
Abstract
A classic problem in computational biology is the identification of altered subnetworks: subnetworks of an interaction network that contain genes/proteins that are differentially expressed, highly mutated, or otherwise aberrant compared with other genes/proteins. Numerous methods have been developed to solve this problem under various assumptions, but the statistical properties of these methods are often unknown. For example, some widely used methods are reported to output very large subnetworks that are difficult to interpret biologically. In this work, we formulate the identification of altered subnetworks as the problem of estimating the parameters of a class of probability distributions that we call the Altered Subset Distribution (ASD). We derive a connection between a popular method, jActiveModules, and the maximum likelihood estimator (MLE) of the ASD. We show that the MLE is statistically biased, explaining the large subnetworks output by jActiveModules. Based on these insights, we introduce NetMix, an algorithm that uses Gaussian mixture models to obtain less biased estimates of the parameters of the ASD. We demonstrate that NetMix outperforms existing methods in identifying altered subnetworks on both simulated and real data, including the identification of differentially expressed genes from both microarray and RNA-seq experiments and the identification of cancer driver genes in somatic mutation data.
1. Introduction
A standard paradigm in computational biology is to use interaction networks as prior knowledge in the analysis of high-throughput omics data, with numerous applications, including: protein function prediction (Deng et al., 2003; Nabieva et al., 2005; Chua et al., 2006; Sharan et al., 2007; Radivojac et al., 2013), gene expression analysis (Ideker et al., 2002; Dittrich et al., 2008; de la Fuente, 2010; Cho et al., 2012; Xia et al., 2015), germline variants (Lee et al., 2011; Califano et al., 2012; Leiserson et al., 2013; Hormozdiari et al., 2015; Huang et al., 2018), somatic variants in cancer (Nibbe et al., 2010; Vandin et al., 2011; Hofree et al., 2013; Creixell et al., 2015; Leiserson et al., 2015; Shrestha et al., 2017), and other analysis of other data (modENCODE Consortium et al., 2010; Wang et al., 2011; Berger et al., 2013; Halldórsson and Sharan, 2013; Gligorijević and Pržulj, 2015; Chasman et al., 2016; Cowen et al., 2017; Luo et al., 2017).
One classic approach is to identify active, or altered, subnetworks of an interaction network that contain unusually high or low measurements. The altered subnetwork problem takes as input: (1) an interaction network whose vertices are biological entities (e.g., genes or proteins) and whose edges represent biological interactions (e.g., physical or genetic interactions, co-expression, etc.); and (2) a measurement or score for each vertex. The goal is to find high-scoring subnetworks that correspond to groups of similarly altered vertices. This problem was introduced in Ideker et al. (2002) for gene expression analysis, where gene scores were derived from p-values of differential expression. Ideker et al. (2002) developed the jActiveModules algorithm to solve this problem and identify altered subnetworks of differentially expressed genes. Subsequently, Dittrich et al. (2008) introduced heinz as “the first approach that really tackles and solves the original problem raised by Ideker et al. (2002) to optimality.” jActiveModules and heinz have since become widely used tools with diverse applications; a few recent examples include mass-spectrometry proteomics (Kim and Hwang, 2016; Liu et al., 2018), damaging de novo mutations in schizophrenia and other neurological disorders (Gulsuner et al., 2013; Choi et al., 2016), and single-cell RNA-seq (Soul et al., 2015; Guo et al., 2016; Klimm et al., 2019).
In the past two decades, many algorithms have been developed to identify altered subnetworks in biological data (reviewed in Mitra et al., 2013; Creixell et al., 2015; Dimitrakopoulos and Beerenwinkel, 2017; Cowen et al., 2017). Each publication describing a new algorithm demonstrates the performance of their algorithm on specific biological datasets, and many of these publications also benchmark their algorithm against existing algorithms on real and/or simulated data. However, few of these publications prove theoretical guarantees for their algorithm’s performance on a well-defined generative model of the data. Thus, the true performance of these algorithms is often unknown. Indeed, recent benchmarking studies (Batra et al., 2017; He et al., 2017) of several widely used network algorithms—including jActiveModules and heinz—show considerate disagreement between subnetworks identified by different methods on the same biological datasets. Moreover, these benchmarking studies (and many others) do not compare network algorithms against single-gene tests that do not use the network; thus, the tacit assumption that interaction networks necessarily improve gene prioritization is often not tested.
