
Abstract
Abstract
Cyberpsychology is a recently emergent field that examines the impact of technology upon human cognition and behavior. Given its infancy, authors have rapidly created new measures to gauge their constructs of interest. Unfortunately, few of these authors have had the opportunity to test their scales' psychometric properties and validity. This is concerning, as many theoretical assumptions may be founded upon scales with inadequate attributes. If this were found to be true, then previous findings in cyberpsychology studies would need to be retested, and future research would need to shift its focus to creating psychometrically sound and valid measures. To provide inferences on this concern, the current study examines the article reporting, scale creation, and scale reliabilities of every article published in Cyberpsychology, Behavior, and Social Networking from its inception to July 2014. The final data set encompassed the coding of 1,478 individual articles, including 921 scales, and spanning 17 years. The results demonstrate that the simple survey methodology has become more popular over time. Authors are gradually applying empirically tested scales. However, self-created measures are still the most popular, leading to concerns about the measures' validity. Also, the use of multi-item measures has increased over time, but many articles still fail to report adequate information to assess the reliability of the applied scales. Lastly, the average scale reliability is 0.81, which barely meets standard cutoffs. Overall, these results are not overly concerning, but suggestions are given on methods to improve the reporting of measures, the creation of scales, and the state of cyberpsychology.
Introduction and Background
T
When using the simple survey design, constructs are often measured by multiple aggregated items, which is considered a scale. It is often challenging to discern whether scales adequately measure their constructs of interest, causing the use of reliable and valid measures to be of paramount importance. However, cyberpsychology is a relatively new field, and researchers have had little time to create established measures for many cyberpsychology constructs. Often, authors are forced to administer self-created measures that have little or no investigation into their psychometric properties or validity.15–17 It is possible that many of these measures may not adequately gauge their intended constructs. If this were found to be true, then previous findings in cyberpsychology studies would need to be retested. Therefore, the current article provides an overview of cyberpsychology scales, as well as an investigation into the scale information reported by researchers.
In the following, findings are presented that analyze authors' uses and reporting of scales, as well as the scales' creation, validity, and reliability. As often claimed, “reliability is a necessary, but not sufficient, condition for validity.”18–20 Although a scale's reliability is not enough to ensure its validity, it is a necessary component. Scales with low reliability can greatly alter research findings and skew the interpretation of construct relatedness.21,22 Through analyzing these factors, the current article provides an important overview of the field, which may guide future research and practice.
Methods
The current study analyzed and coded every article that has been published in Cyberpsychology, Behavior, and Social Networking until July 2014 (Volume 17, Issue 7). This journal was specifically chosen because it is a flagship publication of cyberpsychology studies and characteristic of the larger cyberpsychology field. Two coders concurrently coded seven issues and discussed coding decisions. Then, they independently coded two issues to calculate interrater agreement statistics. The raw interrater agreement was 97%, and the Holsti coefficient of reliability 23 was 0.96, which are considered satisfactory by many standards.24–26 The two raters proceeded to code the remaining Cyberpsychology, Behavior, and Social Networking issues independently. After completely coding all articles and scales, the coders then randomly selected approximately 50 articles to recode in order to re-examine the accuracy of their original coding decisions. No systematic discrepancies arose. These methods were adapted from previous authors' suggestions.27,28 The final data set contained 1,478 individual articles and 921 scales spanning 17 years.
Additionally, although researchers sometimes discard data that were used for training purposes or determining interrater agreement, such as the nine Cyberpsychology, Behavior, and Social Networking issues noted above, this was not done in the current study. These nine issues represented data that could not be replaced through obtaining a larger sample size, and subsequent analyses would suffer without their inclusion. For this reason, they were retained in the analyses.
