
Abstract
The Mapper algorithm is an essential tool for visualizing complex, high-dimensional data in topological data analysis and has been widely used in biomedical research. It outputs a combinatorial graph whose structure encodes the shape of the data. However, the need for manual parameter tuning and fixed (implicit) intervals, along with fixed overlapping ratios, may impede the performance of the standard Mapper algorithm. Variants of the standard Mapper algorithms have been developed to address these limitations, yet most of them still require manual tuning of parameters. Additionally, many of these variants, including the standard version found in the literature, were built within a deterministic framework and overlooked the uncertainty inherent in the data. To relax these limitations, in this work, we introduce a novel framework that implicitly represents intervals through a hidden assignment matrix, enabling automatic parameter optimization via stochastic gradient descent (SGD). In this work, we develop a soft Mapper framework based on a Gaussian mixture model for flexible and implicit interval construction. We further illustrate the robustness of the soft Mapper algorithm by introducing the Mapper graph mode as a point estimation for the output graph. Moreover, a SGD algorithm with a specific topological loss function is proposed for optimizing parameters in the model. Both simulation and application studies demonstrate its effectiveness in capturing the underlying topological structures. In addition, the application to an RNA expression dataset obtained from the Mount Sinai/JJ Peters VA Medical Center Brain Bank successfully identifies a distinct subgroup of Alzheimer’s Disease. The implementation of our method is available at https://github.com/FarmerTao/Implicit-interval-Mapper.git.
INTRODUCTION
The Mapper algorithm is a powerful tool in topological data analysis used to explore the shape of datasets. Initially introduced for 3D object recognition (Singh et al., 2007), the Mapper algorithm has demonstrated remarkable efficiency in extracting topological information across various data types. Its application spans various areas, notably in biomedical research (Skaf and Laubenbacher, 2022). For example, it successfully identified new breast cancer subgroups with superior survival rates (Nicolau et al., 2011). In single-cell RNA-Seq analysis, a Mapper-based algorithm was used to study unbiased temporal transcriptional regulation (Rizvi et al., 2017). The variants of Mapper algorithms were also used to uncover higher-order structures of complex phenomics data (Kamruzzaman et al., 2021). Moreover, many efforts have been made to integrate the Mapper algorithm with other machine learning techniques. For instance, Bodnar et al. (2021) enhanced the performance of a graph neural network by incorporating the Mapper algorithm as a pooling operation. When combined with autoencoders, the Mapper algorithm can be used as a robust classifier (Cyranka et al., 2019), remedying the shortcomings of traditional convolutional neural networks, such as susceptibility to gradient-based attacks. Recently, a visualization method called shapevis, which was inspired by the Mapper algorithm, was proposed to produce a more concise topological structure than the standard Mapper graph (Kumari et al., 2020). In addition to advances in the Mapper algorithms in applications, there have also been new advancements in theory. Carriere et al. (2018) analyzed the Mapper algorithm from a statistical perspective and introduced a novel method for parameter selection. Other studies have explored the algorithm’s convergence to Reeb graphs (Brown et al., 2021) and examined its topological properties (Dey et al., 2017).
The standard Mapper algorithm generates a graph that captures the shape of the data by dividing the support of the filtered data into several overlapped intervals with a fixed length (Singh et al., 2007). Two major limitations of the standard Mapper algorithm are the requirement of a fixed length of intervals and an overlapping rate. Many algorithms were proposed to address these limitations. For instance, F-Mapper (Bui et al., 2020) utilized the fuzzy clustering algorithm to allow flexible interval partitioning by introducing an additional threshold parameter to control the degree of overlap. However, the introduction of the parameter also increased the algorithm’s computational complexity. In a different vein, the ensemble version of Mapper was proposed by Kang and Lim (2021); Fitzpatrick et al. (2023), which can recover the topology of datasets without parameter tuning. However, this method has a significantly high computational cost due to the execution of multiple instances of the Mapper algorithm. Differently, the Ball Mapper (Dłotko, 2019) directly constructed a cover on a given dataset, avoiding the difficulty of choosing filter functions. Nevertheless, its construction process is somewhat arbitrary and could inadvertently introduce extra parameters, increasing computational complexity. The D-Mapper, as introduced by Tao and Ge (2025), developed a probabilistic framework to construct intervals of the projected data based on a mixture distribution. This approach offers flexibility in interval construction. Additionally, the soft Mapper, a smoother version of the standard Mapper algorithm, was proposed by Oulhaj et al. (2024). This algorithm focused on the optimization of filter functions by minimizing the topological loss.
In this study, our objective is to enhance the Mapper algorithm by incorporating a probability model that requires fewer parameter selections and enables flexible interval partitioning. Inspired by the D-Mapper (Tao and Ge, 2025), our approach utilizes a mixture distribution. Still, it implicitly represents intervals through a hidden assignment matrix, eliminating the need for the interval threshold
In addition, the simulation results show that our method is comparable to the standard Mapper algorithm and is more robust. Our model is also applied to an RNA expression dataset and successfully identifies a distinct subgroup of Alzheimer’s Disease (AD).
