In this article, we investigate the problem of detecting boundaries of DNA copy number variation (CNV) regions using the DNA-sequencing data from multiple subject samples. Genomic features along the linear realization of the actual genome are correlated, especially within vicinity of a locus, so are the sequencing reads along the genome. It is then crucial to take the correlated structure of such high-throughput genomic data into consideration when modeling DNA-sequencing data for CNV detection from statistical and computational viewpoints. We use the framework of a fused Lasso latent feature model to solve the problem, and propose a modified information criterion for selecting the tuning parameter when search for common CNVs is shared by multiple subjects. Simulation studies and application on multiple subjects' next-generation sequencing data, downloaded from the 1000 Genome Project, showed that the proposed approach can effectively identify individual CNVs of a single subject profile and common CNVs shared by multiple subjects.
1. Introduction
DNA copy number variation (CNV) is one of the most important genetic hallmarks of living organisms (Redon et al., 2006). Some CNVs may have very complex architectural structure in a subgroup of population(s) (Perry et al., 2008). From the studies of human genetics, it is well understood that CNVs have played important roles in the evolution process. A large study of 491 known biological pathways, along with genotype calls for 4978 CNVs in four populations, concluded that CNVs may have regulated changes in pathways at specific nodes that may have been fixed in certain populations (Poptsova et al., 2013). In a recent study (Newman et al., 2015), it was pointed out that genomic CNV is a major cause of birth defects, intellectual disability, autism spectrum disorders, psychiatric disorders, and other neurodevelopmental disabilities.
Cancer development and progression have long been considered as closely related to CNVs (Chiang et al., 2009). The 1000 Genomes Project Consortium (Consortium hereafter) (1Kgenome, 2010) aimed to discover human genome variation for different populations using sequencing technology, especially, next-generation sequencing (NGS), and continued to provide NGS data of 2504 individuals from 26 populations worldwide (1Kgenome, 2015). The distribution of human genetic variations, summarized by the Consortium, shied much light on studying human susceptibility to diseases due to their CNVs in common or different forms relevant to their ethnic identity. The Consortium data indeed provide a rich library for population health data analytics. We downloaded from the Consortium website two randomly selected subjects from nine ethnic groups. Details of these data are further given in section 5. Our goal is to develop a method that can detect common, as well as individual, CNV regions for a group of subjects across different ethnic populations.
Needless to say, finding common CNV regions shared by multiple subjects from different ethnic groups can help the study of population genetics and disease susceptibility of a population. Knowing common CNV regions shared by a group of patients having the same disease may help finding effective treatment for the targeted patient population while knowing the CNV regions unique to one individual may help advance treatment development on precision medicine. Therefore, developing computationally feasible methods for finding common and shared CNV regions using massive NGS data is biologically important. We propose to use the framework of a fused Lasso latent feature model, originally proposed in Nowak et al. (2011), for handling multiple subjects' array comparative genomic hybridization (aCGH) data without correlation to solve the challenging problem of finding common and individual CNV regions for a group of subjects, and to further propose a modified information criterion for the tuning parameter selection when search for common CNVs is shared by multiple subjects and individual CNVs. We allow the reads along the genomic positions to be correlated according to some covariance structures, this assumption is more close to reality of the data. The method can also be used in other data in which multiple subjects' information is available and when correlation exists within the readings of one subject.
2. Brief Review of Relevant Methods
The retrospective or off-line change point models have been employed for CNV detection naturally due to their model characteristics. Namely, the CNVs reflected by the data are visually and conceptually conceived as parameter changes in an underlying model of the data. Therefore, inference of the parameter changes in an underlying distribution is made during the course of analyzing such data. Circular Binary Segmentation method (Olshen et al., 2004) was the first work that used mean change point concept in DNA copy number data—the aCGH data of a single subject. A likelihood ratio procedure-based method with sliding windows approaches was proposed in Chen et al. (2011) for detecting CNV boundaries in aCGH data of a single subject.
A nonparametric approach, called screening and ranking algorithm (Hao et al., 2013; Xiao et al., 2015), was proposed to detect CNV breakpoints in aCGH data of a single subject. The multiple-subjects CNV detection problem was studied in Zhang and Siegmund (2012) by extending the Bayesian information criterion (BIC) modified in Zhang and Siegmund (2007) to adapt the multiple-subjects situation and applied the method to aCGH data. A fused Lasso latent feature model (and its R-package FLLat) was used in Nowak et al. (2011) to detect CNVs using multiple subjects based on aCGH data without consideration of correlation in the sequence of signal intensities in the vicinity of genomic positions on a chromosome.
When it comes to NGS read counts or reads ratio data for CNV detection, there are only a few studies available, in terms of using statistical change point analysis methods. For example, the modified information method, proposed in Shen and Zhang (2012), modeled the NGS read count data from one subject as inhomogeneous Poisson processes. Their approach came in two steps: the first step used a score and a generalized likelihood ratio statistics for detecting CNVs assuming the number, K, of CNVs is known, and the second aspect used a modified BIC (MBIC) for change point model selection that is also known as deciding the number of CNVs.
A computationally efficient method called the robust segment identifier was proposed by using a local median transformation on the read count data (Cai et al., 2012) for CNV detection. A mixture of Poissons was proposed as the model for detecting CNVs in NGS read data for single subject NGS profiles (Klambauer et al., 2012). The allele-specific copy number detection problem was studied in Chen et al. (2015) based on a bivariate mixed binomial process and BIC approach with application to the next-generation DNA-sequencing data. In those aforementioned works, the NGS reads data are assumed to be independent along the genomic positions for the subject, and the focus of those studies was mainly on single NGS subject sample. Magi et al. (2011) used a multivariate hidden Markov Model to formulate the problem of detecting CNVs in multiple sample NGS data and developed the JointSLM algorithm to solve the problem. A brief review of these methodological developments for CNV detection prompts us to propose an alternative method for detecting common CNV regions shared by multiple subjects and individual CNV regions using NGS data with a correlated structure among a subject's NGS reads.
3. The Proposed Approach
Let \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${y_{ \ell s}}$$
\end{document} denote the normalized sequencing read count [normalized to copy number 2, see Miller et al. (2011)] at genomic location \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\ell ( \ell = 1 , \ldots , \mathcal{L} )$$
\end{document} for subject s, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$s = 1 , \ldots , S.$$
\end{document} We propose to use the latent feature model of Nowak et al. (2011) to represent \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${y_{ \ell s}}$$
\end{document} while allowing the random errors to be correlated within the genomic positions of subject s:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
{y_{\ell s}} = \sum \limits_{j = 1}^J { \beta _{ \ell j}}{ \theta _{js}} + { \varepsilon _{ \ell s}} , \tag{3.1}
\end{align*}
\end{document}
where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$( { \beta _ { 1j } } , \ldots , { \beta _ { \mathcal { L } j }
} ) ^\prime \triangleq { \beta _ { \cdot j } }
$$
\end{document}, for \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$j = 1 , \ldots , J$$
\end{document}, represent the J latent features, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$ ( { \theta _ { 1s } } , \ldots , { \theta _ { Js } } ) ^\prime
\triangleq { { \theta _ { \cdot s } }} $$
\end{document} represents the weights on the features for sample s, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$s = 1 , \ldots , S$$
\end{document}, and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$( { \varepsilon _ { 1s } } , \ldots , { \varepsilon _ {
\mathcal { L } s } } ) ^\prime \triangleq { \varepsilon _ { \cdot
s } } $$
\end{document} is the random error term for sample s, whose components are correlated with each other.
