^ \gamma } { { ( S - \mu ) } ^ { \gamma - 1 } }
{ e^ { - \lambda ( S - \mu ) } } } { \Gamma ( \gamma ) } } { e^ {
{ \lambda _2 } { S^2 } } } } & { S > \mu } \\ 0 & { S \le \mu , }
\\ \end{matrix} \end{cases} \tag { 6 }
\end{align*}
\end{document}
with another Gaussian correction indicated by parameter
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \lambda _2}$$
\end{document}
.
2.2. Large deviation approach
To obtain the score distributions in the region of low probabilities, the approach for sequence alignment as introduced by AKH in Hartmann (2002) was used. The basic principle is to use the Metropolis algorithm (Metropolis et al., 1953) to sample a Markov Chain of sequence pairs with a bias parameter T. In a Markov Chain parameterized by a “time” t, the system state
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${{ \cal C}_t}$$
\end{document}
(here: the sequence pair) is slightly changed to trial state
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal C}^\prime$$
\end{document}
, its new score
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \cal C}^\prime ( S )$$
\end{document}
is calculated and a new step accepted with probability
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$P ( {{ \cal C}_{t + 1}} = { \cal C}^\prime ) = \min \left[ {1 , \exp ( \Delta S / T ) } \right]$$
\end{document}
with
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\Delta S = S ( { \cal C}^\prime ) - S ( {{ \cal C}_t} )$$
\end{document}
. In case of nonacceptance, the current state is kept, that is,
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${{ \cal C}_{t + 1}} = {{ \cal C}_t}$$
\end{document}
. This procedure yields when sampling the steady state of the Markov chain in a biased score distribution
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
{ P_T } ( S ) = { \frac { \exp \left( { S / T } \right) } { { Z_T } } } P ( S ) , \tag { 7 }
\end{align*}
\end{document}
with the partition function ZT for parameter T as normalization. Note that the unbiased distribution then corresponds to the case
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$T = \infty$$
\end{document}
, and we can estimate
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${Z_{T = \infty }} = 1$$
\end{document}
.
For details see Hartmann (2002). In this study we just briefly note that the unbiased distribution can be obtained by successively rescaling the biased distributions by the factor
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\exp ( S / T )$$
\end{document}
and estimating the partition function ZT comparing overlapping data points with the unbiased distribution. The simulations have to be done for an appropriate range of scaling parameters T, so that rescaled distributions have enough overlap to estimate the respective ZT. Algorithm performance can then be improved by sampling several Markov chains with different parameters Ti in parallel and systematically switching parameters Ti,
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${T_{i + 1}}$$
\end{document}
(Geyer, 1991; Marinari and Parisi, 1992; Hukushima and Nemoto, 1996).
2.3. CorGen
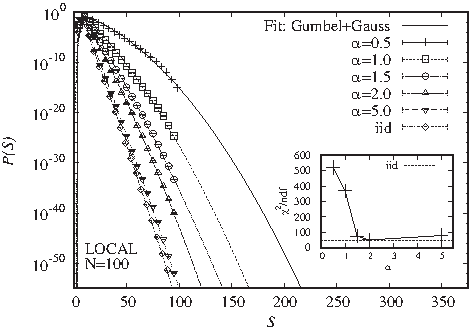
The CorGen algorithm as presented by Messer and Arndt (2006) generates sequences with
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$C ( r ) \propto {r^{ - \alpha }}$$
\end{document}
. An iid sequence x of length N0 is generated initially. A letter xk in the sequence is chosen at random and either mutated with probability
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${P_{{ \rm{mut}}}}$$
\end{document}
or duplicated, that is, introduced at position
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$k + 1$$
\end{document}
after shifting all letters from position
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$k + 1$$
\end{document}
one by one, increasing the sequence length. It is
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\alpha = 2{P_{{ \rm{mut}}}} / ( 1 - {P_{{ \rm{mut}}}} )$$
\end{document}
. Letters are drawn to ensure a GC-content of
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$g = 0.5$$
\end{document}
, the initial sequence length is chosen as
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${N_0} = 6$$
\end{document}
. In practice,
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\alpha$$
\end{document}
has to be chosen according to the typical correlation decay observed in assessed genomes. Therefore it will be varied in this study.
Slightly changing a sequence set can be achieved by randomly changing a single letter for iid sequences without correlation. In this study, however, we have to maintain the correlation in the sequences. To achieve this we use the fact that sequences are generated by pseudo random numbers. A particular set of sequences showing long-range correlation with CorGen can be replicated by feeding the algorithm the exact same pseudo random numbers as in the first run. However, as the decision for or against mutation changes the number of random numbers needed per generation step, one manipulation of the vector could radically change the generation process. This is not desired in a Markov chain simulation, because small changes in a state should yield also only small changes in the results. To avoid resulting large “chaotic” changes, three random vectors are used, one to decide to mutate or duplicate, one to decide which element of the sequence this decision is applied to, and a third vector that, in case of mutation, chooses the replacing letter from the alphabet. While the i-th element of the first two vectors is used in the i-th step of the sequence generation, the k-th element of the third vector decides the k-th mutation (
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$k \le i$$
\end{document}
) that occurs during the generation process.