
Abstract
Abstract
G-quadruplex (G-Q) is advanced DNA or RNA secondary structures frequently found in plant and involved in important biological processes such as transcription, translation, and telomere maintenance. Although some databases and tools were developed for predicting and studying G-Q, none of them was for plant. With the development of next-generation sequencing technology, a large number of plant genomes have been assembled and annotated to provide opportunities for mining G-Q. Plant G-quadruplex database (Plant-GQ) was constructed for predicting G-Q in 195 plants. It has a total of 626,341,645 predicted G-Qs. The database contains four major parts: Search, Tools, JBrowse, and Download. Not only G-Q information but also online forecasting tool can be retrieved and obtained from Plant-GQ. It can also browse and analyze G-Q information by JBrowse in a graph visualization interface. Considering the key role of G-Q in plant, this database will play an important status in the study of the structure, function, and biological relevance of G-Q in plant.
Highlights
1. Plant-GQ is the first database for G-quadruplexes in plant. 2. It contains 195 plant species, a total of 626,341,645 predicted G-quadruplexes. 3. It also provides a user-friendly platform for querying, browsing, and downloading G-quadruplex information.
1. Introduction
Plant DNA, in addition to double helical B-DNA, has various extra-helices (Bochman et al., 2012). G-quadruplex (G-Q) is one of the secondary structures that is ubiquitous and plays an important role in the physiological functions of all living organisms. Structurally, G-Qs are formed by π–π stacking of G-quartet composed of four guanines connected by Hoogsteen hydrogen bonds (Guedin et al., 2018). The layout and bonding to make up G-Q are not random and have very unusual functional purposes (Bochman et al., 2012; Cheng et al., 2018). Depending on the direction of the strands that makes up the quartets, structures can be described as parallel or antiparallel (Moye et al., 2015). These quadruplex structures are stabilized by cations, especially potassium ion (K+). Cations are located in the central channel between each pair of quartets (Bhattacharyya et al., 2016). The complex structure of G-Q determines the complexity of its function.
Since Sen and Gilbert discovered G-Q (Sen and Gilbert, 1988), the study of G-Q has become increasingly hot and developed into a field of preface. The reason for this phenomenon is that G-Qs are widely present in eukaryotic and prokaryotic and concentrate on many functional areas (Beaume et al., 2013; Jackowiak et al., 2017). For example, a high proportion of potential G-Q structures are in G-rich regions of telomeres (Moye et al., 2015; Noer et al., 2016), promoters (Beaume et al., 2013; Voter et al., 2018), mitotic and meiotic double-strand break sites (Lemmens et al., 2015), ribosomal DNA (Wallgren et al., 2016), transcriptional start sites (Morgan et al., 2016), and untranslated regions of messenger RNA (Stefanovic et al., 2015). In human and mammal, the structure of G-Q is related to the instability of the genome (Yadav et al., 2016) and its widespread existence and occurrence in proto-oncogenes (Thandapani et al., 2015). These proto-oncogenes include c-myc (Borgognone et al., 2010), c-myb (Miyazaki et al., 2012), c-kit (Wei et al., 2015), bcl-2 (Feng et al., 2016), KRAS (Cogoi and Xodo, 2006), RET (Garg et al., 2016), VEGF (Sun et al., 2005), and HIF-1 (Du et al., 2009). Distribution of these G-Qs suggests their key role in cancer progression (Wolfe et al., 2014). In bacteria, G-Q is likely to concentrate on the promoter region and regulate the transcription, signaling, and other special functions (Rawal et al., 2006; Beaume et al., 2013). In addition, G-Q plays an important role in Neisseria gonorrhoeae antigenic variation (Cahoon and Seifert, 2009).
G-Q is also abundant in plant. The whole-genome discovery and analysis of G-Q results from 15 monocotyledons and dicotyledons indicated that G-Q was involved in important physiological processes such as plant development, cell growth and size, and gene expression regulation (Garg et al., 2016).
In recent years, a number of databases concerning G-Qs are currently available. Greglist lists genes that contain promoter G-Qs from genomes of different species, including human, mouse, rat, and chicken (Zhang et al., 2008). GRSDB is a database of G-Q near RNA processing sites in human and mouse (Kostadinov et al., 2006). G4RNA was created to help meet the need for known RNA G-Q data (Garant et al., 2015). G4IPDB is a database for G-Q forming nucleic acid interacting proteins (Mishra et al., 2016). In addition, prediction algorithms such as QuadParser (Scaria et al., 2006), G4 calculator (Eddy and Maizels, 2006), QGRS-Conserve (Frees et al., 2014), QGRS mapper (Kikin et al., 2006), and QuadBase2 (Dhapola and Chowdhury, 2016) can also be easily accessible and used widely. However, these databases are all for human and mammal. Therefore, it is urgent to establish a comprehensive and unified database of G-Q in plant.
