
Abstract
The statistical inference of high-order Markov chains (MCs) for biological sequences is vital for molecular sequence analyses but can be hindered by the high dimensionality of free parameters. In the seminal article by Bühlmann and Wyner, variable length Markov chain (VLMC) model was proposed to embed the full-order MC in a sparse structured context tree. In the key procedure of tree pruning of their proposed context algorithm, the word count-based statistic for each branch was defined and compared with a fixed cutoff threshold calculated from a common chi-square distribution to prune the branch of the context tree. In this study, we find that the word counts for each branch are highly intercorrelated, resulting in non-negligible effects on the distribution of the statistic of interest. We demonstrate that the inferred context tree based on the original context algorithm by Bühlmann and Wyner, which uses a fixed cutoff threshold based on a common chi-square distribution, can be systematically biased and error prone. We denote the original context algorithm as VLMC-Biased (VLMC-B). To solve this problem, we propose a new context tree inference algorithm using an adaptive tree-pruning scheme, termed VLMC-Consistent (VLMC-C). The VLMC-C is founded on the consistent branch-specific mixed chi-square distributions calculated based on asymptotic normal distribution of multiple word patterns. We validate our theoretical branch-specific asymptotic distribution using simulated data. We compare VLMC-C with VLMC-B on context tree inference using both simulated and real genome sequence data and demonstrate that VLMC-C outperforms VLMC-B for both context tree reconstruction accuracy and model compression capacity.
INTRODUCTION
Markov chains (MCs) have been widely applied to molecular sequence analyses. For example, MCs provide a natural way to study the dependencies between the bases of DNA sequences (Blaisdell, 1985), the enrichment and depletion of certain word patterns (Pevzner et al., 1989), prediction of the occurrences of long word patterns from short patterns (Arnold et al., 1988; Hong, 1990), and detecting signals in introns (Avery, 1987). The statistical inference of MCs has been established (Billingsley, 1961). In particular, the statistical estimation of the finite-state MC transition probabilities from long DNA sequences has been extensively studied [see the surveys by Reinert et al. (2000, 2005)]. The estimation of MC transition probabilities from next-generation sequencing reads data has been studied in the works by Ren et al. (2016) and Wan et al. (2020).
The full MCs with a high but fixed finite order provide one of the most general ways to model molecular sequences. However, the estimation of high-order MCs suffers from the curse of dimensionality since the number of free parameters of the full MCs will grow exponentially with the increasing of the order k [e.g., for a MC with a finite-state space
To settle the curse of dimensionality problem raised by fitting high-order MC models, the pioneer work by Rissanen (1983) introduced a universal data compression system, which embeds the full MC of order k in a hierarchal structure of a variable length memory. In their seminal article, Bühlmann and Wyner (1999) recasted the concept of universal data compression system as the framework of variable length Markov chains (VLMCs). The processes of VLMC are still Markovian of high order, but with variable length memory: assume that the stationary process
From an algorithmic view, VLMC represents a minimal state space of high-order MC as a context tree, which is sparser than the full context (see the definition in Section 2.2). To infer VLMC from data, Bühlmann and Wyner (1999) proposed the context algorithm to construct the context tree. As we will show later that the context tree inferred by the context algorithm can be systematically biased, we therefore denote the original context algorithm as VLMC-Biased (VLMC-B). VLMC-B mainly contains two steps as follows: (1) first, it constructs a large tree representing an overfitted context tree, or an overestimated VLMC model; (2) then, it prunes nodes of the context tree from bottom up. In the tree-pruning procedure, a branch-specific statistic
Once
In this article, we study the word count statistics for VLMC inference and prove the asymptotic distribution of
The occurrences of words in sequence depend not only on their lengths but also on the ways of counting, which leads to overlapping and nonoverlapping occurrences. For overlapping occurrences, even if the letters in sequence are independent and identically distributed, the random indicators of word occurrences are generally dependent due to overlapping. Without loss of generality, we assume the categorical space
The studies for overlapping word counts aroused great interests of researchers. Gentleman and Mullin (1989) derived the exact probability distribution of frequency of word occurrences for the case that letters are independent and identically distributed and each state occurs at each position randomly with equal probability. Kleffe and Borodovsky (1992) provided the expected frequency of words and found that overlapping properties determine most of the variance and formulated the exact first and second moment of frequency of a given word in sequence generated by a first-order MC.
