
Abstract
The increasing availability of complex data in biology and medicine has promoted the use of machine learning in classification tasks to address important problems in translational and fundamental science. Two important obstacles, however, may limit the unraveling of the full potential of machine learning in these fields: the lack of generalization of the resulting models and the limited number of labeled data sets in some applications. To address these important problems, we developed an unsupervised ensemble algorithm called strategy for unsupervised multiple method aggregation (SUMMA). By virtue of being an ensemble method, SUMMA is more robust to generalization than the predictions it combines. By virtue of being unsupervised, SUMMA does not require labeled data. SUMMA receives as input predictions from a diversity of models and estimates their classification performance even when labeled data are unavailable. It then uses these performance estimates to combine these different predictions into an ensemble model. SUMMA can be applied to a variety of binary classification problems in bioinformatics including but not limited to gene network inference, cancer diagnostics, drug response prediction, somatic mutation, and differential expression calling. In this application note, we introduce the R/PY-SUMMA packages, available in R or Python, that implement the SUMMA algorithm.
1. Introduction
Machine learning models have been extensively used to tackle a wide range of biomedical applications such as disease diagnosis, drug synergy prediction, and predicting gene–gene interactions, to name a few. Although several successful machine learning models are included in products already in use in the clinic, such as Mammaprint (Slodkowska and Ross, 2009), many models still do not generalize well beyond the data sets from which they were created. One common cause leading to poor generalization of machine learning models is overfitting, which occurs when a model is developed with superior accuracy on its training data at the cost of reduced performance of the model to new data sets. Differences in the statistical properties of training and test sets can also lead to poor model generalization. This might stem from systematic differences in experimental technologies or batch effects used in the collection of training data versus testing data. Ensemble models have shown great promise in dealing with the poor generalization problem. One revealing example is the DREAM5 network inference challenge, where it was shown that no individual model is the best under all tasks presented to challenge participants (Marbach et al., 2012). The authors showed that a simple ensemble model was obtained by averaging the predicted ranks submitted by challenge participants. This simple ensemble strategy has been called the wisdom of the crowds (WOCs), and proved effective in many other DREAM challenges.
The WOC strategy is not an optimal ensemble strategy. In the DREAM5 network inference challenge (Marbach et al., 2012), the authors compared the WOC method with a weighted rank average method where the weights were given by the performance of each method, and showed that the weighted average gives superior results. However, performance-weighted averages are not necessarily useful when inferring an unknown regulatory network, because the performance of the inference methods in the new context is not known.
It follows that the use of prior performance as weights in ensembles for new tasks may be either impossible when no training set was available, or inappropriate when the training and test sets have important differences. To overcome these issues, we recently developed the strategy for unsupervised multiple method aggregation (SUMMA) algorithm that uses a matrix of ranked predictions from multiple algorithms to infer the area under the receiver operating characteristic (AUROC) of individual binary classifiers even in the absence of gold standard labels. The inferred AUROCs are then used as weights for aggregating predictions as prescribed by some criteria of optimality (Ahsen et al., 2018). SUMMA can be applied to a variety of binary classification problems in bioinformatics, including gene network inference, cancer diagnostics, drug response prediction, somatic mutation, and differential expression calling. Here we present the R/PY-SUMMA package: a fast, open source, and user friendly implementation of the SUMMA algorithm.
2. Results
Many biomedical problems can be posed as binary classification tasks. In these problems a classifier takes data from a sample as input and produces a score representative of the class that sample is likely to belong to. For example, in network inference, quantities such as mutual information or correlation are used to predict the strength of an edge connecting two genes (Margolin et al., 2006).
