We describe lossless compressed data structures for the colored de Bruijn graph (or c-dBG). Given a collection of reference sequences, a c-dBG can be essentially regarded as a map from k-mers to their color sets. The color set of a k-mer is the set of all identifiers, or colors, of the references that contain the k-mer. While these maps find countless applications in computational biology (e.g., basic query, reading mapping, abundance estimation, etc.), their memory usage represents a serious challenge for large-scale sequence indexing. Our solutions leverage on the intrinsic repetitiveness of the color sets when indexing large collections of related genomes. Hence, the described algorithms factorize the color sets into patterns that repeat across the entire collection and represent these patterns once instead of redundantly replicating their representation as would happen if the sets were encoded as atomic lists of integers. Experimental results across a range of datasets and query workloads show that these representations substantially improve over the space effectiveness of the best previous solutions (sometimes, even dramatically, yielding indexes that are smaller by an order of magnitude). Despite the space reduction, these indexes only moderately impact the efficiency of the queries compared to the fastest indexes.
INTRODUCTION
The colored de Bruijn graph (c-dBG) has become a fundamental tool used across several areas of genomics and pangenomics. For example, it has been widely adopted by methods that perform read mapping or alignment, specifically with respect to RNA-seq and metagenomic identification and abundance estimation (Almodaresi et al., 2021; Almodaresi et al., 2018; Bray et al., 2016; Liu et al., 2016; Mäklin et al., 2020; Reppell and Novembre, 2018; Schaeffer et al., 2017; Skoufos et al., 2022), among methods that perform homology assessment and mapping of genomes (Minkin and Medvedev, 2020a, b), for a variety of different tasks in pangenome analysis (Cleary et al., 2019; Dede and Ohlebusch, 2020; Lees et al., 2020; Luhmann et al., 2021; Manuweera et al., 2019) and for storage and compression of genomic data (Rahman et al., 2023). In most of these applications, a key requirement of the underlying representation of the c-dBG is to be able to determine—with efficiency being critical—the set of references (or “colors”) in which an individual k-mer appears. This set is named the color set of a k-mer1. These motivations bring us to the following problem formulation.
Problem 1 (Colored k-mer indexing). Let be a collection of references. Each reference is a string over the DNA alphabet . We want to build a data structure (referred to as the index in the following) that allows us to retrieve the set ColorSet(x) = { i | x ∈ Ri } as efficiently as possible for any k-mer . If the k-mer x does not occur in any reference, we say that ColorSet(x) = ∅.
Of particular importance for biological analysis is the case where is a pangenome. Roughly speaking, a pangenome is a (large) set of genomes in a particular population, species, or closely related phylogenetic group. Pangenomes have revolutionized DNA analysis by providing a more comprehensive understanding of genetic diversity within a species (Baier et al., 2016; Marcus et al., 2014). Unlike traditional reference genomes, which represent a single individual or a small set of individuals, pangenomes incorporate genetic information from multiple individuals within a species or group. This approach is particularly valuable because it captures a wide range of genetic variations, including rare and unique sequences that may be absent from any particular reference genome.
Contributions. The goal of this article is to propose compressed data structures to solve Problem 1 focusing on the specific, important, application scenario where is a pangenome. We note, however, that the approaches described herein are general, and expect them to work well on any corpus of highly related genomes, whether or not they formally constitute a pangenome. To best exploit the properties of Problem 1, we capitalize on recent indexing development for c-dBGs (Fan et al., 2024) that exploit an order-preserving dictionary of k-mers (Pibiri, 2023; Pibiri, 2022) to map k-mers to color sets in succinct space. This efficient mapping allows us to logically distinguish the problem of representing the dictionary of k-mers from that of representing the color sets. In this article, we therefore focus entirely on the latter problem.
We present two different solutions for the problem of representing the color sets in compressed space and explain how to combine them for even greater space reduction. These solutions are both based on the paradigm of partitioning the color sets into patterns that repeat across the whole collection of color sets. These patterns are encoded once in our data structures, thus avoiding unnecessary redundancy for their representation. This is in net contrast to previous methods in the literature, such as Fulgor (Fan et al., 2024) and Themisto (Alanko et al., 2023b), that represent distinct color sets only once, but which otherwise consider color sets as individual atomic integer lists and allow for repeated patterns within the color sets. Methods such as Mantis (Almodaresi et al., 2020) and MetaGraph (Karasikov et al., 2020b) do consider shared patterns and implement distinct but related forms of “differential” encoding, though the approaches are quite different from those introduced here and seem to require a larger sacrifice in query speed.
After covering preliminary concepts on efficient indexing of c-dBGs in Section 2, we review related work and the state of the art in Section 3. Section 4 describes our repetition-aware compression algorithms for color sets. In Section 5, we present a simple framework to build these compressed data structures. Section 6 presents experimental results to demonstrate that exploiting the repetitiveness of color patterns grants remarkably better compression effectiveness. As a result, the proposed solutions supersede all previous approaches in the literature as they essentially combine the space effectiveness of the most compact methods with the query efficiency of the fastest solutions. This better efficiency comes at the expense of a slower construction algorithm. However, we do not regard this as a serious limiting aspect. We conclude in Section 7 where we also discuss some promising future work.
PRELIMINARIES: MODULAR INDEXING OF c-dBGs
In principle, Problem 1 could be solved using a classical data structure from information retrieval—the inverted index (Pibiri and Venturini, 2021). The inverted index is the backbone of virtually any retrieval system, mapping “terms” (e.g., words in natural language, or bag of words such as n-grams, etc.) to the sorted lists of (the identifiers of) the documents that contain such terms. These sorted lists are called inverted lists. In the context of this problem, the indexed documents are the references in the collection and the terms of the inverted index are all the distinct k-mers of . Using the notation from Problem 1, it follows that ColorSet is the inverted list of the term x. Let denote the inverted index for . The inverted index explicitly stores ColorSet(x) for each k-mer . The goal is to implement the map x → ColorSet(x) as efficiently as possible in terms of both memory usage and query time. To this end, all the distinct k-mers of are stored in a dictionary . Let n indicate the number of distinct k-mers in . These k-mers are stored losslessly in . To be useful for this problem, the dictionary should be associative, that is: to implement the map x → ColorSet(x), is required to support the operation Lookup(x), which returns if k-mer or a unique integer identifier in if .
Problem 1 can then be solved using these two data structures— and —thanks to the interplay between Lookup(x) and ColorSet(x): logically, the index stores the sets {ColorSet(x)}x∈ in some compressed form, sorted by the value returned by Lookup(x).
To exploit at best the potential of this modular decomposition into and , it is essential to rely on the specific properties of Problem 1. For example, we know that consecutive k-mers share -length overlaps; also, k-mers that co-occur in the same set of references have the same color set. A useful, standard, formalism that captures these properties is the so-called c-dBG.
Let be the set of all the distinct k-mers of . The node-centric dBG of is a directed graph whose nodes are the k-mers in . There is an edge if the -length suffix of u equals the -length prefix of v. Note that the edge set E is implicitly defined by the set of nodes, and can therefore be omitted from subsequent definitions (there is a one-to-one correspondence between a dBG and a set of k-mers). We refer to k-mers and nodes in a dBG interchangeably. Likewise, a path in a dBG spells the string obtained by concatenating together all the k-mers along the path without repeating the shared -length overlaps. In particular, unary (i.e., nonbranching) paths can be collapsed into single nodes spelling strings that are referred to as unitigs. Let be the set of unitigs of the graph. The dBG arising from this compaction step is called the compacted dBG, and indicated with .
The colored compacted dBG (c-dBG) is obtained by logically annotating each k-mer x with its color set, ColorSet(x). While different conventions have been adopted in the literature, here we assume that only nonbranching paths with nodes having the same color set are collapsed into unitigs. The unitigs of the c-dBG we consider in this work have the following key properties.
Unitigs spell references in. Each distinct k-mer of appears once as a substring of some unitig of the c-dBG. By construction, each reference can be spelled out by some tiling of the unitigs—an ordered sequence of unitig occurrences that, when glued together [accounting for (k − 1)-symbol overlap and orientation], spells exactly (Fan et al., 2023). Joining together k-mers into unitigs reduces their storage requirements and accelerates looking up k-mers in consecutive order (Pibiri, 2022).
Unitigs are monochromatic. The k-mers belonging to the same unitig all have the same color set. We write to indicate that k-mer x is a substring of the unitig . Thus, we shall use ColorSet(ui) to denote the color set of each k-mer . This suggests that a single color set should be represented per unitig rather than for each k-mer.
Unitigs co-occur. Distinct unitigs often have the same color set, i.e., they co-occur in the same set of references because they derive from conserved sequences in indexed references that are longer than the unitigs themselves. Hereafter, we indicate with z the number of distinct colors set . Note that and that, in practice, there are almost always many more unitigs than there are distinct color sets.
Figure 1a illustrates an example of c-dBG with these properties. In the following sections, we refer to a compacted c-dBG as .