Lundstrom (1990) derived the covariance matrix of overlapping word counts with multiple patterns as well as its limiting value using
In this study, we derive the consistent distribution in tree-pruning process of VLMC-B for each branch-specific statistic based on solid theory of word counts statistics. We prove and demonstrate that, rather than following a common chi-square distribution, the word count-based statistic follows a branch-specific mixed chi-square distribution. We thus propose a new context tree inference algorithm with an adaptive tree-pruning scheme, termed VLMC-Consistent (VLMC-C). The VLMC-C is founded on our consistent branch-specific mixed chi-square distributions calculated from asymptotic normal distribution of multiple word patterns. Meanwhile, VLMC-C also controls the family-wise errors raised by the multiple hypothesis testing of the branches in the context tree. The superiority of our VLMC-C algorithm over VLMC-B proposed by Bühlmann and Wyner (1999) is verified using simulated data and real genome sequence data.
The organization of the article is as follows. In Section 2, we first provide the mathematical formulation of VLMC model (Section 2.1) and the context tree representation of the VLMC model (Section 2.2) and then describe the context algorithm of VLMC-B by Bühlmann and Wyner (1999) (Section 2.3). In Section 3, we provide the details of our VLMC-C method with an adaptive tree-pruning scheme, which reformulates the tree-pruning process for each branch as a hypothesis testing problem: we prove the theorem on the asymptotic distribution of the log-likelihood ratio test statistic (Section 3.1); we then propose our context tree algorithm of VLMC-C using the derived branch-specific mixed chi-square distributions, which are calculated from asymptotic normal distribution of multiple word patterns, and the multiple hypothesis testing (Section 3.2).
In Section 4, we investigate the performance of VLMC-C and compare it with VLMC-B by using simulated data and real biological sequence data. In Section 4.1, we demonstrate using simulated data that the branch-specific statistic follows our theoretical branch-specific mixed chi-square distribution, rather than the common chi-square for all branches. We then compare the VLMC-C algorithm with the VLMC-B algorithm to benchmark their performance on context tree reconstruction (Section 4.2). We demonstrate that the increasing of sequence length will improve the estimation accuracy of VLMC-C, but will worsen the performance of VLMC-B due to its inherent systematic bias (Section 4.3). We apply VLMC-C and VLMC-B on the genomes of Escherichia coli and SARS-CoV-2 and demonstrate that VLMC-C outperforms VLMC-B both in data compression capacity and in balancing model complexity with the likelihood of the sequence (Section 4.4). We conclude the article with discussions (Section 5).
VARIABLE LENGTH MARKOV CHAINS
In this section, we first introduce the VLMC model as well as the context algorithm of VLMC-B. The notations and concepts used here mainly follow the work by Bühlmann and Wyner (1999). In this study, we always refer to a MC as a stationary process