The mentioned Model (3.1) can also be expressed in the following matrix form:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
\textbf{\textit{Y}} = \textbf{\textit{B}} \Theta + \textbf{\textit{E}} , \tag{3.2}
\end{align*}
\end{document}
where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${\textbf{\textit{Y}}_{ \mathcal{L} \times S}} = ( {y_{ \ell s}} )$$
\end{document}, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${\textbf{\textit{B}}_{ \mathcal{L} \times J}} = ( { \beta _{ \ell j}} )$$
\end{document}, and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \Theta _{J \times S}} = ( { \theta _{js}} )$$
\end{document} with the L2 restriction being \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\sum \nolimits_{s = 1}^S \theta _{js}^2 \le 1 ,$$
\end{document} for each j, and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${{ \bf{E}}_{ \mathcal{L} \times S}} = ( { \varepsilon _{ \ell s}} )$$
\end{document} with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \varepsilon _{ \ell s}}$$
\end{document} correlated along \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\ell$$
\end{document} for a given subject s. Specifically, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${\textbf{\textit{y}}_{ \cdot s}} = ( {y_{1s}} , \ldots , {y_{ \mathcal{L}s}} ) ^\prime$$
\end{document} represent the vector consisting of the normalized sequencing read counts for a given sample s on the genome (or a specific chromosome). The idea is to view normalized read counts in each sample as a weighted linear combination of the J latent features in the presence of some random noises, whereas each feature represents a particular pattern of CNV, and the weights, θ's, for a given sample determine how much each feature contributes to that sample.
Notice that CNV carries some unique features, for example, CNV regions tend to occur in contiguous blocks and probe locations within a block tend to have the common copy number (Nowak et al., 2011), whereas outside of CNV regions, such normalized copy number should be 0. Therefore, these phenomena can be mathematically well characterized by sparsity, that is, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \beta _{lj}}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \theta _{js}}$$
\end{document} in Model (3.2) can be estimated by using the fused LASSO signal approximator of Tibshirani et al. (2005), or by minimizing the following function:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
F ( \textbf{\textit{B}} , \Theta ) = \sum \limits_{s = 1}^S \sum \limits_{ \ell = 1}^ \mathcal{L} { \left( {{y_{ \ell s}} - \sum \limits_{j = 1}^J { \beta _{lj}}{ \theta _{js}}} \right) ^2} + \sum \limits_{j = 1}^J {P_{{ \lambda _1} , { \lambda _2}}} ( { \beta _{ \cdot j}} ) , \tag{3.3}
\end{align*}
\end{document}
where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${P_{{ \lambda _1} , { \lambda _2}}} ( { \beta _{ \cdot j}} ) = { \lambda _1} \sum \nolimits_{ \ell = 1}^ \mathcal{L} \vert { \beta _{ \ell j}} \vert + { \lambda _2} \sum \nolimits_{ \ell = 1}^ \mathcal{L} \vert { \beta _{ \ell j}} - { \beta _{ \ell - 1 , j}} \vert$$
\end{document} is the penalty function, whereas the first penalty term (with parameter \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \lambda _1}$$
\end{document}) encouraging sparsity and the second term (with parameter \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \lambda _2}$$
\end{document}) encouraging smoothness or sparsity in the difference of neighboring terms, and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\sum \nolimits_ { s = 1 } ^S \sum \nolimits_ { \ell = 1 } ^
\mathcal { L } { \left( { { y_ { \ell s } } - \sum \nolimits_ { j
= 1 } ^J { \beta _ { lj } } { \theta _ { js } } } \right) ^2 }
\triangleq \parallel \textbf { \textit { Y } } - \textbf { \textit
{ B } } \Theta \parallel _F^2$$
\end{document} is the usual sum of squared errors.
As in all versions of LASSO type of computing, the estimation of the model parameters and the selection of tuning parameters are the essential elements for achieving stable estimates. For given J, Nowak et al. (2011) estimated the model parameters B and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\Theta$$
\end{document} by using the block coordinate descent approach (Tseng, 1988, 2011), in which, a 2D grid searching method was used to obtain the estimators, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \hat{\textbf{\textit{B}}}}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\hat \Theta$$
\end{document}, respectively, by alternating a fixed \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\Theta$$
\end{document} or B. The two tuning parameters, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \lambda _1}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \lambda _2}$$
\end{document} in Equation (3.3), are chosen by selecting two transformed parameters \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\alpha$$
\end{document} (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$0 < \alpha < 1$$
\end{document}) and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \lambda _0}$$
\end{document} (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \lambda _1} = \alpha { \lambda _0} , { \lambda _2} = ( 1 - \alpha ) { \lambda _0}$$
\end{document}) that minimize the following BIC:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
BIC \triangleq ( S \mathcal { L } ) \cdot \log \left( \frac
{\parallel \textbf { \textit { Y } } - {
\hat{\textbf{\textit{B}}}} \Theta {\parallel}_F^2 } { S \mathcal
{L}} \right) + { k_{\alpha, {\lambda{_0} } } } \left({
\hat{\textbf{\textit{B}}}}\right) \log \left( S
\mathcal{L}\right),\quad\quad(3.4)
\end{align*}
\end{document}
where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${k_{ \alpha , { \lambda _0}}} \left({
\hat{\textbf{\textit{B}}}}\right) = \sum \nolimits_{j = 1}^J {k_{
\alpha , { \lambda _0}}} ( { \hat \beta _{ \cdot j}} )$$
\end{document} with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${k_{ \alpha , { \lambda _0}}} ( { \hat \beta _{ \cdot j}} )$$
\end{document} being the number of unique nonzero elements in the jth estimated feature, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$ { \hat \beta _{ \cdot j}}$$
\end{document}.
