
Abstract
The analysis of cancer data from multi-omics can effectively promote cancer research. The main focus of this article is to cluster cancer samples and identify feature genes to reveal the correlation between cancers and genes, with the primary approach being the analysis of multi-view cancer omics data. Our proposed solution, the Multi-View Enhanced Tensor Nuclear Norm and Local Constraint (MVET-LC) model, aims to utilize the consistency and complementarity of omics data to support biological research. The model is designed to maximize the utilization of multi-view data and incorporates a nuclear norm and local constraint to achieve this goal. The first step involves introducing the concept of enhanced partial sum of tensor nuclear norm, which significantly enhances the flexibility of the tensor nuclear norm. After that, we incorporate total variation regularization into the MVET-LC model to further augment its performance. It enables MVET-LC to make use of the relationship between tensor data structures and sparse data while paying attention to the feature details of the tensor data. To tackle the iterative optimization problem of MVET-LC, the alternating direction method of multipliers is utilized. Through experimental validation, it is demonstrated that our proposed model outperforms other comparison models.
INTRODUCTION
Nowadays, cancer represents one of the most severe life-threatening hazards for individuals. Currently, there are many sequencing technologies, through which a large amount of cancer sequencing data have been generated. The exploration of cancer genomics data can provide powerful support for tumor prediction, diagnosis, and treatment. The existing work (Liao et al., 2003) indicates that few genes play a significant role in biological processes. As a result, it is essential to discover the genes that affect biological processes.
Many models have been used in biological data analysis, such as robust principal component analysis (RPCA) (Liu et al., 2014). It divides the observational data into low-rank and sparse. In some works (Bouwmans et al., 2018; Vaswani et al., 2018), nuclear norm minimization is a convex relaxation with rank minimization because rank minimization is discontinuous and non-convex. Then, Oh et al. (2016) pointed out that the nuclear norm can cause some errors. So partial sum of singular values (PSSV) is used to solve this problem (Oh et al., 2016).
In practical application, multidimensional data are ubiquitous. High-dimensional magnetic resonance imaging enables the imaging of unknown lesions to be detected more efficiently and earlier. He et al. (2016a) applied low-rank tensors to sparse sampling and reconstruction of medical images. In the field of biology (Hu et al., 2019), feature factor selection using tensor robust principal component analysis (TRPCA) was first introduced by Hu et al. (Yu et al., 2019). A method called t-product-based sparse regularization tensor robust principal component analysis (t-STRPCA) was proposed to select feature genes, and the clustering of biological data samples has proved to be meaningful (Yang et al., 2020). Zhao et al. (2020) defined a low-rank weighted model based on the tensor framework for tumor genomics sample clustering, which is conducive to disease prevention and treatment. In addition, in literature (Zhao et al., 2021), a new model, hypergraph regularized tensor robust principal component analysis (HTRPCA), is used to preserve the complex geometric information between multiple samples.
A new model, called outlier-robust tensor principal component analysis (OR-TPCA), has been introduced for addressing tensor-related problems (Zhou and Feng, 2017). OR-TPCA can detect outliers better than TRPCA and can provide a more accurate recovery of tensor subspace. Braman (2010) and Kilmer and Martin (2011) are the first to mention tensor singular value decomposition (T-SVD), which allows for the extension of matrix operations to tensor operations while suppressing the absence of inherent information caused by flattening the tensor. However, T-SVD may have some inevitable deviations. Liu et al. (2018) showed that the tensor low-rank signal remains in the core tensor acquired by singular value decomposition.
Liu et al. proposed improved robust tensor principal component analysis (IRTPCA). In fact, T-SVD minimizes all singular values simultaneously with the same strategy, resulting in a rank less than the target rank (Oh et al., 2013; Vaswani et al., 2018). Recently, the weighting strategy mentioned in Gu et al. (2014), Hosono et al. (2016), and Peng et al. (2014) is meaningful. Using the prior knowledge that the larger singular value contains the main information to compress each singular value to different degrees, generalizing nuclear norm. Furthermore, the utilization of the partial sum of tensor nuclear norm (PSTNN) has become increasingly prevalent based on the research concepts presented in Gu et al. (2014), Jiang et al. (2020), Oh et al. (2016), and Zhang and Peng (2019).