PRELIMINARY
Mapper algorithm
The Mapper algorithm has been widely used to output a graph of a given dataset to represent its topological structure (Dey et al., 2017), the output graph can be regarded as a discrete version of the Reeb graph. The core concept of the Mapper algorithm is as follows. First, it projects a given high-dimensional dataset into a lower-dimensional space. Then, it constructs a reasonable cover for the projected data, pulls back the original data points according to each interval, and clusters the points within each preimage (or pullback set). Finally, each cluster is treated as a node of the output graph, and an edge is added between two clusters if they share any data points.
Consider a dataset with n data points,
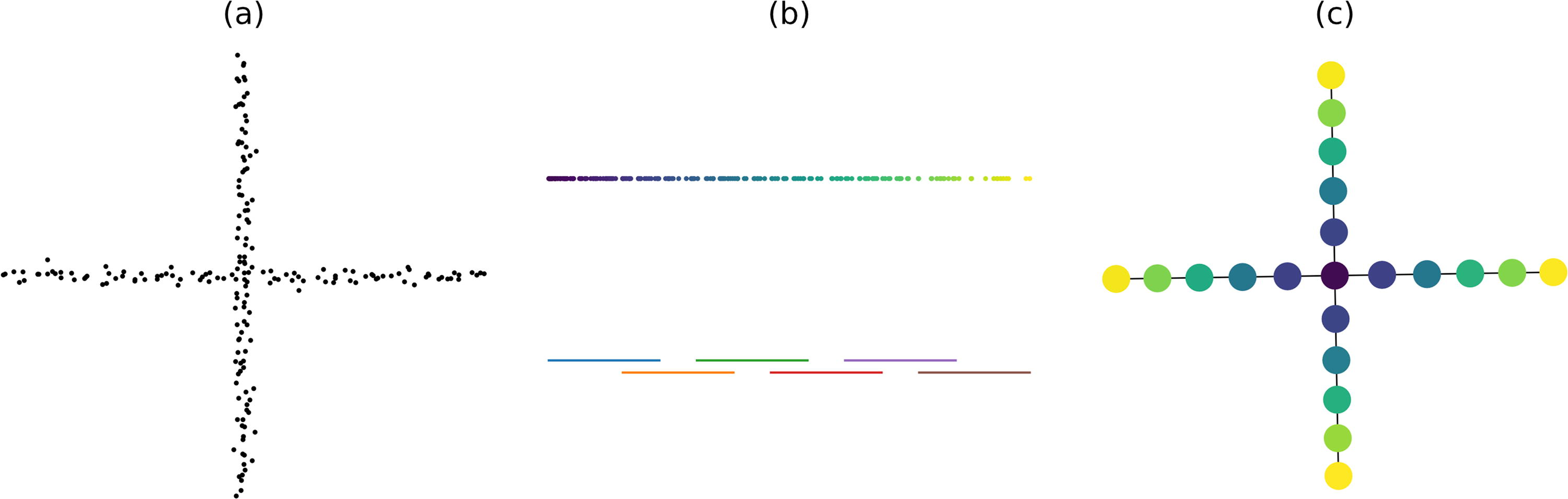
A demonstration of the Mapper algorithm applied to a dataset with a cross structure.
Each interval
Traditional Mapper graphs are constructed through intervals based on the filtered data. The soft Mapper constructs Mapper graphs with a hidden assignment matrix without requiring fixed intervals (Oulhaj et al., 2024). The hidden assignment matrix, a
When a hidden assignment matrix H is a random matrix, the soft Mapper can be viewed as a stochastic version of the Mapper, parametrized by a Mapper function
Where
With this definition, the model inference is simplified to estimate the probability matrix Q, which will yield the distribution of Mapper graphs. However, explicitly estimating Q is challenging. In this work, we address this issue by making certain modifications to the soft Mapper approach.
METHODS
Gaussian mixture model soft Mapper
In the standard Mapper algorithm, a cover is constructed on the projected data, and a cover consists of several intervals and any two adjacent intervals overlap. These intervals can be constructed by partitioning the projected data into multiple groups. Then, pull back the data points by allocating the corresponding projected value into each interval. Analogously, this allocating process of projected data points into intervals of a cover is similar to the allocating process of labels for a mixture probability model. In this work, we focus on a Gaussian mixture model (GMM) to fit the projected data due to its simplicity and flexibility. By incorporating a GMM, we can naturally define a hidden assignment matrix H through soft clustering, and a probability matrix Q can be easily derived from the GMM parameters. We fit a GMM to the projected data
Then, for each point
This GMM-based assignment scheme imposes an implicit constraint on each row of the probability matrix Q, such that the sum of the probabilities for each data point equals one,
Here
Our proposed soft Mapper samples each row
Our approach differs from the soft Mapper described in Oulhaj et al. (2024) in two key ways. First, by using the GMM, our
The Mapper graph mode
The soft Mapper is a probabilistic version of the Mapper algorithm, where a random hidden assignment matrix H can result in varying Mapper graphs. Although the topological structures of these soft Mapper graphs differ in detail, they often share some common features as they are derived from the same underlying distribution. We aim to obtain a Mapper graph that encapsulates all these common structures as its final representation. Since H is a discrete random matrix, and each row is independently distributed, we can take the matrix of which each row is the mode of each row of H as the mode representation of H and then apply the Mapper function to get a Mapper graph, which we call the Mapper graph mode. The mode of a multinomial distribution has an explicit formula, allowing us to compute the mode of the Mapper graph directly and efficiently.
