
Abstract
This study develops a sure joint feature screening method for the case–cohort design with ultrahigh-dimensional covariates. Our method is based on a sparsity-restricted Cox proportional hazards model. An iterative reweighted hard thresholding algorithm is proposed to approximate the sparsity-restricted, pseudo-partial likelihood estimator for joint screening. We rigorously show that our method possesses the sure screening property, with the probability of retaining all relevant covariates tending to 1 as the sample size goes to infinity. Our simulation results demonstrate that the proposed procedure has substantially improved screening performance over some existing feature screening methods for the case–cohort design, especially when some covariates are jointly correlated, but marginally uncorrelated, with the event time outcome. A real data illustration is provided using breast cancer data with high-dimensional genomic covariates. We have implemented the proposed method using MATLAB and made it available to readers through GitHub.
INTRODUCTION
Sure feature screening is a popular dimension reduction technique for ultrahigh-dimensional problems with statistical guarantees (Fan and Lv, 2008). Among many of its applications, sure feature screening methods have been frequently used to rapidly reduce the ultrahigh-dimensional data to a more manageable reduced-dimension model and consequently improve the computational expediency, statistical accuracy, and algorithm stability of many variable selection, estimation, and inference methods for high-dimensional data. For instance, when coupled with a classical, regularized variable selection method, the resulting two-stage variable selection and estimation procedure is not only computationally more stable and faster but also more accurate for variable selection and parameter estimation (Fan and Lv, 2008; Liu et al, 2020).
Since the seminal work by Fan and Lv (2008), there have been extensive developments of feature screening procedures for a variety of model settings that include linear models (Fan and Lv, 2008), generalized linear models (Fan and Song, 2010; Xu and Chen, 2014), additive models (Fan et al, 2011), varying coefficient models (Fan et al, 2014; Liu et al, 2014), quantile models (He et al, 2013), and model-free screening (Li et al, 2012; Zhu et al, 2011) and for different data types such as survival data (Gorst-Rasmussen and Scheike, 2013; Liu et al, 2021; Liu et al, 2020; Song et al, 2014; Yang et al, 2016), missing data (Wang and Li, 2018), longitudinal data (Zhang et al, 2019), and case–cohort data (Zhang et al, 2021a).
We refer to studies by Liu et al (2015), He et al (2019), and Liu and Li (2020), among others, for some nice surveys and further references of recent developments on sure feature screening methods.
This study considers the problem of feature screening for the case–cohort design. The case–cohort design is a widely used design in epidemiological studies and disease prevention trials, with many appealing properties and utilities (Kalbfleisch and Lawless, 1988; Kulich and Lin, 2004; Prentice, 1986). In a case–cohort study, covariates are only measured for subjects in a randomly selected subcohort and for all cases in the full cohort. It is particularly useful when cases are rare and some covariates such as genomic information are expensive to obtain. It does not require matching and thus is easy to implement. It also has the advantage of enabling one to study several disease outcomes by using the same randomly selected subcohort.
It is worth noting that the case–cohort design also offers a useful tool for analyzing the time to a rare event with massive Electronic Health Record (EHR) data, for which fitting a Cox proportional hazards model can be costly and practically infeasible (Borgan et al, 2000; Kawaguchi et al, 2021). However, despite the extensive statistical literature on either sure feature screening or the case–cohort design, sure screening methods for the case–cohort design remain sparse and underdeveloped.
To the best of our knowledge, the only sure screening tool currently available for the case–cohort design was recently developed by Zhang et al (2021a), who derived a weighted sure independence screening (WSIS) method and an iterative weighted sure independence screening (IWSIS) method for a case–cohort design with ultrahigh-dimensional covariates.
However, as shown by the simulation results in Section 3, although WSIS works well for screening marginal effects, it often fails to retain covariates that are jointly correlated, but marginally uncorrelated, with the response. Its iterative version, IWSIS, may offer some limited improvements, but the overall performance is still unsatisfactory for joint screening. Therefore, there is an unmet need to develop improved sure joint screening methods for the case–cohort design.
The purpose of this study is to develop a sure joint feature screening method for the case–cohort design under a high-dimensional Cox proportional hazards model. Our screening procedure is based on a sparsity-restricted maximum pseudo-partial likelihood estimator (SMPLE), inspired by some recent work for the simple random sampling design (Liu et al, 2021; Liu et al, 2020; Xu and Chen, 2014; Yang et al, 2016).
We first rigorously establish that the SMPLE for the case–cohort design has a sure joint screening property in a sense that as the sample size increases, it retains all true active covariates with probability tending to 1. Then, because solving for the exact SMPLE is NP-hard, we propose a customized iterative reweighted hard thresholding (IWHT) algorithm to approximate the SMPLE and show that each IWHT update yields a sure joint screening procedure when a Least Absolute Shrinkage and Selection Operator (LASSO) initial estimate is employed.
The proposed SMPLE screening procedure is a natural extension of the procedure used by Yang et al (2016), from the simple random sampling design to the case–cohort design by incorporating a weight function
Additionally, we establish a new theoretical result for the Cox model under the case–cohort design: each LASSO-initiated IWHT update yields a sure joint screening procedure, which is practically highly desirable and has not been previously established by Yang et al (2016) for the Cox model under the simple random sampling design. Finally, we demonstrate through simulations that the proposed joint screening method can provide substantial improvements over WSIS and IWSIS for the case–cohort design, especially when some covariates are jointly correlated, but marginally uncorrelated, with the event time outcome.
The rest of the study is organized as follows. In Section 2, we describe our SMPLE joint screening method for the ultrahigh-dimensional Cox proportional hazards model for case–cohort data and state its sure screening properties. Section 3 presents simulation studies to assess the finite sample performance of our procedure in comparison with the existing WSIS and IWSIS methods for the case–cohort design. In Section 4, we illustrate our method using breast cancer data to identify relevant genomic features for predicting overall survival.
JOINT FEATURE SCREENING FOR COX'S MODEL UNDER THE CASE–COHORT DESIGN
Case–cohort design and preliminaries
Let
However, under the case–cohort design, the covariate X is only collected from all cases (failures) and from a randomly selected subcohort of fixed size
Assume the following Cox proportional hazards model (Cox, 1972) for
where
For the classic low-dimensional covariate setting with fixed p,

