
Abstract
The problem of aligning a sequence to a walk in a labeled graph is of fundamental importance to Computational Biology. For an arbitrary graph
1. INTRODUCTION
De Bruijn graphs play an essential role in Computational Biology. Their application to de novo assembly spans back to the 1980s (Pevzner, 1989) and has been the topic of extensive research since then (Chikhi et al, 2015; Chikhi and Rizk, 2013; Georganas et al, 2014; Lin et al, 2016; Peng et al, 2010, 2013; Ren et al, 2012; Zerbino and Birney, 2008). More recently, de Bruijn graphs have been applied in metagenomics and in the representation of large collections of genomes (Flick et al, 2017; Kamal et al, 2017; Li et al, 2015; Pell et al, 2012; Ye and Tang, 2016) and for solving other problems such as read error correction (Limasset et al, 2020; Morisse et al, 2018) and compression (Benoit et al, 2015; Holley et al, 2018).
This popularity of the de Bruijn graphs for the modeling of sequencing data makes having efficient algorithms to find walks in a de Bruijn graph matching (or approximately matching) a given query pattern important to numerous applications. For example, in metagenomics, such an algorithm can be used to quickly detect the presence of a particular species within genetic material obtained from an environmental sample. Or, in the case of read error correction, such an algorithm can be used to efficiently find the best mapping of reads onto a “cleaned” reference de Bruijn graph with low-frequency k-mers removed (Limasset et al, 2020). To facilitate such tasks, several algorithms and software tools that perform pattern matching on the de Bruijn (and sometimes general) graphs have been developed (Almodaresi et al, 2018; Heydari et al, 2018; Holley and Peterlongo, 2012; Kavya et al, 2019; Limasset et al, 2016; Liu et al, 2016; Navarro, 2000; Rautiainen and Marschall, 2017). These are often based on seed-and-extend heuristics.
With respect to theory, there has been a recent surge of interest in pattern matching on labeled graphs. This has led to many new fascinating algorithmic and computational complexity results. However, even with this improved understanding of the theory of pattern matching on labeled graphs, our knowledge is still lacking in many respects concerning specific, yet extremely relevant, classes of graphs, such as the de Bruijn graphs. An overview of the current state of knowledge is provided in Table 1.
The Computational Complexity of Pattern Matching on Labeled Graphs
DAGs, directed acyclic graphs; NFA, nondeterministic finite automation.
For general graphs, we can consider exact and approximate matching. For exact matching, conditional lower bounds based on the Strong Exponential Time Hypothesis (SETH), and other conjectures in circuit complexity, indicate that an
However, the problem becomes NP-complete when edits are allowed in arbitrary cyclic graphs. This was originally proven in Amir et al (2000) for large alphabets and more recently proven for binary alphabets in Jain et al (2019). These results hold even when edits are restricted to only substitutions. The distinction between modifications to the graph and modifications to the pattern is important as these two problems are fundamentally different. When changes are made to cyclic graphs, the same modification can be encountered multiple times while matching a pattern with no additional cost [see section 3.1 in Jain et al (2019) for a detailed discussion]. Furthermore, algorithmic solutions appearing in the studies by Kavya et al (2019), Navarro (2000), and Rautiainen and Marschall (2017) are for the case where modifications are performed only to the pattern.
The de Bruijn graphs are an interesting class of graphs from a theoretical perspective. They fall within a more general class of graphs that allow for the extension of the Burrows–Wheeler Transformation-based techniques that enable efficient pattern matching. Sufficient conditions for doing this are captured by the definition of Wheeler graphs, introduced in the study of Gagie et al (2017) and further studied in Alanko et al (2020, 2019), Egidi et al (2020), Gagie (2021), and Gibney and Thankachan (2019). The de Bruijn graphs are themselves Wheeler graphs, which in turn implies that exact pattern matching is solvable in linear time on a de Bruijn graph. However, the complexity of approximate matching in the de Bruijn graphs when permitting modifications to the graph or modifications to the pattern remained open (Jain et al, 2019).
