
Abstract
Genetic mutations can impact protein–protein interactions (PPIs) in biomedical literature. Automated extraction of PPIs affected by gene mutations from biomedical literature can aid in evaluating the clinical importance of gene variations, which is crucial for the advancement of precision medicine. In this study, a new model called the Gaussian-enhanced representation model (GRM) is introduced for PPI extraction. The model utilizes the Gaussian probability distribution to produce a target entity representation based on the BioBERT pretraining model. The GRM assigns more weight to target protein entities and their adjacent entities, resolving the problem of lengthy input text and scattered distribution of target entities in the PPI extraction task. Additionally, the model introduces a supervised contrast learning approach to enhance its effectiveness and robustness. Experiments on the BioCreative VI data set demonstrate that our proposed GRM model has achieved state-of-the-art performance.
INTRODUCTION
Studying the impact of gene mutations on protein–protein interactions (PPIs) is critical for health professionals and precision medical researchers. Automatic extraction of PPIs affected by gene mutations from biomedical literature is a significant step toward achieving the destination of precision medicine. Recently, BioCreative VI task (Rezarta et al., 2019) organizers released the Precision Medicine (PM) task, consisting of two subtasks: (1) Identifying PPIs affected by genetic mutations in PubMed articles. (2) Extracting PPI affected by genetic mutations. Our research focuses on the second of these subtasks.
This challenging PM task has aroused the interest and participation of many people in the field of natural language processing. At present, a variety of PPI extraction methods have been proposed, which can be roughly divided into template-based method, static machine learning method, and neural network method. The template-based approach (Chen et al., 2017) is a simple method that yields high precision. However, the approach has a low recall rate, and constructing an expert-specific template for a particular field takes time and effort. Statistical machine learning methods (Chowdhuryand Lavelli, 2012; Phan and Ohkawa, 2016; Qian and Zhou, 2012), which include feature-based and kernel-based methods, do not require predefined rules but instead involve manually designing features or core functions to enhance performance. However, this process is labor-intensive and time-consuming.
In recent years, the method based on neural network is popular. PPI extraction is carried out by mapping word sequences to low-dimensional vector space and then learning semantic representation information of word sequences. Chen et al. (2017) used convolutional neural network (CNN) to extract local semantic features and obtained 36.33% F1 score. CNN performs convolution through different convolution kernels to pay more attention to local features. This structure captures the features of local position invariance well but ignores the long-term nature. Wang et al. (2017) used a recurrent neural network (RNN)-based approach to capture long-term structure in sequences while integrating word, entity, and sentence information by using the attention mechanism. Zhou et al. (2018) used memory network for PPI extraction, and the results showed that external memory was superior to long short-term memory (LSTM) with local memory.
However, it still lacks the ability to capture long-term dependencies. Zhou et al. (2020) introduced the knowledge-aware attention network (KAN) to fuse contextual and prior knowledge of protein–protein pairs for PPI extraction. Their approach (Chen et al., 2017; Wang et al., 2017; Zhou et al., 2020; Zhou et al., 2018) achieved the prime performance at the time. However, it is no longer competitive compared with the pretraining model with strong performance. However, Wang et al. (2020) proposed a pretraining model combined with an auxiliary task to improve PPI extraction accuracy, which achieved relatively good performance. However, this approach solely enhanced model performance using ordinary techniques and did not consider the unique features of the PPI task.
The PPI extraction task data set presents a challenge due to the long input text and scattered target protein entities. As shown in Figure 1, target entities one and two are marked in orange and blue, respectively, demonstrating the document's length and degree of entity dispersion. We introduce a Gaussian probability distribution (Guo et al., 2019) to improve the weight of the target protein entity and its neighboring words, which helps capture more semantic information around the entity and enhance the model's feature extraction ability. We assume that words adjacent to the target entity contribute more to semantics than words farther away (Guo et al., 2019). Additionally, we utilize supervised contrastive learning (SCL), which treats samples of the same class as positive examples and those of different classes as negative examples, to reduce intraclass distance and increase interclass distance in the embedded space. This approach helps alleviate the long input text issue in the PPI extraction task.

Example document from protein–protein interaction task data set.