In panel (a), an example c-dBG for with three colors (1, 5, and 8) highlighted. (In the Fig., a k-mer and its reverse complement are considered as different k-mer for ease of illustration. In practice, these are considered identical.) The unitigs of the graph are colored according to the set of references they appear in. In panel (b), we schematically illustrate the state-of-the-art index layout (as used in the Fulgor index (Fan et al., 2024)) assuming the c-dBG was built for references, showing the modular composition of a k-mer dictionary, , and an inverted index, . Note that unitigs are stored in in color set order (i.e., unitigs mapping to the same color set are placed consecutively in the dictionary), thereby allowing a very efficient mapping of k-mers to their distinct colors.
The modular indexing layout described in this section allows us to logically divide Problem 1 into two subproblems: (1) that of representing k-mer sets under Lookup queries, and (2) that of compressing the collection of color sets . This work specifically targets the latter problem. Our solutions are presented in Section 4.
RELATED WORK
The data structures proposed in the literature to represent c-dBGs, and that fall under the “color-aggregative” classification (Marchet et al., 2021), all provide different implementations of the modular indexing framework as described in Section 2. As such, they require two data structures: (1) a k-mer dictionary and (2) an inverted index. The methods reviewed below differ in the choice of the dictionary and the compression scheme for the inverted index.
For example, Themisto (Alanko et al., 2023b) makes use of the spectral Burrows-Wheeler transform (SBWT) data structure (Alanko et al., 2023a) for its k-mer dictionary and an inverted index compressed with different strategies based on the sparseness of the color sets (i.e., the ratio ). Mantis (Almodaresi et al., 2022; Almodaresi et al., 2020; Pandey et al., 2018) makes use of the counting quotient filter (Pandey et al., 2017) for the dictionary data structure, and in its most space-efficient variant represents the color sets by deduplicating them and expressing them differentially as edits performed along the branches of an approximate minimum spanning tree over the color sets. MetaGraph (Karasikov et al., 2020b) uses the BOSS (Bowe et al., 2012) data structure for the dictionary and exposes several general schemes to compress metadata associated with k-mers (Karasikov et al., 2020b, 2022), which essentially constitute an inverted index. Bifrost (Holley and Melsted, 2020) instead, uses a (dynamic) hash table to store the set of unitigs and an inverted index compressed with Roaring bitmaps (Lemire et al., 2018). The compact bit-sliced (COBS) index (Bingmann et al., 2019) can be considered as an approximate c-dBG in that ColorSet(x) might contain false positives, i.e., spurious reference identifiers (but never false negatives). This is a consequence of building a Bloom filter (Bloom, 1970) for each reference, filled with all the k-mers in the reference. The Bloom filter matrix is stored in an inverted manner, and represents a collection of approximate color sets. Being approximate, this method completely avoids the space consumption of the exact k-mer dictionary and the space is all due to the approximate color sets.
However, none of these solutions simultaneously exploit all three unitig properties listed in Section 2 to achieve faster query time and better space effectiveness. More specifically, Themisto disregards Property 1 as a direct consequence of using the SBWT data structure that internally arranges the k-mers in colexicographic order and not in their order of appearance in the unitigs. This translates to an overhead of bits2 per k-mer to associate a k-mer to its color set (we recall that z indicates the number of distinct color sets in our discussion). This consideration is also valid of the BOSS data structure, hence for MetaGraph and the counting quotient filter data structure and hence for Mantis. Themisto exploits Property 3 instead, by compressing only the set of the distinct color sets. Alanko et al. also describe how it is possible in Themisto to reduce the space for the mapping from k-mers to colors by spending bits for only some k-mers (called core k-mers in their work), while instead using bits per k-mer for all the others. However, this still requires dedicated storage per-k-mer, thus failing to exploit Property 2. COBS does not exploit any specific property, instead: unitigs are broken into their constituent k-mers and indexed separately; looking up consecutive k-mers (most likely part of the same unitig) has no locality of reference due to Bloom filter lookups; color sets are stored approximately and partitioned into shards, so that a ColorSet(x) query has to combine several partial results together.
State of the art. To the best of our knowledge, the only solution that exploits all the three properties is the recently introduced Fulgor index (Fan et al., 2024). The solution adopted by Fulgor is to first map k-mers to unitigs using , and then succinctly map unitigs to their color sets. By composing these two mappings, Fulgor obtains an efficient map directly from k-mers to their associated color sets. Refer to Figure 1b for an illustration of this index. The composition is made possible by leveraging the order-preserving property of its dictionary—SSHash (Pibiri, 2023; Pibiri, 2022)—which explicitly stores the set of unitigs in any desired order. This property has some important implications. First, looking up consecutive k-mers is cache-efficient since unitigs are stored contiguously in memory as sequences of 2-bit characters. Second, if k-mer x occurs in unitig , the Lookup(x) query of SSHash can efficiently determine the unitig identifier i, allowing to map k-mers to unitigs. Third, if unitigs are sorted in color set order, so that unitigs having the same color set are consecutive, then mapping a unitig identifier i to its color set identifier, ColorSet-ID(i), can be implemented in as little as bits per unitig and in constant time. This is achieved using a succinct Rank query, as explained in Fact 1 below.
Given a bitvector b[1..u], we let Rank1 be the number of bits set in , for any . It is possible to answer Rank queries in using just bits on top of the plain bitvector b (Jacobson, 1989).
Fact 1. Consider a sorted collection of u items where are distinct. Call the i-th item in the sorted order. Given an index , we can determine in without storing all the u items explicitly, as follows. We keep the f distinct items in an array A[1..f] and build a bitvector b[1..u] where: if and only if for any and . (Note that b has exactly f bits set.) With b and A, we recover as A[p] where p = Rank1(b,i) + 1. Apart from the space of A which is at most that of the original collection because , this solution spends bits per item.
We used Fact 1 to succinctly map unitigs to their color sets in Fulgor by letting vi = ColorSet − ID(i) and the array A be . We will use Fact 1 in this article as well.
Finally, the color sets themselves are compressed in Fulgor using three different encodings based on the ratio . If , then the set is considered sparse and the differences between consecutive integers are computed and encoded with Elias’s code (Elias, 1975). If, instead, , the set is considered very dense and the complementary set is compressed using the method explained before. Finally, if , the set is dense and represented as a bitvector of N bits where the j-th bit is set if color . Note that each set is thus encoded individually from the other sets in .
REPETITION-AWARE COMPRESSION FOR c-dBGs
When indexing large pangenomes, the space taken by the color sets , even in compressed format, dominates the whole index space (Alanko et al., 2023b; Fan et al., 2024; Holley and Melsted, 2020). Efforts toward improving the memory usage of c-dBGs should therefore be spent in devising better compression algorithms for the color sets. In this work, we focus on exploiting the following crucial property that can enable substantially better compression effectiveness: The genomes in a pangenome are very similar. This, in turn, implies that the color sets are also very similar (albeit distinct).
By “similar” sets we mean that they share many (potentially, very long) identical integer subsequences. This property is not exploited if each set is compressed individually from the other sets. For example, if set shares a long subsequence with , this subsequence is actually represented twice in the index, which wastes space. We refer to such shared subsequences as “patterns” in the following. Consider Figure 2 for some examples. The pattern [3, 5, 9, 11] repeats in , , and , hence it is represented redundantly three times. The longer pattern [1, 3, 11, 12, 13, 14, 16] repeats twice instead. These examples are instrumentally simple; yet, they suggest that the identification of such patterns across a large collection, as well as the design of an effective compression mechanism for these patterns, is not easy. A further complicating matter is that these patterns can repeat in many sets (not just two or three), hence increasing the pangenome redundancy and aggravating the memory usage of an index that encodes them redundantly in the many sets where they appear.
The color sets from Figure 1b where we highlight some “patterns” (i.e., repetitive subsequences) that repeat across different sets, like [3, 5, 9, 11] and [1, 3, 11, 12, 13, 14, 16].
To address this issue, we propose here two solutions based on partitioning the color sets with the intent of factoring out repetitive patterns. Encoding such repetitive patterns once clearly reduces the amount of redundancy in the representation, which improves the space of the data structures. We explore the effectiveness of two different partitioning paradigms which, for ease of visualization, we refer to as horizontal partitioning (Section 4.1) and vertical partitioning (Section 4.2). Figure 3 shows an example of partitioning that we will refer to in the following sections. In Section 4.3, we argue that these two partitioning paradigms can be combined to improve compression even further.
The color sets from Figure 1b, respectively partitioned horizontally (a) and vertically (b). Intuitively, partitions of “similar” rows are created by horizontal partitioning; vice versa, partitions of similar columns are created by vertical partitioning.
Before presenting the details of our solutions, we first establish the following fact. Given an integer , let be a partition of of size . Let an order between the elements of each be fixed (for example, by sorting the elements in increasing order).
Fact 2. Any induces a permutation , defined as where for and , for and .
Consider the following example for and . Suppose , , and . The boundaries are therefore , , , and . The induced permutation can be visualized by concatenating the sets from to 3 and assigning “new” identifiers, from 1 to q, in this concatenated order:
which results in , , , etc., that is .
Horizontal partitioning: Representative and differential color sets
The first solution we present explores horizontal partitioning. In short, the general idea is that of partitioning the sets in into groups of similar sets (see Fig. 3a for an example); then, for each group, a representative color set is built and all sets in the group are encoded via a differential set with respect to the representative one.