VLMC model
VLMC is a variant of MC by changing the fixed-length memory of MC to variable length memory. Rather than utilizing all states in the history
in the case that
The context length of a variable Xt is
The context tree representation of VLMC model
Under the stationary assumption, a VLMC model can be completely specified by its transition probabilities
For a tree representation
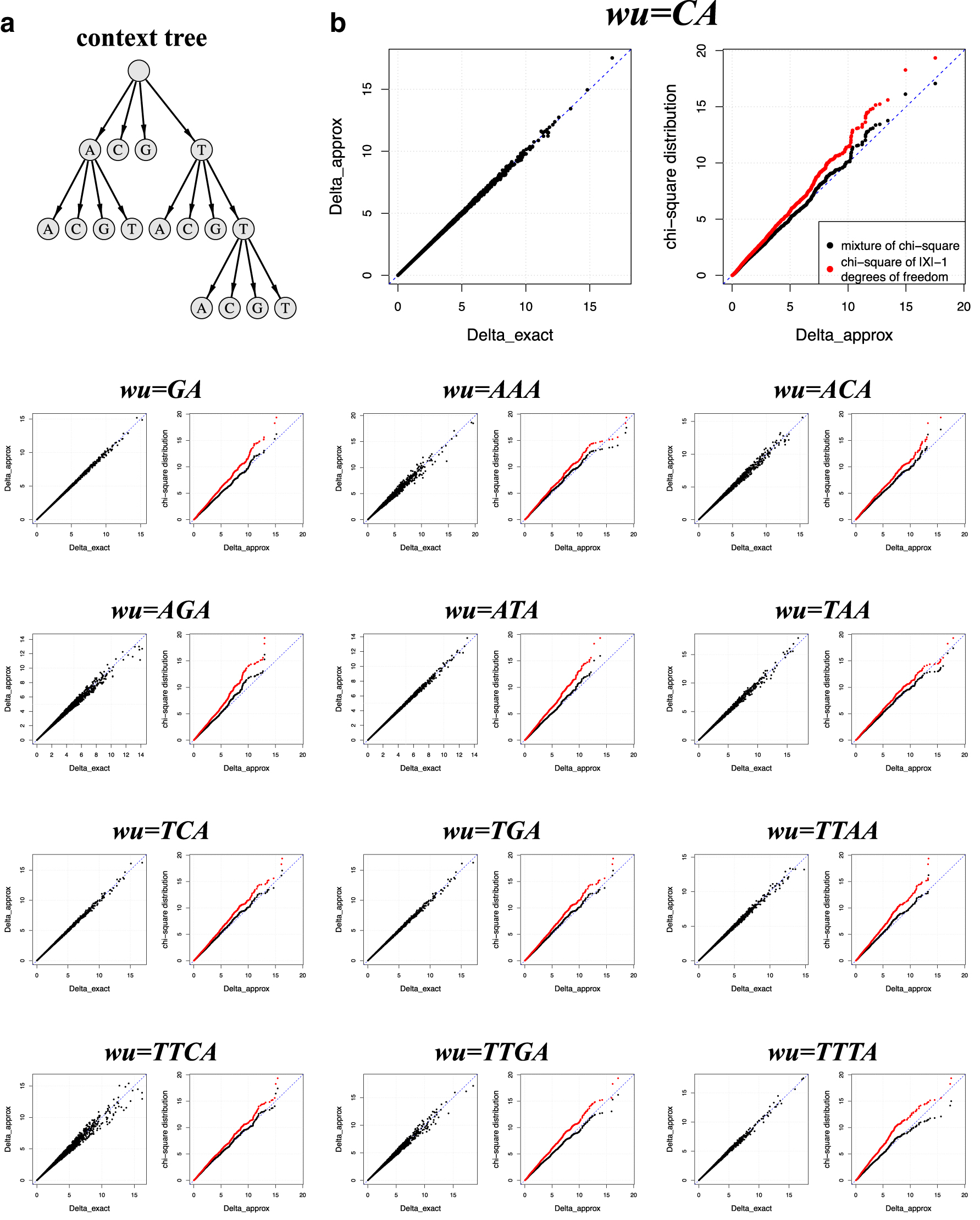
For example, the tree structure in Figure 1a represents a context function defined as follows:
Simulation experiments imply that Delta_approx coincides well with Delta_exact, and statistic Delta_approx follows the branch-specific mixed chi-square distribution.
In practice, for a sequence
First, we present the notations used in the VLMC-B. For a specific word
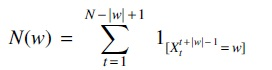
denote the number of occurrences of w in sequence
where

to determine whether to prune away the node
Estimate a large tree
Examine every branch of
the branch wu will be pruned to branch w if
Repeat step 2 with estimated tree
The choice of a cutoff threshold K in step 2 is essential for the estimation of context tree. A small K will result in a large context tree, even leading to overfitting, while a large cutoff value will result in a conservative context tree and underestimation may occur. Bühlmann and Wyner chose
Based on the studies for statistical properties of overlapping word counts, we derive the asymptotic distribution theoretically and hence achieve an unbiased tree-pruning decision. In this section, we first reformulate the pruning process for a specific branch wu in VLMC-B as a hypothesis testing problem. We find that the empirical log-likelihood ratio test statistic, termed
Hypothesis testing for tree pruning
The pruning procedure in step 2 of VLMC-B compares a tree with its subtree, which prunes away a leaf node. Since the context tree corresponds to the depending structure in sequence, the comparison of trees can be formulated as the comparison of conditional distributions based on tree structure. Thus, we formulate the tree-pruning process as the following hypothesis testing problem.
Given an observational sequence
and the log-likelihood ratio test statistic is defined as 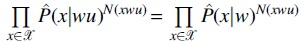 holds while it is not the case for unpruned tree, i.e., under the alternative hypothesis. Actually,
holds while it is not the case for unpruned tree, i.e., under the alternative hypothesis. Actually,
On the basis of studies on difference between overlapping word counts and its estimated expectations (Lundstrom, 1990; Reinert et al., 2000, 2005), we derive the following theorem, indicating the asymptotic normality of the standardized difference of multiple words and proving that
(i)
where
where
(ii)
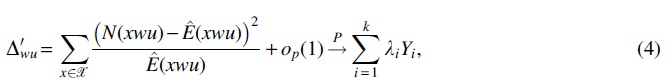
where
Theorem 1 (i) implies an asymptotic normality for the joint distribution of words of multiple patterns. Theorem 1 (ii) can be directly achieved by (i) and eigendecomposition of the covariance matrix. We present the detailed proof in Section 6.