This article proposes a new approach, the Gaussian-enhanced representation model (GRM), for PPI extraction. GRM utilizes the high-quality contextual representation generated by Bert and incorporates Gaussian probability distribution to enhance the weight of target protein entities and their neighboring words in the instance sequence. Additionally, SCL is employed to integrate in-class and interclass examples to facilitate PPI extraction. Finally, the concatenated representations are fed into the Softmax function for PPI extraction. The main contributions of this study are as follows:
Our proposed approach, GRM, addresses the challenges of PPI extraction in the biomedical field, where the input is often lengthy, and the target entity is scattered. GRM leverages the Gaussian probability distribution to enhance the weight of the target protein entity and its neighbors, which improves the model's ability to extract relevant semantic information. Additionally, we integrate SCL to enhance the model's effectiveness and robustness in identifying PPIs affected by gene mutations. Experimental results on the BioCreative VI precision medicine track corpus demonstrate that GRM performs state-of-the-art PPI extraction.
This section will briefly overview the literature in two main areas: PPI extraction task and contrast learning method.
PPI extraction task
Biomedical relation extraction can be classified into three categories: template-based, statistical machine learning-based, and neural network-based. Similarly, PPI extraction can also be categorized into three methods as a subset of biomedical relationship extraction. Two template-based methods (Chen et al., 2017; Huang et al., 2004; Krallinger et al., 2011; Sun et al., 2016) have been proposed to extract PPI. Huang et al. (2004) applied dynamic programming to calculate discrimination patterns by aligning related sentences and key verbs describing protein interactions, whereas Chen et al. (2017) used an easy rule-template-based co-occurrence strategy. However, template-based methods require time-consuming domain-specific templates that depend on experts to develop.
Statistical machine learning methods eliminate the need for domain experts, thus improving upon template-based approaches. Phan and Ohkawa (2016) combined different features in a feature-based approach, including vocabulary context features, syntactic features, and automatic extraction of PPI feature from existing patterns. Qian and Zhou (2012) proposed a tree core-based PPI extraction method that uses the shortest dependent path between two proteins. However, the manual design of features or cores is still necessary and time-consuming for statistical machine-learning methods.
Deep learning relies on neural networks to automatically learn features from data, reducing the need for manual feature engineering required in statistical machine learning methods. Zhou et al. (2020) proposed a KAN, which integrates the prior knowledge of protein pairs with context information and obtains the knowledge perceived dependence between different words in the sequence through multiple attention mechanism for PPI extraction. Peng and Lu (2017) used a CNN model based on multichannel dependence (McDepCNN). It applies one channel to the embedding vector of each word in the sentence and another channel to the embedding vector model of the corresponding word header to get richer information from different channels. Wang et al. (2020) combined the pretraining model with the multitasking strategy to conduct PPI extraction.
They used BioBERT to obtain text representation and adopted the multitasking learning strategy to improve performance. Tang et al. (2022) proposed a semi-supervised PPI extraction method using knowledge distillation and virtual adversarial training. This approach improved the model's ability to learn from text features and better used large amounts of unlabeled data through virtual adversarial training, which enhanced semi-supervised learning. Li et al. (2021) proposed a multigranularity semantic fusion method that supports biomedical relationship extraction for PPI extraction. Transformer integrates global semantic representation and local semantic representation to enhance the recognition ability of neural network.
Contrast learning method
Contrast learning is an epidemic unsupervised representational learning method. It was first introduced by Hadsell et al. (2006) with the Dimensionality Reduction by Learning an Invariant Mapping approach that maps similar inputs to approximate points in the representation space. He et al. (2020) used a contrast learning method called Momentum Contrast (MoCo) for unsupervised visual representation learning. In this method, momentum updating is used to build a dynamic dictionary in the learning process to use the information in the unlabeled data better. By introducing some negative samples into the dynamic dictionary, the MoCo method can adaptively increase the difficulty during the training process, thus improving the quality of the representation.
Chen et al. (2020) used contrast learning to learn visual representations and proposed a simple and efficient contrast learning framework, SimCLR. The framework constructs positive samples from multiple perspectives and negative samples from different image perspectives and uses special data enhancement techniques to enhance the learning process. The framework also uses nonlinear transformation and contrast loss functions to optimize the model, achieving excellent performance on multiple visual tasks. Zhu et al. (2022) proposed a simple and effective framework for visual relationship prediction, which transferred the natural language knowledge learned from the Contrast language-Image Pretraining model to enhance relationship prediction. Exploring visual-semantic alignment at the relational level by learning to match cross-modal relational embedding enables models to generate more discriminative and robust representations.