Definition. Let be a partition of [z], of size , and let be its corresponding permutation as established by Fact 2. For each , we build a set in some way that we will explain shortly and represent the set as for all . Notation stands for the symmetric difference between the sets X and Y, and it is . The idea is that the set should include the most repetitive patterns that occur in the sets of partition , so that each difference is small. Since should capture the repetitiveness of , it is named the representative color set of . The symmetric difference is instead called the differential color set of with respect to . We indicate with the set of all representative color sets. Note that as we have one representative per partition. Similarly, we indicate with the set of all differential color sets, where as we have one differential color set for each original set in .
Both sets, and , are therefore made up of sequences of increasing integers that can be compressed effectively using a plethora of different methods (Pibiri and Venturini, 2021). We discuss implementation details in Section 6.
Compared to a c-dBG , its differential-colored c-dBG (or, Dfc-dBG) variant is the graph where the set of nodes, , is the same as that of G but the sets in are factorized into and . We now illustrate an example of how the sets in can be modeled via and .
Example. Let us consider the partitions from Figure 3a for the color sets as highlighted by different shades, i.e., , , and . Assume the following representative color sets, , , and , are built.
We then obtain the following differential color sets.
Note how the pattern [3, 5, 9, 11] shared by all the three sets , , and is now encoded once in the representative set and implicitly encoded in each differential set , , and . Consider the pattern [1, 3, 11, 12, 13, 14, 16] shared by and for another example (in this case, the pattern is exactly equal to the representative set ). If, instead, the representative color set does not include patterns that appear in sufficiently many sets in its partition, then the representation is wasteful. This is the case, in this example, for the set . In the worst case, when the intersection between and is empty, then , which is more than storing the set itself.
To conclude, Figure 4 shows all the components of the Dfc-dBG from this example. Most important, note that the order of the sets has been permuted according to to efficiently determine the partition of any given color set identifier as to perform decoding of the set (see the following discussion for more details).
The Dfc-dBG layout derived from the color sets in Figure 1b. Most important, note that color sets are stored in the order given by the permutation induced by the horizontal partitioning. This allows mapping a color set identifier to its partition in very succinct space. Note that also the unitigs in are resorted following the permuted order of the color sets.
Discussion. We now discuss the salient features of the introduced Dfc-dBG. All in all, the Dfc-dBG saves space compared to the original c-dBG with only a minor slowdown when performing a ColorSet(x) query.
As already explained, if the representative color sets include the most repetitive patterns in their respective partitions, then the size of differential color sets is expected to be small, thereby reducing the amount of integers that are represented in the index. This clearly saves space compared to because the memory usage of the index is proportional to the number of integers being encoded.
The order in which the differential color sets are stored in the index is not necessarily , as illustrated in the layout from Figure 1b. The order is instead obtained by applying to [z]. In our example from Figure 4, the permutation is [1, 4, 2, 3, 6, 5, 7, 8], hence the color sets are stored in the order , given that , , , etc. So, color sets belonging to the same partition are placed consecutively by . This clearly permits to determine the partition a color belongs to in an efficient way, e.g., using Fact 1. Specifically, we use a binary vector b[1..z] and let if and only if i is the position of the last color set of a partition. Continuing our example, we have
where because the third, the fifth, and the eighth color set in the permuted order are the last in their respective partitions. To conclude, using extra bits per color, we can compute the partition of color as in constant time as per Fact 1.
Finally, it is efficient to decode from . By definition of symmetric set difference, it follows that . Hence decoding corresponds to computing the symmetric difference between the representative color set and the differential color set. This can be simply implemented in time linear in the size of the two sets. Note that (with equality holding only when ), hence decoding takes more time than just scanning the original color . This imposes some overhead compared to any representation encoding each set individually. However, as we are going to see in Section 6, this overhead is not much because decoding is cache-friendly.
The optimization problem. The effectiveness of the Dfc-dBG evidently depends on the choice of the partition , i.e., what color sets to cluster together, and the choice of the representative for each partition . Intuitively, one would like to group similar color sets together and let their shared patterns be included in their representative color set. On one hand, the number of partitions, r, should not be too large to amortize the cost of the representative color sets; on the other hand, smaller partitions better highlight the repetitiveness of the patterns in the collection. In the following section, let be the encoding cost of the sorted list L according to some encoding method. We can formally state the optimization problem faced by the Dfc-dBG representation as follows. We call it the minimum-cost partition arrangement (MPA) problem for Dfc-dBG.
Problem 2 (MPA for Dfc-dBG). Let be the compacted c-dBG built from the reference collection , where . Determine the partition of [z] for some and the sets such that is minimum.
We suspect this problem is hard depending on the chosen encoding method. Instead, we prove the following.
Theorem 1. Given a partition of [z] of size , let and
where denotes the number of occurrences of the integer x in the color sets of . Then the cost is minimum.
The rationale behind the choice is to minimize the number of integers being encoded in the differential color sets, which is the most expensive component in the Dfc-dBG.
Proof. By contradiction. Assume is optimal and there exists an integer such that . This means that there are differential color sets containing x. Let . We can therefore remove x from to obtain a new solution such that
where the last inequality holds because . Solution has therefore a lower cost than . This contradicts the initial assumption that Ai is optimal.□
The representative color sets in Figure 4 and in all previous examples are built with the strategy described in Theorem 1. Consider, for example, the color sets in the partition from Figure 3a. In this case, and , so any integer appearing at least twice among those in , , and is included in . Specifically, we have , , , , etc. It is easy to see that the only two integers that cannot make it into are 4 and 15 since . In conclusion, we have .
The quantities can be computed by iterating through all color sets in once and, given that there are at most N distinct integers in each partition , the sets are computed in a total of time.
Vertical partitioning: Partial and meta color sets
In this section, we present a second solution, based on vertical partitioning (see Fig. 3b for an example). Now, each color set in is spelled by a list of references, or meta colors, to smaller repetitive patterns that we call partial color sets.
Definition. Let be a partition of [N], of size , and refer to as its induced permutation as per Fact 2. We assume from now on that the N reference identifiers and the integers in the sets of have been permuted according to . After the permutation, determines a partition of into r disjoint sets:
Let be the set
for . The elements of the set are the partial color sets induced by the partition . We indicate with the set of all partial color sets. In simple words, is the set obtained by considering the distinct color sets only for the references in the i-th partition , noting that—by construction—they comprise integers x such that . The idea is that the set forms a dictionary of subsequences (the partial color sets) that spell the original color sets . Let us now formally define this spelling.
Let be a color set. A meta color is an integer pair indicating the sublist if there exists such that , for . It follows that can be modeled as a list of at most r meta colors. We indicate with the set of all meta color sets.
We have therefore obtained a representation of that consists of the sets and . These sets are, again, made up of integer sequences that can be further compressed. For the experiments in Section 6, we will choose a suitable compression methods for these sets.
Given , the meta-colored c-dBG (or, Mac-dBG) is the graph where the set of nodes, , is the same as that of G but the color sets in are represented with the partial color sets and the meta color sets . We now illustrate an example.
Example. Let us consider the color sets from Figure 1b, for . Let and , , , , assuming we use the natural order between the integers to determine an order between the elements of each . Thus, we have , , , and . The corresponding permutation is therefore [1, 11, 6, 12, 7, 13, 9, 14, 8, 15, 10, 2, 3, 4, 16, 5]. Now we apply the permutation to each color set, obtaining the following permuted color sets (vertical bars represent the partial color set boundaries ).
For example, set , that before was [3, 4, 5, 9, 10, 11, 13, 15] (see Fig. 1b), now is
or [3, 6, 7, 8, 10, 12, 15, 16] once sorted. The partial color sets are the distinct sub-sequences in each partition of the permuted color sets. For example, is the set of the distinct subsequences in partition 1, i.e., those comprising the integers x such that . Hence, we have five distinct partial color sets in partition 1, and these are [3], [1], [1, 3], [1, 2, 3, 4, 5], and [2, 5]. Most important, note that from the integers in the partial color sets of partition we can subtract the lower bound . For example, we can subtract from the integers of [6, 7, 8] that is the partial color set used in the partition 2 of , to obtain [1, 2, 3]. Overall, we thus obtain that comprises four partial color sets, as shown in Figure 5. The figure also shows the rendering of the color sets via meta color lists, i.e., how each color can be spelled by a proper concatenation of partial color sets.
The Mac-dBG layout derived from the color sets in Figure 1b. Note that the partial color set shared between and is now represented once as a direct consequence of partitioning, and indicated with the meta color instead of replicating the five integers it contains in both and . The same consideration applies to other shared subsequences.
Discussion. The Mac-dBG permits to encode the color sets in into smaller space compared to the original c-dBG and without compromising the efficiency of the ColorSet(x) query, for the following reasons.
If is the total number of partial color sets, then each meta color can be indicated with just bits. Potentially long patterns, shared between several color sets, are therefore encoded once in and only referenced with bits instead of redundantly replicating their representation. Since partial color sets are encoded once, the total number of integers in is at most that in the original . In practice, is expected to contain a much smaller number of integers than .