Separately, many publications in the statistics and machine-learning literature investigate the problem of detecting whether or not a network contains an anomalous subnetwork, or a network anomaly (Arias-Castro et al., 2006, 2008, 2018; Addario-Berry et al., 2010; Arias-Castro et al., 2011; Sharpnack and Singh, 2013; Sharpnack et al., 2013a, 2016). These papers describe specific generative models of network anomalies and use a rigorous hypothesis-testing framework to prove asymptotic results regarding the conditions under which it is possible to detect a network anomaly. Importantly, these papers also provide theoretical guarantees about conditions under which a network contributes to anomaly detection. However, the network anomaly literature does not address the specific altered subnetwork problem studied in computational biology, with three key differences. First, the detection problem of deciding whether or not an altered subnetwork exists is not the same as the estimation problem of identifying the vertices in an altered subnetwork. Second, biological networks have a finite size, and it is unclear what guarantees the asymptotic results provide for finite-size networks. Finally, the topological constraints on network anomalies are often different from those considered in computational biology.
In this article, we aim at bridging the gap between the theoretical guarantees in the network anomaly literature and the practical problem of identifying altered subnetworks in biological data. We provide a rigorous formulation of the Altered Subnetwork Problem, the problem that jActiveModules (Ideker et al., 2002), heinz (Dittrich et al., 2008), and other methods aim at solving. Our formulation of the Altered Subnetwork Problem is inspired by the generative model used in the network anomaly literature, but it requires that the altered subnetwork is a connected subnetwork, a constraint motivated by the topology of signaling pathways (Bhalla and Iyengar, 1999); Kelley et al., 2004) and by the seminal works of Ideker et al. (2002) and Dittrich et al. (2008).
We show that the Altered Subnetwork Problem is equivalent to estimating the parameters of a distribution, which we define as the Altered Subset Distribution (ASD). We prove that the jActiveModules problem (Ideker et al., 2002) is equivalent to finding a maximum likelihood estimator (MLE) of the parameters of the ASD for connected subgraphs. At the same time, we demonstrate that if (1) the size of the altered subnetwork is moderately small and (2) the scores of vertices inside and outside of the altered subnetwork are not well separated, then the MLE is a biased estimator of the size of the altered subnetwork. This statistical bias provides a rigorous explanation for the large subnetworks produced by jActiveModules (Nikolayeva et al., 2018). We also show that the size of the altered subnetworks identified by heinz (Dittrich et al., 2008) is biased for most choices of its user-defined parameters.
We introduce a new algorithm, NetMix, that combines a Gaussian mixture model (GMM) and a combinatorial optimization algorithm to identify altered subnetworks. We show that NetMix is a reduced-bias estimator of the size of the altered subnetwork. We demonstrate that NetMix outperforms other methods for identifying altered subnetworks on simulated data, gene expression data, and somatic mutation data.
2. Altered Subnetworks, Altered Subsets, and Maximum Likelihood Estimation
2.1. Altered subnetwork problem
Let

Altered Subnetwork Problem. Measurements, or scores,
Altered Subnetwork Problem (ASP)
Let  and let
and let

where
Note that the Altered Subnetwork Problem (ASP) assumes that the interaction network
The seminal algorithm for solving the ASP is jActiveModules (Ideker et al., 2002). jActiveModules takes as input a
The presentation of jActiveModules in Ideker et al. (2002) does not specify the altered distribution
Normally Distributed Altered Subnetwork Problem
Let  and let
and let
Given
The Normally Distributed ASP has a sound statistical interpretation: if the
More generally, the Normally Distributed Altered Subnetwork Problem is related to a larger class of network anomaly problems, which have been studied extensively in the machine-learning and statistics literature (Arias-Castro et al., 2006, 2008, 2011, 2018; Addario-Berry et al., 2010; Sharpnack and Singh, 2013; Sharpnack et al., 2013a, b; Sharpnack et al., 2016). To better understand the relationships between these problems and the algorithms developed to solve them, we will describe a generalization of the Altered Subnetwork Problem. We start by defining the following distribution, which generalizes the connected subnetworks in the Normally Distributed Altered Subnetwork Problem to any family of altered subsets.
Normally Distributed ASD
Let  be distributed according to the Normally Distributed
be distributed according to the Normally Distributed

Here,
More generally, the ASD can be defined for any background distribution
The distribution in the Altered Subnetwork Problem is the
ASD Estimation Problem
The ASD Estimation Problem is a general problem of estimating the parameters of a structured alternative distribution, sometimes known as a “structured normal means” problem in statistics (Sharpnack et al., 2013a). Different choices of S for the ASD Estimation Problem yield a number of interesting problems, some of which have been previously studied in the altered subnetwork literature.
