
Abstract
Source code implementing our cutting-plane algorithm for shortest hyperpaths is available free for research use in a new tool called
Mmunin.
INTRODUCTION
Signaling and metabolic pathways are cornerstones of systems biology. They underlie cellular communication, govern environmental response, and their perturbation has been implicated in the causes of disease (Li et al., 2020). Networks comprised of these pathways are traditionally represented as ordinary graphs (Sharan and Ideker, 2006; Vidal et al., 2011), modeling each molecule as a vertex, and each reaction by a collection of edges directed from each of its reactants to each of its products. Such representations in terms of ordinary graphs, however, do not faithfully model multiway reactions—which are ubiquitous in cellular processes—and shortest paths from these models are often not biologically meaningful (Klamt et al., 2009; Ritz et al., 2014).
Directed hypergraphs generalize ordinary graphs, where an edge, now called a hyperedge, is directed from one set of vertices, called its tail, to another set of vertices, called its head. Hypergraphs have been used to model many cellular processes (Christensen et al., 2009; Heath and Sioson, 2009; Hu et al., 2007; Klamt et al., 2009; Ramadan et al., 2010; Ramadan et al., 2004; Ritz and Murali, 2014; Ritz et al., 2014; Zhou and Nakhleh, 2011). In particular, a reaction with multiple input reactants (all of which must be present for the reaction to proceed) and multiple output products (all of which are produced upon its completion) is correctly captured by a single hyperedge, directed from its set of reactants to its set of products. Despite hypergraphs affording more faithful models of cellular processes, the lack of practical hypergraph algorithms has hindered their potential for properly representing and reasoning about such reaction networks.
Biologically, a typical metabolic or signaling pathway consists of a collection of reactions that synthesize a set of target molecules—key metabolites or transcription factors—from a set of source compounds—molecules available to the cell or activated membrane-bound receptors (Alberts et al., 2007). Computationally, inferring the most likely pathway maps to the shortest hyperpath problem (a generalization of shortest paths to directed hypergraphs) that we consider in this paper: given a cellular reaction network whose reactions, reactants, and products are modeled by the vertices and weighted hyperedges of a directed hypergraph, together with a set of sources and a set of targets, find a series of hyperedges of minimum total weight that yields a pathway producing the targets from the sources.
Next we briefly survey related work, then give our contributions, and the plan of the paper.
Related work
The two fundamental hypergraph models that have emerged for pathway inference in cellular reaction networks are hyperpaths and factories (see Krieger, 2022). We first contrast them, and then summarize computational results.
Informally, a hyperpath in a directed hypergraph is a series of hyperedges that starts from a set of source vertices and ends at a set of target vertices, where for each hyperedge in the series, the vertices it comes out of are covered by the vertices that prior hyperedges go into. In a network whose reactions are modeled by hyperedges, this means for each reaction its input reactants are created as the output products of prior reactions, so the reactions in the hyperpath may proceed without interruption from sources to targets.
On the other hand, a factory in a directed hypergraph for a network whose reactions now also have stoichiometries, is a set of hyperedges that again starts from a set of sources and ends at a set of targets, together with a positive real-valued flux on each hyperedge, where for all vertices other than sources or targets, the total incoming flux from all hyperedges that enter the vertex (multiplied by the stoichiometries for the reaction product represented by the vertex) is at least the total outgoing flux from all hyperedges that leave it (again multiplied by the stoichiometries now for the reactant represented by the same vertex). In a metabolic network, this flux condition means that by supplying the source compounds to the factory, its reactions will produce the target molecules without depleting intermediate metabolites.
While factories contain unordered hyperedges, and all their reactions effectively proceed simultaneously, hyperpaths contain ordered hyperedges, and their reactions essentially proceed in an ordered cascade. For many of the reactions in current pathway databases, stoichiometries are not given (and most reaction rates are unknown). While factories require stoichiometries (or an appropriate default choice for them), hyperpaths do not.
Factories
In systems biology and synthetic biology, factories have mainly been applied to metabolic networks. Current computational approaches find a factory that produces all targets while either minimizing the number of sources it uses, called a min-source factory, or minimizing the number of reactions it uses (equivalently, minimizing its number of hyperedges with nonzero flux), called a min-edge factory.
Cottret et al. (2008) introduced the min-source factory problem and showed it is NP-complete, while Zarecki et al. (2014) extended the problem to consider molecular weights of sources.
Acuña et al. (2012) and Andrade et al. (2016) give methods for enumerating all min-source factories, either excluding or including stoichiometry.
Krieger and Kececioglu (2022b) introduced the min-edge factory problem, showed it is NP-complete, incorporated higher-order models of negative regulation into pathway inference for the first time, and developed approaches based on mixed-integer linear programming (MILP) that are fast in practice to find optimal min-edge factories without interference from negative regulation.
Hyperpaths
Initially studied within the field of algorithms, hyperpaths have been applied in systems biology to pathway inference in cell-signaling and metabolic networks.
Italiano and Nanni (1989) proved that finding a shortest hyperpath is NP-complete, even for singleton-head hypergraphs (where all hyperedges have only one head vertex) that are acyclic and have unit-weight edges.
In a seminal paper that is the source for much of the subsequent work on directed hypergraphs, Gallo et al. (1993) explore many variants of hypergraphs and associated notions of connectivity, including what they call a B-path (though see the correction of Nielsen and Pretolani, 2001), which is essentially equivalent to our definition of hyperpath in Section 2. They give an algorithm for reachability in hypergraphs that finds all vertices reachable from a source vertex in time linear in the total cardinality of the tail- and head-sets of all hyperedges, an efficient algorithm for variants of shortest hyperpaths under additive cost functions (our objective in this paper of minimizing the total weight of the hyperedges in a hyperpath is non-additive), and study source-sink cuts in hypergraphs, proving that finding a minimum cut in a hypergraph is NP-complete.
Carbonell et al. (2012) gave an efficient algorithm to find a source-sink hyperpath if one exists (irrespective of its length), and proved that finding any hyperpath that must contain a fixed set of hyperedges is NP-complete.
Ritz and Murali (2014) and Ritz et al. (2017) were the first to give a practical exact algorithm (guaranteed to find optimal solutions) for shortest acyclic hyperpaths (the special case of cycle-free hyperpaths, which remains NP-complete), by formulating it as an MILP, and demonstrated that optimal acyclic hyperpaths can be found in practice even for large cell-signaling networks. Their acyclic MILP formulation—the state-of-the-art for shortest hyperpaths—does not extend to general hyperpaths with cycles, which occur naturally in cellular reaction networks, for instance due to feedback loops and the processes of assembly and disassembly of protein complexes.
Schwob et al. (2021) later extended the acyclic MILP formulation to include reaction time-dependencies, while Franzese et al. (2019) study parameterized notions of hypergraph connectivity that interpolate between ordinary-path- and hyperpath-connectivity.
Ausiello and Laura (2017) survey results on singleton-head hypergraphs, and note the inapproximability of shortest hyperpaths: unless P = NP, no polynomial-time approximation algorithm exists (that is guaranteed to find near-optimal solutions) for shortest hyperpaths with approximation ratio
Krieger and Kececioglu (2021, 2022a) gave the first efficient heuristic for shortest hyperpaths that allows cycles, proved that their heuristic finds optimal hyperpaths for singleton-tail hypergraphs (where all hyperedges have only one tail vertex), and developed a tractable hyperpath enumeration algorithm. They demonstrated their heuristic is close to optimal in cellular reaction networks through experiments over all source-sink instances from the standard reaction pathway databases, leveraging their enumeration algorithm to verify near-optimality.