We make two important contributions, which are indicated in Table 1. First, we prove that for the de Bruijn graphs, despite exact matching being solvable in linear time, the approximate matching problem with vertex label substitutions is NP-complete. Second, we prove that a strongly subquadratic time algorithm for the approximate pattern matching problem on the de Bruijn graphs, where substitutions are only allowed to the pattern, is not possible under the SETH. Note that, in contrast, pattern-to-text matching (under substitutions) can be solved in subquadratic
1.1. Technical preliminaries
1.1.1. Notation for edges
For a directed edge from a vertex u to a vertex v, we will use the notation
1.1.2. Walks versus paths
A distinction must be made between the concept of a walk and a path in a graph. A walk is a sequence of vertices
1.1.3. Induced subgraphs
An induced subgraph of a graph
1.1.4. De Bruijn graphs
An order-k full de Bruijn graph is a compact representation of all k-mers (strings of length k) from an alphabet
1.1.5. Strings and matching
For a string S of length n indexed from 1 to n, we use
With these definitions in hand, we can formally define our first problem.
Theorem 1 is proven in Section 2. Intuitively, our reduction transforms a general directed graph into a de Bruijn graph that maintains key topological properties related to the existence of walks. The distinct problem of approximately matching a pattern to a path in a de Bruijn graph was shown to be NP-complete in the study by Limasset et al (2016). As mentioned by the authors of that work, the techniques used there do not appear to be easily adaptable to the problem for walks. Our approach uses edge transformations more closely inspired by those used in the study by Kapun and Tsarev (2013) for proving hardness on the paired de Bruijn sound cycle problem.
For Problem 2, we provide a hardness result based on the SETH, which is frequently used for establishing conditional optimality of polynomial time algorithms (Abboud et al, 2018; Backurs and Indyk, 2016; Equi et al, 2019; Gibney, 2020; Gibney et al, 2021; Hoppenworth et al, 2020). We refer the reader to the study of Williams (2015) for the definition of the SETH and for the reduction to the orthogonal vectors (OV) problem, which is utilized to prove Theorem 2.
Note that the order, k, of the de Bruijn graphs used in ours proofs are
2. HARDNESS OF PROBLEM 1 ON THE DE BRUIJN GRAPHS
Our proof of NP-completeness uses a reduction from the Hamiltonian cycle problem on directed graphs, which is the problem of deciding if there exists a cycle through a directed graph that visits every vertex exactly once. The Hamiltonian cycle problem has been proven NP-complete, even when restricted to directed graphs where the number of edges is linear in the number of vertices (Plesník, 1979). To present our reduction, we introduce the concept of merging two vertices. To merge vertices u and v, we first create a new vertex w. We then take all edges with either u or v as their head and make w their new head. Next, we take all edges with either u or v as their tail and make w their new tail. This makes the edges
2.1. Reduction
We start with an instance of the Hamiltonian cycle problem on a directed graph where the number of edges is linear in the number of vertices. We can assume that there are no self-loops or vertices with in-degree or out-degree zero. To simplify the proof, we first eliminate any cycles of length 2 using the gadget in Figure 1. We denote the resulting graph as 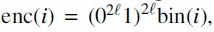

Gadget to remove cycles of length 2 from the initial input graph.
We construct a new (de Bruijn) graph

The transformation from edges to paths used in our reduction.