The SUMMA algorithm takes as input an (
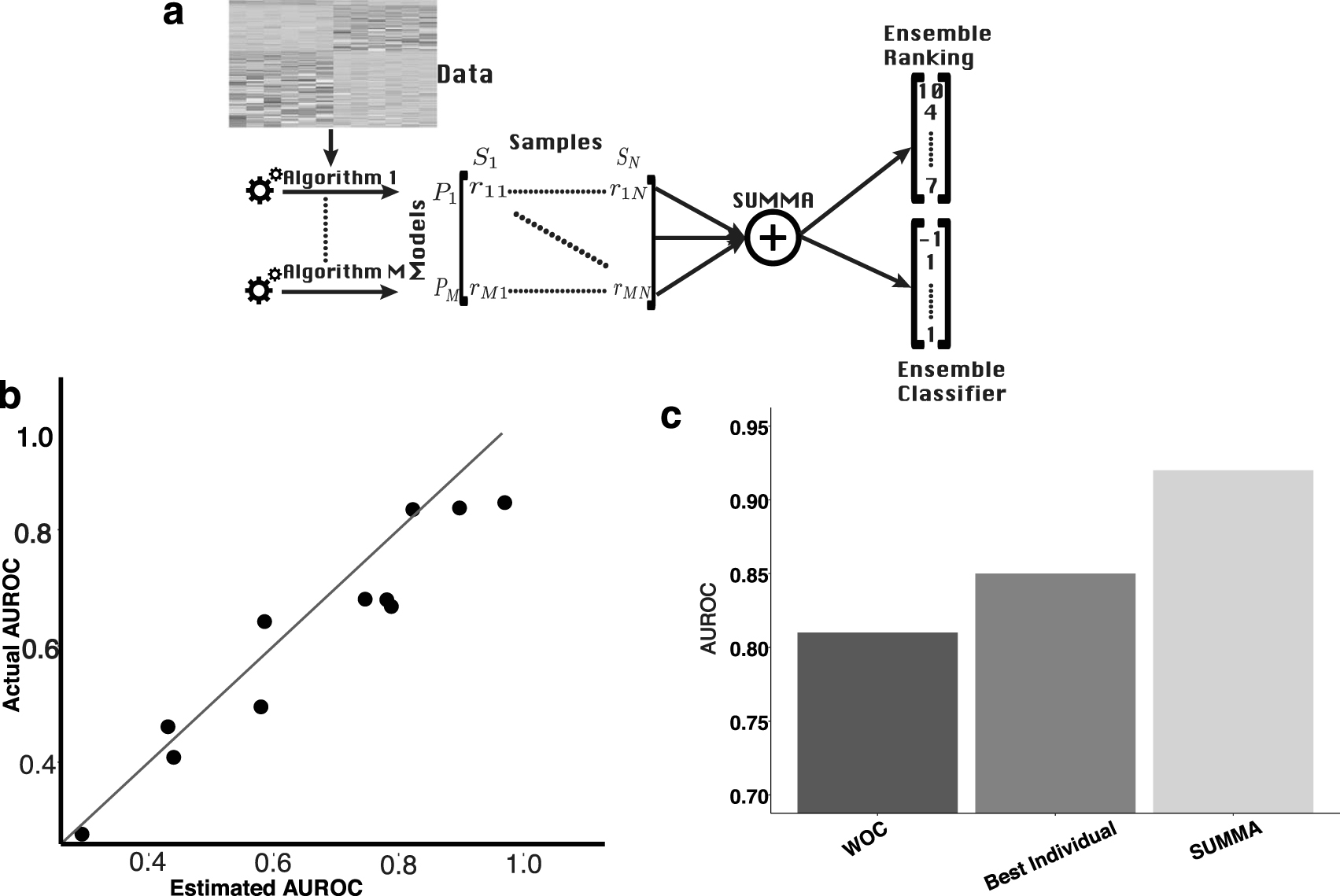
The SUMMA package implements the SUMMA algorithm (which is invoked using a single function), the WOC ensemble, simulation tools to create synthetic predictions, and comparative analysis tools. The comparative analysis tools are used for benchmarking the individual models against the ensemble model when a data set with class labels is available. It computes the AUROC of the individual methods, SUMMA, and WOC algorithms and displays them in an intuitive and publication quality figure. Although the comparative analysis relies upon labeled data, we emphasize that no such labels are required for executing the SUMMA pipeline.
2.1. BCL6 target prediction DREAM challenge
In the BCL6 transcriptional target prediction challenge (Stolovitzky et al., 2009), 11 teams were asked to use microarray data to produce a score for each one of 200 genes representative of the likelihood that that gene is a transcriptional target of BCL6. Hidden from the participants were gold standard labels for 200 genes collected from validation experiments. To apply SUMMA, we use the prediction scores provided by each team to make an (200, 11) rank prediction matrix.
We first analyzed how well SUMMA inferred the AUROC of each individual model. Figure 1b shows that SUMMA infers the AUROC of individual classifiers accurately (the correlation between actual and estimated correlation is 0.96). Figure 1c shows that the SUMMA ensemble (AUROC 0.92) outperforms all individual classifiers (best AUROC = 0.85) and the WOC ensemble (AUROC = 0.81). Next we analyzed the performance of all the methods in inferring class labels. In the binary classification task, SUMMA has a balanced accuracy (BA), defined as the average of the true positive and negative rates, of 0.82, whereas the best individual method, second best, and WOC ensemble exhibited BA values of 0.79, 0.66, and 0.52, respectively.
3. Conclusion
We introduce the SUMMA package that, given the vector of predictions of M base classifiers infers the AUROC of each classifier in the absence of labels, and aggregates these predictions into an ensemble prediction. The R/PY-SUMMA package provides easy-to-use commands for applying the SUMMA algorithm to data and performing graphical comparative analysis. SUMMA does not require any user-defined tuning parameters and is available in both the R and Python programming languages.
Footnotes
Author Disclosure Statement
The authors declare they have no conflicting financial interests.
Funding Information
This work was funded by the institutions that the authors are affiliated with (MEA: University of Illinois at Urbana Champaign; RV and GAS: IBM Research).