Our contributions
In contrast to prior work, we give the first practical exact algorithm for shortest hyperpaths with cycles, which solves a new integer linear programming (ILP) formulation by a cutting-plane approach to find provably optimal hyperpaths even in large cellular reaction networks. More specifically, we make the following contributions.
We derive a new graph-theoretic characterization of hyperpaths in terms of source-sink cuts, that captures fully-general hyperpaths with cycles.
We leverage this characterization to obtain the first integer linear programming formulation of the general shortest hyperpath problem with nonnegative edge weights. This ILP formulation has an exponential number of constraints, however, and cannot be solved directly.
We show we can nevertheless solve this ILP indirectly by a practical cutting-plane approach, that computes over a small subset of the constraints, while guaranteeing an optimal solution to the full ILP.
Our cutting-plane approach is typically fast in practice on real biological instances, finding optimal hyperpaths with a median running time of under 10 seconds, and a maximum running time of around 30 minutes, as measured through comprehensive experiments over all of the many thousands of source-sink instances from the two standard reaction databases in the literature.
We also evaluate for the first time how well shortest hyperpaths infer true pathways, and show they accurately recover known pathways, typically with very high precision and recall.
A preliminary implementation of our cutting-plane algorithm in a new tool called Mmunin (short for “integer-linear-progra
Plan of the paper
The next section defines the computational problem of shortest hyperpaths. Section 3 then gives a new graph-theoretic characterization of hyperpaths that leads to the first formulation of shortest hyperpaths as an integer linear program for fully general hyperpaths with cycles, as well as a cutting-plane algorithm for solving this integer program to optimality in practice. Section 4 compares our algorithm to alternate hyperpath methods through comprehensive experiments over the two standard reaction pathway databases, and shows we can accurately infer true pathways. Finally Section 5 concludes, and offers directions for further research.
SHORTEST HYPERPATHS IN DIRECTED HYPERGRAPHS
We arrive at our computational problem by successively defining hypergraphs, superpaths, hyperpaths, their cycles, and finally the Shortest Hyperpaths problem.
Directed hypergraphs
Directed hypergraphs are a generalization of directed graphs where an edge, instead of touching two vertices, now connects two subsets of vertices. Formally, a directed hypergraph is a pair
Hyperedge
Figure 1 shows how we draw a general directed hyperedge.
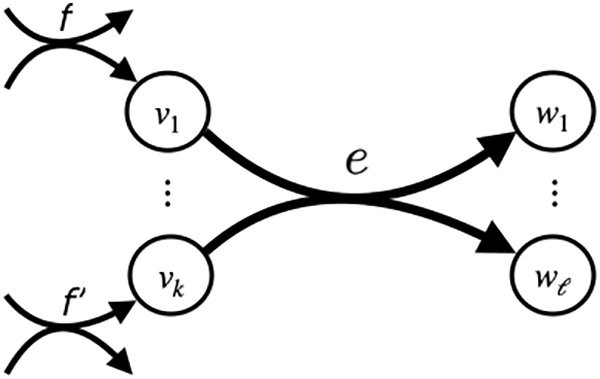
A generic hyperedge e with
In the rest of the paper, the terms hypergraph and hyperedge always refer to a directed hypergraph and a directed hyperedge. We use the term ordinary graph to refer to a standard directed graph (the special case where all hyperedges e have
Hyperpaths are a generalization of directed paths to hypergraphs. In ordinary graphs, a path from a vertex s to a vertex t is a sequence of edges starting from s and ending at t, where for consecutive edges e and f, the preceding edge e must enter the vertex that the following edge f leaves. We say t is reachable from s when there is such an
In generalizing these notions to hypergraphs, the conditions both for when a hyperedge can follow another in a hyperpath and when a vertex is reachable from another become more involved. A hyperpath is again a sequence of hyperedges, but now for hyperedge f in a hyperpath, for every vertex
for each
and 
For an
The term superpath was introduced in Krieger and Kececioglu (2021), and is intended to convey that it is a superset of a hyperpath (which we define next). The concept of superpath is worth distinguishing, since as we will see in Section 3.2, superpaths are directly amenable to representation by the inequalites of an integer linear program, whereas hyperpaths are not.
We now define hyperpaths in terms of superpaths. A set S is minimal with respect to some property X if S satisfies X, but no proper subset of S satisfies X.
In other words, a hyperpath P is a superpath for which removing any hyperedge
Figures 2–4 from Section 4.4 illustrate hyperpaths from cellular reaction networks.
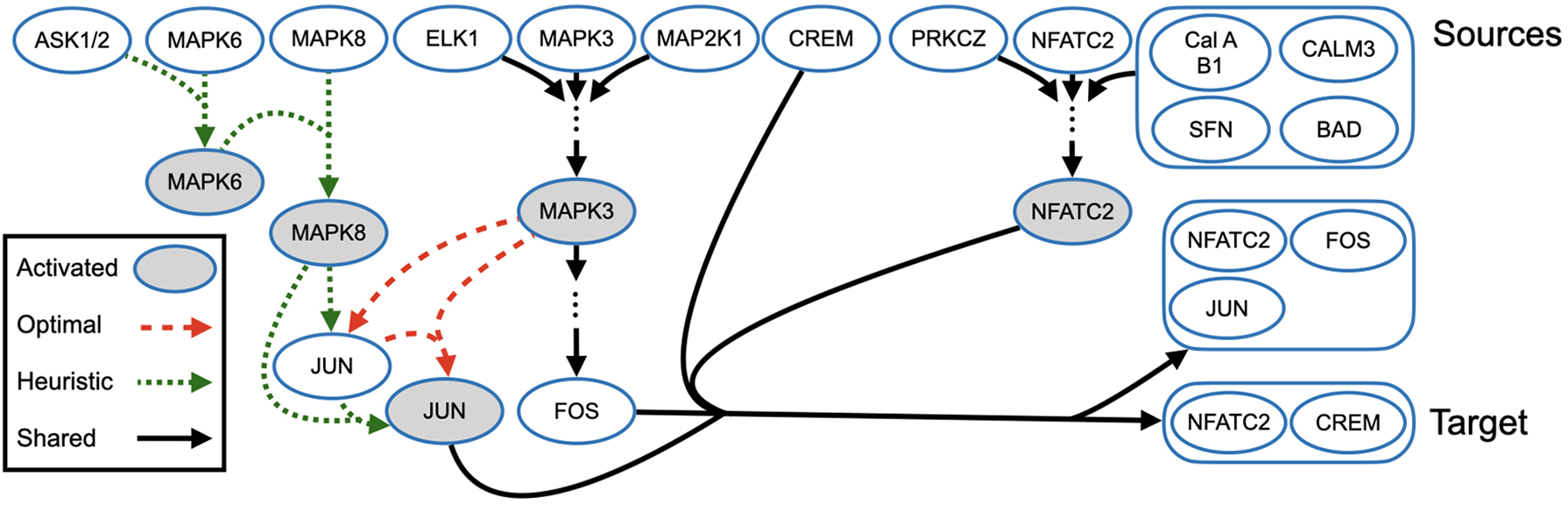
Comparison of hyperpaths whose target is the NFATC2/CREM complex. Sources are shown across the top of the figure, and the target is in the bottom right corner. Hyperedges drawn in dashed red are unique to Mmunin's hyperpath, hyperedges in dotted green are unique to Hhugin's hyperpath, and hyperedges in solid black are common to both hyperpaths. Eight hyperedges that are shared by both hyperpaths have been replaced by ellipses. Hyperedges from MAPK8 to JUN and from MAPK3 to JUN denote transcription and translation of JUN. Vertices with gray fill denote the activated form of a protein.
