
Abstract
1. Introduction
Aribonucleic acid (RNA) is single stranded and can be viewed as a sequence of nucleotides (also known as bases, denoted by A, C, G, and U). It plays an important role in regulating genetic and metabolic activities according to the central dogma of biology. To understand the biological functions of RNAs elaborately, we should know their structures at first. The primary structure of an RNA strand is formed by the order of the nucleotides. An RNA folds into a three-dimensional structure by forming hydrogen bonds between nonconsecutive bases that are complementary, such as the Watson–Crick pairs C-G and A-U and the wobble pair G-U. The three-dimensional arrangement of the atoms in the folded RNA molecule is the tertiary structure; the collection of base pairs in the tertiary structure is the secondary structure. Actually, the secondary structure can tell us where there are additional connections between the bases and where the RNA molecule could be folded. In the article (Tinoco and Bustamante, 1999), the author claimed that “the folding of RNA is hierarchical, since secondary structure is much more stable than tertiary folding”, which results in that, the tertiary folding would obey the secondary structure mostly. Since the three-dimensional structure determines the function of the RNA to some extent, predicting the secondary structure of RNA becomes a key problem to study RNA in a larger and deeper scope.
Nussinov et al. (1978) began considering the computational study of RNA secondary structure prediction, but this problem is still not well solved yet. The biggest impediment is the existing of pseudoknots, which are composed of two interleaving base pairs provided when we arrange the RNA sequence in a linear order.
Lyngsø and Pedersen (2000) have proven that determining the optimal secondary structure possibly with pseudoknots is NP-hard (nondeterministic polynomial-hard) under special energy functions. And Akutsu (2000) has shown that it remains NP-hard, even if the secondary structure requires to be planar. There are a lot of positive works where there are no pseudoknots. Nussinov et al. (1978), Nussinov and Jacobson (1980), Zuker and Stiegler (1981), Zuker and Sankoff (1984), Sankoff (1985), and Lyngsø et al. (1999) have computed the optimal RNA secondary structure in
To predict secondary structures with pseudoknots, most research focus on the base pairs individually. The nearest neighbor energy model was studied popularly (Akutsu, 2000; Lyngsø and Pedersen, 2000; Ieong et al., 2003; Lyngsø, 2004): the energy of each base pair depends not only on its two bases but also on the other adjacent base pairs. According to the Tinoco model (Tinoco et al., 1973): an RNA structure can recursively be decomposed into loops with independent free energy; the energy of each loop is an affine function in the number of unpaired bases and the number of interior base pairs. The only type of loops without unpaired bases is formed by two adjacent and parallel base pairs, which is called a stacking; the negative energy of such stackings stabilizes the RNA structure. Lyngsø (2004) initiated the study for the maximum stacking base pairs problem. He showed this problem to be NP-hard and devised a polynomial-time exact algorithm over a fixed-size alphabet Σ and with a subset of Σ × Σ of legal pair types. Unfortunately, this algorithm has very high complexities of
Among all the above results, the base pairs are given implicitly, that is, under some fix biology principle, for example, Watson–Crick base pairs: A-U and C-G, any such two bases can form a base pair. As an alternative, the set of candidate base pairs may be given explicitly as input, because there could be additional conditions from comparative analysis which prevent two bases forming a pair. It would generalize the maximum stacking base pairs problem with explicit base pairs, so the problem remains NP-hard. Jiang (2010) improved the approximation factor for the maximum stacking base pairs problem with explicit base pairs to 5/2. Zhou et al. (2017) further improved the approximation factor to 7/3 by a local search method. Once the candidate base pairs are taken as the input for this problem, naturally, we can put restriction and generalization on it. Similar to the research on graph problems, one basic restriction is to bound the degree of each base, that is, we require each base to associate with at most a constant of k candidate base pairs. This problem is called k-MSBP. In addition, in light that the optimal secondary structure has the minimum negative energy, we generalize this problem to the weighted version, where we give each base pair a weight (representing energy) and the problem becomes computing a maximum weight stacking base pairs, this problem is called k-MWSBP. So far as we know, there are no results on k-MWSBP.
The main contributions of this article are: (1) we show that k-MSBP is APX-hard for k ≥ 2; (2) we devise an approximation algorithm with a factor of
2. Preliminaries
Let
Now we present the formal definition of the problems studied in this article.
k-MSBP is a special case of k-MWSBP with all base pairs having a weight of 1. In the next section, we will prove that k-MSBP is APX-hard, which implies that k-MWSBP is also APX-hard. Note that an approximation algorithm for k-MWSBP also works on k-MSBP.
3. Hardness Results
In this section, we will show that k-MSBP is APX-hard by a reduction from the Maximum Independent Set Problem on Cubic Graphs (3-MIS).
For the sake of simplicity, we just prove that 2-MSBP is NP-hard and then APX-hard, which means that k-MSBP is also APX-hard for all k ≥ 2.