Wu et al. (2022) proposed a novel peer-to-peer contrast learning with multiple extensions, which constructs different positive and negative comparisons for unsupervised sentence embedding at the group level, making the model capable of both peer-to-peer positive comparison and peer-to-peer network cooperation, which is an effective way to learn from multiple enhancements. Chen and He (2021) proposed a novel contrastive learning algorithm called SimSiam (Simple Siamese Representation Learning) for learning image representations using a self-supervised strategy. It learns shared features by predicting the representation vectors of two views of the same image, with one representation vector as the target for prediction. Caron et al. (2020) proposed a contrastive learning algorithm called Swapping Assignments between Views for learning image representations using clustering and assignment swapping. It groups images with a clustering algorithm and constructs positive and negative pairs using the view-swapping strategy.
Additionally, contrastive learning has been applied to supervised learning. Wang et al. (2022) proposed a graph-based supervised contrast learning method called ClusterSCL. This method aims to learn node representation so that nodes in the same cluster are closer to each other in the feature space and nodes between different clusters are more dispersed in the feature space. ClusterSCL uses clustering algorithms to divide nodes into clusters and uses these clusters to construct positive and negative sample pairs. Meanwhile, the weight difference among different clusters is considered to optimize the contrast loss function further. Prannay et al. (2020) proposed an SCL method. This method uses label data to construct positive and negative sample pairs so that sample pairs of the same category are closer in the feature space and sample pairs of different categories are more dispersed in the feature space.
The model can learn more discriminative feature representations by minimizing the contrast loss of these sample pairs. Chi et al. (2022) realized the equal probability of text classification by contrast learning. They first theoretically analyzed the connection between the learning representation with fairness constraint and the comparison objective of conditional supervision and then used the fair representation in the text classification of conditional supervision comparison objective learning. Chen et al. (2022) proposed a new contrast learning framework based on expectation maximization algorithm, which makes maximum use of the internal structure of multimodal data and adaptively improves target prediction by using phrase object contrast loss without positive comments. GRM can achieve nice improvements in PPI extraction by increasing accuracy.
Chen et al. (2020) proposed a supervised learning method called Contrastive Multiview Coding for contrastive learning using multiview data. It uses different views of the same sample as positive samples and views of different samples as negative samples, trained with a cross-entropy (CE) loss function. Gunel et al. (2020) used contrastive learning to improve the fine-tuning process of pretrained language models. They employed a contrastive loss function to compare the representations of a positive sample and a negative sample and adjust these representations to be more discriminative, making the model more suitable for downstream tasks.
METHODOLOGY
This section summarizes the Methods, which can be classified into two main classifications: PPI extraction task and GRM.
PPI extraction task
We define PPI extraction as a two-class classification problem, aiming to detect PPI relation between protein–protein pairs in a given set of PubMed Unique Identifier (PMID) documents. This task is evaluated using the “PPI” type in the BioCreative VI Precision Medicine Track corpus. The classification problem is determining if a PPI relationship exists between a pair of target proteins in a set of PMID documents, which can be formulated as a binary classification problem. Specifically, given the input text 
Gaussian-enhanced representation model
Figure 2 illustrates the overall structure of GRM. It inputs document-level instances and extracts their features using BioBERT to obtain a high-quality context representation. The Gaussian probability distribution is applied to enhance the weight of the target entity and its adjacencies in the representation, resulting in an improved representation of related entities. The Gaussian-enhanced representations of the target entities are concatenated with the BioBERT representation of the input instance to obtain a fusion representation. The model is trained using supervised contrast loss (SCL) and CE loss, and the Softmax function is applied to the fusion representation to extract PPI in the inference phase. Each component of the model is explained in detail below.

Gaussian-enhanced representation model.
Pretraining models have been widely accepted in natural language processing (NLP) due to their effectiveness in various tasks. BioBERT has been found to outperform a pre-trained language model (BERT) in biomedical text mining tasks such as named entity recognition (NER) and relation extraction (RE), according to a previous study (Lee et al., 2019). Therefore, we utilized BioBERT for the RE task to obtain the input text representation. Our input text is a document similar to Figure 1, and the representation of input text is denoted as
Gaussian-enhanced module
We utilize the Gaussian probability distribution in our model to enhance the weight of the target protein entity and its neighboring words, allowing the model to learn semantic information in the proximity of the target entity. The Gaussian probability density function used is:
the Gaussian cumulative distribution function is:
the Gaussian probability distribution function is:
where

where x1 and x2 represent the relative distance list of tokens, ui is the token representation of the instance,
The contrastive learning compares the input of the same categories and the input of different class to distinguish semantic features. Positive samples refer to the information of the same type, whereas negative samples refer to the input of other types. In the training process, input representations are learned by guiding positive samples with similar representations and making negative samples with different representations so that similar representations are closer together and other representations are further apart in the embedding space. Our method employs the CE loss function as the prime function for dealing with the classification problem. To further improve the model's ability to extract PPI, we also utilize the supervised contrastive loss function proposed by Khosla et al. (2020). This loss function distinguishes semantic features by using positive and negative samples. The positive sample contains instances of the same category, whereas the negative sample contains instances from other categories in the batch. The multiclass CE loss is defined as:

where N is a batch of training samples,

where hi is the concatenated fusion representations
where
Data set
The experiment used the BioCreative VI Precision Medicine Track Corpus (Rezarta et al., 2019), and only the subtask 2 PPI extraction data set was used in this study. The training set contained 1729 PPI-related articles, and the test set contained 704 articles, as shown in Table 1. The protein entities in the training and test sets were annotated using GNormPlus toolkits1 (Wei et al., 2020) and normalized to Entrez Gene ID.
