
Abstract
Abstract
This article presents a new approach to detect coiled coil and leucine zipper (L-Zip) motifs in protein sequences. The approach is based on protein scale calculation and sequence analysis. For this purpose, the wavelet-based local extrema extraction is employed, and window-based variations of local extrema afterward. This, in turn, provided a way to distinguish coiled coil subsequences and potential L-Zip motifs. The approach is validated on carefully chosen protein sequences that return inconclusive results within known frameworks for L-Zip detection, for example, 2ZIP. The results show that this new approach represents an improvement over previously presented approaches.
1. INTRODUCTION
L
Simpler statement to describe L-Zip would be that these are subsequences that are coiled coil, but with four to six heptad repeats of leucine amino acid. This means the extraction of heptads is performed first, and then the check whether they are a part of a coiled coil subsequence.
Foremost, the coiled coil prediction is essential for L-Zip prediction. In Bornberg-Bauer et al. (1998), the authors employ NCOILS, which is based on the procedure presented in Lupas (1996). This, in turn, is based on the previous work by the same authors in Lupas et al. (1991). This approach is based on a database of known coiled coil and globular proteins. It proposes a score function that clearly divides globular proteins and coiled coil proteins into two distinct groups. In Berger et al. (1995), the authors present PAIRCOIL algorithm that computes pairwise residue correlations obtained from two-stranded coiled coil residues. This correlation is a good indication whether certain protein is a coiled coil. This approach was improved in McDonnell et al. (2005).
The rest of the article is organized as follows. In Section 2, a novel approach to coiled coil prediction is presented. Second, by employing this approach, the L-Zip prediction is explained. In Section 3, the initial results from our approach are presented. In Section 4, the article concludes with the list of proteins that were used for analysis given in Appendix.
2. METHODS
In this section, the new approach to L-Zip prediction is presented. First, the procedure for detecting coiled coil in a protein sequence based on protein scale analysis is described, followed by an explanation about detection of the heptads that make an L-Zip in the same sequence. All of the sequences were obtained from NCBI protein database, focusing on those proteins that are already annotated as L-Zips.
2.1. Coiled coil prediction
This approach is based on the calculation of protein scales presented in Deleage and Roux (1987), where authors present an algorithm for predicting a secondary structure of proteins. The presented approach takes into account contents of secondary structure, that is, α-helix, β-sheet, and coiled coil. This algorithm was implemented within ExPASy server tool called ProtScale (Gasteiger et al., 2005).
Typically, results from this tool are presented as a plot of score values for all amino acids within a protein sequence. By analyzing these plots, an interesting pattern was noticed, which is further elaborated in the next paragraph. For this purpose, the protein scales for three sequences—AT1 (NC_000012.12), ATF5 (NP_036200.2), and cFOS (NP_005243.1)—were computed. The plots of these scales are presented in Figures 1–3.
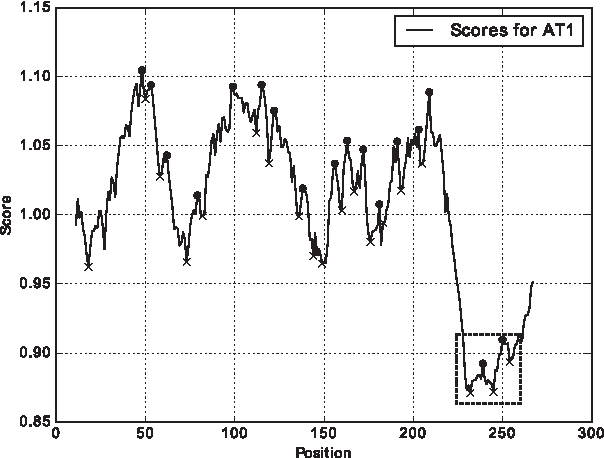
Protein scale for AT1.
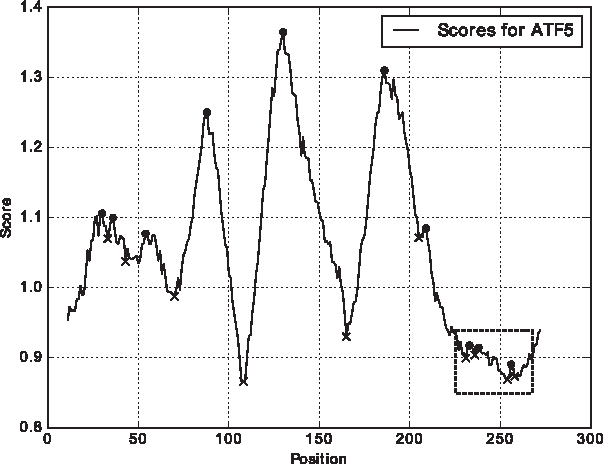
Protein scale for ATF5.

Protein scale for cFOS.