Building upon the theoretical background, we introduce a novel tensor nuclear norm (TNN) called the enhanced partial sum of tensor nuclear norm (EPSTNN). EPSTNN incorporates the first N singular values, preventing issues of rank deficiency. In addition, we apply total variation (TV) regularization (He et al., 2016b; Sun et al., 2019; Wang et al., 2018) to enforce constraints on the low-rank component. The following are the contributions of our study:
A new model, Multi-View Enhanced Tensor Nuclear Norm and Local Constraint (MVET-LC), is proposed to effectively perform feature gene selection and clustering experiments on multi-view cancer data sets. EPSTNN is introduced to enhance the ability of MVET-LC to distinguish between the relative significance of internal data information, resulting in its capability to effectively extract low-rank structures from multiview data. TV regularization is integrated into MVET-LC to constrain the low-rank component, equipping the model with a better ability to capture the finer details of the internal data structures.
Tensor preliminaries
In this article, we adopt Euler notation to represent tensors, for example, 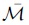 denotes the Fourier transformed tensor of tensor
denotes the Fourier transformed tensor of tensor
where

Although the minimization problem of TNN can be easily solved, it treats all singular values equally. However, large singular values are closely related to vital information, and they should be subject to more minor penalties to ensure that information is not lost or destroyed. Therefore, PSTNN has been proposed to approximate the rank (Jiang et al., 2020; Zhang and Peng, 2019), as follows:

where
TNN treats all singular values equally. However, large singular values should be subject to more minor penalties to ensure that information is not lost or destroyed. We propose a new nonconvex proxy EPSTNN. EPSTNN orders the singular values of the first N according to their magnitudes and assigns weights to them. Generally, the larger singular values are related to the main projection direction, so the weights of the larger values should be increased to reduce the shrinkage of the values. Figure 1 is a diagram of EPSTNN. EPSTNN expands the difference of internal structure information, which is conducive to the accurate retention of necessary data, as follows:

Illustrations of enhanced partial sum of tensor nuclear norm.
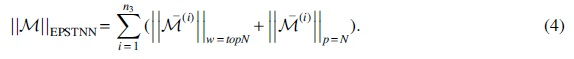
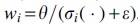 .
.
To solve the minimization problem based on EPSTNN, the enhanced partial sum of the singular value thresholding operator
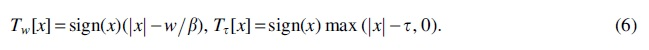
It has been mentioned in Hu et al. (2019) and Liu et al. (2013) that low-rank and sparse tensors can be obtained from original observation tensor, in which the sparse tensor data are regarded as important genes so that feature genes can be extracted from the sparse data. To achieve high accuracy in the feature genes extraction from cancer data, TV is introduced in this article. The definition of TV is as follows:

Let
Advances in sequencing technology have allowed more gene expression data to be detected. These gene expression data contain a lot of meaningful biological information. Some genomics data are close to some low-dimensional subspaces (Bartenhagen et al., 2010; Bertoni and Valentini, 2005; Liu et al., 2014; Liu et al., 2013). To take into account the internal structure of the subspace in cancer omics data and to accurately extract feature data, we propose a data processing model called MVET-LC.
Through the use of alternating direction method of multipliers, we can transform Equation (10) into the following form:
Next, we decompose Equation (11) into multiple subproblems to solve iteratively. Algorithm 1 outlines the iterative solution process for MVET-LC (Table 1).