Vertices with the same implicit label are merged while transforming D to

Vertices with the same implicit label are merged while transforming D to
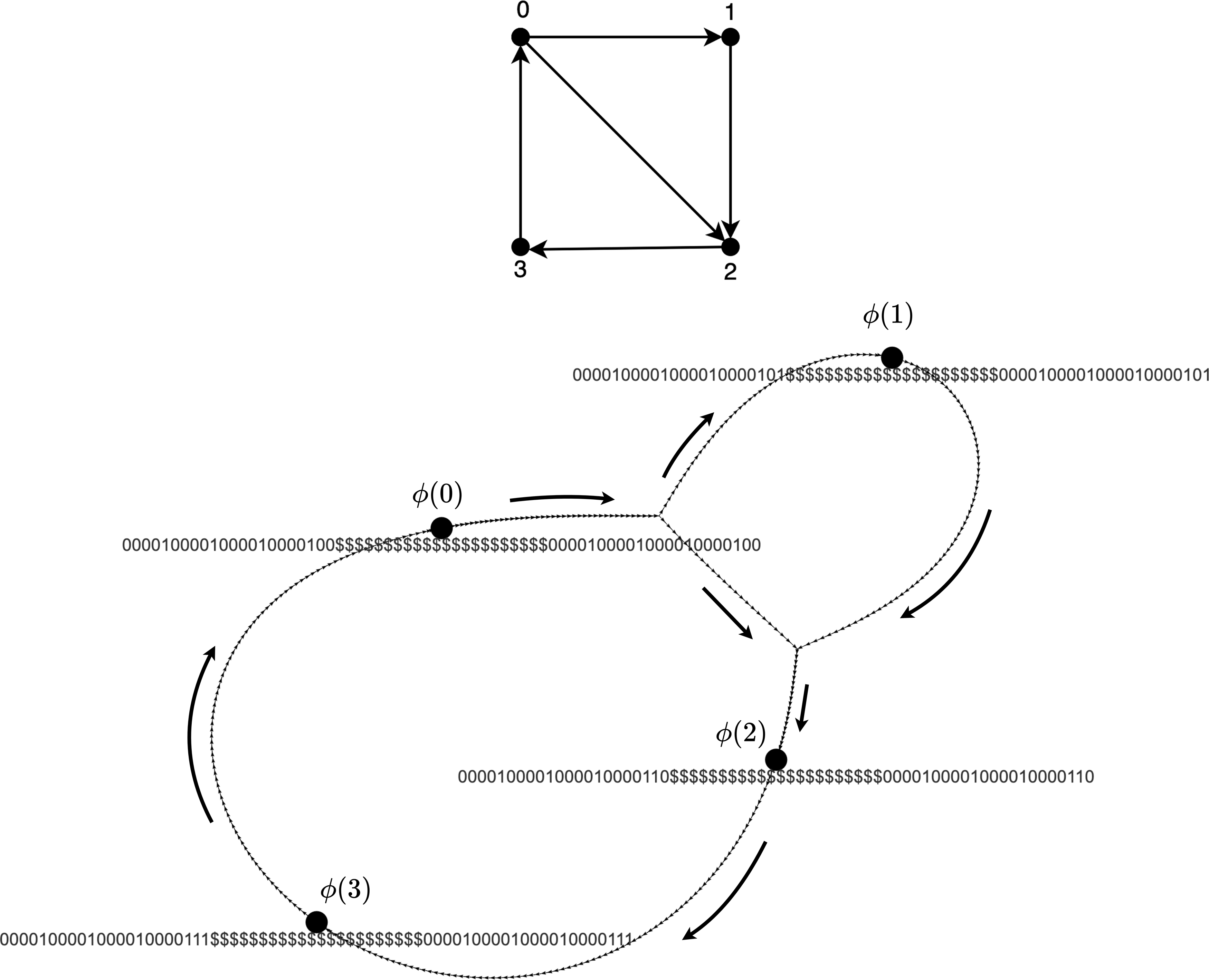
(Top) A graph before the reduction is applied to it. (Bottom) The transformed graph. Implicit labels for marked vertices are shown, and the path directions are annotated by arrows beside each path.
We will show that there exists a walk in
2.1.1. Proof of correctness
Proof. There are three properties that must be proven: (i) Implicit labels are unique, meaning for every implicit label at most one vertex is assigned that label; (ii) There are no edges missing, that is, if the implicit label of
Property (i) holds since after every edge transformation, vertices with the same implicit label are merged, making every implicit label occur at most once.
For Property (ii), consider the completed graph Case: the implicit label of y is Then, any potential However, the only implicit labels created that have a suffix of the form Case: the implicit label of y is Because the only implicit labels with the substring Case: the implicit label of y is In the case Case: the implicit label of y is Because the only implicit labels with the substring Case: the implicit label of y is For
We prove Property (iii) that all walks of length
For
After processing all vertices on
The correctness of the reduction remains to be shown. Lemmas 2–4 establish useful structural properties of
This is proven using induction on the number of edges transformed. It is shown that for every vertex, a key property regarding the distances to its closest marked vertices continues to hold after vertices on any newly created path are merged.