where
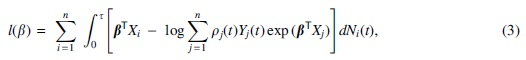
is the logarithm of a pseudo-partial likelihood (Kalbfleisch and Lawless, 1988),
Below we develop a joint screening procedure for the high-dimensional setting
Define a sparsity-restricted maximum pseudo-partial likelihood estimator (SMPLE) of

where the cardinality of the true set
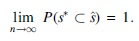
Note that the optimization problem (4) is NP-hard and hence computationally infeasible in a high-dimensional setting. Instead of solving for the exact SMPLE
Step 0. Let
Step t. For each
(a) Define
where
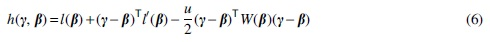
is a local quadratic approximation of
where
(b) Obtain an updated
To appreciate the above IWHT algorithm, one may regard
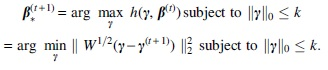
We next state some desirable properties of the IWHT in Theorems 2 and 3. The proofs are provided in Section 7.
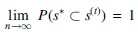
for any fixed
In this section, we present some simulations to evaluate the performance of the proposed SMPLE joint screening method and compare it with the WSIS and IWSIS methods by Zhang et al (2021a). For the IWSIS method, we follow the same setup used by Zhang et al (2021a), with
In our simulation, we consider
We considered the following three model settings:
Case 1: Case 2: Case 3: The same as Case 1, except that
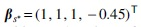 and
and  and
and 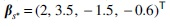 and
and
It can be shown that in all three settings,
The performance of the screening methods is evaluated and compared using Pj, the proportion that the jth predictor is selected in a given model size k in 100 Monte Carlo replications, and
We set
Simulated Probabilities Pj and
of Retaining an Individual Variable Xj and All Four Active Variables (
; Each Entry Is Based on 100 Monte Carlo Replicates)
Simulated Probabilities Pj and
IWSIS, iterative weighted sure independence screening; SMPLE, sparsity-restricted maximum pseudo-partial likelihood estimator; WSIS, weighted sure independence screening.
It is observed from Table 1 that the proposed SMPLE outperforms WSIS and IWSIS, with a much higher probability
As expected, the performance of all methods would improve as the case-to-noncase ratio increases from 1:1 to 1:2. Furthermore, under Case 2, with much large signals, both SMPLE and IWSIS work well with
As suggested by a referee, we conducted more simulations to investigate the performance of the proposed method under a number of other scenarios, including a nonproportional hazards model, discrete covariates, weaker signals, highly correlated covariates, and higher CR. The results are consistent with those reported in Table 1. Details are presented in sections S1–S5 of Supplementary Data.
As an illustration, we apply our methodology to a breast cancer dataset that contains 24,885 genes for 295 female patients between 1984 and 1995 at the Netherlands Cancer Institute (Annest et al, 2009). After an initial screening by the Rosetta error model (Annest et al, 2009) and discarding patients with missing values, we used 289 patients and 4919 genes for our analysis. The overall CR is 76%, and we set the case-to-noncase ratio of 1:1.
First, we applied the SMPLE, WSIS, and IWSIS methods to perform screening for important genes related to overall survival. All predictors were standardized with mean zero and variance 1. We set
Genes Selected by the Sparsity-Restricted Maximum Pseudo-Partial Likelihood Estimator, Weighted Sure Independence Screening, and Iterative Weighted Sure Independence Screening Methods for Breast Cancer Data
