
Abstract
With ever growing amounts of omics data, the next challenge in biological research is the interpretation of these data to gain mechanistic insights about cellular function. Dynamic models of cellular circuits that capture the activity levels of proteins and other molecules over time offer great expressive power by allowing the simulation of the effects of specific internal or external perturbations on the workings of the cell. However, the study of such models is at its infancy and no large-scale analysis of the robustness of real models to changing conditions has been conducted to date. Here we provide a computational framework to study the robustness of such models using a combination of stochastic simulations and integer linear programming techniques. We apply our framework to a large collection of cellular circuits and benchmark the results against randomized models. We find that the steady states of real circuits tend to be more robust in multiple aspects compared with their randomized counterparts.
1. Introduction
Protein–protein interaction networks have been mapped for over a decade using techniques such as yeast two-hybrid and coimmunoprecipitation. Comprehensive maps are available for multiple species, including yeast and human, with hundreds of thousands of interactions in each [see e.g., the BioGRID database (Chatr-Aryamontri et al., 2015)]. As we and others have shown, substantial portions (over 40%) of those maps are spanned by signaling interactions (Silberberg et al., 2014). Thus, protein networks have been extensively used for interpreting genome-wide screens in the context of a phenotype of interest. Previous work in this regard can be broadly categorized into topology based and logic based. The first category includes the vast majority of current studies. It aims to characterize a given phenotype by the following: (i) the location of its affected proteins in a network, identifying network regions, or modules that are associated with the phenotype (Ideker et al., 2002; Dittrich et al., 2008; Shachar et al., 2008; Huang and Fraenkel, 2009; Yeger-Lotem et al., 2009; Yosef et al., 2009; Vandin et al., 2011; Cowen et al., 2017); and (ii) the network-based attributes of the proteins, such as degree of connectivity and more (Said et al., 2004; Jonsson and Bates, 2006).
The second logic-based category aims to provide mechanistic models for the phenotype of interest (Novere, 2015). While a variety of models can be used, most prior works focus on logical (Boolean) models or variations thereof (Morris et al., 2010), thanks to the rich history of these models in the biological domain (Kauffman, 1969). These works include Boolean modeling of fundamental systems such as epidermal growth factor receptor (EGFR) signaling (Oda et al., 2005; Samaga et al., 2009) and mitogen-activated protein kinase (MAPK) signaling (Grieco et al., 2013); algorithms to optimize Boolean models against experimental data (Mitsos et al., 2009; Saez-Rodriguez et al., 2009; Moignard et al., 2015); algorithms to traverse the state space of a model (Dubrova and Teslenko, 2011; Chaouiya et al., 2012; Qiu et al., 2014); and generalizations of these models to multivalued (Morris et al., 2011; Huard et al., 2012), constraint-based (Dasika et al., 2006; Vardi et al., 2012), and probabilistic (Gat-Viks et al., 2006) ones.
The advantage of the latter logic-based models is that they allow simulating a process of interest under different genetic and environmental perturbations. In recent years, a concentrated community effort has led to the curation of dozens of logic models for a diverse array of cellular processes (Ideker et al., 2002), providing for the first time the opportunity to study the properties of these circuits at large scale.
Since biological processes need to operate consistently in a noisy environment, they must be robust to perturbations, such as stochastic changes in molecular concentrations and protein activity. Extensive research has been done on empirical stability of biological processes (Alon et al., 1997; Li et al., 2004), as well as stability of Boolean models (Aldana and Cluzel, 2003; Sevim and Rikvold, 2008; Fretter et al., 2009; Peixoto, 2010; Schwab et al., 2017) and alternative modeling frameworks (Chen and Aihara, 2002, 2006; Klemm and Bornholdt, 2002, 2005; Lyapunov, 2007; Chaves et al., 2008).
However, there are few studies that compare the robustness of real networks to those of random networks with similar structural properties. Indeed, random networks can be artificially selected for robustness, affecting their structural properties (Sevim and Rikvold, 2008; Fretter et al., 2009). We are aware of only a single work that directly compares real networks to topologically similar random ones. Specifically, Daniels et al. (2018) compared 67 biological models with topologically and functionally similar random models, identifying a node-based sensitivity measure that differs between the two types of models.