Lastly, single item measures of time spent on the Internet were not coded within the current study for two reasons. First, most cyberpsychology studies include these measures. If included, some of the current study's coded variables, such as whether an article included single item measures (described below), would not demonstrate adequate variability for statistical analyses. Second, measuring time spent on the Internet is substantively different from most other self-report scales. Most scales measure latent constructs, which are mental abstractions that describe an idea. Alternatively, measuring time spent on the Internet gauges a specific behavior. While it has some of the same concerns as other scales, time spent on the Internet is more prone to recall effects, causing researchers to be concerned with alternative aspects of the measure. Therefore, the exclusion of these single item measures does not indicate that these measures are unimportant, as an extreme number of noteworthy findings are based upon the single-item measurement of Internet use. However, measuring time spent on the Internet through this method is theoretically and conceptually different from most other self-report scales.
Article coding
For inclusion in scale analyses, each article was coded on the first variable below (used simple survey design). If it was coded into this variable, then the article was coded on the second variable below (cyberpsychology scale). If the article met both of these criteria, then it was coded on the rest of the variables below.
Used simple survey design
Each article was coded on whether the authors employed a simple survey methodology. To be considered a simple survey methodology, authors could not have applied any experimental manipulation or include any qualitative data.
Cyberpsychology scale
Articles were coded on whether they included a scale measuring any technology-related construct. For example, a scale measuring online gambling addiction 29 would be considered a cyberpsychology scale, but a general gambling addiction scale 30 would not.
All scale reliabilities included
Articles were coded on whether reliabilities for all measures were included. Although only Cronbach's alphas were recorded for individual scale coding, articles were considered to have reported all reliabilities if they presented alternative indicators of reliability.
Single item measures
Articles were coded on whether they administered a single item measure, and whether they only included single item measures.
Sufficient information provided
Each article was coded on whether they included sufficient information when reporting their scales, such as reliabilities, constructs, and number of items.
Scale coding
If an article contained a cyberpsychology scale, then the scale was coded on the variables presented below. However, if an article did not include reliabilities for all their measures, then none of their scales was coded within the database. This was done to ensure that authors did not “cherry pick” scales displaying high reliabilities, leaving low-reliability scales unreported.
Reliability
Each scale's Cronbach's alpha was recorded. A small portion of studies provided alternative forms of reliability, such as composite or test–retest reliability, and they were not included in the analyses. Although these other forms of reliability are certainly valid, they are not statistically analogous to Cronbach's alphas 29 and could systematically bias results.
Self-created
Scales were coded on whether they were created for the purpose of the article.
Previously used
Scales were coded on whether they were used in previous articles.
Validation
Scales were coded on whether their psychometric properties and/or validity were investigated in a previous study.
Validation study
Scales were coded on whether the article's purpose was to explore the validity and/or psychometric properties of the specific measure.
Adapted from a noncyberpsychology scale
Scales were coded on whether they were adapted from a noncyberpsychology scale.
Adapted from a previous scale
Scales were coded on whether they were adapted from a previous scale, both cyberpsychology related and noncyberpsychology related.
Results
Table 1 presents all information about the nature of articles in Cyberpsychology, Behavior, and Social Networking, whereas Tables 2 and 3 present information about the scales. To observe longitudinal trends better, Figures 1–3 are included. Before performing any statistical analyses, all variables were standardized through creating z-scores, as the coded variables and reliabilities were not normally distributed. An analysis of variance (ANOVA) of the number of articles that used the simple survey design by year was statistically significant, F=15.855, p<0.001, dfnum=16, dfdem=1,415. Analyzing descriptive trends reveals that this significance is due to a steady increase over time in the use of the simple survey methodology. Another ANOVA of the number of articles that included sufficient reporting information by year was statistically significant, F=2.675, p<0.001, dfnum=16, dfdem=543. Descriptive trends indicate that the reporting of scales has improved over time.

Percentage of articles that used simple survey design.