2.2. Bias in maximum likelihood estimation of the ASD
One reasonable approach for solving the ASD Estimation Problem is to compute an MLE for the parameters of the ASD. We derive the MLE next and show that it has undesirable statistical properties. All proofs are in the Supplementary Data.
The maximization of
Despite this insight that jActiveModules computes the MLE, it has been observed that jActiveModules often identifies large subnetworks. Nikolayeva et al. (2018) note that the subnetworks identified by jActiveModules are large and “hard to interpret biologically.” They attribute the tendency of jActiveModules to identify large subnetworks to the fact that a graph typically has more large subnetworks than small ones. Although this observation about the relative numbers of subnetworks of different sizes is correct, we argue that this tendency of jActiveModules to identify large subnetworks is due to a more fundamental reason: The MLE
First, we recall the definitions of bias and consistency for an estimator
When it is clear from context, we omit the subscript
Let
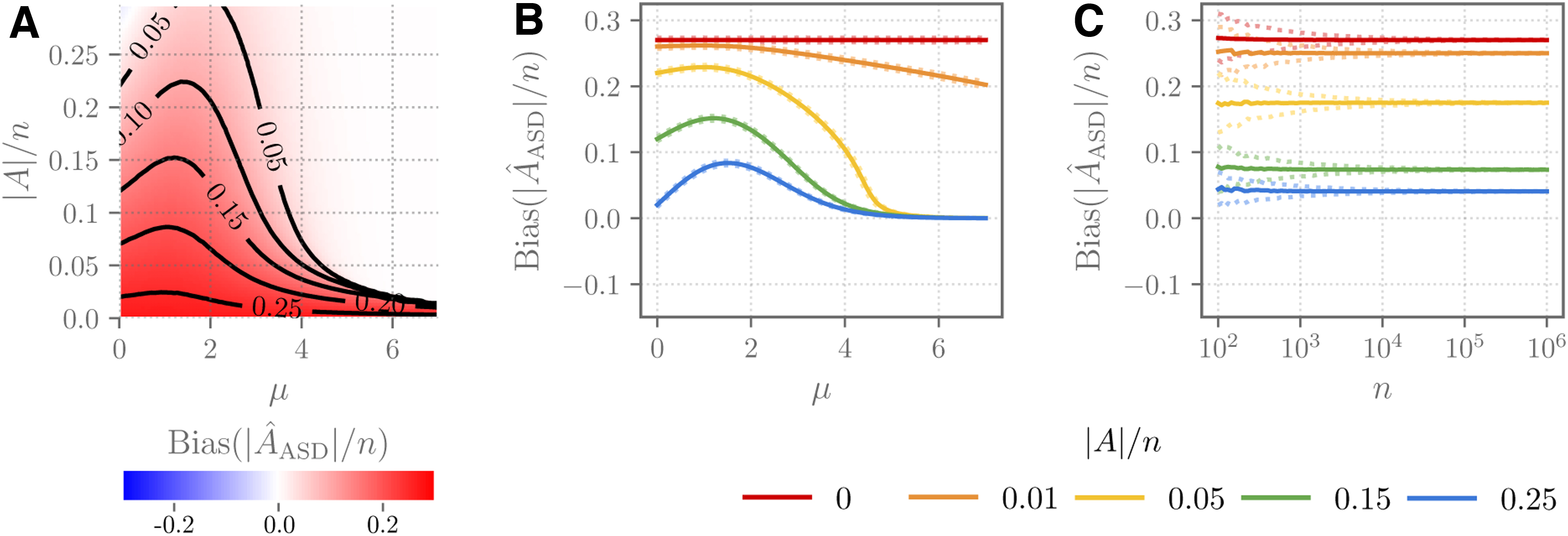
Scores
Note that there are many examples in the literature of biased MLEs; for example, the MLE for the variance of a (univariate) normal distribution or the MLE for the inverse of the mean of a Poisson distribution (Firth, 1993). However, examples of inconsistent MLEs are somewhat rare (Ferguson, 1982).
Although we do not have a proof of the earlier conjecture, we prove the following results that partially explain the bias and inconsistency of the estimators
Empirically, we observe
3. The Netmix Algorithm
Following the observation that the MLEs of the distribution
3.1. Gaussian mixture model
We start by recalling the definition of a GMM.