Here, the
The mode of the Mapper graph can be defined by a Mapper function and the mode of the hidden assignment matrix
The explicit form of
Loss function
The probability matrix Q is derived from a GMM fitted to the projected data. Therefore, optimizing the Mapper graph is equivalent to optimizing the parameter
We adopt a similar formula to Oulhaj et al. (2024) to measure the topological information loss. The topological information of a Mapper graph can be encoded by the extended persistence diagram (Carriere and Oudot, 2018). A significant advantage of the extended persistence diagram is its ability to capture the branches of a Mapper graph. The branches of a Mapper graph are crucial in downstream data analysis. We denote the extended persistence diagram as D, where
To compute the extended persistence diagram, we need to define a filtration function for each node of a Mapper graph. Typically, the filtration function of a node on a Mapper graph is defined as the average of the filtered data within that node. However, to integrate the model parameters into the optimization framework, we introduce a novel node filtration function for computing the extended persistence diagram. For each node c on a Mapper graph, the filtration function on this node is
This function calculates the averaged log-likelihood of the data points assigned to node c, where the number of points at node c is denoted as
To represent the topological information on the extended persistence diagram, a function that maps the diagram to a real number is defined, denoted as
This value offers a reasonable summary of the extended persistence diagram. An effective diagram should predominantly feature signal points. The detonator in this term is used to avoid encouraging spurious structures in the Mapper graph.
The extended persistence diagram D is derived from a Mapper graph G, while G is generated by the Mapper function of the hidden assignment matrix H. For notation simplicity, we denote
Since the hidden assignment matrix H is random, the resulting
The total loss function of the GMM soft Mapper can be defined as a weighted average of the negative log-likelihood of the filtered data and the topological loss concerning H,
Here, the first term is the averaged log-likelihood, representing the information carried out by the filter data. By averaging, we ensure that the log-likelihood is comparable across datasets of varying sample sizes. The parameters
SGD parameter estimation
In this study, we use the SGD algorithm (Bottou, 2010) to optimize the loss function defined above. Our goal is to find parameters