We design a context inference algorithm, VLMC-C, based on the consistent testing founded on Theorem 1. The framework of VLMC-C is basically the same as that of VLMC-B, consisting of constructing an initial overestimated context tree and then pruning redundant nodes one by one. We use the same method to construct an initial tree as VLMC-B does.
During tree-pruning process, we apply the breadth-first traversal technique from bottom (leaf nodes) to top (root) when performing hypothesis testing. Strictly speaking, branches with the greatest lengths are first tested, followed by testing the branches in the upper layer, which are shorter. It is worth noting that the significance levels need to be adjusted for multiple hypothesis testing problem. Inspired by the Bonferroni correction method (Dunn, 1961), we set the significance levels of branches in the i-th layer of tree as
We set
RESULTS
Statistic
follows our derived mixed chi-square distribution
We study the word count statistic
Context-Based Transition Probabilities of Simulated Variable Length Markov Chain in Figure 1a
Context-Based Transition Probabilities of Simulated Variable Length Markov Chain in Figure 1a
Since the asymptotic normality in Theorem 1 requires the approximation of two statistics (Section 6), denoted as
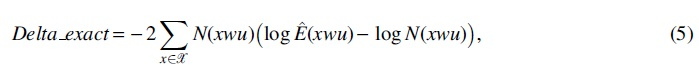
and
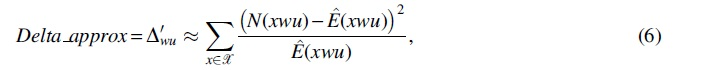
respectively. For each of the R sequences, we calculate the Delta_exact and the Delta_approx, and check whether they are consistent with each other. Since the asymptotic normality holds under null hypothesis, we set w as one of the contexts (corresponding to one of the 13 branches) in Figure 1a to ensure that the null hypothesis holds. And without loss of generality, we set
We then validate the derived theoretical mixed chi-square distribution. For each context w in the context tree and any state
We benchmark the context algorithms of VLMC-C and VLMC-B on context tree reconstruction accuracy using simulated data. The same initial trees for two algorithms are first constructed following the procedures of the VLMC-B software (Mächler and Bühlmann, 2004), where the branches whose corresponding word counts are greater than a predefined count number threshold are retained. For the purpose of saving computation time, we set the threshold as
When applied to a generated sequence with

VLMC-C outperforms VLMC-B in inferring context tree using simulated data.
We further analyze why context AG and AC are missed in the estimated context tree by VLMC-C. We conduct 10 simulation experiments under the same stationary process shown in Figure 1a and Table 1. VLMC-C underestimates context A instead of the real context AC in five simulations, while reconstructing AC successfully in the remaining five simulations. This uncertainty of context AC by VLMC-C indicates the dropping of AC is mainly caused by random errors. VLMC-C fails to reconstruct context AG in all 10 simulations. This is mainly caused by the simulation mechanism of data. The transition probabilities designed are slightly different as
We also quantify the accuracy of reconstructed trees on the 10 sequences. For each of sequence, we compare the reconstructed trees with the real context tree and calculate the numbers of the false-positive (FP) and false-negative (FN) nodes at each layer of the context tree: an FP event in the hypothesis testing problem corresponds to keeping a redundant node, and an FN event corresponds to cutting off a node by mistake. In each layer of context tree estimated by VLMC-B and VLMC-C, we compute the averaged number, as well as its standard deviation (data in parentheses in Table 2), of FP and FN events based on 10 simulations. It is clearly shown that the estimated context trees by VLMC-C are much more accurate than the trees by VLMC-B (Table 2).
Averaged Numbers of False-Positive and False-Negative Events Among 10 Simulations for the Estimated Context Tree by Variable Length Markov Chain-Biased and Variable Length Markov Chain-Consistent, Respectively
The numbers in parentheses are their respective corresponding standard deviations. VLMC-C constructs more accurate context trees than those by VLMC-B.
VLMC, variable length Markov chain; VLMC-B, VLMC-Biased; VLMC-C, VLMC-Consistent.