Here, for the first time, we compare real and similar random models in terms of their dynamical properties. Since the space of model states is exponentially large, mapping its attractors and basins of attraction is very costly. To tackle this computational problem, we design novel integer linear programming (ILP) formulations for model learning and attractor computations. We apply our methodology to a set of 30 curated models covering fundamental biological processes in multiple species with up to 62 nodes. We analyze their steady-state (attractor) properties and their robustness to small perturbations. As a benchmark, we use randomized models that maintain the topology and logical complexity of the real models. We find that real models tend to be more robust than random models in several aspects that concern the steady-state changes in response to intrinsic noise in the system or due to small perturbations to its logic.
2. Preliminaries
For a cell circuit of interest, a Boolean model is a pair
An assignment of binary activity levels to each node defines a state of the model. We assume a synchronous model, where for each discrete time point t and vertex vi,
An attractor for G is a simple cycle of network states. Formally, a state path A of length T is a tuple
3. Methods
To test the robustness of a given model, we examine the impact of small perturbations on its dynamics. Specifically, we consider two types of perturbations: (i) changing k bits in the truth tables of one or more of its functions, where k is a small constant; (ii) switching from any state to another state whose Hamming distance to the original is at most k. We study the impact of such changes on the set of model attractors by quantifying for each change the percent of model states, leading to a different attractor in the perturbed model/state.
Since the space of model states is exponentially large, mapping its attractors and basins of attraction is very costly. To tackle this computational problem, we combine novel ILP formulations for model learning and attractor computations with stochastic simulations for estimating the size of each basin of attraction. To describe our formulation for attractor representation, we first describe a set of subprograms that form its building blocks.
3.1. State comparisons
The representation of attractor states requires efficient means to compare them to one another to make sure that they represent a cyclic path of distinct states and that no two attractors share the same state. One way to tackle this problem as well as remove degrees of freedom from solutions is to assign a unique numeric key to each possible network state. The resulting order can then be used to implement equality and inequality constraints.
A natural key for a state is the binary number it represents, but the representation size may exceed the number of bits in a computer word. Instead, we implement this representation by assuming an arbitrary upper bound of M bits per word and splitting the number into
It holds that
This implies that
We can use these indicators to implement a set membership indicator
3.2. Path constraints
Let
For an input node vi such that
We call this subprogram
3.3. Attractor learning
We are now ready to present our formulations for attractor learning under various constraints. Using fixed values for the outputs of F, we can use such formulations to compute the attractors of a given model. By substituting the outputs of F with binary variables, we get a formulation whose solution represents a possible model on G and its attractors. For brevity, in the following formulations whenever we write an indicator as a constraint, we require its value to be 1. All formulations depend on specifying in advance the upper bounds on the number and length of the model's attractors. For clarity, we assume at first that there are exactly K attractors of length T each. We apply the conditional constraint mechanism below to generalize the formulations to the case that K and T are upper bounds.
Let
where degrees of freedom in attractor representation are eliminated by forcing the final state of each attractor to be the largest in terms of its associated numeric value, and the final states of different attractors to be ordered as well.
To generalize the program from
where
3.4. Robustness to state perturbations
To quantify robustness, we first consider the sensitivity of a model to small perturbations to its current state, similar to Fretter et al. (2009); Sevim and Rikvold (2008); and Ghanbarnejad and Klemm (2012). As attractors represent the steady states or behaviors of the system under study, it is natural to consider the ability of a perturbation to alter the system's behavior. Such perturbations could occur due to the inherent noise in the biological system.
Let
We evaluate the robustness of a model by a weighted average of its sensitive attractors, where attractors are weighted by their basin size estimate and the result is averaged over multiple choices of S, constrained to have cardinality k. The procedure is as follows:
As an alternative sensitivity measure, we use an ILP formulation to compute an upper bound rather than an average on sensitivity. That is, we find the maximal weighted average of attractors that are sensitive to a set S of a given cardinality. Denote the relative basin size of attractor
3.5. Robustness to logic perturbations
An orthogonal way to measure the robustness of a model is by the effects of perturbing its logical functions on the model's attractors (Li et al., 2004; Sevim and Rikvold, 2008). As before, we assume that up to k bits are changed in the truth tables of the Boolean functions.