To apply SGD to the log-likelihood of a GMM, it is crucial to handle the constraints on the parameters. For weights
Instead of updating

SYNTHETIC DATASETS
In this section, we compare our proposed algorithm to the standard Mapper algorithm and D-Mapper on synthetic datasets to demonstrate its effectiveness. The output graphs indicate that our proposed method performs comparable or better than the standard Mapper and D-Mapper algorithms concerning the topological structures. To quantitatively compare these algorithms, we calculate the Silhouette Coefficient (SC) (Han et al., 2022) and the adjusted SC (
Uniform dataset
We start with two uniformly sampled datasets. 1000 data points are sampled from two separate circles and two overlapping circles, respectively. Figure 2a and f provide a visualization of these two datasets and (implicit) intervals produced by each algorithm. To visualize the implicit intervals, we take the minimum value within each cluster as the starting point of the interval and the maximum value within each cluster as the ending point of the interval. In both datasets, the filter function is the coordinates of the x-axis. For the disjoint circles dataset, we set the number of (implicit) intervals to
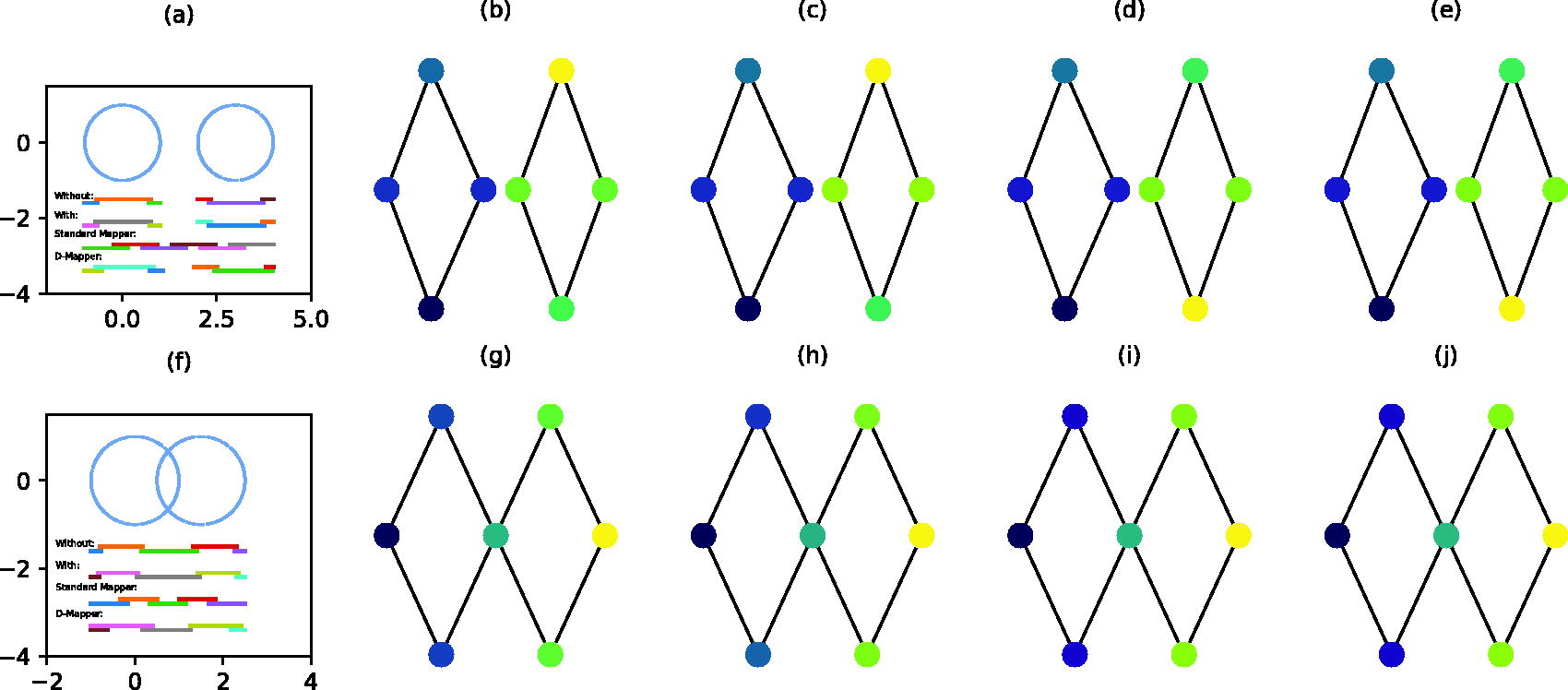
Comparison of the standard Mapper algorithm, D-Mapper algorithm and our proposed algorithm on a two disjoint circles dataset and a two intersecting circles dataset.
Model Parameters Setting for Synthetic Datasets
DBSCAN, density-based spatial clustering of applications with noise; TCs, two disjoint circles; TICs, two intersecting circles.
As the underlying data structure for these two small datasets is relatively simple, all these three algorithms can easily reveal the underlying structure. The topological structure of the data can even be well captured by the Mapper graph mode with an appropriate choice of the GMM initial values without optimization.
We make slight modifications to the datasets above, resulting in two disjoint and two intersecting circles with different radii, each containing 1000 points. Figure 3a and f provide a visualization of these two datasets and (implicit) intervals produced by each algorithm. The same filter function is applied. For the unequal-sized disjoint circles, the DBSCAN parameters are set to
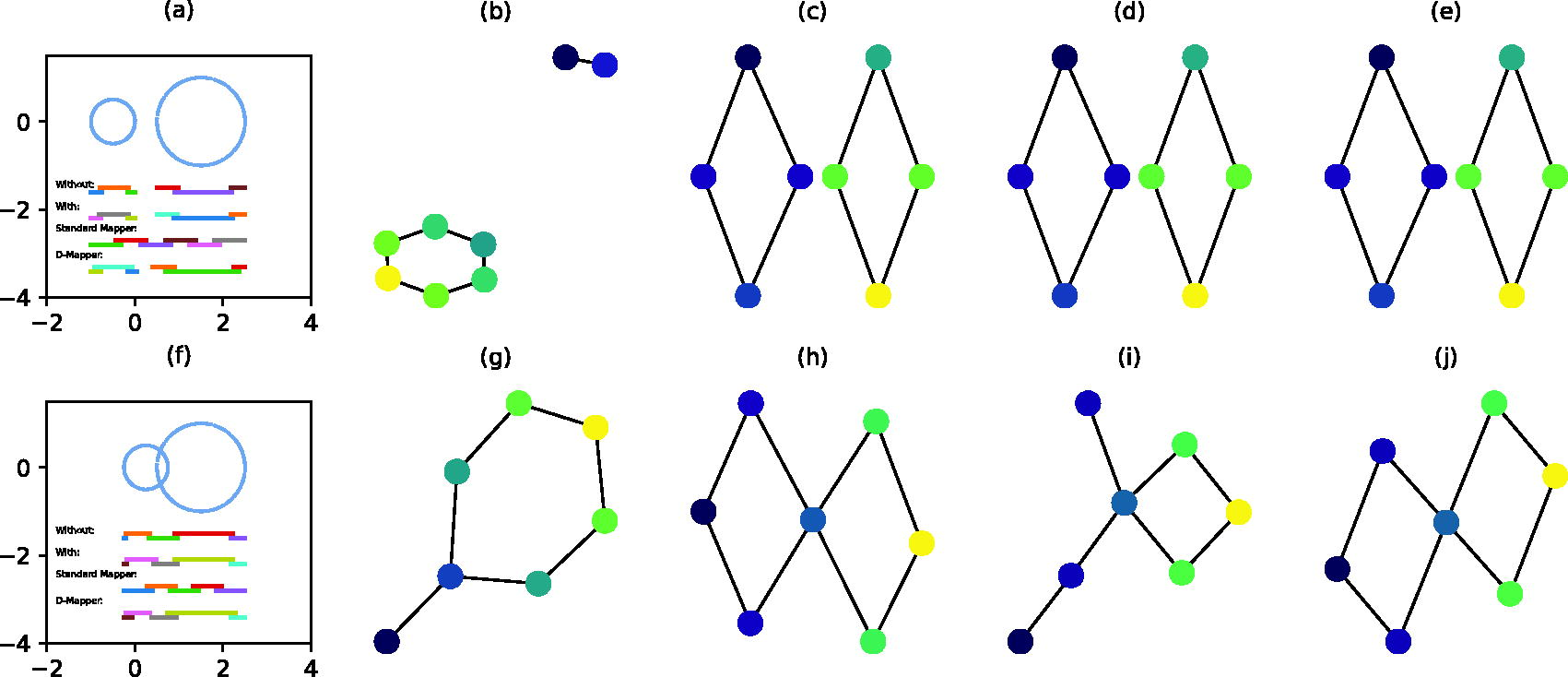
Comparison of the standard Mapper algorithm, D-Mapper algorithm and our proposed algorithm on a two unequal-sized disjoint circles dataset and a two unequal-sized intersecting circles dataset.
