
Abstract
The classical methods for the classification problem include hypothesis test with the Benjamini–Hochberg method, hidden Markov chain model, and support vector machine. One major application of the classification problem is gene expression analysis, for example, detecting the host genes having interaction with pathogen. The classical methods can be applied and have a good performance when the number of genes having interaction with the pathogen is not sparse with respect to the candidate genes. However, conditional random field (CRF), with an appropriate design, can be applied and have good performance even when it is sparse. In this work, we proposed a modified CRF with a baseline to reduce the number of parameters in CRF. Moreover, we show an application of CRF with the least absolute shrinkage and selection operator (LASSO) to classifying barley genes of its reaction to the pathogen.
1. Introduction
The conditional random field (CRF) was introduced by Sutton and McCallum (2012). The major reason why CRF is flexible is that we can define the feature functions base on the complexity of the problems with respect to the data set. With an appropriate design, CRF can fit into several different scenarios such as text process (Ammar et al., 2014), bioinformatics (Thiagarajan and Bremananth, 2015), and image process (Lu et al., 2018). However, because of the flexibility, the CRF usually contains a large number of parameters. This causes computational difficulty during the training step. CRF contains its own penalty to prevent overfitting; the penalty proposed in Sutton and McCallum (2012) considers the Euclidean distance (l2-norm) of parameters. To enforce the sparsity of covariates in CRF, a stronger penalty (l1-norm) of the parameters in CRF, least absolute shrinkage and selection operator (LASSO) penalty is applied (Hayashida et al., 2013).
This study demonstrates the flexibility of CRF and propose an improved CRF model with a fewer number of parameters by setting a baseline. An improved CRF model with LASSO is proposed for the barley gene expression data, which are collected to classify different reactions of host genes to pathogens to improve the immunity of barley. Since the gene expression levels on different time points for one host gene may have strong interdependence on each other, the classical classification method may not have a well-fit. We demonstrate an application of CRF with proper model specification and LASSO penalty to the barley data.
This work is organized as follows. Section 2 provides the experiment details of gene data. Section 3 shows the technical details about how to design CRF for this barley data and how to improve CRF and implement the LASSO into CRF. Section 4 demonstrates the performance of CRF by comparing it with support vector machine (SVM; Meyer et al., 2019) and generalized linear model (GLM) with LASSO (Friedman et al., 2010). Finally, we apply the CRF to the barley data and draw the conclusion in Section 5.
2. The Barley–Pathogen Interaction Experiment
An experiment was conducted by Dr. Shaobin Zhong's group in the Department of Plant Pathology at North Dakota State University to determine what genes in the barley genome will be changed at expression level during infection by the fungus Bipolaris sorokiniana causing the spot blotch disease. The study aimed to identify barley genes involved in host resistance or susceptibility to the disease. The information will allow us to have a better understanding of the interaction between the pathogen and the host and may help us to design new approaches for better control of the disease.
In this study, there are two treatments: Barley cv. Bowman infected by the original isolate (ND90Pr), which is highly virulent on Bowman, and the barley infected by the mutated isolate with low virulence on Bowman. The mutant was generated by deleting an NPS gene conforming high virulence of the isolate. For each treatment, three leaf samples were collected at 0, 6, 12, 18, 24, 36, 48, and 72 hours after inoculation. Hence, a total of 48 samples, that is, 3 replicates in 2 treatments at 8 time points are used to generate the data set.
In this experiment, the expression level of 6325 genes of Barley cv. Bowman are studied (Trapnell et al., 2012), and each contains 8 records collected at the 8 time points, respectively. When the gene expression level is missing in some of the 8 hours records, it is assumed to have a very low expression level and numerically set to 0. To analyze the data, the ratio between two treatments gene expression levels, namely, relative gene expression level, is used. The relative gene expression level is
where
After computing the relative gene expression level, the next problem is the large range of the data (from
After finishing all the data process, the next step is for the classification problem to determine the behavior of observations in each group. We selected 200 observations and labeled it as follows:
Label 0 ( Label 1 ( Label 2 (
Finally, 171 of 200 genes were labeled as 0, 19 of 200 genes were labeled as 1, and 10 of 200 genes were labeled as −1.
Figure 1 shows that if the gene shows no significant different pattern between different environments, then the gene is labeled as 0.