Let
To estimate the average rather than maximum sensitivity to changes, we use a stochastic procedure similar to the above.
4. Results
4.1. Data retrieval and implementation details
We downloaded 76 Boolean models from the CellCollective repository (Helikar et al., 2012), using the truth tables' export features. We excluded three models with missing information or could not be parsed and three models with acyclic graphs (hence, no dynamic behavior).
For each model, we applied four scoring variants quantifying the sensitivity of the model to state changes (stochastic and ILP-based variants) and attractor elimination due to function changes (stochastic and ILP-based variants). We used 1000 iterations to estimate each model's attractors and their basin sizes. For stochastic measures, we used 200 iterations per model. For optimization variants, we set the bound on the path length to an attractor to be
We benchmarked the sensitivity of the different models against randomized models in which both topology and logic functions are randomized. Specifically, the topology was randomized while preserving in- and out-degrees using the switching method with
We split the processing jobs among five servers. Two with 72 CPUs (2300 MHz) and 258 GB RAM, and the remaining three with 40 CPUs (2800 MHz) and 258 GB RAM. When running the stochastic algorithms, we ran iterations in parallel, and let the ILP solver (Gurobi) utilize all cores. Table 1 provides running time statistics. Running times varied considerably between models, and thus, we set a time-out of 90 minutes (in addition to ILP problem setup time) for running the different scoring methods on each model and discarded the results for models on which the computation was not completed within the given time bound. Overall, we collected results for 30 of the 70 models. The source code used for the analysis can be found at github.com/arielbro/attractor_learning, commit hash cd0874b6103f142ae3bb828e565e6162e7ff2f0e