Obviously, L-Zip is a coiled coil (O'Shea et al., 1989), therefore, coiled coil prediction is a primary problem to be solved. Analyzing the proteins that truly contain L-Zip, the first point to notice is that the position of these protein subsequences could correlate with parts of the plot where protein scale value drops below a certain value. Another important point is that the plot contains variations that can lead to erroneous results by the previous assumption. Therefore, local minima and maxima are computed and labeled in these three plots. This is due to the nature of such a computation since it is in fact a window-based approach that takes values of protein scale within a certain window. Black dots represent local maxima, whereas black crosses represent local minima. As mentioned, these points are obtained by the window-based approach, which computes a local wavelet transform to detect local extrema in a signal (Du et al., 2006). The local minima and maxima variations within a frame, along with an observation that these should mostly occur below the protein scale value of 0.8971, yield a useful information about the possible coiled coil locations. This value is determined using K-means clustering algorithm presented in Hartigan and Wong (1979) and Kanungo et al. (2002). Unlike in Deleage and Roux (1987), we do not require coiled coil to be near the C-terminal, for example, BATF(NP_006390.1), which has a coiled coil in the middle of the sequence. This idea is presented with the pseudocode in Algorithm 1.
In this case, window size is determined as the largest width of rectangle such that var is <0.2. This value is empirically determined for the data set used in this article. This pattern is met with all of the tested protein sequences with experimentally verified coiled coils.
2.2. Predicting L-Zip in protein sequence
The procedure to determine potential L-Zip can be explained with the pseudocode in Algorithm 2.
As is shown in Algorithm 2, subsequences that satisfy the condition of being an L-Zip are first determined. L-Zip heptad repeats are extracted from a sequence by simple string processing. The pseudocode of the algorithm developed for this purpose is given in Algorithm 3.
All of the possible L-Zip candidates are returned as a result of detect_possible_zippers procedure. These candidates are then further processed to eliminate those not satisfying other conditions for a sequence to be a zipper sequence. For example, for the cFOS protein sequence given as
MMFSGFNADYEASSSRCSSASPAGDSLSYYHSPADSFSSMGSPVNAQDFCTDLAVSSANFIPTVTAISTS
PDLQWLVQPALVSSVAPSQTRAPHPFGVPAPSAGAYSRAGVVKTMTGGRAQSIGRRGKVEQLSPEEEEKR
RIRRERNKMAAAKCRNRRRELTDTLQAETDQLEDEKSALQTEIANLLKEKEKLEFILAAHRPACKIPDDL
GFPEEMSVASLDLTGGLPEVATPESEEAFTLPLLNDPEPKPSVEPVKSISSMELKTEPFDDFLFPASSRP
SGSETARSVPDMDLSGSFYAADWEPLHSGSLGMGPMATELEPLCTPVVTCTPSCTAYTSSFVFTYPEADS
FPSCAAAHRKGSSSNEPSSDSLSSPTLLAL
The following L-Zip candidate is obtained:
1-----10-----20-----30-----40-----50-----60-----70-----
MMFSGFNADYEASSSRCSSASPAGDSLSYYHSPADSFSSMGSPVNAQDFCTDLAVSSANFIPTVTAISTSPDLQW
------80-----90-----100-----109-----119-----129-----139-----
LVQPALVSSVAPSQTRAPHPFGVPAPSAGAYSRAGVVKTMTGGRAQSIGRRGKVEQLSPEEEEKRRIRRERNKMA
-----149-----159-----169-----179-----189-----199-----208-----
AAKCRNRRRELTDTLQAETDQLEDEKSALQTEIANLLKEKEKLEFILAAHRPACKIPDDLGFPEEMSVASLDLTG
L-----L-----L-----L-----L
-----218-----228-----238-----248-----258-----268-----278
GLPEVATPESEEAFTLPLLNDPEPKPSVEPVKSISSMELKTEPFDDFLFPASSRPSGSETARSVPDMDLSGSFYA
-----288-----298-----307-----317-----327-----337-----3
ADWEPLHSGSLGMGPMATELEPLCTPVVTCTPSCTAYTSSFVFTYPEADSFPSCAAAHRKGSSSNEPSSDSLSSP
47-----357-----367-----377-----387-----397-----406-----
TLLA
The resulting candidates are then filtered so they can correspond to coiled coil determined in the previous stage. As shown in Figure 3, the rectangle that is most probable coiled coil corresponds to the determined leucine heptads. This is in accordance with the data found in NCBI entry NP_005243.1. Similar results are obtained for longer protein sequences such as NRF2 (I59340), as well as shorter protein sequences such as JDP2 (NP_001128521.1).
3. INITIAL RESULTS AND ANALYSIS
In this section, we present the results obtained for 50 entries from NCBI database. These proteins are such that programs such as 2ZIP and NCOILS have certain problems determining both L-Zip and coiled coil subsequences for some of these proteins. Among those, which are given in Appendix A1, are those proteins that do not have coiled coil subsequences and, therefore, no L-Zip either, for example, HCFC1 (XP_006724878.1), as well as those that 2ZIP does not recognize as L-Zip, but only as a coiled coil, for example, ATF6 (AAB64434.1). The obtained results are in accordance with NCBI database entries for respective protein sequences. One notable difference is HLF (NP_002117.1) that requires a small tweak in heptad repeat detection procedure to recognize it as an L-Zip, since the length of this experimentally verified L-Zip is only one heptad repeat.
4. CONCLUSION
We have presented a new approach for L-Zip and coiled coil detection in protein sequences. Unlike 2ZIP, which employs coiled coil prediction by NCOILS, we have proposed a new approach to coiled coil prediction that employs the protein scale calculation and analysis. All the results do not differ from similar approaches mentioned in the introduction of this article. We expect that this approach will provide more flexibility in the identification of coiled coils and L-Zip. Moreover, we expect to improve this approach to relaxed leucine heptad repeats that involve iso-leucine, metionine, and valine.
5. APPENDIX