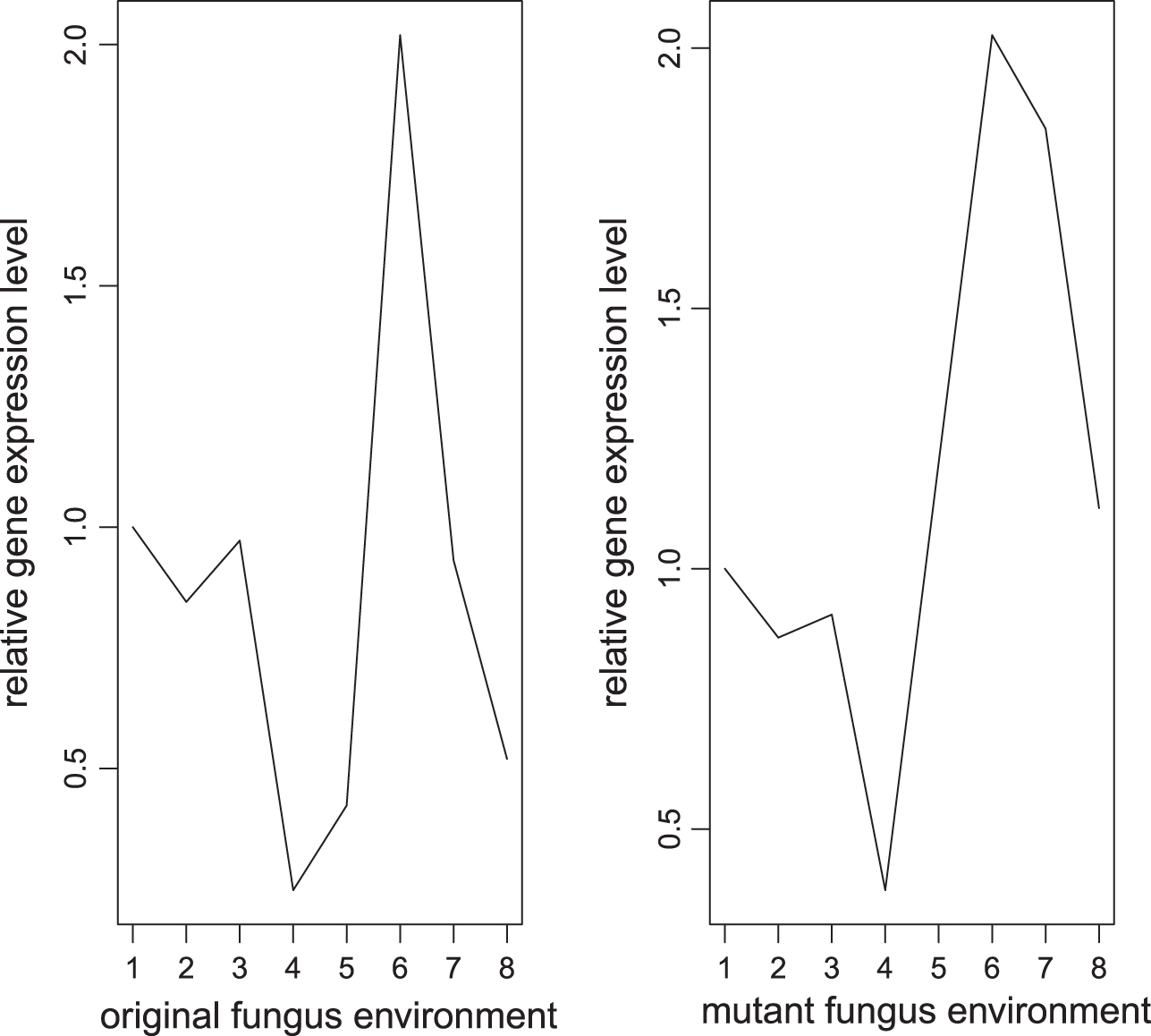
Example of relative gene expression level labeled as 0.
Figure 2 shows that if the gene shows activities in original isolate environment and shows no activities in mutant isolate environment, then the gene is labeled as 1.