Solving Multi-View Enhanced Tensor Nuclear Norm and Local Constraint by Alternating Direction Method of Multipliers
Update
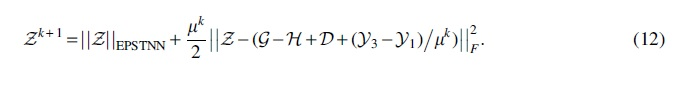
Update
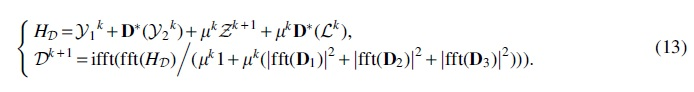
Update
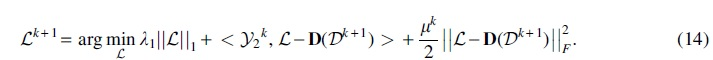
Update
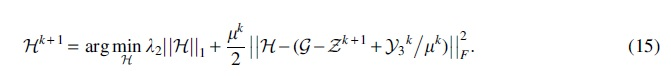
In Algorithm 1, the main time cost of MVET-LC is the update of
Some genomics data are close to low-dimensional subspaces, so the low-rank tensor
The proposed model, MVET-LC, is applied to multiview data for feature selection and clustering experiments. The framework of MVET-LC is illustrated in Figure 2. RPCA (Oh et al., 2016), TRPCA (Lu et al., 2016), the model by Lu et al. (2020) (referred to in this article as T-TRPCA), OR-TPCA (Zhou and Feng, 2017), IRTPCA (Liu et al., 2018), PSTNN (Zhang and Peng, 2019), and EPSTNN (in this article) are chased as comparison models.
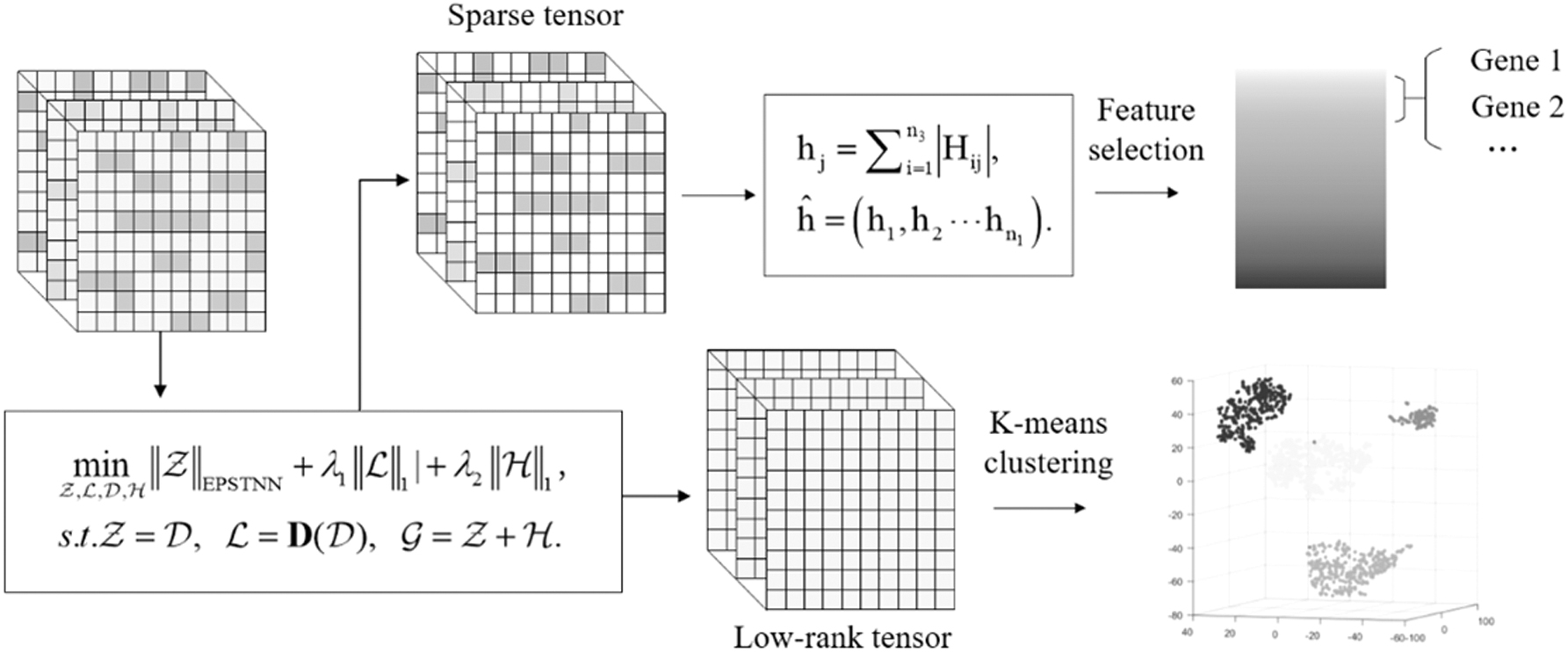
The framework of the Multi-View Enhanced Tensor Nuclear Norm and Local Constraint model.
