
Abstract
Abstract
DNA sequences are fundamental for encoding genetic information. The genetic information may be understood not only from symbolic sequences but also from the hidden signals inside the sequences. The symbolic sequences need to be transformed into numerical sequences so the hidden signals can be revealed by signal processing techniques. All current transformation methods encode DNA sequences into numerical values of the same length. These representations have limitations in the applications of genomic signal compression, encryption, and steganography. We propose a novel integer chaos game representation (inter-CGR or iCGR) of DNA sequences and a lossless encoding method DNA sequences by the iCGR. In the iCGR method, a DNA sequence is represented by the iterated function of the nucleotides and their positions in the sequence. Then the DNA sequence can be uniquely encoded and recovered using three integers from iCGR. One integer is the sequence length and the other two integers represent the accumulated distributions of nucleotides in the sequence. The integer encoding scheme can compress a DNA sequence by 2 bits per nucleotide. The integer representation of DNA sequences provides a prospective tool for sequence analysis and operations.
1. Introduction
In recent years, the next-generation sequencing (NGS) techniques have resulted in massive DNA and protein sequences. There are strong demands for efficiently analyzing these genomic sequences. A DNA sequence consists of four types of nucleotides: adenine (A), guanine (G), thymine (T), and cytosine (C). DNA sequence analysis requires conversion of a symbolic sequence to a numerical sequence so that intrinsic patterns and characters can be characterized by digital signal processing approaches (Anastassiou, 2000; Mendizabal-Ruiz et al., 2017; Yin and Yau, 2008; Yin and Wang, 2016). Numerical representations of DNA sequences are also essential to genome comparison, compression, encryption, and steganography.
An effective numerical representation must be able to capture all significant properties of the biological reality without introducing any spurious effects. Currently, the most commonly used encoding method is the Voss 4D binary indicator representations (Felsenstein et al., 1982; Voss, 1992), which has been used in protein-coding prediction, similarity analysis, and periodicity detection in genomes. However, the Voss 4D method and DNA sequence mapping are not one-to-one. In 1990, Jeffrey first proposed a numerical and graphical chaos game representation (CGR) of a DNA sequence (Jeffrey, 1990). The CGR is generated in a square with the four vertices for the nucleotides A, C, G, and T, respectively. In the CGR graph, the first point is placed on the halfway position between the center of the unit square and the vertex of the unit square for the first nucleotide of the DNA sequence. The successive point is generated on the halfway position between the previous CGR point and the vertex for the current nucleotide of the sequence. An important feature of the CGR is that the value of any point in CGR contains the historical information of the preceding sequence and visually displays all subsequent frequencies of a given DNA sequence. The CGR preserves all statistical properties of DNA sequences and allows investigation of both local and global patterns in DNA sequences, visually revealing previously hidden sequence structures. The CGR was then developed for k-mer counting and referred to frequency CGR, which renders a unique two-dimensional (2D) image signature for a genome sequence.
Because CGR has a remarkable ability to differentiate between genetic sequences belonging to different species, it has thus been proposed as a genomic signature (Deschavanne et al., 1999; Almeida et al., 2001). Owing to the character of information preservation of CGR, it has been applied in different research domains, including similarity analysis of genomes (Stan et al., 2010; Kari et al., 2015; Joseph and Sasikumar, 2006; Hoang et al., 2016) and detection of hidden periodicity signal in genomes (Messaoudi et al., 2014; Yin and Yau, 2005; Yin et al., 2014). However, all existing numerical representation methods of DNA sequences produce a list of values of the same length of DNA sequences, and these types of representations cannot be directly used for storing, compressing, encrypting, and aligning DNA sequences.
In this article, we propose an integer chaos game representation (iCGR) of DNA sequences, in which nucleotides of DNA sequences are represented by iterated integer functions. Using iCGR, a DNA sequence can be uniquely encoded and recovered by three integers. One of the integers is the length of the DNA sequence, and the other two integers are determined by the type and positions of nucleotides in the DNA sequence. One application of the encoding is to compress DNA sequences. The result shows that 2 bits are required for storing a nucleotide symbol in integer encoding, whereas the common character representation of a nucleotide needs 8 bits. The proposed method will have wide applications in NGS analysis.