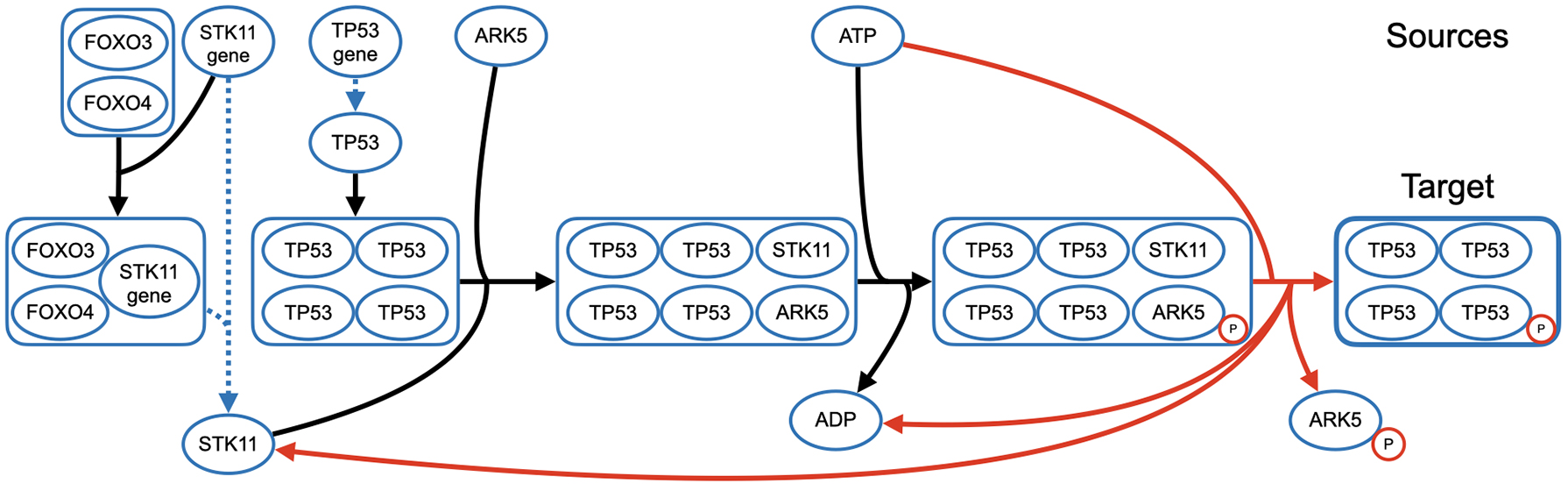
Shortest hyperpath to the phosphorylated p53 tetramer. Sources are shown across the top of the figure, and the target is in the bottom right corner. The hyperedges in dotted blue represent transcription/translation events. The hyperedge in red creates a cycle in the hyperpath, as node STK11 in its head occurs in the tail of a prior hyperedge in the hyperpath.
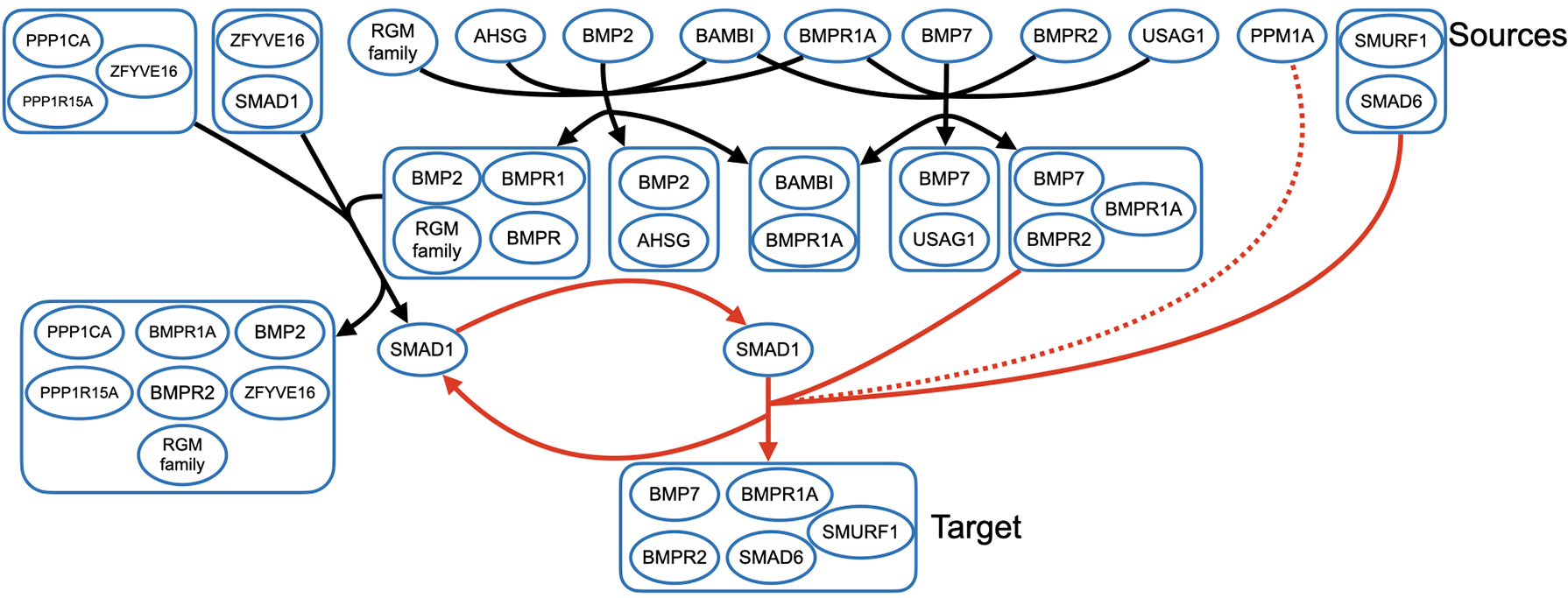
Shortest hyperpath to the BMP7/BMPR2/BMPR1A/SMAD6/SMURF1 complex. Sources are shown across the top of the figure, and the target is shown at the bottom. The portion of the final hyperedge in dotted red represents PPM1A acting as a positive regulator of the reaction. The hyperedges in red form a cycle in the hyperpath.
The above definitions for superpath and hyperpath are essentially equivalent to the notions of B-connectivity and B-path in the original paper of Gallo et al. (1993) (though see Nielsen and Pretolani, 2001), while being more explicit. A similar definition of hyperpath is also given in Carbonell et al. (2012).
Hyperpath P contains a cycle if, for every ordering
Figures 3 and 4 from Section 4.4 show two examples of hyperpaths with cycles in real reaction networks. In practice, cyclic hyperpaths are unavoidable: there are source-sink instances in cellular reaction networks where every
We mention that whether a hyperpath contains a cycle can be efficiently determined through the following construction. Given a hyperpath consisting of hyperedge set P that touches vertex set V, construct an ordinary directed graph
Shortest hyperpaths
We now come to our computational problem. When the hyperedges of a hypergraph all have real-valued weights that are strictly positive, an
For an edge weight function
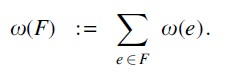
Below, positive edge weights means

This
We mention that Shortest Hyperpaths can be extended to nonnegative edge weights
We note that Shortest Hyperpaths with multiple sources and multiple sinks can be reduced to the above version with a single source and sink, as follows. To find a hyperpath that starts from a set of sources
For a cellular reaction network, on choosing uniform edge weights
Shortest Hyperpaths is NP-complete (Italiano and Nanni, 1989), so there is likely no algorithm that finds optimal solutions and is efficient in the worst-case. Shortest Hyperpaths remains NP-complete even when the underlying hypergraph is acyclic, has unit edge weights
We also mention that by restricting to the following doubly-reachable subgraph, we can often significantly reduce the size of an instance of Shortest Hyperpaths in practice, while not altering its set of solutions. A hyperedge e is doubly-reachable from source s and sink t if all vertices in
The next section casts Shortest Hyperpaths as a new integer linear programming problem, allowing us to leverage powerful techniques for solving such problems in practice, and compute optimal hyperpaths even for large real-world reaction networks.
