
Abstract
RNA secondary structures are essential abstractions for understanding spacial folding behaviors of those macromolecules. Many secondary structure algorithms involve a common dynamic programming setup to exploit the property that secondary structures can be decomposed into substructures. Dirks et al. noted that this setup cannot directly address an issue of distinguishability among secondary structures, which arises for classes of sequences that admit nontrivial symmetry. Circular sequences are among these. We examine the problem of counting distinguishable secondary structures. Drawing from elementary results in group theory, we identify useful subsets of secondary structures. We then extend an algorithm due to Hofacker et al. for computing the sizes of these subsets. This yields a cubic-time algorithm to count distinguishable structures compatible with a given circular sequence. Furthermore, this general approach may be used to solve similar problems for which the RNA structures of interest involve symmetries.
INTRODUCTION
The RNA secondary structure model is a convenient framework for analyzing and understanding RNA conformations (Mathews, 2006). A secondary structure is a specifically constrained set of paired positions in a sequence. Algorithms to identify optimal structures for given RNA sequences, that is, to “fold” RNA, focused on maximizing the number of paired bases (Nussinov and Jacobson, 1980) and finding minimum free energy secondary structures (Waterman, 1978; Zuker and Stiegler, 1981). Although models of varying intricacies exist, free energy for a secondary structure is typically evaluated as a function of energies associated with bases at paired positions. The algorithm of McCaskill (1990) efficiently computes the partition function for the set of secondary structures, and enables a detailed characterization of equilibrium secondary structural features.
Secondary structures with so-called pseudoknots are biologically relevant, but inclusion of such structures in the analysis dramatically increases its complexity (Akutsu, 2000; Dirks and Pierce, 2003; Rivas and Eddy, 1999).
Most of the algorithmic work on secondary structures has focused on ordinary RNA sequences, that is, strings, but certain variations have also emerged as important. For example, circular RNAs are relevant in studies of certain viruses (Gudima et al., 2004) and viroids (Flores et al., 2004). Although circular RNAs fundamentally differ from ordinary RNA sequences, the usual algorithms can often be adapted by slight modifications to solve corresponding problems on circular sequences. Zuker and Sankoff (1984) and Zuker (1989) established a folding algorithm for circular RNAs. Secondary structures for interacting RNA sequences have also been studied, driven, in part, by applications in biotechnology (Isaacs et al., 2006).
Algorithms to fold multiple interacting RNA sequences have been developed by Dimitrov and Zuker (2004) and Andronescu et al. (2005). Dirks et al. (2007) gave a cubic time algorithm to compute the partition function for a multiset of RNA sequences under restrictions that remain useful in practice.
The core of most RNA folding and partition function algorithms is dynamic programming that exploits properties of substructures. The recurrences for such algorithms closely resemble those for context-free grammars (Sakai, 1961) and may be viewed as variants thereof. In this article, we refer to this type of dynamic programming algorithm as the “standard” dynamic programming for convenience. For ordinary RNA sequences, the secondary structures accounted for by such algorithms all represent physically distinguishable conformations. However, this need not hold for circular RNAs or multiple interacting RNAs. For circular RNAs, if the sequence consists of repeated substrings, different secondary structures may be indistinguishable (Hofacker et al., 2012). Dirks et al. (2007) also observed that secondary structures of interacting RNA sequences can be indistinguishable.
Such indistinguishable secondary structures can lead to redundancy when attempting to count or compute partition functions. Moreover, the extent of such redundancy depends on the symmetry (defined formally below) of each structure (Dirks et al., 2007). Since this symmetry is a global property for any individual secondary structure, the standard dynamic programming schemes, which decompose a problem as independent subproblems, cannot be adapted through local adjustments. Dirks et al. (2007) observed that, in computing the partition function, the above fact does not cause an issue, and had the insight that a symmetry correction to the free energy can compensate for any redundancy. However, redundancy cannot be ignored when counting distinguishable secondary structures. To our knowledge, no efficient algorithm to count distinguishable secondary structures for circular RNAs has been given.
We introduce a general approach to count distinguishable secondary structures on circular sequences. We use a result from group theory to identify certain subsets of secondary structures, the sizes of which are related to the number of distinguishable secondary structures. This allows us to build on an algorithm given by Hofacker et al. (2012), extending it to count distinguishable secondary structures for circular sequences in cubic time, in a model of computation that allows constant time multiplication.
PRELIMINARIES
A circular RNA sequence w is a cyclically ordered multiset of RNA bases {A,C,G,U}. Cyclic ordering implies, for example, that circular sequences spelled  for each
for each
A secondary structure s for w is a set of unordered pairs from
S1. For all
S2. For all
S3. For all
S4. For all
Condition S1 prevents a base from pairing with itself. In practical applications, steric constraints such as
The problem of counting structures for a given circular sequence w is closely related to the partition function problem for ordinary sequences, which can be solved in cubic time (Lyngsø et al., 1999; McCaskill, 1990). We note that, while the last positions for the sequence w is
where
The quantities
Here we lay out the concepts of symmetry for structures over circular sequences, and distinguishability of structures. Our explanation here follows the analogous framework given by Dirks et al. (2007) for particular interacting sequences (which we discuss in Section 5).
