
Abstract

A new study in this issue from Eugene Koonin and his colleagues (Shmakov et al. page 535) investigates isolated CRISPR arrays and defines true “orphan” arrays that may be associated with yet unknown CRISPR-Cas systems
CRISPR-Cas systems have evolved into a very complex family, as reflected by the composition and functionality of the cas gene clusters and the diversity of CRISPR repeats. Despite a remarkably conserved structure, CRISPR arrays display heterogeneity in size, nature and length of their leader, and their capacity to expand, all characteristics that are poorly understood.
Whereas the arrays in archaea and many extremophiles can store >100 spacers, in most species, CRISPR arrays are no longer than a few dozen spacers, which may be due to deletion by recombination between repeats. The leader, a 100–200 bp sequence flanking the array on its proximal side, 1 is involved in transcription and in adaptation through binding of the Cas1–Cas2 complex onto the leader-repeat junction. 2 It coevolves with repeats, the Cas1 protein, and the protospacer adjacent motif. 3 Interestingly, in many genomes, a single cluster of cas genes may be associated with several arrays (up to 24 in Nocardiopsis alba ATCC BAA-2165 for a single Type IA cas gene cluster; https://crisprcas.i2bc.paris-saclay.fr/ 4 ), which possess the same or very similar repeat sequences and do not share any spacer. They are generally flanked by a leader with 70–90% similarity over >100 bp, and can be targets for spacer acquisition.
Multiple arrays are found more frequently in genomes bearing a Type I and/or Type III system, as in most archaea and bacteria, but are rare in Type II systems. They can be scattered or grouped, often near the cas gene cluster. The multiplication of CRISPR arrays with their leader is probably not an accident. An analysis of 5,796 genomes bearing a single Type I or Type III cas gene cluster shows that the number of spacers increases with the number of CRISPR arrays (Fig. 1A). This may suggest that in cells where the size of the CRISPR arrays seems to be limited, the existence of multiple copies that can be transcribed efficiently and are available for insertion of spacers provides a selective advantage. This would prevent the loss of isolated CRISPR arrays, as observed for different gene families. 5
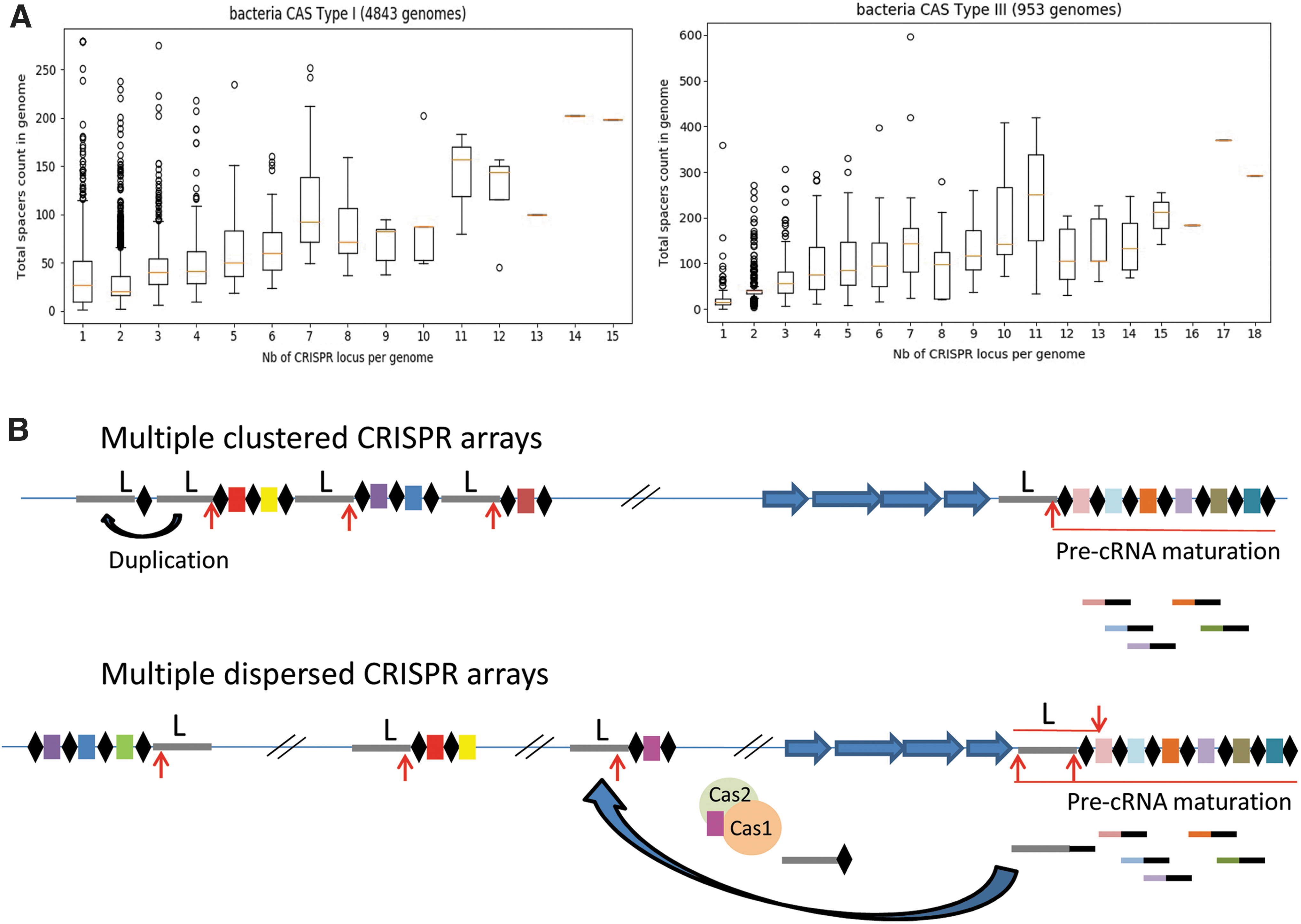
Multiplication of CRISPR arrays.