As noted in Zhang and Siegmund (2012) and other studies in the literature, BIC in Equation (3.4) may not be able to provide optimal parameter estimation for high-dimensional data in general. Moreover, for the latent feature model (3.2), counting only the estimated features associated with the estimated parameter \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \hat{\textbf{\textit{B}}}}$$
\end{document} does not give enough penalty in Equation (3.4). We, therefore, propose to modify the tuning parameter selection process by introducing an MBIC with an inclusion of the number of nonzero weights in the penalty. Specifically, let \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${k_{ \alpha , { \lambda _0}}} ( {\hat{\bm{\Theta}}} ) = \sum
\nolimits_{j = 1}^J {k_{ \alpha , { \lambda _0}}} (
{\hat{\bm{\theta}}}_{j \cdot } )$$
\end{document} with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${k_{ \alpha , { \lambda _0}}} ( {\hat{\bm{\theta}}}_{j \cdot } )$$
\end{document} being the number of unique nonzero elements in the weights of jth estimated feature, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$ {\hat{\bm{\theta}}}_{j \cdot }$$
\end{document}, we propose to use an MBIC to choose the tuning parameters \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \lambda _1}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \lambda _2}$$
\end{document}, in the forms of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\alpha$$
\end{document} (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$0 < \alpha < 1$$
\end{document}) and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \lambda _0}$$
\end{document}, and to examine the following four possible MBICs:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
MBI{C_1} ( \gamma ) \triangleq \ & ( S
\mathcal{L} ) \cdot \log \left( \frac { \parallel \textbf {
\textit { Y } } - { \hat{\textbf{\textit{B}}}} {\hat{\Theta}
\parallel _F^2}} {S \mathcal{L}} \right)
\\ \ & + ( 1 + {k_{ \alpha , { \lambda{_0}}}} \left(
{\hat{\textbf{\textit{B}}}} \right) + {k_{ \alpha , {
\lambda{_0}}}} ( {\hat{\Theta}} ) )^{\gamma} \log (S \mathcal{L} )
, \quad\quad(3.5)
\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
MBI{C_2} ( \gamma ) \triangleq \ & ( S \mathcal{L} ) \cdot \log
\left( \frac { \parallel \textbf { \textit { Y } } - {
\hat{\textbf{\textit{B}}}} {\hat{\Theta}
\parallel _F^2}} {S \mathcal{L}} \right)
\\ \ & + ( 1 + {k_{ \alpha , { \lambda{_0}}}} (
{\hat{\textbf{\textit{B}}}} ) )^{\gamma} \log (S \mathcal{L} ) ,
\quad\quad(3.6)
\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
MBI{C_3} ( \gamma ) \triangleq \ & ( S \mathcal{L} ) \cdot \log
\left( \frac { \parallel \textbf { \textit { Y } } - {
\hat{\textbf{\textit{B}}}} {\hat{\Theta}
\parallel _F^2}} {S \mathcal{L}} \right)
\\ \ & + 2 \gamma ( {k_{ \alpha , { \lambda{_0}}}} ( { \hat{\textbf{\textit{B}}}} ) + {k_{\alpha , {
\lambda{_0}}}} ( {\hat{\Theta}} ) ) \log ( S \mathcal{L} ) ,
{\rm{and}} \quad\quad(3.7)
\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
MBI{C_4} ( \gamma ) \triangleq \ & ( S \mathcal{L} ) \cdot \log
\left( \frac { \parallel \textbf { \textit { Y } } - {
\hat{\textbf{\textit{B}}}} {\hat{\Theta}
\parallel _F^2}} {S \mathcal{L}} \right)
\\ \ & + 2 \gamma ( {k_{ \alpha , { \lambda{_0}}}} ( { \hat{\textbf{\textit{B}}}} ) ) \log ( S \mathcal{L} ) ,
\quad\quad(3.8)
\end{align*}
\end{document}
where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\gamma \ge 1$$
\end{document} is a constant.
The estimate of J is needed in this process. Clearly, the choice of J, the number of features, and the choice of tuning parameters \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \lambda _1}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \lambda _2}$$
\end{document} mutually influence each other. Our numerical experiments suggest that a plausible way to choose J is to use a semiautomatic process, suggested by Nowak et al. (2011), that is based on the percentage of variation explained (PVE), defined as
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
PVE ( { J^* } ) = 1 - { \frac { \sum \nolimits_ { s = 1 } ^S { \sum \nolimits_ { \ell = 1 } ^ \mathcal { L } { { { \left( { { y_ { \ell s } } - \sum \nolimits_ { j = 1 } ^ { { J^* } } { { { \hat \beta } _ { \ell j } } { { \hat \theta } _ { js } } } } \right) } ^2 } } } } { \sum \nolimits_ { s = 1 } ^S { \sum \nolimits_ { \ell = 1 } ^ \mathcal { L } { { { ( { y_s } - { { \bar y } _ { \cdot s } } ) } ^2 } } } } } \tag { 3.9 }
\end{align*}
\end{document}
for given \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${J^*}$$
\end{document}, where \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \bar y_{ \cdot s}} = \sum \nolimits_{ \ell = 1}^ \mathcal{L} {y_{ \ell s}} / \mathcal{L}$$
\end{document}, and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \hat \beta _{lj}}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \hat \theta _{js}}$$
\end{document} are the estimates obtained from the aforementioned estimation procedure with one criterion [BIC or one of the four MBIC(γ) criterions]. For the potential values of J, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\{ 1 , \ldots , S \} $$
\end{document}, the PVEs can be obtained. J is then chosen as the plateau point of the PVEs, that is, any additional features will not significantly improve the estimated fit or increase the PVEs. After the plateau point J is found, the optimal tuning parameters along with the estimated values for \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \beta _{lj}}$$
\end{document}s and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \theta _{js}}$$
\end{document}s can be obtained.
We proposed the mentioned strategy to achieve the best parameter estimation for the situation. We next conducted extensive simulation studies to make recommendation on which MBIC to use among the four given in Equations (3.5)–(3.8) for the particular data and also summarize our estimation procedure in the sequel.