With the reduction in the cost of sequencing, more and more plant genomes have been assembled and annotated. For better study of G-Qs in plant, mining and annotation of G-Qs in these genomes are essential. In this study, a structure-based approach was used for G-Q determination and annotation in the genomes of sequenced plant. Plant G-quadruplex database (Plant-GQ) contains a series of user-friendly webpage for query and presentation of G-Q. Plant-GQ will greatly accelerate the study of various regulatory effects of G-Qs. The database is obtained from http://biodb.sdau.edu.cn/plantgq/index.php
2. Methods
2.1. Data sets
Genome and GFF3 files were downloaded from public data platforms (http://biodb.sdau.edu.cn/plantgq/Public/table/Supplementary%20Table1.xlsx). For each plant species, the G-Q information was mined and annotated in genome and GFF3.
2.2. Identification of G-Q
Based on the following G-Q motif, the G-Qs were identified by Perl scripts (Huppert and Balasubramanian, 2007):
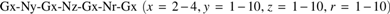
x is the number of guanine tetrads in each short G-tract. In G-Q motif, the four groups of guanines are of equal length. Ny, Nz, and Nr can be any combination of four residues A, T, G, and C, forming the loops. y, z, and r are the lengths of the loops.
2.3. System implementation
The server of Plant-GQ was constructed using Centos 6.5, Apache 2.4.27, MySQL 14.4, PHP 7.1.9, ThinkPHP 3.2.3, and xampp 3.2.2. For efficient management, query, and presentation, all G-Q information was stored in MySQL tables. The web interface was developed by HTML5, CSS, and JavaScript languages. Common Gateway Interface programs were built by Perl and PHP programming languages. A complete flowchart portraying the data collection and content management steps in building the Plant-GQ is provided with Figure 1.
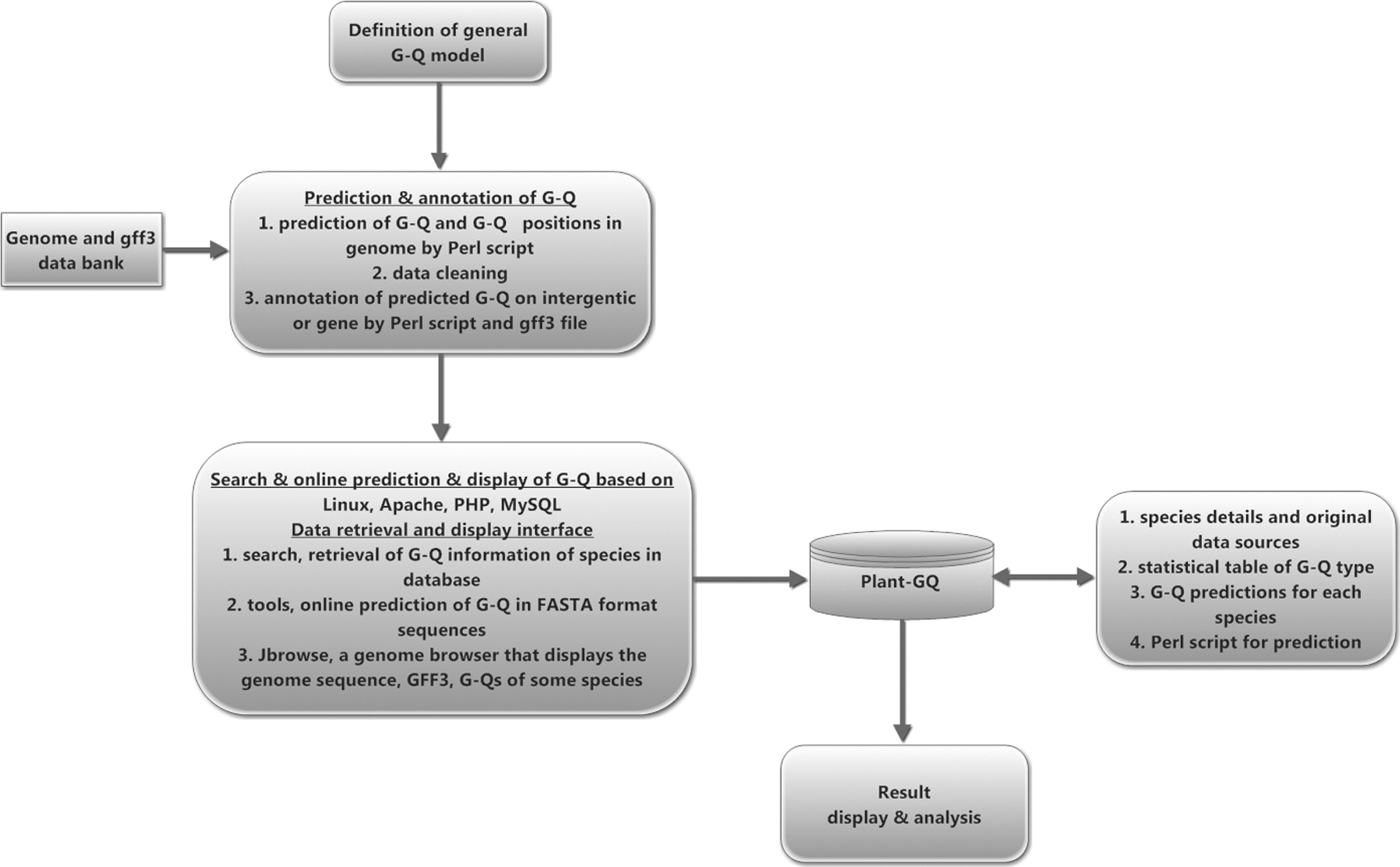
Schematic representation of Plant-GQ. G-Q, G-quadruplex; Plant-GQ, Plant G-quadruplex database.
3. Results
3.1. Summary of G-Q
A total of 626,341,645 putative G-Qs were identified with 195 plant species. The total G-Qs of two G-tracts, three G-tracts, and four G-tracts were 610,897,949, 14,326,347, and 1,117,349, respectively. Apparently, most of them are two G-tracts, accounting for 97.43% of the total. The G-Q formed by four G-tracts is the most stable, but the proportion of the smallest, which accounted for 0.19%.
3.2. Database features and data retrieval and display tools
A complete flowchart depicts the main contents of the database (Fig. 2). To facilitate the query and browsing of G-Q information, Plant-GQ provides query function, online tool, and graphical visualization page.

Overview of Plant-GQ. This database contains four major parts: Search, Tools, JBrowse, and Download.