Genes Selected by the Sparsity-Restricted Maximum Pseudo-Partial Likelihood Estimator, Weighted Sure Independence Screening, and Iterative Weighted Sure Independence Screening Methods for Breast Cancer Data
Second, we further performed variable selection with Smoothly Clipped Absolute Deviation (SCAD) penalty for the models obtained by each screening method. The selected genes, along with the degree of freedom, and Bayesian Information Criterion (BIC) scores of the resulting model are summarized in Table 3. It is seen that SMPLE-SCAD yielded the most favorable model with the lowest BIC score compared with WSIS-SCAD and IWSIS-SCAD. We also note that NM.003258 is retained by SMPLE, but not by the other methods.
Genes Selected by Applying Smoothly Clipped Absolute Deviation (SCAD) After Screening for Breast Cancer Data
BIC, Bayesian information criterion; DF, degree of freedom.
We also point out that replacing the SCAD penalty with either LASSO or Minimax Concave Penalty (MCP) will lead to a similar conclusion (see Table S6 of Supplementary Data).
We have developed a sure joint screening procedure with rigorous theoretical justification for the ultrahigh-dimensional Cox proportional hazards model for the case–cohort design. The proposed procedure is based on an SMPLE and computationally efficient IWHT algorithm. Empirical studies show that the proposed SMPLE screening procedure generally outperforms the existing marginal screening method (WSIS) and its iterative version (IWSIS) (Zhang et al, 2021a) when some covariates are marginally uncorrelated, but jointly correlated, with the event time.
Although this study only considers time-independent covariates for simplicity, the proposed method can be easily extended to time-dependent covariates that are continuously measured over time. It is also worth noting that oftentimes, a time-dependent covariate is measured only intermittently and/or with measurement error, which can be handled using a joint model framework for longitudinal and time-to-event outcomes (Elashoff et al, 2017). It would be interesting to investigate if the proposed method can be extended to joint models in future research.
Furthermore, our joint screening method for the Cox proportional hazards model is developed for the case–cohort design with a simple, random subcohort sample. It would be useful to further extend this approach to the case–cohort design with other sampling schemes such as the stratified, simple random sampling (Borgan et al, 2000) and counter-matched design (Langholz and Borgan, 1995). It would also be of interest to extend this approach to other models such as Accelerated Failure Time (AFT) models for the case–cohort design (Chiou et al, 2014; Kong and Cai, 2009), other related designs such as the nested case–control design (Goldstein and Langholz, 1992), and other types of survival data such as left-truncated data (Volovics and van den Brandt, 1997).
Finally, it would be interesting to investigate if some existing model-free screening methods such as the sure independence screening procedure based on distance correlation (Li et al, 2012) and sufficient variable screening/selection (Yang et al, 2022; Yang et al, 2019) for the standard random sample setting can be extended to the case–cohort design.
REGULARITY CONDITIONS
The following notations and regularity conditions are needed to establish the sure screening properties of the proposed joint screening procedure.
For each n, we define