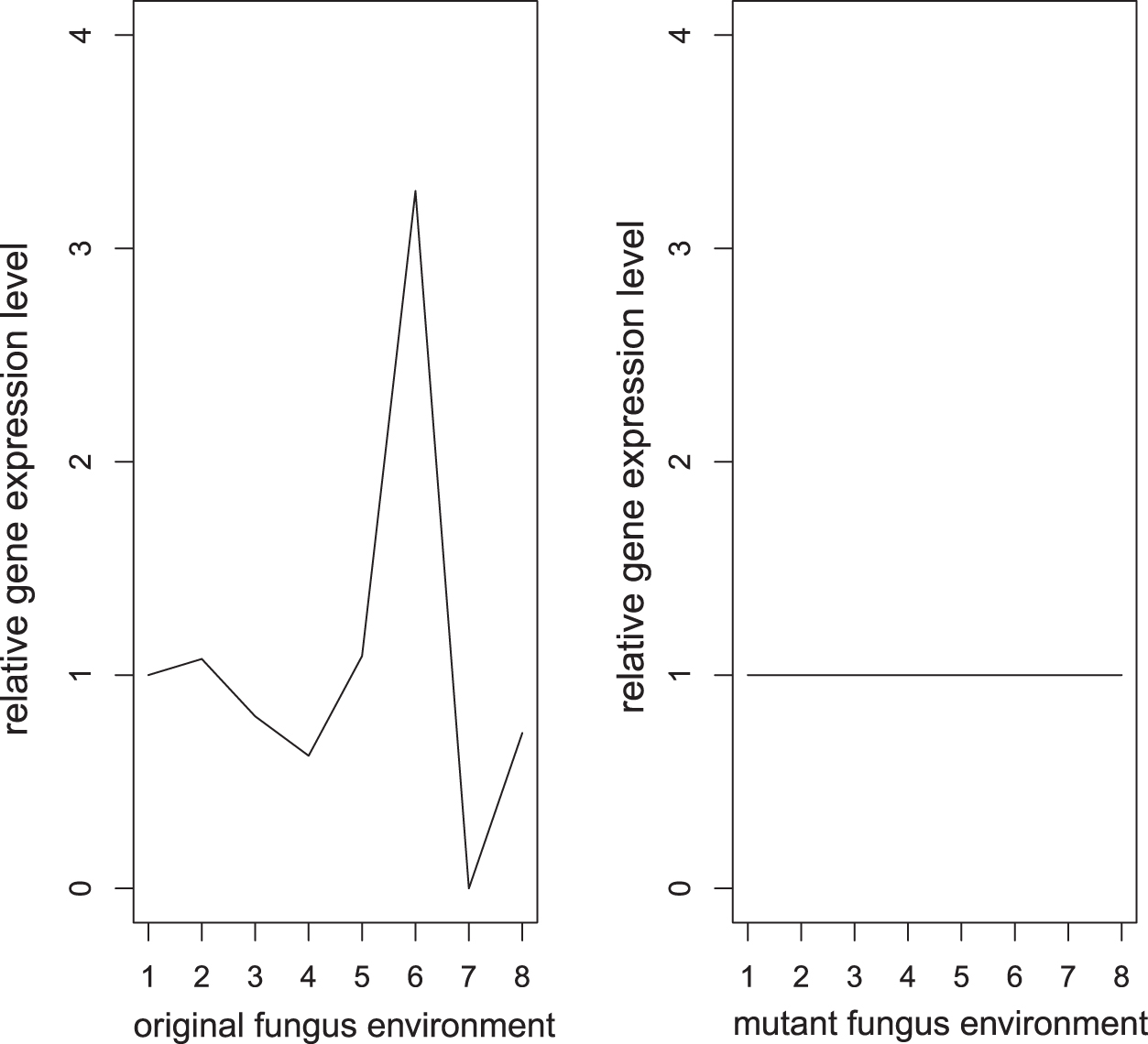
Example of relative gene expression level labeled as 1.
Figure 3 shows that if the gene shows activities in mutant isolate environment but shows no activities in original isolate environment, then the gene is labeled as 2.