Running Times in Seconds of the Different Scoring Variants
ILP, integer linear programming.
4.2. Real models are more robust than their randomized counterparts
We applied our robustness computation pipeline to the 30 models described above and compared the results with those obtained on randomized models. When applying the ILP-based sensitivity analysis of model changes, we observed that in almost all cases (for both real and random models) a single bit change was enough to eliminate the entire attractor space of a model. Thus, we computed an alternative score where the change is constrained to a specific node at a time, producing a sensitivity score for each of the model's nodes, and modified the stochastic version similarly.
The distributions of the four score variants on real and random models are given in Figure 1. Evidently, real models have lower sensitivity scores than random models across all score variants. To quantify the deviation of the real models from the corresponding distributions of random scores, we used a Wilcoxon signed-rank test, where the score of each real model was paired with the mean score of its random counterparts. For the node-based model perturbation scores, we paired the mean score of vertices in a real model with the mean scores of nodes in its random counterparts.
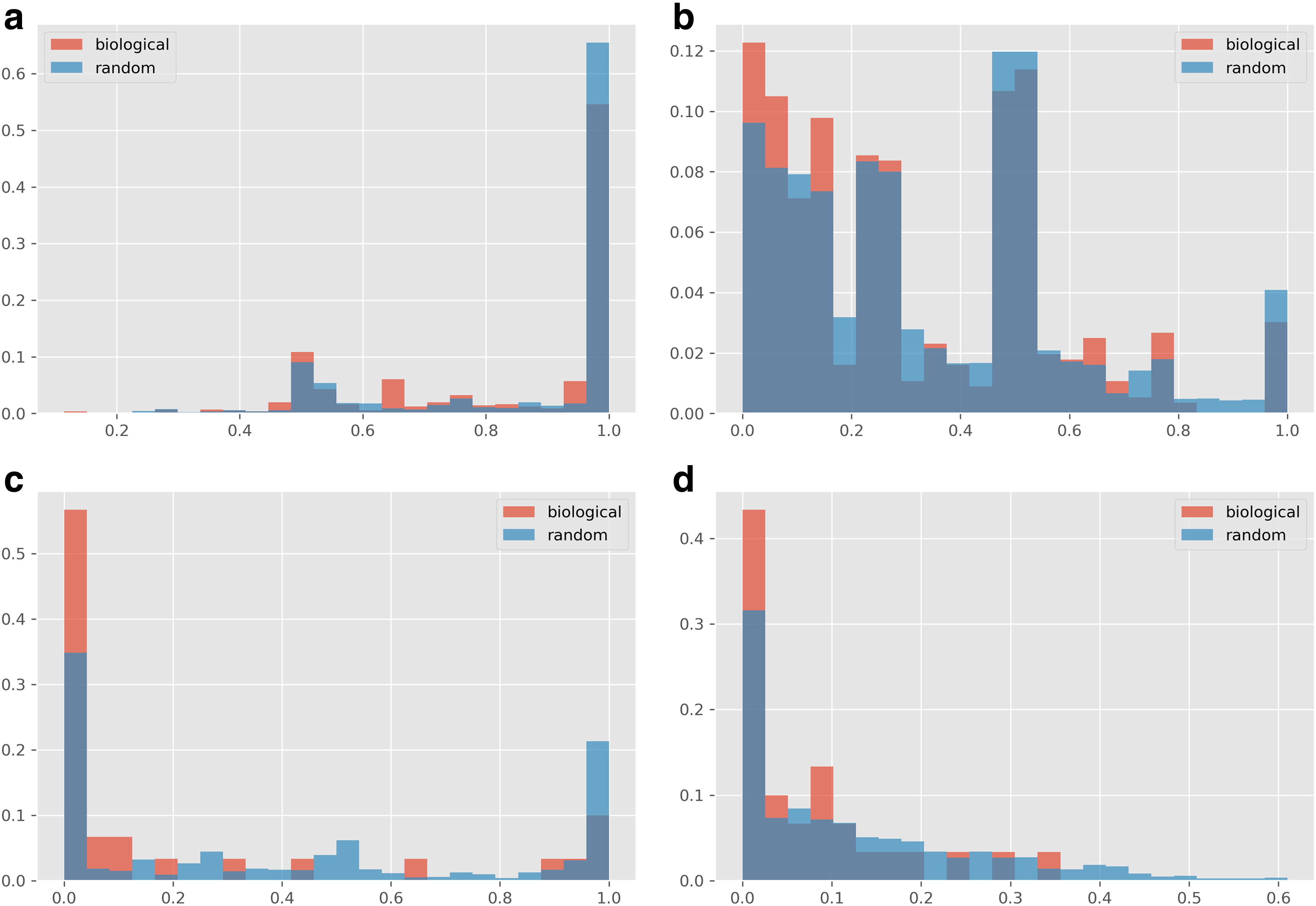
Distribution of model scores for each score variant, comparing real and random models.
The comparison results are summarized in Table 2, revealing that in all cases the real models are more robust to changes than their randomized instances. These differences were significant for all score types (

Box plots showing the distribution of sensitivity scores for each base network. Whiskers denote furthest data point within 1.5 IQR from median. Red dots denote the real models, and for per-node scores, the mean of real model node scores.