Each partial color set can be encoded more succinctly because the permutation guarantees that it only comprises integers lower-bounded by and upper-bounded by . Hence, only bits per integer is sufficient.
It is efficient to recover the original color set from the meta color set : for each meta color , sum back to each decoded integer of . Hence, we decode strictly increasing integers. This is, again, a direct consequence of having permuted the reference identifiers with . Observe that, in principle, the representation of the color sets with partial/meta color sets could be described without any permutation —however, one would sacrifice space (for reason 2 above) and query time since decoding a set would eventually need to sort the decoded integers. In conclusion, permuting the reference identifiers with is an extra degree of freedom that we can exploit to improve index space and preserve query efficiency, noting that the correctness of the index is not compromised when reference identifiers are reassigned globally.
The optimization problem. As already noted in Section 4.1 for the Dfc-dBG, also the effectiveness of the Mac-dBG crucially depends on the choice of the partition and upon the order of the references within each partition as given by the permutation . There is, in fact, an evident friction between the encoding costs of the partial and meta color sets. Let and be the number of meta colors and partial color sets, respectively. Since each meta color can be indicated with bits, the meta color sets cost bits overall. Instead, let be the cost (in bits) of the partial color set according to some encoding method. On one hand, we would like to select a large value of r so that diminishes since each color set is partitioned into several, small, partial color sets, thereby increasing the chances that each partition has many repeated patterns. This will help in reducing the encoding cost for the partial color sets, i.e., the quantity . On the other hand, a large value of r will yield larger meta color sets, i.e., will increase . This, in turn, could erode the benefit of encoding shared patterns and would require more time to read the meta color sets. The MPA problem for Mac-dBG is therefore as follows.
Problem 3 (MPA for Mac-dBG). Let be the compacted c-dBG built from the reference collection . Determine the partition of [N] for some and permutation such that is minimum.
Depending upon the chosen encoding, smaller values of may be obtained when the gaps between subsequent reference identifiers are minimized. Finding the permutation that minimizes the gaps between the identifiers over all partial color sets is an instance of the bipartite minimum logarithmic arrangement (BIMLOGA) problem as introduced by Dhulipala et al. (2016) for the purpose of minimizing the cost of delta-encoded lists in inverted indexes. The BIMLOGA problem is NP-hard (Dhulipala et al., 2016). We note that BIMLOGA is a special case of MPA: that for (one partition only) and being the sum of the of the gaps between consecutive integers in the permuted set . It follows that also MPA is NP-hard under these constraints. This result immediately suggests that it is unlikely that polynomial-time algorithms exist for solving the MPA problem for the Mac-dBG.
Comparing and combining the two representations
Sections 4.1 and 4.2 introduce two solutions to the same problem; that of representing a collection of sorted integer sets taking into account for patterns of integers that repeat across the collection. These two solutions are very different, given that are based on orthogonal partitioning paradigms. As it is not therefore immediately obvious which solution may yield better results, we discuss them comparatively:
The representative/differential color set approach can capture patterns that are formed by colors not necessarily appearing in consecutive positions, whereas the approach via partial/meta color sets necessarily needs to permute the reference identifiers to be effective. The use of permuted reference identifiers is, however, beneficial for compression as it typically reduces the number of bits to encode the differences between consecutive colors in a set.
Both methods incur one extra level of indirection when decoding a color set compared to a representation that encodes each set individually. In particular, up to r partial color sets have to be accessed and decoded from their respective partitions; a representative and differential color set must be scanned simultaneously to decode . Recall, however, that while exactly integers are decoded to reconstruct using the partial/meta color set representation, the encoding with representative/differential can instead decode more than integers.
The two observations above suggest that the representation via meta/partial color sets has a net advantage over that based on representative/differential color sets. However, we argue in the following that an even improved representation can be achieved when these two paradigms are combined together. In fact, note that both the set of differential color sets and the set of partial color sets are, in turn, collections of sorted integer sets. Applying the same encoding strategy recursively would therefore seem the most straightforward option to consider. A recursive encoding makes little sense, however, as the hypothetical benefits arising from finer partitioning should have been obtained during the “outer” and only partitioning step. We therefore consider the two scenarios where: (1) the set is encoded with meta/partial color sets, and (2) the set is encoded with representative/differential color sets. Albeit possible, the former combination is not promising as the differential color sets in each partition are expected to be very different from each other rather than similar because shared patterns are captured and encoded in the representative color sets only. (In other words, if a shared pattern emerged in the differential color sets, then this pattern would have been included in the representative color set, thus reducing the “similarity” between the differential color sets.) This is also apparent from the small example from Figure 4. The latter combination, instead, retains good potential as the partial color sets in a partition tend to be similar as well. Consider the example in Figure 5.
In conclusion, we will also experiment in Section 6 with a combined representation where the partial color sets are further compressed via representative/differential color sets.
THE SCPO FRAMEWORK
In this section we illustrate a framework to build the compressed data structures described in Section 4, the Dfc-dBG and the Mac-dBG. We then detail the specific instance of the framework used for the experiments in this work.
As evident from their definitions, the crux of both data structures is how to perform partitioning in an effective and efficient way. We recall that the input of partitioning is different for the two data structures, i.e., the colors in for the Dfc-dBG and the references in for the Mac-dBG. We therefore generically refer to the elements of the input as “objects” in the following. The framework is a heuristic for the introduced MPA optimization problems (Problem 2 and 3) and is based on the intuition that similar objects should be grouped together in the same partition so as to increase the likeliness of having larger shared patterns. It consists in the following four steps: (1) Sketching, (2) Clustering, (3) Partitioning, and (4) Ordering. Hence, we call it SCPO framework.
Sketching. As a preprocessing step for the actual partitioning (step 2 below), we first compute sketches of the objects to be partitioned. This makes the partitioning less-memory intensive and faster as it operates on smaller objects (the sketches). Furthermore, the sketches should preserve the essential information of the original objects, thus if two sketches are similar then the original objects are similar as well.
For the Dfc-dBG, we simply build one sketch for each color set. The sketches for the Mac-dBG, instead, are obtained as follows. Recall from Property 1 (Section 2) that each reference can be spelled by a proper concatenation (a “tiling”) of the unitigs of the underlying compacted dBG. If these unitigs are assigned unique identifiers by the chosen dictionary data structure [e.g., SSHash (Pibiri, 2023; Pibiri, 2022)], it follows that each can be seen as a list of unitig identifiers. These lists of unitig identifiers are obviously much shorter and take less space than the original DNA references. We compute one sketch for each such integer list.
Clustering. The sketches are fed as input of a clustering algorithm.
Partitioning. Once the clustering is done, each object in the input is labeled with the cluster label of the corresponding sketch so that the partition is uniquely determined.
Ordering. Finally, one may order the objects in each partition. While this might not be relevant for the Dfc-dBG, it is definitely for the Mac-dBG because reference identifiers can be permuted to reduce the encoding cost of the lists being represented (i.e., the partial colors for the Mac-dBG). In fact, while the goal of partitioning is to factorize the color sets in their repetitive patterns, the goal of the ordering step is to assign nearby identifiers to colors that tend to co-occur in the color sets. This would mean to determine a permutation that globally re-assign identifiers to references. As discussed in Section 4.2, this problem was shown to be NP-hard but good heuristics exist (Dhulipala et al., 2016).
Specific framework instance. For the experiments in this work, we use the following specific instance of the framework. We build hyper-log-log (Flajolet et al., 2007) sketches of bytes each. As a clustering algorithm, we use a divisive K-means approach that does not need an a priori number of clusters to be supplied as input. At the beginning of the algorithm, the whole input forms a single cluster that is recursively split into two clusters until the mean squared error (MSE) between the sketches in the cluster and the cluster’s centroid is not below a prescribed threshold (which we fix to 10% of the MSE at the start of the algorithm). Let r be the number of found clusters. The complexity of the algorithm depends on the topology of the binary tree representing the hierarchy of splits performed. Let Z be the number of sketches to cluster. We recall that for the Dfc-dBG we have (the number of distinct color sets) whereas for the Mac-dBG (the number of references). In the worst case, the topology is completely unbalanced and the complexity is ; in the best case, the topology is perfectly balanced instead, for a cost of . Note that the worst-case bound is very pessimistic because, in practice, the formed clusters tend to be reasonably well-balanced in size. Usually , thus we expect the clustering step performed for the Dfc-dBG to take more time and space in practice compared to that for the Mac-dBG.
In the current version of the work, we did not perform any ordering of the references. We leave the investigation of this opportunity as future work.
Finally, in this section, it is worth noting that the approach we describe here for constructing our new compressed c-dBGs bears a conceptual resemblance to the phylogenetic compression framework recently introduced by Břinda et al. (2024). At a high level, this owes to the fact that both approaches take advantage of well-known concepts in compression and information retrieval—namely that clustering and reordering are practical and effective heuristics for boosting compression. However, while the approach by Břinda et al. focuses on clustering references so as to improve the construction of collections of disparate dictionaries, we strictly focus on the effectiveness and efficiency of the index. As such, our approach adopts a single k-mer dictionary and instead induces a logical partitioning over the color sets. This layout allows to avoid having to record k-mers that appear in multiple partitions more than once. As a result, while the phylogenetic compression framework aims to scale to immense and highly diverse collections of references, it anticipates a primarily disk-based index in which partitions are loaded, decompressed, and searched for matches, similarly to a database search [or similarly to BLAST (Altschul et al., 1990)]. On the other hand, the approaches we present here place a premium on query time and aim to enable in-memory indexing with interactive lookups for the purpose of fast read-mapping against the index.