4. Implementation Procedure for Estimation and Simulation Studies
4.1. Simulation studies
To compare how the proposed MBICs would help to make our decision on the choices of the optimal parameters for this complex algorithm with the BIC (3.4) used in Nowak et al. (2011), especially when the data have correlation presented, we generated data according to the latent feature model (3.1) by first setting the total number of probe locations to be \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\mathcal{L} = 100$$
\end{document}, the number of subjects to be \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$S = 20$$
\end{document}, the number of latent features \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$J = 3$$
\end{document}, and the specified latent features as follows:
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
{ \beta _{ \cdot 1}} = ( { \beta _{11}} , \ldots , { \beta _{ \mathcal{L}1}} ) ^\prime { = ( 0_{10}}{ , 2_{20}}{ , 0_{30}} , - {4_{10}}{ , 0_{30}} ) ^\prime
\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
\quad\quad\quad { \beta _{ \cdot 2}} = ( { \beta _{12}} , \ldots , { \beta _{ \mathcal{L}2}} ) ^\prime { = ( 0_{10}} , - {3_{10}}{ , 0_{30}}{ , 4_{20}}{ , 0_{20}} , - {2_{10}} ) ^\prime
\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
\quad\quad\;{ \beta _{ \cdot 3}} = ( { \beta _{13}} , \ldots , { \beta _{ \mathcal{L}3}} ) ^\prime { = ( 0_{20}}{ , 4_{10}}{ , 0_{20}} , - {2_{10}}{ , 0_{30}}{ , 2_{10}} ) ^\prime ,
\end{align*}
\end{document}
where ab represents a constant vector of dimension b with every element the constant a. The weights \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\Theta = ( { \theta _{js}} )$$
\end{document} were generated by a matrix whose elements were generated from N(0, 1) and whose rows were normalized to satisfy the required L2 constraint. The random error term for the sth sample was generated from the multivariate normal distribution \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${N_ \mathcal{L}} ( { \bf{0}} , \textbf{\textit{V}} )$$
\end{document}, where V has the autoregressive correlation (AR) structure with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${V_{uv}} = { \rho ^{ \vert u - v \vert }} ( u , v = 1 , \ldots , \mathcal{L} )$$
\end{document}, or the compound symmetric correlation (CS) structure with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${V_{uv}} = \rho ( u \ne v , u , v = 1 , \ldots , L )$$
\end{document}, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${V_{uu}} = 1 ( u = 1 , \ldots , \mathcal{L} )$$
\end{document}. The results for the mean of the estimate of J based on 100 replicates are given in Tables 1 and 2 for the covariate matrix of the error term being AR and CS, respectively.
Simulation Results for the Estimated J When the Covariate Matrix of the Error Term Is AR(\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\rho$$
\end{document}) and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$( S , \mathcal{L} ) = ( 20 , 100 )$$
\end{document}
Simulation Results for the Estimated J When the Covariate Matrix of the Error Term Is CS(\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\rho$$
\end{document}) and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$( S , \mathcal{L} ) = ( 20 , 100 )$$
\end{document}
Next, to consider the performance of the estimate for J when \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$( S , \mathcal{L} ) = ( 20 , 1000 )$$
\end{document}, we set the latent features \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \beta _{ \cdot 1}} , { \beta _{ \cdot 2}}$$
\end{document}, and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \beta _{ \cdot 3}}$$
\end{document} by repeating those in the \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$( S , \mathcal{L} ) = ( 20 , 100 )$$
\end{document} case for 10 times. And the weights and the random error terms are generated in the same way as in the \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$( S , \mathcal{L} ) = ( 20 , 100 )$$
\end{document} case. The results for the mean of the estimate of J in this case are given in Table 3.
Simulation Results for the Estimated J When the Covariate Matrix of the Error Term Is AR(\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\rho$$
\end{document}) and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$( S , \mathcal{L} ) = ( 20 , 1000 )$$
\end{document}
From Tables 1–3, we conclude that the BIC given in Equation (3.4) is not able to give the estimate of the true number of features in comparison with one of the MBICs we proposed in Equations (3.5)–(3.8), and among the four proposed MBICs, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \rm{MBI}}{{ \rm{C}}_1} ( \gamma )$$
\end{document} is the best criterion with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$1 < \gamma < 2$$
\end{document}. For data with the covariate structure of the error term being \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$AR ( \rho )$$
\end{document}, the choice of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\gamma$$
\end{document} increases as the value of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\rho$$
\end{document} increases, for example, if \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\rho = 0.1$$
