
Abstract

Biology’s design space is vast, shaped by billions of years of evolution. Since the discovery of the double helix more than 70 years ago, 1 our understanding of genes and genomes has grown exponentially. In the intervening decades, scientists sequenced millions of genomes, delved deeply into their coding potential, and now frequently rewrite the instructions with the precision afforded by CRISPR. 2
While we can read and edit DNA with remarkable precision, our ability to design new biological systems has remained limited by our understanding of nature’s rules. With rapid developments in computing, artificial intelligence (AI) has offered an exciting opportunity to learn from the enormous diversity of genomic DNA at scale. However, any AI method that strives to capture the complexity of biology must integrate genetic information from diverse organisms at single nucleotide resolution with a view of genomes at kilobase scales; an impractical task due to limitations in available highly curated data, computational capacity, and network architectures.
In a recent article in Science, researchers from the Arc Institute led by Eric Nguyen, Patrick Hsu, and Brian Hie describe the design and implementation of Evo, a model trained using a unique network architecture that can stomach millions of genomes while maintaining larger genomic contexts at single nucleotide resolution. 3 Evo represents a genomic foundation model with training on the interconnected language of biology across scales, from individual nucleotides to complete genomes.
Nguyen et al. validated Evo’s comprehension by prompting it to generate an entire Escherichia coli-like genome sequence producing a genome with realistic properties. Beyond this task, when prompted, Evo outperformed existing models to reliably predict the effect of mutations on fitness. While undoubtedly a quantum leap forward in both capacity and capability with clear impact potential on synthetic biology, Evo shows some limitations with generated synthetic genomes lacking certain hallmarks of real organisms, such as complete sets of essential genes known to be required in rationally designed minimal genomes. 4
Beyond genomes, Evo demonstrates an unprecedented ability to generate functional molecular machines that appear absent in nature—from CRISPR-Cas effectors to active transposons—while maintaining the intricate dance between DNA, RNA, and proteins needed to make biology work. This capability to explore the adjacent possible in evolution’s landscape has profound implications.
We can now systematically probe evolutionary trajectories that nature may have avoided, potentially discovering molecular tools that were either lost to time or never emerged. Given this capability, it raises the question: why haven’t some of these AI-generated molecular systems appeared naturally? The answer likely lies in the complex interplay between evolutionary constraints and biological context. Natural evolution operates under specific selective pressures and historical contingencies—what works must not only function but provide a fitness advantage in a particular environmental context. Evo, freed from these constraints, can explore sequence space more broadly, potentially discovering solutions that nature either “rejected” or never encountered. However, this raises intriguing questions about biological robustness and context-dependence of activity that merit further investigation.
AI and IP
The successful generation of a functional CRISPR system showcases a vast space of useful designer biotechnologies. However, the application of generative AI in this space raises important questions around intellectual property. Who owns an AI-designed protein if it’s sufficiently similar to existing tools? And at what point is an AI-designed Cas9 not in fact Cas9? Does each AI-designed protein provide freedom to operate outside of existing patents on related enzymes? This is not a question isolated to CRISPR biotechnology but it is clear from emerging patents that inventors are making broad claims across entire swathes of AI-designed sequence space. Will this encourage competition or lead to yet more patent disputes? Only time will tell.