Given a cubic graph
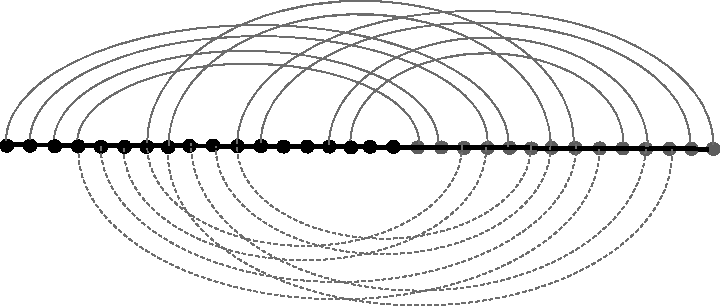
The RNA subsequence and base pairs corresponding to a vertex. RNA, ribonucleic acid.
To make use of the edges, we first orient the edges of G in such a way that each vertex has at most two incoming edges and at most two outgoing edges. This can be done as follows: iteratively find edge-disjoint cycles in G and, in each cycle, orient the edges to form a directed cycle. The remaining edges form a forest till there does not exist any cycle. For each tree in the forest, choose one of its nodes of degree one to be the root and orient all edges in the tree away from the root. This orientation will clearly satisfy the desired properties.
For each vertex v, we name
Construct new base pairs as follows:
If If If If
Proof. From our construction, each RNA subsequence can have a feasible secondary structure with either 10 base pairs or 8 base pairs. The crucial observation is that, if there is an edge (u, v) between two vertices in G, then the RNA subsequence corresponding to u and v cannot both have feasible secondary structures with 10 base pairs.
So, if there is an independent set I of size l in G, for u ɛ I, choose a feasible secondary structure with 10 base pairs; for
Conversely, if there is a feasible secondary structure FS(RG) of size f, let I consist of all vertices u such that the subsequence corresponding to u contributes 10 base pairs; it is obvious that I is an independent set, and
Proof. Note that the maximum stacking base pairs instance we construct from an instance of 3-MIS is actually an instance of 2-MSBP. Let I be an instance of 3-MIS and OPT(I) be its optimal solution. Let f (I) be an instance of 2-MSBP constructed from I and
This completes the proof.
4. Approximation Algorithms for k-MWSBP by LP-Rounding
In this section, we will design an approximation algorithm for k-MWSBP by a nonlinear LP-rounding method. First, we formulate k-MWSBP as a 0–1 Integer Linear Program (ILP). Let
ILP-(1):
Constraints (1) guarantee that the chosen base pairs are mutually compatible. Constraints (2) require that each chosen base pair must have at least one adjacent partner. Relaxing ILP-(1) to the linear programming formulation.
LP-(2):
Proof. To obtain a feasible secondary structure, every chosen base pair must be compatible with each other; we say that such base pairs are effective. Let
where c is a constant, to be determined later. To make effective base pairs (si, sj) chosen into the feasible secondary structure, it also requires at least one of (
Since
Let APP denote the size of the output solution of Algorithm 1, OPT denote the size of the optimal solution, which is also the optimal solution of ILP-(1), and OPT(LP) denote the optimal solution of LP-(2). Obviously,
Let
By setting
Proof. The difference between k-MWSBP and 2-MWSBP is the degree of bases. In an k-MWSBP instance, a base pair (si, sj) is not compatible with
by constraint (1),
The probability that (si, sj) takes part in constituting stacking is
Let
By setting
5. Simulations
In this section, we show some experiments on randomly generated simulated data. In the simulated data, the length of the RNA sequences ranges from n = 500 to n = 2000, we choose three values for k: k = 2, k = 3, k = 4. For comparison, besides running the LP-rounding approximation algorithm, we also run the ILP-(1) to obtain the optimal solutions (although when n gets large, the running time gets really high.) The performance is summarized as follows.
5.1. Performance evaluation
For k = 2, the experimental results are shown in Table 1 and Figure 2. As what is stated in Theorem 2, the approximation factor for 2-MWSBP is about 31. From the experimental results in Table 1, the actual approximation factor is about 5.41, which is much better than the theoretical bound.

The plot graph of the optimal solution and the approximate solution generated by Algorithm 1, when k = 2.
Values of Optimal Solution [OPT(I)], Approximation Solution [APP(I)], and the Approximation Factor, When k = 2
For k = 3, the experimental results are shown in Table 2 and Figure 3. Similarly, the actual approximation factor is about 14.16. The theoretical approximation factor for 3-MWSBP is about 121. Again, the experimental results show much better performance compared with the theoretical results.