COMPUTING SHORTEST HYPERPATHS BY INTEGER LINEAR PROGRAMMING
We now formulate Shortest Hyperpaths as a discrete optimization problem known as an integer linear program, using a new characterization of superpaths in terms of cuts. This integer linear programming formulation is the first in the literature that captures fully-general hyperpaths with cycles.
Characterizing superpaths via cuts in hypergraphs
We can give a surprisingly clean characterization of superpaths in terms of cuts. An
A hyperedge e crosses
A remarkable aspect of the following characterization theorem is that it gives an equivalent representation of superpaths without requiring the ordering of hyperedges inherent to the definition of superpaths. This characterization in terms of cuts is the key that will enable us to find shortest hyperpaths via integer linear programming.
Proof. To prove the forward implication, take an ordering of the hyperedges of
We claim
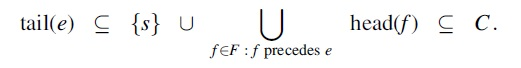
So
For the reverse implication, we prove the contrapositive. Suppose F is not an
Interestingly, Gallo et al. (1993) in their seminal paper use a different definition of edge crossing in a characterization theorem for hyperedge sets that cross all cuts, that led not to a characterization of superpaths, but to a structure they call a B-reduction.
Representing superpaths by linear inequalities
We now formulate Shortest Hyperpaths as an integer linear programming problem. In general, an integer linear program (ILP) is a mathematical optimization problem over integer-valued variables that maximizes a linear function of these variables, subject to constraints that are linear inequalities in the variables. The key to the formulation is to represent the set of all
The variables of our ILP encode the hyperedges in a superpath 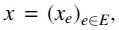 where
where
The constraints of the ILP ensure that an assignment of values to the variables actually encodes an

This has a constraint for every
Consequently, by Theorem 1, the domain
The objective function of the ILP is to minimize
Finally, our integer linear program is to compute,
Since domain
For a hypergraph of n vertices and m hyperedges, the integer linear program given by relation (3) above has m variables and
A cutting-plane algorithm computes over a subset of the constraints of the full integer linear program, and solves a series of less-constrained problems, stopping once it detects it has an optimal solution to the full ILP. The key to a cutting-plane algorithm is an efficient separation algorithm, which for a given solution x to the current ILP, reports whether x satisfies all constraints of the full ILP, and if x does not, returns a constraint violated by x. (This violated constraint is a hyperplane, called a cutting plane, that separates x from the domain of the full ILP.) For our above ILP for Shortest Hyperpaths, this proceeds as follows.
Let
Solve the ILP restricted to the inequalities in
Run the separation algorithm to efficiently find an
If the separation algorithm found a cut C not crossed by
Otherwise, the hyperedges in
This starts with an initial set of inequalities
While this algorithm does not directly solve the full ILP for Shortest Hyperpaths, but instead works on a subset of its constraints, it is nevertheless guaranteed to find an optimal hyperpath, as we show next.
Proof. The cutting-plane algorithm halts on every input, as each iteration adds an inequality to the ILP corresponding to a new
When the algorithm halts and outputs its final solution
As indicated by the proof, the cutting-plane algorithm at most adds an inequality for every
An important observation that follows from the above proof is that the objective function values of successive solutions
The simplest possible realization of the above cutting-plane algorithm starts with
The next section specifies the initial inequalities
We can markedly reduce the number of iterations of the cutting-plane algorithm by seeding it with a strong set of initial inequalites
Structure-based inequalities
We now define a concise class of inequalities based on structural properties of hyperpaths, which has the following three subclasses.
The tail-covering inequalities ensure that for any hyperedge chosen by a solution to the ILP, its tail set is covered by the head sets of other chosen hyperedges (corresponding to condition (ii) in Definition 1 for a superpath). More formally, for every hyperedge

The head-hitting inequalities ensure that for a hyperedge e chosen by a solution, its head intersects (or “hits”) the tail of another chosen hyperedge (following from the minimality condition in Definition 2 for a hyperpath, since otherwise e can be safely trimmed while maintaining reachability). More formally, for every hyperedge
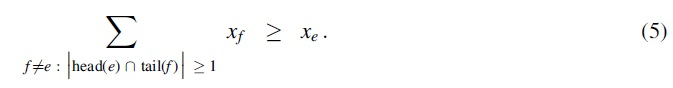
The target-production inequality ensures that target t is reached by hyperedges chosen by the solution (corresponding to condition (iii) in Definition 1 for an

Together the above structure-based inequalities drive the solution found by the cutting-plane algorithm toward having the connected structure of a hyperpath (whereas without them, the solutions over many iterations tend to be disconnected hyperedges that cross the current set of cuts). As shown later in Section 4.6, adding this class of inequalities to the initial ILP dramatically reduces the number of iterations of the cutting-plane algorithm, greatly improving its running time.
For a hypergraph with total tail-set cardinality
Distance-based inequalities
Next we define a concise class of cut-inequalities that are based on distances of vertices from the source, which are efficiently computable. We first define this distance-based class for ordinary graphs, and then generalize it to hypergraphs.
Ordinary graphs
For an ordinary directed graph with source s and sink t reachable from s, let
Finally, denote the family of these
In Section 3.4.3, we prove in Theorem 3 that this class of distance-based cuts is sufficiently strong for ordinary graphs to make the small integer program with cut-inequalities just from this class have an optimal solution value equal to the length of a shortest
The number of cuts in family
Generalizing to hypergraphs
To generalize the distance-based cuts
For a hyperedge e, let an
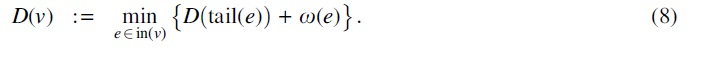
Note that computing tail-distances
To make this practical, we run the efficient hyperpath heuristic of Krieger and Kececiogu (2021, 2022a), which in polynomial time computes estimated tail-distances
Using these vertex-distance estimates
For a hypergraph with n vertices, this distance-based class comprises less than n inequalities.
To summarize, the structure- and distance-based classes, for an input hypergraph with n vertices and hyperedges of total tail-set cardinality t, together yield an initial constraint set
We now prove that the structure- and distance-based classes together suffice for ordinary graphs, in the sense that solving the ILP with just these two classes of inequalities finds a shortest
Below,
Capturing path lengths
The class of distance-based inequalities is sufficient to capture lengths of shortest
Proof. We first show by induction that the weight of an edge set crossing cuts
For the basis with
so the basis holds.
For the inductive step with
In the above, inequality (9) is by nonnegativity of edge weights. Inequality (10) follows from the inductive hypothesis on
Thus any edge set F that crosses all cuts in family
So by Theorem 3, solving an integer linear program containing just the distance-based inequalities gives the length of a shortest
Capturing shortest paths
We now add the class of structure-based inequalities. Our next theorem states that for ordinary graphs, the structure- and distance-based classes together suffice in the following sense to capture shortest paths. Solving the small integer program containing just these two constraint classes—which for an ordinary graph with n vertices and m edges has m variables, less than n distance-based inequalities, and at most
As an aside, we note that the following result gives a concise ILP formulation of shortest paths in ordinary graphs that is different from the standard linear-programming-based formulations in the literature (see Wolsey, 1998, pp. 42–43). Of course, simply writing down the ILP requires us to have already solved the shortest path problem, just in determining the distance-based cuts. Nevertheless, this ILP formulation could provide a convenient way to tackle NP-complete variants of shortest path problems, by casting them as ILPs with additional side constraints in order to solve them to optimality in practice.