Using 12 different types of cancer data from the TCGA website, including pancreatic adenocarcinoma (PAAD), cholangiocarcinoma (CHOL), colon adenocarcinoma (COAD), esophageal carcinoma (ESCA), head and neck squamous cell carcinoma (HNSC), stomach adenocarcinoma (STAD), rectum adenocarcinoma (READ), liver hepatocellular carcinoma (LIHC), lung adenocarcinoma (LUAD), uterine corpus endometrial carcinoma (UCEC), cervical squamous cell carcinoma and endocervical adenocarcinoma (CESC), and uterine carcinosarcoma (UCS), three data sets (SRLL, PCCEH, and UCU) were obtained. As shown in Figure 3, the three dimensions in the three-dimensional tensor data set represent genes, data types, and samples. Feature selection and clustering experiments were then performed on these multiview data sets using the MVET-LC framework.

Schematic diagram of tensor cancer genomics data.
SRLL is the combination of STAD, READ, LIHC, and LUAD, PCCEH is the combination of PAAD, CHOL, COAD, ESCA, and HNSC, and UCU is the combination of UCEC, CESC, and UCS. Table 2 lists the detailed information.
Descriptions of the Data Sets
We use the aforementioned models to extract feature genes from multiview data and compare and analyze the extraction results. First of all, according to Hu et al. (2019), we sort the genes extracted from each model according to the gene relevance score (GRS). Generally, genes with higher correlation scores have a greater impact on tissue lesions. We selected the top 500 genes and searched for them on the GeneCards website for further analysis.
Figure 4 presents the top genes selected by the models with GRS in the three data sets and their corresponding average values. HRS and ARS denote the highest GRS and the average GRS, respectively. HRS can reflect whether an algorithm can effectively select the most effective key genes. ARS represents the average GRS value of the selected genes. Therefore, ARS reflects the overall quality of the selected genes. In contrast, HRS represents the gene with the highest GRS value, indicating the most significant gene in the feature selection process. Thus, MVET-LC can effectively select key genes with high GRS values (HRS high). In other words, some other genes not proved to be pathogenic extracted by MVET-LC may be associated with cancers, which provides a new path for tumor analysis.

The results of extraction of feature genes.
Table 3 shows the top two genes selected by the MVET-LC model with the highest GRS in each data set. We then focused on the relationship between the SMAD4 gene and the SRLL data set.
The Top Two Genes with the Highest GRS Are Selected in Each Data Set
SMAD4 is classified as a tumor suppressor gene (Howe et al., 2002). Researchers found that selective deletion of SMAD4 in T cells can lead to carcinogenesis in the gastrointestinal tract of mice (Kim et al., 2006). Therefore, SMAD4 signaling in T cells is necessary to inhibit gastrointestinal tumors. A recent study by Jiang et al. (2019) investigated the association between BRAF and SMAD4 mutations and resistance to neoadjuvant chemoradiotherapy in patients with locally advanced rectal cancer.
SMAD family of genes are candidate tumor suppressor genes in LIHC (Yu et al., 2016). SMAD4 was found to be commonly mutated through genome sequencing of lung tumors in patients diagnosed with squamous cell carcinoma (Liu et al., 2015). According to Bian et al. (2015) the prognosis of patients with LUAD can be predicted based on the immunohistochemical status of P53Mut, P16, and SMAD4. Through case analysis, we prove that the genes selected by the MVET-LC model have biological significance.