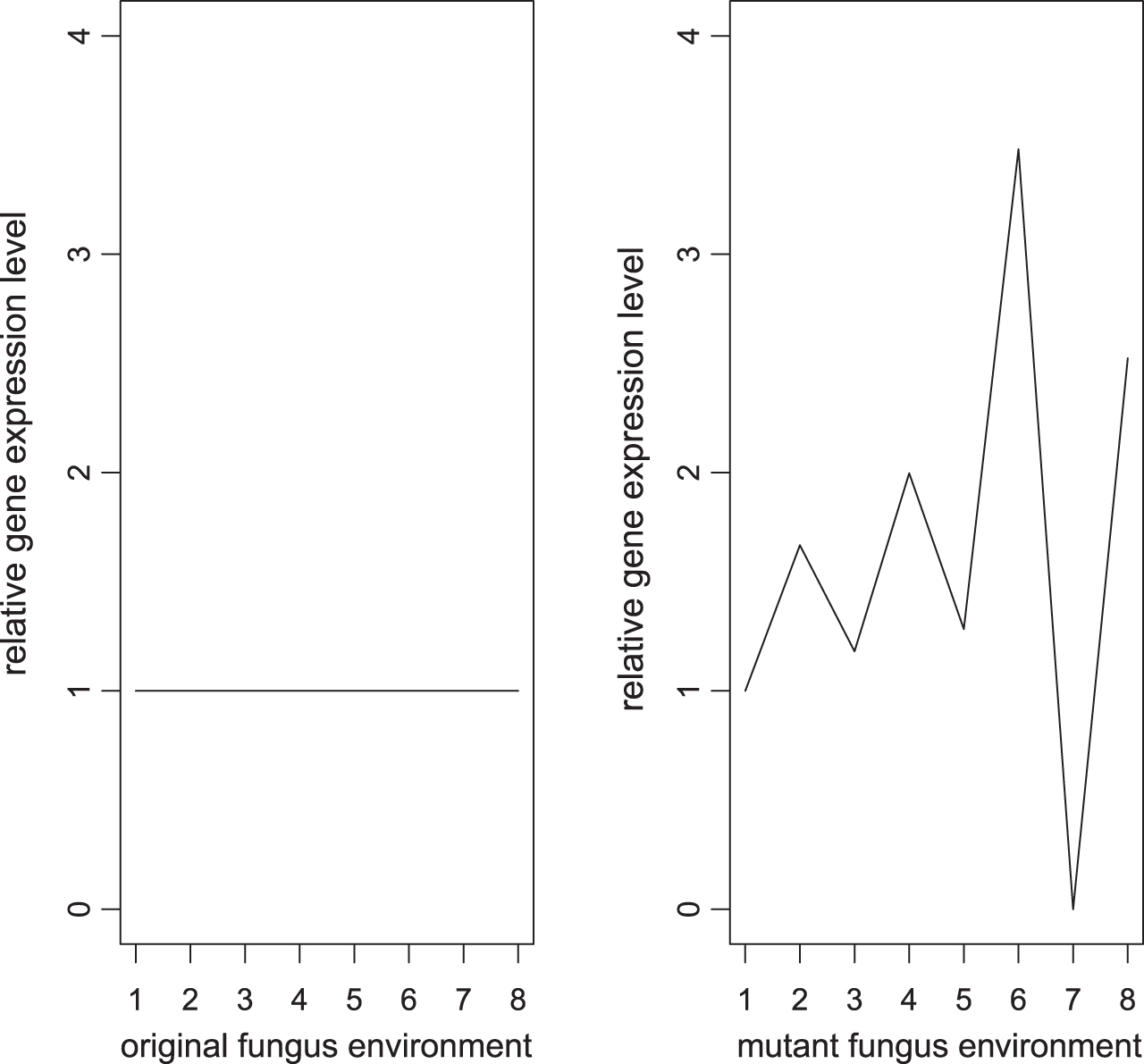
Example of relative gene expression level labeled as 2.
The training step of CRF used these 200 genes and their gene expression ratio (xi, which will be introduced in Section 3.1) as the training data to train the CRF model, and the training data ratio plot is shown in Figure 4.

The training data ratio plot.
3. Methodology
3.1. Conditional random field
As mentioned in Section 2, each gene expression level has eight records. To analysis the data set, CRF with a proper model specification of feature functions is applied. The CRF model is defined as
where
where
where
and l is the label that indicates the relation between the plant gene and the specific fungus gene where:
To simplify the notation for the 36 combinations of
The CRF model is changed to
with
is a 36-dimensional vector. The footnote
There are two steps to determine the label for each gene via
3.2. CRF training
The major problem in the first step is how to estimate the
where
is a 108-dimensional vector. As mentioned in Section 1, since the number of parameters for CRF is large, estimating the parameters via traditional computational methods is not practical. Hence, gradient descent is applied to maximize the log-likelihood function.
3.3. Gradient descent
Gradient descent is a first-order iterative algorithm to find the minimum of the objective function.
In this study, the objective function is
Furthermore, the first derivative of
where
with
Notice that when l only has two outcomes, that is,
Hence, the update rule for
Therefore, with the initial value for
after T iterations. Hence, in this scenario, the number of parameters that need to be estimated is not
3.4. Dimension reduction
After the first derivative of
where
Apply the equation for the feature function
To further reduce the number of the parameters, we set a baseline for the model. Similar to the J-1 baseline-category logits for nominal response (Kutner et al., 2005), we can set a baseline for the CRF. Let
where
Moreover, let
where
To do that, LASSO is applied (Hastie et al., 2015).