2. Methods and Algorithms
2.1. CGR of DNA sequences
CGR is an iterative mapping and scale-independent representation for geometric representation of DNA sequences (Jeffrey, 1990). The CGR space can be viewed as a continuous reference system, where all possible sequences of any length occupy a unique position. The position is produced by the four possible nucleotides, which are treated as vertices of a unit binary square since a DNA sequence can be treated formally as a string of the four letters A, C, G, and T. In this study, we redesign the CGR corners of four nucleotides so the relationship between two nucleotides can be reflected by the distances of the CGR corners. The CGR vertices are assigned to the four nucleotides as
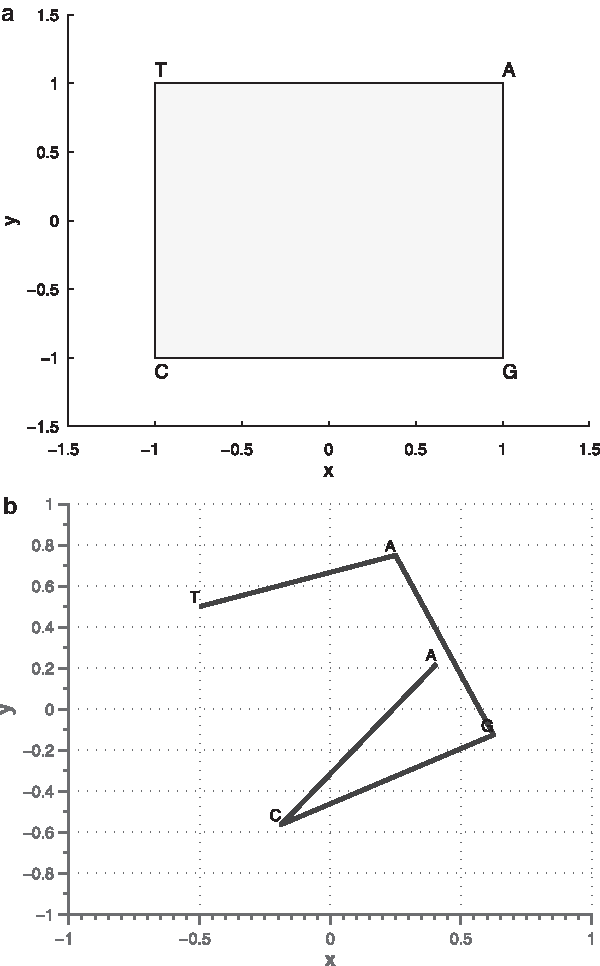
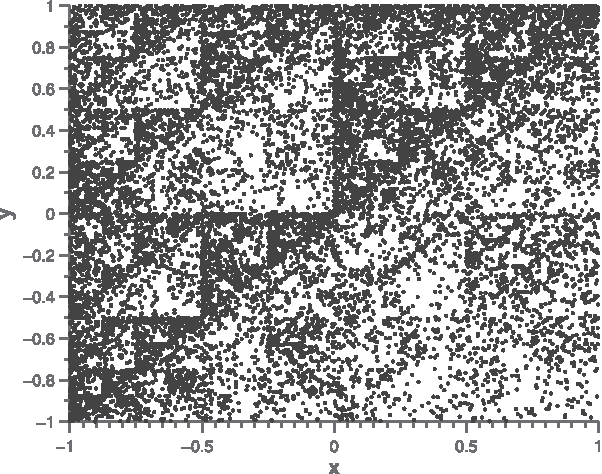
The CGR graph of human mitochondrial genome (GenBank access no.: D38116).