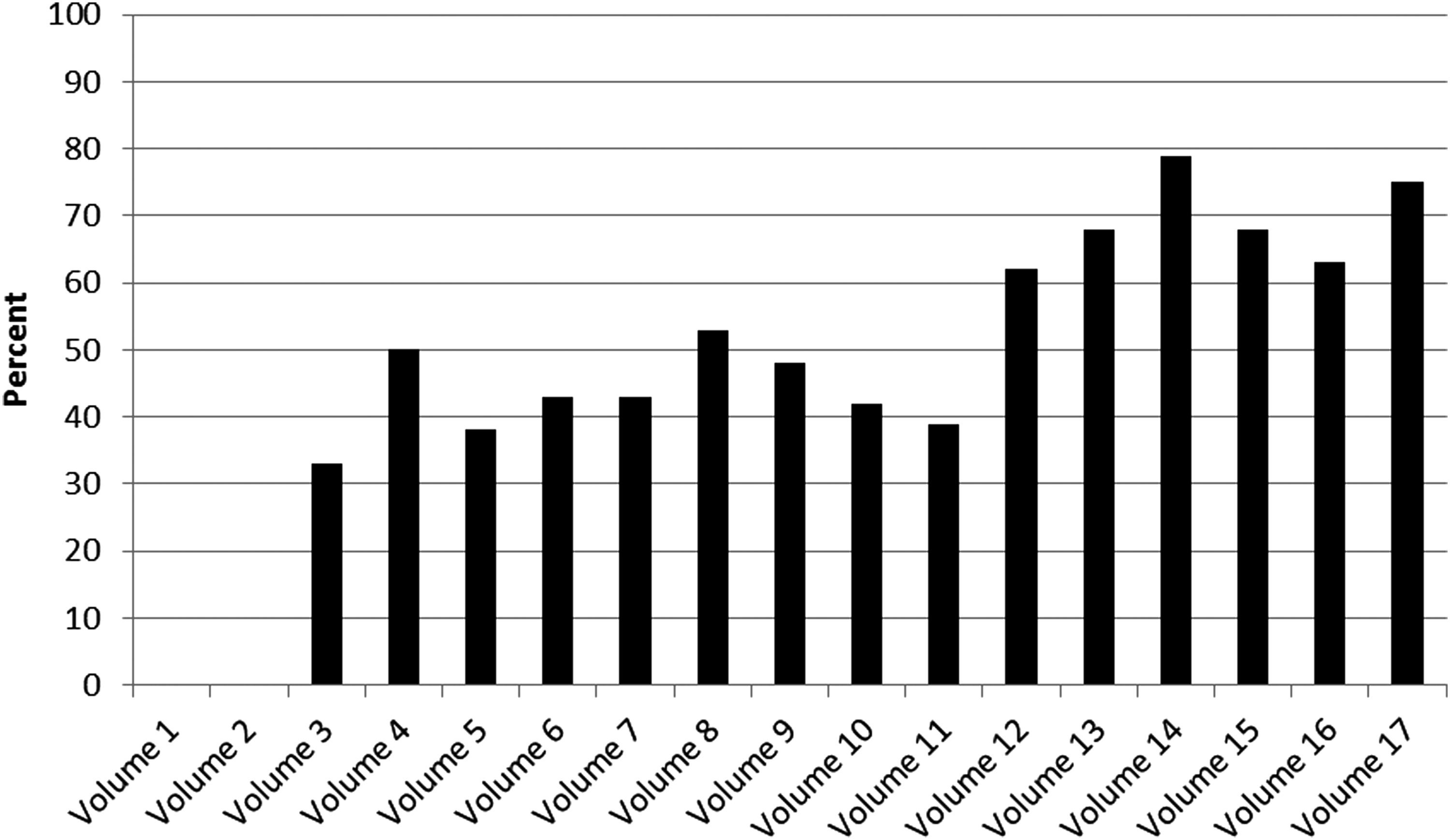
Percentage of articles that reported sufficient scale information.

Average scale reliability.
Percentage is from total number of articles.
Percentage is from total number of articles that used simple survey design.
Percentage is from total number of articles that used simple survey design and included a cyberpsychology scale.
Percentage is from total number of articles that used simple survey design, included a cyberpsychology scale, and included at least one multiple item measure.
Volume 17 only consisted of seven issues at time of coding.
Volume 17 only consisted of seven issues at time of coding.