Proof. We first define forward distance and backward distance. Let
We use induction on the number of edges transformed. Our IH will be that the length of all walks that end at and contain only two marked vertices is
 has backward distance
has backward distance  has backward distance
has backward distance  has backward distance
has backward distance
The base case,
Also, all the stated properties in the IH also hold for
Proof. In the case where
In the case where
The case
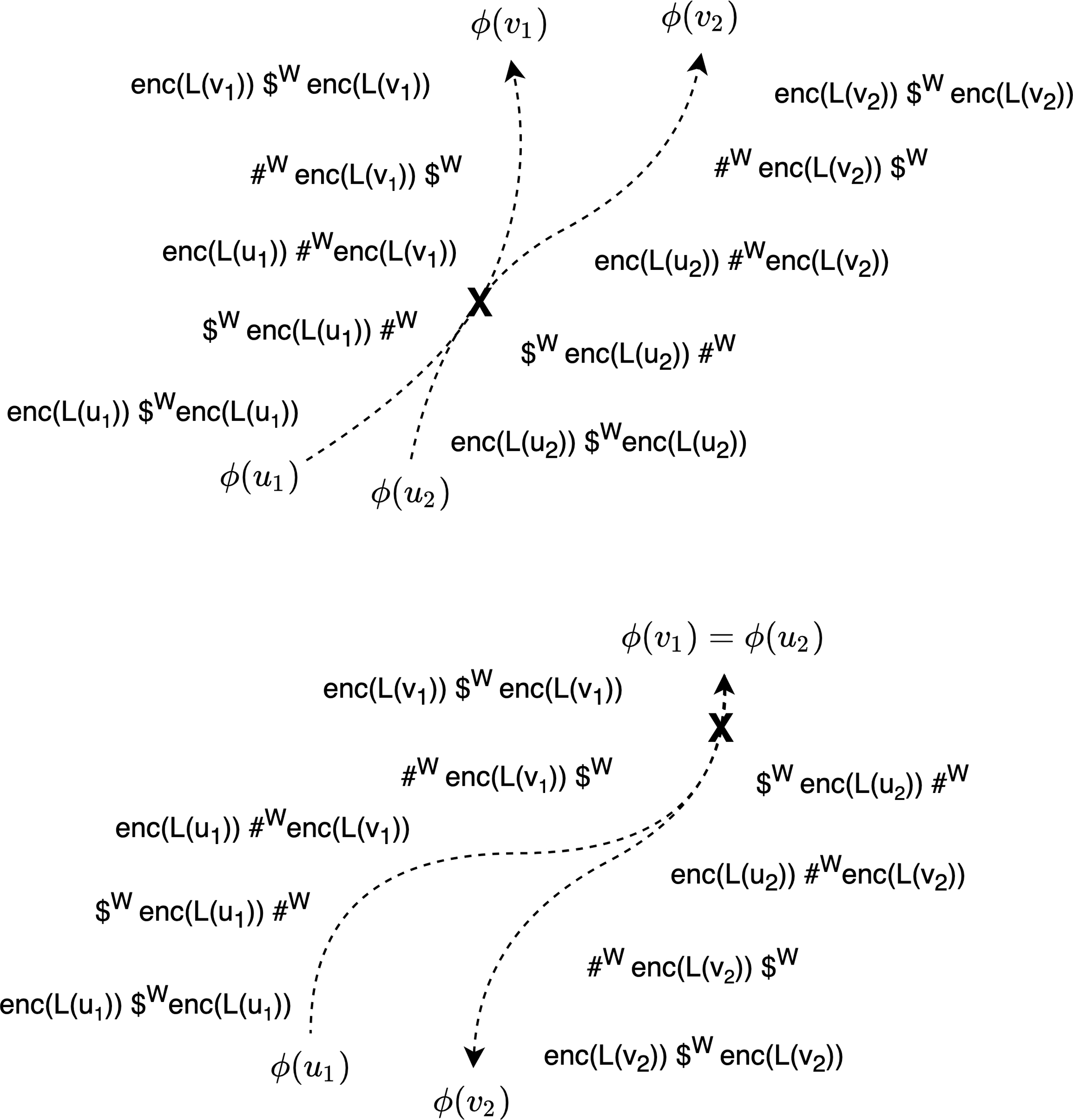
Examples where paths between marked vertex cannot share any vertex: (Top) The case where
Proof. It is clear from construction that if there is an edge
In the other direction, suppose for the sake of contradiction that there exists such a walk starting at The more interesting case is if
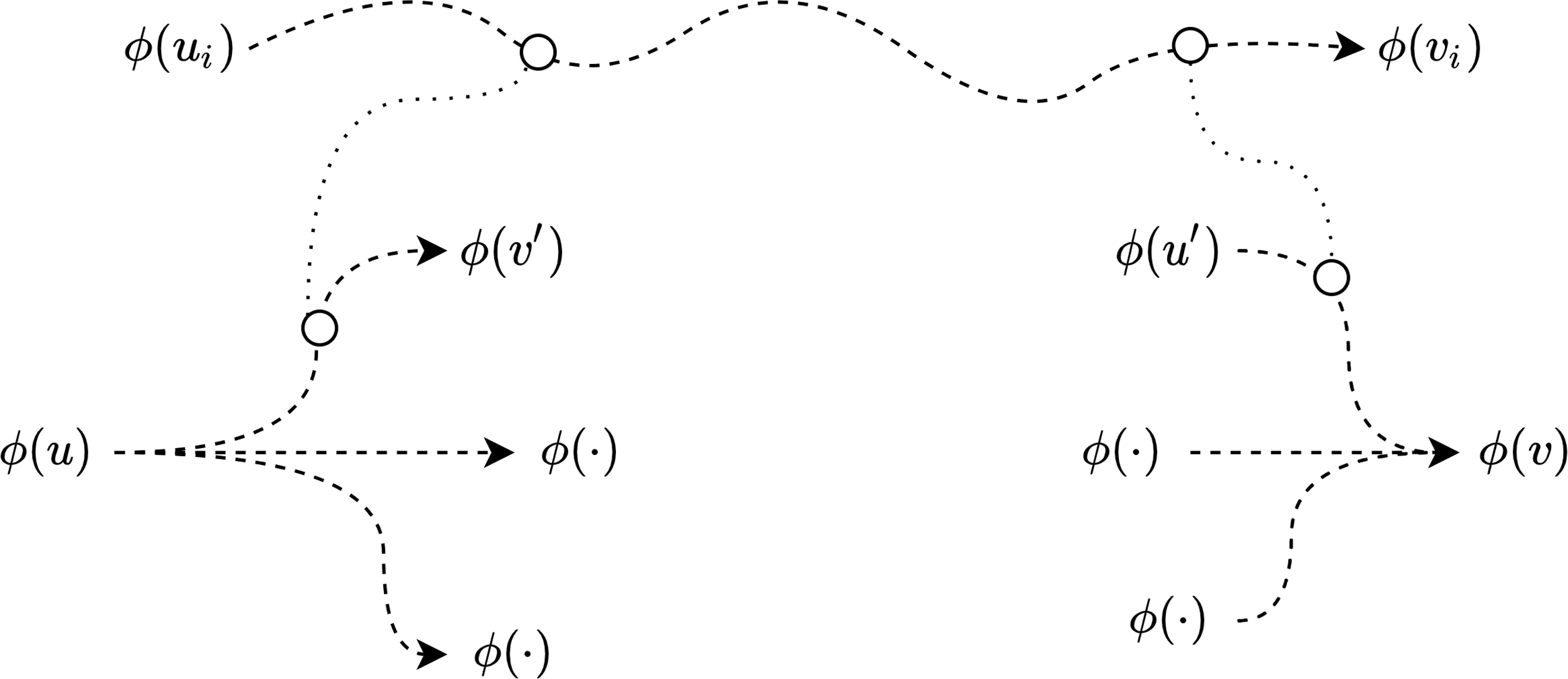
In the proof of Lemma 4, we consider whether the path

In the proof of Lemma 4, the case where
In the proof of Lemma 4, the case where

In the proof of Lemma 4, the case where
Proof. Let