Formally, the integer linear program
Proof. Let
We first show every
Consequently, optimality of
Moreover, minimality holds for
We next argue sink t must be reachable from source s along edges in
The distance-based inequalities ensure
Hence t must be reachable from s through
While a result analogous to Theorem 4 does not hold for hypergraphs (since the very first ILP solved by the cutting-plane algorithm, whose constraints
Recall that the cutting-plane algorithm starts with inequalities
We mention that the trivial separation algorithm described near the end of Section 3.3 can be viewed as a special case of this more general separation algorithm, which only performs source-augmentation of the single cut
The general separation algorithm outlined above that augments distance-based cuts can find up to
This general separation algorithm is correct, as argued in the next subsection on source-augmentation, in the following sense. Given current solution
Moreover, the general separation algorithm is also efficient (even though the full ILP contains exponentially-many inequalities), as shown by the time analysis at the end of this section.
We next describe source-augmentation, sink-augmentation, and then bound the running time of the resulting separation algorithm.
Source-side augmentation
Given current solution
For a given active hyperedge e that crosses C, we enlarge C to form a new cut
We note that this process can fail to find a new cut
We also note that the above process actually finds the unique
Importantly, the trivial cut
This last observation verifies that our separation algorithm is correct: given current solution
Sink-side augmentation
We perform sink-augmentation of distance-based cut
For a given active hyperedge e that crosses C, we enlarge
We note that the above process can fail to find a new cut
Time complexity
We bound the time complexity of the separation algorithm in terms of the following key parameters:
the number of distance-based cuts k, the number of active hyperedges h in the current solution the number of doubly-reachable hyperedges m (which are discussed at the end of Section 2; informally, these are all hyperedges that are both reachable in the forward direction from the source, and reachable in a backward sense from the sink), the number of vertices n in the doubly-reachable subgraph (namely, the cardinality of the union of the tail- and head-sets of all doubly-reachable hyperedges), and the standard measure of the size

To aid the analysis, we make the implementation of source- and sink-augmentation more concrete.
Source-augmentation of a distance-based cut C can be implemented straightforwardly as a repeated scan of the list of active hyperedges F in solution
To easily test whether a hyperedge crosses the current augmentation, we maintain a boolean variable for each vertex v in the doubly-reachable subgraph that records whether v is on the source-side of
Since each scan until termination makes at least one hyperedge e of F no longer cross
So for a family of k distance-based cuts, source-augmentation takes total time
Sink-augmentation of a distance-based cut can be similarly implemented as a repeated scan of the active hyperedges, where for efficiency we now use the following variables:
a boolean variable for each vertex v that indicates whether v is on the source side of the current augmentation,
a boolean variable for each hyperedge e that records whether all of the tail- and head-vertices for e are on the source side of the current augmentation, and
an integer variable for each vertex v that counts the number of active hyperedges
This integer count for v is precisely the number of active hyperedges that will newly cross the current augmentation on moving v from its source side to its sink side. Initializing these variables for vertices and hyperedges when processing a given distance-based cut takes
When the scan detects that an active hyperedge e crosses the current augmentation
As before, each scan until termination makes at least one active hyperedge no longer cross the current augmentation (and this hyperedge remains non-crossing during subsequent scans), so this performs at most h scans, spending
To summarize the time complexity, for k distance-based cuts, a solution with h active hyperedges, and a doubly-reachable subgraph of size
In terms of the input hypergraph, for a doubly-reachable subgraph of n vertices and m hyperedges, since
EXPERIMENTAL RESULTS
We now present experimental results with a preliminary implementation of our cutting-plane algorithm, in a tool we call Mmunin (Krieger and Kececioglu, 2022d). † As the experiments show, Mmunin can find optimal hyperpaths in large real-world cellular reaction networks quickly, often in less than 10 seconds.
We first give details on our experimental setup, describing the datasets and our implementation. We then show, through comprehensive experiments across all of the thousands of source-sink instances from the two standard cellular reaction databases in the literature, how Mmunin surpasses both the state-of-the-art heuristic for general shortest hyperpaths (Krieger and Kececioglu, 2021, 2022a) and the state-of-the-art exact algorithm for shortest acyclic hyperpaths (Ritz et al., 2017). The last subsections discuss three biological examples, study how well Mmunin recovers known biological pathways, and investigate the effect of the various constraint classes on running time.
Experimental setup
We briefly describe the datasets and how we transform them into hypergraphs, and then give details on our implementation, including two modifications that further improve running time.
Datasets and their preparation
Our source-sink instances for Shortest Hyperpaths were formed from the two standard cellular reaction databases in the literature, following an established hypergraph construction protocol (Krieger and Kececioglu, 2022a; Ritz et al., 2017). Our NCI-PID dataset aggregates all 213 pathways from the US National Cancer Institute's Pathway Interaction Database (NCI-PID) (Schaefer et al., 2009), while our Reactome dataset aggregates all 2,516 pathways from the Reactome database (Joshi-Tope et al., 2005).
To build a hypergraph for each dataset, we map each protein or small molecule to a vertex, and each reaction to a hyperedge. In each reaction's hyperedge, its input reactants and positive regulators are in the tail, and its output products are in the head. The set S of all vertices that originally have no incoming hyperedges we call the sources. The set T of vertices that originally have no outgoing hyperedges we call the targets. For the hypergraph, we create a single supersource vertex s, with one outgoing hyperedge
In our single-target experiments, each source-sink instance has a single target
Table 1 gives summaries of these hypergraphs and their source-sink instances. The NCI-PID hypergraph has more than 9,000 vertices and 8,000 hyperedges, while the Reactome hypergraph has more than 20,000 vertices and 11,000 hyperedges. In both hypergraphs, vertices have small average in-degree and out-degree. The head-sets and tail-sets of the hyperedges also tend to have small average size. Both hypergraphs contain many hyperedges that are self-loops, which cannot be trivially removed, and which would be excluded when finding shortest acyclic hyperpaths. Some of these self-loops are unreachable, meaning at least one tail vertex has only this same hyperedge as an incoming hyperedge; in such a case, we resolve this cycle in the self-loop by adding such tail vertices to the source set.
Dataset Summaries
Dataset Summaries
Out of all possible targets
For each
All hyperedges are given unit weight, even though the cutting-plane algorithm handles positive edge weights. (In the reaction databases, reaction rates for many reactions are unknown.) A shortest hyperpath in these unit-weight hypergraphs corresponds to a pathway that produces the target from the sources using the fewest reactions—the most parsimonious pathway for that target.
Implementation
The cutting-plane algorithm and its separation algorithm are both implemented in Python 3.8, comprising around 2,000 lines of code. All procedures are implemented as described in Section 3, with a few exceptions.
First, for an
Lastly, at each iteration the cutting-plane algorithm compares the objective function value of its current solution to the length of Hhugin's heuristic hyperpath
We also made one modification to Hhugin to improve its solution quality, while only slightly increasing its running time. In the original description of Hhugin (Krieger and Kececioglu, 2021, 2022a), once a hyperedge is extracted from the heap in the overall while-loop, its in-edge list becomes frozen, and further hyperedges are not added to it. We changed this rule, so that now the in-edge list for a hyperedge no longer on the heap can continue to grow as more hyperedges are subsequently extracted.
Source code for this cutting-plane algorithm implementation, including all datasets, is available free for research use at http://mmunin.cs.arizona.edu (Krieger and Kececioglu, 2022d).