Statistics of Data Set
Statistics of Data Set
PPI, protein–protein interaction.
For PPI extraction tasks, BC6PM organizers provide two evaluation indicators: (1) Exact Match: The prediction relationship counts only if the GeneID is the same as the GeneID of the human annotation. (2) HomoloGene Match: As long as the predicted gene identifiers are homologous with artificially annotated gene identifiers, this relation is considered correct. Since the first method is more accurate and can exclude cases of homologous but inconsistent gene IDs, only the first assessment method is selected in this article and the official assessment script is used.
To enable the model to classify gene pairs, we utilized Tran and colleagues' text substitution method (Tran and Kavuluru, 2017). When a PPI was linked to only one gene ID, references to the involved gene were replaced with “gene A” and “gene B” or “gene S,” whereas other references were replaced with “gene N.” Our deep neural network model was implemented using the PyTorch framework, with BioBERT (Lee et al., 2019) serving as the text embedding layer. We employed the Adam algorithm with various learning rates to train the BioBERT embedded layer and the downstream layer of the model. During training, we utilized cross-validation to choose suitable hyperparameters. The hyperparameter configurations are presented in Table 2.
Hyperparameter
Hyperparameter
SCL, supervised contrastive learning.
We compared the GRM method with other PPI model methods, and the results are as follows:
Rule template-based approach (Chen et al., 2017): This approach proposes a method for document triage and relation extraction for PPIs affected by mutations. The method involves a combination of machine learning techniques, including a CNN for sentence classification, NER for identifying protein entities, and a rule-based system for extracting relations between proteins. The proposed approach is evaluated on a corpus of biomedical literature and achieves promising results in both document triage and relation extraction tasks.
Deep learning method based on CNN (Tung and Ramakanth, 2018): This method proposes an end-to-end deep learning architecture for extracting PPIs affected by genetic mutations. The approach involves using a CNN to extract features from sentences and an RNN to model protein interactions. The model is trained on a corpus of scientific literature and evaluated on a benchmark data set. Results show that the proposed architecture outperforms existing methods for PPI extraction, particularly in cases involving genetic mutations.
KAN (Zhou et al., 2018): This model uses a deep learning architecture called the KAN for extracting PPI information from biomedical texts. The architecture uses self-attention mechanisms to focus on words related to protein interactions in text and previously trained language models, and domain knowledge maps to improve the model's performance.
Pretraining model method based on BioBERT (Wang et al., 2020): This method uses the auxiliary task and pretraining domain model to extract protein interaction relationships affected by a gene mutation. An additional task was added to the model to help it learn better feature representations by predicting the functional effects of mutated proteins. At the same time, the pretraining domain model is used to initialize the model's parameters to improve the performance and generalization ability. Finally, the effectiveness and superiority of the proposed method are demonstrated by experiments on several data sets.
All methods, including GRM, used the GNormPlus toolkit for gene identification and normalization. The performance indicators were calculated based on accurate matching to ensure a fair comparison. Table 3 shows that GRM outperformed BioBERT-RC-only (Wang et al., 2020) without the auxiliary task, with an improvement of 1.84% in the F1 score. GRM also outperformed the KAN model (Zhou et al., 2020), with an increase in the F1 score of 5.29%, demonstrating its effectiveness.
Performance Comparisons on Protein–Protein Interaction
CNN, convolutional neural network; GRM, Gaussian-enhanced representation model; KAN, knowledge-aware attention network.