Gaussian Mixture Model
Let
An alternate interpretation of the GMM is to draw a latent variable
Given data
Analogously, by fitting a GMM to data

Scores
3.1.2. Conjecture
Let
Although we do not have a proof of the earlier conjecture, a partial justification is the following relationship between the unstructured ASD and the GMM distribution. Let
3.2. NetMix algorithm
We derive an algorithm, NetMix, that uses the MLEs
Given a graph
where
Next, NetMix aims at finding a connected subgraph
We formally describe the NetMix algorithm for solving the Altered Subnetwork Problem later.
NetMix bears some similarities to heinz (Dittrich et al., 2008), another algorithm to identify altered subnetworks. However, there are two important differences. First, heinz does not solve the Altered Subnetwork Problem defined in the previous section. Instead, heinz models the vertex scores (assumed to be
Second, heinz requires that the user specify a false discovery rate (FDR) and shifts the
Despite these limitations, the ILP given in heinz to solve the MWCS problem is very useful for implementing NetMix and for computing the scan statistic [Eq. (2)] used in jActiveModules (Section 4).
4. Results
We compared NetMix with jActiveModules (Ideker et al., 2002) and heinz (Dittrich et al., 2008) on simulated instances of the Altered Subnetwork Problem and on real datasets, including differential gene expression experiments from the Expression Atlas (Petryszak et al., 2015) and somatic mutations in cancer. jActiveModules is accessible only through Cytoscape (Shannon et al., 2003; Cline et al., 2007) and not a command-line interface, making it difficult to run on a large number of datasets. Thus, we implemented jActiveModules*, which computes the scan statistic [Eq. (5)] by adapting the integer linear program in heinz. † jActiveModules* output relies on the global optimum of the scan statistic, whereas jActiveModules relies on heuristics (simulated annealing and greedy search) to find a local optimum.
4.1. Simulated data