EXPERIMENTS
In this section, we illustrate the results of experiments conducted to assess the performance of the proposed c-dBG indexes, in comparison to the state-of-the-art methods reviewed in Section 3. We fix the k-mer length to . All experiments were run on a machine equipped with Intel Xeon Platinum 8276L CPUs (clocked at 2.20 GHz), 500 GB of RAM, and running Linux 4.15.0.
Datasets. We perform experiments using the following pangenomes of bacteria: 3,682E. Coli () genomes from NCBI (Alanko, 2022); different collections of S. Enterica () genomes from the “661K” collection by (Blackwell et al., 2021). Specifically, we use collections of different sizes, ranging from 5000 to 150,000 genomes. We also test a much more diverse collection of 30,691 genomes assembled from human gut samples (), originally published by Hiseni et al. (2021). Table 1 reports some basic statistics about these collections.
Basic Statistics for the Tested Collections, for
E. Coli ()
S. Enterica ()
Gut bacteria ()
Genomes
3682
5000
10,000
50,000
100,000
150,000
30,691
Distinct color sets ()
5.59
2.69
4.24
13.92
19.36
23.61
227.80
Integers in color sets ()
5.74
5.77
15.68
133.49
303.53
490.04
10.04
Avg. color set size ()
1.03
2.14
3.70
9.69
15.68
20.76
0.04
k-mers in dBG ()
170.65
104.69
239.88
806.23
1018.69
1194.44
13,936.86
Unitigs in dBG ()
9.31
4.95
8.24
30.64
41.16
49.60
566.39
Note how for the dataset, being much more diverse, the average color set size (computed as the ratio between the number of integers in the color sets and the number of distinct color sets) is just integers—two order of magnitude smaller than that of the other collections evaluated here.
Implementation details. Our methods from Section 4 are neither bound to a specific compression scheme nor to a specific dictionary data structure, allowing one to obtain a spectrum of different space/time trade-offs depending on choices made. Here, we use these new methods to compress the color sets of the Fulgor index (Fan et al., 2024)—the state-of-the-art c-dBG index and our own previous work (see Section 3). Similar to Fulgor, we therefore use the SSHash data structure (Pibiri, 2023; Pibiri, 2022) to represent the set of unitigs and the same mechanism to map unitigs to their color sets (see Fact 1). Very important, note that these choices directly imply that our new indexes fully exploit the unitig properties described in Section 2 as Fulgor does. We therefore experiment with the following indexes: the differential-colored version of Fulgor, or “d-Fulgor” in the following; the meta-colored version, or “m-Fulgor”; and the “md-Fulgor” representation, obtained by encoding with representative/differential color sets each partial color set as explained in Section 4.3.
Both representative and differential color sets in d-Fulgor are simply encoded by taking the gaps between consecutive integers and representing each gap with Elias’ code. For the partial color sets of m-Fulgor, we adopt the same compression methods as used to represent the color sets in Fulgor (see the description at the end of Section 3). Each meta color list is instead a list of -bit integers, being the total number of partial color sets.
For the md-Fulgor index—our most succinct variant of Fulgor—we also use a different schemes for the meta colors to improve compression further. Recall from Section 4.2 that each meta color is an integer pair , where i indicates a partition and j indicates the offset of the partial color set . A list of meta colors can therefore be decomposed into the two integer lists and , which we referred to as first and second components in the following. For example, the meta color list from Figure 5 can be decomposed into its first component [1, 2, 3, 4] and its second component [4, 3, 2, 4]. Note that while the first component is always a sorted list of all elements are distinct, this is not true in general for the second component. We thus use different encoding schemes for first and second components.
First, observe that—especially when the number of partitions is small—we expect a small number of distinct first components, say f, compared with the total number of color sets, z. Hence, it is convenient to keep the distinct first components in an array A[1..f] and, for each meta color, specify the index of the array’s entry corresponding to the first component, using bits. Even better, we can sort the meta color lists by first component and implement the succinct map via Rank explained in Fact 1. Thus, we use a bitvector b[1..z] plus the array A[1..f] and recover the first component of the t-th meta color list as A[p] where .
The second components, instead, are not so repetitive and, as noted above, the integers are not necessarily distinct and increasing. Thus, we use the following variable-length encoding: given the meta color , we encode the integer j using bits. For the example meta color list we have used above, we will encode its second component [4, 3, 2, 4] using bits, that is bits.
Compared indexes. Throughout this section, we compare our c-dBG data structures—d-Fulgor, m-Fulgor, and md-Fulgor—against the following indexes: the original Fulgor index (Fan et al., 2024), Themisto (Alanko et al., 2023b), MetaGraph (Karasikov et al., 2020a, b, 2022), and COBS (Bingmann et al., 2019). Links to the corresponding software libraries can be found in the References. We use the C++ implementations from the respective authors. All software (including ours) was compiled with gcc 11.1.0.
We provide some details on the tested tools. Both Themisto and COBS were built under default parameters as suggested by the authors, that is: with option -d 20 for Themisto for better space effectiveness; in COBS, we have shards of at most 1024 references where each Bloom filter has a false positive rate of 0.3 and one hash function to accelerate lookup operations. MetaGraph indexes were built with the relaxed row-diff BRWT data structure (Karasikov et al., 2020b) using a workflow available at https://github.com/theJasonFan/metagraph-workflows that we wrote with the input of the MetaGraph authors.
Space effectiveness
Table 2 reports the total on disk index size for all of the methods evaluated. In particular, Table 2a illustrates the effectiveness of the methods introduced in Section 4. Compared to the Fulgor index that was previously shown to achieve the most desirable space/time trade-off (Fan et al., 2024), our three methods, in order from left to right in the table, offer a progressive reduction is space. The improvement in the representation of the color sets is even more dramatic as the number of references in the dataset increases. In fact, as the size of the collection grows and more repetitive patterns in the color sets appear, our repetition-aware compression algorithms are able to better capture and reduce this redundancy. To make a concrete example, on the larger −150K dataset, the space spent to represent the color sets goes from 68.61 GB in Fulgor to:
Index Space in GB, Broken Down by Space Required for Indexing the k-Mers in the dBG (SSHash for All Fulgor Variants, Which we Hence Report Only Once, SBWT for Themisto, and BOSS for MetaGraph) and Data Structures Required to Encode Color Sets and Map k-Mers to the Sets
(a)
Fulgor
d-Fulgor
m-Fulgor
md-Fulgor
Dataset
dBG
Color sets
Total
Color sets
Total
Color sets
Total
Color sets
Total
0.29
1.36 (83%)
1.65
0.45 (61%)
0.74
0.40 (58%)
0.69
0.24 (45%)
0.52
−5K
0.16
0.59 (79%)
0.75
0.20 (56%)
0.36
0.16 (50%)
0.32
0.11 (40%)
0.27
−10K
0.35
1.66 (83%)
2.01
0.48 (58%)
0.83
0.34 (49%)
0.70
0.22 (39%)
0.57
−50K
1.25
17.03 (93%)
18.29
4.31 (77%)
5.57
2.08 (62%)
3.34
1.38 (52%)
2.64
−100K
1.71
40.71 (96%)
42.43
9.37 (84%)
11.10
3.75 (68%)
5.47
2.26 (57%)
3.98
−150K
2.02
68.61 (97%)
70.65
15.73 (89%)
17.77
5.27 (72%)
7.31
3.22 (61%)
5.26
21.29
15.54 (42%)
36.83
7.51 (26%)
28.81
9.16 (30%)
30.46
6.19 (23%)
27.48
(b)
Themisto
MetaGraph
COBS
Dataset
dBG
Color sets
Total
dBG
Color sets
Total
Total
0.22
1.85
2.08
0.10
0.23
0.33
7.53
−5K
0.14
1.29
1.43
0.07
0.19
0.26
9.11
−10K
0.32
3.50
3.81
0.13
0.38
0.51
18.68
−50K
1.07
32.42
33.48
0.36
1.95
2.31
88.61
−100K
1.35
75.94
77.28
0.45
3.50
3.95
173.58
−150K
1.58
125.16
126.74
NA
NA
NA
265.49
18.33
30.88
49.21
5.23
4.77
10.00
21.23
In (a), we also indicate in parentheses the percentage of space taken by the color sets with respect to the total. For COBS, we report the total index size, which coincides with the space of the approximate color sets. COBS, compact bit-sliced.