2.2. Encoding DNA sequences by iCGR
From the definition of CGR, we notice that the CGR coordinates of current nucleotide is determined by the CGR coordinates of the preceding nucleotide and the fixed CGR corner coordinates of the current nucleotide. According to this recursive relationship, we may get the final CGR coordinates of a DNA sequence. The CGR theorem suggests that the final coordinates contain the full DNA sequence information (Jeffrey, 1990). However, due to the floating-point errors in the computation of CGR, DNA sequences cannot be fully recovered by the final CGR coordinates. We hereto solve this lossless encoding and decoding problems that occur in the classical CGR representation.
To address the floating-point errors when encoding DNA sequences in the original CGR scheme, here we redefine a new CGR coordinate relationship as in Equations (3) and (4). Instead of taking the midpoint of the preceding position and the current CGR corner as in original CGR (Jeffrey, 1990), the current position of the new CGR schema is the sum of the preceding coordinate and exponential of two of the CGR corner [Eq. (4)]. As an example, the iCGR of a short DNA sequence, TAGCA, is illustrated in Figure 3. It should be noted that the proposed CGR mapping of DNA sequences is different from the original CGR. In the proposed CGR mapping, the coordinates of DNA sequences are integers and can extend all the 2D space, whereas regular CGR coordinates are float numbers and are limited to the unit square. Thus, we may consider that the proposed iCGR is an open mapping, and the original CGR is a closed mapping. Although the original CGR coordinates are determined by the DNA sequences from theoretical analysis, due to floating-point errors, the original CGR cannot recover a DNA sequence when the length of the sequence is longer than 32 bp. Our proposed CGR mapping results in integer coordinates without the floating-point errors; therefore, the iCGR can recover a full DNA sequence when the length of the sequence is <1024 bp. This is the significant advantage of our proposed iCGR mapping.
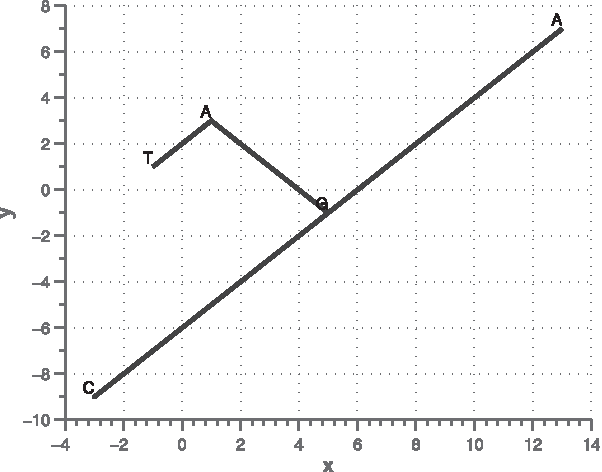
iCGR encoding the DNA sequence, TAGCA. The corresponding iCGR coordinates are:
We propose here an iCGR encoding algorithm for a DNA sequence. Using this algorithm, a DNA sequence can be uniquely represented by three numbers: the length of the sequence and the two integers of the final CGR coordinate of the DNA sequence. These integers contain all the DNA sequence information and can recover the sequence reversely. Encoding a DNA sequence into three integers by iCGR is as follows [Eq. (3)] and (Algorithm 2). We first initialize the CGR coordinate at the first position of a DNA sequence using the CGR corner coordinate, and then the following CGR coordinate is computed based on the preceding coordinate and the nucleotide at this position.
Then we can get all the current iCGR coordinates at position i based on the preceding coordinate at position
From the recursive relation [Eq. (4)], we may prove that the iCGR coordinates are the sum of the product of position exponents and nucleotide types [Eq. (5)]. When a DNA sequence of length n is finally encoded by the three integer numbers
2.3. Integer decoding DNA sequences
We can prove that the sign of pi is the same as that of nucleotide
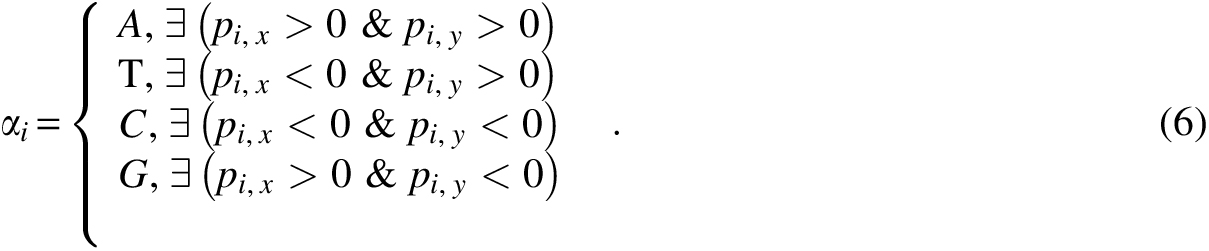
We have the following theorem on integer encoding DNA sequences.