In this section, we assess the robustness of our proposed algorithm by introducing noises into the intersecting circles dataset. The noise is drawn from a Gaussian distribution and is added to each point’s coordinates. Initially, we introduce a small amount of noise, characterized by a Gaussian distribution with mean of zero and standard deviation of 0.1. The dataset is shown in Figure 4a. With this setting for noises, both the standard Mapper, D-Mapper and our Mapper graph mode can accurately represent the correct topological structure. The results are shown in Figure 4b–e.
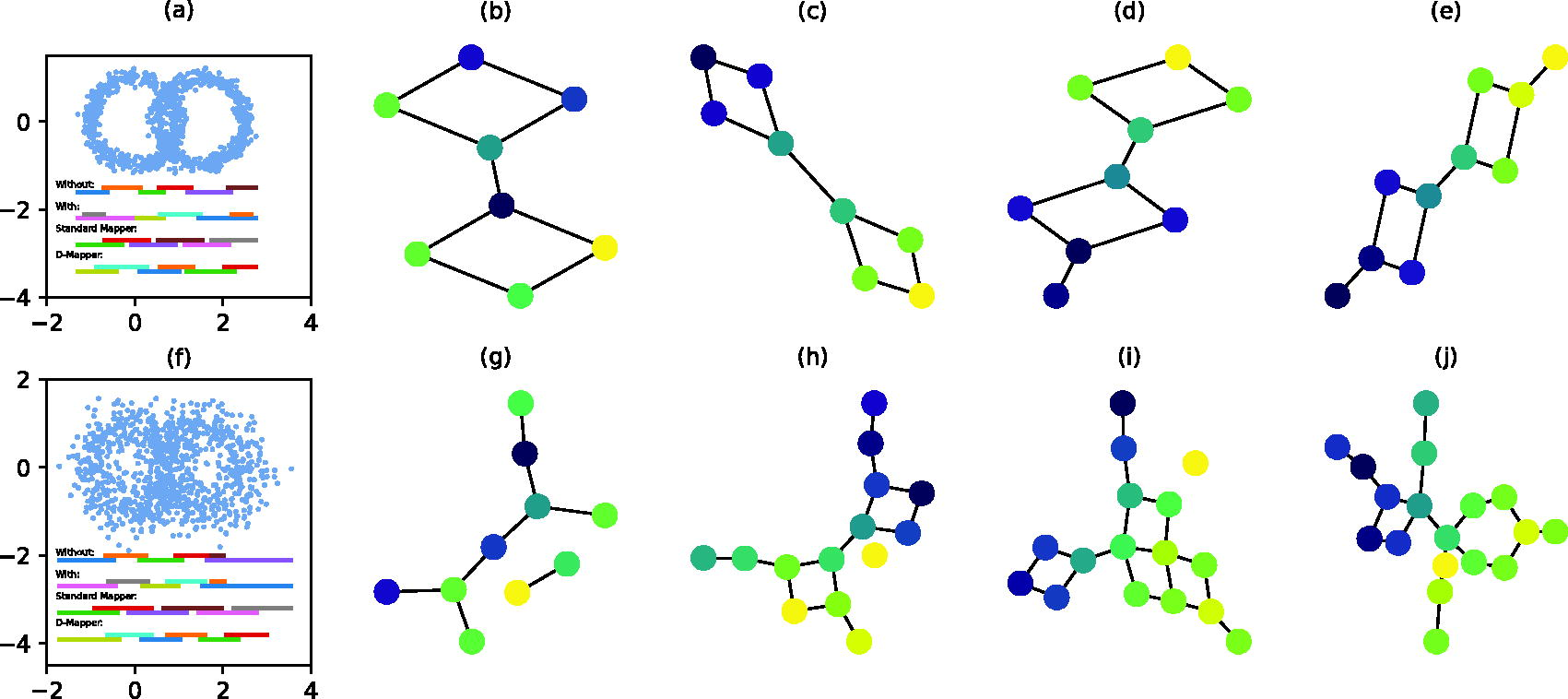
Comparison of the standard Mapper algorithm, D-Mapper algorithm and our proposed algorithm on a two intersecting circles dataset with noises.