\end{document} or 0.5, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \rm{MBI}}{{ \rm{C}}_1} ( \gamma = 1.1 )$$
\end{document} will quickly help estimate the right number of features, for \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\rho = 0.9$$
\end{document}, one can select \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\gamma = 1.2$$
\end{document}. For data with the covariate structure of the error term being \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$CS ( \rho )$$
\end{document}, similarly, the choice of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\gamma$$
\end{document} increases as the value of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\rho$$
\end{document} increases, for example, if \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\rho = 0.1$$
\end{document}, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \rm{MBI}}{{ \rm{C}}_1} ( \gamma = 1.1 )$$
\end{document} will quickly help estimate the right number of features, for \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\rho = 0.5$$
\end{document}, one can select \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\gamma = 1.7$$
\end{document}, but for \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\rho = 0.9$$
\end{document}, no \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\gamma$$
\end{document} <2 will generate good estimate of J, but a larger \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\gamma$$
\end{document} will be able to help according to our further simulation (results not given in this article).
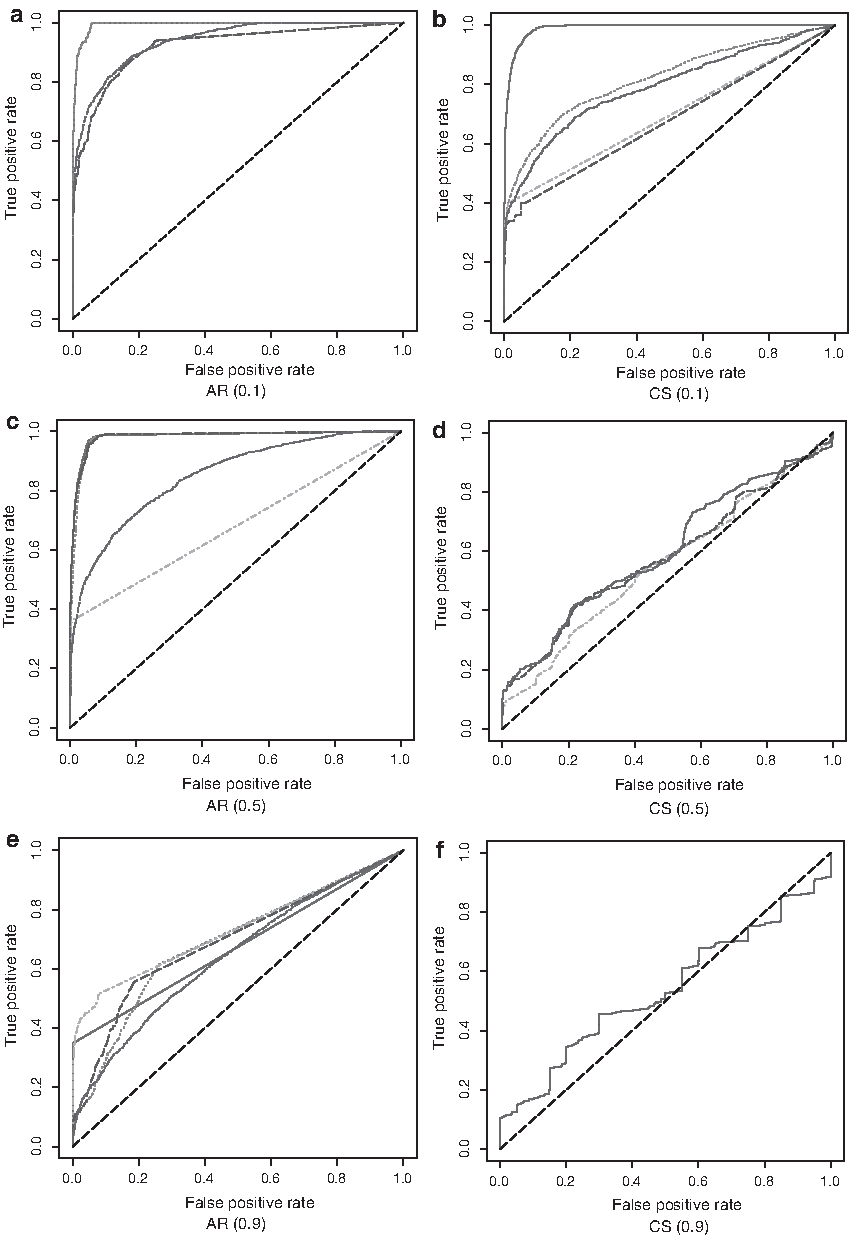
In addition to mentioned simulation studies, to evaluate how the proposed MBICs, along with the BIC given in Equation (3.4), would perform in terms of false positive and true positive rates, we obtain the receiver operating characteristic (ROC) curves for the simulated data with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$( S , \mathcal{L} ) = ( 20 , 1000 )$$
\end{document} and the covariance matrix of the error term being AR(ρ) and CS(ρ) as before. The resulting ROC curves are shown in Figure 1 with six subfigures for different scenarios as specified in the figure caption. Specifically, MBIC1, MBIC2, MBIC3, and MBIC4 with their best \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\gamma$$
\end{document} values, and BIC of Equation (3.4) were used to obtain the estimated signal, where signal was given by \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${y_{ls}}$$
\end{document} as generated previously. For each sample, a probe was declared as an aberration if its estimated signal was greater than a fixed threshold. The ROC curves in all the six situations confirm that, in general, for data with AR(ρ) structures, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \rm{MBI}}{{ \rm{C}}_1} ( \gamma )$$
\end{document} appears as the best criterion for detecting the true features and hence improve the downstream analysis for common CNV detection. This analysis confirms our proposal of using \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \rm{MBI}}{{ \rm{C}}_1} ( \gamma )$$
\end{document} for detecting common CNV regions among multiple subjects.
ROC curves for the estimate with BIC and (a) MBIC1 (1.1), MBIC2 (1.1), MBIC3 (1.3), and MBIC4 (1.3) when V = AR(0.1); (b) MBIC1 (1.1), MBIC2 (1), MBIC3 (1.2), and MBIC4 (1.9) when V = CS(0.1); (c) MBIC1 (1), MBIC2 (1.1), MBIC3 (1.2), and MBIC4 (1.2) BIC when V = AR(0.5); (d) MBIC1 (1), MBIC2 (1), MBIC3 (2), and MBIC4 (2) when V = CS(0.5); (e) MBIC1 (1.2), MBIC2 (1.3), MBIC3 (1.3), and MBIC4 (1.8) when V = AR(0.9); (f) MBIC1 (1), MBIC2 (1), MBIC3 (1), and MBIC4 (1) when V = CS(0.9). The “solid line,” “dotted line,” “dotdash line,” “longdash line,” and “twodash line” are for MBIC1, MBIC2, MBIC3, MBIC4, and BIC, respectively. AR, autoregressive correlation; CS, compound symmetric correlation; ROC, receiver operating characteristic.
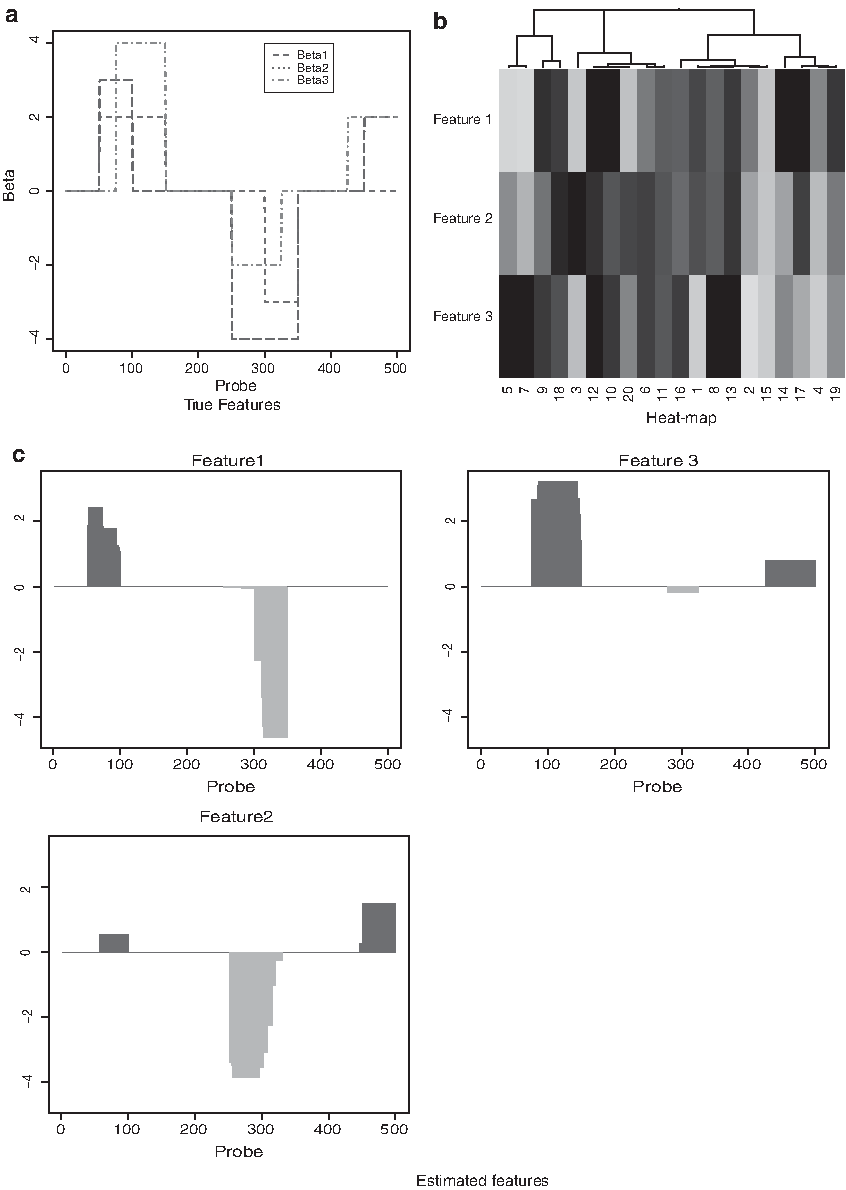
Moreover, to visualize the performance of the FLLat method based on the proposed estimate of J, we applied the method to the following simulated data, generated using \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$( S , \mathcal{L} ) = ( 20 , 500 )$$
\end{document} with the specified latent features as
\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
{ \beta _{ \cdot 1}} = ( { \beta _{11}} , \ldots , { \beta _{ \mathcal{L}1}} ) ^\prime { = ( 0_{50}}{ , 2_{100}}{ , 0_{150}} , - {3_{50}}{ , 0_{150}} ) ^\prime
\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
\quad\quad { \beta _{ \cdot 2}} = ( { \beta _{12}} , \ldots , { \beta _{ \mathcal{L}2}} ) ^\prime { = ( 0_{50}}{ , 3_{50}}{ , 0_{150}} , - {4_{100}}{ , 0_{100}}{ , 2_{50}} ) ^\prime
\end{align*}
\end{document}\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
\begin{align*}
\quad\quad{ \beta _{ \cdot 3}} = ( { \beta _{13}} , \ldots , { \beta _{ \mathcal{L}3}} ) ^\prime { = ( 0_{75}}{ , 4_{75}}{ , 0_{100}} , - {2_{75}}{ , 0_{100}}{ , 2_{75}} ) ^\prime ,
\end{align*}
\end{document}
these simulated latent features are shown in Figure 2(a). The weights and random error terms were generated in the same way as in the mentioned simulations.