We compared NetMix, jActiveModules*, and heinz on simulated instances of the Altered Subnetwork Problem by using the HINT+HI interaction network (Leiserson et al., 2015), a combination of binary and co-complex interactions in High-quality INTeractones (HINT) (Das and Yu, 2012) with high-throughput derived interactions from the Human Interactone (HI) network (Rolland et al., 2014) as the graph
We found that NetMix output subnetworks whose size
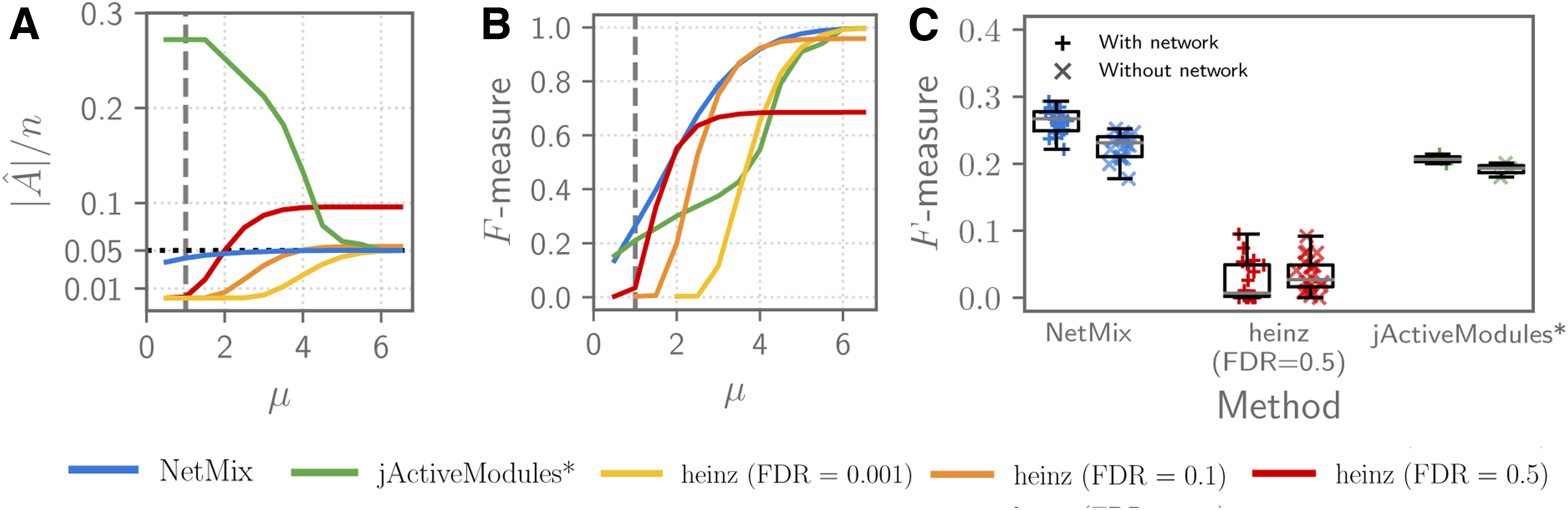
Comparison of altered subnetwork identification methods on simulated instances of the Altered Subnetwork Problem using the HINT+HI interaction network with
We also quantified the overlap between the true altered subnetwork
The bias in
4.2. Differential gene expression subnetworks
We compared NetMix, jActiveModules*, and heinz on gene expression data from the Expression Atlas (Petryszak et al., 2015). We analyzed
As many experiments had a small null proportion (i.e., most genes in the experiment were differentially expressed), we restricted our analysis to the
Both NetMix and heinz identified subnetworks that were significantly smaller than jActiveModules* (Fig. 5A), which is consistent with previous observations (Nikolayeva et al., 2018) that jActiveModules estimates overly large subnetworks. At the same time, NetMix identified subnetworks with significant overlap (
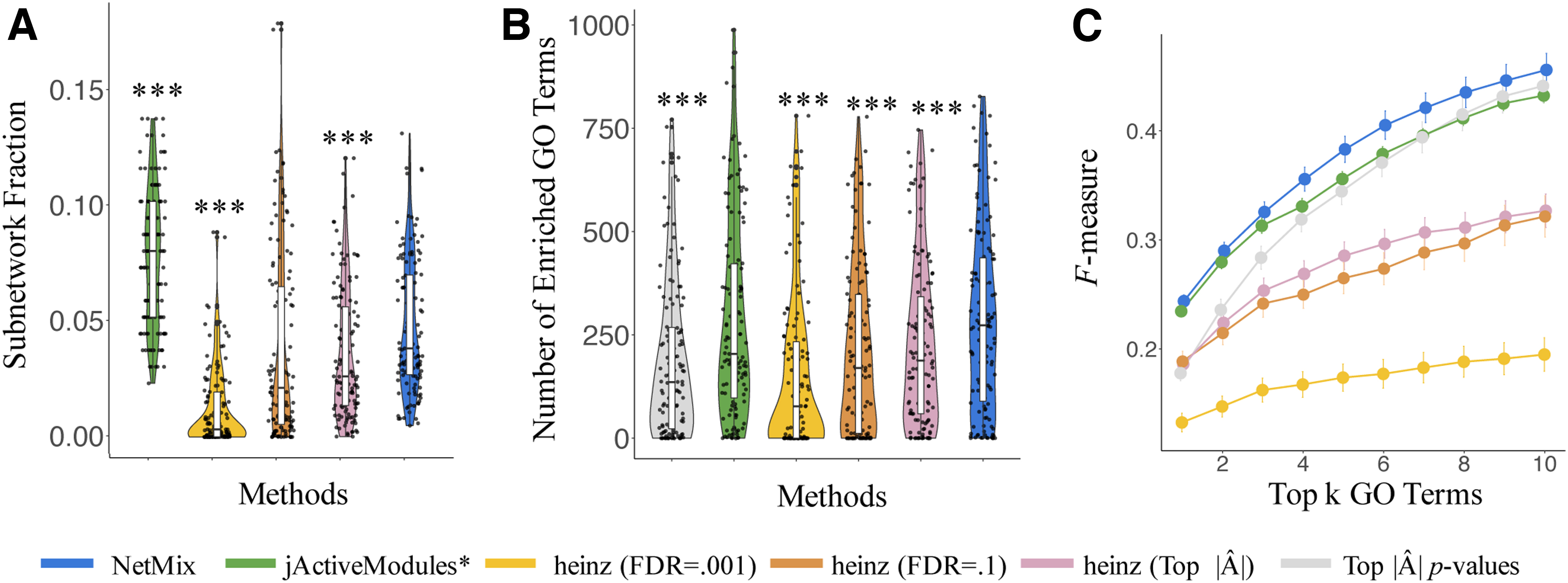
We examined the experiment E-GEOD-11199 in more detail. This experiment compared Mtb-stimulated and unstimulated macrophages (Thuong et al., 2008). NetMix identified a subnetwork containing
4.3. Somatic mutations in cancer
We compared the performance of NetMix, jActiveModules* (Arias-Castro et al., 2008; Addario-Berry et al., 2010), jActiveModules (Ideker et al., 2002), heinz (Dittrich et al., 2008), and Hierarchical HotNet (Reyna et al., 2018) in identifying cancer driver genes, using the MutSig2CV driver
We evaluated the quality of the subnetwork
Results of Network Methods on Cancer Driver Gene Prediction Using MutSig2CV Driver
Bold values indicate the highest score.