Clustering analysis of multiview cancer samples is beneficial for finding potential correlation and complementarity information in complex data. Also, it can provide support for the study of the similarity among cancers and the discovery of new cancer subtypes. The evaluation metrics used are as follows: accuracy (ACC), normalized mutual information (NMI), F-measure (F-M), and adjusted Rand index (ARI).
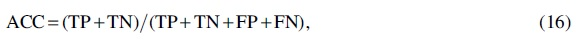
We have
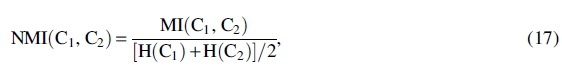
where
F-M is defined as

ARI is defined as
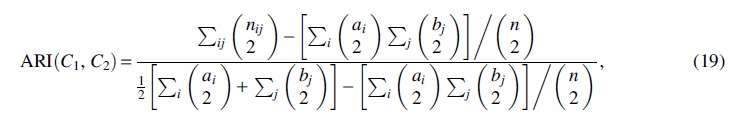
where ai and bj are the number of samples in class
Table 4 and Figure 5 show the results of the aforementioned models on the three data sets. To show the experimental results more intuitively, we visualized the clustering results of the MVET-LC model in Figure 6. Different colors represent different diseases in the data sets.
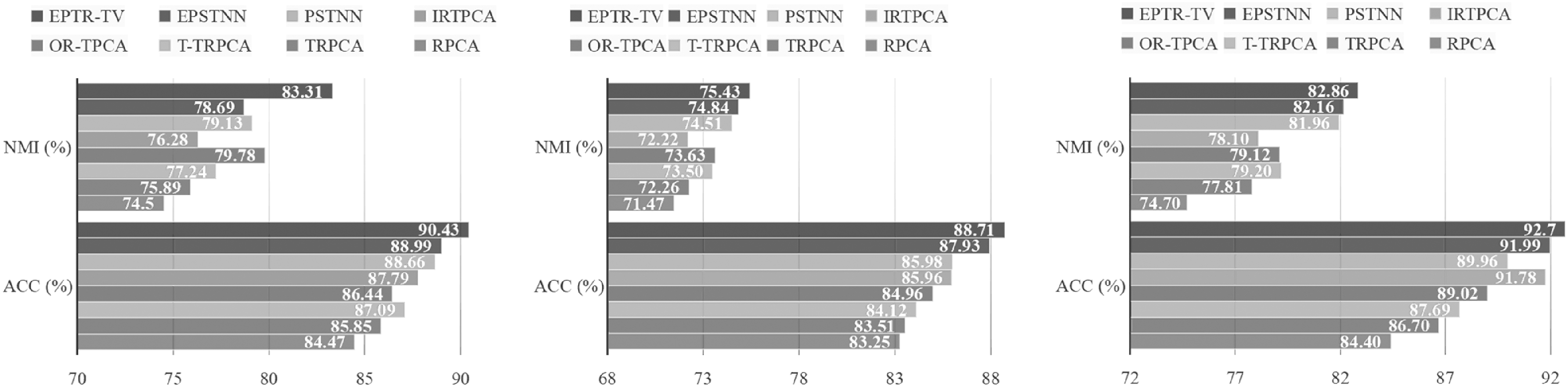
The clustering outcomes for the SRLL, PCCEH, and UCU data sets.