The search interface allows users to filter G-Qs through four categories, including species, chromosome, G-Q type, and start and end. For species searches, a drop-down menu lists all species in Latin alphabetical order (Fig. 3A). The predicted G-Qs that comprise the search results will be listed in search results interface (Fig. 3B). The search results interface is a list of 30 rows at a time. Each G-Q entry contains details of the species, chromosome, type, start, end, motif, and location. If more than 30 results are generated in a search, users can navigate between pages using the paging bar at the top of search results interface. In addition, the total number of filtered results is shown at the top of the paging bar. All results of search results interface can be downloaded in batches of “GQ-result” in download interface.

Screenshots of data retrieval and display interface.
A tools interface is mainly used for online prediction of G-Qs. Common sequences in FASTA format, such as gene or CDS sequences, can be pasted directly into textarea (Fig. 3C). The query results include chromosomes, positive and negative chains, start and end, motif, G-tract, and loops type which will be opened with a new interface (Fig. 3D). Full information about the predicted G-Qs can also be downloaded in tools results interface.
JBrowse provides a convenient genome browser that displays the genome sequence, GFF3, G-Qs of some species. Select a species in the table for large-scale browsing in the graphical visual interface. In graphical visualization interface, the left column lists the reference sequence of the plant species genome, GFF3 choice, and G-Q locations. The GFF3 information and G-Q locations will be displayed in the right column as a histogram when the selection item in the left column is clicked. The top column allows to select the species' chromosomes and zoom in or out of the results. The detail information about G-Q can also be conveniently browsed by clicking on the G-Q name of the visual interface (Fig. 3E).
4. Conclusions and Future Directions
Plant-GQ provides a user-friendly platform for querying, browsing, and downloading G-Q information. The database contains 626,341,645 G-Qs. In addition, Plant-GQ accelerates scientific research by mining G-Q for analysis of its various regulatory effects in plant. In the future, more G-Q structures will be identified as the information on genomes continues to improve. Furthermore, Plant-GQ will be upgraded and will optimize the database interface at regular intervals.
Footnotes
Acknowledgments
This work was supported by the Foundation of Shandong Province Modern Agricultural Technology System Innovation Team (SDAIT-25-02 to L.Y.) and the Open Project Program of Beijing Key Laboratory of Grape Science and Enology.
Author Disclosure Statement
The authors declare that there are no competing financial interests.