Mmunin outperforms the state-of-the-art hypergraph methods for pathway inference via hyperpaths: both the efficient heuristic for general shortest hyperpaths with cycles, called Hhugin (Krieger and Kececioglu, 2021, 2022a); and the MILP-based exact algorithm for shortest acyclic hyperpaths (Ritz and Murali, 2014; Ritz et al., 2017), which we call AcycMILP. We compare these three methods across all instances from Reactome and NCI-PID.
Table 2 summarizes statistics from this comparison for reachable instances, where an
Suboptimality of Alternate Hyperpath Methods
Suboptimality of Alternate Hyperpath Methods
For all these instances, Mmunin computes an optimal hyperpath in less than 30 minutes, while allowing cycles for the first time. Mmunin surpasses AcycMILP on the 22 Reactome instances and 38 NCI-PID instances where all
Notably, Mmunin not only finds an optimal hyperpath for these instances where Hhugin is suboptimal, it even finishes its computation before Hhugin—showing that Mmunin (without the distance-based constraints obtained using Hhugin) actually finds an optimal solution for these instances faster than the heuristic finds a suboptimal solution. In fact, overall, we found that Mmunin is faster than Hhugin on more than 20% of all instances.
Mmunin is typically fast in practice, with a median running time across all instances of under 10 seconds. Table 3 gives performance statistics for computing optimal hyperpaths by Mmunin over all reachable instances: specifically, the number of hyperedges in the shortest hyperpath, the number of inequalities in the final ILP, the number of iterations to find an optimal solution, the running time per iteration, and the total time over all iterations. (Due to inherent randomness in the CPLEX solver we use, there is some variation in running time even for the same instance.)
Performance of Mmunin
Performance of Mmunin
The maximum running time across all instances is just under 30 minutes, demonstrating it is now feasible to find shortest hyperpaths in cellular reaction networks even for large instances with more than 10,000 hyperedges.
The number of hyperedges in the shortest hyperpath tends to be very low, with a median of 3 hyperedges for both NCI-PID and Reactome, and a maximum of 16 and 17 hyperedges, respectively. This is likely because, in current practice, the pathways that have been annotated tend to have a small number of reactions, and they tend to exhibit low overlap with other annotated pathways. As a result, the shortest hyperpath to any target using only the reactions from one annotated pathway will tend to have a small number of hyperedges (and any hyperpath outside the annotated pathway would tend to be longer).
The number of iterations for Mmunin to find an optimal solution also tends to be very low—around 2 or 3 iterations—but it can require more than 1,500 iterations. Note that at each iteration, the cutting-plane algorithm must solve an ILP containing thousands of variables and inequalities. Even when an instance requires many iterations, on average each iteration is fast, with a maximum time per iteration around 12 seconds.
The number of inequalities in the final ILP varies widely between instances and between datasets, with median values of around 2,500 inequalities for NCI-PID and around 150 inequalities for Reactome. The number of inequalities for an instance is mainly a function of both the size of its doubly-reachable subgraph (which determines how many structure-based inequalities are in the initial ILP), and the number of iterations of the cutting-plane algorithm (which strongly affects how many cut-based inequalities are added to the ILP). The difference in median values between the datasets comes largely from their doubly-reachable hyperedges, since most instances require very few iterations of the cutting-plane algorithm. The maximum values of more than 11,000 inequalities for NCI-PID and 7,000 inequalities for Reactome are on instances where a large number of cutting-plane iterations are needed to find an optimal solution.
To provide some concrete examples of shortest hyperpaths found by Mmunin, we discuss three biological instances (of a size that can be readily shown): an instance from NCI-PID, where Mmunin finds a shorter hyperpath than the heuristic Hhugin; and two instances from Reactome where all
The NFATC2/CREM complex
The first example is drawn from the 23 instances in NCI-PID where Mmunin outperforms Hhugin, as it finds a suboptimal hyperpath. (We chose this particular instance because the size of its hyperpaths makes them reasonable to draw.) We note that AcycMILP is also optimal on this instance, as there is a shortest hyperpath that is acyclic.
Figure 2 shows the hyperpaths returned by Mmunin and Hhugin for this example, which consist of reactions involved in the deactivation of the “nuclear factor of activated T cells 2” (NFATC2) by the “cAMP response element modulator” (CREM). Sources are shown across the top of the figure, and the target is in the bottom right corner. Hyperedges drawn in a red dash are unique to Mmunin's hyperpath, and hyperedges in a green dotted line are unique to Hhugin's hyperpath, while hyperedges in a solid black line are common to both hyperpaths. Eight hyperedges that are shared by both pathways have been replaced in the figure by ellipses, for simplicity. All hyperedges denote biochemical reactions except the hyperedges from MAPK8 to JUN and from MAPK3 to JUN, which denote the transcription and translation of JUN. Vertices with a gray fill denote the activated form of a protein. Note that stoichiometry of the reactions is not considered in our hyperpath formulation, so this hyperpath is valid, even though two copies of NFATC2 are needed in the final reaction.
Each hyperpath contains hyperedges from the following four NCI-PID pathways: “Calcium signaling in the CD4+ TCR pathway,” “RAS signaling in the CD4+ TCR pathway,” “JNK signaling in the CD4+ TCR pathway,” and “Nongenotropic androgen signaling.” The hyperpaths show CREM repressing the activated form of NFATC2 before forming a ternary complex with NFATC2 and its DNA binding sites, resulting in the attenuation of transcription of T helper-1-specific cytokine genes in human medullary thymocytes (Bodor and Habener, 1998).
Hhugin's hyperpath contains 13 hyperedges, while Mmunin's hyperpath contains 11 hyperedges, which is optimal. Notably, hyperedges unique to Mmunin's hyperpath only use vertices that are common to both hyperpaths, further simplifying it, and making it a more likely pathway.
The phosphorylated p53 tetramer
The second example was chosen from the 22 instances in Reactome with no acyclic hyperpath, on which AcycMILP finds no solution. We note that the heuristic Hhugin also finds an optimal hyperpath for this particular instance.
Figure 3 shows the optimal hyperpath returned by Mmunin, which captures the phosphorylation of “cellular tumor antigen p53” (TP53) by “AMPK-related protein kinase 5” (ARK5), causing its activation. Sources are shown across the top of the figure, and the target is in the bottom right corner. The hyperedges in dotted blue represent transcription/translation events, and the hyperedge in red shows the cycle in the hyperpath, where a node in the head of the red hyperedge is in the tail of an earlier hyperedge in the hyperpath.
This hyperpath shows the transcription and translation of key proteins involved in the formation of a complex with the TP53 homotetramer. Once this complex is formed, ARK5 is activated by phosphorylation, allowing it to directly phosphorylate p53 (Hou et al., 2011), activating p53 and allowing it to assist in DNA damage repair.
This example from Reactome has more than 1,600 hyperedges in the doubly-reachable subgraph, making it one of the largest instances. It is also one of the longer cycles for any Reactome instance, with three hyperedges involved in the cycle. Interestingly, even though this is a large instance, no alternate hyperpaths exist that reach the target for this instance.
The BMP7/BMPR2/BMPR1A/SMAD6/SMURF1 complex
The third example was also chosen from the 22 instances in Reactome where all source-sink hyperpaths are cyclic, hence Mmunin outperforms AcycMILP. Again Hhugin is optimal on these as well.