We further validate the performance of VLMC-C and VLMC-B on a fifth-order VLMC model (shown in Fig. 3a and Table 3). On a simulated DNA sequence with
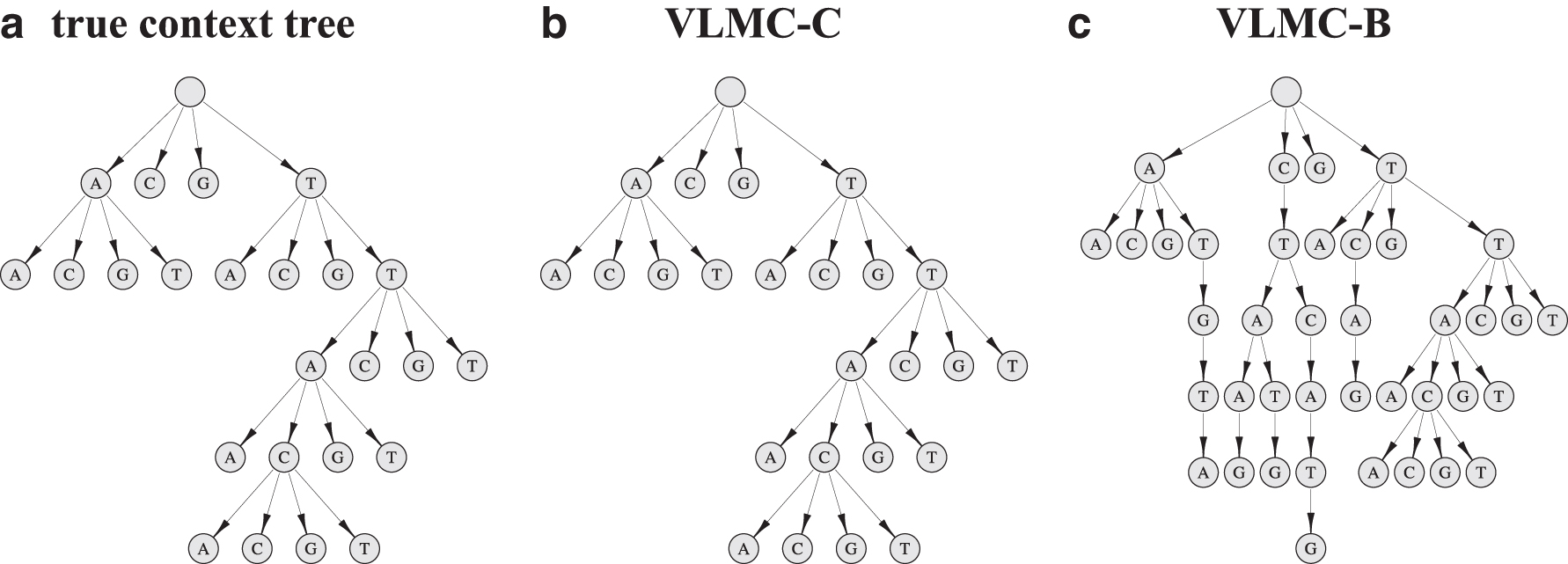
VLMC-C outperforms VLMC-B in inferring a simulated fifth-order VLMC model.
Context-Based Transition Probabilities of Simulated Variable Length Markov Chain in Figure 3a
We study the impact of sequence length on the performance of VLMC-C and VLMC-B using four simulated data sets, each of which contains 10 sequences, with the corresponding sequence length
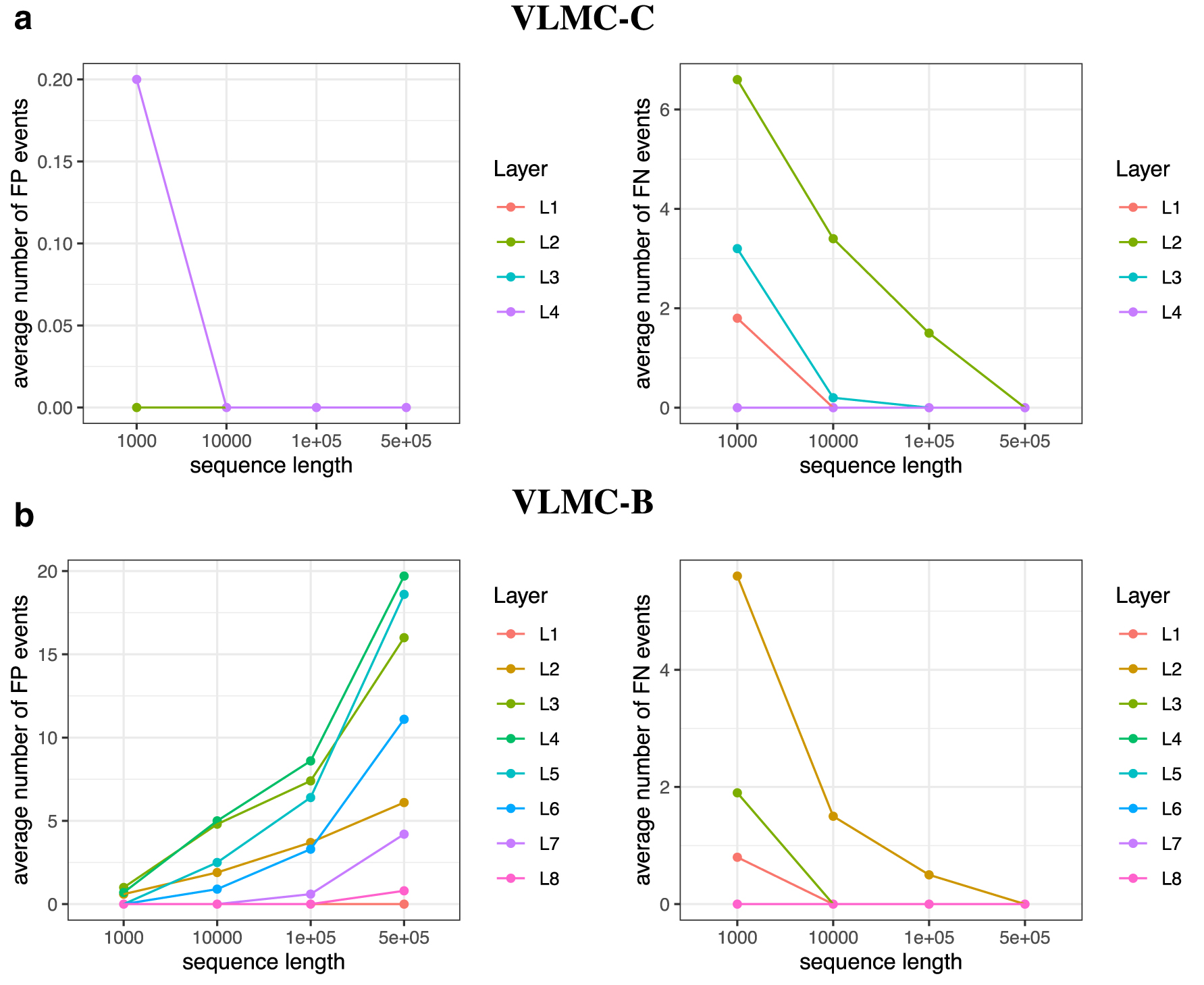
Increasing sequence length has no effect on improving estimation accuracy of VLMC-B while greatly enhance the estimation accuracy of VLMC-C. The averaged numbers of false-positive and false-negative events in each layer of estimated context tree by
In contrast, when increasing sequence length, the number of FN events by VLMC-B decreases in each layer, but the number of FP events increases markedly (Fig. 4b). The failure of VLMC-B in control of FP events with increasing sequence length is due to its systematic bias induced by the common chi-square distribution used. The increase of FP events with increasing sequence length is caused by the increase of branches in the initial tree, which also results in the decrease of FN events.
