
Abstract
Abstract
Human–robot interaction (HRI) will soon transform and shift the communication landscape such that people exchange messages with robots. However, successful HRI requires people to trust robots, and, in turn, the trust affects the interaction. Although prior research has examined the determinants of human–robot trust (HRT) during HRI, no research has examined the messages that people received before interacting with robots and their effect on HRT. We conceptualize these messages as SMART (Strategic Messages Affecting Robot Trust). Moreover, we posit that SMART can ultimately affect actual HRI outcomes (i.e., robot evaluations, robot credibility, participant mood) by affording the persuasive influences from user-generated content (UGC) on participatory Web sites. In Study 1, participants were assigned to one of two conditions (UGC/control) in an original experiment of HRT. Compared with the control (descriptive information only), results showed that UGC moderated the correlation between HRT and interaction outcomes in a positive direction (average Δr = +0.39) for robots as media and robots as tools. In Study 2, we explored the effect of robot-generated content but did not find similar moderation effects. These findings point to an important empirical potential to employ SMART in future robot deployment.
Introduction
R
Human–robot trust
Human–robot trust (HRT) serves as a foundation to HRI.7,8 HRT is a crucial empirical and practical problem. Anticipating HRI, people experience heightened uncertainties and lower expectations of social attraction compared with human interaction. 9 Recent findings estimate that approximately a quarter of the U.S. population experiences a heightened level of fear toward robots and artificial intelligence (Liang Y, Lee SA. “Fear of autonomous robots and artificial intelligence: evidence from national representative data with probability sampling,” unpublished data). These results document a societal-level problem with robot avoidance and fear, likely affecting HRT.
Research shows that robot task performance affects HRT. 10 However, robots are not immune to errors and technical problems, and performance does not fully address contexts where the need for higher-level trust is emerging (e.g., battlefield).8,11 Instead of engineering robot performance, this research focuses on engineering HRT through messages that people receive.
Mayer et al. conceptualize trust as “the willingness of a party (i.e., users) to be vulnerable to the actions of another party (i.e., robot) based on the expectation that the other will perform a particular action important to the trustor.”12(p712) This conceptualization differs from trustworthiness, 13 which relates to the idea of source morality. Based on Mayer et al., we conceptualize trust as risk-taking and actual user behavior. This conceptualization aligns more closely to future HRI and collaborative robots (co-robots). 11
Preinteraction messages affect HRT based on interpersonal theories of communication. These theories point to a clear effect of preconceived expectations5,14,15 on the actual future interaction. Similarly, messages regarding robot partners can strategically alter pending HRI by modifying user expectations. These messages are strategic in that they can be selected on the basis of increasing HRT. Accordingly, we advance a new terminology, Strategic Messages Affecting Robot Trust (SMART). One type of SMART originates from other users.
Persuasive influence of user-generated content
User-generated content (UGC) refers to messages that naïve individuals exchange online to evaluate a person or product (e.g., product reviews). UGC affords unique persuasiveness given the inherent trust between users. 16 It also features and aggregates multiple sources of persuasive influence. 3 Research points to a robust effect of UGC such that readers are attitudinally affected by UGC's valence.17,18 In addition, research shows that UGC can affect indirect outcomes, including learning.19,20 UGC may directly shape people's HRT given its persuasive effects. Alternatively, UGC may re-shape how HRT affects HRI and the associated outcomes described later.