3.5. Least absolute shrinkage and selection operator
As mentioned above, LASSO can also reduce the dimensions of the parameters, that is, force
when
where
Notice that when
subject to
Since
However, there are mainly two difficulties when LASSO is applied. The first problem is, assuming the
Proximal gradient descent is a general case for the projected gradient method. The idea is: first, use traditional gradient descent to find the solution for

where
and
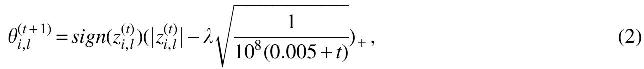
where
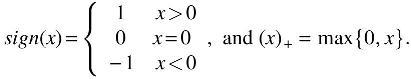
The next difficulty is the choice of
By applying both proximal gradient descent and PCD, the LASSO method is complete. Hence, CRF can now be applied. Up to this point, CRF with LASSO regulation can be computed. To test the accuracy of CRF, a numeric experiment is necessary. The numeric experiment will discuss the performance of CRF.
4. Numeric Experiment
The data set of the simulation is conducted in a scenario of 1000 observations with 100 features. The observations are labeled into three groups: 0, 1, and 2. The corresponding parameter of the first 5 features are set to have non-zero values, and the corresponding parameter of the rest 95 features are set to be zero.
4.1. Label 0
For the observation of label 0, we have
For the other dimensions of the observation, we have
where
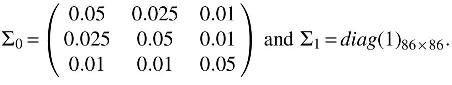
Letting the rest 95 dimensions independent of the first 5 dimensions will let the parameters of these dimensions equal to 0. Notes that, the mean of the first 5 dimensions is neither increasing nor decreasing; this is because the label 0 is simulating the no reaction for the gene expression.
4.2. Label 1
For the observation of label 1, we have
For the other dimensions of the observation, we have
Again, letting the rest of 95 dimensions independent of the first 5 dimensions will let the parameters of these dimensions equal to 0. Note that the mean of the first 5 dimensions is increasing; this is because the label 1 is simulating the positive impact for the gene expression.
4.3. Label 2
For the observation of label 2, we have
For the other dimensions of the observation, we have
where the covariance matrix
Note that the mean of the first 5 dimensions is decreasing, this is because the label 2 is simulating the negative impact for the gene expression.
4.4. Additional setting
For x9 in label 1,
Moreover, the numeric experiments contain three different scenarios, and each scenario is repeated 200 times. These scenarios are set as follows:
1. 20 of 1000 genes are changed by the fungus (20/1000)
980 of 1000 observations have 94.8% chance to be label 0. 10 of 1000 observations have 98.5% chance to be label 1. 10 of 1000 observations have 97.6% chance to be label 2.
2. 500 of 1000 genes are changed by the fungus (500/1000) 500 of 1000 observations have 94.8% chance to be label 0. 250 of 1000 observations have 98.5% chance to be label 1. 250 of 1000 observations have 97.6% chance to be label 2.
3. 980 of 1000 genes are changed by the fungus (980/1000) 20 of 1000 observations have 94.8% chance to be label 0. 490 of 1000 observations have 98.5% chance to be label 1. 490 of 1000 observations have 97.6% chance to be label 2.
In Figure 5, the black line is the mean of 100-dimensional features labeled as 0. This line is simulating the unchanged genes. The red line is the mean of 100-dimensional features labeled as 1, which is simulating the positively changed genes. The blue line is the mean of 100-dimensional features labeled as 2, which is simulating the negatively changed genes. As the plot shows, after the fifth dimension, the features tend to be alike. Therefore, the features after fifth dimension are useless. The CRF model results are generated under this simulation setting. To compare the result with some classical model, the SVM with linear kernel and the GLM with LASSO are used.

Simulation data.
4.5. Results
As mentioned in the Section 3.5, when
There are mainly two aspects to analyze the performance of CRF, the error rate of the CRF model, and the performance of LASSO in CRF.
4.6. Error rate of the model
There are three different error rates of the model, that is, the error rate to predict label 1
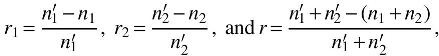
where
4.7. The performance of the LASSO in CRF
To demonstrate the performance of CRF, both SVM with linear kernel (Meyer et al., 2019) and the GLM with LASSO (Friedman et al., 2010) are used. In addition, for the GLM, the multinomial distribution is assumed (Simon et al., 2011; Tibshirani et al., 2012).