15.73 GB in d-Fulgor ( smaller space),
5.27 GB in m-Fulgor ( smaller space),
3.22 GB in md-Fulgor, for a total reduction in space of more than .
We also report in the table the percentage of space taken by the color sets relative to the total size of the indexes (in gray shade). For the largest index compared to here, the original Fulgor, the percentage illustrates how the space for the color sets tends to dominate the whole representation space for c-dBGs. However, note how the percentage gradually diminishes moving from the left to the right side of the table, i.e., as compression gradually improves. In some instances, the reduction offered by our algorithms surprisingly makes SSHash a “heavy” component of the index (which takes a constant fraction of the total space across all Fulgor variants).
Remarkably, observe that d-Fulgor compresses better than m-Fulgor the color sets for the pangenome (7.51 GB vs. 9.16 GB). This suggests that the method based on representative/differential color sets works better than the other one when the sets being represented are small.
We now turn our attention to the comparison against the other state-of-the-art methods evaluated in Table 2b. Note that the original Fulgor index already improves over the space usage of Themisto, thus making even more apparent the reduction in space of our newly introduced variants compared to Themisto. In fact, the only index whose size is competitive to ours is MetaGraph in the relaxed row-diff BRWT configuration—at least in the cases where we were able to construct the latter within the construction resource constraints. However, as we observe in Section 6.2, unlike the other indexes evaluated, the on disk index size MetaGraph is not representative of the working memory required for query when using the (recommended and default) “batch” mode query. The color sets of md-Fulgor also mostly require less space than those of MetaGraph.
The COBS index, despite being approximate, is consistently and considerably larger than all of the other (exact) indexes, except for the the gut bacteria collection (). The differing behavior on likely derives from the fact that the diversity of that data cause the exact indexes to spend a considerable fraction of their total size on the representation of the k-mer dictionary itself (e.g., GB). However COBS, by design, eliminates this component of the index entirely.
Query efficiency
Table 3 reports the query times of the indexes on a high-hit workload, e.g., when (more than) of the queries have a nonempty result. (Performance on a low-hit workload is less informative since few k-mers would actually be found in the indexes, thus testing the speed of negative k-mer lookups against the dictionary data structure, rather than the time spent in processing the color sets.) The time we measure for this experiment is that for performing pseudoalignment. There are several pseudoalignment algorithms [see Section 4 of (Fan et al., 2024) for an overview] that standard c-dBG data structures directly support; here we focus on the full intersection algorithm [Alg. 1 from (Fan et al., 2024)]. Given a query string Q, we consider it as a set of k-mers. Let (Q) = {x ∈ Q | ColorSet(x) ≠ ∅}. The full intersection method computes the intersection between the color sets of all the k-mers in .
Total Query Time (Elapsed Time) and Memory Used during Query (Max. RSS) as Reported by /Usr/Bin/Time-v Using 16 Processing Threads
(a)
Dataset
Hit rate
Fulgor
d-Fulgor
m-Fulgor
md-Fulgor
mm:ss
h:mm:ss
mm:ss
h:mm:ss
98.99
2:10
1.67
5:20
0.78
2:30
0.73
5:00
0.57
-5K
89.49
1:10
0.80
2:00
0.41
1:16
0.37
1:48
0.32
-10K
89.71
2:20
2.06
4:30
0.90
2:28
0.77
3:34
0.65
-50K
91.25
12:00
18.24
29:00
5.82
13:10
3.64
22:25
2.95
-100K
91.41
24:00
42.20
1:02:00
11.58
27:00
6.08
50:00
4.62
-150K
91.52
37:00
70.55
1:38:00
18.51
41:30
8.29
1:15:00
6.28
92.91
1:10
36.01
1.00
28.17
1:09
29.79
1.03
26.88
(b)
Dataset
Hit rate
Themisto
MetaGraph-B
MetaGraph-NB
COBS
h:mm:ss
mm:ss
h:mm:ss
h:mm:ss
98.99
3:40
2.46
22:00
30.44
1:05:41
0.40
45:11
34.93
-5K
89.49
3:50
1.82
14:14
36.54
20:32
0.33
38:34
41.93
-10K
89.71
7:35
4.16
28:15
92.18
43:40
0.61
1:01:14
84.20
-50K
91.25
42:02
33.14
NA
NA
4:30:03
2.72
3:54:18
408.82
-100K
91.41
1:22:00
75.93
NA
NA
9:40:06
4.82
8:07:29
522.56
-150K
91.52
2:00:13
124.27
NA
NA
NA
NA
7:47:14
522.63
92.91
1:20
48.47
28:55
15.86
22:05
9.91
34:45
225.57
The read-mapping output is written to /Dev/Null for this experiment. We also report the mapping rate in percentage (fraction of mapped read over the total number of queried reads). The query algorithm used here is full-intersection. The “B” query mode of MetaGraph corresponds to the batch mode (with default batch size); the “NB” corresponds to the nonbatch query mode instead. In red font, we have highlighted the workloads exceeding the available memory ( GB).
The queried reads consist of all FASTQ records in the first read file of the following accessions: for , for , and for . These files contain several million reads each. Timings are relative to a second run of each experiment, where the indexes are loaded from the disk cache (which benefits the larger indexes more than the smaller ones).
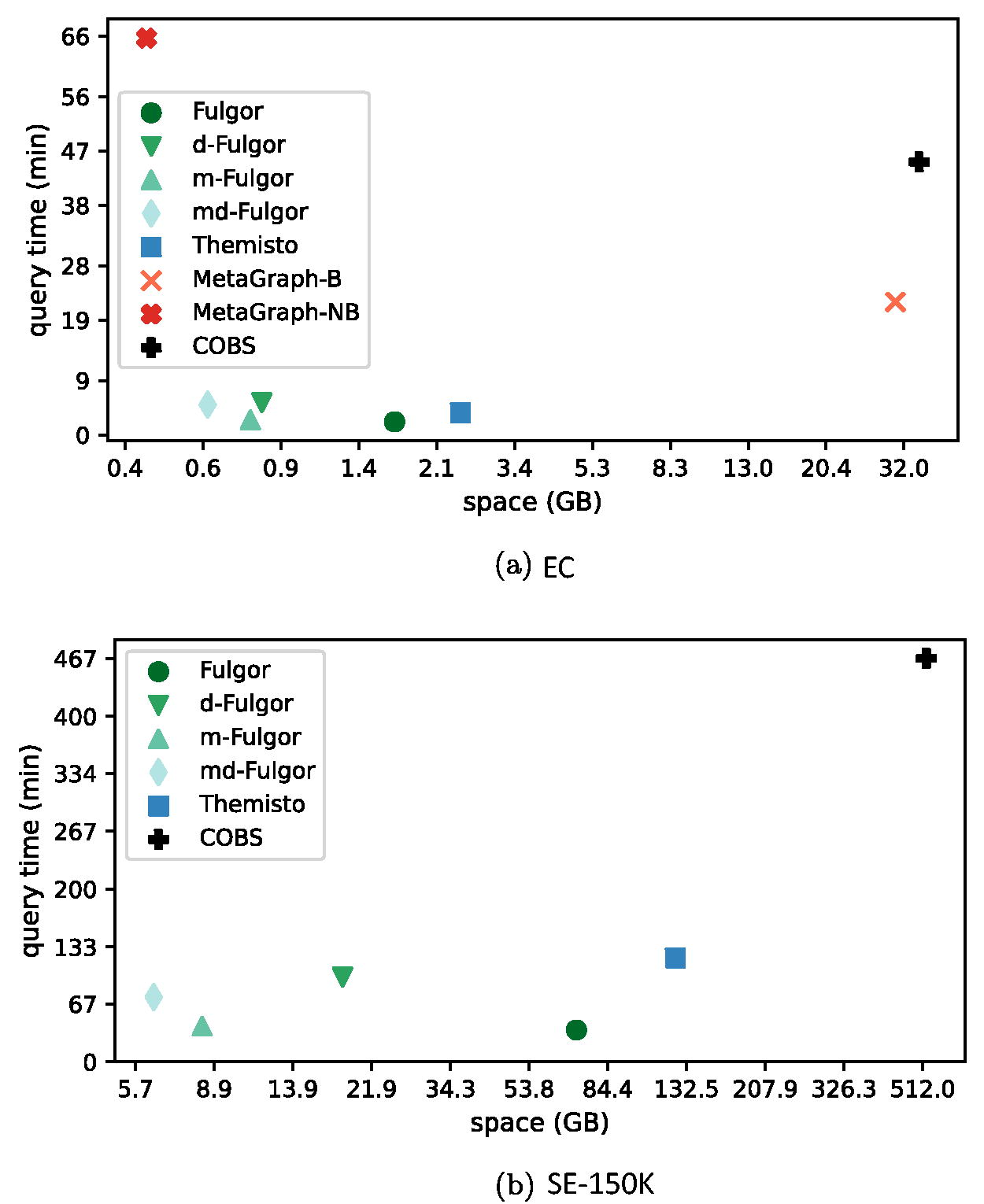
Consistent with previously reported results (Fan et al., 2024), we find that among existing indexes, Fulgor provides the fastest queries. The d-Fulgor variant results in being approximately slower than Fulgor but also offers much better compression effectiveness. The slowdown is due to the differential color sets taking more time to be decoded than the original color sets (i.e., linear time in the sum of the lengths of the representative and the differential sets).