Functional triad and interaction outcomes
Fogg 21 conceptualizes that persuasive technologies elicit interactive experiences in three aspects that are called the functional triad. Robots serve as such a technology given their ability to affect users. 22 First, robots as media refers to the robots' ability to create experiences. For instance, robots can affect people's affective state, or mood, which contains both positive and negative dimensions. 23 Second, robots as tools refers to the robots' functional and task-related capabilities. The technology acceptance model 24 proposes that adoption behaviors predicate on the technology's perceived usefulness and ease of use, which apply to robots. Finally, robots as social actors occur when users respond to robots or regard them as social entities. Users may evaluate the credibility of robots as a social source based on competence, trustworthiness, and caring.13,25
Given the relationships between UGC, HRT, and interaction outcomes previously described, this research advances two SMART models (Fig. 1). The first mediation model posits that UGC directly affects trust, which, in turn, affects the interaction outcomes. This explanation follows the persuasive effects of UGC from previous research. The second moderation model states that UGC alters the relationship between HRT and interaction outcomes. This competing hypothesis posits that UGC affects how users regard robots in terms of pending the interaction experience. UGC may facilitate users in cognitively searching for more favorable experiences with robots during the actual interaction, consistent with interpersonal theories of relational development and impression formation.14,15 The models are formalized here:
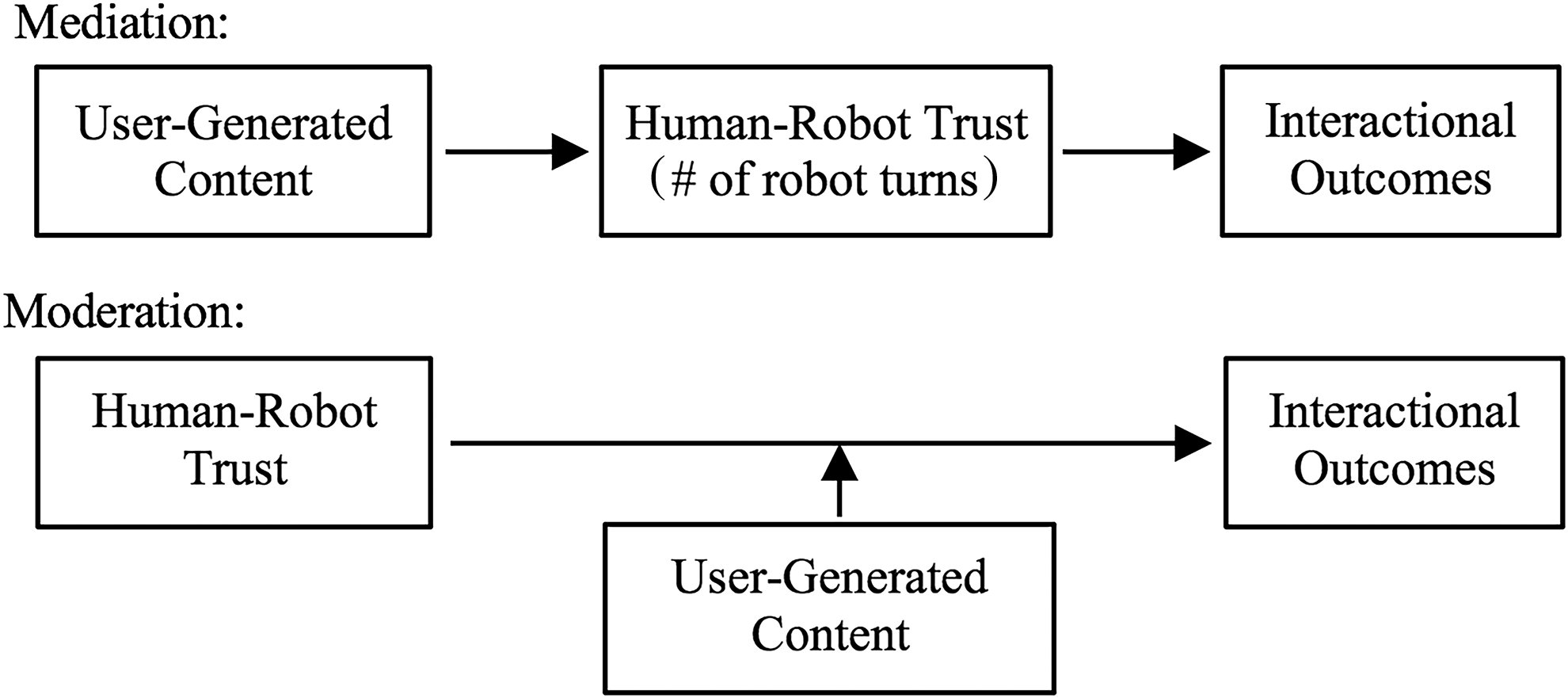
User-generated content, trust, and interaction outcomes: mediation versus moderation models.
Study 1: User-Generated Content
Method
Procedure
Participants (N = 52) were undergraduate students in a communication department subject pool at a private university. This pool contained more female participants (age = 18–24). After obtaining the Institutional Review Board's approval, participants were assigned to a two-condition experiment (UGC/control). A trained experimenter informed each participant that the 30-minute study involved game play with an ostensible autonomous robot named CASEY. Participants were (a) asked to read game instructions and (b) assigned to read one of two informational online blogs about CASEY (UGC/control conditions) using a lab computer. When participants indicated that they fully understood the instructions and read the blog, the experimenter demonstrated the game and addressed any remaining questions. Then, the experimenter brought CASEY into the room. CASEY displayed an anthropomorphic face (Fig. 2) using a robotic synthesized voice through a text-to-speech system (Microsoft David with −2 speed). A trained robot operator controlled CASEY in another room unseen by the participants. CASEY first greeted and then played the game with each participant (described later). Afterward, the experimenter returned to administer the interaction outcome measures and finally debriefed the participants. Debriefing revealed that the participants were unaware of the study purpose and believed that CASEY was actually autonomous.

