
Abstract
Automatic radiology medical report generation is a necessary development of artificial intelligence technology in the health care. This technology serves to aid doctors in producing comprehensive diagnostic reports, alleviating the burdensome workloads of medical professionals. However, there are some challenges in generating radiological reports: (1) visual and textual data biases and (2) long-distance dependency problem. To tackle these issues, we design a visual recalibration and gating enhancement network (VRGE), which composes of the visual recalibration module and the gating enhancement module (gating enhancement module, GEM). Specifically, the visual recalibration module enhances the recognition of abnormal features in lesion areas of medical images. The GEM dynamically adjusts the contextual information in the report by introducing gating mechanisms, focusing on capturing professional medical terminology in medical text reports. We have conducted sufficient experiments on the public datasets of IU X-Ray to illustrate that the VRGE outperforms existing models.
INTRODUCTION
Medical imaging is pivotal in diagnosing and treating a comprehensive range of diseases. Traditionally, clinical medical imaging reports rely on the extensive medical knowledge and practical experience of health care professionals. To write accurate and high-quality medical reports, it usually requires experienced medical imaging experts to provide detailed information and analysis. However, because of differences in professional knowledge among different doctors, generating medical image reports that are consistent with radiological images is a major challenge. In addition, doctors usually need to spend 10 minutes or even longer to write a medical imaging report (Alfarghaly et al., 2021; Li et al., 2018).
The increasing number of medical images has added to the heavy task of writing reports for doctors. The varying workload and status of doctors may lead to time-consuming processes and inconsistent report quality. To address these challenges, automatic medical imaging report generation has become an urgent task in clinical practice. This task not only reduces the huge burden on health care professionals but also significantly accelerates the progress of workflow, thereby improving the overall quality and standardization level of health care (Hou et al., 2023a).
Recently, deep learning has made remarkable strides in image captioning, effectively producing precise short text narratives for natural images. This success ignites considerable research interest in generating radiology reports. Many existing methods (Jing et al., 2018b; Liang et al., 2017; Yu et al., 2016) for radiology generation reports use image-captioning models and traditional encoder–decoder architectures: During the encoding phase, medical image visual features are derived from Convolutional Neural Networks (CNNs); in the decoding layer, the report is generated by the Transformer (Liu et al., 2021a; Lu et al., 2017). Automatically generate radiological reports involves producing detailed, professional, and terminology-rich long-text reports based on all findings, encompassing both normal and abnormal observations in medical imaging. Although the task of generating radiological reports has achieved great success, it still faces many challenges, as follows:

A chest X-ray image and its report. Red represents organs, whereas blue with underline represents descriptions of abnormal parts.
This article proposes a visual recalibration and gating enhancement network (Visual Recalibration and Gating Enhancement Network, VRGE) to tackle the overhead challenges. We introduce a visual recalibration module (visual recalibration module, VRM) to enhance the visual feature information extracted from medical images and improve the VRGE’s sensitivity to determine abnormal characteristics. In addition, to relieve text bias and model long text dependencies, we adopt a gating enhancement module (GEM) in the Transformer decoder to associate disease information effectively and integrate contextual information from radiology reports. Our specific contributions are in the following aspects:
The VRGE employs the VRM, which improves the model’s ability to identify crucial parts and diseased areas in radiological images by re-adjusting and enhancing the extracted medical visual feature information. The GEM associates and integrates contextual information from input sequences to capture key disease feature representations in medical reports, which can relieve the long-distance dependency problem. Comprehensive experiments demonstrate that the VRGE model achieves state-of-the-art performance compared to other baselines on the public IU X-Ray dataset.
Image captioning
Image Captioning task aims to generate corresponding natural language contents by extracting information from images. These methods usually adopt the structure of CNN–RNN to extract image feature information through CNNs, and use Recurrent Neural Network (RNN) to generate a single sentence description. Vinyals et al. (2015) designed the Neural Image Caption (NIC) model, which uses CNN as an alternative to RNN to generate semantically abundant description. To tackle the long-term dependency in RNN, these methods introduce structures such as long short-term memory networks (LSTMs) and gated recurrent units. These structures effectively solve the problems of gradient disappearance and gradient explosion, making the model more capable.
Recently, the attention mechanism has been introduced into the image captioning model to pay more concentration to crucial areas in the image, providing a basis for better expression of semantic information. Xu et al. (2015) designed a “hard-soft” attention mechanism embedded in CNN to obtain underlying image feature information, thereby improving the coherence and relevance of the generated description content. Unlike image captioning, radiological medical reports need to consider the essential features in the image, conduct a detailed analysis of anomaly detection and lesion location in medical images, and generate more professional diagnostic descriptions.