To compare with Wang et al.'s (2020) work, we applied additional tasks to the training process based on GRM. As shown in Table 4, adding the NER task slightly decreased the F1 score by 0.25% compared with BioBERT RC+NER (Wang et al., 2020). Adding a Triage task increased the F1 score by 0.62% compared with BioBERT RC+Triage (Wang et al., 2020). These results demonstrated that GRM outperformed Wang et al.'s model (Wang et al., 2020) by adding a multitask strategy. However, the F1 score of GRM with the addition of a multitask strategy was not as good as that of our proposed model without a multitask strategy. This indicates that the multitask strategy only benefits specific models but not all.
Performance Comparisons on Protein–Protein Interaction (+Auxiliary Task)
NER, named entity recognition.
In this section, we discuss the impact of each component of GRM. First, we evaluated the model without the Gaussian-enhanced module while retaining the BioBERT and SCL parts. Table 5 shows that the F1 score decreased by 1.16%, demonstrating the effectiveness of the Gaussian-enhanced module. Second, we evaluated the model without the SCL part while retaining the BioBERT and Gaussian-enhanced modules. Table 5 shows that the F1 score decreased by 0.61%, indicating that the SCL part also positively impacts GRM. These results suggest that the Gaussian-enhanced module and SCL are beneficial for PPI extraction and are complementary to each other. Third, we change the pretraining model from BioBERT to Bert-BASE-uncased (Devlin et al., 2018).
Ablation Study Results
Ablation Study Results
GRM-mp denotes mean pooling within the target entity local window.
According to Table 5, compared with GRM, F1 score decreased by 0.3. This shows that BioBERT is more effective than general Bert for biomedical tasks. To investigate the impact of Gaussian probability distribution on the model, we conducted an experiment where we replaced the Gaussian probability distribution with mean pooling within the target entity's local window. As a result, the F1 score decreased by 0.72%. These experimental findings confirm the importance of using Gaussian distribution.
As can be seen from Table 6, the true positive number of the GRM model is slightly lower than that of the BioBERT RC-only (Wang et al., 2020) model. An interesting finding is that among the false positives, the false-positive number of GRM is much lower than that of the BioBERT RC-only (Wang et al., 2020) model, and the false-negative number is higher than that of the BioBERT RC-only (Wang et al., 2020) model, which indicates that the GRM model is superior to BioBERT RC-only model in accuracy, but it loses a certain recall rate.
Results on Test Data of Different Models
Results on Test Data of Different Models