The ostensible autonomous robot. Reprinted with permission from Cyberpsychology, Behavior, and Social Networking 2016; 19:524–527.
Human-robot trust game
An original HRI game focused on participants' willingness to allow robot risk-taking. Participants played with CASEY collaboratively to score points as a team, not individually. The rule of the game was simple. Each participant drew from a deck of 12 cards, with heart, diamond, or spade suits. For each card/turn, the participant decided whether the participant or CASEY rolled a dice to score points that equated to the roll. To incur risks during game play, additional rules applied based on the suit drawn such that there were some circumstances where there was more risk to allow CASEY to roll. Without the participant's knowledge, there were four cards of each suit evenly distributed in the deck. CASEY (confederate) tracked the total points during game play.
Experimental inductions
The experiment included UGC and control (n = 26 per condition). The control condition contained only descriptive information about CASEY (Fig. 3). The UGC condition included additional mockup positive reviews (n = 5) simulated from a format that was analogous to

Control descriptive message about CASEY.

Example of experimental user-generated content about CASEY.
Measures
Human–robot trust
HRT conceptualized risk-taking and was measured by the number of turns that participants allocated to CASEY (M = 5.67, SD = 1.72; range: 0–12).
Interactional outcomes
Robot usefulness
Venkatesh and Davis's 25 technology acceptance measures assessed robot usefulness and ease of use. The four-item, seven-point Likert-type measure asked participants to indicate their agreement or disagreement with statements such as: CASEY improved my performance in the game and I found using CASEY to be useful in the game (M = 4.23, SD = 1.22; α = 0.86).
Robot ease of use
A four-item, seven-point Likert-type measure 24 measured ease of use by asking participants to indicate their agreement or disagreement to statements such as: My interaction with CASEY was clear and understandable, and I found CASEY to be easy to use (M = 5.49, SD = 1.20; α = 0.87).
Robot competence
McCroskey and Teven's source credibility measure 13 assessed perceptions toward CASEY. For each dimension of competence, caring, and trustworthiness described later, participants responded to a seven-point semantic-differential measure with a question asking, “How do you feel about CASEY?” Competence items included the following responses: intelligent/unintelligent and expert/inexpert (M = 5.38, SD = 1.09; α = 0.88).
Robot caring
Examples of caring items included (some were reverse items on the survey, affecting reliability) the following: cares about me/doesn't care about me, and has my best interests at heart/doesn't have my best interests at heart (M = 4.24, SD = 0.92; α = 0.61).
Robot trustworthiness
Examples of trustworthiness items included trustworthy/untrustworthy and genuine/phony (M = 4.82, SD = 1.30; α = 0.92).
Participant mood
The PANAS scale 23 assessed participants' positive and negative moods. Participants indicated how they felt after interacting with CASEY on a five-point scale ranging from very slightly or not at all to extremely. Examples of positive mood questions included interested and excited (M = 2.73, SD = 0.90; α = 0.91). Negative mood examples included distressed and afraid (M = 1.36, SD = 0.41; α = 0.77).
Induction check
One 7-point Likert-type item asked participants whether the information they read contained information from other users, ranging from strongly disagree to strongly agree. An independent-samples t test showed that participants rated the UGC condition as providing more information from other users (M = 6.08, SD = 1.15) than the control condition (M = 2.48, SD = 1.16), t(48) = 11.02, p < 0.001, r = 0.84.
Results
The overarching hypothesis compared the mediation (H1) and the moderation (H2) models. The data were inconsistent with H1. The conditions failed to elicit variations in HRT (number of turns), t(46) = 1.94, p = 0.06, r = 0.28. To test the mediation, a correlational analysis examined the relationship between HRT and all interaction outcome variables, with the only significant factor being between HRT and usefulness, r(46) = 0.38, p = 0.01. The correlations between HRT and other interaction outcome variables ranged from r = −0.10 to r = 0.17. Given these results, the hypothesized mediation was unlikely.