Medical report generation
Different from image captioning, medical report generation is based on all the content in the medical image (normal and abnormal structural findings) to generate a detailed text report with professional medical terms rather than a sentence description. Many existing methods generate radiology medical reports by aligning text and image information. Jing et al. (2018b) used a co-attention mechanism to locate sub-region feature information in medical images and generate corresponding accurate descriptions. Chen et al. (2020) introduced a memory-driven module in the Transformer decoder layer, which can store critical information about modalities to enhance the interaction and generation process between modalities. Chen et al. (2022) further proposed memory query and memory response modules to align text and image information to promote radiology report generation. Liu et al. (2021) designed a contrastive attention model to extract image contrast information and effectively capture image anomaly feature representation. Currently, some methods utilize additional prior knowledge to help models better understand the contextual information of medical reports. For example, Zhang et al. (2020) constructed a knowledge graph for chest discovery and passed information through graph convolutional networks, which can improve the model to detect and analyze disease characteristics.
METHOD
Radiology medical report generation involves a complex approach integrating textual and visual data. In this process, we use artificial intelligence methods to mine critical information extracted from the input radiological medical images
Next, we will elaborate on the proposed VRGE, which aims to generate accurate radiological medical reports automatically. The VRGE involves four essential modules: Visual embedding module (VEM) aims to extract visual features from the medical images. The VRM is to recalibrate the visual features to enhance the representation of crucial content. The GEM can capture and integrate contextual information to ensure the coherence and accuracy of reports, and a report generator (RG) can generate the final radiology medical report. The overall structure of VRGE is shown in Figure 2.
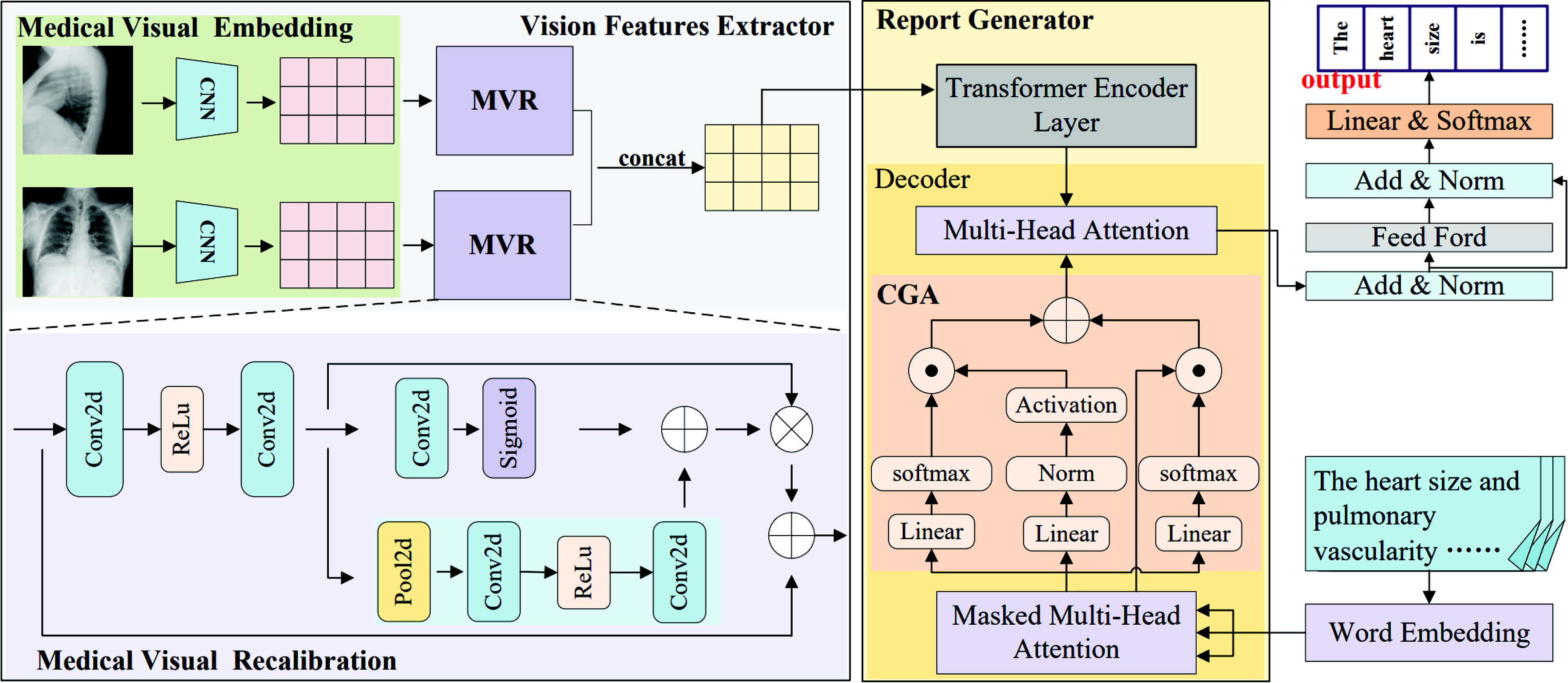
This is the overall structure of visual recalibration and gating enhancement network, which contains four core modules: Visual embedding module (VEM), Visual recalibration module (VRM), Gating enhancement module (GEM) and report generator (RG). CNNs, Convolutional Neural Networks.