We say that circular sequence w has symmetry p if p is the largest integer such that w may be formed by concatenating one string p times. For example, the circular sequence
Nontrivial symmetry in a circular sequence renders some structures indistinguishable. Consider a structure s for circular sequence w of length n and symmetry
for any
Let
Therefore, the orbits induced by
where the stabilizer subgroup of s under the action of
We define the symmetry of a structure s as the size of its stabilizer. Note that the order of the cyclic group

Orbits of different sizes for a circular sequence of symmetry 4 (0 indicates the location of the first site).
That is, we treat each orbit as a distinguishable structure.
Our computational problem is the counting problem defined as follows:
Problem: Distinguishable Count
Input: A circular sequence w of length n and symmetry p.
Question: What is the size of
To our knowledge, there is no efficient algorithm for Distinguishable Count problem in the literature. We provide an efficient algorithm by defining subsets consisting of structures having certain periodic characteristics. We first establish some properties of these subsets and then exploit those properties to design an efficient algorithm for counting distinguishable structures compatible with a circular sequence.
Consider a circular sequence w of length n and symmetry p, and let
where
is the subset of
for any
Hofacker et al. (2012) showed that in a structure with nontrivial symmetry, the pairs can be said to be repeated. More precisely, assume w is a circular sequence of length n and symmetry
Let n, p, g, q, and r be as defined above. When considering structures in
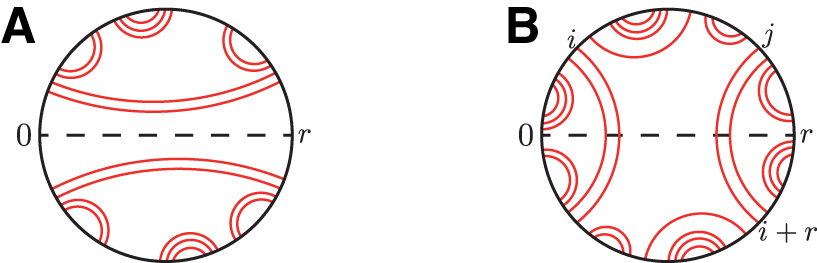
Example secondary structures for circular sequence of symmetry 4.
where substructure
In case (ii), as depicted in Figure 2B, there is a unique external pair
In other words, the structures in
Using Equation (5), we develop an algorithm to solve the Distinguishable Count problem. The pseudocode is shown in Algorithm 1. We state the main result of this work in the following theorem.
Proof. We refer to Algorithm 1. A standard dynamic programming scheme to compute
Analyzing unlabeled sequences is relevant in studying the combinatoric characteristics of structures. Previous studies (Cuesta and Manrubia, 2017; Hofacker et al., 2012) involved enumeration of secondary structures for circular sequences. However, no study has been done on enumerating distinguishable structures.
Waterman (1978) derived a recursion relation for the number of structures compatible with an unlabeled sequence of length n. This removes the burden of ensuring that every pair forms a valid base pair, since this would hold for some sequence. Let
for
We carry out the same analysis on distinguishable structures for unlabeled circular sequences. We define
where
We note that the case of
Dirks et al. (2007) defined a class of pseudoknot-free secondary structures for interacting sequences. In their model, m sequences are concatenated in a given fixed order and treated as a linear sequence along with the locations of the concatenation points. Structures of interest must satisfy S1–S4 as well as a condition involving the concatenation points to ensure the individual sequences are “connected” [see Dirks et al. (2007) for details]. If the concatenated sequence has length n, we define
A key observation by Dirks et al. (2007) is that, if the m sequences involve some that are identical, certain orderings of the sequences may have symmetry. Specifically, the symmetry of the ordering is the greatest divisor p of m such that the concatenated sequence does not change when cyclically shifting the ordering by
for proper divisor g of p, where
In this work, we addressed the problem of counting distinguishable structures for circular RNA sequences, a problem that, to our knowledge, has not yet seen an efficient algorithm. We applied a result from group theory to identify useful subsets, the periodic subsets, of the structures. We then extended the algorithm of Hofacker et al. (2012), applying it to these periodic subsets, allowing us to compute their sizes. This leads to a cubic-time algorithm. We also showed that the developed approach could be applied to count distinguishable structures for unlabeled circular sequences as well as for multiple interacting sequences. While we focused on secondary structures without pseudoknots, the approach laid out here can also be applied to structures with pseudoknots.
Our claim of cubic time assumes that multiplication takes constant time, which is intertwined with restrictions on the magnitudes of numbers and the sizes of their representations. It is well known that for ordinary sequence, the number of secondary structures grows exponentially with sequence length (Waterman, 1978). Since the fastest current algorithm to multiply c-bit integers takes
Since Dirks et al. (2007) first raised the issue of distinguishability, it has not been obvious whether it is possible to efficiency account for the redundancy in standard dynamic programming algorithms for RNA secondary structures. In this study, we answered the above question in the affirmative. We note that another issue, raised by Dirks et al. (2007) regarding the minimum free energy problem in the presence of entropic energy correction, still remains. The challenge stems from accounting for such a global property as symmetry while using a dynamic programming scheme that operates on local problems. We believe that our strategy, building on the works by Dirks et al. (2007) and Hofacker et al. (2012), forms a framework in which one can address the issue regarding the symmetry in secondary structures.
Footnotes
ACKNOWLEDGMENTS
We thank Dr. Guilherme de Sena Brandine and Dr. Amal Thomas for constructive discussions.
AUTHORs' CONTRIBUTION
Both authors wrote, reviewed, and approved the final article.
AUTHOR DISCLOSURE STATEMENT
The authors declare they have no conflicting financial interests.
FUNDING INFORMATION
No funding was received for this article.