To examine the moderation hypothesis in H2, a series of tests were conducted using the PROCESS macro for SPSS, which employs a regression-based path analytic framework for testing mediation, moderation, and conditional process models (i.e., mediated moderation, moderated mediation).26,27 Each interactional outcome received a separate test. Only the significant models are reported.
Positive mood
Overall, the model was significant, R2 = 0.19, F(3, 44) = 3.47, p = 0.02. Positive mood was not a significant predictor of HRT, B = −1.68, SE = 0.88, t(44) = −1.91, p = 0.06, 95% CI [−3.46 to 0.10]. Message condition was a significant predictor of HRT, B = −4.33, SE = 1.52, t(44) = −2.85, p = 0.01, 95% CI [−7.40 to −1.27]. The interaction term between positive mood and message condition accounted for a significant proportion of the variance in HRT, ΔR2 = 0.10, ΔF(1, 44) = 5.33, B = 1.23, SE = 0.53, t(44) = 2.31, p = 0.03, 95% CI [0.16–2.31]. Positive mood positively predicted HRT when UGC was presented, B = 0.79, SE = 0.35, t(44) = 2.26, p = 0.03, 95% CI [0.08–1.49] but not in the control condition, B = −0.45, SE = 0.41, t(44) = −1.10, p = 0.28, 95% CI [−1.26 to 0.37].
Usefulness
Overall, the model was significant, R2 = 0.31. F(3, 44) = 6.55, p < 0.001. Usefulness was not a significant predictor of HRT, B = −0.98, SE = 0.62, t(44) = −1.59, p = 0.12, 95% CI [−2.23 to 0.26]. Message condition was a significant predictor of HRT, B = −5.14, SE = 1.70, t(44) = −3.01, p = 0.004, 95% CI [−8.57 to −1.70]. The interaction term was significant, ΔR2 = 0.11, ΔF(1, 44) = 6.72, B = 0.98, SE = 0.38, t(44) = 2.59, p = 0.01, 95% CI [0.22–1.75]. Usefulness positively predicted HRT when UGC was presented, B = 0.98, SE = 0.25, t(44) = 3.86, p < 0.001, 95% CI [0.47–1.49], but not in the control condition, B = −0.001, SE = 0.28, t(44) = −0.004, p = 0.99, 95% CI [−0.57 to 0.57].
Ease of use
Overall, the model was significant, R2 = 0.21, F(3, 44) = 3.82, p = 0.02. Ease of use was not a significant predictor of HRT, B = −1.06, SE = 0.60, t(44) = −1.77, p = 0.08, 95% CI [−2.27 to 0.14]. Message condition was a significant predictor of HRT, B = −6.00, SE = 2.19, t(44) = −2.74, p = 0.01, 95% CI [−10.42 to −1.58]. The interaction term was significant, ΔR2 = 0.10, ΔF(1, 44) = 5.43, B = 0.89, SE = 0.38, t(44) = 2.33, p = 0.02, 95% CI [0.12–1.67]. Ease of use positively predicted HRT when UGC was presented, B = 0.73, SE = 0.28, t(44) = 2.62, p = 0.01, 95% CI [0.17–1.28], but not in the control condition, B = −0.17, SE = 0.27, t(44) = −0.63, p = 0.53, 95% CI [−0.70 to 0.37].
Summary
Overall, the data revealed a clear pattern of a moderating effect. UGC positively shifted the relationship between HRT and three out of seven interaction outcomes. In the control condition, HRT correlated negatively with all seven interaction outcomes. In the UGC condition, all correlations shifted toward a positive direction. The average correlation shift was +0.39 for the moderating effect on interaction outcomes. Table 1 provides the details of the changes in correlations. The moderation analyses revealed also showed that competence approached conventional levels of statistical significance (p = 0.09). Given the overall directions of findings, the data were consistent with the moderation hypothesis.
UGC, user-generated content.