Subsequently, we increase the noise level, increasing the standard deviation to 0.3. The dataset is shown in Figure 4f. At this noise level, the standard Mapper algorithm is unable to output meaningful structures, as illustrated in Figure 4g. The D-Mapper algorithm can capture the main two loops of the data, while still has some extra branches and an isolated node, as shown in Figure 4h. Without optimization, the Mapper graph mode does not capture the two circles, as shown in Figure 4i. After optimization, our Mapper graph mode can capture the two primary loops, as shown in Figure 4j, though with some additional branches. These results highlight the efficacy of flexible implicit interval partitioning in uncovering the data’s inherent structure, even in the presence of significant noise. Parameter optimization plays a crucial role in accurately determining the implicit intervals, which boosts the algorithm’s performance.
We finally test our proposed algorithm on a 3D human dataset from Oulhaj et al. (2024). In this example, the number of (implicit) intervals is set to
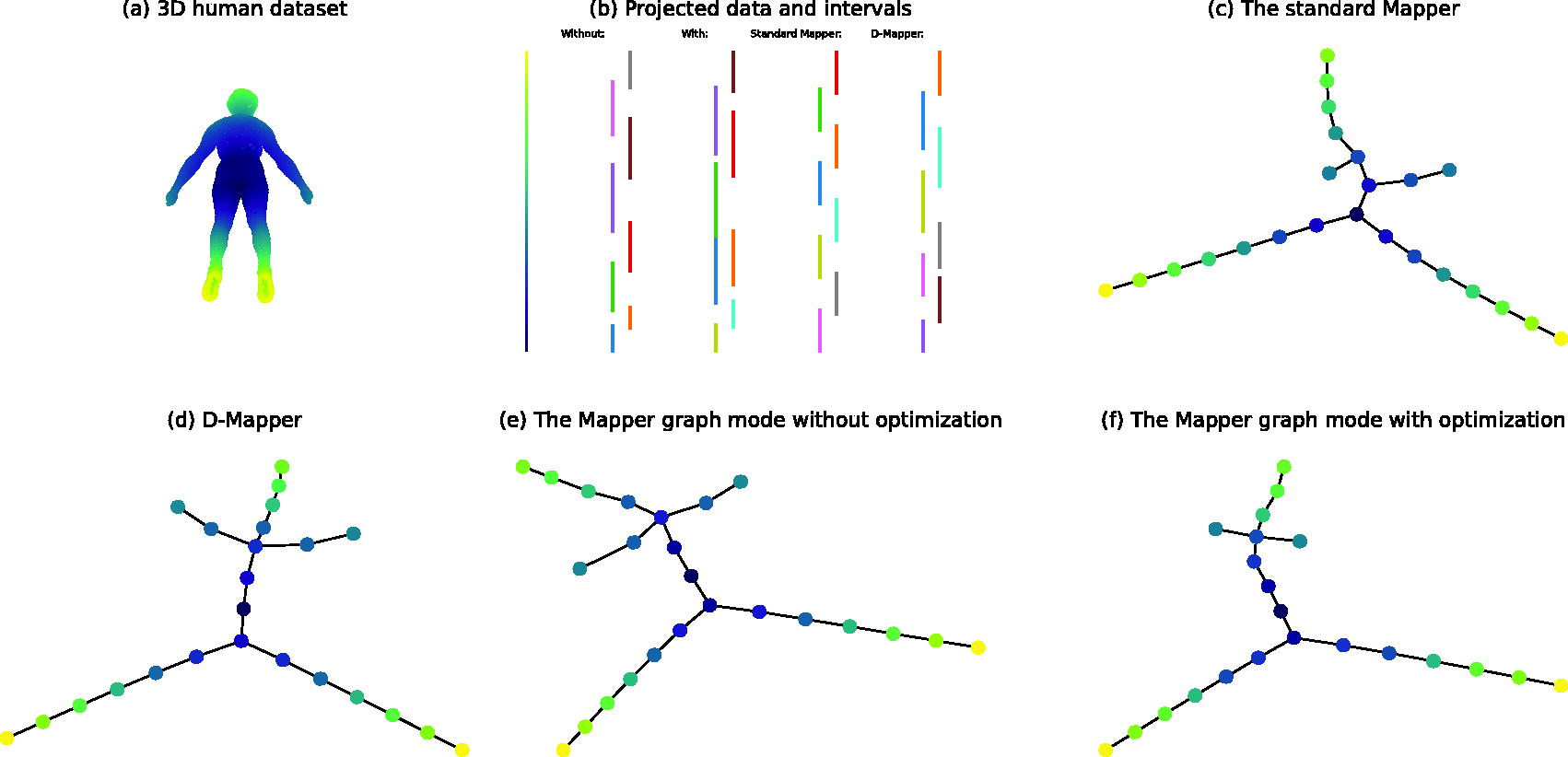
Comparison of the standard Mapper algorithm, D-Mapper and our proposed algorithm on a 3D human dataset.