Writing in this issue of The CRISPR Journal, Shmakov et al. present the results of their exploration of 13,116 complete genome sequences in search for isolated CRISPR arrays, that is, those with no nearby cas genes. 6 Over the past 15 years, Eugene Koonin's group has been a leader in cataloguing Cas proteins, allowing the precise definition and classification of the CRISPR-Cas types and subtypes. In the latest work, they apply the minCED tool (https://github.com/ctSkennerton/minced) and a filtering pipeline to identify CRISPR arrays that are not adjacent to cas genes. In agreement with previous observations made with a more limited number of sequences, they find that 90% of arrays that have no cas gene in their vicinity possess a repeat shared with a cas-accompanied array in the same or different genomes and a leader. Interestingly, they identify 116 unique bona fide arrays distributed across 89 clusters, for which repeats show no similarity to known CRISPR, and are therefore “orphans” until the cas they complement is uncovered.
To explain the existence of isolated arrays with similarity to cas-adjacent arrays, the authors analyzed their region of insertion, and found that transposable elements were three times more frequent than in other part of the genome. Therefore, they propose a plausible scenario: the loss of the cas gene cluster following transfer of a complete CRISPR-Cas system. Another hypothesis is de novo generation by off-target insertion of spacers into a repeat-like sequence as observed experimentally 7 and dissemination by mobile genetic elements.
These mechanisms may apply in some situations but can hardly explain the majority of isolated-CRISPR arrays. The systematic deletion of cas clusters seems improbable, and the creation of arrays following off-target insertion of spacers is incompatible with the presence of the conserved leader sequence in a majority of isolated arrays. I propose two additional mechanisms that could lead to production of copies of the leader and the first repeat of a cas-associated array and allow their insertion at different positions. In cases where arrays are clustered and separated only by their leader, such as in Fusobacterium pseudoperiodonticum KCOM 2555 (with 11 arrays within 9 kb), it might result from tandem duplication of the original array and exclusion of preexisting spacers by recombination between repeats (Fig. 1B). Excision of some arrays and nonhomologous recombination could account for scattered distribution of new copies.
Another mechanism could involve retro-transcription of a mature RNA bearing the leader and the proximal repeat (Fig. 1C). RNA-seq analysis has shown that in addition to transcription initiated at the leader, antisense transcripts can be common due to the presence of promoters within repeats or in some spacers.8,9 Furthermore, in some arrays such as in Myxococcus xhantus, the leader is transcribed from the cas gene cluster readthrough. 10 Ancillary proteins with reverse transcriptase activity, group II intron or RT-Cas1 fusion proteins in Type III systems, might be actors in the generation of new CRISPR arrays.11,12
In the past few years, the term “orphan” has been used somewhat indiscriminately to define any array that is not physically associated with cas genes, whether the repeat was shared with a cas-associated array or not. They were also called “split arrays,” 13 although the presence of the leader shows that the majority do not correspond to an array that has been fragmented. Shmakov et al. propose a list of arrays that do not seem to be associated with known cas genes and will be the subject of future investigations. It is important that each genome presumably holding orphan arrays be reexamined with caution such as the cited Ktedonobacterales bacterium SCAWS-G2 genome which does possess Type IIID and Type ID cas genes and 8 isolated arrays.
Much work remains in order to understand the dynamics of the CRISPR-Cas systems and particularly the birth and multiplication of CRISPR arrays. The organization we see today is the result of millions of years of slow evolution, and we need to analyze more genomes to reconstruct these ancient events.