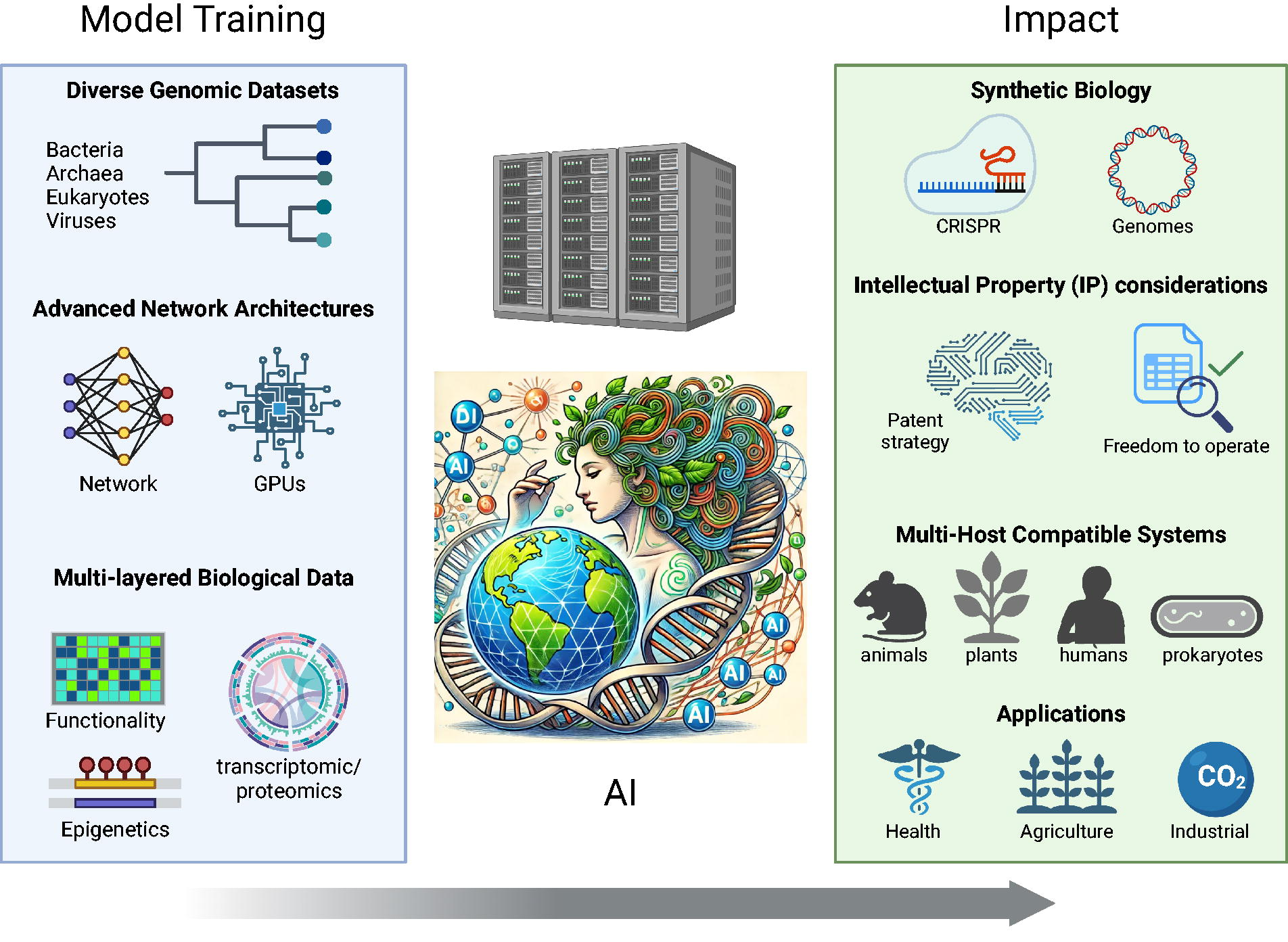
Evolution of biological AI systems: From training to impact. (Left) Model training requirements including large-scale genomic databases (bacteria, archaea, eukaryotes, viruses, minimal and synthetic chromosomes), advanced network architectures (neural networks and GPU acceleration), and multi-layered biological data (functional assays, integrated genomic features, epigenetic modifications). (Center) AI systems comprehending biological complexity through integrative sequence and structure analysis, supported by high-performance computing infrastructure. (Right) Major impacts including novel molecular machineries (CRISPR systems, engineered genomes), intellectual property considerations (patent strategy, freedom to operate analysis), multi-host compatible systems (spanning animals, plants, humans, prokaryotes), and applications in health, agriculture and industrial sectors. Arrow indicates progression from fundamental training data to real-world impact. Image created in BioRender. Valentin, L. (2025) https://BioRender.com/s15y218.
Regardless, Evo demonstrates the power of AI to dramatically accelerate the engineering cycle in synthetic biology, effectively slamming the door wide open for improved biotechnologies and novel applications. Traditional approaches to designing novel biological systems often require extensive trial and error in the lab.5,6 By learning the rules of biological design from millions of genomes, Evo can propose candidates with a much higher likelihood of success—as evidenced by the remarkable success in generating functional transposons and efficient Cas9 gene editors.
What comes next?
Looking ahead, we can envision several exciting frontiers. The extension of Evo-like models to mobile genetic elements, archaeal, and eukaryotic systems could reveal new insights into genome organization and regulation. Critically, this will require further innovation in network architecture to not only expand the context size to megabase scales but move beyond the language of DNA to include the grammar and punctuation of life—epigenetics—a challenge given that comprehensive epigenetic studies across diverse organisms remain limited.
Beyond genomic data, integration with experimental methods for high-throughput testing could create a virtuous cycle of design and validation (Fig. 1). Perhaps most intriguingly, these models might help us understand how complex biological features emerge from simpler components—one of biology’s most enduring mysteries. Notably, the Arc Institute team has made its code and models openly available, enabling the broader scientific community to build upon this foundation. This transparency, combined with thoughtful consideration of biosafety implications, sets an important precedent for the responsible development of AI in biology.
Evo represents a new paradigm in biological engineering—one that learns from evolution’s grand experiment while expanding beyond its historical constraints. Tools like Evo promise to accelerate both our understanding of life’s fundamental principles and our ability to harness them for beneficial applications. However, the complexity of natural biological systems—with their intricate regulatory networks, contextual dependencies, and evolutionary history—will continue to provide both challenges and insights.
The success of Evo in generating functional biological entities while maintaining a modicum of realistic genomic properties suggests that we are beginning to capture some of biology’s fundamental design principles. Yet, the gap between our synthetic creations and naturally evolved systems reminds us of the remarkable sophistication of life’s solutions. Understanding this gap may prove as valuable as our ability to bridge it.
Footnotes
Author Disclosure Statement
The authors have patents pending or approved relating to CRISPR-Cas biotechnologies.
Funding Information
GK was supported by the Snow Medical Research Foundation (SMRF2021-276). Snow Medical were not involved in the design of the study, data collection, analysis, interpretation, writing, or the decision to submit the article for publication.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.