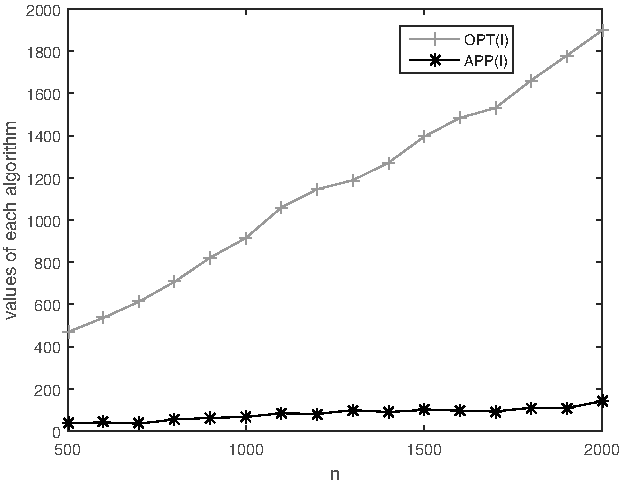
The plot graph of the optimal solution and the approximate solution generated by Algorithm 1, when k = 3.
Values of Optimal Solution [OPT(I)], Approximation Solution [APP(I)], and the Approximation Factor, When k = 3
For k = 4, the experimental results are shown in Table 3 and Figure 4. While the practical approximation factor fluctuates more in the case, the average approximation factor is about 26.38. The theoretical approximation factor for 4-MWSBP is about 270.
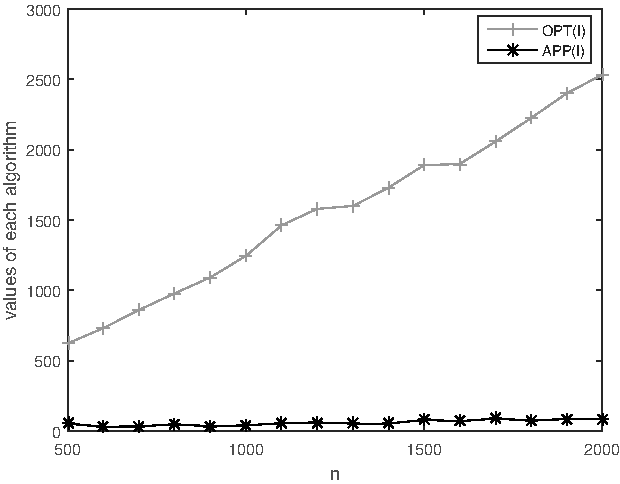
The plot graph of the optimal solution and the approximate solution generated by Algorithm 1, when k = 4.
Values of Optimal Solution [OPT(I)], Approximation Solution [APP(I)], and the Actual Approximation Factor, When k = 4
From our experimental results, we can conclude that the actual performance of our algorithm is much better than the corresponding theoretical bound; the reason is probably due to that the theoretical result is based on the worst-case analysis.
5.2. Runtime analysis
As discussed above, solving the ILP-(1) takes quite a lot of time when n grows larger. Hence, we compare the running time of solving the ILP and our LP-rounding approximation algorithm. The results are summarized in Table 4 and Figure 5. As shown in Figure 5, solving the ILP takes much more time as n increases, while the running time of our approximation algorithm is very stable. This is probably due to that the ILP solver takes exponential time, while the approximation algorithm takes polynomial time.
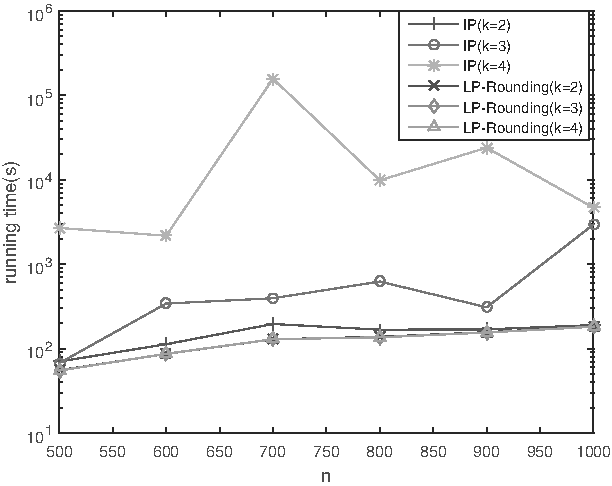
The plot graph of the running times of the ILP and LP-rounding algorithms. ILP, Integer Linear Program; LP.
The Running Time (Seconds) of Solving the Integer Linear Program and The LP-Rounding Approximation Algorithm
ILP, Integer Linear Program; LP.
6. Concluding Remarks
In this article, we studied a restricted version of the maximum stacking base pairs problem, which originates from RNA secondary structure prediction. Regardless of whether the base pairs are weighted or not, we show that this problem is APX-hard, when the degree of each base is bounded by a constant k. In addition, we design the first approximation algorithm with a factor of
Footnotes
Author Disclosure Statement
The authors declare they have no conflicting financial interests.
Funding Information
This research is supported by NSF of China under Grant Nos. 61872427, 61732009, and 61628207, by NSF of Shandong Provence under grant ZR201702190130. H.J. is also supported by Young Scholars Program of Shandong University. P.L. is also supported by Key Research and Development Program of Yantai City (No. 2017ZH065) and CERNET Innovation Project (No. NGII20161204).