Discussion
Results showed a clear SMART effect. Specifically, the data showed that UGC modifies HRI by changing the outcomes in a positive direction. There are multiple applications for the SMART effect; however, implementation requires that UGC is populated as a form of strategic communication before robot deployment. However, such content may be difficult to accrue initially and may be time consuming to achieve practically. The second study aims at addressing this concern. Specifically, it aims at an easier and direct manner to deploy the strategic messages: utilizing the robot as the source of its own strategic messages. Alternatively, if a robot generated the same content as other users, would the content have the same effect? This approach, however, loses UGC's clear theoretical and persuasive affordances. However, testing robot-generated content offers a more practical angle for utilizing the strategic message perspective. Experimentally, providing a robot-generated content condition ascertains whether the previously observed moderation effects can be attributed to the information provided in the message content or the source of the content (i.e., people or robots). Based on this logic, the first RQ is advanced:
Study 2: Robot-Generated Content
Method and procedure
The procedures and experimental setup mirrored Study 1. The only exception is that the UGC was modified to change the source to CASEY. The blog provided information that indicated, “CASEY says…” with statements such as “[People] were impressed by my ability to do things like, play games with them, talk to them, and how was able to maintain myself.” Informationally, the new robot-generated content condition remained identical to UGC, except that the content was credited to CASEY. To control for heuristics or social approval of the message, the number of stars, date of review, and number of helpful ratings remained identical to the UGC condition. All participants (n = 16) were debriefed at the end of the experiment and thanked for their participation.
Results
The data were first analyzed for mediation effects. Compared with the control condition from Study 1 (M = 6.13, SD = 1.51), the robot-generated content failed to elicit differences in HRT (M = 5.81, SD = 1.38), t(38) = 0.66, p = 0.51, r = 0.11. HRT did not correlate with the interaction outcomes, inconsistent with the mediation model (Table 2). Similar to Study 1, the PROCESS macro 26 tested and did not reveal a moderation pattern across any outcomes.
The average positive shift in correlation was +0.13. Interestingly, some aspects of interaction outcomes actually shifted negatively: ease of use and caring. Given the conflicted direction of effects (positive and negative) and the absence of statistically significant findings, robot-generated content has only limited to no effect on HRT and interaction outcomes.
General Discussion
To summarize, the findings demonstrated that UGC moderated the effects of HRT on interaction outcomes. Although the sample size and characteristics were limited, the effects of UGC were substantial to elicit significant differences between the control and the positive review conditions. Reading UGC altered the relationship such that HRT actually led to a better mood and more positive evaluations of the robot as tools (i.e., usefulness and ease of use). In Study 2, robot-generated content instead of UGC led to no significant moderation effects. Robot-generated content increased perceived robot competence to some degree, but it failed to reach statistical significance. Comparably, the moderating effects for UGC were globally stronger than robot-generated content (average r = 0.39 vs. r = 0.13). Although these effects do not differ significantly from each other given the limited sample size, the results showed that the UGC effects were likely attributed to aspects regarding the message source. Message content alone (robot-generated content) was insufficient to yield the strong effects observed.
The results render a novel and interesting picture regarding how UGC affects HRI and stimulates theoretical work on employing strategic messages to facilitate HRI. We advance a conceptual model of HRI and HRT that involves three stages of communication: preinteraction, initial, and relationship. The current findings encourage and enable a new genre of communication research examining the effect of strategic messages at a preinteraction stage, and how these messages affect HRT. In fact, work is already underway to examine the initial stage, with the ultimate goal of coupling the preinteraction and the initial stages to understand the cumulative effect of communication in building trust between humans and robots. Future work will integrate these results into the relationship stage.
At a practical level, the results offer suggestions for designers and engineers who aim at capitalizing on the SMART effect. These findings are crucial as the HRI community searches for ways to introduce society at large to pending human–robot collaboration (i.e., co-robot 11 ). The current findings also indicate large effect sizes, presenting a clear opportunity to enhance the relationship between HRT and interaction outcomes. We offer some suggestions for robot practitioners. First, it is clear that UGC or robot-generated content failed to directly affect HRT or interaction outcomes. Instead, the results document a clear role of SMART as a moderator between the two. Thus, applications of this research should not focus on building trust or enhancing interaction outcomes directly through strategic messages. Rather, the applications should focus on augmenting the effects of initial trust on maximizing favorable interaction outcomes by employing SMART. Second, although the content utilized in this study involved UGC as a form of social influence, other types of persuasive messages may still afford similar effects. More research is needed to identify the specific mechanisms that drive the effect.
Although the results are encouraging, care should be taken given the small sample size at a single university with certain demographics. These results may differ for more technically oriented (e.g., engineering) students. Moreover, negative reviews were not examined; only positive online reviews were tested. The UGC environment is replete with both positive and negative information, and the current study should be replicated with negative information mixed alongside positive information. Despite the limitations, the findings are exciting as a portal for communication research in HRI. The results presented here offer an empirical basis for more work examining message effects on trust in HRI. Certainly, the results are encouraging as preliminary data to justify a new genre of research examining the effects of receiving preinteractional messages, such as UGC, on HRI.
Footnotes
Author Disclosure Statement
No competing financial interests exist.