Vertical partitioning, instead, opens the possibility to achieve even faster query times than a traditional c-dBG, due to the manner in which the partitions factorize the space of references, if a two-level intersection algorithm is employed for pseudoalignment. First, only meta color sets are intersected (thus, without any need to access the partial color sets) to determine the partitions in common to all color sets being intersected. Then, only the common partitions are considered. Two cases can happen for each partition. Case (1): the meta color is the same for all color sets being intersected. In this case, the result of the intersection is implicit and it suffices to decode the partial color set indicated by the meta color. Case (2): the meta color is not the same, thus we have to compute the intersection between different partial color sets. This optimization is clearly beneficial when the color sets being intersected have very few partitions in common, or when they have identical meta color sets. This is the reason why m-Fulgor does not sacrifice query efficiency compared with Fulgor, as expected, despite the significant reduction in space.
All Fulgor variants are instead equally efficient when indexing the dataset. The reason is that, on average, very small color sets are being decoded and intersected.
Taking also into account the space of the indexes as discussed in Section 6.1, two main conclusions emerge:
The m-Fulgor variant dominates completely the original Fulgor index, as it is considerably more space efficient and equally fast to query.
The combination of vertical and horizontal partitioning in the md-Fulgor index, partially mitigates the slowdown given by d-Fulgor. Overall, this combination makes the md-Fulgor more than one order of magnitude smaller than the original Fulgor index with a slowdown in query processing of less than . We consider this space/time trade-off very reasonable for the sake of indexing larger and larger c-dBGs in internal memory. As we note below, md-Fulgor is still faster than Themisto, the next fastest index in the literature.
After Fulgor and m-Fulgor, we note that Themisto is the next fastest index, followed by MetaGraph in batch query mode. Our most succinct but also slower version, the md-Fulgor index, is still roughly faster than Themisto. The query speeds of COBS and of MetaGraph when not executed in batch mode are much lower than that of the other indexes, in some cases being (more than) an order of magnitude slower.
Critically, as anticipated in Section 6.1, it is not the case with all indexes evaluated here that the size of the index on disk is a good proxy for the memory required to actually query the index. Specifically, for MetaGraph, when used in batch query mode (“B”), the required memory can exceed the on-disk index size by up to 2 orders of magnitude, and in several tests this resulted in the exhaustion of available memory and an inability to complete the queries under the tested configuration. On the other hand, all Fulgor variants, Themisto, and MetaGraph when not executed in batch mode (“NB”) require only a small constant amount of working memory beyond the size of the index present on disk.
The COBS query is generally much slower than the other indexes, except for MetaGraph in nonbatch mode. This is likely because COBS partitions the input collection into shards of references of roughly the same size prior to indexing. This permits to build Bloom filters of different sizes: filters belonging to different shards have a different number of bits allocated, hence saving space compared to the case where all references are represented with filters of the same size. At query time, however, a k-mer lookup has to be resolved by every shard and individual results combined.
Construction time and space
In Table 4 we consider the resources needed to build the indexes. Both d-Fulgor and m-Fulgor are built from a Fulgor index to which we apply the SCPO framework (Section 5). Similarly, the md-Fulgor is built from an m-Fulgor index. For this reason, the time reported in Table 4 for these indexes has to be summed to the time needed to first build another variant of Fulgor. The SCPO framework is single-threaded except for the construction and clustering of the sketches.
Total Index Construction Time (Elapsed Time) and GB of Memory Used during Construction (Max. RSS), as Reported by /Usr/Bin/Time-v Using 48 Processing Threads
(a)
Dataset
Fulgor
d-Fulgor
m-Fulgor
md-Fulgor
h:mm
h:mm
h:mm
h:mm
0:06
17
+0:12
11
+0:05
3
+0:14
4
−5K
0:04
13
+0:06
8
+0:04
1
+0:05
3
−10K
0:09
24
+0:09
14
+0:10
3
+0:11
4
−50K
1:13
44
+0:43
105
+1:50
22
+0:30
13
−100K
2:56
74
+1:20
207
+4:37
48
+0:43
20
−150K
4:36
137
+1:55
305
+7:41
77
+0:55
25
2:27
115
+10:00
182
+0:31
69
+7:12
127
(b)
Dataset
Themisto
MetaGraph
COBS
h:mm
h:mm
h:mm
0:19
17
0:46
149
0:03
6
−5K
0:11
13
0:47
191
0:09
8
−10K
0:25
24
1:50
219
0:17
16
−50K
2:32
96
14:16
120
1:41
82
−100K
6:25
202
26:40
104
2:37
84
−150K
10:00
323
NA
NA
4:54
159
6:21
184
10:50
100
0:22
17
The reported time includes the time to serialize the index on disk. In red font, we have highlighted the constructions exceeding the available memory ( GB) and for which we had to cap the maximum memory usage to 100 GB. The time for the three fulgor variants is that for running the SCPO construction, so it has to be summed to the time needed to first build an index to partition: the time of both d-Fulgor and m-Fulgor must be summed to that of Fulgor, and the time for md-Fulgor must be summed to that of m-Fulgor.
We note that the m-Fulgor index is slower to build compared to a d-Fulgor index, despite the fact that d-Fulgor rebuilds a (permuted) SSHash dictionary and clusters many more sketches. The reason lies in the different parameters that we used for the clustering of the sketches. For d-Fulgor, we do not impose any constraint of the minimum size of a cluster, hence allowing the algorithm to produce small and many clusters. On the contrary, the number of clusters must be kept under control for the m-Fulgor variant as this directly impacts on the length of the meta color lists (thus, their space usage). For this reason, the clustering algorithm attempts to greedily reassign sketches from small clusters to big clusters, with the goal of reducing the number of clusters. The memory used during the building of d-Fulgor is nonetheless much higher than that of m-Fulgor for the much larger number of sketches that are being clustered. The md-Fulgor variant can instead be built very economically from an existing m-Fulgor index.
Despite not being heavily engineered yet, the end-to-end construction of our indexes is competitive to that of Themisto and much faster than that of MetaGraph. The fastest indexes to build are Fulgor and COBS, the latter being even faster on the collection for reasons already explained (i.e., it does not build any exact dictionary for the k-mers). The tested MetaGraph configuration is significantly slower to build than all the other indexes; for example, we were unable to build the index for -150K within 3 days and using 48 parallel threads (the construction also produced more than 1 TB of intermediate files).
CONCLUSIONS AND FUTURE WORK
In this work, we have introduced new compressed representations for the c-dBG, where repetitive patterns within colors are encoded once as to improve the memory usage of pseudoalignment queries. More specifically, we have applied our compression algorithms to represent the color sets as stored in the recently introduced Fulgor index as it embodies the most favorable space vs. time trade-off, and we have introduced two distinct, and largely orthogonal, approaches for factorizing and compressing redundant patterns among the color sets. One scheme, d-Fulgor, is a “horizontal” compression method which performs a representative/differential encoding of the color sets. The other scheme, m-Fulgor, is a “vertical” compression method which instead decomposes the color sets into meta and partial color sets. Crucially, these methods exploit different characteristics for compression, and so they can be combined to achieve an even greater compression of the color sets. We show the effect of this combination with an index that we call md-Fulgor.
We perform an extensive experimental analysis across several datasets to assess these different schemes and compare them against alternative representations of the c-dBG. From our analysis, we conclude that: (1) the meta-colored version of Fulgor, m-Fulgor, does not introduce any new trade-off compared to the original Fulgor index but simply supersedes it, given that it is considerably smaller and equally fast; (2) the meta-differential-colored variant, md-Fulgor, is even more compact with a relatively minor query overhead compared to Fulgor, especially compared to the space savings it provides.
Our representations provide a substantially improved new reference point for the problem of indexing c-dBGs in compressed space, as apparent from Figure 6. Our most succinct index, md-Fulgor, is competitive with the smallest variant of MetaGraph but an order of magnitude faster to query; and up to smaller than Themisto and still twice as fast. We believe this improved performance has the potential of enabling large-scale color set queries across a range of applications.
The same data from Table 3 but shown as space vs. time trade-off points for two example datasets.
Future work will focus on different aspects of improving the index and relevant operations upon it. First, we would like to accelerate pseudoalignment queries in general, and especially for the md-Fulgor index. Second, we will provide a better engineered build pipeline for our indexes. Third, we would like to explore the effect of approximately optimal ordering within the partial color sets (i.e., the “O” step of the SCPO framework we have introduced). Finally, we plan to extend the indexing capabilities of Fulgor by annotating its graph with more information such as k-mer abundances and their positions in the references.
Footnotes
ACKNOWLEDGMENTS
We are grateful to Laxman Dhulipala for useful comments on an early draft of this article.
AUTHORS’ CONTRIBUTIONS
A.C.: Conceptualization, Methodology, Software, Validation; G.E.P.: Conceptualization, Methodology, Writing—Original Draft, Supervision; J.F.: Conceptualization, Software; R.P.: Conceptualization, Methodology, Writing—Review and Editing. All authors read and approved the final article.
AUTHOR DISCLOSURE STATEMENT
R.P. is the cofounder of Ocean Genomics inc. J.F.’s contributions to this work were completed while he was affiliated with the University of Maryland.