The analyzed results for the simulated data of 20 samples with 500 probes under the situation that covariate structure of the error term is AR(ρ) with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\rho = 0.1$$
\end{document}. (a) The curves of the true features. (b, c) The results obtained from the FLLat method with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \rm{MBI}}{{ \rm{C}}_1} ( 1.2 )$$
\end{document}. (b) A heat-map of the estimated weights. Black and light grey indicate negative and positive weights, respectively. (c) The three estimated features.
We obtained the estimated values \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \hat y_{ \ell s}}$$
\end{document}s by using the FLLat method along with our proposed criterion \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \rm{MBI}}{{ \rm{C}}_1} ( 1.2 )$$
\end{document}. The results obtained from the FLLat method with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \rm{MBI}}{{ \rm{C}}_1} ( 1.2 )$$
\end{document} are shown in Figure 2b and c, where Figure 2b shows the heat-map of the estimated weights and Figure 2c shows the estimated features. From these subfigures, it can be found out that the estimated features are consistent with the true features.
4.2. Implementation of the proposed method
We now summarize the proposed process of detecting CNVs for multiple subjects for easy implementation:
Step 1. Optimizing the choice of J: Let J be \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$1 , \ldots , S$$
\end{document}, respectively. For each J, the optimized tuning parameters \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\hat \alpha$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \hat \lambda _0}$$
\end{document}, thus \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \hat \lambda _1}$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \hat \lambda _2}$$
\end{document} along with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\hat \beta$$
\end{document} and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${\hat{\bm{\theta}}}$$
\end{document} are obtained from the FLLat method with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \rm{MBI}}{{ \rm{C}}_1} ( \gamma )$$
\end{document} for \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\gamma \in \{ 1 , 1.1 , \ldots , 1.9 , 2.0 \} $$
\end{document}. For each γ, PVE(J) is calculated for each J by using the parameter estimates obtained previously and the plateau point \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${J_0} ( \gamma )$$
\end{document} for PVEs is found. Declare \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${J_0} ( \gamma )$$
\end{document} as the optimal value of J for this γ.
Step 2. Final parameter estimation: Let \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \gamma _0}$$
\end{document} be the one such that the optimal \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${J_0} ( \gamma )$$
\end{document} obtained from the first step gives the closest value to the true value of J, with simultaneous products of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \hat \lambda _1}$$
\end{document}, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \hat \lambda _2}$$
\end{document}, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\hat \beta$$
\end{document}s, and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${\hat{\bm{\theta}}}$$
\end{document}s.
Step 3. Visualization and common/individual CNV region detection: Use the \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\hat \beta$$
\end{document}s and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${\hat{\bm{\theta}x}}$$
\end{document}s obtained in Step 2 to obtain the predicted \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \hat y_{ \ell s}} = \sum \nolimits_{j = 1}^{{J_0}} \,{ \hat \beta _{ \ell j}}{ \hat \theta _{js}}$$
\end{document}. Then input gains and losses based on \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \hat y_{ \ell s}}$$
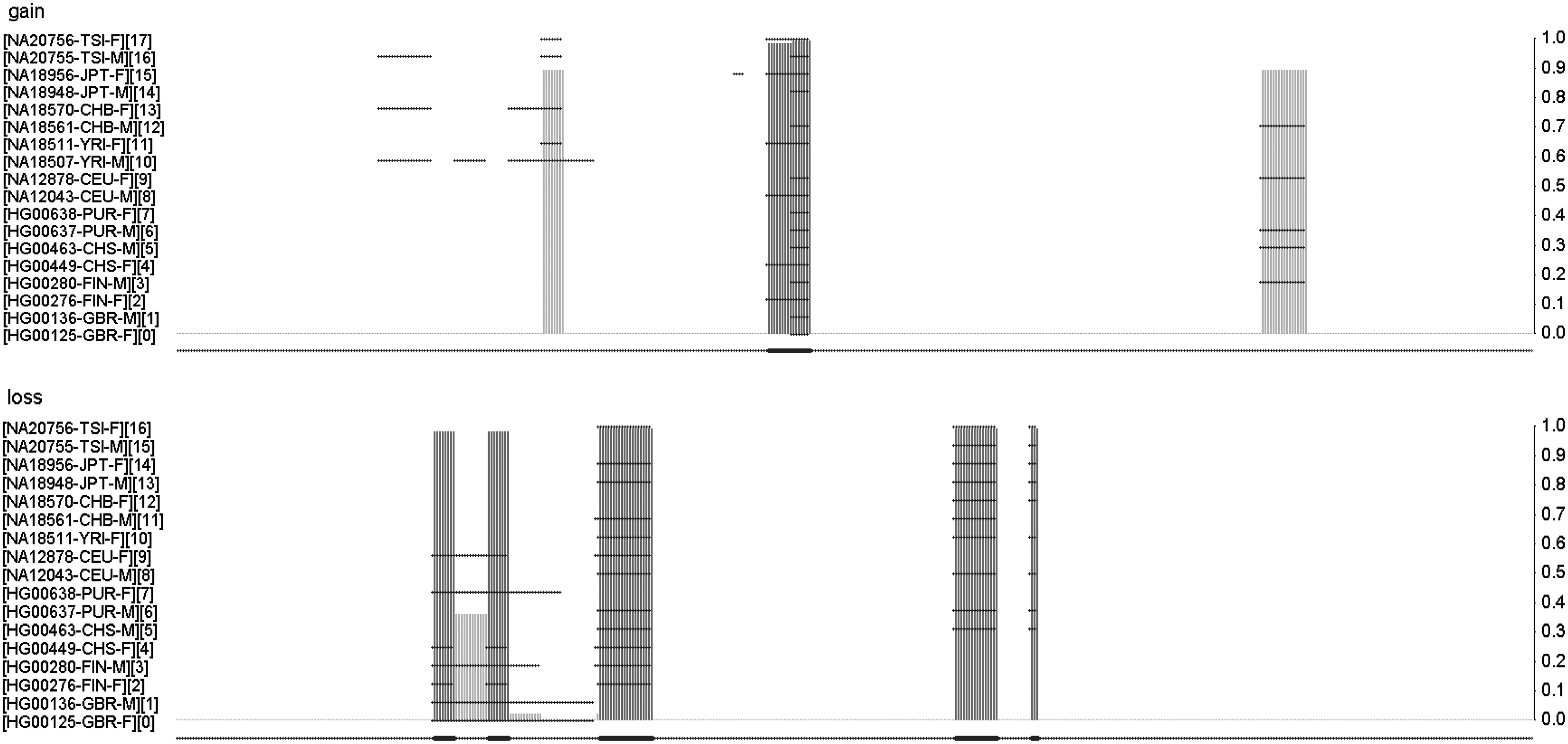
\end{document} to the Significance Testing of Aberrant Copy number (STAC) analysis to obtain visualization of the detected common/individual CNV regions and the endpoints of the regions.