Through a series of synthetic dataset experiments, we find that the optimized Mapper graph mode can capture dataset shapes more accurately in general. It should be noted that the quantitative evaluation of the Mapper graphs is a challenging problem, as the topological information of given data is often not available (Bui et al., 2020; Carriere et al., 2018). As in most of the literature, here we compute the SC, this metric accounts for the clustering performance only (Bui et al., 2020; Chalapathi et al., 2021; Dłotko, 2019). The
As shown in Table 2, in all cases but the two intersecting circles dataset and the 3D human dataset, the D-Mapper performs comparably or better than the standard Mapper and the Mapper graph mode performs best in terms of metric
Quantitative Comparison of the Mapper, D-Mapper, and Mapper Graph Mode Across Different Datasets
Quantitative Comparison of the Mapper, D-Mapper, and Mapper Graph Mode Across Different Datasets
Generally, the D-Mapper has a higher value of metric
TCs, two disjoint circles; TICs, two intersecting circles.
We also apply our method to an RNA expression dataset to assess its ability to identify subgroups within AD patients. The dataset is obtained from the Mount Sinai/JJ Peters VA Medical Center Brain Bank (MSBB) (Wang et al., 2018), which includes RNA gene expression profiles from four distinct brain regions, the frontal pole (FP) in Brodmann area 10, the superior temporal gyrus (STG) in area 22, the parahippocampal gyrus (PHG) in area 36, and the inferior frontal gyrus (IFG) in area 44. In this application study, we focus on brain area 36, which includes 215 patient samples, each with over 20,000 gene expression values. Each patient is given a Braak AD staging score, ranging from 0 to 6, with higher scores indicating more severe disease stages (Braak et al., 2003). The Braak score is treated as a label for each sample. Our goal is to identify subgroups with a significantly different distribution of Braak scores from the rest of the population given the gene expression profiles. These subgroups can be branches or isolated nodes on the hidden topological features of the gene expression profiles.
As indicated in Zhou and Sharpee (2021), the gene expression data could exhibit a hyperbolic structure especially as the number of genetic sites increases. To capture the complex and hierarchical relationships between samples based on gene expression more effectively, we use the Lorentzian distance, a standard hyperbolic distance, to measure the similarity between samples. The hyperbolic distance can preserve the hierarchical structures inherent in gene expression data and is considered particularly suitable for high-dimensional data (Liu et al., 2024). In the Lorentzian distance, the centroid is crucial because of its ability to reveal the hierarchical structure of datasets. In this study, we set each data point in the dataset as the centroid to get a distance matrix repetitively and use the averaged distance matrix as the final distance matrix. The filter function is set to the mean value of the distance between each sample and others. Due to the high computational cost of calculating the distance matrix for over 20, 000 genes, we select the top 37 gene sites as listed in Wang et al. (2016). These gene sites are from the top 50 probes ranked in association with disease traits in 19 brain regions, excluding those unmatched. The selected gene sites are then used to compute the hyperbolic distances.
We set the number of (implicit) intervals to
In brain area 36, we find a distinct branch that is associated with high Braak scores, as shown in the red dashed box in Figure 6a. The bar charts in Figure 6b reveal distribution differences between this branch and the other nodes. The p value of the
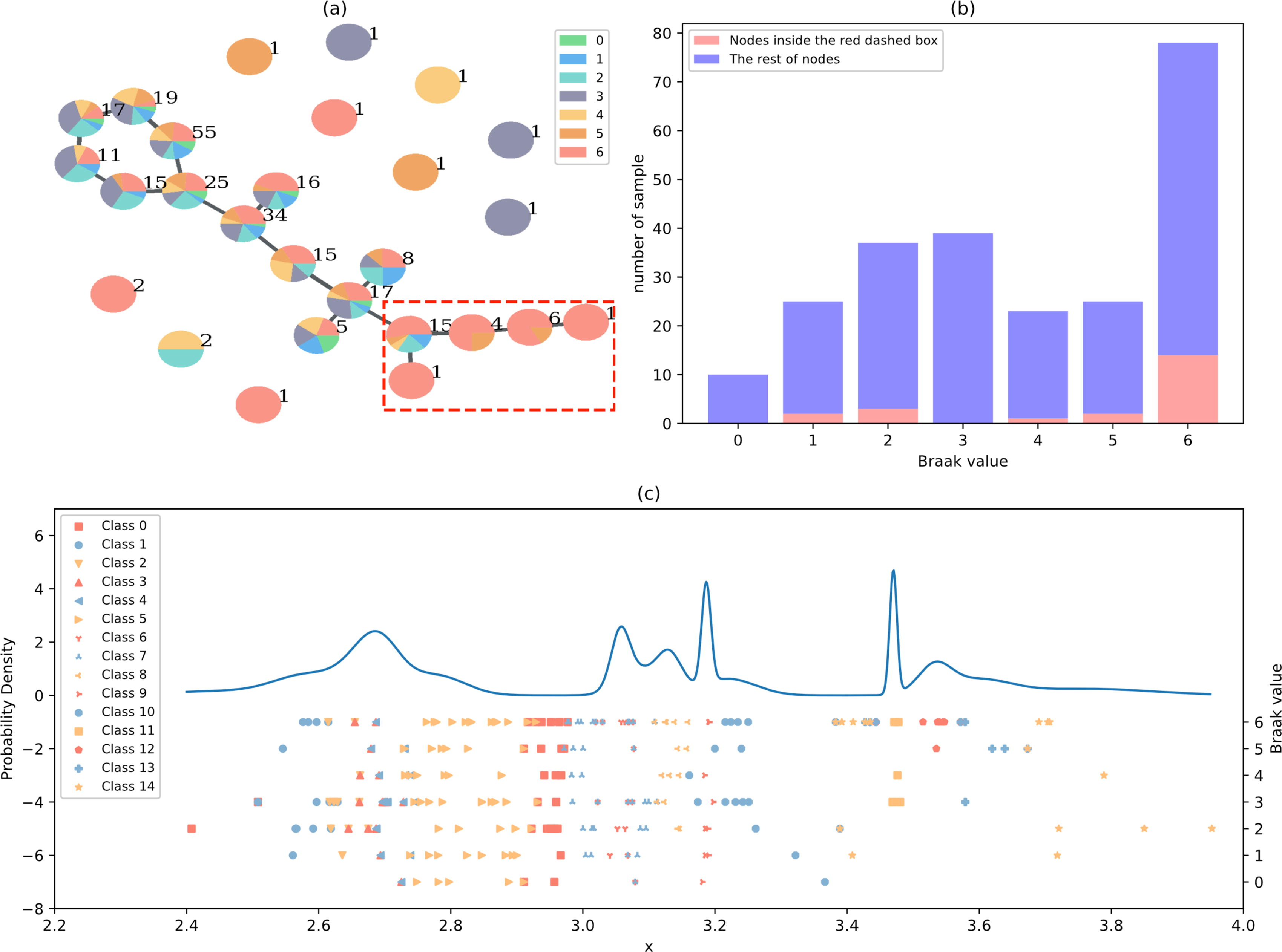
Results of the brain area 36.
We also run the standard Mapper and D-Mapper on this dataset, and the results are shown in Supplementary Figure A11 in Supplementary Appendix A4, respectively. The standard Mapper exhibits a distinct branch (in the red dashed box) that demonstrates a significant distributional difference compared with other nodes (81% severe conditions vs. 37.1% severe conditions with the p value of the