After a DNA sequence of length n is encoded recursively by the iCGR method, then the sequence can be represented by the encoding integers
By this encoding method, we can see that any DNA sequences that end with nucleotide A are encoded by two large integers in Quadrant I, those end with nucleotide T are in Quadrant II, those end with nucleotide C are in Quadrant III, and those end with nucleotide G are in Quadrant IV. From the locations of the sequences, we can determine the type of the last nucleotide of the sequences.
After a DNA sequence is encoded into tri-integers by the iCGR scheme, the sequence can be fully recovered from the tri-integers. To recover the DNA sequence from encoded tri-integers
The tri-integers can also detect single nucleotide mutation in a DNA sequence. For example, the mutation from A to T in a DNA sequence, of which the wild-type sequence is represented by tri-integer
It is noted that the encoding scheme can detect an error if the given tri-integers are not for a DNA sequence. In each step of decoding, the value of each nucleotide can be recovered. If the values are not 1/-1 pairs, then the given tri-integers are not for a DNA sequence. Therefore, when DNA sequences are encoded by the proposed iCGR, if there is an error during data storage and transfer, the iCGR encoding and decoding method can detect this error at the location.
3. Results
In the encoding and decoding algorithms, we consider two classes of four different bases in DNA, the pyrimidines [cytosine (C) and thymine (T)], and the purines [adenine (A) and guanine (G)], and design new CGR corners. The algorithms use integer iteration so the relationship between nucleotide positions and encoding integers are one-to-one. We perform case studies for evaluating the effectiveness of the integer encoding and decoding algorithms in sequence representation and compression.
An example of encoding a short DNA sequence of length 10 bp is illustrated in Table 1. Table 1 shows the encoded
Encoding a DNA Sequence of Length 10 by Tri-Integers
A, adenine; C, cytosine; G, guanine; T, thymine.
An example of decoding a DNA sequence is illustrated in Table 2. Table 2 shows the encoded integers
Decoding a DNA Sequence from Tri-Integers
Another example of encoding is for encoding Homo sapiens globin gene (GenBank access no.: HF583935). For each position of the sequence, we generate the encoding iCGR coordinates as shown in Figure 4. The final encoding tri-integers for this gene are (171, 2050339409081302816541928568690764733194931295596027, 1119453162673286728512143679440023858905057236646823).

Integer encoding Homo sapiens globin gene (GenBank access no.: HF583935).
Using the encoding method, the average bits of the tri-integers per nucleotide is 2.0, whereas symbolic DNA sequences need 8 bits per nucleotide. For example, the total bits of the tri-integers for the Homo sapiens globin gene are 349 bits, each nucleotide needs 2.041 bits. Therefore, encoding DNA sequences as the tri-integers may save storage space.
4. Conclusions
We present a novel method for encoding a DNA sequence into three integers. Encoding a DNA sequence by iCGR produces unique tri-integers that contain all sequence information. Therefore, the tri-integers from encoding a DNA sequence can be considered as the mathematical descriptor of the sequence. The encoding method can be a promising tool for DNA sequence compressions, encryption, and steganography.
Footnotes
Acknowledgment
We are grateful to Professor Jiasong Wang at the Department of Mathematics, Nanjing University for helpful discussion.
Author Disclosure Statement
The author declares that no competing financial interests exist.