Comparison of Mean Sensitivity Scores for Real and Random Models
4.3. Stochastic versus optimization-based sensitivity analysis
It is interesting to compare the stochastic scores that measure the mean sensitivity to a change versus the ILP-based optimization scores that measure the extremes. As an example, The majority of models had an optimization score of 1 for attractor elimination, but less than
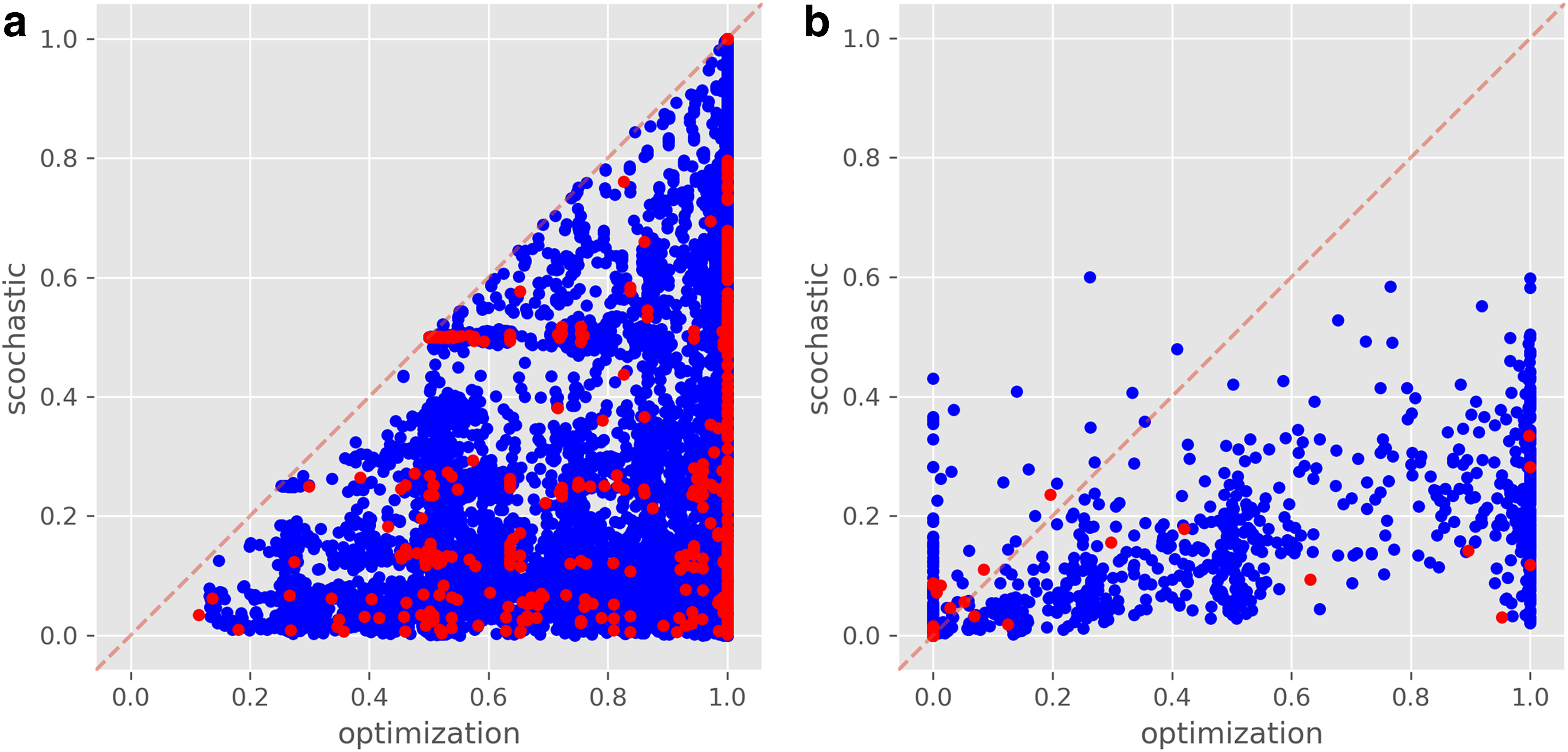
Scatter plots comparing ILP-based and stochastic-based scores across all models. Real models appear in red and randomized models in blue.
5. Conclusions
We have presented a first analysis of the attractor landscape of Boolean models of cellular circuits and its sensitivity to state and logic changes. Our analysis combined novel ILP formulations with stochastic simulations to overcome the inherent complexity of the problem. We found that real models are more robust than their randomized counterparts with respect to both state and logic changes. The significant difference between real and random models, across the four measures, supports the motivating assumption that the abstract notion of robustness is captured in the dynamics of Boolean models.
While the analysis could be successfully applied to dozens of circuits with up to 62 nodes each, the optimization problem remains challenging for larger circuits, especially when allowing longer paths from a state to its associated attractor. Another interesting problem is the generalization of the methods presented to asynchronous update schemes. Finally, further research is required to gain insight into the mechanisms behind the increased robustness of real models.
Footnotes
Author Disclosure Statement
The authors declare they have no conflicting financial interests.
Funding Information
R.S. was supported by a research grant from the Israel Science Foundation (no. 715/18). A.B. was support by the Deutsch Research Fund.