Figure 4 shows the optimal hyperpath found by both Mmunin and Hhugin for this example, which represents a signaling pathway resulting in the degradation of the “bone morphogenetic protein receptors” (BMPR2 and BMPR1A) in Reactome (Murakami et al., 2003). Sources are shown across the top of the figure, and the target is in the bottom right corner. The part of the final hyperedge shown with a dotted line represents PPM1A acting as a positive regulator of the reaction. The cycle in this hyperpath is shown in red, and represents the phosphorylation and subsequent dephosphorylation of “Mothers against decapentaplegic homolog 1” (SMAD1).
The hyperpath for this example shows the formation of many different complexes that include “bone morphogenetic proteins” (BMP2, BMP7) and their receptors. These receptor complexes are then marked for ubiquitination and degradation both by SMAD1 and the complex of SMAD6 and “SMAD-specific E3 ubiquitin protein ligase 1” (SMURF1).
This particular example shows how even a short hyperpath can be fairly involved, by sharing many vertices among its hyperedges in various ways. While this hyperpath has only five hyperedges, most have tails and heads with multiple vertices, and hence would likely not be captured correctly by ordinary graph-based methods.
Accuracy of pathway inference
Mmunin recovers known annotated pathways from Reactome typically with very high accuracy. For the following pathway inference experiments, we formed new problem instances for a small number of known pathways in Reactome: namely, all ten pathways from the 22 instances with only cyclic hyperpaths where the target appears in only one annotated Reactome pathway † (and hence there is a unique true pathway that produces the target). This gave ten instances for the inference experiment.
For each instance, given by a particular Reactome pathway
For five of these instances, the sink was not reachable from the supersource, due to an unreachable cycle. (A simple example of such a cycle is when vertex v is in the tail of all in-edges to vertex w and vice versa.) To reestablish reachability, we manually inspected each unreachable cycle and added vertices to the source set ‡ from the cycle that would not normally qualify as sources (since these vertices have incoming hyperedges). We tried to choose for these new source vertices those that would minimize the number of reactions that could now be bypassed, since these new sources could now be in the tail of a hyperedge in a hyperpath before being reached in the head of a prior hyperedge.
This resulted in a doubly-reachable subgraph containing up to 3,600 hyperedges for some pathway inference instances, which is more than double the size of this subgraph for any of our previous single-target instances. Due to the expansion of this subgraph, the running time of Mmunin on some instances was significantly longer, taking up to 25 hours to compute an optimal hyperpath (which we investigate further below).
To evaluate the accuracy of pathway inference on these instances, we compared Mmunin's inferred hyperpath
We evaluated the accuracy of recovering the true pathway
Across the ten instances,
precision has range
recall has range
overlap has range
This experiment shows Mmunin is able to accurately recover known pathways, or possibly discover more efficient ones.
Factors affecting inference time
The markedly longer running time for some instances of pathway inference is likely due to a much larger doubly-reachable subgraph. For these instances, we compared Mmunin's running time with three features of the instance with which we thought it might share a correlation: (a) the number of hyperedges in the doubly-reachable subgraph, (b) the number of hyperedges in the shortest hyperpath, and (c) the number of targets for the instance (since all these instances now have more than one target, in contrast to our earlier single-target experiments).
Figure 5a–c shows scatterplots comparing running time with these three features. The ten instances can be naturally separated into two groups by their running time, so we identified the same four instances with high running time by red discs across the plots, and the same six instances with low running time by blue triangles.
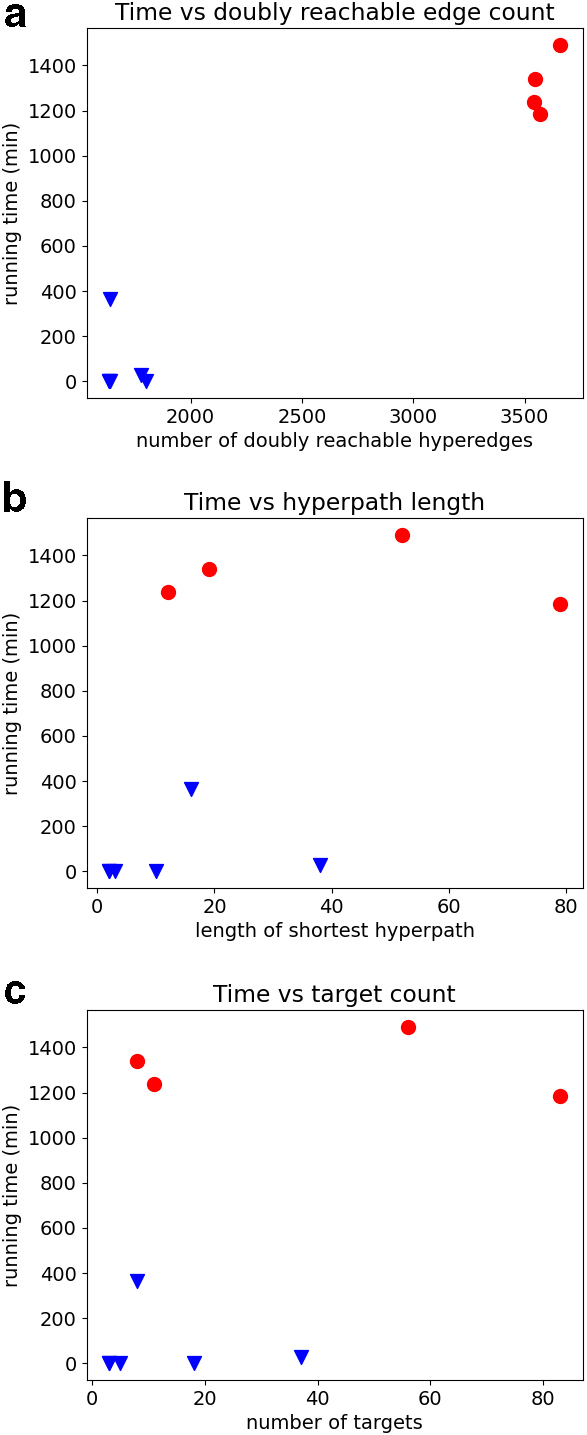
Comparison of Mmunin's running time to three features of the instances for the pathway inference experiment. The three features are:
Interestingly, of these three features, the only one having any correlation with running time is the number of doubly-reachable hyperedges. The number of targets for an instance, and the length of its shortest hyperpath, surprisingly seem to have no relation with running time.
Our last experiments study the effect of the structure- and distance-based constraint classes—and their subclasses—on the running time of Mmunin. We first compare running times when excluding separately each single constraint-subclass, and then compare times when including subclasses together one-by-one within the cutting-plane algorithm.
Excluding constraint classes
To understand which constraints best contribute to Mmunin's running time, we conducted the following exclusion experiment. We separately considered these classes: the distance-based cuts, the head-hitting constraints, the tail-covering constraints, the target-production constraint, and the class of cut-inequalities added at each iteration of the cutting-plane algorithm. For each of these classes, we determined their contribution to Mmunin's running time by removing that single class from the initial ILP or from subsequent iterations, and then comparing the resulting running time with the original time for Mmunin with all classes present. We performed this experiment on the 22 instances from Reactome with no acyclic hyperpath. We chose this small set of instances because they have diverse shortest hyperpath lengths and (as shown later) Mmunin's running time when excluding constraint classes can be very high. The results of this exclusion experiment are summarized in Table 4.