5. Application to Multiple Subjects NGS Data
We then follow the mentioned implementation process to analyze 18 subjects, 1 male (M) and 1 female (F) from each of the 9 ethnic groups, whose sequencing reads are downloaded from the 1000 Genome Project Consortium. These subjects are abbreviated as GBR—British in England and Scotland, FIN—Finnish in Finland, CHS—Southern Han Chinese, PUR—Puerto Ricans from Puerto Rico, CEU—Utah residents with Northern and Western European Ancestry, YRI—Yoruba in Ibadan, Nigeria, CHB—Han Chinese in Beijing, China, JPT—Japanese in Tokyo, Japan, and TSI—Toscani in Italia with these specific subjects IDs: HG00125-GBR-F, HG00136-GBR-M, HG00276-FIN-F, HG00280-FIN-M, HG00449-CHS-F, HG00463-CHS-M, HG00638-PUR-F, HG00637-PUR-M, NA12878-CEU-F, NA12043-CEU-M, NA18507-YRI-M, NA18511-YRI-F, NA18561-CHB-M, NA18570-CHB-F, NA18948-JPT-M, NA18956-JPT-F, NA20755-TSI-M, and NA20756-TSI-F. For this study, we did not consider possible difference due to gender.
Let \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \tilde y_{ \ell s}}$$
\end{document} represent the GC-corrected read count values for individual s at the \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\ell$$
\end{document}-th genome location. Let \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$ { \mu _ { \cdot s } } = \frac { 1 } { \mathcal { L } } \sum \nolimits_ { \ell = 1 } ^ \mathcal { L } { \tilde y_ { \ell s } } $$
\end{document} denote the whole genome mean for the copy number read counts for individual s. Then the copy number read count \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \tilde y_{ \ell s}}$$
\end{document} can be normalized to copy number 2 by using \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${y_{ \ell s}} = { \tilde y_{ \ell s}} / { \mu _{ \cdot s}}$$
\end{document} for \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$s = 1 , \ldots , S , \ell = 1 , \ldots , \mathcal{L}.$$
\end{document} These \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${y_{ \ell s}}$$
\end{document} values are the input data values in our analysis.
For the genomic positions from 150,401 to 150,900 kbp (\documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\mathcal{L} = 500$$
\end{document}) on chromosome 1, the predicted values \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \hat y_{ \ell s}}$$
\end{document} of \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${y_{ \ell s}}$$
\end{document} are obtained by the FLLat method with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \rm{MBI}}{{ \rm{C}}_1} ( 1.2 )$$
\end{document}. Let \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$ { \hat \mu _ { \cdot s } } = \frac { 1 } { \mathcal { L } } \sum \nolimits_ { \ell = 1 } ^ \mathcal { L } { \hat y_ { \ell s } } $$
\end{document} for \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$s = 1 , \ldots , S$$
\end{document}, and \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$ { \hat \sigma _ { \cdot s } } = \sqrt { \frac { 1 } { { \mathcal { L } - 1 } } \sum \nolimits_ { \ell = 1 } ^ \mathcal { L } { { ( { { \hat y } _ { \ell s } } - { { \hat \mu } _ { \cdot s } } ) } ^2 } } $$
\end{document}. To visualize the profile patterns with the proposed estimate of J, we applied the STAC (Diskin et al., 2006) software to the data. To do the STAC analysis, for regions with copy number gains, we set the probe location \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\ell$$
\end{document} for sample s as 1 if \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \hat y_{ \ell s}} - { \hat \mu _{ \cdot s}} > 1.5{ \hat \sigma _{ \cdot s}}$$
\end{document} and as 0 otherwise. Similarly, for copy number losses, we set the probe location \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$$\ell$$
\end{document} for sample s as 1 if \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \hat y_{ \ell s}} - { \hat \mu _{ \cdot s}} < - 1.5{ \hat \sigma _{ \cdot s}}$$
\end{document} and as 0 otherwise. The STAC analysis results for gains (top) and losses (bottom) on the chromosome position from 150,401 to 150,900 kbp of chromosome 1 with the frequency statistic and the cutoff being 0.95 are shown in Figure 3.
The STAC analysis for gains (top) and losses (bottom) of copy numbers from position 150,401 to 150,900 kbp of chromosome 1 for all 18 subjects with the frequency statistic and the cutoff being 0.95. In the figure, 1-kb locations are plotted along the x-axis, and each sample having at least one interval of gain/loss along the chromosome is plotted on the y-axis. The gray bars track the maximum STAC confidence (1-p-value), darker bars are those with confidence >0.95. STAC, Significance Testing of Aberrant Copy number.
For the read counts data on the whole chromosome 13, estimates, \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \hat y_{ls}}$$
\end{document}, of the normalized read counts are obtained by the FLLat method with \documentclass{aastex}\usepackage{amsbsy}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{bm}\usepackage{mathrsfs}\usepackage{pifont}\usepackage{stmaryrd}\usepackage{textcomp}\usepackage{portland, xspace}\usepackage{amsmath, amsxtra}\usepackage{upgreek}\pagestyle{empty}\DeclareMathSizes{10}{9}{7}{6}\begin{document}
$${ \rm{MBI}}{{ \rm{C}}_1} ( 1.1 )$$
\end{document}, and the gains and losses are also identified. The gain intervals on chromosome 13 for the 18 subjects are given in Table 4 and loss intervals are given in Table 5. The results shown in Figure 3 are in line with the findings presented in Tables 4 and 5.