The theoretical analysis about statistical power of VLMC-C is mainly on the convergence rate of the derived multivariate normal distribution. Huang (2002) studied the error bounds on multivariate normal approximations for word counts and proved the error bounds decay at rate 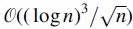 for the first-order Markov case. Robin and Schbath (2001) studied the quality of Gaussian approximation by simulations and claimed that the approximation is satisfactory when the expected count exceeds the hundreds. Since the probability of the occurrence of a word is inversely related to the word's length, this claim suggests that the Gaussian approximation would work badly for infrequent words, which are likely to be long words. Therefore, based on previous study, for a k-th order VLMC model with cardinality m of categorical space, the sample of at least
for the first-order Markov case. Robin and Schbath (2001) studied the quality of Gaussian approximation by simulations and claimed that the approximation is satisfactory when the expected count exceeds the hundreds. Since the probability of the occurrence of a word is inversely related to the word's length, this claim suggests that the Gaussian approximation would work badly for infrequent words, which are likely to be long words. Therefore, based on previous study, for a k-th order VLMC model with cardinality m of categorical space, the sample of at least
We investigate the model compression capabilities of VLMC-C and VLMC-B by applying to real genomic sequence data. We first analyze a whole-genome sequence of E. coli containing
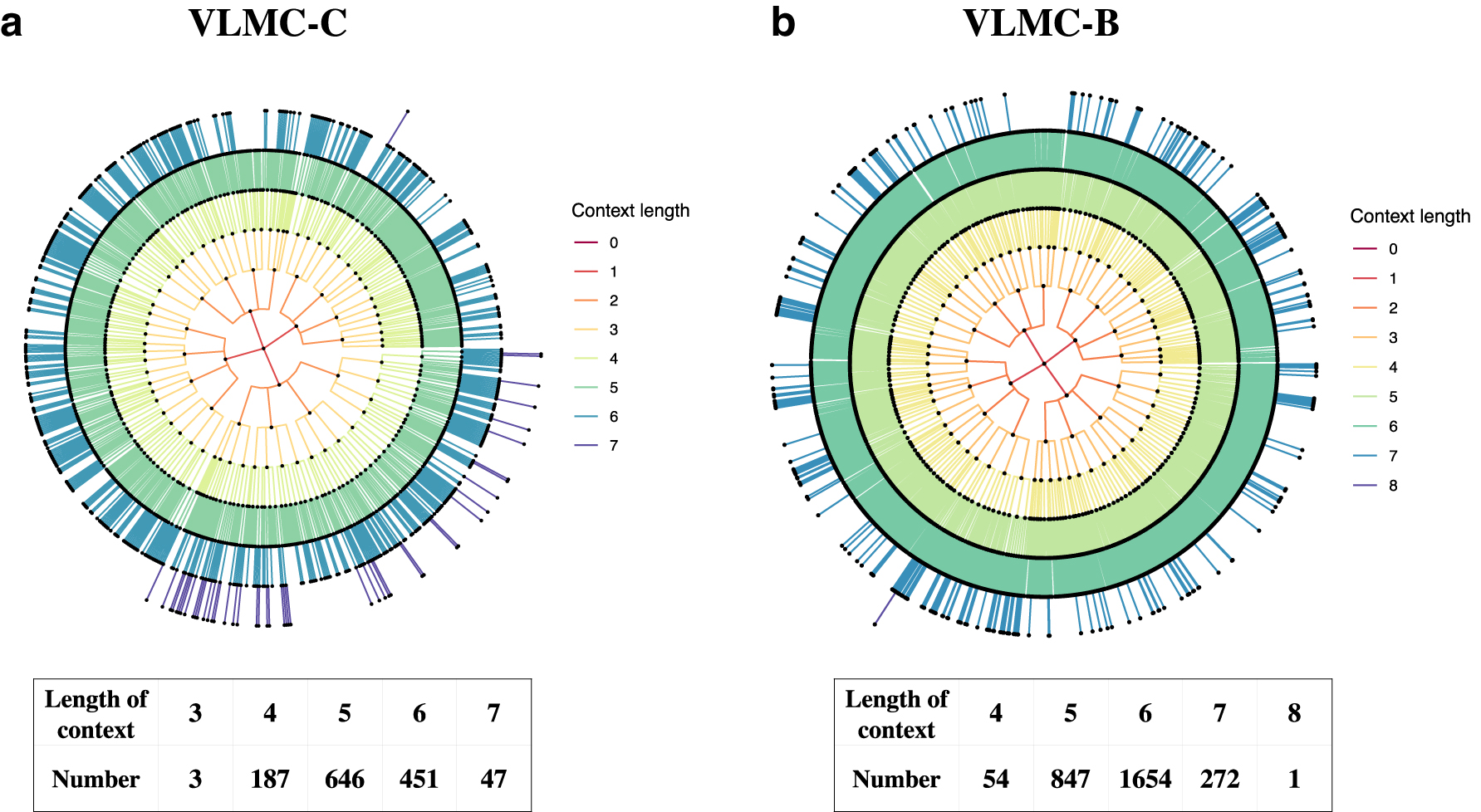
VLMC-C constructs a more sparse context tree than that by VLMC-B on the Escherichia coli genome sequence.
Bayesian information criterion (BIC) is a widely used measure for model selection. It is defined as
We also apply VLMC-C and VLMC-B algorithms to the whole genome of SARS-CoV-2 virus with

The context tree structures of SARS-CoV-2 virus reconstructed by
In this study, we derive the asymptotic distribution for testing statistic used in tree-pruning procedure of context algorithm proposed by Bühlmann and Wyner (1999). We prove theoretically and by simulations that the inferred context tree based on a fixed cutoff threshold from a common chi-square distribution used by VLMC-B (Mächler and Bühlmann, 2004) can be highly biased and error prone. Due to the systematic bias inferred by VLMC-B, increasing sequence length cannot help improve the accuracy of inferred context tree structure of VLMC model. In contrast, our theory of adaptive criterion for tree-pruning procedure improves the performance of accuracy of context tree reconstruction clearly: increasing sequence length does markedly enhance its accuracy in tree reconstruction.