Each entry reports the size/
FDR, false discovery rate; HI, Human Interactone; HINT, High-quality INTeractone.
5. Discussion
In this article, we revisit the classic problem of identifying altered subnetworks in high-throughput biological data. We formalize the Altered Subnetwork Problem as the estimation of the parameters of the ASD. We show that the seminal algorithm for this problem, jActiveModules (Ideker et al., 2002), is equivalent to an MLE of the ASD. At the same time, we show that the MLE is a biased estimator of the altered subnetwork, with especially a large positive bias for small altered subnetworks. This bias explains previous reports that jActiveModules tends to output large subnetworks (Nikolayeva et al., 2018).
We leverage these observations to design NetMix, a new algorithm for the Altered Subnetwork Problem. We show that NetMix outperforms existing methods on simulated and real data. NetMix fits a GMM to observed vertex scores and then finds a maximum-weighted connected subgraph by using vertex weights derived from the GMM. heinz (Dittrich et al., 2008), another widely used method for altered subnetwork identification that also derives vertex weights from a mixture model (a BUM of
We note a number of directions for future work. The first is to generalize our theoretical contributions to the identification of multiple altered subnetworks, a situation that is common in biological applications where multiple biological processes may be perturbed (Menche et al., 2015). Although it is straightforward to run NetMix iteratively to identify multiple subnetworks—as jActiveModules does—a rigorous assessment of the identification of multiple altered subnetworks would be of interest.
Second, our results on simulated data (Section 4.1) show that altered subnetwork methods have only marginal gains over simpler methods that rank vertices without information from network interactions. We hypothesize that this is because connectivity is not a strong constraint for biological networks; indeed, the biological interaction networks that we use have both small diameter and small average shortest path between vertices (see the Supplementary Data for specific statistics). Specifically, we suspect that most subsets of vertices are “close” to a connected subnetwork in such biological networks, and thus the MLE of the connected ASD has similar bias as the MLE of the unstructured ASD. In contrast, for other network topologies such as the line graph, connectivity is a much stronger topological constraint (see the Supplementary Data for a brief comparison of different topologies). It would be useful to investigate this hypothesis and characterize the conditions when networks provide benefit for finding altered subnetworks. In particular, other topological constraints such as dense subgraphs (Guo et al., 2007; Ayati et al., 2015), cliques (Amgalan and Lee, 2014), and subgraphs resulting from heat diffusion and network propagation processes (Vanunu et al., 2010; Vandin et al., 2011; Leiserson et al., 2015; Cowen et al., 2017) have been used to model altered subnetworks in biological data. Generalizing the theoretical results in this article to these other topological constraints may be helpful for understanding the parameter regimes where these topological constraints provide a signal for the identification of altered subnetworks. In general, which topological constraints best model altered subnetworks remains an open question.
Finally, we note that biological networks often have substantial ascertainment bias: More interactions are annotated for well-studied genes (Rolland et al., 2014; Horn et al., 2018), and so these well-studied genes, in turn, may also be more likely to have outlier measurements/scores. Thus, any network method should carefully quantify the regime where it outperforms straightforward approaches—for example, methods based on ranking vertices by gene scores or degree—both on well-calibrated simulations and on real data.
Footnotes
Acknowledgments
The authors thank Mohammed El-Kebir for assistance with implementing jActiveModules* by modifying the ILP in heinz. They also thank David Tse for directing them to the network anomaly literature.
Author Disclosure Statement
B.J.R. is a cofounder of, and consultant to, Medley Genomics.
Funding Information
M.A.R. was supported in part by the National Cancer Institute of the NIH (Cancer Target Discovery and Development Network grant U01CA217875). B.J.R. was supported by US National Institutes of Health (NIH) grants R01HG007069 and U24CA211000.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.