To prove this, we establish the existence of a long non-branching path for every marked vertex that can be traversed at most once when matching P. This, combined with maximal paths of,
Proof. We first make the following observations: pre-substitution of any of the vertex labels in For all vertices and all vertices on this path have in-degree and out-degree one. In fact, the only vertices with in-degree greater than one having implicit labels where where Every maximal walk containing only
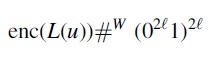
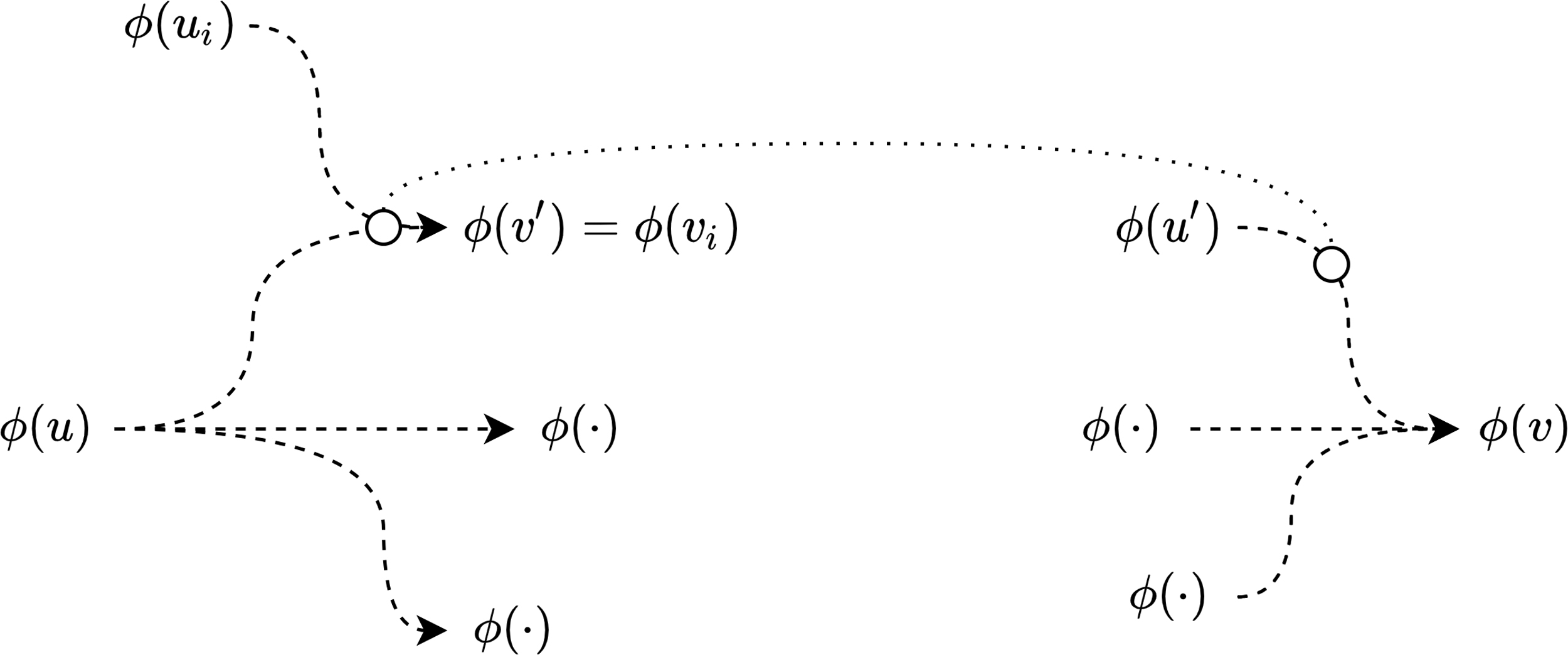
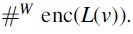 ). This path contains the marked vertex
). This path contains the marked vertex
To see the “local” number of substitutions caused by matching a  at least
at least
We now look at the number of substitutions needed on a “global” level due to shift of size
If 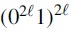 in P may not be needed, but the total number of substitutions required is still greater than
in P may not be needed, but the total number of substitutions required is still greater than
For
Post-substitution to vertex labels, we will refer to a vertex as newly marked if there exists a walk ending at it that matches a string of the form
for some
Proof. Pre-substitution, only marked vertices have implicit labels of the form
Proof. First, we show that all marked vertices, except the one with implicit label
We next show that each marked vertex is visited at least once. Suppose for sake of contradiction that some marked vertex is not visited. By Lemma 7, no additional marked vertices are created. Hence, a marked vertex ending a path matching
Proof. By Lemma 4, the paths between marked vertices traversed while matching with P correspond to edges between vertices in D. Combined with marked vertices being visited exactly once from Lemma 8 (except the marked vertex ending a path matching
This completes the proof of Theorem 1. We next show that
3. HARDNESS FOR PROBLEM 2 ON THE DE BRUIJN GRAPHS
3.1. Reduction
The OV problem is defined as follows: given two sets of binary vectors
Let the given instance of OV consists of
We will next provide a formal description of the graph D our reduction creates from the set

An illustration of the reduction from orthogonal vectors to Problem 2.