In this work, we introduce a novel approach for flexibly constructing a Mapper graph based on a probability model. We develop implicit intervals for soft Mapper graphs using a Gaussian mixture model and a multinomial distribution. With a given number of implicit intervals, our algorithm automatically assigns each data point to an implicit interval based on the allocation probability. Then, based on these implicit intervals, we derive the concept of the Mapper graph mode as a point estimation. Additionally, we design an optimization approach that enhances the topological structure of Mapper graphs by minimizing a specific loss function. This function considers both the likelihood of the projected data with respect to the GMM and the topological information of the Mapper graph mode. This optimization process is particularly suited for complex and noisy datasets, as the standard Mapper algorithm can be sensitive to noise and may fail in certain situations. Both simulation and application studies demonstrate its effectiveness in capturing the underlying topological structures. The application of our proposed algorithm to the gene expression of brain area 36 of the MSBB successfully identifies a unique subgroup whose distribution of Braak scores differs significantly from the rest of the nodes.
It is worth noting that the multimodal nature of the objective function makes it challenging to find a globally optimal Mapper graph. We suggest performing multiple optimization runs with careful parameter tuning and incorporating domain knowledge to generate high-quality Mapper graphs. In addition, the mean persistence loss function used in this work is a simple representation of information on the extended persistence diagram. Numerous alternative approaches may be available, for example, one could consider distinguishing signals from noise in a Mapper graph using confidence sets (Fasy et al., 2013). Finding a more robust persistence-specific loss function will be one of the future work directions. Moreover, as you may have noticed, the filter function is also important for constructing a meaningful Mapper graph. In this work, covers are constructed based on the filtered data, as in most literature. Optimizing the filter function and (implicit) intervals simultaneously would be a challenging but meaningful direction. Moreover, a more appropriate quantitative assessment of the Mapper algorithms poses significant challenges. We adopt
Footnotes
ACKNOWLEDGMENTS
The authors thank ShanghaiTech University for supporting this work through the startup fund and the High Performance Computing (HPC) platform.
AUTHORS’ CONTRIBUTIONS
Y.T.: Conceptualization, data collection, formal analysis, methodology, coding, visualization, writing—original draft. S.G.: Conceptualization, data curation, formal analysis, methodology, coding evaluation, project administration, supervision, writing—review and editing. All authors read and approved the final article.
AVAILABILITY OF DATA AND MATERIALS
The article employs publicly accessible datasets in the 3D human synthetic and application experiments. The 3D human dataset was originally created by Oulhaj et al. (2024), and is accessible at https://github.com/ZiyadOulhaj/Mapper-Optimization/tree/main/Datasets. The RNA expression sequences used in the application are obtained from the Mount Sinai/JJ Peters VA Medical Center Brain Bank (Wang et al., 2018) and are available at https://www.synapse.org/ with SynID 20801188. The rest of the synthetic data, the results of all experiments, and the code are available at ![]() .
.
AUTHOR DISCLOSURE STATEMENT
The authors declare they have no conflicting financial interests and no personal interests to disclose.
FUNDING INFORMATION
This project was supported by the startup fund of ShanghaiTech University, Shanghai Science and Technology Program (No. 21010502500) and National Natural Science Foundation of China (12401383).
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.