Table 1 is the error rate's mean and standard deviation for both CRF and SVM. Two conclusions can be drawn from this comparison. First, the error rate in SVM largely decreases when the ratio of changed gene increases from 20/1000 to 500/1000 (
Error Rates for Conditional Random Field and Support Vector Machine
CRF, conditional random field; GLM, generalized linear model; SD, standard deviation; SVM, support vector machine.
Table 1 also shows the error rate for CRF and GLM. From this table, we can see that CRF have a better performance only in scenario 20/1000; in the rest of the scenarios, both CRF and GLM shows a very similar performance.
In conclusion, both the SVM and GLM are suitable for the data in which there is a significant proportion of changed genes. CRF has a better performance when number of genes having interaction with the pathogen is sparse (i.e., the ratio of changed/total genes is small). In addition, when the change ratio increases, the
Since the simulation study assumes that the observation are separated into three groups, there are three parameters for each dimensions (
4.7.1. Scenario 20/1000
Table 2 is the 2.5% percentile and the 97.5% percentile for both CRF and GLM estimates under scenario 20 of 1000 genes should be labeled as changed.
Percentile for Conditional Random Field and Generalized Linear Model Estimates Under Scenario 20/1000
For estimates of label 0, as mentioned in Section 3, the CRF set label 0 as reference. Hence, for
For estimates of label 1, CRF estimates show that
For estimates of label 2, CRF estimates show that
For the rest of 95 dimensions, both CRF and GLM show insignificant results.
All in all, under the scenario 20/1000, CRF shows that first, fourth, and fifth dimensions should be considered to separate genes into three groups. However, GLM shows that the third dimension should be considered.
4.7.2. Scenario 500/1000
Table 3 is the 2.5% percentile and the 97.5% percentile for both CRF and GLM estimates under scenario 500 of 1000 genes should be labeled as changed. For estimates of label 0, similar to the previous results, the CRF set label 0 as reference. However, GLM estimates show that
Percentile for Conditional Random Field and Generalized Linear Model Estimates Under Scenario 500/1000
For estimates of label 1, CRF estimates show that
For estimates of label 2, CRF estimates show that
For the rest of 95 dimensions, both CRF and GLM show insignificant results. The results can be seen in Appendix Table A1.
All in all, under scenario 500/1000, CRF shows that first and fifth dimensions should be considered to separate genes into three groups. Similar to CRF, GLM shows that the first and fifth dimension should be considered.
4.7.3. Scenario 980/1000
Table 4 is the 2.5% percentile and the 97.5% percentile for both CRF and GLM estimates under scenario 980 of 1000 genes should be labels as changed.
Percentile for Conditional Random Field and Generalized Linear Model Estimates Under Scenario 980/1000
For estimates of label 0, GLM estimates show that
For estimates of label 1, CRF estimates show that
For estimates of label 2, CRF estimates show that
Similar to the previous two scenarios, both CRF and GLM estimates show that the rest of 95 dimensions are not significant.
All in all, for scenario 980/1000, CRF estimates show that first and fifth dimensions are significant. GLM estimates show that first and third dimensions are significant.
4.7.4. Summary
Considering all three scenarios for both CRF and GLM, for the first 5 dimensions, the estimates for CRF and GLM are very different under the first scenario. That is, there are 20 of 1000 genes should be considered as changed genes. As a result, CRF has a lower error rate. For the other two scenarios, both CRF and GLM show very similar results in both parameter estimation and error rate.
For the rest of 95 dimensions, both CRF and GLM estimates show no significance. Hence, the LASSO has a robust performance in both CRF and GLM.
5. Case Study: ND90PR and Barley CV. Bowman
As mentioned in Section 2, this experiment collects the gene expression level for barley under two treatments at nine time points. The experiment data contain 727,609 observations, and each observation contains the gene id, the time that the gene expression is collected, the gene expression value, which is greater than or equal to 0, and the p-value to determine if the gene expression is significant. We filter the data with p-value <0.05 and manipulate the original gene expression according to the method in Section 2. After the data processes, we have 6325 genes expression data, and each gene contains 36 records (
Trained Data Distribution
Footnotes
Acknowledgments
The author would like to thank Dr. Shaobing Zhong, Yueqiang Leng, and the rest of Plant Pathology Laboratory members for providing their valuable data set and advice.
Author Disclosure Statement
The authors declare they have no competing financial interests.
Funding Information
The authors received no funding for this article.