FUNDING INFORMATION
This work is supported by the NIH under grant award numbers R01HG009937 to R.P.; the NSF awards CCF-1750472 and CNS-1763680 to R.P. and DGE-1840340 to J.F. Funding for this research has also been provided by the European Union’s Horizon Europe research and innovation program (EFRA project, Grant Agreement Number 101093026). This work was also partially supported by DAIS – Ca’ Foscari University of Venice within the IRIDE program.
AlankoJN, PuglisiSJ, VuohtoniemiJ. Small searchable k-spectra via subset rank queries on the spectral burrows-wheeler transform. SIAM Conference on Applied and Computational Discrete Algorithms (ACDA23), pages 225–2362023a.
3.
AlankoJN, VuohtoniemiJ, MäklinT, et al.Themisto: A scalable colored k-mer index for sensitive pseudoalignment against hundreds of thousands of bacterial genomes. Bioinformatics, 2023b;39(39 (Suppl 1)):i260–i269. URL https://github.com/algbio/themisto
4.
AlmodaresiF, KhanJ, MadaminovS, et al.An incrementally updatable and scalable system for large-scale sequence search using the Bentley–saxe transformation. Bioinformatics, 2022; 38(12):3155–3163.
5.
AlmodaresiF, PandeyP, FerdmanM, et al.An efficient, scalable, and exact representation of high-dimensional color information enabled using de bruijn graph search. J Comput Biol, 2020; 27(4):485–499.
6.
AlmodaresiF, SarkarH, SrivastavaA, et al.A space and time-efficient index for the compacted colored de Bruijn graph. Bioinformatics, 2018; 34(13):i169–i177.
7.
AlmodaresiF, ZakeriM, PatroR. PuffAligner: A fast, efficient and accurate aligner based on the pufferfish index. Bioinformatics, 2021; 37(22):4048–4055.
8.
AltschulSF, GishW, MillerW, et al.Basic local alignment search tool. J Mol Biol, 1990; 215(3):403–410.
9.
BaierU, BellerT, OhlebuschE. Graphical pan-genome analysis with compressed suffix trees and the burrows–wheeler transform. Bioinformatics, 2016; 32(4):497–504.
10.
BingmannT, BradleyP, GaugerF, et al.Cobs: A compact bit-sliced signature index. In: International Symposium on String Processing and Information Retrieval, pages 285–303. Springer, 2019. URL https://github.com/bingmann/cobs
BloomBH. Space/time trade-offs in hash coding with allowable errors. Commun ACM, 1970; 13(7):422–426.
13.
BoweA, OnoderaT, SadakaneK, et al.Succinct de Bruijn graphs. In International Workshop on Algorithms in Bioinformatics (WABI), pages 225–235. Springer, 2012.
BřindaK, LimaL, PignottiS, et al.Efficient and robust search of microbial genomes via phylogenetic compression. bioRxiv, 2024.
16.
ClearyA, RamarajT, KahandaI, et al.Exploring frequented regions in pan-genomic graphs. IEEE/ACM Trans Comput Biol Bioinform, 2019; 16(5):1424–1435.
17.
DedeK, OhlebuschE. Dynamic construction of pan-genome subgraphs. Open Computer Science, 2020; 10(1):82–96.
18.
DhulipalaL, KabiljoI, KarrerB, et al.Compressing graphs and indexes with recursive graph bisection. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 1535–1544, 2016.
19.
EliasP. Universal codeword sets and representations of the integers. IEEE Trans Inform Theory, 1975; 21(2):194–203.
20.
FanJ, KhanJ, PibiriGE, et al.Spectrum preserving tilings enable sparse and modular reference indexing. In Research in Computational Molecular Biology, pages 21–402023.
21.
FanJ, KhanJ, SinghNP, et al.Fulgor: A fast and compact k-mer index for large-scale matching and color queries. Algorithms Mol Biol, 2024; 19(1):1–21. URL https://github.com/jermp/fulgor
22.
FlajoletP, FusyÉ, GandouetO, et al.Hyperloglog: The analysis of a near-optimal cardinality estimation algorithm. In Discrete Mathematics and Theoretical Computer Science, pages 137–156. Discrete Mathematics and Theoretical Computer Science, 2007.
23.
HiseniP, RudiK, WilsonRC, et al.HumGut: A comprehensive human gut prokaryotic genomes collection filtered by metagenome data. Microbiome, 2021; 9(1):165–112. URL https://arken.nmbu.no/∼larssn/humgut/index.htm
24.
HolleyG, MelstedP. Bifrost: Highly parallel construction and indexing of colored and compacted de Bruijn graphs. Genome Biol, 2020; 21(1):249–220.
25.
IqbalZ, CaccamoM, TurnerI, et al.De novo assembly and genotyping of variants using colored de Bruijn graphs. Nat Genet, 2012; 44(2):226–232.
26.
JacobsonG. Space-efficient static trees and graphs. In 30th annual symposium on foundations of computer science, pages 549–554. IEEE Computer Society, 1989.
27.
KarasikovM, MustafaH, DanciuD, et al.Metagraph: Indexing and analysing nucleotide archives at petabase-scale. BioRxiv, 2020apages:2020–2010.
28.
KarasikovM, MustafaH, JoudakiA, et al.Sparse Binary Relation Representations for Genome Graph Annotation. J Comput Biol, 2020b;27(4):626–639. URL https://github.com/ratschlab/metagraph
29.
KarasikovM, MustafaH, RätschG, et al.Lossless indexing with counting de bruijn graphs. Genome Res, 2022; 32(9):1754–1764.
30.
LeesJA, MaiTT, GalardiniM, et al.Improved prediction of bacterial genotype-phenotype associations using interpretable pangenome-spanning regressions. mBio, 2020; 11(4).
31.
LemireD, KaserO, KurzN, et al.Roaring bitmaps: Implementation of an optimized software library. Software: Practice and Experience, 2018; 48(4):867–895.
32.
LiuB, GuoH, BrudnoM, et al.deBGA: Read alignment with de Bruijn graph-based seed and extension. Bioinformatics, 2016; 32(21):3224–3232.
33.
LuhmannN, HolleyG, AchtmanM. BlastFrost: Fast querying of 100, 000s of bacterial genomes in bifrost graphs. Genome Biol, 2021; 22(1):30.
34.
MäklinT, KallonenT, DavidS, et al.High-resolution sweep metagenomics using fast probabilistic inference [version 1; peer review: 1 approved, 1 approved with reservations]. Wellcome Open Res, 2020; 5(14):14.
35.
ManuweeraB, MudgeJ, KahandaI, et al.Pangenome-Wide Association Studies with Frequented Regions. In Proceedings of the 10th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics.ACM, 2019.
36.
MarchetC, BoucherC, PuglisiSJ, et al.Data structures based on k-mers for querying large collections of sequencing data sets. Genome Res, 2021; 31(1):1–12.
37.
MarcusS, LeeH, SchatzMC. Splitmem: A graphical algorithm for pan-genome analysis with suffix skips. Bioinformatics, 2014; 30(24):3476–3483.
38.
MinkinI, MedvedevP. Scalable multiple whole-genome alignment and locally collinear block construction with SibeliaZ. Nat Commun, 2020a;11(1):6327.
39.
MinkinI, MedvedevP. Scalable pairwise whole-genome homology mapping of long genomes with BubbZ. iScience, 2020b;23(6):101224.
40.
PandeyP, AlmodaresiF, BenderMA, et al.Mantis: A fast, small, and exact large-scale sequence-search index. Cell Syst, 2018; 7(2):201–207.
41.
PandeyP, BenderMA, JohnsonR, et al.A general-purpose counting filter: Making every bit count. In Proceedings of the 2017 ACM international conference on Management of Data, pages 775–787, 2017.
42.
PibiriGE, VenturiniR. Techniques for inverted index compression. ACM Comput Surv, 2021; 53(6):1–36.
43.
PibiriGE. On weighted k-mer dictionaries. Algorithms Mol Biol, 2023; 18(1):3.
44.
PibiriGE. Sparse and skew hashing of k-mers. Bioinformatics 062022; 38(Suppl 1):i185–i194.
45.
PibiriGE, FanJ, PatroR. Meta-colored compacted de Bruijn graphs. In International Conference on Research in Computational Molecular Biology, pages 131–146. Springer, 2024.
46.
RahmanA, DufresneY, MedvedevP. Compression algorithm for colored de bruijn graphs. In: 23rd International Workshop on Algorithms in Bioinformatics (WABI 2023), pages 17:1–17: 2023.
47.
ReppellM, NovembreJ. Using pseudoalignment and base quality to accurately quantify microbial community composition. PLoS Comput Biol, 2018; 14(4):1–23.
48.
SchaefferL, PimentelH, BrayN, et al.Pseudoalignment for metagenomic read assignment. Bioinformatics, 2017; 33(14):2082–2088.
49.
SkoufosG, AlmodaresiF, ZakeriM, et al.AGAMEMNON: An accurate metaGenomics and MEtatranscriptoMics quaNtificatiON analysis suite. Genome Biol, 2022; 23(1):39.