
Abstract
Abstract
Recently, the number of the amino acid sequences shared in online databases is growing rapidly in huge amounts. By using sequence-derived features, machine learning algorithms are successfully applied to prediction of protein functional classes, protein–protein interactions, subcellular location, and peptides of specific properties in many studies. Protein Sequence Encoding System (PROSES) is a web server designed as freely and easily accessible for all researchers who want to use computational methods on protein sequence data. That is, PROSES provides users to encode their protein sequences easily without writing any programming code.
1. Introduction
P
In this article, we introduce a web tool named Protein Sequence Encoding System (PROSES) to provide users residue encoding and sequence search. PROSES is an online web server designed as freely and easily accessible for all researchers who want to encode protein sequences as data preprocess for machine learning methods.
In the literature, PROFEAT (Li et al., 2006; Rao et al., 2011), iFrag (Garcia-Garcia et al., 2017), PseAAC (Shen and Chou, 2008), and offline Matlab toolbox (Zhang and Ke, 2014) are the prominent online and offline tools. However, the existing tools do not cover all of the encoding methods provided in the PROSES web server and some of these tools are not freely accessible. Moreover, with PROSES web server, we also facilitate the sequence searching, file conversion, and feature encoding for predicting protein–protein interactions. The web server is especially useful for those who are not familiar with programming languages. PROSES is available at (http://proses.yalova.edu.tr). The use of web server and detailed explanation of provided methods can be found at the web server's link (http://proses.yalova.edu.tr/help.html).
2. Proses's Modules
We design the PROSES web server with user-friendly and responsive interface. The web server consists of four main modules: protein encoding, protein sequence search, protein–protein interaction, and file converter (see Supplementary Figs. S1–S3 for flowcharts of modules). Each module is placed in the web site at different pages but the functions in each module are used in the other modules as well. For example, the functions of the search module are used in the protein–protein interaction page for generating the sequences of interacted proteins by looking at their UniProt ids. The diagram of PROSES's modules and relationship among them are shown in Figure 1.
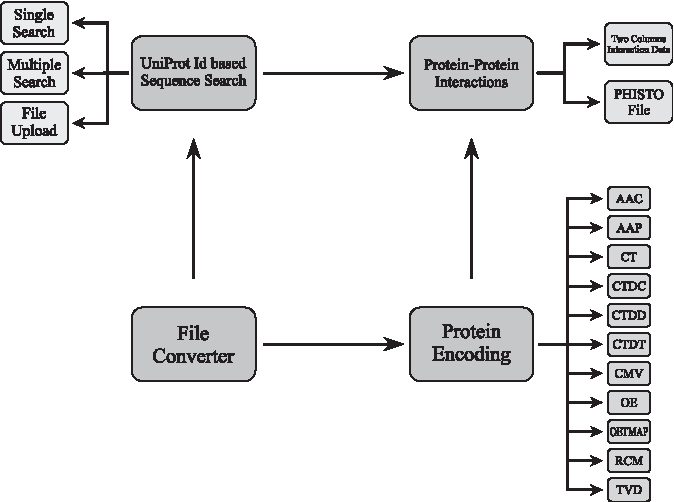
Flowcharts of the PROSES's modules. PROSES, Protein Sequence Encoding System.
In protein encoding module, our web server provides to encode amino acid sequence with 12 different encoding methods: amino acid composition (Bhasin and Raghava, 2004), amino acid pair (Chen et al., 2007), conjoint triad (Shen et al., 2007), composition-transition-distribution (Dubchak et al., 1995), dipeptide composition (Bhasin and Raghava, 2004), composition moment vector (Ruan et al., 2005), orthonormal encoding (Maetschke et al., 2005), OETMAP (Gök and Özcerit, 2013), Taylor's venn diagram (Taylor, 1986), and residue-couple model (Guo et al., 2000).
In the protein encoding module, there are two options for inputting the sequence data: with a multiline textbox or a fasta file. After uploading the data, a table with its sequences and IDs appears. From this table, users can select the listed sequences one-by-one or all the sequences and then choose an encoding method. Finally, the encoded sequence data will appear in a popup window that provides the results in diverse file formats.
PROSES provide users to search a protein sequence by fetching the sequence from the UniProt web site (www.uniprot.org) through UniProt ids of proteins. The search module is used for querying protein sequence that can be used in encoding or protein–protein interaction module. The aim of the protein–protein interaction module is to generate a feature vector for each interacted protein pairs. Proteins in the interacted pair are encoded independently, and then the extracted feature vectors are concatenated as a final feature vector to predict the protein interactions. The users need to give interaction data in one of the txt, xls, xlsx, or csv file formats that contain uniprot ids of interacted proteins in two columns.
PROSES provides users to work with commonly used file formats. Users can keep the encoded data in txt, xls, xlsx, csv, or arff file formats and can also make conversion among these file formats.
Footnotes
Acknowledgments
We thank our undergraduate students Onur Duman and Furkan Zambak for their assistance in the building of PROSES web server.
Author Disclosure Statement
The authors declare that no competing financial interests exist.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.