Comparing Excluded Constraint Classes
Comparing Excluded Constraint Classes
We found that the distance-based cuts, head-hitting constraints, and tail-covering constraints contribute the most to a reasonable running time, as their absence causes a huge slowdown. In reality, rather than literally excluding all distance-based cuts, to ensure that the cutting-plane algorithm terminates (given enough time) we must replace the distance-based cuts with the single cut
To determine the effect on running time of the cutting-plane inequalities that are source- and sink-augmented distance-based cuts, we replaced Mmunin's general separation algorithm with the trivial one that at each iteration just finds the set R of vertices reachable from s along the active hyperedges of the current solution
For the second inclusion experiment, we first ranked the constraint classes by their effect on running time (from greatest effect to least) based on the outcome of the previous exclusion experiment, which gave the following order: (a) head-hitting constraints, (b) tail-covering constraints, (c) distance-based constraints, (d) target-production constraint, and (e) augmented cutting-planes. Then for each of the 22 cyclic Reactome instances, we initially ran Mmunin without any constraint classes, followed by including classes together one-by-one in this order, rerunning Mmunin on including each successive class. For this inclusion experiment, we set a time limit of 48 hours for each run.
The simplest possible version of the cutting-plane algorithm with none of the initial constraint classes (and the trivial separation algorithm) did not finish within this time limit on any of these instances. When starting with no initial constraints in the first ILP, the earliest iterations of this simplest cutting-plane algorithm tend to find current solutions
Including just the head-hitting constraints allows Mmunin to now find optimal hyperpaths on eight of the 22 instances within 48 hours. For these instances, the cutting-plane algorithm still requires a very large number of iterations to find an optimal solution, with a median of more than 5,000 iterations, and a minimum time of more than 24 hours. Even though this restricted version of Mmunin can find optimal solutions for some instances within the limit, further constraint classes are necessary to make it in fact practical.
Its performance when in addition including the tail-covering constraints is similar to its performance when only the distance-based constraints are excluded. Mmunin finds an optimal hyperpath within 48 hours now for 19 of the 22 instances, with a median of 2 iterations, a median time per iteration of 4 seconds, and a median total time of 10 seconds. This is close to when excluding the distance-based class likely because excluding the other classes (namely the target-production constraint and the augmented cutting-planes) does not have a major impact on performance on these instances (as seen earlier in Table 4).
The further addition of the distance-based constraints allows us to finally find optimal solutions on all 22 instances, yet its typical performance is still roughly the same as the preceding version: a median of 2 iterations, a median time per iteration of 4 seconds, and now a median total time of 9 seconds.
The results for adding the final two constraint classes—the target-production constraint and the augmented cutting-planes—are already given in Table 4 under the respective columns “cutting-plane” and “none.” The effect of including these last two classes for these 22 instances is inconclusive: their inclusion or exclusion does not have a consistent effect on our median and maximum performance criteria.
In short, the results of this experiment confirm the importance of the head-hitting, tail-covering, and distance-based inequalities, and indicate that their mutual inclusion allows us to typically find optimal hyperpaths quickly.
CONCLUSION
We have presented the first practical exact algorithm for Shortest Hyperpaths—a generalization of shortest paths to directed hypergraphs—which employs a cutting-plane-like approach to solve an integer linear programming formulation, derived from a new graph-theoretic characterization of superpaths, that for the first time captures fully-general hyperpaths with cycles. Comprehensive experiments on large real-world cellular reaction networks show we can compute optimal hyperpaths quickly, and that shortest hyperpaths infer true pathways with high accuracy.
Further research
This opens many directions for further research. We offer some avenues for investigation in combinatorial optimization, algorithm design, computational biology, and algorithm evaluation.
Studying the superpath polytope
The largest advance in solving Shortest Hyperpaths to optimality is likely to come from studying an object in combinatorial optimization called the superpath polytope: a representation of the convex hull of the domain
On a related note, it is surprising how quickly modern solvers such as CPLEX can find optimal solutions to the series of integer linear programs in our current cutting-plane approach—even on instances with thousands of hyperedge variables—which suggests the linear programming relaxation of our integer program may already tend to be integer-valued in practice.
Accommodating negative edge weights
Our formulation of Shortest Hyperpaths relies on positive edge weights (but can be extended to nonnegative edge weights through postprocessing as mentioned toward the end of Section 2), and breaks down for negative edge weights.
This parallels the behavior of shortest paths in ordinary directed graphs, where algorithms like Dijkstra's for the special case of nonnegative edge weights are much simpler and more efficient than those for the general case of arbitrary weights (and in particular negative weights), whose known algorithms differ markedly from Dijkstra's. Moreover, shortest paths with negative edge weights can be efficiently solved in ordinary graphs only because the problem statement permits non-simple paths that can repeatedly use a given cycle, allowing an algorithm to report there is no best solution once it discovers a reachable negative-weight cycle, which can be efficiently detected. When shortest paths are required to be simple paths, which effectively corresponds to requiring solutions be minimal, the problem under negative edge weights becomes NP-complete even for ordinary graphs, as an algorithm can then be forced to find a longest path (or equivalently, detect a Hamiltonian path). In the context of Shortest Hyperpaths, solutions already must be minimal—as hyperpaths are minimal superpaths—so for negative edge weights the recourse of reporting there is no best solution is never available (since a shortest hyperpath trivially exists whenever the sink is reachable from the source), hence an algorithm has to also deal with finding longest hyperpaths.
While our integer program finds a minimal superpath for positive weights, it fails for arbitrary edge weights. Furthermore, as indicated above, any algorithm for Shortest Hyperpaths that handles negative weights can be forced to solve a generalization of Longest Paths to hypergraphs. Whether there is a more general algorithm that can in practice find optimal hyperpaths while accommodating negative edge weights is open, and will require a much different design than our current one.
Incorporating negative regulation
More directly relevant to computational biology is incorporating negative regulation when finding shortest hyperpaths. A negative regulator is a molecule that inhibits a particular reaction from occurring. Consequently, a hyperpath whose reactions create (as output products) negative regulators of its own reactions is not a suitable solution for producing targets from sources (as it inhibits itself from proceeding).
Krieger and Kececioglu (2022b) consider negative regulators in the context of finding optimal factories in metabolic networks, and introduce the notion of non-interference under first-order negative regulation—where a factory does not directly produce negative regulators of its own reactions—and second-order negative regulation—where in addition negative regulators of a factory's reactions are not indirectly produced downstream by reactions outside the factory.
Their approach to finding optimal factories under first- and second-order negative regulation provides a general technique that applies to integer-programming-based methods (through adding side-constraints and generating next-best solutions). Exploring whether this technique also enables finding optimal hyperpaths under first- and second-order negative regulation seems promising.
Collecting benchmark hypergraphs
Our experiments evaluating the cutting-plane approach implemented by Mmunin in Section 4.5 suggest its hardest instances arise from growth in the size of the doubly-reachable subgraph. While comprehensive evaluation of Mmunin over all single-target instances from the two available cellular reaction databases shows it can quickly find optimal hyperpaths in current reaction networks, its performance will inevitably degrade for even larger future networks, due to the inherent difficulty of solving Shortest Hyperpaths via integer linear programming.
Are there other classes of real-world directed hypergraphs (in contrast to simulated instances from random hypergraph generators which can lack the challenging structure of real instances) besides cellular reaction networks, for evaluating shortest hyperpath solvers, that contain harder structure (such as larger doubly-reachable subgraphs), and naturally arise from applications needing solution? Collecting such challenging benchmark hypergraphs would be a valuable contribution to the evaluation and development of improved hyperpath solvers, and likely other hypergraph algorithms as well.
Clearly there are many avenues for future investigation.
Footnotes
ACKNOWLEDGMENTS
AUTHORs' CONTRIBUTIONS
J.K.: Conceptualization, funding, and supervision. S.K.: Data curation, investigation, software, and visualization. J.K. and S.K. both contributed to method development, method analysis, writing, and editing.
AUTHOR DISCLOSURE STATEMENT
The authors declare they have no conflicting financial interests.
FUNDING INFORMATION
This research was supported by the U.S. National Science Foundation through grants CCF-1617192 and IIS-2041613 to John Kececioglu.