The visual features representation utilizes the VEM and the VRM. These components concentrate on the lesion part and enhance the detection of abnormal visual characteristics within radiological images. This approach is designed to mitigate the impact of data bias, allowing for more subtle and accurate feature extraction from medical images.
Visual embedding module
The VEM takes radiological medical images
After forward propagation through ResNet-101, the medical image
Following VEM, we derive a sequence of visual features from radiological imaging. Subsequently, a VRM is utilized to enhance the capability in recognizing crucial structures and lesion positions within medical images.
Since visual data bias and the uneven allocation of visual features, normal visual features dominate, whereas abnormal parts occupy a relatively small proportion. As the number of layers in deep neural networks increases, low-level image features tend to be diminished by the uppermost deep layers.
To address this issue, the residual blocks (RBs) introduces a skip connection mechanism, enabling the model to deliver input features directly to subsequent layers, which can capture affluent semantic information. To diagnose and analyze radiological medical images more accurately, VRM introduces RBs to capture critical visual features. This strategy effectively utilizes RBs to capture positive visual feature representations in medical images, especially in balancing normal and abnormal visual features. By fully utilizing RBs, the VRGE can efficiently focus on abnormal visual features, significantly improving the model’s performance. VRM can help address data bias and imbalanced feature distribution issues and enhance the model’s expressive ability when facing deep neural network structures, enabling it to accurately capture critical information in medical images.
We take
Additionally, VRM incorporates channel attention (CA) and spatial attention (SA) to boost the VRGE’s capacity in extracting abnormal features. Employing operations like squeeze, excitation, and scaling, it dynamically enhances attention toward crucial features within input visual features. CA facilitates the adaptive learning of lesion-related visual features, improving the discernibility and expressiveness of visual features for disease-related information in medical images. The
The spatial attention mechanism can accurately focus on local lesion areas in medical images. Enhancing the attention to abnormal regions enables the model to explore the details and microstructure of medical images more deeply. At the same time, spatial attention effectively promotes the model to integrate contextual information across scales, which can help VRGE to understand image content comprehensively and enhance the model’s lesion detection performance in medical image analysis.
We combine the visual features of CA and SA to obtain the final VRM feature results.
Integrating a GEM in the decoder aims to improve the Transformer’s context-related understanding. GEM addresses text data bias and medical reports’ long-distance dependencies. GEM effectively tackles the challenge of long text dependencies by introducing information and state gates and captures contextual information from text reports. GEM identifies the imbalanced distribution of lesion information in the report and associates these details to improve the ability of VRGE to extract key disease details.
In the decoding process, the word embeddings of the radiological reports are initially input to the masked multi-head attention within the decoder. This step aims to derive contextual representations
An information gate is activated to regulate the flow of information and amplify the significance of lesion-related areas. The progression is detailed as follows:
Subsequently, the context representation
The result yielded by the GEM module is:
Regarding the report generator, we utilize a Transformer encoder and Transformer decoder (Vaswani et al., 2017). In the decoder, we incorporate the GEM to merge positive features and vital details from radiological contents. The GEM is designed to associate and integrate contextual information, addressing the challenge of long-text dependencies.