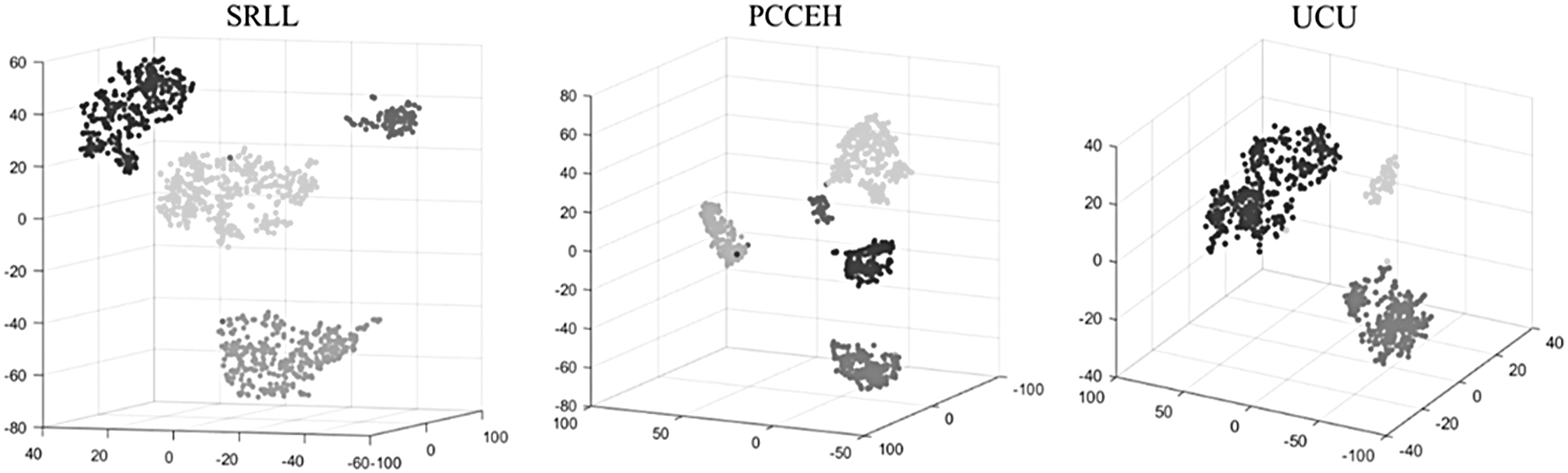
Visualization of clustering effect.
The Results of the Models on the Three Data Sets
Bold values show the best results.
ARI, adjusted Rand index; EPSTNN, enhanced partial sum of tensor nuclear norm; F-M, F-measure; IRTPCA, improved robust tensor principal component analysis; MVET-LC, Multi-View Enhanced Tensor Nuclear Norm and Local Constraint; OR-TPCA, outlier-robust tensor principal component analysis; PSTNN, partial sum of tensor nuclear norm; RPCA, robust principal component analysis; TRPCA, tensor robust principal component analysis;
The specific analysis and discussion are as follows:
Table 4 shows that the matrix model RPCA has a lower accuracy by at least 1% compared with the tensor data analysis models. This phenomenon may be because RPCA destroys the geometric structure information of three-dimensional data when processing multiview cancer genomics data. It also fails to effectively detect the outliers by matrix or flattening the data. However, tensor methods can avoid the aforementioned problems and concentrate on dealing with multiview data.
In general, the experimental outcomes obtained from EPSTNN and the approach built on EPSTNN (MVET-LC) are superior to those from PSTNN and models constructed based on TNN (TRPCA, T-TRPCA, OR-TPCA, and IRTPCA). EPSTNN is exploited to widen the discrimination between the data. Data with different information can be identified more clearly, which increases the probability of discovering new cancer subtypes. Meanwhile, EPSTNN can enhance the precision of low-rank structures extraction, thereby facilitating the identification of genes that are more closely linked to cancer.
MVET-LC with TV has the advantage of preserving the spatial structure of multiview data sets compared with other models. Meanwhile, due to the addition of TV item, MVET-LC pays more attach to the local features easily overlooked in the data. In Table 4 and Figure 5, the comprehensive evaluation index shows that MVET-LC is satisfactory.
Our research has presented a new model, MVET-LC, designed specifically for the analysis of cancer data. EPSTNN is utilized in this model to capture complex internal structures of the data, whereas TV is added as a constraint term for the low-rank tensor to preserve local features. Our experiments have shown that the MVET-LC model performs better than other models.
In the future, our research will continue to focus on the analysis of multiview cancer data, with particular emphasis on low-rank structure extraction and sparse component separation.
Footnotes
AUTHORs' CONTRIBUTIONS
Writing—review and editing (equal) by Q.Q., S.-S.Y., and J.S. Writing—review and editing (lead) by J.-X.L.
AUTHOR DISCLOSURE STATEMENT
The authors declare they have no conflicting financial interests.
FUNDING INFORMATION
This study was supported in part by the National Natural Science Foundation of China under Grant Nos. 61872220 and 62172254.