In this study, we conducted a detailed analysis of the GRM model's advantages and disadvantages by selecting two articles from the PPI data set, as shown in Figure 3. We compared the prediction results of BioBERT RC-only (Wang et al., 2020) and GRM. In Case 1, the BioBERT RC-only model produced a false-positive prediction, whereas GRM correctly predicted a true negative when the ground truth was negative. This shows that the GRM model effectively improves the PPI extraction effect. In Case 2, if the ground truth is positive, BioBERT RC-only produced a true-positive prediction, whereas GRM produced a false-negative (FN) prediction. The Gaussian probability distribution enhancement module in the GRM model plays a limited role in this case since the target entity is a single entity.
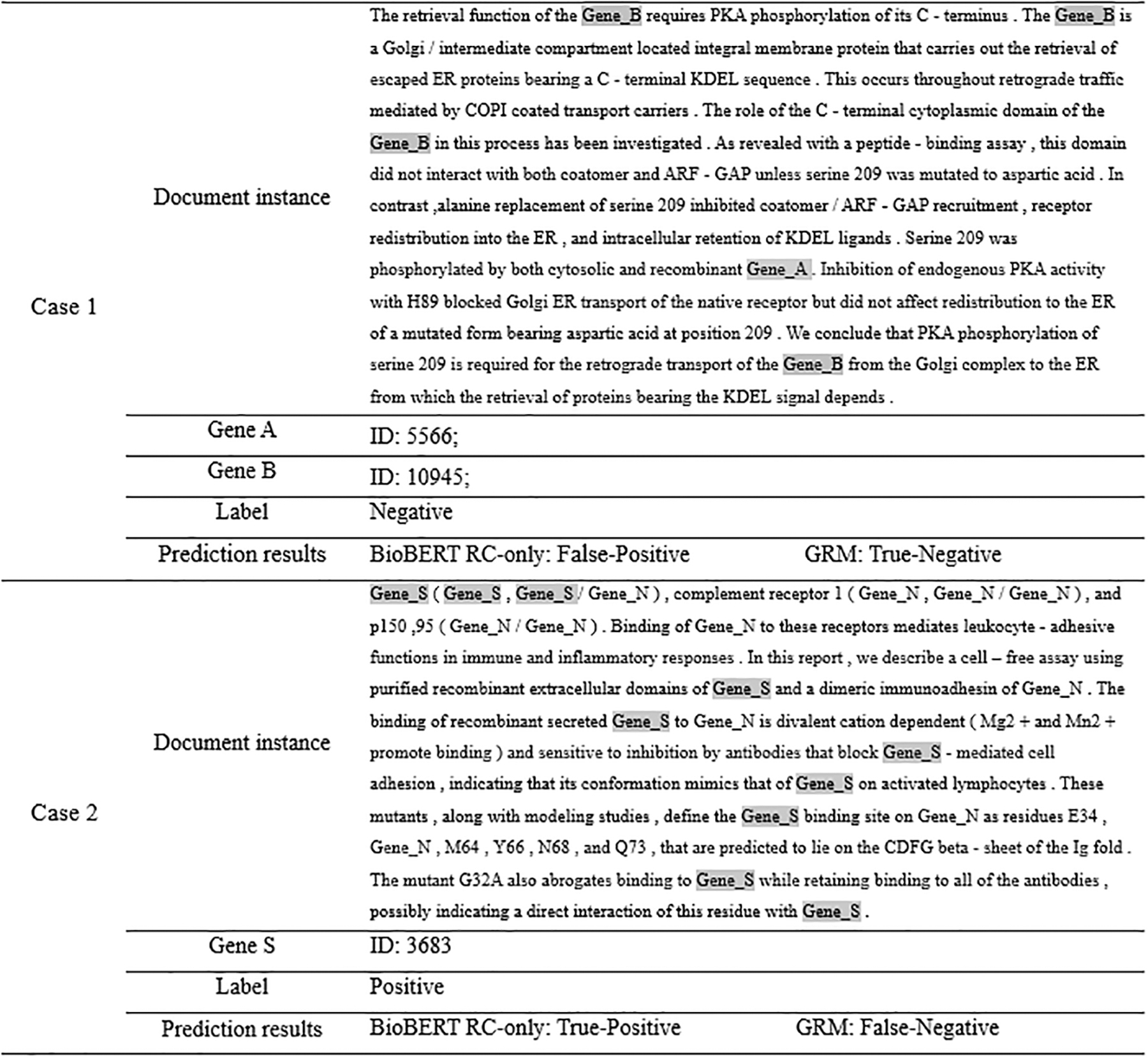
Case study.
To demonstrate the effect of Gaussian probability distribution, we extract and visualize the attention weights of different words. The visualization results are shown in Figure 4. We have identified the target entity pairs Gene_A and Gene_B at the corresponding locations from the input document in Figure 1. The scale value on the right corresponds to the probability value of different colors. The darker the color, the greater the attention weight of the corresponding word.
Visualization of Gaussian probability distributions around entities.
We used our proposed model to predict entity pairs Gene_A and Gene_B in the document in Figure 1 and judged them as true positive, that is, PPI relationship of entity pairs was correctly predicted.
However, after removing the Gaussian-enhanced module from the model, the prediction result is FN, indicating that the prediction is incorrect. Results show that the our proposed model not only improves the weight of the target protein entity and its adjacent words but also improves the prediction ability of the model, which proves the benefit of the Gaussian probability distribution to the pretraining model.
In this article, we introduce a new model for enhancing PPI extraction, which includes the Gaussian probability distribution and SCL. Our proposed model achieved state-of-the-art performance through experiments on the BioCreative VI precision medicine track corpus (43.57% in F1 score). Ablation experiments confirmed the effectiveness of the Gaussian probability distribution and SCL for the pretraining model.
The primary limitation of this study was that only 56% of genetic pairs were identified using the GNormPlus toolkit. Future work will address this limitation by exploring the upstream task of relational classification; improving the F1 value for the PPI task requires this as a prerequisite. Additionally, to address the current task's limitations, we will incorporate attention mechanisms at the sentence level and retain Gaussian probability distribution at the word level for modeling. The model can capture more crucial semantic information in different sentences and words by doing so.
Footnotes
AUTHORs' CONTRIBUTIONS
D.L. performed experimental method design, writing—original draft and conceptualization. M.Y., J.Y., and W.Q. performed writing—review and editing. Y.Z. provided suggestions and feedback. All authors have read and approved the final article.
AUTHOR DISCLOSURE STATEMENT
The authors declare they have no conflicting financial interests.
FUNDING INFORMATION
This work is supported by grant from the Natural Science Foundation of China (grant No. 62072070).