Regularity conditions:
(C1)
(C2)
(C3)
(C4) There exists a positive constant c1 such that for sufficiently large n,
(C5) There exist positive constants, c2 and c3, such that
(C6) There exists a neighborhood
(C7) There exists a positive constant
for any
Note that (C1) guarantees a finite, baseline cumulative hazard and a nonempty risk set at the end of the study. Conditions (C2)–(C5) are similar to those used by Xu and Chen (2014) for the sure screening property. Condition (C6) essentially requires
TECHNICAL PROOFS
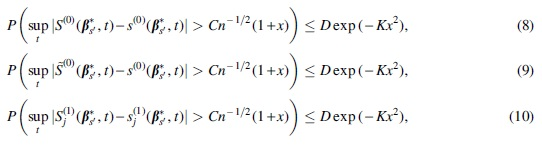
and
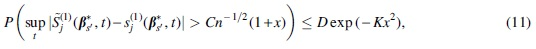
for any
We first prove (10). Write
Next, we prove (11). Rewrite

and we have
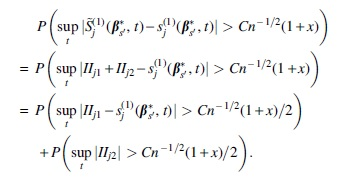
Similar to the proof of Equation (10), we have

and

which completes the proof of Equation (11).□

We now prove (12). Consider

where

where

By theorem 3.1 of Bradic et al (2011), we have
where
For

We further note that

and
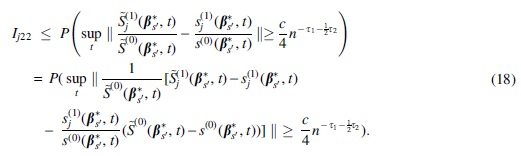
By (C6),
It follows immediately that
Combining (13) to (16) gives
Hence,
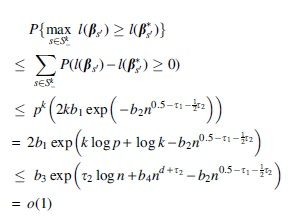
for some generic positive constants
For any

This completes the proof. □
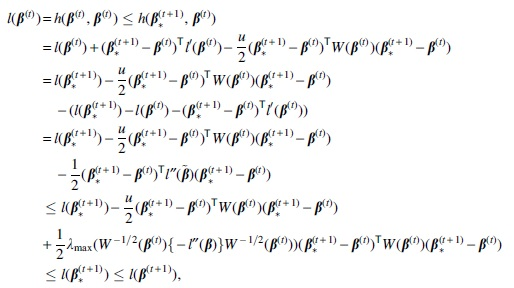
where
To prove Theorem 3, we first establish the following lemma.
where the constant
Let  . Then, by the Taylor series expansion, we have
. Then, by the Taylor series expansion, we have
for some intermediate value
We next establish an upper bound for
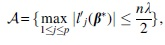
where for each

as
which further implies that
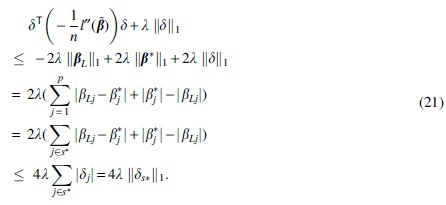
Since
Combining Cauchy inequality and Equation (21), we have
This leads to
under event
When
Under conditions
Suppose that
Under the induction assumption,
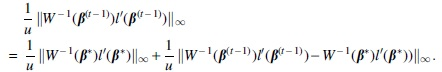
Under the conditions of this theorem,
Finally, from theorem 1 of Ni et al (2016) and condition (C2), we have
Footnotes
AUTHOR DISCLOSURE STATEMENT
The authors declare they have no conflicting financial interests.
FUNDING INFORMATION
G.L.'s research was supported, in part, by the U.S. National Science Foundation (Grant No. 2205441) and the U.S. National Institutes of Health (Grant Nos. P30 CA-16042, UL1TR000124-02, and P50 CA211015). Y.L.'s research was supported by the National Natural Science Foundation of China (Grant No. 11801567).
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.