Meanwhile, we control the family-wise errors raised by multiple hypothesis testing in VLMC-C algorithm during the tree-pruning procedure. Since the longer branches in context tree tend to contain more redundant information of lagged states, we consider the length of the testing context when setting the significance level
APPENDIX
Equivalence of
and
The estimated likelihood function can be factorized into the products of a series of conditional probabilities based on the depending structure corresponding to the context tree. Under hypothesis H0 and H1, the decomposed terms are the same except for the terms, which are conditioned on context wu and w, that is, 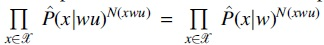 holds under H0 while it does not under H1. Then, the likelihood ratio test statistic can be simplified and reformulated as follows:
holds under H0 while it does not under H1. Then, the likelihood ratio test statistic can be simplified and reformulated as follows:

It implies that the two statistics are equivalent except that
Proof of Theorem 1
Theorem 1 mainly follows the studies on asymptotic distribution of differences between overlapping word counts and its estimated expectations (Lundstrom, 1990; Prum et al., 1995; Reinert et al., 2005). We first present the relevant studies in Lemma 1 used in the proof of Theorem 1.
where
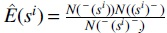 is the maximum likelihood estimator of the expectation of number of overlapping occurrences of word si. And
is the maximum likelihood estimator of the expectation of number of overlapping occurrences of word si. And
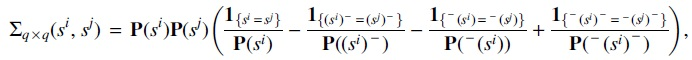
where
Proof of Theorem 1:
(i). (ii). We first substitute
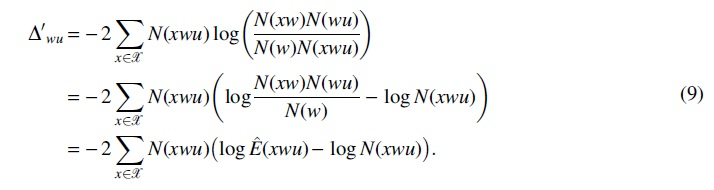
Using the Taylor expansion, we have
Then,

In the equation, the first term is zero because
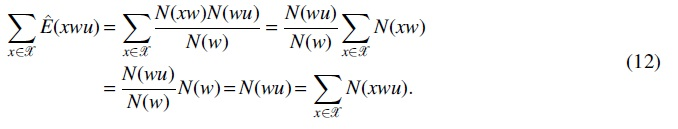
By law of large numbers,

Decompose the covariance matrix in (i)  , where
, where
Thus, we have

It indicates that
For validating our theorem and comparison with VLMC-B algorithm by Mächler and Bühlmann (2004), we simulate a VLMC model of order
Significance level setting
In our context algorithm of VLMC-C, to control the type I error rates (focus on family-wise error rate here), the significance level for each test in i-th level of tree is set to be
It can be seen with such setting, the probability of making zero type I errors is smaller than
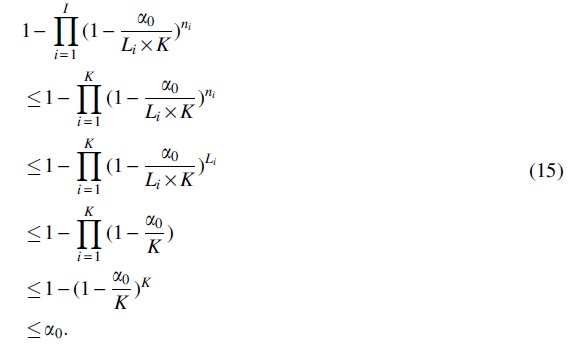
Pseudocode of VLMC-C algorithm
Footnotes
AVAILABILITY OF DATA
The whole-genome sequence of Escherichia coli data was downloaded under accession number NZ_CABFNN010000001 with version NZ_CABFNN010000001.1. The whole genome of SARS-CoV-2 virus data was downloaded from GenBank under accession number MN908947. The codes of VLMC-C are available at https://github.com/ShaokunAn/VLMC-C. The VLMC-B was implemented using the R package VLMC (Mächler and Bühlmann, ![]() ).
).
AUTHOR DISCLOSURE STATEMENT
The authors declare they have no conflicting financial interests.
FUNDING INFORMATION
L.W. was supported by the National Key Research and Development Program of China under Grant 2019YFA0709501 and the National Natural Science Foundation of China (No. 12071466). F.S. was supported by the National Institutes of Health Grants R01GM120624 and 1R01GM131407 and the National Science Foundation Grant EF-2125142.