We start with the Selection fan-in. Let
The Selection section consists of 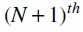 path has
path has  Let si denoted the start vertex of path i. We arbitrarily choose
Let si denoted the start vertex of path i. We arbitrarily choose
We define the implicit label size as
To construct the Synchronization loop, we create a directed cycle with
Let

and the maximum number of allowed substitutions
We call substrings in P of the form
3.2. Proof of correctness
Proof. For each of the four graph sections discussed above, we will prove for each vertex in that section that Properties (i)–(iii) from the proof of Lemma 1 hold. That is, for every vertex v, the implicit label of v is well defined, unique, and there are no additional edges that should have v as their head.
Selection fan-in: (well defined) For any vertex v in the Selection fan-in, there are two paths of length (unique) The binary string B could only possibly occur again as a suffix the Selection section. However, all implicit labels occurring in that section contain longer binary strings. Hence, the implicit label occurs only once in D. (no missing inbound edges) Let u be any vertex such that where Based on the limited number of implicit labels present in D, it must be that Selection section: (well defined) For a vertex v in the Selection section, there are two length where (unique) If v has a path of length
then it must be in the Selection section. The substring (no missing inbound edges) Taking u and v as above, if the vertex v has an implicit label of the form or In either case, If the vertex v has an implicit label of the form then any potential vertex u has an implicit label where Post-Selection Merge section: (well defined) For a vertex v in this section, all length (unique) Again by construction, if another vertex (no missing inbound edges) Taking u and v as above, vertex v has an implicit label of the form Synchronization loop: (well defined) There are two length (unique) An implicit label for a vertex in any other section contains a symbol that is not a 2 or a 3. Within the Synchronization loop, each implicit label clearly occurs exactly once. (no missing inbound edges) Taking u and v as above, vertex v has an implicit label of the form 
Proof. Suppose that some 3 in P is not matched with 3 in D or with the final vertex in a path in the Selection section. Since any walk between 3s in D has a length that is a multiple of k and 3 in P are
for
Next, suppose some 3 in P is matched with the last vertex in a path in the Selection section. We consider the first such occurrence. In the case where this occurrence of 3 in P is followed in P by a substring
then a cost of at least
Hence, matching 3 in P with the last vertex in a path in the Selection section is suboptimal. In the case where the occurrence of 3 in P is followed in P by
Proof. Suppose otherwise. By Lemma 11, this can only occur if some vector gadget in P is matched against the Synchronization loop. This requires at least  path in the Selection section. Due to
path in the Selection section. Due to
Hence, the cost decreases by matching the vector gadget in P to a vector gadget in D instead.
Proof. Match the vector gadget for b in P with the vector gadget for a in the Selection section of D. This costs 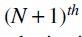 path in the Selection section, requiring
path in the Selection section, requiring
Proof. By Lemma 12, we can assume vector gadgets in P are only matched against vector gadgets in D. Suppose that there does not exist a pair of OV
4. DISCUSSION
We leave open several interesting problems. An NP-completeness proof for Problem 1 on the de Bruijn graphs when
A practical question is whether these problems are hard for small
Footnotes
AUTHOR DISCLOSURE STATEMENT
The authors declare they have no conflicting financial interests.
FUNDING INFORMATION
This research was supported in part by the U.S. National Science Foundation (NSF) grants CCF-1704552, CCF-1816027, and CCF-2112643.