All scales are only those taken from articles that reported sufficient information on all measures.
Volume 17 only consisted of seven issues at time of coding.
The reliabilities of scales within Cyberpsychology, Behavior, and Social Networking varied greatly, ranging from 0.02 to 0.97. The average reliability across all years was 0.81, and the median was 0.83. An ANOVA of scale reliabilities by year was statistically significant, F=3.345, p<0.001, dfnum=14, dfdem=898, showing that notable differences exist across years. An additional ANOVA of the number of scales that were self-created by year was statistically significant, F=5.113, p<0.001, dfnum=14, dfdem=898, indicating that the use of self-created measures has fluctuated over time.
Discussion
These results demonstrate several notable findings. First, the simple survey methodology is rapidly growing in popularity in cyberpsychology, as shown in Table 1 and Figure 1. During the inception of Cyberpsychology, Behavior, and Social Networking, the simple survey methodology saw little use, accounting for only 9%, 8%, and 6% of articles in 1998, 1999, and 2000, respectively. This number quickly grew, accounting for up to 64% of all studies in 2012. A possible reason for this shift may be changes in research interests. Authors have continuously demonstrated interest in certain concepts measured through self-report, such as Internet addiction31–33 and computer-related perceptions.34–36 Likewise, many variables recently growing in popularity are also measured through self-report, particularly those related to social networking,37–39 smartphones,40–42 online gaming,43–45 cyberbullying,46–48 and blogging.49,50 Studies regularly infer several aspects of these topics, such as motives51–53 and intentions,54–56 through this measurement method. Together, these historic topics along with new trends prompt the growing use of self-report surveys.
Second, apparent from Table 1, authors are using more comprehensive measures and fewer single item measures. This is fortunate because multiple item measures demonstrate several advantages over single item measures. The reliability of multiple item measures is stronger than single item measures, as individuals give less consistent answers to single item measures.57,58 Also, the validity of multiple item measures is better than single item measures, as many constructs are “broad in scope and simply cannot be assessed with a single question.” 57 (p673) These two factors partially demonstrate the recent improvement in cyberpsychology scales' validity and reliability, and bolster authors' abandonment of single item measures.
Third, authors have become more comprehensive in the reporting of their scale properties, as seen in Table 1 and Figure 2. No article within the first 2 years of Cyberpsychology, Behavior, and Social Networking reported all sufficient scale information. Then, starting in 2000, authors increasingly improved their scale reporting, reaching a high of 79% of articles reporting sufficient information in 2011.
Fourth, as seen in Table 2 and Figure 3, the reliabilities of scales have trended toward the traditional 0.80 benchmark of acceptability.59,60 However, since 2000, no volume's average reliability has exceeded 0.83. Although 0.80 is the benchmark of acceptability, it is also the standard. Authors should strive to create scales with higher reliabilities and more robust psychometric properties. To add to this concern, a small note should be made. The current study only coded scales within articles that presented all reliabilities. It is possible, if not likely, that many authors discovered Cronbach's alphas well below 0.80 and chose not to report them. If this were true, then the reliabilities seen in the current article are a “best case” scenario, as the coding only includes articles that included all reliabilities. Future cyberpsychology scholars should seek to improve the reliabilities of their measures.
Fifth, as shown in Table 3, authors are still largely reliant on self-created measures, likely due to the lack of existing empirically tested measures. This dearth may partially explain the evidenced modest reliabilities. This finding also draws concerns over the validity of extant measures. Few authors have investigated the nomological networks of their created measures, prompting uncertainty toward the extent that these measures reflect the constructs of interest.
Future research should develop psychometrically sound and valid measures of cyberpsychology constructs, as well as empirically test the validity of extant scales. Particularly, a need is evident for an empirically tested measure of time spent on the Internet, as many extant studies apply potentially problematic single item measures to gauge this extremely important construct.
Footnotes
Acknowledgment
We would like to thank Melissa B. Gutworth for her comments on a previous version of this article.
Author Disclosure Statement
No competing financial interests exist.