These results provide detailed common copy number gain and loss regions for these groups of 18 subjects, as well as the individual gain/loss regions, if any exist, for each one of them. The results show that all 18 subjects have 3 significant copy number gain regions (refer Table 4) and share the same 6 significant copy number loss regions (refer to Table 5) on chromosome 13, regardless of their ethnic classification. In addition, subjects 1–10 and 12–18 share one extra copy number gain region (refer second row of Table 5) on chromosome 13, and subject 11 has one more extra copy number gain region in comparison with others. Interestingly, the female GBR (British in England and Scotland, subject 2) has one more extra copy number gain region than the male GBR (subject 2), the male YRI (Yoruba in Ibadan & Nigeria, subject 11) has one more extra copy number gain region than the female YRI (subject 12), and all other female and male subjects in each of the other seven ethnic groups share the same copy number gain regions. These results may be further studied by population geneticists.
6. Conclusion and Discussion
In this article, we proposed a strategy to find common CNV regions, as well as individual CNV regions, for NGS data when correlation among the reads of a subject is considered. This strategy includes a fused Lasso latent feature model for formulating the read counts (normalized to copy number 2), a fused LASSO approach for parameter estimation, a modified information criterion for the tuning parameter selection, and an STAC analysis for visualization of the results. Extensive simulation studies showed that the strategy or pipeline of the proposed approach works efficiently for NGS data when certain correlation structure is assumed. The application of the approach to 18 subjects' NGS data (obtained from the 1000 Genome Project Consortium) has provided satisfactory results. To our knowledge, this is the first article that combines several studies in the literature to provide a complete application strategy, which includes estimation, tuning parameter selection, and visualization, to analyze NGS data of multiple subjects for common and individual CNV region detection with certain correlation structure allowed in the data. There is more theoretical work to be done on the properties of the proposed MBIC. In addition, our next steps are to apply this approach to cancer patients' data in collaboration with cancer researchers. Our other goal is to provide an R-package for the whole pipeline for practitioners to use the approach with ease.
Footnotes
Acknowledgments
The research of J.C. is supported by the Medical College of Georgia at Augusta University. Part of the work was done while S.D. was supported as a postdoctoral fellow by the Medical College of Georgia. S.D.'s research is also partly supported by the National Natural Science Foundation of China (No. 11401443).
Author Disclosure Statement
The authors declare that no competing financial interests exist.
References
1.
CaiT., JengJ., and LiH.2012. Robust detection and identification of sparse segments in ultra-high dimensional data analysis. J. R. Stat. Soc. Series B. Stat. Methodol., 74, 773–797.
2.
ChenH., BellJ.M., ZavalaN.A., et al.2015. Allele-specific copy number profiling by next-generation DNA sequencing. Nucleic Acids Res. 43, e23.
3.
ChenJ., YigiterA., and ChangK.C.2011. A Bayesian approach to inference about a change point model with application to DNA copy number experimental data. J. Appl. Stat., 38, 1899–1913.
4.
ChiangD.Y., GetzG., JaffeD.B., et al.2009. High-resolution mapping of copy-number alterations with massively parallel sequencing. Nat. Methods, 6, 99–103.
5.
DiskinS.J., EckT., GreshockJ., et al.2006. STAC: A method for testing the significance of DNA copy number aberrations across multiple array-CGH experiments. Genome Res. 16, 1149–1158.
6.
HaoN., NiuY., and ZhangH.2013. Multiple Change-point detection via a screening and ranking algorithm. Stat. Sin., 23, 1553–1572.
7.
KlambauerG., SchwarzbauerK., MayrA., et al.2012. cn.MOPS: Mixture of Poissons for discovering copy number variations in next-generation sequencing data with a low false discovery rate. Nucleic Acids Res. 40, e69.
8.
MagiA., BenelliM., YoonS., et al.2011. Detecting common copy number variants in high-throughput sequencing data by using JointSLM algorithm. Nucleic Acids Res. 39, e65.
9.
MillerC.A., HamptonO., CoarfaC., et al.2011. ReadDepth: A parallel R package for detecting copy number alterations from short sequencing reads. PLoS. One, 6, e16327.
10.
NewmanS., HermetzK.E., WeckselblattB., et al.2015. Next-generation sequencing of duplication CNVs reveals that most are tandem and some create fusion genes at breakpoints. Am. J. Hum. Genet., 96, 208–220.
11.
NowakG., HastieT., PollackJ.R., et al.2011. A fused lasso latent feature model for analyzing multi-sample aCGH data. Biostatistics, 12, 776–791.
12.
OlshenA.B., VenkatramanE.S., LucitoR., et al.2004. Circular binary segmentation for the analysis of array-based DNA copy number data. Biostatistics, 5, 557–572.
13.
PerryG.H., Ben-DorA., TsalenkoA., et al.2008. The fine-scale and complex architecture of human copy-number variation. Am. J. Hum. Genet., 82, 685–695.
14.
PoptsovaM., BanerjeeS., GokcumenO., et al.2013. Impact of constitutional copy number variants on biological pathway evolution. BMC Evol. Biol. 13, 19.
15.
RedonR., IshikawaS., FitchK.R., et al.2006. Global variation in copy number in the human genome. Nature, 444, 444–454.
16.
ShenJ.J., and ZhangN.R.2012. Change-point model on non homogeneous poisson process with application in copy number profiling by next-generation DNA sequencing. Ann. Appl. Stat., 6, 476–496.
17.
The 1000 Genomes Project Consortium. 2010. A map of human genome variation from population scale sequencing. Nature, 467, 1061–1073.
18.
The 1000 Genomes Project Consortium. 2015. A global reference for human genetic variation. Nature, 526, 68–74.
19.
TibshiraniR., SaundersM., RossetS., et al.2005. Sparsity and smoothness via the fused lasso. J. R. Stat. Soc. Series B (Stat. Methodol.), 67, 91–108.
20.
TsengP.1988. Coordinate Ascent for Maximizing Nondifferentiable Concave Functions. Technical Report LIDS-P-1840.Laboratory for Information and Decision Systems, Massachusetts Institute of Technology, Cambridge, MA.
21.
TsengP.2011. Convergence of a block coordinate descent method for nondifferentiable minimization. J. Optim. Theory Appl., 109, 475–494.
22.
XiaoF., MinX., and ZhangH.2015. Modified screening and ranking algorithm for copy number variation detection. Bioinformatics, 31, 1341–1348.
23.
ZhangN.R., and SiegmundD.O.2007. A modified bayes information criterion with applications to the analysis of comparative genomic hybridization data. Biometrics, 63, 22–32.
24.
ZhangN.R., and SiegmundD.O.2012. Model selection for high-dimensional multi-sequence change-point problems. Stat. Sin., 22, 1507–1538.