Transformer encoder
In this part, we elaborate the operation flow of the Transformer encoder utilized for recalibrated visual features
Initially, the recalibrated visual feature sequence
Then, we use attention mechanism to capture key abnormal representations in recalibrated visual features, and the calculation process is as follows:
Then, the multiple attention heads' results are concatenated as follows:
Following the MHA, the last output
We incorporate the GEM in Transformer decoder. The GEM focuses on pathology contextual contents within medical text sequences, enhancing the VRGE’s capability to obtain valuable text feature and generate detailed descriptions.
After the above steps of calculation, the calculation of the radiology report can be formulated as:
Datasets
Following the previous approach (Chen et al., 2020), we evaluate our model using available IU X-Ray datasets.
Evaluation metrics
To evaluate the reports generated by the VRGE, we utilize various metrics, such as BLEU-n (
Baseline models
To demonstrate the model’s efficacy, we compare VRGE with other models:
NIC* (Vinyals et al., 2015): It utilizes CNN in place of RNN to extract comprehensive visual details from image data and employs RNN to generate the ultimate text output. Show Attend and Tell (SA&T)* (Xu et al., 2015): It introduces an attention-based method for generating descriptions, integrating hard and soft attention to extract valuable image elements for generating elaborate semantic characterizations. Hybrid Retrieval-Generation Reinforced Agent (HRGR-Agent) (Li et al., 2018): This model adopts a hierarchical retrieval mechanism and reinforcement learning methods, combining advanced retrieval and low-level generation modules to generate structurally balanced radiological medical reports. CoAttention radiology report generation model (COATT) (Jing et al., 2018b): It designs a multitasking learning framework, which introduces a common attention mechanism to locate abnormal medical image feature regions and establishes a hierarchical LSTM architecture to generate rich text reports. Generating radiology reports via memory-driven transformer (R2Gen) (Chen et al., 2020): It employs a relational memory driver module into the Transformer encoder to record key information from previous processes, enhancing the encoder’s decoding ability and generating semantically rich radiological medical reports. Generating radiology reports via memory-driven transformer, Cross-modal Memory Networks (R2GenCMN) (Chen et al., 2022): It introduces a memory query and response module to associate text and image information more effectively, improving the consistency and richness of generated radiological reports. Posterior-and-Prior Knowledge Exploring-and-Distilling approach (PPKED) (Liu et al., 2021a): This model integrates multi-domain knowledge extractors to explore prior and posterior knowledge to alleviate text and data bias, thereby enhancing the consistency and richness of generated reports.
Our experimental setup chooses ResNet-101 as the medical imaging visual encoder trained on ImageNet. We set the size of each medical image as
We set the beam size to 3 to balance the quality of generated reports and computational efficiency. The entire experiment is trained on an NVIDIA 3080 GPU, with a maximum number of training rounds of
EXPERIMENT AND ANALYSIS
Main experiments
In our experimentation, we conduct a comparative analysis of the proposed VRGE model using the IU X-Ray dataset. Table 1 illustrates the outcomes, revealing that our VRGE model achieve SOTA performance. A detailed comparison against the PPKED model, as indicated in Table 1, showcases the superior performance of our model across various key metrics. There are notable improvements in BLEU-n (
Comparison of Experimental Results with Other Models on the IU X-Ray
Comparison of Experimental Results with Other Models on the IU X-Ray
Moreover, our model demonstrates enhancements in various other evaluation metrics. The METEOR score surpasses the PPKED by 2.8%, underscoring our model’s proficiency in producing accurate and fluent radiology medical reports. The ROUGE-L further demonstrates a 3.5% enhancement in VRGE compared to PPKED, signifying substantial progress in generating coherent disease descriptions. In short, the VRGE achieves advancements in accuracy, coherence and fluency in report descriptions. The enhancement of the VRGE model is notable, as it reflects the model’s capacity to produce reports with heightened linguistic fluency and coherence.
We perform dedicated experiments for every module using the IU X-Ray dataset to validate the efficiency of the VRM and GEM. In these experiments, we systematically evaluate the performance of each module to assess their contributions to the overall model efficacy. Specifically, we isolate the impact of the VRM and GEM by conducting controlled experiments, allowing us to demonstrate their influence on the quality and accuracy of the generated medical reports.
Effect of the VRM
To prove the efficacy of the VRM, we remove it from the VRGE model. We conduct experiments using BLEU-n, METEOR, and ROUGE-L to evaluate its impact on model performance. From the results in Table 2, it can be observed that after removing the VRM, BLEU-n (
Result of the Ablation Experiment on the IU X-Ray
Result of the Ablation Experiment on the IU X-Ray
The boldface represents the highest performance.
This experiment demonstrates the importance of the VRM. Its removal resulted in performance degradation, especially in the Bilingual Evaluation Understudy (BLEU) and METEOR evaluation metrics, indicating that the module is crucial to capture anomaly detection in radiological medical images, enhancing visual features of anomaly detection, and alleviating data bias. These results emphasize this module’s contribution to the model’s overall performance and support its effectiveness in generating radiology medical image reports.
To verify the effectiveness of the GEM, we remove it from the VRGE model and conduct experiments to evaluate its impact on model performance. The results in Table 2 prove the efficacy of the GEM. After removing the GEM, we observe a significant decrease in various indicators. Specifically, BLEU-1, BLEU-2, BLEU-3, and BLEU-4 decreased by 0.7%, 1.2%, 1.1%, and 1.1%, respectively. Moreover, METEOR and ROUGE-L are 2.0% and 4.3% lower than VRGE, respectively. This series of experimental results demonstrates the crucial role of the GEM in model performance. Its removal results in a significant decrease in performance metrics, especially in BLEU and METEOR evaluations. This indicates that the GEM effectively utilizes contextual information to generate coherent and consistent radiological reports. Further analyzing the experimental results, we find that adding the GEM improves the fluency of language generation and helps solve the long-distance dependencies overall. This confirms the importance of the GEM in generating radiological reports, providing reliable support for improving the model’s understanding of medical image context and accurate report generation.
CASE Study
To further examine the feasibility of the VRGE model in clinical practice, we randomly select three cases in the IU X-Ray data set for in-depth analysis, as shown in Figure 3. We compare the differences between the radiology medical reports generated by VRGE on the test set with those generated by the Transformer, R2GenCMN methods, and Ground Truth. In the comparison, we utilize different color identifications, where red represents descriptions of organs, and blue underlined represents similar descriptions to ground truth.

Cases of the IU X-ray generated reports. Our results are compared with the ground truth, the Transformer method and R2GenCMN method. Red indicates organs, and blue underline indicates that each model is close to the description of ground truth.
For the first case, the report generated by VRGE aligns more closely with the ground truth, unlike the Transformer model, which fails to recognize “left infrahilar region.” Notably, VRGE can identify crucial abnormal findings in radiological images, such as “Calcified lymph identified,” a detail overlooked by the other two models. This underscores the emphasis of the proposed VRGE model on effective anomaly detection in medical images.
For the second case, it is evident that the report generated by VRGE provides a thorough and exhaustive contents of the medical image compared to the other two models. Furthermore, our model successfully identifies “no focal consolidation pneumothorax,” a detail overlooked by the Transformer model.
For the last case, compared to other methods, VRGE generates comprehensive medical reports. Notably, it can identify and generate exceptions absent in the Transformer and R2GenCMN methods, such as “slight vascular capitation.”
Recently, deep learning has demonstrated remarkable success in radiology report generation. However, there is a pressing need for further research in several key areas, notably model interpretability and data privacy security. Meanwhile, radiologists find it challenging to believe in inexplicable systems. As these systems become more sophisticated, it becomes essential for the results and reasoning processes to be interpretable. This interpretability can promote confidence in the generated reports and enhance the model’s utility in clinical decision-making. Moreover, given that radiology reports often include sensitive information, ensuring robust privacy protection measures is imperative.
In conclusion, while deep learning has shown promising results in radiology report generation, ongoing research efforts should prioritize enhancing model interpretability and implementing robust privacy measures. This approach ensures the responsible and ethical deployment of these technologies in the health care domain, promoting both efficacy and patient trust.
CONCLUSION
This article designs a model, VRGE, to generate radiological medical reports automatically. We develop a dedicated visual recalibration module to boost the VRGE’s capabilities in capturing essential lesion features. This module enhances the VRGE’s attention to crucial visual areas within medical images and mitigates visual data bias. Additionally, our approach incorporates a GEM, which effectively aggregates pertinent contextual elements. By extracting text descriptions associated with lesions, this module enables the model to filter out irrelevant information, addressing long-distance dependency issues and textual data bias. The results obtained from experiments on the IU X-Ray dataset highlight that the VRGE model outperforms other previous baseline models significantly.
Footnotes
AUTHOR DISCLOSURE STATEMENT
The authors declare they have no conflicting financial interests.
FUNDING INFORMATION
This work is supported by grant from the Natural Science Foundation of China (No. 62072070).